Gradle 用户手册:版本 8.7
概述
梯度用户手册
Gradle 构建工具
Gradle Build Tool 是一种快速、可靠且适应性强的开源构建自动化工具,具有优雅且可扩展的声明性构建语言。

在本用户手册中,Gradle Build Tool 缩写为Gradle。
为什么是摇篮?
Gradle 是一种广泛使用且成熟的工具,拥有活跃的社区和强大的开发者生态系统。
-
Gradle 是最流行的 JVM 构建系统,也是 Android 和 Kotlin 多平台项目的默认系统。它拥有丰富的社区插件生态系统。
-
Gradle 可以使用其内置功能、第三方插件或自定义构建逻辑来自动化各种软件构建场景。
-
Gradle 提供了一种高级的、声明性的、富有表现力的构建语言,使构建逻辑的阅读和编写变得容易。
-
Gradle 速度快、可扩展,并且可以构建任何规模和复杂性的项目。
-
Gradle 生成可靠的结果,同时受益于增量构建、构建缓存和并行执行等优化。
Gradle, Inc. 提供名为Build Scan®的免费服务,可提供有关构建的广泛信息和见解。您可以查看扫描以识别问题或共享它们以获取调试帮助。

兼容的 IDE
所有主要 IDE 都支持 Gradle,包括 Android Studio、IntelliJ IDEA、Visual Studio Code、Eclipse 和 NetBeans。

您还可以通过终端中的命令行界面(CLI) 或通过持续集成 (CI) 服务器调用 Gradle。
教育
Gradle用户手册是 Gradle 构建工具的官方文档。
-
入门教程—了解 Gradle 基础知识以及使用 Gradle 构建应用程序的好处。
-
培训课程— 前往课程页面注册免费 Gradle 培训。
许可证
Gradle Build Tool 源代码是开放的,并根据Apache License 2.0获得许可。 Gradle 用户手册和 DSL 参考手册已根据Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License获得许可。
用户手册
浏览我们的 Gradle 使用指南和示例。
内容
Gradle 用户手册分为以下部分:
- 运行 Gradle 构建
-
了解 Gradle 基础知识以及如何使用 Gradle 构建项目。
- 编写 Gradle 构建
-
开发任务和插件来定制您的构建。
- 编写 JVM 构建
-
将 Gradle 与您的 Java 项目结合使用。
- 使用依赖项
-
将依赖项添加到您的构建中。
- 优化构建
-
使用缓存来优化您的构建并了解 Gradle 守护进程、增量构建和文件系统监视。
- CI 上的 Gradle
-
Gradle 与流行的持续集成 (CI) 服务器集成。
发布
安装 Gradle
摇篮安装
如果您只想运行现有的 Gradle 项目,并且构建使用Gradle Wrapper ,则无需安装 Gradle 。这可以通过项目根目录中是否存在gradlew或文件来识别:gradlew.bat
. // (1) ├── gradle │ └── wrapper // (2) ├── gradlew // (3) ├── gradlew.bat // (3) └── ⋮
-
项目根目录。
-
用于执行 Gradle 构建的脚本。
如果gradlew或gradlew.bat文件已存在于您的项目中,则无需安装 Gradle。但您需要确保您的系统满足 Gradle 的先决条件。
如果您想更新项目的 Gradle 版本,可以按照升级 Gradle 部分中的步骤进行操作。请使用Gradle Wrapper升级 Gradle。
Android Studio 附带了 Gradle 的有效安装,因此当您仅在该 IDE 中工作时,无需单独安装 Gradle。
如果您不满足上述条件并决定在计算机上安装 Gradle,请首先通过gradle -v在终端中运行来检查 Gradle 是否已安装。如果该命令没有返回任何内容,则 Gradle 尚未安装,您可以按照以下说明进行操作。
您可以在 Linux、macOS 或 Windows 上安装 Gradle Build Tool。安装可以手动完成,也可以使用像SDKMAN 这样的包管理器完成!或自制。
您可以在版本页面上找到所有 Gradle 版本及其校验和。
先决条件
Gradle 可以在所有主要操作系统上运行。它需要Java 开发工具包(JDK) 版本 8 或更高版本才能运行。您可以检查兼容性矩阵以获取更多信息。
要检查,请运行java -version:
❯ java -version openjdk version "11.0.18" 2023-01-17 OpenJDK Runtime Environment Homebrew (build 11.0.18+0) OpenJDK 64-Bit Server VM Homebrew (build 11.0.18+0, mixed mode)
❯ java version "1.8.0_151" Java(TM) SE Runtime Environment (build 1.8.0_151-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
Gradle 使用它在您的路径中找到的 JDK、IDE 使用的 JDK 或项目指定的 JDK。在此示例中,$PATH 指向 JDK17:
❯ echo $PATH /opt/homebrew/opt/openjdk@17/bin
您还可以将JAVA_HOME环境变量设置为指向特定的JDK安装目录。当安装了多个 JDK 时,这尤其有用:
❯ echo %JAVA_HOME% C:\Program Files\Java\jdk1.7.0_80
❯ echo $JAVA_HOME /Library/Java/JavaVirtualMachines/jdk-16.jdk/Contents/Home
Linux安装
使用包管理器安装
SDKMAN!是一个用于管理大多数类 Unix 系统(macOS、Linux、Cygwin、Solaris 和 FreeBSD)上多个软件开发套件的并行版本的工具。 Gradle由SDKMAN部署和维护!:
❯ sdk install gradle
其他包管理器也可用,但它们分发的 Gradle 版本不受 Gradle, Inc. 控制。Linux 包管理器可能会分发与官方版本不兼容或不完整的 Gradle 修改版本。
手动安装
第 1 步 -下载最新的 Gradle 发行版
分发 ZIP 文件有两种形式:
-
仅二进制 (bin)
-
完整(全部)包含文档和来源
我们建议下载bin文件;它是一个较小的文件,可以快速下载(并且可以在线获取最新的文档)。
第 2 步 - 解压发行版
将分发 zip 文件解压缩到您选择的目录中,例如:
❯ mkdir /opt/gradle ❯ unzip -d /opt/gradle gradle-8.7-bin.zip ❯ ls /opt/gradle/gradle-8.7 LICENSE NOTICE bin README init.d lib media
第 3 步 - 配置您的系统环境
要安装 Gradle,解压文件的路径需要位于您的 Path 中。配置PATH环境变量以包含bin解压发行版的目录,例如:
❯ export PATH=$PATH:/opt/gradle/gradle-8.7/bin
或者,您也可以添加环境变量GRADLE_HOME并将其指向解压缩的发行版。PATH您可以将特定版本的 Gradle 添加$GRADLE_HOME/bin到您的PATH.升级到不同版本的 Gradle 时,只需更改GRADLE_HOME环境变量即可。
export GRADLE_HOME=/opt/gradle/gradle-8.7
export PATH=${GRADLE_HOME}/bin:${PATH}
macOS安装
手动安装
第 1 步 -下载最新的 Gradle 发行版
分发 ZIP 文件有两种形式:
-
仅二进制 (bin)
-
完整(全部)包含文档和来源
我们建议下载bin文件;它是一个较小的文件,可以快速下载(并且可以在线获取最新的文档)。
第 2 步 - 解压发行版
将分发 zip 文件解压缩到您选择的目录中,例如:
❯ mkdir /usr/local/gradle ❯ unzip gradle-8.7-bin.zip -d /usr/local/gradle ❯ ls /usr/local/gradle/gradle-8.7 LICENSE NOTICE README bin init.d lib
第 3 步 - 配置您的系统环境
要安装 Gradle,解压文件的路径需要位于您的 Path 中。配置PATH环境变量以包含bin解压发行版的目录,例如:
❯ export PATH=$PATH:/usr/local/gradle/gradle-8.7/bin
或者,您也可以添加环境变量GRADLE_HOME并将其指向解压缩的发行版。PATH您可以将特定版本的 Gradle 添加$GRADLE_HOME/bin到您的PATH.升级到不同版本的 Gradle 时,只需更改GRADLE_HOME环境变量即可。
最好.bash_profile在主目录中编辑以添加GRADLE_HOME变量:
export GRADLE_HOME=/usr/local/gradle/gradle-8.7 export PATH=$GRADLE_HOME/bin:$PATH
Windows安装
手动安装
第 1 步 -下载最新的 Gradle 发行版
分发 ZIP 文件有两种形式:
-
仅二进制 (bin)
-
完整(全部)包含文档和来源
我们建议下载 bin 文件。
第 2 步 - 解压发行版
C:\Gradle使用文件资源管理器创建一个新目录。
打开第二个文件资源管理器窗口并转到下载 Gradle 发行版的目录。双击 ZIP 存档以公开内容。将内容文件夹拖到gradle-8.7新创建的C:\Gradle文件夹中。
C:\Gradle或者,您可以使用您选择的归档工具将 Gradle 发行版 ZIP 解压。
第 3 步 - 配置您的系统环境
要安装 Gradle,解压文件的路径需要位于您的 Path 中。
在文件资源管理器中,右键单击This PC(或Computer) 图标,然后单击Properties→ Advanced System Settings→ Environmental Variables。
在System Variables选择下Path,然后单击Edit。添加一个条目C:\Gradle\gradle-8.7\bin.单击OK保存。
或者,您可以添加环境变量GRADLE_HOME并将其指向解压缩的发行版。Path您可以将特定版本的 Gradle 添加%GRADLE_HOME%\bin到您的Path.升级到不同版本的Gradle时,只需更改GRADLE_HOME环境变量即可。
验证安装
打开控制台(或 Windows 命令提示符)并运行gradle -vgradle 并显示版本,例如:
❯ gradle -v ------------------------------------------------------------ Gradle 8.7 ------------------------------------------------------------ Build time: 2023-03-03 16:41:37 UTC Revision: 7d6581558e226a580d91d399f7dfb9e3095c2b1d Kotlin: 1.8.10 Groovy: 3.0.13 Ant: Apache Ant(TM) version 1.10.11 compiled on July 10 2021 JVM: 17.0.6 (Homebrew 17.0.6+0) OS: Mac OS X 13.2.1 aarch64
您可以通过下载 SHA-256 文件(可从发布页面获取)并遵循这些验证说明来验证 Gradle 发行版的完整性。
兼容性矩阵
以下部分描述了 Gradle 与多种集成的兼容性。此处未列出的版本可能有效,也可能无效。
Java
执行 Gradle 需要 8 到 21 之间的 Java 版本。尚不支持 Java 22 及更高版本。
Java 6 和 7 可用于编译,但不推荐用于测试。 Gradle 9.0 不支持使用 Java 6 和 7 进行测试。
任何完全支持的 Java 版本都可以用于编译或测试。但是,最新的 Java 版本可能仅支持编译或测试,而不支持运行 Gradle。支持是使用工具链实现的,并适用于支持工具链的所有任务。
请参阅下表了解特定 Gradle 版本支持的 Java 版本:
| Java版本 | 对工具链的支持 | 支持运行 Gradle |
|---|---|---|
8 |
不适用 |
2.0 |
9 |
不适用 |
4.3 |
10 |
不适用 |
4.7 |
11 |
不适用 |
5.0 |
12 |
不适用 |
5.4 |
13 |
不适用 |
6.0 |
14 |
不适用 |
6.3 |
15 |
6.7 |
6.7 |
16 |
7.0 |
7.0 |
17 号 |
7.3 |
7.3 |
18 |
7.5 |
7.5 |
19 |
7.6 |
7.6 |
20 |
8.1 |
8.3 |
21 |
8.4 |
8.5 |
22 |
8.7 |
不适用 |
23 |
不适用 |
不适用 |
Kotlin
Gradle 使用 Kotlin 1.6.10 到 2.0.0-Beta3 进行了测试。 Beta 和 RC 版本可能会也可能不会。
| 最低 Gradle 版本 | 嵌入式 Kotlin 版本 | Kotlin 语言版本 |
|---|---|---|
5.0 |
1.3.10 |
1.3 |
5.1 |
1.3.11 |
1.3 |
5.2 |
1.3.20 |
1.3 |
5.3 |
1.3.21 |
1.3 |
5.5 |
1.3.31 |
1.3 |
5.6 |
1.3.41 |
1.3 |
6.0 |
1.3.50 |
1.3 |
6.1 |
1.3.61 |
1.3 |
6.3 |
1.3.70 |
1.3 |
6.4 |
1.3.71 |
1.3 |
6.5 |
1.3.72 |
1.3 |
6.8 |
1.4.20 |
1.3 |
7.0 |
1.4.31 |
1.4 |
7.2 |
1.5.21 |
1.4 |
7.3 |
1.5.31 |
1.4 |
7.5 |
1.6.21 |
1.4 |
7.6 |
1.7.10 |
1.4 |
8.0 |
1.8.10 |
1.8 |
8.2 |
1.8.20 |
1.8 |
8.3 |
1.9.0 |
1.8 |
8.4 |
1.9.10 |
1.8 |
8.5 |
1.9.20 |
1.8 |
8.7 |
1.9.22 |
1.8 |
Groovy
Gradle 使用 Groovy 1.5.8 到 4.0.0 进行了测试。
用 Groovy 编写的 Gradle 插件必须使用 Groovy 3.x 才能与 Gradle 和 Groovy DSL 构建脚本兼容。
安卓
Gradle 使用 Android Gradle 插件 7.3 到 8.2 进行了测试。 Alpha 和 Beta 版本可能有效,也可能无效。
功能生命周期
Gradle 正在不断开发。如生命周期终止支持部分所述,定期且频繁地(大约每六周)提供新版本。
持续改进与频繁交付相结合,可以让新功能尽早提供给用户。早期用户提供了宝贵的反馈,这些反馈已纳入开发过程。
定期将新功能交付给用户是 Gradle 平台的核心价值。
同时,API 和功能稳定性也受到非常重视,并被视为 Gradle 平台的核心价值。设计选择和自动化测试被设计到开发过程中,并由向后兼容性部分正式化。
Gradle功能生命周期旨在满足这些目标。它还向 Gradle 用户传达功能的状态。在此上下文中,术语“功能”通常指的是 API 或 DSL 方法或属性,但它不限于此定义。命令行参数和执行模式(例如构建守护进程)是其他功能的两个示例。
1. 内部
内部功能不是为公共使用而设计的,仅供 Gradle 本身使用。它们可以随时以任何方式更改,恕不另行通知。因此,我们建议避免使用此类功能。 内部功能未记录。如果它出现在本用户手册、DSL 参考或 API 参考中,则该功能不是内部功能。
内部功能可能会演变成公共功能。
2. 孵化
功能在孵化状态下引入,以便在公开之前将现实世界的反馈纳入功能中。它还为愿意测试未来潜在变化的用户提供了早期访问权限。
处于孵化状态的功能可能会在未来的 Gradle 版本中发生变化,直到它不再处于孵化状态。 Gradle 版本的孵化功能的更改将在该版本的发行说明中突出显示。新功能的孵化期根据功能的范围、复杂性和性质而有所不同。
指出了孵化的特征。在源代码中,所有正在孵化的方法/属性/类都带有incubating注释。这导致它们在 DSL 和 API 参考中具有特殊标记。
如果本用户手册中讨论了孵化功能,则将明确表示该功能处于孵化状态。
功能预览 API
功能预览 API 允许通过添加设置文件来激活某些孵化功能。各个预览功能将在发行说明中公布。enableFeaturePreview('FEATURE')
当孵化功能升级为公开或删除时,它们的功能预览标志将变得过时、无效,应从设置文件中删除。
3. 公开
非内部功能的默认状态是public。用户手册、DSL 参考或 API 参考中记录的任何未明确表示正在孵化或弃用的内容都被视为公开的。据说这些功能正在从孵化状态向公众推广。每个版本的发行说明表明该版本正在推广哪些先前孵化的功能。
公共功能在未经过弃用的情况下永远不会被删除或故意更改。所有公共功能均受向后兼容性政策的约束。
4. 已弃用
由于 Gradle 的自然演变,某些功能可能会被替换或变得无关紧要。这些功能最终将在被弃用后从 Gradle 中删除。已弃用的功能可能会变得过时,直到根据向后兼容性策略最终将其删除。
已弃用的功能已表明如此。在源代码中,所有不推荐使用的方法/属性/类都带有“@java.lang.Deprecated”注释,这反映在 DSL 和 API 参考中。在大多数情况下,已弃用的元素有替代品,这将在文档中进行描述。使用已弃用的功能将导致 Gradle 输出中出现运行时警告。
应避免使用已弃用的功能。每个版本的发行说明都会指出该版本弃用的任何功能。
向后兼容政策
Gradle 提供跨主要版本(例如, 、 等)的向后1.x兼容性2.x。一旦在 Gradle 版本中引入公共功能,它将无限期保留,除非被弃用。一旦被弃用,它可能会在下一个主要版本中被删除。主要版本可能会支持已弃用的功能,但这并不能得到保证。
发布报废政策
每天都会创建一个新的 Gradle 夜间构建。
这包含当天通过 Gradle 广泛的持续集成测试所做的所有更改。每晚构建可能包含可能稳定也可能不稳定的新更改。
Gradle 团队为每个次要或主要版本创建一个称为候选版本 (RC) 的预发布发行版。当短时间(通常是一周)后没有发现问题时,候选版本将升级为通用版本(GA)。如果在候选版本中发现回归,则会创建新的 RC 发行版,并重复该过程。只要发布窗口打开,候选版本就会受到支持,但它们并不打算用于生产。在 RC 阶段,错误报告非常受欢迎。
由于关键错误修复或回归,Gradle 团队可能会创建额外的补丁版本来替换最终版本。例如,Gradle 5.2.1 取代了 Gradle 5.2 版本。
一旦候选版本确定,所有功能开发都会转移到最新主要版本的下一个版本。因此,每个次要 Gradle 版本都会导致同一主要版本中的先前次要版本终止生命 (EOL)。 EOL 版本不会收到错误修复或功能向后移植。
对于主要版本,Gradle 会将关键修复程序和安全修复程序向后移植到先前主要版本中的最后一个次要版本。例如,当 Gradle 7 是最新的主要版本时,6.x 系列中发布了多个版本,包括 Gradle 6.9(及后续版本)。
因此,每个主要的 Gradle 版本都会导致:
-
以前的主要版本仅成为维护版本。它只会收到严重的错误修复和安全修复。
-
上一个版本之前的主要版本将停止使用 (EOL),并且该发行版将不会收到任何新的修复。
核心理念
摇篮基础知识
Gradle根据构建脚本中的信息自动构建、测试和部署软件。

Gradle 核心概念
插件
插件用于扩展 Gradle 的功能,并可选择向项目贡献任务。
Gradle 项目结构
许多开发人员会通过现有项目首次与 Gradle 交互。
项目根目录中存在gradlew和文件是使用 Gradle 的明确标志。gradlew.bat
Gradle 项目将类似于以下内容:
project
├── gradle // (1)
│ ├── libs.versions.toml // (2)
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew // (3)
├── gradlew.bat // (3)
├── settings.gradle(.kts) // (4)
├── subproject-a
│ ├── build.gradle(.kts) // (5)
│ └── src // (6)
└── subproject-b
├── build.gradle(.kts) // (5)
└── src // (6)-
Gradle 目录用于存储包装文件等
-
用于依赖管理的 Gradle 版本目录
-
Gradle 包装脚本
-
Gradle 设置文件用于定义根项目名称和子项目
-
两个子项目的 Gradle 构建脚本 -
subproject-a以及subproject-b -
项目的源代码和/或附加文件
调用Gradle
集成开发环境
Gradle内置于许多 IDE 中,包括 Android Studio、IntelliJ IDEA、Visual Studio Code、Eclipse 和 NetBeans。
当您在 IDE 中构建、清理或运行应用程序时,可以自动调用 Gradle。
建议您查阅所选 IDE 的手册,以了解有关如何使用和配置 Gradle 的更多信息。
Gradle 包装器
Wrapper 是一个调用 Gradle 声明版本的脚本,是执行 Gradle 构建的推荐方法。它可以在项目根目录中作为gradlew或gradlew.bat文件找到:
$ gradlew build // Linux or OSX
$ gradlew.bat build // Windows下一步: 了解 Gradle 包装器>>
Gradle 包装器基础知识
执行任何 Gradle 构建的推荐方法是使用 Gradle Wrapper。

Wrapper脚本调用声明的 Gradle 版本,并在必要时提前下载它。

包装器可作为gradlew或gradlew.bat文件使用。
Wrapper 具有以下优点:
-
在给定 Gradle 版本上标准化项目。
-
为不同用户提供相同的 Gradle 版本。
-
为不同的执行环境(IDE、CI 服务器……)配置 Gradle 版本。
使用 Gradle 包装器
始终建议使用 Wrapper 执行构建,以确保构建的可靠、受控和标准化执行。
根据操作系统的不同,您可以运行gradlew或gradlew.bat来代替该gradle命令。
典型的 Gradle 调用:
$ gradle build
要在 Linux 或 OSX 计算机上运行 Wrapper:
$ ./gradlew build
要在 Windows PowerShell 上运行包装器:
$ .\gradlew.bat build
该命令在 Wrapper 所在的同一目录中运行。如果要在不同目录中运行该命令,则必须提供 Wrapper 的相对路径:
$ ../gradlew build
以下控制台输出演示了在 Windows 计算机上的命令提示符 (cmd) 中,对于基于 Java 的项目如何使用 Wrapper:
$ gradlew.bat build Downloading https://services.gradle.org/distributions/gradle-5.0-all.zip ..................................................................................... Unzipping C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-all\ac27o8rbd0ic8ih41or9l32mv\gradle-5.0-all.zip to C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-al\ac27o8rbd0ic8ih41or9l32mv Set executable permissions for: C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-all\ac27o8rbd0ic8ih41or9l32mv\gradle-5.0\bin\gradle BUILD SUCCESSFUL in 12s 1 actionable task: 1 executed
请参阅Gradle Wrapper 参考以了解更多信息。
下一步: 了解 Gradle CLI >>
命令行界面基础知识
命令行界面是在 IDE 之外与 Gradle 交互的主要方法。
强烈鼓励使用Gradle Wrapper 。
在以下示例中替换为./gradlew(在 macOS / Linux 中)或gradlew.bat(在 Windows 中) 。gradle
在命令行执行Gradle符合以下结构:
gradle [taskName...] [--option-name...]
任务名称之前和之后允许使用选项。
gradle [--option-name...] [taskName...]
如果指定了多个任务,则应该用空格分隔它们。
gradle [taskName1 taskName2...] [--option-name...]
接受值的选项可以=在选项和参数之间指定,也可以不指定。=推荐使用。
gradle [...] --console=plain
启用行为的选项具有长格式选项,其逆值用 指定--no-。以下是相反的情况。
gradle [...] --build-cache gradle [...] --no-build-cache
许多长期权都有相应的短期权。以下是等效的:
gradle --help gradle -h
设置文件基础知识
设置文件是每个 Gradle 项目的入口点。

设置文件的主要目的是将子项目添加到您的构建中。
Gradle 支持单项目和多项目构建。
-
对于单项目构建,设置文件是可选的。
-
对于多项目构建,设置文件是必需的并声明所有子项目。
设置脚本
设置文件是一个脚本。它可以是settings.gradle用 Groovy 编写的文件,也可以是settings.gradle.kts用 Kotlin 编写的文件。
Groovy DSL和Kotlin DSL是 Gradle 脚本唯一接受的语言。
设置文件通常位于项目的根目录中。
让我们看一个例子并将其分解:
rootProject.name = "root-project" // (1)
include("sub-project-a") // (2)
include("sub-project-b")
include("sub-project-c")-
Define the project name.
-
Add subprojects.
rootProject.name = 'root-project' // (1)
include('sub-project-a') // (2)
include('sub-project-b')
include('sub-project-c')-
Define the project name.
-
Add subprojects.
构建文件基础知识
一般来说,构建脚本详细介绍了构建配置、任务和插件。

每个 Gradle 构建至少包含一个构建脚本。
在构建文件中,可以添加两种类型的依赖项:
-
Gradle 和构建脚本所依赖的库和/或插件。
-
项目源(即源代码)所依赖的库。
构建脚本
构建脚本可以是build.gradle用 Groovy 编写的文件,也可以是build.gradle.kts用 Kotlin 编写的文件。
Groovy DSL和Kotlin DSL是 Gradle 脚本唯一接受的语言。
让我们看一个例子并将其分解:
plugins {
id("application") // (1)
}
application {
mainClass = "com.example.Main" // (2)
}-
Add plugins.
-
Use convention properties.
plugins {
id 'application' // (1)
}
application {
mainClass = 'com.example.Main' // (2)
}-
Add plugins.
-
Use convention properties.
1.添加插件
插件扩展了 Gradle 的功能,并且可以向项目贡献任务。
将插件添加到构建中称为应用插件,并使附加功能可用。
plugins {
id("application")
}该application插件有助于创建可执行的 JVM 应用程序。
依赖管理基础知识
Gradle 内置了对依赖管理的支持。

依赖管理是一种用于声明和解析项目所需的外部资源的自动化技术。
Gradle 构建脚本定义了构建可能需要外部依赖项的项目的过程。依赖项是指支持构建项目的 JAR、插件、库或源代码。
版本目录
版本目录提供了一种将依赖项声明集中在libs.versions.toml文件中的方法。
该目录使子项目之间共享依赖关系和版本配置变得简单。它还允许团队在大型项目中强制执行库和插件的版本。
版本目录通常包含四个部分:
-
[versions] 声明插件和库将引用的版本号。
-
[libraries] 定义构建文件中使用的库。
-
[bundles] 定义一组依赖项。
-
[plugins] 定义插件。
[versions]
androidGradlePlugin = "7.4.1"
mockito = "2.16.0"
[libraries]
googleMaterial = { group = "com.google.android.material", name = "material", version = "1.1.0-alpha05" }
mockitoCore = { module = "org.mockito:mockito-core", version.ref = "mockito" }
[plugins]
androidApplication = { id = "com.android.application", version.ref = "androidGradlePlugin" }该文件位于该gradle目录中,以便 Gradle 和 IDE 自动使用它。应将版本目录签入源代码管理:gradle/libs.versions.toml。
声明你的依赖关系
要向项目添加依赖项,请在build.gradle(.kts)文件的依赖项块中指定依赖项。
以下build.gradle.kts文件使用上面的版本目录向项目添加一个插件和两个依赖项:
plugins {
alias(libs.plugins.androidApplication) // (1)
}
dependencies {
// Dependency on a remote binary to compile and run the code
implementation(libs.googleMaterial) // (2)
// Dependency on a remote binary to compile and run the test code
testImplementation(libs.mockitoCore) // (3)
}-
将 Android Gradle 插件应用于此项目,该项目添加了一些特定于构建 Android 应用程序的功能。
-
将材质依赖项添加到项目中。 Material Design 提供了用于在 Android 应用程序中创建用户界面的组件。该库将用于编译和运行本项目中的 Kotlin 源代码。
-
将 Mockito 依赖项添加到项目中。 Mockito 是一个用于测试 Java 代码的模拟框架。该库将用于编译和运行该项目中的测试源代码。
Gradle 中的依赖项按配置进行分组。
-
该
material库被添加到implementation配置中,用于编译和运行生产代码。 -
该
mockito-core库被添加到testImplementation配置中,用于编译和运行测试代码。
|
笔记
|
还有更多配置可供选择。 |
查看项目依赖关系
您可以使用以下命令在终端中查看依赖关系树./gradlew :app:dependencies:
$ ./gradlew :app:dependencies
> Task :app:dependencies
------------------------------------------------------------
Project ':app'
------------------------------------------------------------
implementation - Implementation only dependencies for source set 'main'. (n)
\--- com.google.android.material:material:1.1.0-alpha05 (n)
testImplementation - Implementation only dependencies for source set 'test'. (n)
\--- org.mockito:mockito-core:2.16.0 (n)
...请参阅依赖管理章节以了解更多信息。
下一步: 了解任务>>
任务基础知识
任务代表构建执行的某些独立工作单元,例如编译类、创建 JAR、生成 Javadoc 或将存档发布到存储库。

build您可以使用以下命令或通过调用项目目录中的gradleGradle Wrapper(./gradlew或)来运行 Gradle任务:gradlew.bat
$ ./gradlew build可用任务
项目中的所有可用任务都来自 Gradle 插件和构建脚本。
您可以通过在终端中运行以下命令来列出项目中的所有可用任务:
$ ./gradlew tasksApplication tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
...
Documentation tasks
-------------------
javadoc - Generates Javadoc API documentation for the main source code.
...
Other tasks
-----------
compileJava - Compiles main Java source.
...运行任务
该run任务的执行方式为./gradlew run:
$ ./gradlew run
> Task :app:compileJava
> Task :app:processResources NO-SOURCE
> Task :app:classes
> Task :app:run
Hello World!
BUILD SUCCESSFUL in 904ms
2 actionable tasks: 2 executed在此示例 Java 项目中,任务的输出run是Hello World打印在控制台上的语句。
任务依赖性
很多时候,一个任务需要先运行另一个任务。
例如,要让 Gradle 执行build任务,必须首先编译 Java 代码。因此,build任务取决于任务compileJava。
这意味着该任务将在以下任务之前compileJava运行:build
$ ./gradlew build
> Task :app:compileJava
> Task :app:processResources NO-SOURCE
> Task :app:classes
> Task :app:jar
> Task :app:startScripts
> Task :app:distTar
> Task :app:distZip
> Task :app:assemble
> Task :app:compileTestJava
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses
> Task :app:test
> Task :app:check
> Task :app:build
BUILD SUCCESSFUL in 764ms
7 actionable tasks: 7 executed构建脚本可以选择定义任务依赖关系。然后 Gradle 自动确定任务执行顺序。
请参阅任务开发章节以了解更多信息。
下一步: 了解插件>>
插件基础知识
Gradle 是建立在插件系统之上的。 Gradle 本身主要由基础设施组成,例如复杂的依赖解析引擎。它的其余功能来自插件。
插件是一个为 Gradle 构建系统提供附加功能的软件。

插件可以应用于 Gradle 构建脚本以添加新任务、配置或其他与构建相关的功能:
- Java 库插件 -
java-library -
用于定义和构建 Java 库。它随任务编译 Java 源代码
compileJava,随任务生成 Javadocjavadoc,并随任务将编译的类打包到 JAR 文件中jar。 - Google 服务 Gradle 插件 -
com.google.gms:google-services -
使用名为 的配置块
googleServices{}和名为 的任务在 Android 应用程序中启用 Google API 和 Firebase 服务generateReleaseAssets。 - Gradle Bintray 插件 -
com.jfrog.bintray -
允许您通过使用块配置插件来将工件发布到 Bintray
bintray{}。
插件分发
插件以三种方式分发:
-
核心插件- Gradle 开发并维护一组核心插件。
-
社区插件- Gradle 社区通过Gradle 插件门户共享插件。
-
本地插件- Gradle 使用户能够使用API创建自定义插件。
应用插件
将插件应用到项目允许插件扩展项目的功能。
您可以使用插件 ID(全局唯一标识符/名称)和版本在构建脚本中应用插件:
plugins {
id «plugin id» version «plugin version»
}1. 核心插件
Gradle Core 插件是 Gradle 发行版本身包含的一组插件。这些插件提供了构建和管理项目的基本功能。
核心插件的一些示例包括:
-
java:提供对构建 Java 项目的支持。
-
groovy:添加对编译和测试 Groovy 源文件的支持。
-
ear:添加了对为企业应用程序构建 EAR 文件的支持。
核心插件的独特之处在于,它们在构建脚本中应用时提供短名称,例如java核心JavaPlugin 。它们也不需要版本。要将java插件应用到项目中:
plugins {
id("java")
}用户可以利用许多Gradle 核心插件。
2. 社区插件
社区插件是由 Gradle 社区开发的插件,而不是核心 Gradle 发行版的一部分。这些插件提供可能特定于某些用例或技术的附加功能。
Spring Boot Gradle 插件打包可执行 JAR 或 WAR 档案,并运行Spring Boot Java 应用程序。
要将org.springframework.boot插件应用到项目中:
plugins {
id("org.springframework.boot") version "3.1.5"
}社区插件可以在Gradle 插件门户上发布,其他 Gradle 用户可以轻松发现和使用它们。
3.本地插件
自定义或本地插件是在特定项目或组织内开发和使用的。这些插件不会公开共享,而是根据项目或组织的特定需求量身定制的。
本地插件可以封装常见的构建逻辑,提供与内部系统或工具的集成,或者将复杂的功能抽象为可重用的组件。
Gradle 为用户提供了使用 API 开发自定义插件的能力。要创建您自己的插件,您通常需要遵循以下步骤:
-
定义插件类:创建一个实现接口的新类
Plugin<Project>。// Define a 'HelloPlugin' plugin class HelloPlugin : Plugin<Project> { override fun apply(project: Project) { // Define the 'hello' task val helloTask = project.tasks.register("hello") { doLast { println("Hello, Gradle!") } } } } -
构建并可选择发布您的插件:生成一个包含插件代码的 JAR 文件,并可选择将此 JAR 发布到存储库(本地或远程)以在其他项目中使用。
// Publish the plugin plugins { `maven-publish` } publishing { publications { create<MavenPublication>("mavenJava") { from(components["java"]) } } repositories { mavenLocal() } } -
应用您的插件:当您想要使用插件时,请在
plugins{}构建文件的块中包含插件 ID 和版本。// Apply the plugin plugins { id("com.example.hello") version "1.0" }
请参阅插件开发章节以了解更多信息。
下一步: 了解增量构建和构建缓存>>
Gradle 增量构建和构建缓存
Gradle 使用两个主要功能来减少构建时间:增量构建和构建缓存。

增量构建
增量构建是一种避免运行自上次构建以来输入未更改的任务的构建。如果这些任务只会重新产生相同的输出,则无需重新执行这些任务。
为了使增量构建发挥作用,任务必须定义其输入和输出。 Gradle 将确定输入或输出在构建时是否已更改。如果它们发生了变化,Gradle 将执行任务。否则,它将跳过执行。
增量构建始终处于启用状态,查看它们实际效果的最佳方法是打开详细模式。在详细模式下,每个任务状态在构建期间都会被标记:
$ ./gradlew compileJava --console=verbose
> Task :buildSrc:generateExternalPluginSpecBuilders UP-TO-DATE
> Task :buildSrc:extractPrecompiledScriptPluginPlugins UP-TO-DATE
> Task :buildSrc:compilePluginsBlocks UP-TO-DATE
> Task :buildSrc:generatePrecompiledScriptPluginAccessors UP-TO-DATE
> Task :buildSrc:generateScriptPluginAdapters UP-TO-DATE
> Task :buildSrc:compileKotlin UP-TO-DATE
> Task :buildSrc:compileJava NO-SOURCE
> Task :buildSrc:compileGroovy NO-SOURCE
> Task :buildSrc:pluginDescriptors UP-TO-DATE
> Task :buildSrc:processResources UP-TO-DATE
> Task :buildSrc:classes UP-TO-DATE
> Task :buildSrc:jar UP-TO-DATE
> Task :list:compileJava UP-TO-DATE
> Task :utilities:compileJava UP-TO-DATE
> Task :app:compileJava UP-TO-DATE
BUILD SUCCESSFUL in 374ms
12 actionable tasks: 12 up-to-date当您运行先前已执行且未更改的任务时,UP-TO-DATE任务旁边会打印 then 。
|
提示
|
要永久启用详细模式,请添加org.gradle.console=verbose到您的gradle.properties文件中。
|
构建缓存
增量构建是一种很好的优化,有助于避免已经完成的工作。如果开发人员不断更改单个文件,则可能不需要重建项目中的所有其他文件。
但是,当同一个开发人员切换到上周创建的新分支时会发生什么?即使开发人员正在构建以前构建过的东西,文件也会被重建。
这就是构建缓存有用的地方。
构建缓存存储以前的构建结果并在需要时恢复它们。它可以防止执行耗时且昂贵的流程的冗余工作和成本。
当构建缓存已用于重新填充本地目录时,任务将标记为FROM-CACHE:
$ ./gradlew compileJava --build-cache
> Task :buildSrc:generateExternalPluginSpecBuilders UP-TO-DATE
> Task :buildSrc:extractPrecompiledScriptPluginPlugins UP-TO-DATE
> Task :buildSrc:compilePluginsBlocks UP-TO-DATE
> Task :buildSrc:generatePrecompiledScriptPluginAccessors UP-TO-DATE
> Task :buildSrc:generateScriptPluginAdapters UP-TO-DATE
> Task :buildSrc:compileKotlin UP-TO-DATE
> Task :buildSrc:compileJava NO-SOURCE
> Task :buildSrc:compileGroovy NO-SOURCE
> Task :buildSrc:pluginDescriptors UP-TO-DATE
> Task :buildSrc:processResources UP-TO-DATE
> Task :buildSrc:classes UP-TO-DATE
> Task :buildSrc:jar UP-TO-DATE
> Task :list:compileJava FROM-CACHE
> Task :utilities:compileJava FROM-CACHE
> Task :app:compileJava FROM-CACHE
BUILD SUCCESSFUL in 364ms
12 actionable tasks: 3 from cache, 9 up-to-date重新填充本地目录后,下一次执行会将任务标记为UP-TO-DATE而不是FROM-CACHE。
构建缓存允许您跨团队共享和重用未更改的构建和测试输出。这加快了本地和 CI 构建的速度,因为不会浪费周期来重新构建不受新代码更改影响的二进制文件。
请参阅“构建缓存”一章以了解更多信息。
下一步: 了解构建扫描>>


其他主题
持续构建
持续构建允许您在文件输入更改时自动重新执行请求的任务。您可以使用-t或--continuous命令行选项在此模式下执行构建。
例如,您可以test通过运行以下命令连续运行该任务和所有相关任务:
$ gradle test --continuous
gradle testGradle 的行为就像您在更改有助于请求任务的源或测试后运行一样。这意味着不相关的更改(例如对构建脚本的更改)将不会触发重建。要合并构建逻辑更改,必须手动重新启动连续构建。
持续构建使用文件系统监视来检测输入的更改。如果文件系统监视在您的系统上不起作用,那么连续构建也将不起作用。特别是,使用时连续构建不起作用--no-daemon。
当 Gradle 检测到输入发生更改时,它不会立即触发构建。相反,它将等待一段时间(安静期),直到没有检测到任何其他更改。您可以通过 Gradle 属性以毫秒为单位配置安静期org.gradle.continuous.quietperiod。
终止持续构建
如果 Gradle 连接到交互式输入源(例如终端),则可以通过按退出连续构建CTRL-D(在 Microsoft Windows 上,还需要按ENTER或RETURN之后CTRL-D)。
如果 Gradle 未附加到交互式输入源(例如作为脚本的一部分运行),则必须终止构建过程(例如使用命令kill或类似命令)。
如果通过 Tooling API 执行构建,则可以使用 Tooling API 的取消机制取消构建。
局限性
在某些情况下,连续构建可能无法检测输入的更改。
创建输入目录
有时,由于文件系统监视的工作方式,创建以前丢失的输入目录不会触发构建。例如,创建src/main/java目录可能不会触发构建。同样,如果输入是经过筛选的文件树,并且没有文件与筛选器匹配,则匹配文件的创建可能不会触发构建。
对项目目录之外的文件进行更改
Gradle 仅监视项目目录内文件的更改。对项目目录外部文件的更改将不会被检测到,并且不会触发构建。
构建周期
Gradle 在任务执行之前开始监视更改。如果任务在执行时修改了自己的输入,Gradle 将检测到更改并触发新的构建。如果每次任务执行时,再次修改输入,则会再次触发构建。这并不是持续构建所独有的。在没有持续构建的情况下“正常”运行时,修改其自身输入的任务永远不会被认为是最新的。
如果您的构建进入这样的构建周期,您可以通过查看 Gradle 报告的更改的文件列表来跟踪任务。识别出每次构建期间更改的文件后,您应该查找将该文件作为输入的任务。在某些情况下,这可能是显而易见的(例如,Java 文件是用 编译的compileJava)。在其他情况下,您可以使用--info日志记录来查找由于识别的文件而过期的任务。
基础
摇篮目录
Gradle 使用两个主要目录来执行和管理其工作:Gradle 用户主目录和项目根目录。
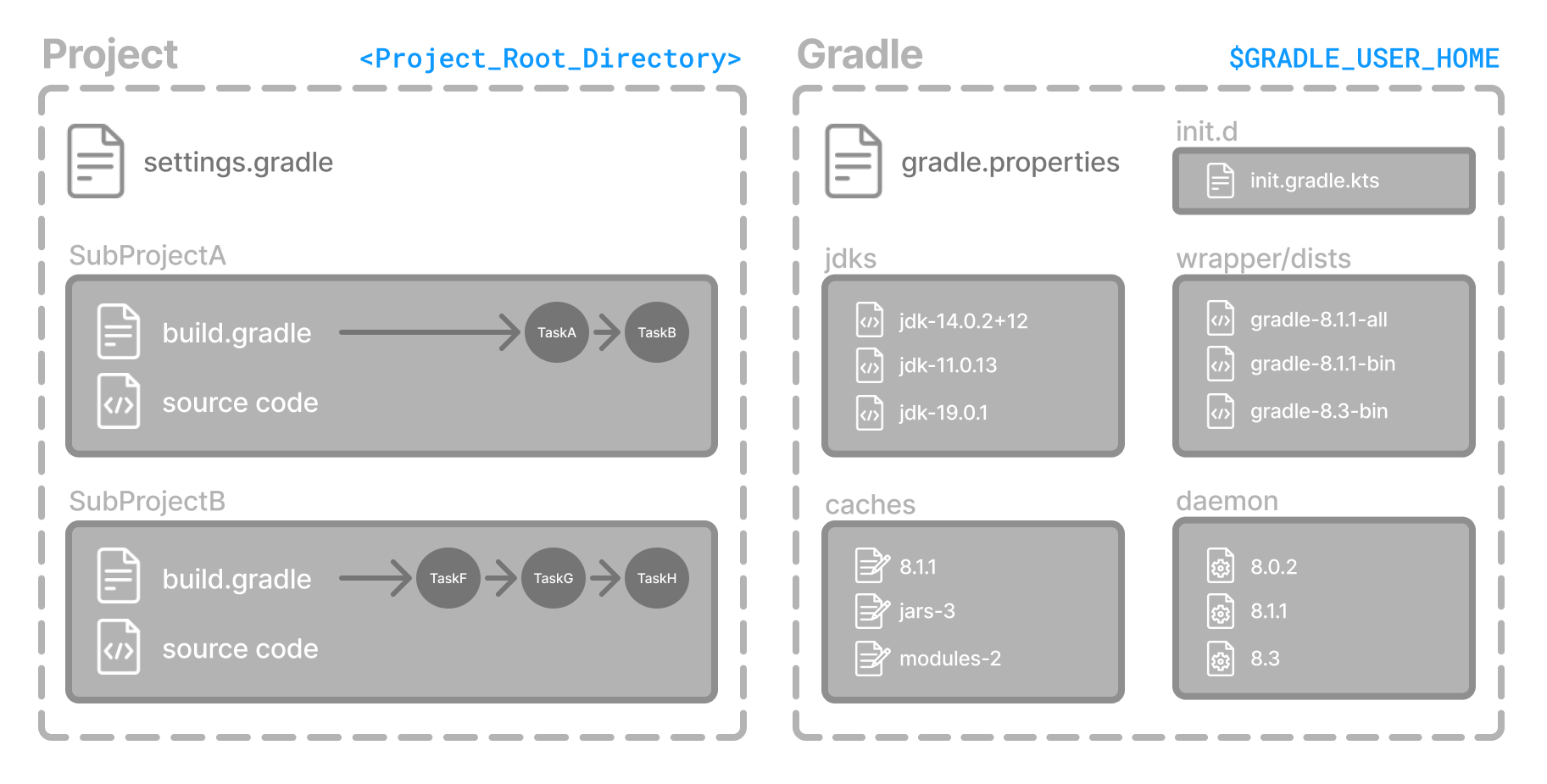
Gradle 用户主目录
默认情况下,Gradle 用户主页(~/.gradle或C:\Users\<USERNAME>\.gradle)存储全局配置属性、初始化脚本、缓存和日志文件。
可以通过环境变量来设置GRADLE_USER_HOME。
|
提示
|
GRADLE_HOME不要与Gradle 的可选安装目录
混淆。 |
其结构大致如下:
├── caches // (1) │ ├── 4.8 // (2) │ ├── 4.9 // (2) │ ├── ⋮ │ ├── jars-3 // (3) │ └── modules-2 // (3) ├── daemon // (4) │ ├── ⋮ │ ├── 4.8 │ └── 4.9 ├── init.d // (5) │ └── my-setup.gradle ├── jdks // (6) │ ├── ⋮ │ └── jdk-14.0.2+12 ├── wrapper │ └── dists // (7) │ ├── ⋮ │ ├── gradle-4.8-bin │ ├── gradle-4.9-all │ └── gradle-4.9-bin └── gradle.properties // (8)
-
全局缓存目录(用于所有非项目特定的内容)。
-
版本特定的缓存(例如,支持增量构建)。
-
共享缓存(例如,用于依赖项的工件)。
-
Gradle Daemon的注册表和日志。
-
全局初始化脚本。
-
通过工具链支持下载的 JDK 。
-
由Gradle Wrapper下载的发行版。
-
全局Gradle 配置属性。
请参阅Gradle 目录参考以了解更多信息。
项目根目录
项目根目录包含项目中的所有源文件。
它还包含 Gradle 生成的文件和目录,例如.gradle和build。
虽然.gradle通常会签入源代码管理,但该build目录包含构建的输出以及 Gradle 用于支持增量构建等功能的临时文件。
典型项目根目录的剖析如下:
├── .gradle // (1) │ ├── 4.8 // (2) │ ├── 4.9 // (2) │ └── ⋮ ├── build // (3) ├── gradle │ └── wrapper // (4) ├── gradle.properties // (5) ├── gradlew // (6) ├── gradlew.bat // (6) ├── settings.gradle.kts // (7) ├── subproject-one // (8) | └── build.gradle.kts // (9) ├── subproject-two // (8) | └── build.gradle.kts // (9) └── ⋮
-
Gradle 生成的项目特定的缓存目录。
-
版本特定的缓存(例如,支持增量构建)。
-
该项目的构建目录,Gradle 在其中生成所有构建工件。
-
包含Gradle Wrapper的 JAR 文件和配置。
-
项目特定的Gradle 配置属性。
-
使用Gradle Wrapper执行构建的脚本。
-
定义子项目列表的项目设置文件。
-
通常,一个项目被组织成一个或多个子项目。
-
每个子项目都有自己的 Gradle 构建脚本。
请参阅Gradle 目录参考以了解更多信息。
下一步: 了解如何构建多项目构建>>
多项目构建基础知识
Gradle 支持多项目构建。

虽然一些小型项目和整体应用程序可能包含单个构建文件和源代码树,但更常见的情况是项目被分割成更小的、相互依赖的模块。 “相互依赖”这个词至关重要,因为您通常希望通过单个构建将许多模块链接在一起。
Gradle 通过多项目构建支持这种场景。这有时被称为多模块项目。 Gradle 将模块称为子项目。
多项目构建由一个根项目和一个或多个子项目组成。
多项目结构
以下表示包含两个子项目的多项目构建的结构:

目录结构应如下所示:
├── .gradle
│ └── ⋮
├── gradle
│ ├── libs.version.toml
│ └── wrapper
├── gradlew
├── gradlew.bat
├── settings.gradle.kts // (1)
├── sub-project-1
│ └── build.gradle.kts // (2)
├── sub-project-2
│ └── build.gradle.kts // (2)
└── sub-project-3
└── build.gradle.kts // (2)
-
该
settings.gradle.kts文件应包含所有子项目。 -
每个子项目都应该有自己的
build.gradle.kts文件。
多项目标准
Gradle 社区对于多项目构建结构有两个标准:
-
使用 buildSrc 进行多项目构建- 其中
buildSrc是 Gradle 项目根目录中包含所有构建逻辑的类似子项目的目录。 -
复合构建- 包含其他构建的构建,其中
build-logic包含可重用构建逻辑的 Gradle 项目根目录中的构建目录。

1. 多项目构建使用buildSrc
多项目构建允许您组织具有许多模块的项目,连接这些模块之间的依赖关系,并轻松地在它们之间共享通用的构建逻辑。
例如,一个包含许多名为mobile-app、web-app、api、lib、的模块的构建documentation可以按如下方式构建:
.
├── gradle
├── gradlew
├── settings.gradle.kts
├── buildSrc
│ ├── build.gradle.kts
│ └── src/main/kotlin/shared-build-conventions.gradle.kts
├── mobile-app
│ └── build.gradle.kts
├── web-app
│ └── build.gradle.kts
├── api
│ └── build.gradle.kts
├── lib
│ └── build.gradle.kts
└── documentation
└── build.gradle.kts这些模块之间将具有依赖关系,例如web-app和mobile-appdependent on lib。这意味着为了让 Gradle 构建web-app或mobile-app,它必须lib首先构建。
在此示例中,根设置文件将如下所示:
include("mobile-app", "web-app", "api", "lib", "documentation")|
笔记
|
子项目(模块)的包含顺序并不重要。 |
buildSrcGradle 会自动识别该目录。它是定义和维护共享配置或命令式构建逻辑(例如自定义任务或插件)的好地方。
buildSrc如果build.gradle(.kts)在buildSrc.
如果java插件应用于buildSrc项目,则编译后的代码buildSrc/src/main/java将放入根构建脚本的类路径中,使其可用于构建中的任何子项目( web-app、mobile-app、等...)。lib
请参阅如何声明子项目之间的依赖关系以了解更多信息。
2. 复合构建
复合构建,也称为包含构建,最适合在构建(而不是子项目)之间共享逻辑或隔离对共享构建逻辑(即约定插件)的访问。
让我们以前面的例子为例。其中的逻辑buildSrc已转变为包含插件的项目,并且可以独立于根项目构建进行发布和工作。
build-logic该插件被移动到使用构建脚本和设置文件调用的自己的构建中:
.
├── gradle
├── gradlew
├── settings.gradle.kts
├── build-logic
│ ├── settings.gradle.kts
│ └── conventions
│ ├── build.gradle.kts
│ └── src/main/kotlin/shared-build-conventions.gradle.kts
├── mobile-app
│ └── build.gradle.kts
├── web-app
│ └── build.gradle.kts
├── api
│ └── build.gradle.kts
├── lib
│ └── build.gradle.kts
└── documentation
└── build.gradle.kts|
笔记
|
build-logic位于根项目的子目录中
的事实是无关紧要的。如果需要,该文件夹可以位于根项目之外。
|
根设置文件包括整个build-logic 构建:
pluginManagement {
includeBuild("build-logic")
}
include("mobile-app", "web-app", "api", "lib", "documentation")请参阅如何创建复合构建以includeBuild了解更多信息。
多项目路径
项目路径具有以下模式:它以可选的冒号开头,表示根项目。
根项目:是路径中唯一未按其名称指定的项目。
项目路径的其余部分是用冒号分隔的项目名称序列,其中下一个项目是上一个项目的子项目:
:sub-project-1运行时可以看到项目路径gradle projects:
------------------------------------------------------------
Root project 'project'
------------------------------------------------------------
Root project 'project'
+--- Project ':sub-project-1'
\--- Project ':sub-project-2'项目路径通常反映文件系统布局,但也有例外。最显着的是复合构建。
确定项目结构
您可以使用该gradle projects命令来识别项目结构。
作为示例,让我们使用具有以下结构的多项目构建:
> gradle -q projects
------------------------------------------------------------ Root project 'multiproject' ------------------------------------------------------------ Root project 'multiproject' +--- Project ':api' +--- Project ':services' | +--- Project ':services:shared' | \--- Project ':services:webservice' \--- Project ':shared' To see a list of the tasks of a project, run gradle <project-path>:tasks For example, try running gradle :api:tasks
多项目构建是您可以运行的任务的集合。不同之处在于您可能想要控制执行哪个项目的任务。
以下部分将介绍在多项目构建中执行任务的两个选项。
按名称执行任务
该命令将在相对于具有该任务的当前工作目录的任何子项目中gradle test执行该任务。test
如果从项目根目录运行该命令,您将test在api、shared、services:shared和services:webservice中运行。
如果从services项目目录运行命令,则只会执行services:shared和services:webservice中的任务。
Gradle 行为背后的基本规则是使用该名称执行层次结构中的所有任务。如果在遍历的任何子项目中都没有找到这样的任务,则进行抱怨。
|
笔记
|
某些任务选择器(例如help或dependencies)只会在调用它们的项目上运行任务,而不是在所有子项目上运行,以减少屏幕上打印的信息量。
|
通过完全限定名称执行任务
您可以使用任务的完全限定名称来执行特定子项目中的特定任务。例如:gradle :services:webservice:build将运行webservicebuild子项目的任务。
任务的完全限定名称是其项目路径加上任务名称。
这种方法适用于任何任务,因此如果您想知道特定子项目中有哪些任务,请使用任务tasks,例如gradle :services:webservice:tasks。
多项目构建和测试
该build任务通常用于编译、测试和检查单个项目。
在多项目构建中,您可能经常希望跨多个项目执行所有这些任务。和buildNeeded任务buildDependents可以帮助解决这个问题。
在此示例中,:services:person-service项目同时依赖于:api和:shared项目。项目:api也要看:shared项目。
假设您正在处理单个项目,即该:api项目,您一直在进行更改,但自从执行clean.您想要构建任何必要的支持 JAR,但仅对已更改的项目部分执行代码质量和单元测试。
该build任务执行以下操作:
$ gradle :api:build > Task :shared:compileJava > Task :shared:processResources > Task :shared:classes > Task :shared:jar > Task :api:compileJava > Task :api:processResources > Task :api:classes > Task :api:jar > Task :api:assemble > Task :api:compileTestJava > Task :api:processTestResources > Task :api:testClasses > Task :api:test > Task :api:check > Task :api:build BUILD SUCCESSFUL in 0s
如果您刚刚从版本控制系统获取了最新版本的源代码,其中包括:api依赖的其他项目中的更改,您可能想要构建您依赖的所有项目并测试它们。
该buildNeeded任务构建并测试配置的项目依赖项中的所有项目testRuntime:
$ gradle :api:buildNeeded > Task :shared:compileJava > Task :shared:processResources > Task :shared:classes > Task :shared:jar > Task :api:compileJava > Task :api:processResources > Task :api:classes > Task :api:jar > Task :api:assemble > Task :api:compileTestJava > Task :api:processTestResources > Task :api:testClasses > Task :api:test > Task :api:check > Task :api:build > Task :shared:assemble > Task :shared:compileTestJava > Task :shared:processTestResources > Task :shared:testClasses > Task :shared:test > Task :shared:check > Task :shared:build > Task :shared:buildNeeded > Task :api:buildNeeded BUILD SUCCESSFUL in 0s
您可能想要重构:api其他项目中使用的项目的某些部分。如果进行这些更改,仅测试:api项目是不够的。您必须测试依赖于该:api项目的所有项目。
该buildDependents任务测试对指定项目具有项目依赖性(在 testRuntime 配置中)的所有项目:
$ gradle :api:buildDependents > Task :shared:compileJava > Task :shared:processResources > Task :shared:classes > Task :shared:jar > Task :api:compileJava > Task :api:processResources > Task :api:classes > Task :api:jar > Task :api:assemble > Task :api:compileTestJava > Task :api:processTestResources > Task :api:testClasses > Task :api:test > Task :api:check > Task :api:build > Task :services:person-service:compileJava > Task :services:person-service:processResources > Task :services:person-service:classes > Task :services:person-service:jar > Task :services:person-service:assemble > Task :services:person-service:compileTestJava > Task :services:person-service:processTestResources > Task :services:person-service:testClasses > Task :services:person-service:test > Task :services:person-service:check > Task :services:person-service:build > Task :services:person-service:buildDependents > Task :api:buildDependents BUILD SUCCESSFUL in 0s
最后,您可以构建和测试所有项目中的所有内容。您在根项目文件夹中运行的任何任务都将导致该同名任务在所有子项目上运行。
您可以运行gradle build来构建和测试所有项目。
请参阅构建构建章节以了解更多信息。
下一步: 了解 Gradle 构建生命周期>>
构建生命周期
作为构建作者,您可以定义任务以及任务之间的依赖关系。 Gradle 保证这些任务将按照其依赖关系的顺序执行。
您的构建脚本和插件配置此依赖关系图。
例如,如果您的项目任务包括build、assemble、createDocs,您的构建脚本可以确保它们按照build→ assemble→ 的顺序执行createDoc。
任务图
Gradle 在执行任何任务之前构建任务图。
在构建中的所有项目中,任务形成有向无环图(DAG)。
该图显示了两个示例任务图,一个是抽象的,另一个是具体的,任务之间的依赖关系用箭头表示:

插件和构建脚本都通过任务依赖机制和带注释的输入/输出对任务图做出贡献。
构建阶段
Gradle 构建具有三个不同的阶段。

Gradle 按顺序运行这些阶段:
- 第 1 阶段. 初始化
- 第 2 阶段. 配置
-
-
build.gradle(.kts)评估参与构建的每个项目的构建脚本。 -
为请求的任务创建任务图。
-
- 第三阶段:执行
-
-
安排并执行选定的任务。
-
任务之间的依赖关系决定了执行顺序。
-
任务的执行可以并行发生。
-

例子
以下示例显示了设置和构建文件的哪些部分对应于各个构建阶段:
rootProject.name = "basic"
println("This is executed during the initialization phase.")println("This is executed during the configuration phase.")
tasks.register("configured") {
println("This is also executed during the configuration phase, because :configured is used in the build.")
}
tasks.register("test") {
doLast {
println("This is executed during the execution phase.")
}
}
tasks.register("testBoth") {
doFirst {
println("This is executed first during the execution phase.")
}
doLast {
println("This is executed last during the execution phase.")
}
println("This is executed during the configuration phase as well, because :testBoth is used in the build.")
}rootProject.name = 'basic'
println 'This is executed during the initialization phase.'println 'This is executed during the configuration phase.'
tasks.register('configured') {
println 'This is also executed during the configuration phase, because :configured is used in the build.'
}
tasks.register('test') {
doLast {
println 'This is executed during the execution phase.'
}
}
tasks.register('testBoth') {
doFirst {
println 'This is executed first during the execution phase.'
}
doLast {
println 'This is executed last during the execution phase.'
}
println 'This is executed during the configuration phase as well, because :testBoth is used in the build.'
}以下命令执行上面指定的test和testBoth任务。由于 Gradle 仅配置请求的任务及其依赖项,因此configured任务从不配置:
> gradle test testBoth
This is executed during the initialization phase.
> Configure project :
This is executed during the configuration phase.
This is executed during the configuration phase as well, because :testBoth is used in the build.
> Task :test
This is executed during the execution phase.
> Task :testBoth
This is executed first during the execution phase.
This is executed last during the execution phase.
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executed> gradle test testBoth
This is executed during the initialization phase.
> Configure project :
This is executed during the configuration phase.
This is executed during the configuration phase as well, because :testBoth is used in the build.
> Task :test
This is executed during the execution phase.
> Task :testBoth
This is executed first during the execution phase.
This is executed last during the execution phase.
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executed第 1 阶段. 初始化
在初始化阶段,Gradle 检测项目集(根项目和子项目)并包含参与构建的构建。
Gradle 首先评估设置文件,settings.gradle(.kts)并实例化一个Settings对象。然后,Gradle 实例化Project每个项目的实例。
第 2 阶段. 配置
在配置阶段,Gradle 将任务和其他属性添加到初始化阶段找到的项目中。
写入设置文件
设置文件是每个 Gradle 构建的入口点。

找到设置文件后settings.gradle(.kts),Gradle 会实例化一个Settings对象。
该对象的用途之一Settings是允许您声明要包含在构建中的所有项目。
设置脚本
设置脚本可以是settings.gradleGroovy 中的文件,也可以是settings.gradle.ktsKotlin 中的文件。
在 Gradle 组装项目进行构建之前,它会创建一个Settings实例并针对它执行设置文件。

当设置脚本执行时,它会配置此Settings.因此,设置文件定义了该Settings对象。
|
重要的
|
Settings实例和文件
之间存在一一对应的关系settings.gradle(.kts)。
|
物体Settings
该对象是Gradle APISettings的一部分。
设置脚本中的许多顶级属性和块都是设置 API 的一部分。
例如,我们可以使用以下属性在设置脚本中设置根项目名称Settings.rootProject:
settings.rootProject.name = "root"通常缩写为:
rootProject.name = "root"标准Settings特性
该Settings对象在您的设置脚本中公开一组标准属性。
下表列出了一些常用的属性:
| 姓名 | 描述 |
|---|---|
|
构建缓存配置。 |
|
已应用于设置的插件的容器。 |
|
构建的根目录。根目录是根项目的项目目录。 |
|
构建的根项目。 |
|
返回此设置对象。 |
下表列出了几种常用的方法:
| 姓名 | 描述 |
|---|---|
|
将给定的项目添加到构建中。 |
|
包括复合构建的指定路径处的构建。 |
设置脚本结构
设置脚本是对 Gradle API 的一系列方法调用,通常使用{ … },这是 Groovy 和 Kotlin 语言中的特殊快捷方式。块在 Kotlin 中{ }称为lambda ,在 Groovy 中称为闭包。
简而言之,该plugins{ }块是一个方法调用,其中传递 Kotlin lambda对象或 Groovy闭包对象作为参数。它的缩写形式是:
plugins(function() {
id("plugin")
})块映射到 Gradle API 方法。
函数内的代码针对一个对象执行,该对象在 Kotlin lambda 中this称为接收器,在 Groovy 闭包中称为委托。 Gradle 确定正确的this对象并调用正确的相应方法。this方法调用对象的 的类型id("plugin")为PluginDependenciesSpec。
设置文件由构建在 DSL 之上的 Gradle API 调用组成。 Gradle 从上到下逐行执行脚本。
让我们看一个例子并将其分解:
pluginManagement { // (1)
repositories {
gradlePluginPortal()
google()
}
}
plugins { // (2)
id("org.gradle.toolchains.fake") version "0.6.0"
}
rootProject.name = "root-project" // (3)
dependencyResolutionManagement { // (4)
repositories {
mavenCentral()
}
}
include("sub-project-a") // (5)
include("sub-project-b")
include("sub-project-c")-
Define the location of plugins
-
Apply plugins.
-
Define the root project name.
-
Define build-wide repositories.
-
Add subprojects to the build.
pluginManagement { // (1)
repositories {
gradlePluginPortal()
google()
}
}
plugins { // (2)
id 'org.gradle.toolchains.fake' version '0.6.0'
}
rootProject.name = 'root-project' // (3)
dependencyResolutionManagement { // (4)
repositories {
mavenCentral()
}
}
include('sub-project-a') // (5)
include('sub-project-b')
include('sub-project-c')-
Define the location of plugins.
-
Apply plugins.
-
Define the root project name.
-
Define build-wide repositories.
-
Add subprojects to the build.
1.定义插件的位置
设置文件可以选择定义您的项目使用的插件pluginManagement,包括二进制存储库,例如 Gradle 插件门户或其他使用以下 Gradle 构建includeBuild:
pluginManagement {
repositories {
gradlePluginPortal()
google()
}
}您还可以在此块中包含插件和插件依赖项解析策略。
2. 应用插件
设置文件可以选择声明稍后可能应用的插件,这可以在多个构建/子项目之间添加共享配置:
应用于设置的插件仅影响Settings对象。
plugins {
id("org.gradle.toolchains.fake") version "0.6.0"
}这通常用于确保所有子项目使用相同的插件版本。
4. 定义构建范围的存储库
设置文件可以选择使用 Maven Central 等二进制存储库和/或其他 Gradle 构建来定义项目所依赖的组件的位置(以及如何解析它们):repositoriesincludeBuild
dependencyResolutionManagement {
repositories {
mavenCentral()
}
}您还可以在此部分中包含版本目录。
5. 将子项目添加到构建中
设置文件通过使用以下语句添加所有子项目来定义项目的结构include:
include("app")
include("business-logic")
include("data-model")设置文件脚本
该对象还有更多属性和方法Settings可用于配置构建。
重要的是要记住,虽然许多 Gradle 脚本通常是用简短的 Groovy 或 Kotlin 语法编写的,但设置脚本中的每个项目本质上都是调用SettingsGradle API 中对象的方法:
include("app")实际上是:
settings.include("app")此外,您还可以使用 Groovy 和 Kotlin 语言的全部功能。
例如,include您可以迭代项目根文件夹中的目录列表并自动包含它们,而不是多次添加子项目:
rootDir.listFiles().filter { it.isDirectory && (new File(it, "build.gradle.kts").exists()) }.forEach {
include(it.name)
}|
提示
|
这种类型的逻辑应该在插件中开发。 |
下一步: 学习如何编写构建脚本>>
编写构建脚本
Gradle Build 生命周期中的初始化阶段使用设置文件查找项目根目录中包含的根项目和子项目。
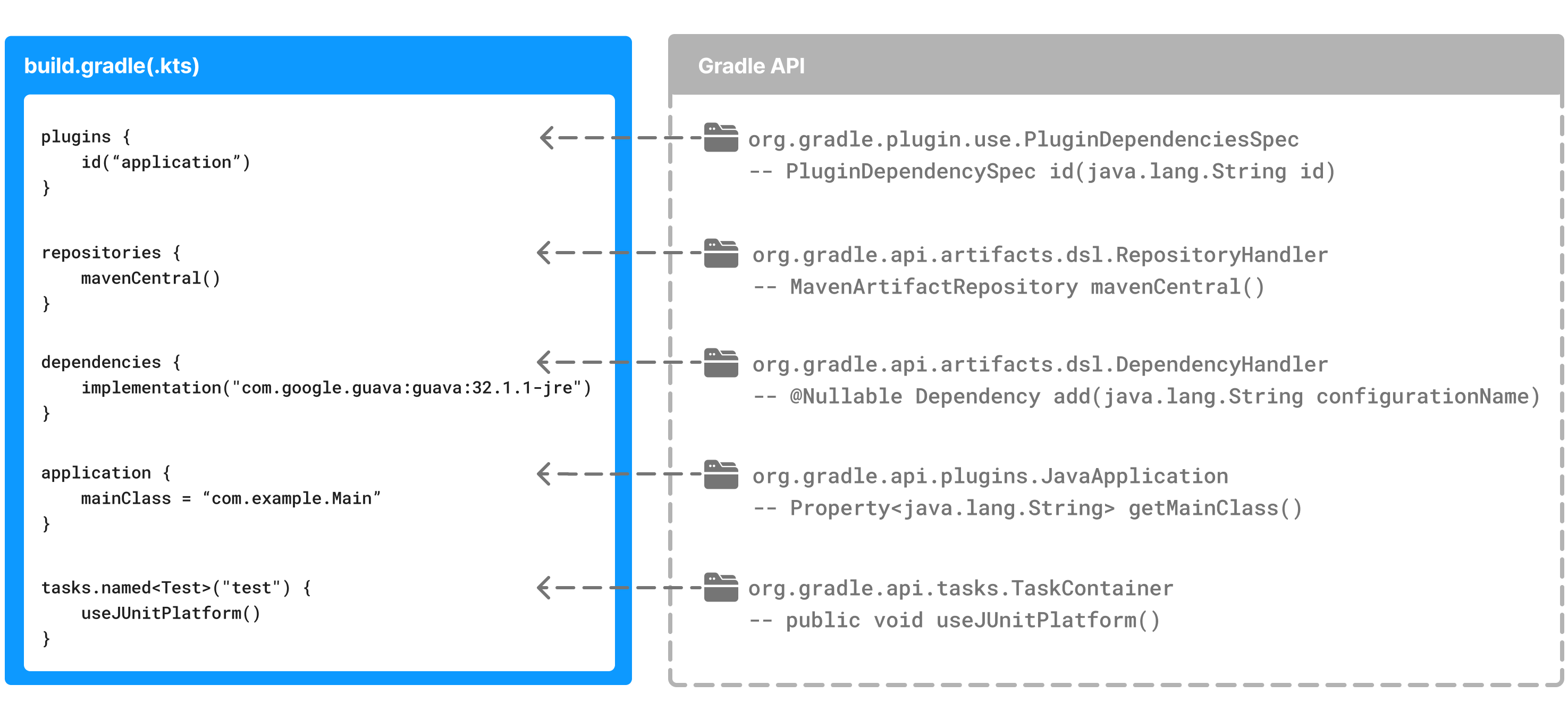
然后,对于设置文件中包含的每个项目,Gradle 都会创建一个Project实例。
然后 Gradle 查找相应的构建脚本文件,该文件在配置阶段使用。
构建脚本
每个 Gradle 构建都包含一个或多个项目;根项目和子项目。
项目通常对应于需要构建的软件组件,例如库或应用程序。它可能代表一个库 JAR、一个 Web 应用程序或由其他项目生成的 JAR 组装而成的分发 ZIP。
另一方面,它可能代表要做的事情,例如将应用程序部署到临时或生产环境。
Gradle 脚本使用 Groovy DSL 或 Kotlin DSL(特定领域语言)编写。
构建脚本配置项目并与 类型的对象关联Project。

当构建脚本执行时,它会配置Project.
构建脚本可以是*.gradleGroovy 中的文件,也可以是*.gradle.ktsKotlin 中的文件。
|
重要的
|
构建脚本配置Project对象及其子对象。
|
物体Project
该对象是Gradle APIProject的一部分:
构建脚本中的许多顶级属性和块都是项目 API 的一部分。
例如,以下构建脚本使用Project.name属性来打印项目的名称:
println(name)
println(project.name)println name
println project.name$ gradle -q check project-api project-api
两个println语句都打印出相同的属性。
name第一个使用对象属性的顶级引用Project。第二条语句使用project可用于任何构建脚本的属性,该属性返回关联的Project对象。
标准项目属性
该Project对象在构建脚本中公开一组标准属性。
下表列出了一些常用的属性:
| 姓名 | 类型 | 描述 |
|---|---|---|
|
|
项目目录的名称。 |
|
|
项目的完全限定名称。 |
|
|
项目的描述。 |
|
|
返回项目的依赖处理程序。 |
|
|
返回项目的存储库处理程序。 |
|
|
提供对项目的几个重要位置的访问。 |
|
|
这个项目的小组。 |
|
|
该项目的版本。 |
下表列出了几种常用的方法:
| 姓名 | 描述 |
|---|---|
|
将文件路径解析为 URI,相对于该项目的项目目录。 |
|
使用给定名称创建一个任务并将其添加到此项目中。 |
构建脚本结构
{ … }Build 脚本由Groovy 和 Kotlin 中的一个特殊对象组成。该对象在 Kotlin 中称为lambda ,在 Groovy 中称为闭包。
简而言之,该plugins{ }块是一个方法调用,其中传递 Kotlin lambda对象或 Groovy闭包对象作为参数。它的缩写形式是:
plugins(function() {
id("plugin")
})块映射到 Gradle API 方法。
函数内的代码针对一个对象执行,该对象在 Kotlin lambda 中this称为接收器,在 Groovy 闭包中称为委托。 Gradle 确定正确的this对象并调用正确的相应方法。this方法调用对象的 的类型id("plugin")为PluginDependenciesSpec。
构建脚本本质上是由构建在 DSL 之上的 Gradle API 调用组成。 Gradle 从上到下逐行执行脚本。
让我们看一个例子并将其分解:
plugins { // (1)
id("org.jetbrains.kotlin.jvm") version "1.9.0"
id("application")
}
repositories { // (2)
mavenCentral()
}
dependencies { // (3)
testImplementation("org.jetbrains.kotlin:kotlin-test-junit5")
testImplementation("org.junit.jupiter:junit-jupiter-engine:5.9.3")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
implementation("com.google.guava:guava:32.1.1-jre")
}
application { // (4)
mainClass = "com.example.Main"
}
tasks.named<Test>("test") { // (5)
useJUnitPlatform()
}-
Apply plugins to the build.
-
Define the locations where dependencies can be found.
-
Add dependencies.
-
Set properties.
-
Register and configure tasks.
plugins { // (1)
id 'org.jetbrains.kotlin.jvm' version '1.9.0'
id 'application'
}
repositories { // (2)
mavenCentral()
}
dependencies { // (3)
testImplementation 'org.jetbrains.kotlin:kotlin-test-junit5'
testImplementation 'org.junit.jupiter:junit-jupiter-engine:5.9.3'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
implementation 'com.google.guava:guava:32.1.1-jre'
}
application { // (4)
mainClass = 'com.example.Main'
}
tasks.named('test') { // (5)
useJUnitPlatform()
}-
Apply plugins to the build.
-
Define the locations where dependencies can be found.
-
Add dependencies.
-
Set properties.
-
Register and configure tasks.
1. 将插件应用到构建中
插件用于扩展 Gradle。它们还用于模块化和重用项目配置。
可以使用插件脚本块应用插件PluginDependenciesSpec。
插件块是首选:
plugins {
id("org.jetbrains.kotlin.jvm") version "1.9.0"
id("application")
}在示例中,application已应用 Gradle 附带的插件,将我们的项目描述为 Java 应用程序。
Kotlin gradle 插件 1.9.0 版本也已应用。该插件不包含在 Gradle 中,因此必须使用 aplugin id和 a进行描述plugin version,以便 Gradle 可以找到并应用它。
2.定义可以找到依赖的位置
一个项目通常具有完成其工作所需的许多依赖项。依赖项包括 Gradle 必须下载才能成功构建的插件、库或组件。
构建脚本让 Gradle 知道在哪里查找依赖项的二进制文件。可以提供多个位置:
repositories {
mavenCentral()
google()
}在示例中,将从Maven Central Repository下载guava库和 JetBrains Kotlin 插件 ( ) 。org.jetbrains.kotlin.jvm
3.添加依赖
一个项目通常具有完成其工作所需的许多依赖项。这些依赖项通常是在项目源代码中导入的预编译类的库。
依赖项通过配置进行管理并从存储库中检索。
使用DependencyHandlerbyProject.getDependencies()方法返回的值来管理依赖关系。使用RepositoryHandlerbyProject.getRepositories()方法返回来管理存储库。
dependencies {
implementation("com.google.guava:guava:32.1.1-jre")
}在示例中,应用程序代码使用 Google 的guava库。 Guava 提供了用于集合、缓存、原语支持、并发、通用注释、字符串处理、I/O 和验证的实用方法。
4. 设置属性
插件可以使用扩展向项目添加属性和方法。
该Project对象有一个关联ExtensionContainer对象,其中包含已应用于项目的插件的所有设置和属性。
在示例中,application插件添加了一个application属性,用于详细说明 Java 应用程序的主类:
application {
mainClass = "com.example.Main"
}5. 注册并配置任务
任务执行一些基本工作,例如编译类、运行单元测试或压缩 WAR 文件。
虽然任务通常在插件中定义,但您可能需要在构建脚本中注册或配置任务。
注册任务会将任务添加到您的项目中。
您可以使用以下方法在项目中注册任务TaskContainer.register(java.lang.String):
tasks.register<Zip>("zip-reports") {
from 'Reports/'
include '*'
archiveName 'Reports.zip'
destinationDir(file('/dir'))
}您可能已经看到了应该避免的TaskContainer.create(java.lang.String)方法的用法:
tasks.create<Zip>("zip-reports") {
from 'Reports/'
include '*'
archiveName 'Reports.zip'
destinationDir(file('/dir'))
}|
提示
|
register(),它可以避免任务配置,优于create().
|
您可以使用以下方法找到任务并对其进行配置TaskCollection.named(java.lang.String):
tasks.named<Test>("test") {
useJUnitPlatform()
}下面的示例将Javadoc任务配置为从 Java 代码自动生成 HTML 文档:
tasks.named("javadoc").configure {
exclude 'app/Internal*.java'
exclude 'app/internal/*'
exclude 'app/internal/*'
}构建脚本
构建脚本由零个或多个语句和脚本块组成:
println(project.layout.projectDirectory);语句可以包括方法调用、属性分配和局部变量定义:
version = '1.0.0.GA'脚本块是一个方法调用,它采用闭包/lambda 作为参数:
configurations {
}闭包/lambda 在执行时配置一些委托对象:
repositories {
google()
}构建脚本也是 Groovy 或 Kotlin 脚本:
tasks.register("upper") {
doLast {
val someString = "mY_nAmE"
println("Original: $someString")
println("Upper case: ${someString.toUpperCase()}")
}
}tasks.register('upper') {
doLast {
String someString = 'mY_nAmE'
println "Original: $someString"
println "Upper case: ${someString.toUpperCase()}"
}
}$ gradle -q upper Original: mY_nAmE Upper case: MY_NAME
它可以包含 Groovy 或 Kotlin 脚本中允许的元素,例如方法定义和类定义:
tasks.register("count") {
doLast {
repeat(4) { print("$it ") }
}
}tasks.register('count') {
doLast {
4.times { print "$it " }
}
}$ gradle -q count 0 1 2 3
灵活的任务注册
使用 Groovy 或 Kotlin 语言的功能,您可以在循环中注册多个任务:
repeat(4) { counter ->
tasks.register("task$counter") {
doLast {
println("I'm task number $counter")
}
}
}4.times { counter ->
tasks.register("task$counter") {
doLast {
println "I'm task number $counter"
}
}
}$ gradle -q task1 I'm task number 1
声明变量
构建脚本可以声明两个变量:局部变量和额外属性。
局部变量
使用关键字声明局部变量val。局部变量仅在声明它们的范围内可见。它们是底层 Kotlin 语言的一个功能。
使用关键字声明局部变量def。局部变量仅在声明它们的范围内可见。它们是底层 Groovy 语言的一个功能。
val dest = "dest"
tasks.register<Copy>("copy") {
from("source")
into(dest)
}def dest = 'dest'
tasks.register('copy', Copy) {
from 'source'
into dest
}额外属性
Gradle 的增强对象(包括项目、任务和源集)可以保存用户定义的属性。
通过所属对象的属性添加、读取和设置额外的属性extra。或者,您可以使用 .kotlin 委托属性来访问额外的属性by extra。
通过所属对象的属性添加、读取和设置额外的属性ext。或者,您可以使用ext块同时添加多个属性。
plugins {
id("java-library")
}
val springVersion by extra("3.1.0.RELEASE")
val emailNotification by extra { "build@master.org" }
sourceSets.all { extra["purpose"] = null }
sourceSets {
main {
extra["purpose"] = "production"
}
test {
extra["purpose"] = "test"
}
create("plugin") {
extra["purpose"] = "production"
}
}
tasks.register("printProperties") {
val springVersion = springVersion
val emailNotification = emailNotification
val productionSourceSets = provider {
sourceSets.matching { it.extra["purpose"] == "production" }.map { it.name }
}
doLast {
println(springVersion)
println(emailNotification)
productionSourceSets.get().forEach { println(it) }
}
}plugins {
id 'java-library'
}
ext {
springVersion = "3.1.0.RELEASE"
emailNotification = "build@master.org"
}
sourceSets.all { ext.purpose = null }
sourceSets {
main {
purpose = "production"
}
test {
purpose = "test"
}
plugin {
purpose = "production"
}
}
tasks.register('printProperties') {
def springVersion = springVersion
def emailNotification = emailNotification
def productionSourceSets = provider {
sourceSets.matching { it.purpose == "production" }.collect { it.name }
}
doLast {
println springVersion
println emailNotification
productionSourceSets.get().each { println it }
}
}$ gradle -q printProperties 3.1.0.RELEASE build@master.org main plugin
project此示例通过 向对象添加两个额外的属性by extra。此外,此示例purpose通过设置extra["purpose"]为为每个源集添加一个名为 的属性null。添加后,您可以通过读取和设置这些属性extra。
project此示例通过块向对象添加两个额外属性ext。此外,此示例purpose通过设置ext.purpose为为每个源集添加一个名为 的属性null。添加后,您可以像预定义的属性一样读取和设置所有这些属性。
Gradle 需要特殊的语法来添加属性,以便它可以快速失败。例如,这允许 Gradle 识别脚本何时尝试设置不存在的属性。您可以在任何可以访问其所属对象的地方访问额外的属性。这为额外属性提供了比局部变量更广泛的范围。子项目可以访问其父项目的额外属性。
有关额外属性的更多信息,请参阅 API 文档中的ExtraPropertiesExtension 。
配置任意对象
示例greet()任务显示了任意对象配置的示例:
class UserInfo(
var name: String? = null,
var email: String? = null
)
tasks.register("configure") {
val user = UserInfo().apply {
name = "Isaac Newton"
email = "isaac@newton.me"
}
doLast {
println(user.name)
println(user.email)
}
}class UserInfo {
String name
String email
}
tasks.register('configure') {
def user = configure(new UserInfo()) {
name = "Isaac Newton"
email = "isaac@newton.me"
}
doLast {
println user.name
println user.email
}
}$ gradle -q greet Isaac Newton isaac@newton.me
闭幕代表
每个闭包都有一个delegate对象。 Groovy 使用此委托来查找对非局部变量和闭包参数的变量和方法引用。 Gradle 将其用于配置闭包,其中delegate对象指的是正在配置的对象。
dependencies {
assert delegate == project.dependencies
testImplementation('junit:junit:4.13')
delegate.testImplementation('junit:junit:4.13')
}默认导入
为了使构建脚本更加简洁,Gradle 会自动向脚本添加一组 import 语句。
因此,throw new org.gradle.api.tasks.StopExecutionException()您可以不写throw new StopExecutionException()而是写。
Gradle 隐式地将以下导入添加到每个脚本中:
import org.gradle.*
import org.gradle.api.*
import org.gradle.api.artifacts.*
import org.gradle.api.artifacts.component.*
import org.gradle.api.artifacts.dsl.*
import org.gradle.api.artifacts.ivy.*
import org.gradle.api.artifacts.maven.*
import org.gradle.api.artifacts.query.*
import org.gradle.api.artifacts.repositories.*
import org.gradle.api.artifacts.result.*
import org.gradle.api.artifacts.transform.*
import org.gradle.api.artifacts.type.*
import org.gradle.api.artifacts.verification.*
import org.gradle.api.attributes.*
import org.gradle.api.attributes.java.*
import org.gradle.api.attributes.plugin.*
import org.gradle.api.cache.*
import org.gradle.api.capabilities.*
import org.gradle.api.component.*
import org.gradle.api.configuration.*
import org.gradle.api.credentials.*
import org.gradle.api.distribution.*
import org.gradle.api.distribution.plugins.*
import org.gradle.api.execution.*
import org.gradle.api.file.*
import org.gradle.api.flow.*
import org.gradle.api.initialization.*
import org.gradle.api.initialization.definition.*
import org.gradle.api.initialization.dsl.*
import org.gradle.api.initialization.resolve.*
import org.gradle.api.invocation.*
import org.gradle.api.java.archives.*
import org.gradle.api.jvm.*
import org.gradle.api.launcher.cli.*
import org.gradle.api.logging.*
import org.gradle.api.logging.configuration.*
import org.gradle.api.model.*
import org.gradle.api.plugins.*
import org.gradle.api.plugins.antlr.*
import org.gradle.api.plugins.catalog.*
import org.gradle.api.plugins.jvm.*
import org.gradle.api.plugins.quality.*
import org.gradle.api.plugins.scala.*
import org.gradle.api.problems.*
import org.gradle.api.provider.*
import org.gradle.api.publish.*
import org.gradle.api.publish.ivy.*
import org.gradle.api.publish.ivy.plugins.*
import org.gradle.api.publish.ivy.tasks.*
import org.gradle.api.publish.maven.*
import org.gradle.api.publish.maven.plugins.*
import org.gradle.api.publish.maven.tasks.*
import org.gradle.api.publish.plugins.*
import org.gradle.api.publish.tasks.*
import org.gradle.api.reflect.*
import org.gradle.api.reporting.*
import org.gradle.api.reporting.components.*
import org.gradle.api.reporting.dependencies.*
import org.gradle.api.reporting.dependents.*
import org.gradle.api.reporting.model.*
import org.gradle.api.reporting.plugins.*
import org.gradle.api.resources.*
import org.gradle.api.services.*
import org.gradle.api.specs.*
import org.gradle.api.tasks.*
import org.gradle.api.tasks.ant.*
import org.gradle.api.tasks.application.*
import org.gradle.api.tasks.bundling.*
import org.gradle.api.tasks.compile.*
import org.gradle.api.tasks.diagnostics.*
import org.gradle.api.tasks.diagnostics.configurations.*
import org.gradle.api.tasks.incremental.*
import org.gradle.api.tasks.javadoc.*
import org.gradle.api.tasks.options.*
import org.gradle.api.tasks.scala.*
import org.gradle.api.tasks.testing.*
import org.gradle.api.tasks.testing.junit.*
import org.gradle.api.tasks.testing.junitplatform.*
import org.gradle.api.tasks.testing.testng.*
import org.gradle.api.tasks.util.*
import org.gradle.api.tasks.wrapper.*
import org.gradle.api.toolchain.management.*
import org.gradle.authentication.*
import org.gradle.authentication.aws.*
import org.gradle.authentication.http.*
import org.gradle.build.event.*
import org.gradle.buildinit.*
import org.gradle.buildinit.plugins.*
import org.gradle.buildinit.tasks.*
import org.gradle.caching.*
import org.gradle.caching.configuration.*
import org.gradle.caching.http.*
import org.gradle.caching.local.*
import org.gradle.concurrent.*
import org.gradle.external.javadoc.*
import org.gradle.ide.visualstudio.*
import org.gradle.ide.visualstudio.plugins.*
import org.gradle.ide.visualstudio.tasks.*
import org.gradle.ide.xcode.*
import org.gradle.ide.xcode.plugins.*
import org.gradle.ide.xcode.tasks.*
import org.gradle.ivy.*
import org.gradle.jvm.*
import org.gradle.jvm.application.scripts.*
import org.gradle.jvm.application.tasks.*
import org.gradle.jvm.tasks.*
import org.gradle.jvm.toolchain.*
import org.gradle.language.*
import org.gradle.language.assembler.*
import org.gradle.language.assembler.plugins.*
import org.gradle.language.assembler.tasks.*
import org.gradle.language.base.*
import org.gradle.language.base.artifact.*
import org.gradle.language.base.compile.*
import org.gradle.language.base.plugins.*
import org.gradle.language.base.sources.*
import org.gradle.language.c.*
import org.gradle.language.c.plugins.*
import org.gradle.language.c.tasks.*
import org.gradle.language.cpp.*
import org.gradle.language.cpp.plugins.*
import org.gradle.language.cpp.tasks.*
import org.gradle.language.java.artifact.*
import org.gradle.language.jvm.tasks.*
import org.gradle.language.nativeplatform.*
import org.gradle.language.nativeplatform.tasks.*
import org.gradle.language.objectivec.*
import org.gradle.language.objectivec.plugins.*
import org.gradle.language.objectivec.tasks.*
import org.gradle.language.objectivecpp.*
import org.gradle.language.objectivecpp.plugins.*
import org.gradle.language.objectivecpp.tasks.*
import org.gradle.language.plugins.*
import org.gradle.language.rc.*
import org.gradle.language.rc.plugins.*
import org.gradle.language.rc.tasks.*
import org.gradle.language.scala.tasks.*
import org.gradle.language.swift.*
import org.gradle.language.swift.plugins.*
import org.gradle.language.swift.tasks.*
import org.gradle.maven.*
import org.gradle.model.*
import org.gradle.nativeplatform.*
import org.gradle.nativeplatform.platform.*
import org.gradle.nativeplatform.plugins.*
import org.gradle.nativeplatform.tasks.*
import org.gradle.nativeplatform.test.*
import org.gradle.nativeplatform.test.cpp.*
import org.gradle.nativeplatform.test.cpp.plugins.*
import org.gradle.nativeplatform.test.cunit.*
import org.gradle.nativeplatform.test.cunit.plugins.*
import org.gradle.nativeplatform.test.cunit.tasks.*
import org.gradle.nativeplatform.test.googletest.*
import org.gradle.nativeplatform.test.googletest.plugins.*
import org.gradle.nativeplatform.test.plugins.*
import org.gradle.nativeplatform.test.tasks.*
import org.gradle.nativeplatform.test.xctest.*
import org.gradle.nativeplatform.test.xctest.plugins.*
import org.gradle.nativeplatform.test.xctest.tasks.*
import org.gradle.nativeplatform.toolchain.*
import org.gradle.nativeplatform.toolchain.plugins.*
import org.gradle.normalization.*
import org.gradle.platform.*
import org.gradle.platform.base.*
import org.gradle.platform.base.binary.*
import org.gradle.platform.base.component.*
import org.gradle.platform.base.plugins.*
import org.gradle.plugin.devel.*
import org.gradle.plugin.devel.plugins.*
import org.gradle.plugin.devel.tasks.*
import org.gradle.plugin.management.*
import org.gradle.plugin.use.*
import org.gradle.plugins.ear.*
import org.gradle.plugins.ear.descriptor.*
import org.gradle.plugins.ide.*
import org.gradle.plugins.ide.api.*
import org.gradle.plugins.ide.eclipse.*
import org.gradle.plugins.ide.idea.*
import org.gradle.plugins.signing.*
import org.gradle.plugins.signing.signatory.*
import org.gradle.plugins.signing.signatory.pgp.*
import org.gradle.plugins.signing.type.*
import org.gradle.plugins.signing.type.pgp.*
import org.gradle.process.*
import org.gradle.swiftpm.*
import org.gradle.swiftpm.plugins.*
import org.gradle.swiftpm.tasks.*
import org.gradle.testing.base.*
import org.gradle.testing.base.plugins.*
import org.gradle.testing.jacoco.plugins.*
import org.gradle.testing.jacoco.tasks.*
import org.gradle.testing.jacoco.tasks.rules.*
import org.gradle.testkit.runner.*
import org.gradle.util.*
import org.gradle.vcs.*
import org.gradle.vcs.git.*
import org.gradle.work.*
import org.gradle.workers.*下一步: 了解如何使用任务>>
使用任务
Gradle 可以在项目上执行的工作由一项或多项任务定义。

任务代表构建执行的某些独立工作单元。这可能是编译一些类、创建 JAR、生成 Javadoc 或将一些档案发布到存储库。
当用户./gradlew build在命令行中运行时,Gradle 将执行该build任务及其依赖的任何其他任务。
列出可用任务
Gradle 为项目提供了几个默认任务,通过运行列出./gradlew tasks:
> Task :tasks
------------------------------------------------------------
Tasks runnable from root project 'myTutorial'
------------------------------------------------------------
Build Setup tasks
-----------------
init - Initializes a new Gradle build.
wrapper - Generates Gradle wrapper files.
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in root project 'myTutorial'.
...任务来自构建脚本或插件。
一旦我们将插件应用到我们的项目中,例如application插件,其他任务就变得可用:
plugins {
id("application")
}$ ./gradlew tasks
> Task :tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
Documentation tasks
-------------------
javadoc - Generates Javadoc API documentation for the main source code.
Other tasks
-----------
compileJava - Compiles main Java source.
...开发人员应该熟悉其中的许多任务,例如assemble、build、 和。run
任务分类
可以执行两类任务:
-
可操作的任务附加了一些操作来在您的构建中完成工作:
compileJava。 -
生命周期任务是没有附加操作的任务:
assemble,build。
通常,生命周期任务取决于许多可操作的任务,并且用于一次执行许多任务。
任务注册和行动
让我们看一下构建脚本中的一个简单的“Hello World”任务:
tasks.register("hello") {
doLast {
println("Hello world!")
}
}tasks.register('hello') {
doLast {
println 'Hello world!'
}
}在示例中,构建脚本注册hello一个使用TaskContainer API调用的单个任务,并向其添加一个操作。
如果列出了项目中的任务,则该hello任务可供 Gradle 使用:
$ ./gradlew app:tasks --all
> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Other tasks
-----------
compileJava - Compiles main Java source.
compileTestJava - Compiles test Java source.
hello
processResources - Processes main resources.
processTestResources - Processes test resources.
startScripts - Creates OS-specific scripts to run the project as a JVM application.您可以使用以下命令在构建脚本中执行任务./gradlew hello:
$ ./gradlew hello Hello world!
当 Gradle 执行hello任务时,它会执行提供的操作。在这种情况下,操作只是一个包含一些代码的块:println("Hello world!")。
任务组和描述
hello上一节中的任务可以通过描述进行详细说明,并通过以下更新分配给一个组:
tasks.register("hello") {
group = "Custom"
description = "A lovely greeting task."
doLast {
println("Hello world!")
}
}将任务分配给组后,它将按以下方式列出./gradlew tasks:
$ ./gradlew tasks
> Task :tasks
Custom tasks
------------------
hello - A lovely greeting task.要查看有关任务的信息,请使用以下help --task <task-name>命令:
$./gradlew help --task hello
> Task :help
Detailed task information for hello
Path
:app:hello
Type
Task (org.gradle.api.Task)
Options
--rerun Causes the task to be re-run even if up-to-date.
Description
A lovely greeting task.
Group
Custom正如我们所看到的,该hello任务属于该custom组。
任务依赖关系
您可以声明依赖于其他任务的任务:
tasks.register("hello") {
doLast {
println("Hello world!")
}
}
tasks.register("intro") {
dependsOn("hello")
doLast {
println("I'm Gradle")
}
}tasks.register('hello') {
doLast {
println 'Hello world!'
}
}
tasks.register('intro') {
dependsOn tasks.hello
doLast {
println "I'm Gradle"
}
}$ gradle -q intro Hello world! I'm Gradle
taskXto的依赖taskY可以在taskY定义之前声明:
tasks.register("taskX") {
dependsOn("taskY")
doLast {
println("taskX")
}
}
tasks.register("taskY") {
doLast {
println("taskY")
}
}tasks.register('taskX') {
dependsOn 'taskY'
doLast {
println 'taskX'
}
}
tasks.register('taskY') {
doLast {
println 'taskY'
}
}$ gradle -q taskX taskY taskX
hello上一个示例中的任务已更新以包含依赖项:
tasks.register("hello") {
group = "Custom"
description = "A lovely greeting task."
doLast {
println("Hello world!")
}
dependsOn(tasks.assemble)
}现在任务hello依赖于assemble任务,这意味着 Gradle 必须先assemble执行任务才能执行任务:hello
$ ./gradlew :app:hello
> Task :app:compileJava UP-TO-DATE
> Task :app:processResources NO-SOURCE
> Task :app:classes UP-TO-DATE
> Task :app:jar UP-TO-DATE
> Task :app:startScripts UP-TO-DATE
> Task :app:distTar UP-TO-DATE
> Task :app:distZip UP-TO-DATE
> Task :app:assemble UP-TO-DATE
> Task :app:hello
Hello world!任务配置
注册后,可以通过TaskProvider API访问任务以进行进一步配置。
例如,您可以使用它在运行时动态向任务添加依赖项:
repeat(4) { counter ->
tasks.register("task$counter") {
doLast {
println("I'm task number $counter")
}
}
}
tasks.named("task0") { dependsOn("task2", "task3") }4.times { counter ->
tasks.register("task$counter") {
doLast {
println "I'm task number $counter"
}
}
}
tasks.named('task0') { dependsOn('task2', 'task3') }$ gradle -q task0 I'm task number 2 I'm task number 3 I'm task number 0
或者您可以向现有任务添加行为:
tasks.register("hello") {
doLast {
println("Hello Earth")
}
}
tasks.named("hello") {
doFirst {
println("Hello Venus")
}
}
tasks.named("hello") {
doLast {
println("Hello Mars")
}
}
tasks.named("hello") {
doLast {
println("Hello Jupiter")
}
}tasks.register('hello') {
doLast {
println 'Hello Earth'
}
}
tasks.named('hello') {
doFirst {
println 'Hello Venus'
}
}
tasks.named('hello') {
doLast {
println 'Hello Mars'
}
}
tasks.named('hello') {
doLast {
println 'Hello Jupiter'
}
}$ gradle -q hello Hello Venus Hello Earth Hello Mars Hello Jupiter
|
提示
|
调用doFirst和doLast可以多次执行。他们将操作添加到任务操作列表的开头或结尾。任务执行时,会按顺序执行动作列表中的动作。
|
named以下是用于配置插件添加的任务的方法示例:
tasks.named("dokkaHtml") {
outputDirectory.set(buildDir.resolve("dokka"))
}任务类型
Gradle 任务是Task.
在构建脚本中,HelloTask该类是通过扩展创建的DefaultTask:
// Extend the DefaultTask class to create a HelloTask class
abstract class HelloTask : DefaultTask() {
@TaskAction
fun hello() {
println("hello from HelloTask")
}
}
// Register the hello Task with type HelloTask
tasks.register<HelloTask>("hello") {
group = "Custom tasks"
description = "A lovely greeting task."
}该hello任务已注册为type HelloTask。
执行我们的新hello任务:
$ ./gradlew hello
> Task :app:hello
hello from HelloTask现在hello任务是 typeHelloTask而不是 type Task。
Gradlehelp任务揭示了变化:
$ ./gradlew help --task hello
> Task :help
Detailed task information for hello
Path
:app:hello
Type
HelloTask (Build_gradle$HelloTask)
Options
--rerun Causes the task to be re-run even if up-to-date.
Description
A lovely greeting task.
Group
Custom tasks写作任务
Gradle 任务是通过扩展DefaultTask.
但是,该泛型DefaultTask没有为 Gradle 提供任何操作。如果用户想要扩展 Gradle 及其构建脚本的功能,他们必须使用内置任务或创建自定义任务:
-
内置任务- Gradle 提供内置实用任务,例如
Copy、Jar、Zip、Delete等... -
自定义任务- Gradle 允许用户子类化
DefaultTask以创建自己的任务类型。
创建任务
创建自定义任务最简单、最快捷的方法是在构建脚本中:
要创建任务,请从该类继承DefaultTask并实现@TaskAction处理程序:
abstract class CreateFileTask : DefaultTask() {
@TaskAction
fun action() {
val file = File("myfile.txt")
file.createNewFile()
file.writeText("HELLO FROM MY TASK")
}
}它CreateFileTask实现了一组简单的操作。首先,在主项目中创建一个名为“myfile.txt”的文件。然后,一些文本被写入该文件。
注册任务
使用该方法在构建脚本中注册任务TaskContainer.register(),然后可以在构建逻辑中使用它。
abstract class CreateFileTask : DefaultTask() {
@TaskAction
fun action() {
val file = File("myfile.txt")
file.createNewFile()
file.writeText("HELLO FROM MY TASK")
}
}
tasks.register<CreateFileTask>("createFileTask")任务组和描述
设置任务的组和描述属性可以帮助用户了解如何使用您的任务:
abstract class CreateFileTask : DefaultTask() {
@TaskAction
fun action() {
val file = File("myfile.txt")
file.createNewFile()
file.writeText("HELLO FROM MY TASK")
}
}
tasks.register<CreateFileTask>("createFileTask", ) {
group = "custom"
description = "Create myfile.txt in the current directory"
}将任务添加到组后,在列出任务时即可看到该任务。
任务输入和输出
为了让任务做有用的工作,它通常需要一些输入。任务通常会产生输出。
abstract class CreateFileTask : DefaultTask() {
@Input
val fileText = "HELLO FROM MY TASK"
@Input
val fileName = "myfile.txt"
@OutputFile
val myFile: File = File(fileName)
@TaskAction
fun action() {
myFile.createNewFile()
myFile.writeText(fileText)
}
}
tasks.register<CreateFileTask>("createFileTask") {
group = "custom"
description = "Create myfile.txt in the current directory"
}配置任务
使用该方法可以选择在构建脚本中配置任务TaskCollection.named()。
该类CreateFileTask已更新,以便文件中的文本是可配置的:
abstract class CreateFileTask : DefaultTask() {
@get:Input
abstract val fileText: Property<String>
@Input
val fileName = "myfile.txt"
@OutputFile
val myFile: File = File(fileName)
@TaskAction
fun action() {
myFile.createNewFile()
myFile.writeText(fileText.get())
}
}
tasks.register<CreateFileTask>("createFileTask") {
group = "custom"
description = "Create myfile.txt in the current directory"
fileText.convention("HELLO FROM THE CREATE FILE TASK METHOD") // Set convention
}
tasks.named<CreateFileTask>("createFileTask") {
fileText.set("HELLO FROM THE NAMED METHOD") // Override with custom message
}在该named()方法中,我们找到createFileTask任务并设置将写入文件的文本。
任务执行时:
$ ./gradlew createFileTask
> Configure project :app
> Task :app:createFileTask
BUILD SUCCESSFUL in 5s
2 actionable tasks: 1 executed, 1 up-to-datemyfile.txt在项目根文件夹中创建一个名为的文本文件:
HELLO FROM THE NAMED METHOD请参阅“开发 Gradle 任务”一章以了解更多信息。
下一步: 了解如何使用插件>>
使用插件
Gradle 的大部分功能都是通过插件提供的,包括随 Gradle 分发的核心插件、第三方插件以及构建中定义的脚本插件。
插件引入新任务(例如,JavaCompile)、域对象(例如,SourceSet)、约定(例如,将 Java 源定位于src/main/java),并扩展核心或其他插件对象。
Gradle 中的插件对于自动化常见构建任务、与外部工具或服务集成以及定制构建过程以满足特定项目需求至关重要。它们还充当组织构建逻辑的主要机制。
插件的好处
在构建脚本中编写许多任务并复制配置块可能会变得混乱。与直接向构建脚本添加逻辑相比,插件具有以下几个优点:
-
促进可重用性:减少跨项目重复类似逻辑的需要。
-
增强模块化:允许更加模块化和有组织的构建脚本。
-
封装逻辑:保持命令式逻辑分离,从而实现更具声明性的构建脚本。
插件分发
您可以利用 Gradle 和 Gradle 社区的插件,也可以创建自己的插件。
插件可以通过三种方式使用:
-
核心插件- Gradle 开发并维护一组核心插件。
-
社区插件- 在远程存储库(例如 Maven 或Gradle 插件门户)中共享的 Gradle 插件。
-
本地插件- Gradle 使用户能够使用API创建自定义插件。
插件类型
插件可以实现为二进制插件、预编译脚本插件或脚本插件:
- 二进制插件
-
二进制插件是通常用 Java 或 Kotlin DSL 编写的编译插件,打包为 JAR 文件。它们被应用到使用块的项目中
plugins {}。与脚本插件或预编译脚本插件相比,它们提供更好的性能和可维护性。 - 预编译脚本插件
-
预编译脚本插件是 Groovy DSL 或 Kotlin DSL 脚本,它们被编译并作为打包在库中的 Java 类文件分发。它们被应用到使用块的项目中
plugins {}。它们提供了一种跨项目重用复杂逻辑的方法,并允许更好地组织构建逻辑。 - 脚本插件
-
脚本插件是 Groovy DSL 或 Kotlin DSL 脚本,它们使用语法直接应用于 Gradle 构建脚本
apply from:。它们在构建脚本中内联应用,以添加功能或自定义构建过程。它们使用起来很简单。
插件通常作为脚本插件启动(因为它们很容易编写)。然后,随着代码变得更有价值,它会被迁移到可以在多个项目或组织之间轻松测试和共享的二进制插件。
使用插件
要使用插件中封装的构建逻辑,Gradle 需要执行两个步骤。首先,它需要解析插件,然后需要将插件应用到目标,通常是Project.
-
解析插件意味着找到包含给定插件的 JAR 的正确版本并将其添加到脚本类路径中。一旦插件被解析,它的 API 就可以在构建脚本中使用。脚本插件是自我解析的,因为它们是从应用它们时提供的特定文件路径或 URL 解析的。作为 Gradle 发行版的一部分提供的核心二进制插件会自动解析。
-
应用插件意味着在项目上执行插件的Plugin.apply(T) 。
建议使用插件DSL一步解决并应用插件。
解决插件问题
Gradle 提供了核心插件(例如,JavaPlugin、GroovyPlugin、MavenPublishPlugin等)作为其分发的一部分,这意味着它们会自动解析。
核心插件使用插件名称应用在构建脚本中:
plugins {
id «plugin name»
}例如:
plugins {
id("java")
}非核心插件必须先解析后才能应用。非核心插件由构建文件中的唯一 ID 和版本来标识:
plugins {
id «plugin id» version «plugin version»
}并且必须在设置文件中指定插件的位置:
pluginManagement {
repositories {
gradlePluginPortal()
}
maven {
url 'https://maven.example.com/plugins'
}
}解决和应用插件还有其他注意事项:
| # | 到 | 使用 | 例如: |
|---|---|---|---|
将核心、社区或本地插件应用到特定项目。 |
|
||
将通用核心、社区或本地插件应用到多个子项目。 |
|
||
应用构建脚本本身所需的核心、社区或本地插件。 |
|
||
应用本地脚本插件。 |
|
plugins{}1. 使用块应用插件
插件 DSL 提供了一种简洁便捷的方式来声明插件依赖项。
插件块配置一个实例PluginDependenciesSpec:
plugins {
application // by name
java // by name
id("java") // by id - recommended
id("org.jetbrains.kotlin.jvm") version "1.9.0" // by id - recommended
}核心 Gradle 插件的独特之处在于它们提供短名称,例如java核心JavaPlugin。
要应用核心插件,可以使用短名称:
plugins {
java
}plugins {
id 'java'
}所有其他二进制插件必须使用插件 ID 的完全限定形式(例如com.github.foo.bar)。
要从Gradle 插件门户应用社区插件,必须使用完全限定的插件 id (全局唯一标识符):
plugins {
id("com.jfrog.bintray") version "1.8.5"
}plugins {
id 'com.jfrog.bintray' version '1.8.5'
}PluginDependenciesSpec有关使用插件 DSL 的更多信息,请参阅 参考资料。
插件 DSL 的限制
插件 DSL 为用户提供了方便的语法,并且让 Gradle 能够快速确定使用哪些插件。这使得 Gradle 能够:
-
优化插件类的加载和复用。
-
为编辑者提供有关构建脚本中潜在属性和值的详细信息。
然而,DSL 要求插件是静态定义的。
plugins {}区块机制和“传统”方法机制之间存在一些关键的区别apply()。还有一些限制和可能的限制。
约束语法
该plugins {}块不支持任意代码。
它被限制为幂等(每次产生相同的结果)和无副作用(Gradle 可以随时安全执行)。
形式为:
plugins {
id(«plugin id») // (1)
id(«plugin id») version «plugin version» // (2)
}-
for core Gradle plugins or plugins already available to the build script
-
for binary Gradle plugins that need to be resolved
plugins {
id «plugin id» // (1)
id «plugin id» version «plugin version» // (2)
}-
for core Gradle plugins or plugins already available to the build script
-
for binary Gradle plugins that need to be resolved
其中«plugin id»和«plugin version»是一个字符串。
其中«plugin id»和«plugin version»必须是常量、文字字符串。
该plugins{}块还必须是构建脚本中的顶级语句。它不能嵌套在另一个构造中(例如,if 语句或for 循环)。
仅在构建脚本和设置文件中
该块只能在项目的构建脚本和文件plugins{}中使用。它必须出现在任何其他块之前。它不能在脚本插件或初始化脚本中使用。build.gradle(.kts)settings.gradle(.kts)
将插件应用到所有子项目
假设您有一个多项目构建,您可能希望将插件应用于构建中的部分或全部子项目,但不应用于项目root。
虽然该块的默认行为plugins{}是立即resolve 使用 apply插件,但您可以使用apply false语法告诉 Gradle 不要将插件应用到当前项目。然后,plugins{}在子项目的构建脚本中使用没有版本的块:
include("hello-a")
include("hello-b")
include("goodbye-c")plugins {
id("com.example.hello") version "1.0.0" apply false
id("com.example.goodbye") version "1.0.0" apply false
}plugins {
id("com.example.hello")
}plugins {
id("com.example.hello")
}plugins {
id("com.example.goodbye")
}include 'hello-a'
include 'hello-b'
include 'goodbye-c'plugins {
id 'com.example.hello' version '1.0.0' apply false
id 'com.example.goodbye' version '1.0.0' apply false
}plugins {
id 'com.example.hello'
}plugins {
id 'com.example.hello'
}plugins {
id 'com.example.goodbye'
}您还可以通过使用自己的约定插件编写构建逻辑来封装外部插件的版本。
buildSrc2. 从目录应用插件
buildSrc是 Gradle 项目根目录中的一个可选目录,其中包含用于构建主项目的构建逻辑(即插件)。您可以应用驻留在项目buildSrc目录中的插件,只要它们具有已定义的 ID。
以下示例显示如何将my.MyPlugin在 中定义的插件实现类绑定buildSrc到 id“my-plugin”:
plugins {
`java-gradle-plugin`
}
gradlePlugin {
plugins {
create("myPlugins") {
id = "my-plugin"
implementationClass = "my.MyPlugin"
}
}
}plugins {
id 'java-gradle-plugin'
}
gradlePlugin {
plugins {
myPlugins {
id = 'my-plugin'
implementationClass = 'my.MyPlugin'
}
}
}然后可以通过 ID 应用该插件:
plugins {
id("my-plugin")
}plugins {
id 'my-plugin'
}buildscript{}3. 使用块应用插件
该buildscript块用于:
-
全局
dependencies且repositories构建项目所需(在子项目中应用)。 -
声明哪些插件可在构建脚本中使用(在
build.gradle(.kts)文件本身中)。
因此,当您想在构建脚本本身中使用库时,必须使用以下命令将此库添加到脚本类路径上buildScript:
import org.apache.commons.codec.binary.Base64
buildscript {
repositories { // this is where the plugins are located
mavenCentral()
google()
}
dependencies { // these are the plugins that can be used in subprojects or in the build file itself
classpath group: 'commons-codec', name: 'commons-codec', version: '1.2' // used in the task below
classpath 'com.android.tools.build:gradle:4.1.0' // used in subproject
}
}
tasks.register('encode') {
doLast {
def byte[] encodedString = new Base64().encode('hello world\n'.getBytes())
println new String(encodedString)
}
}您可以在需要它的子项目中应用全局声明的依赖项:
plugins {
id 'com.android.application'
}作为外部 jar 文件发布的二进制插件可以通过将插件添加到构建脚本类路径然后应用该插件来添加到项目中。
可以使用块将外部 jar 添加到构建脚本类路径,如构建脚本的外部依赖项buildscript{}中所述:
buildscript {
repositories {
gradlePluginPortal()
}
dependencies {
classpath("com.jfrog.bintray.gradle:gradle-bintray-plugin:1.8.5")
}
}
apply(plugin = "com.jfrog.bintray")buildscript {
repositories {
gradlePluginPortal()
}
dependencies {
classpath 'com.jfrog.bintray.gradle:gradle-bintray-plugin:1.8.5'
}
}
apply plugin: 'com.jfrog.bintray'4. 使用遗留apply()方法应用脚本插件
脚本插件是一个临时插件,通常在同一构建脚本中编写和应用。它是使用遗留应用程序方法应用的:
class MyPlugin : Plugin<Project> {
override fun apply(project: Project) {
println("Plugin ${this.javaClass.simpleName} applied on ${project.name}")
}
}
apply<MyPlugin>()other.gradle让我们看一个在与该文件位于同一目录中的文件中编写的插件的基本示例build.gradle:
public class Other implements Plugin<Project> {
@Override
void apply(Project project) {
// Does something
}
}首先,使用以下命令导入外部文件:
apply from: 'other.gradle'然后你就可以应用它:
apply plugin: Other脚本插件会自动解析,并且可以从本地文件系统上的脚本或远程应用:
apply(from = "other.gradle.kts")apply from: 'other.gradle'文件系统位置是相对于项目目录的,而远程脚本位置是使用 HTTP URL 指定的。多个脚本插件(任一形式)可以应用于给定目标。
插件管理
该pluginManagement{}块用于配置插件解析的存储库,并为构建脚本中应用的插件定义版本约束。
该pluginManagement{}块可以在文件中使用settings.gradle(.kts),它必须是文件中的第一个块:
pluginManagement {
plugins {
}
resolutionStrategy {
}
repositories {
}
}
rootProject.name = "plugin-management"pluginManagement {
plugins {
}
resolutionStrategy {
}
repositories {
}
}
rootProject.name = 'plugin-management'该块也可以在初始化脚本中使用:
settingsEvaluated {
pluginManagement {
plugins {
}
resolutionStrategy {
}
repositories {
}
}
}settingsEvaluated { settings ->
settings.pluginManagement {
plugins {
}
resolutionStrategy {
}
repositories {
}
}
}自定义插件存储库
默认情况下,plugins{}DSL 解析来自公共Gradle 插件门户的插件。
许多构建作者还希望解析来自私有 Maven 或 Ivy 存储库的插件,因为它们包含专有的实现细节,或者可以更好地控制哪些插件可用于其构建。
要指定自定义插件存储库,请使用repositories{}内部块pluginManagement{}:
pluginManagement {
repositories {
maven(url = "./maven-repo")
gradlePluginPortal()
ivy(url = "./ivy-repo")
}
}pluginManagement {
repositories {
maven {
url './maven-repo'
}
gradlePluginPortal()
ivy {
url './ivy-repo'
}
}
}这告诉 Gradle 在解析插件时首先查看 Maven 存储库,../maven-repo如果在 Maven 存储库中找不到插件,则检查 Gradle 插件门户。如果您不想搜索 Gradle 插件门户,请省略该gradlePluginPortal()行。最后,../ivy-repo将检查Ivy 存储库。
插件版本管理
plugins{}内部的块允许pluginManagement{}在单个位置定义构建的所有插件版本。然后可以通过块通过 id 将插件应用到任何构建脚本plugins{}。
以这种方式设置插件版本的好处之一是,它pluginManagement.plugins{}不具有与构建脚本块相同的约束语法plugins{}。这允许从 获取插件版本gradle.properties,或通过其他机制加载插件版本。
通过以下方式管理插件版本pluginManagement:
pluginManagement {
val helloPluginVersion: String by settings
plugins {
id("com.example.hello") version "${helloPluginVersion}"
}
}plugins {
id("com.example.hello")
}helloPluginVersion=1.0.0pluginManagement {
plugins {
id 'com.example.hello' version "${helloPluginVersion}"
}
}plugins {
id 'com.example.hello'
}helloPluginVersion=1.0.0插件版本从设置脚本加载gradle.properties并在设置脚本中配置,允许将插件添加到任何项目而无需指定版本。
插件解析规则
插件解析规则允许您修改plugins{}块中发出的插件请求,例如,更改请求的版本或显式指定实现工件坐标。
要添加解析规则,请使用块resolutionStrategy{}内部pluginManagement{}:
pluginManagement {
resolutionStrategy {
eachPlugin {
if (requested.id.namespace == "com.example") {
useModule("com.example:sample-plugins:1.0.0")
}
}
}
repositories {
maven {
url = uri("./maven-repo")
}
gradlePluginPortal()
ivy {
url = uri("./ivy-repo")
}
}
}pluginManagement {
resolutionStrategy {
eachPlugin {
if (requested.id.namespace == 'com.example') {
useModule('com.example:sample-plugins:1.0.0')
}
}
}
repositories {
maven {
url './maven-repo'
}
gradlePluginPortal()
ivy {
url './ivy-repo'
}
}
}这告诉 Gradle 使用指定的插件实现工件,而不是其从插件 ID 到 Maven/Ivy 坐标的内置默认映射。
自定义 Maven 和 Ivy 插件存储库必须包含插件标记工件和实现该插件的工件。请阅读Gradle 插件开发插件,了解有关将插件发布到自定义存储库的更多信息。
有关使用该块的完整文档,请参阅PluginManagementSpecpluginManagement{}。
插件标记工件
由于plugins{}DSL 块仅允许通过全局唯一的插件id和version属性来声明插件,因此 Gradle 需要一种方法来查找插件实现工件的坐标。
为此,Gradle 将查找坐标为 的插件标记工件plugin.id:plugin.id.gradle.plugin:plugin.version。该标记需要依赖于实际的插件实现。发布这些标记是由java-gradle-plugin自动完成的。
例如,项目中的以下完整示例sample-plugins展示了如何使用java-gradle-plugin、maven-publish插件和ivy-publish插件的组合将插件发布到 Ivy 和 Maven 存储com.example.hello库。com.example.goodbye
plugins {
`java-gradle-plugin`
`maven-publish`
`ivy-publish`
}
group = "com.example"
version = "1.0.0"
gradlePlugin {
plugins {
create("hello") {
id = "com.example.hello"
implementationClass = "com.example.hello.HelloPlugin"
}
create("goodbye") {
id = "com.example.goodbye"
implementationClass = "com.example.goodbye.GoodbyePlugin"
}
}
}
publishing {
repositories {
maven {
url = uri(layout.buildDirectory.dir("maven-repo"))
}
ivy {
url = uri(layout.buildDirectory.dir("ivy-repo"))
}
}
}plugins {
id 'java-gradle-plugin'
id 'maven-publish'
id 'ivy-publish'
}
group 'com.example'
version '1.0.0'
gradlePlugin {
plugins {
hello {
id = 'com.example.hello'
implementationClass = 'com.example.hello.HelloPlugin'
}
goodbye {
id = 'com.example.goodbye'
implementationClass = 'com.example.goodbye.GoodbyePlugin'
}
}
}
publishing {
repositories {
maven {
url layout.buildDirectory.dir("maven-repo")
}
ivy {
url layout.buildDirectory.dir("ivy-repo")
}
}
}在示例目录中运行gradle publish会创建以下 Maven 存储库布局(Ivy 布局类似):

旧版插件应用程序
随着插件 DSL的引入,用户应该没有理由使用应用插件的传统方法。此处记录是为了防止构建作者由于当前工作方式的限制而无法使用插件 DSL。
apply(plugin = "java")apply plugin: 'java'可以使用插件 id应用插件。在上面的例子中,我们使用短名称“java”来应用JavaPlugin。
除了使用插件 ID 之外,还可以通过简单地指定插件的类来应用插件:
apply<JavaPlugin>()apply plugin: JavaPluginJavaPlugin上面示例中的符号指的是JavaPlugin。此类并不严格需要导入,因为该org.gradle.api.plugins包会在所有构建脚本中自动导入(请参阅默认导入)。
此外,在 Kotlin 中而不是在 Java 中,需要附加::class后缀来标识类文字.class。
此外,在 Groovy 中不需要.class像在 Java 中那样通过追加来标识类文字。
使用版本目录
当项目使用版本目录时,应用时可以通过别名引用插件。
我们来看一个简单的版本目录:
[versions]
intellij-plugin = "1.6"
[plugins]
jetbrains-intellij = { id = "org.jetbrains.intellij", version.ref = "intellij-plugin" }然后可以使用以下方法将插件应用于任何构建脚本alias:
plugins {
alias(libs.plugins.jetbrains.intellij)
}|
提示
|
jetbrains-intellij可用作 Gradle 生成的安全访问器:jetbrains.intellij.
|
下一步: 学习如何编写插件>>
编写插件
如果 Gradle 或 Gradle 社区没有提供您的项目所需的特定功能,创建您自己的插件可能是一个解决方案。
此外,如果您发现自己在子项目中重复构建逻辑,并且需要更好的方式来组织它,自定义插件可以提供帮助。
自定义插件
插件是实现该Plugin接口的任何类。下面的例子是最简单的插件,一个“hello world”插件:
import org.gradle.api.Plugin
import org.gradle.api.Project
abstract class SamplePlugin : Plugin<Project> {
override fun apply(project: Project) {
project.tasks.create("SampleTask") {
println("Hello world!")
}
}
}脚本插件
许多插件都是以构建脚本中编码的脚本插件开始的。这提供了一种在构建插件时快速原型化和实验的简单方法。让我们看一个例子:
// Define a task
abstract class CreateFileTask : DefaultTask() { // (1)
@get:Input
abstract val fileText: Property<String> // (2)
@Input
val fileName = "myfile.txt"
@OutputFile
val myFile: File = File(fileName)
@TaskAction
fun action() {
myFile.createNewFile()
myFile.writeText(fileText.get())
}
}
// Define a plugin
abstract class MyPlugin : Plugin<Project> { // (3)
override fun apply(project: Project) {
tasks {
register("createFileTask", CreateFileTask::class) {
group = "from my plugin"
description = "Create myfile.txt in the current directory"
fileText.set("HELLO FROM MY PLUGIN")
}
}
}
}
// Apply the local plugin
apply<MyPlugin>() // (4)-
子类
DefaultTask(). -
在任务中使用惰性配置。
-
扩展
org.gradle.api.Plugin接口。 -
应用脚本插件。
1. 子类DefaultTask()
首先,通过子类化来构建任务DefaultTask()。
abstract class CreateFileTask : DefaultTask() { }这个简单的任务将一个文件添加到我们应用程序的根目录中。
2.使用惰性配置
Gradle 有一个称为惰性配置的概念,它允许任务输入和输出在实际设置之前被引用。这是通过Property类类型完成的。
abstract val fileText: Property<String>这种机制的一个优点是,您可以将一个任务的输出文件链接到另一个任务的输入文件,所有这些都在文件名确定之前进行。该类Property还知道它链接到哪个任务,从而使 Gradle 能够自动添加所需的任务依赖项。
3.扩展org.gradle.api.Plugin接口
接下来,创建一个扩展该接口的新类org.gradle.api.Plugin。
abstract class MyPlugin : Plugin<Project> {
override fun apply() {}
}您可以在apply()方法中添加任务和其他逻辑。
4.应用脚本插件
最后,在构建脚本中应用本地插件。
apply<MyPlugin>()当MyPlugin在构建脚本中应用时,Gradle 会调用fun apply() {}自定义类中定义的方法MyPlugin。
这使得该插件可供应用程序使用。
|
笔记
|
不推荐使用脚本插件。脚本插件提供了一种快速原型构建逻辑的简单方法,然后将其迁移到更永久的解决方案(例如约定插件或二进制插件)。 |
约定插件
约定插件是一种在 Gradle 中封装和重用常见构建逻辑的方法。它们允许您为项目定义一组约定,然后将这些约定应用到其他项目或模块。
上面的示例已被重写为存储在的约定插件buildSrc:
import org.gradle.api.DefaultTask
import org.gradle.api.Plugin
import org.gradle.api.Project
import org.gradle.api.provider.Property
import org.gradle.api.tasks.Input
import org.gradle.api.tasks.OutputFile
import org.gradle.api.tasks.TaskAction
import java.io.File
abstract class CreateFileTask : DefaultTask() {
@get:Input
abstract val fileText: Property<String>
@Input
val fileName = project.rootDir.toString() + "/myfile.txt"
@OutputFile
val myFile: File = File(fileName)
@TaskAction
fun action() {
myFile.createNewFile()
myFile.writeText(fileText.get())
}
}
class MyConventionPlugin : Plugin<Project> {
override fun apply(project: Project) {
project.tasks.register("createFileTask", CreateFileTask::class.java) {
group = "from my plugin"
description = "Create myfile.txt in the current directory"
fileText.set("HELLO FROM MY PLUGIN")
}
}
}可以给插件一个idusinggradlePlugin{}块,以便可以在根中引用它:
gradlePlugin {
plugins {
create("my-convention-plugin") {
id = "com.gradle.plugin.my-convention-plugin"
implementationClass = "com.gradle.plugin.MyConventionPlugin"
}
}
}该gradlePlugin{}块定义了项目正在构建的插件。使用新创建的id,该插件可以相应地应用到其他构建脚本中:
plugins {
application
id("com.gradle.plugin.my-convention-plugin") // Apply the new plugin
}构建构建
使用 Gradle 构建项目
构建 Gradle 项目以优化构建性能非常重要。多项目构建是 Gradle 中的标准。

多项目构建由一个根项目和一个或多个子项目组成。 Gradle 可以在一次执行中构建根项目和任意数量的子项目。
项目地点
多项目构建在 Gradle 视为根路径的目录中包含单个根项目:.。
子项目物理上位于根路径下:./subproject。
子项目有一个 path,它表示该子项目在多项目构建中的位置。大多数情况下,项目路径与其在文件系统中的位置一致。
项目结构在settings.gradle(.kts)文件中创建。设置文件必须存在于根目录中。
简单的多项目构建
让我们看一个基本的多项目构建示例,其中包含一个根项目和一个子项目。
根项目名为basic-multiproject,位于您计算机上的某个位置。从Gradle的角度来看,根目录是顶级目录.。
该项目包含一个名为的子项目./app:
.
├── app
│ ...
│ └── build.gradle.kts
└── settings.gradle.kts.
├── app
│ ...
│ └── build.gradle
└── settings.gradle这是启动任何 Gradle 项目的推荐项目结构。 build init 插件还会生成遵循此结构的骨架项目 - 具有单个子项目的根项目:
该settings.gradle(.kts)文件向 Gradle 描述了项目结构:
rootProject.name = "basic-multiproject"
include("app")rootProject.name = 'basic-multiproject'
include 'app'app在这种情况下,Gradle 将在目录中查找子项目的构建文件./app。
您可以通过运行以下命令查看多项目构建的结构projects:
$ ./gradlew -q projects ------------------------------------------------------------ Root project 'basic-multiproject' ------------------------------------------------------------ Root project 'basic-multiproject' \--- Project ':app' To see a list of the tasks of a project, run gradle <project-path>:tasks For example, try running gradle :app:tasks
在此示例中,app子项目是一个 Java 应用程序,它应用应用程序插件并配置主类。应用程序打印Hello World到控制台:
plugins {
id("application")
}
application {
mainClass = "com.example.Hello"
}plugins {
id 'application'
}
application {
mainClass = 'com.example.Hello'
}package com.example;
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, world!");
}
}run您可以通过从项目根目录中的应用程序插件执行任务来运行应用程序:
$ ./gradlew -q run Hello, world!
添加子项目
在设置文件中,可以使用以下include方法将另一个子项目添加到根项目中:
include("project1", "project2:child1", "project3:child1")include 'project1', 'project2:child1', 'project3:child1'该include方法将项目路径作为参数。假定项目路径等于相对物理文件系统路径。例如,路径services:api默认映射到文件夹./services/api(相对于项目 root .)。
有关如何使用项目路径的更多示例可以在Settings.include(java.lang.String[])的 DSL 文档中找到。
让我们添加另一个子项目,lib调用之前创建的项目。
我们需要做的就是include在根设置文件中添加另一条语句:
rootProject.name = "basic-multiproject"
include("app")
include("lib")rootProject.name = 'basic-multiproject'
include 'app'
include 'lib'lib然后 Gradle 将在目录中查找新子项目的构建文件./lib/:
.
├── app
│ ...
│ └── build.gradle.kts
├── lib
│ ...
│ └── build.gradle.kts
└── settings.gradle.kts.
├── app
│ ...
│ └── build.gradle
├── lib
│ ...
│ └── build.gradle
└── settings.gradle项目描述
为了进一步向 Gradle 描述项目架构,设置文件提供了项目描述符。
您可以随时在设置文件中修改这些描述符。
要访问描述符,您可以:
include("project-a")
println(rootProject.name)
println(project(":project-a").name)include('project-a')
println rootProject.name
println project(':project-a').name使用此描述符,您可以更改项目的名称、项目目录和构建文件:
rootProject.name = "main"
include("project-a")
project(":project-a").projectDir = file("custom/my-project-a")
project(":project-a").buildFileName = "project-a.gradle.kts"rootProject.name = 'main'
include('project-a')
project(':project-a').projectDir = file('custom/my-project-a')
project(':project-a').buildFileName = 'project-a.gradle'有关详细信息,请参阅API 文档中的ProjectDescriptor类。
修改子项目路径
让我们假设一个具有以下结构的项目:
.
├── app
│ ...
│ └── build.gradle.kts
├── subs // Gradle may see this as a subproject
│ └── web // Gradle may see this as a subproject
│ └── my-web-module // Intended subproject
│ ...
│ └── build.gradle.kts
└── settings.gradle.kts.
├── app
│ ...
│ └── build.gradle
├── subs // Gradle may see this as a subproject
│ └── web // Gradle may see this as a subproject
│ └── my-web-module // Intended subproject
│ ...
│ └── build.gradle
└── settings.gradle如果你settings.gradle(.kts)看起来像这样:
include(':subs:web:my-web-module')Gradle 看到一个子项目的逻辑项目名称为 ,:subs:web:my-web-module并且两个(可能是无意的)其他子项目的逻辑名称为:subs和:subs:web。这可能会导致幻像构建目录,特别是在使用allprojects{}或时subproject{}。
为了避免这种情况,您可以使用:
include(':subs:web:my-web-module')
project(':subs:web:my-web-module').projectDir = "subs/web/my-web-module"这样您最终只会得到一个名为 的子项目:subs:web:my-web-module。
或者您可以使用:
include(':my-web-module')
project(':my-web-module').projectDir = "subs/web/my-web-module"这样您最终只会得到一个名为 的子项目:my-web-module。
因此,虽然物理项目布局相同,但逻辑结果却不同。
命名建议
随着项目的发展,命名和一致性变得越来越重要。为了保持您的构建可维护,我们建议如下:
-
保留子项目的默认项目名称:可以在设置文件中配置自定义项目名称。然而,对于开发人员来说,跟踪哪些项目属于哪些文件夹是不必要的额外工作。
-
对所有项目名称使用小写连字符
-:所有字母均为小写,单词之间用破折号 ( ) 字符分隔。 -
在设置文件中定义根项目名称:
rootProject.name有效地为构建分配一个名称,用于构建扫描等报告中。如果未设置根项目名称,则该名称将是容器目录名称,这可能不稳定(即,您可以在任何目录中查看您的项目)。如果未设置根项目名称并检出到文件系统的根(例如,/或C:\),则该名称将随机生成。
声明子项目之间的依赖关系
如果一个子项目依赖于另一个子项目怎么办?如果一个项目需要另一个项目生成的工件怎么办?

这是多项目构建的常见用例。 Gradle为此提供了项目依赖项。
取决于另一个项目
让我们探索具有以下布局的理论多项目构建:
.
├── api
│ ├── src
│ │ └──...
│ └── build.gradle.kts
├── services
│ └── person-service
│ ├── src
│ │ └──...
│ └── build.gradle.kts
├── shared
│ ├── src
│ │ └──...
│ └── build.gradle.kts
└── settings.gradle.kts.
├── api
│ ├── src
│ │ └──...
│ └── build.gradle
├── services
│ └── person-service
│ ├── src
│ │ └──...
│ └── build.gradle
├── shared
│ ├── src
│ │ └──...
│ └── build.gradle
└── settings.gradle在此示例中,有三个子项目,分别称为shared、api和person-service:
-
该
person-service子项目依赖于其他两个子项目,shared和api。 -
子项目
api取决于shared子项目。
我们使用:分隔符来定义项目路径,例如services:person-service或:shared。有关定义项目路径的更多信息,请参阅Settings.include(java.lang.String[])的 DSL 文档。
rootProject.name = "dependencies-java"
include("api", "shared", "services:person-service")plugins {
id("java")
}
repositories {
mavenCentral()
}
dependencies {
testImplementation("junit:junit:4.13")
}plugins {
id("java")
}
repositories {
mavenCentral()
}
dependencies {
testImplementation("junit:junit:4.13")
implementation(project(":shared"))
}plugins {
id("java")
}
repositories {
mavenCentral()
}
dependencies {
testImplementation("junit:junit:4.13")
implementation(project(":shared"))
implementation(project(":api"))
}rootProject.name = 'basic-dependencies'
include 'api', 'shared', 'services:person-service'plugins {
id 'java'
}
repositories {
mavenCentral()
}
dependencies {
testImplementation "junit:junit:4.13"
}plugins {
id 'java'
}
repositories {
mavenCentral()
}
dependencies {
testImplementation "junit:junit:4.13"
implementation project(':shared')
}plugins {
id 'java'
}
repositories {
mavenCentral()
}
dependencies {
testImplementation "junit:junit:4.13"
implementation project(':shared')
implementation project(':api')
}项目依赖性会影响执行顺序。它会导致首先构建另一个项目,并将输出与另一个项目的类添加到类路径中。它还将其他项目的依赖项添加到类路径中。
如果执行./gradlew :api:compile,则首先shared构建项目,然后api构建项目。
取决于另一个项目生成的工件
有时,您可能希望依赖另一个项目中特定任务的输出,而不是整个项目。然而,不鼓励显式声明从一个项目到另一个项目的任务依赖关系,因为它会引入任务之间不必要的耦合。
对依赖项进行建模的推荐方法是生成输出并将其标记为“传出”工件,其中一个项目中的任务依赖于另一个项目的输出。 Gradle 的依赖管理引擎允许您在项目之间共享任意工件并按需构建它们。
在子项目之间共享构建逻辑
多项目构建中的子项目通常共享一些共同的依赖关系。

Gradle 提供了一个特殊的目录来存储可自动应用于子项目的共享构建逻辑,而不是在每个子项目构建脚本中复制和粘贴相同的 Java 版本和库。
共享逻辑buildSrc
buildSrc是 Gradle 识别和受保护的目录,它具有一些优点:
-
可重用的构建逻辑:
buildSrc允许您以结构化方式组织和集中您的自定义构建逻辑、任务和插件。在 buildSrc 中编写的代码可以在您的项目中重复使用,从而更轻松地维护和共享常见的构建功能。 -
与主构建的隔离:
放置的代码
buildSrc与项目的其他构建脚本隔离。这有助于保持主要构建脚本更清晰并更专注于特定于项目的配置。 -
自动编译和类路径:
该目录的内容
buildSrc会自动编译并包含在主构建的类路径中。这意味着 buildSrc 中定义的类和插件可以直接在项目的构建脚本中使用,无需任何额外的配置。 -
易于测试:
由于
buildSrc是单独的构建,因此它可以轻松测试您的自定义构建逻辑。您可以为构建代码编写测试,确保其行为符合预期。 -
Gradle 插件开发:
如果您正在为您的项目开发自定义 Gradle 插件,那么
buildSrc这是一个存放插件代码的方便位置。这使得插件可以在您的项目中轻松访问。
该buildSrc目录被视为包含的构建。
对于多项目构建,只能有一个buildSrc目录,并且必须位于项目根目录中。
|
笔记
|
使用它的缺点buildSrc是,对其进行任何更改都会使项目中的每个任务无效并需要重新运行。
|
buildSrc使用适用于 Java、Groovy 和 Kotlin 项目的相同源代码约定。它还提供对 Gradle API 的直接访问。
一个典型的项目包括buildSrc以下布局:
.
├── buildSrc
│ ├── src
│ │ └──main
│ │ └──kotlin
│ │ └──MyCustomTask.kt // (1)
│ ├── shared.gradle.kts // (2)
│ └── build.gradle.kts
├── api
│ ├── src
│ │ └──...
│ └── build.gradle.kts // (3)
├── services
│ └── person-service
│ ├── src
│ │ └──...
│ └── build.gradle.kts // (3)
├── shared
│ ├── src
│ │ └──...
│ └── build.gradle.kts
└── settings.gradle.kts-
Create the
MyCustomTasktask. -
A shared build script.
-
Uses the
MyCustomTasktask and shared build script.
.
├── buildSrc
│ ├── src
│ │ └──main
│ │ └──kotlin
│ │ └──MyCustomTask.groovy // (1)
│ ├── shared.gradle // (2)
│ └── build.gradle
├── api
│ ├── src
│ │ └──...
│ └── build.gradle // (3)
├── services
│ └── person-service
│ ├── src
│ │ └──...
│ └── build.gradle // (3)
├── shared
│ ├── src
│ │ └──...
│ └── build.gradle
└── settings.gradle-
Create the
MyCustomTasktask. -
A shared build script.
-
Uses the
MyCustomTasktask and shared build script.
在 中,创建了buildSrc构建脚本。shared.gradle(.kts)它包含多个子项目共有的依赖项和其他构建信息:
repositories {
mavenCentral()
}
dependencies {
implementation("org.slf4j:slf4j-api:1.7.32")
}repositories {
mavenCentral()
}
dependencies {
implementation 'org.slf4j:slf4j-api:1.7.32'
}在 中buildSrc,MyCustomTask还创建了 。它是一个辅助任务,用作多个子项目的构建逻辑的一部分:
import org.gradle.api.DefaultTask
import org.gradle.api.tasks.TaskAction
open class MyCustomTask : DefaultTask() {
@TaskAction
fun calculateSum() {
// Custom logic to calculate the sum of two numbers
val num1 = 5
val num2 = 7
val sum = num1 + num2
// Print the result
println("Sum: $sum")
}
}import org.gradle.api.DefaultTask
import org.gradle.api.tasks.TaskAction
class MyCustomTask extends DefaultTask {
@TaskAction
void calculateSum() {
// Custom logic to calculate the sum of two numbers
int num1 = 5
int num2 = 7
int sum = num1 + num2
// Print the result
println "Sum: $sum"
}
}该任务在和项目MyCustomTask的构建脚本中使用。该任务自动可用,因为它是.apisharedbuildSrc
该shared.build(.kts)文件也适用:
// Apply any other configurations specific to your project
// Use the build script defined in buildSrc
apply(from = rootProject.file("buildSrc/shared.gradle"))
// Use the custom task defined in buildSrc
tasks.register<MyCustomTask>("myCustomTask")// Apply any other configurations specific to your project
// Use the build script defined in buildSrc
apply from: rootProject.file('buildSrc/shared.gradle')
// Use the custom task defined in buildSrc
tasks.register('myCustomTask', MyCustomTask)使用约定插件共享逻辑
Gradle 组织构建逻辑的推荐方法是使用其插件系统。
我们可以编写一个插件来封装一个项目中多个子项目通用的构建逻辑。这种插件称为约定插件。
虽然编写插件超出了本节的范围,但构建 Gradle 项目的推荐方法是将通用构建逻辑放入位于buildSrc.
让我们看一个示例项目:
.
├── buildSrc
│ ├── src
│ │ └──main
│ │ └──kotlin
│ │ └──myproject.java-conventions.gradle // (1)
│ └── build.gradle.kts
├── api
│ ├── src
│ │ └──...
│ └── build.gradle.kts // (2)
├── services
│ └── person-service
│ ├── src
│ │ └──...
│ └── build.gradle.kts // (2)
├── shared
│ ├── src
│ │ └──...
│ └── build.gradle.kts // (2)
└── settings.gradle.kts-
Create the
myproject.java-conventionsconvention plugin. -
Applies the
myproject.java-conventionsconvention plugin.
.
├── buildSrc
│ ├── src
│ │ └──main
│ │ └──kotlin
│ │ └──myproject.java-conventions.gradle.kts // (1)
│ └── build.gradle
├── api
│ ├── src
│ │ └──...
│ └── build.gradle // (2)
├── services
│ └── person-service
│ ├── src
│ │ └──...
│ └── build.gradle // (2)
├── shared
│ ├── src
│ │ └──...
│ └── build.gradle // (2)
└── settings.gradle-
Create the
myproject.java-conventionsconvention plugin. -
Applies the
myproject.java-conventionsconvention plugin.
该构建包含三个子项目:
rootProject.name = "dependencies-java"
include("api", "shared", "services:person-service")rootProject.name = 'dependencies-java'
include 'api', 'shared', 'services:person-service'目录中创建的约定插件源码buildSrc如下:
plugins {
id("java")
}
group = "com.example"
version = "1.0"
repositories {
mavenCentral()
}
dependencies {
testImplementation("junit:junit:4.13")
}plugins {
id 'java'
}
group = 'com.example'
version = '1.0'
repositories {
mavenCentral()
}
dependencies {
testImplementation "junit:junit:4.13"
}约定插件应用于api、shared和person-service子项目:
plugins {
id("myproject.java-conventions")
}
dependencies {
implementation(project(":shared"))
}plugins {
id("myproject.java-conventions")
}plugins {
id("myproject.java-conventions")
}
dependencies {
implementation(project(":shared"))
implementation(project(":api"))
}plugins {
id 'myproject.java-conventions'
}
dependencies {
implementation project(':shared')
}plugins {
id 'myproject.java-conventions'
}plugins {
id 'myproject.java-conventions'
}
dependencies {
implementation project(':shared')
implementation project(':api')
}不要使用跨项目配置
在子项目之间共享构建逻辑的一种不正确的方法是通过和DSL 构造进行跨项目配置。subprojects {}allprojects {}
|
提示
|
避免使用subprojects {}和allprojects {}。
|
通过交叉配置,构建逻辑可以注入到子项目中,这在查看其构建脚本时并不明显。
从长远来看,交叉配置通常会变得更加复杂并成为一种负担。交叉配置还可能在项目之间引入配置时耦合,这可能会阻止按需配置等优化正常工作。
复合构建
复合构建是包含其他构建的构建。

复合构建类似于 Gradle 多项目构建,只不过不是包含,而是包含subprojects整个。builds
复合构建允许您:
-
组合通常独立开发的构建,例如,在应用程序使用的库中尝试修复错误时。
-
将大型多项目构建分解为更小、更独立的块,这些块可以根据需要独立或一起工作。
包含在复合构建中的构建称为包含构建。包含的构建不与复合构建或其他包含的构建共享任何配置。每个包含的构建都是独立配置和执行的。
定义复合构建
以下示例演示了如何将两个通常单独开发的 Gradle 构建组合成一个复合构建。
my-composite
├── gradle
├── gradlew
├── settings.gradle.kts
├── build.gradle.kts
├── my-app
│ ├── settings.gradle.kts
│ └── app
│ ├── build.gradle.kts
│ └── src/main/java/org/sample/my-app/Main.java
└── my-utils
├── settings.gradle.kts
├── number-utils
│ ├── build.gradle.kts
│ └── src/main/java/org/sample/numberutils/Numbers.java
└── string-utils
├── build.gradle.kts
└── src/main/java/org/sample/stringutils/Strings.java多my-utils项目构建生成两个 Java 库,number-utils以及string-utils.构建my-app使用这些库中的函数生成可执行文件。
构建my-app不直接依赖于my-utils.相反,它声明对以下生成的库的二进制依赖关系my-utils:
plugins {
id("application")
}
application {
mainClass = "org.sample.myapp.Main"
}
dependencies {
implementation("org.sample:number-utils:1.0")
implementation("org.sample:string-utils:1.0")
}plugins {
id 'application'
}
application {
mainClass = 'org.sample.myapp.Main'
}
dependencies {
implementation 'org.sample:number-utils:1.0'
implementation 'org.sample:string-utils:1.0'
}通过定义复合构建--include-build
命令--include-build行参数将执行的构建转换为复合构建,将包含的构建中的依赖项替换为执行的构建。
./gradlew run --include-build ../my-utils例如, run from的输出my-app:
$ ./gradlew --include-build ../my-utils run link:http://gradle.github.net.cn/8.7/samples/build-organization/composite-builds/basic/tests/basicCli.out[role=include]
通过设置文件定义复合构建
通过使用Settings.includeBuild(java.lang.Object)声明文件中包含的构建,可以使上述安排持久化settings.gradle(.kts)。
设置文件可用于同时添加子项目和包含的构建。
包含的构建按位置添加:
includeBuild("my-utils")在示例中,settings.gradle(.kts) 文件组合了其他单独的构建:
rootProject.name = "my-composite"
includeBuild("my-app")
includeBuild("my-utils")rootProject.name = 'my-composite'
includeBuild 'my-app'
includeBuild 'my-utils'要执行构建run中的任务,请运行。my-appmy-composite./gradlew my-app:app:run
您可以选择定义一个依赖于的run任务,以便您可以执行:my-compositemy-app:app:run./gradlew run
tasks.register("run") {
dependsOn(gradle.includedBuild("my-app").task(":app:run"))
}tasks.register('run') {
dependsOn gradle.includedBuild('my-app').task(':app:run')
}包括定义 Gradle 插件的构建
包含构建的一个特殊情况是定义 Gradle 插件的构建。
应使用设置文件块includeBuild内的语句包含这些构建。pluginManagement {}
使用这种机制,包含的构建还可以提供一个可以应用于设置文件本身的设置插件:
pluginManagement {
includeBuild("../url-verifier-plugin")
}pluginManagement {
includeBuild '../url-verifier-plugin'
}对包含的构建的限制
大多数构建都可以包含在组合中,包括其他组合构建。有一些限制。
在常规构建中,Gradle 确保每个项目都有唯一的项目路径。它使项目可识别和可寻址,而不会发生冲突。
在复合构建中,Gradle 向包含的构建中的每个项目添加额外的资格,以避免项目路径冲突。在复合构建中标识项目的完整路径称为构建树路径。它由包含的构建的构建路径和项目的项目路径组成。
默认情况下,构建路径和项目路径源自磁盘上的目录名称和结构。由于包含的构建可以位于磁盘上的任何位置,因此它们的构建路径由包含目录的名称确定。这有时会导致冲突。
总而言之,包含的版本必须满足以下要求:
-
每个包含的构建都必须具有唯一的构建路径。
-
每个包含的构建路径不得与主构建的任何项目路径冲突。
这些条件保证了即使在复合构建中也可以唯一地标识每个项目。
如果出现冲突,解决它们的方法是更改包含的构建的构建名称:
includeBuild("some-included-build") {
name = "other-name"
}|
笔记
|
当一个复合构建包含在另一个复合构建中时,两个构建具有相同的父代。换句话说,嵌套的复合构建结构被展平了。 |
与复合构建交互
与复合构建的交互通常类似于常规的多项目构建。可以执行任务、运行测试并将构建导入到 IDE 中。
执行任务
包含的构建中的任务可以从命令行或 IDE 执行,其方式与常规多项目构建中的任务相同。执行任务将导致执行任务依赖项,以及从其他包含的构建构建依赖项工件所需的那些任务。
您可以使用完全限定路径(例如:included-build-name:project-name:taskName.项目和任务名称可以缩写。
$ ./gradlew :included-build:subproject-a:compileJava > Task :included-build:subproject-a:compileJava $ ./gradlew :i-b:sA:cJ > Task :included-build:subproject-a:compileJava
要从命令行中排除任务,您需要提供该任务的完全限定路径。
|
笔记
|
包含的构建任务会自动执行以生成所需的依赖项工件,或者包含的构建可以声明对包含的构建中的任务的依赖关系。 |
导入IDE
复合构建最有用的功能之一是 IDE 集成。
导入复合构建允许来自单独 Gradle 构建的源轻松地一起开发。对于每个包含的构建,每个子项目都作为 IntelliJ IDEA 模块或 Eclipse 项目包含在内。配置源依赖项,提供跨构建导航和重构。
声明由包含的构建替换的依赖项
默认情况下,Gradle 将配置每个包含的构建以确定它可以提供的依赖项。执行此操作的算法很简单。 Gradle 将检查包含的构建中项目的组和名称,并替换任何外部依赖项匹配的项目依赖项${project.group}:${project.name}。
|
笔记
|
默认情况下,不会为主构建注册替换。 要使主构建的(子)项目可通过 寻址 |
在某些情况下,Gradle 确定的默认替换是不够的,或者必须针对特定组合进行更正。对于这些情况,可以明确声明所包含构建的替换。
例如,名为 的单项目构建anonymous-library会生成一个 Java 实用程序库,但不会声明 group 属性的值:
plugins {
java
}plugins {
id 'java'
}当此构建包含在组合中时,它将尝试替换依赖模块undefined:anonymous-library(undefined是 的默认值project.group,并且anonymous-library是根项目名称)。显然,这在复合构建中没有用。
要在复合构建中使用未发布的库,您可以显式声明它提供的替换:
includeBuild("anonymous-library") {
dependencySubstitution {
substitute(module("org.sample:number-utils")).using(project(":"))
}
}includeBuild('anonymous-library') {
dependencySubstitution {
substitute module('org.sample:number-utils') using project(':')
}
}通过此配置,my-app复合构建将用org.sample:number-utils对 的根项目的依赖项替换对 的任何依赖项anonymous-library。
停用配置的包含构建替换
如果您需要解析也可作为包含的构建的一部分提供的模块的已发布版本,则可以在已解析的配置的ResolutionStrategy上停用包含的构建替换规则。这是必要的,因为规则在构建中全局应用,并且默认情况下,Gradle 在解析过程中不考虑已发布的版本。
例如,我们创建一个单独的publishedRuntimeClasspath配置,该配置被解析为也存在于本地构建之一中的模块的已发布版本。这是通过停用全局依赖替换规则来完成的:
configurations.create("publishedRuntimeClasspath") {
resolutionStrategy.useGlobalDependencySubstitutionRules = false
extendsFrom(configurations.runtimeClasspath.get())
isCanBeConsumed = false
attributes.attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage.JAVA_RUNTIME))
}configurations.create('publishedRuntimeClasspath') {
resolutionStrategy.useGlobalDependencySubstitutionRules = false
extendsFrom(configurations.runtimeClasspath)
canBeConsumed = false
attributes.attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, Usage.JAVA_RUNTIME))
}一个用例是比较已发布的 JAR 文件和本地构建的 JAR 文件。
必须声明包含的构建替换的情况
许多构建将作为包含的构建自动运行,无需声明替换。以下是一些需要声明替换的常见情况:
-
当该
archivesBaseName属性用于设置已发布工件的名称时。 -
default当发布以外的配置时。 -
当
MavenPom.addFilter()用于发布与项目名称不匹配的工件时。 -
当使用
maven-publish或ivy-publish插件进行发布且发布坐标不匹配时${project.group}:${project.name}。
复合构建替换不起作用的情况
某些构建在包含在组合中时将无法正常运行,即使显式声明了依赖项替换也是如此。此限制是因为替换的项目依赖项将始终指向default目标项目的配置。每当为项目的默认配置指定的工件和依赖项与发布到存储库的内容不匹配时,复合构建可能会表现出不同的行为。
以下是发布的模块元数据可能与项目默认配置不同的一些情况:
-
default当发布以外的配置时。 -
当使用
maven-publish或ivy-publish插件时。 -
当
POM或ivy.xml文件作为发布的一部分进行调整时。
当包含在复合构建中时,使用这些功能的构建无法正常运行。
取决于包含的构建中的任务
虽然包含的构建彼此隔离并且无法声明直接依赖关系,但复合构建可以声明其包含的构建的任务依赖关系。使用Gradle.getIncludedBuilds()或Gradle.includedBuild(java.lang.String)访问包含的构建,并通过IncludedBuild.task(java.lang.String)方法获取任务引用。
使用这些 API,可以声明对特定包含的构建中的任务的依赖关系:
tasks.register("run") {
dependsOn(gradle.includedBuild("my-app").task(":app:run"))
}tasks.register('run') {
dependsOn gradle.includedBuild('my-app').task(':app:run')
}或者,您可以在部分或全部包含的构建中声明对具有特定路径的任务的依赖关系:
tasks.register("publishDeps") {
dependsOn(gradle.includedBuilds.map { it.task(":publishMavenPublicationToMavenRepository") })
}tasks.register('publishDeps') {
dependsOn gradle.includedBuilds*.task(':publishMavenPublicationToMavenRepository')
}复合构建的局限性
当前实施的局限性包括:
-
不支持包含不反映项目默认配置的发布的构建。
请参阅复合构建不起作用的情况。 -
如果多个复合构建包含相同的构建,则并行运行时多个复合构建可能会发生冲突。
Gradle 不会在 Gradle 调用之间共享共享复合构建的项目锁,以防止并发执行。
按需配置
按需配置尝试仅为所请求的任务配置相关项目,即,它仅评估参与构建的项目的构建脚本文件。这样,可以减少大型多项目构建的配置时间。
按需配置功能正在孵化中,因此仅保证某些构建能够正常工作。该功能非常适合解耦的多项目构建。
按需配置模式下,项目配置如下:
-
根项目始终已配置。
-
执行构建的目录中的项目也已配置,但仅限于在没有任何任务的情况下执行 Gradle 时。
这样,当按需配置项目时,默认任务就会正确运行。 -
支持标准项目依赖,并配置相关项目。
如果项目 A 对项目 B 有编译依赖性,则构建 A 会导致两个项目的配置。 -
支持通过任务路径声明的任务依赖项,并导致配置相关项目。
例子:someTask.dependsOn(":some-other-project:someOtherTask") -
从命令行(或工具 API)通过任务路径请求的任务会导致相关项目被配置。
例如,构建project-a:project-b:someTask会导致project-b.
使能够configuration-on-demand
--configure-on-demand您可以使用该标志或添加org.gradle.configureondemand=true到文件来启用按需配置gradle.properties。
要在每次构建运行时按需配置,请参阅Gradle 属性。
要根据给定构建的需要进行配置,请参阅命令行面向性能的选项。
解耦项目
当项目仅通过声明的依赖项和任务依赖项进行交互时,它们被认为是解耦的。对另一个项目对象的任何直接修改或读取都会在项目之间创建耦合。使用“按需配置”时,配置期间的耦合可能会导致有缺陷的构建结果,而执行期间的耦合可能会影响并行执行。
耦合的一种常见来源是配置注入,例如使用allprojects{}或subprojects{}在构建脚本中。
为避免耦合问题,建议:
-
避免引用其他子项目的构建脚本,并且更喜欢从根项目进行交叉配置。
-
避免在执行过程中动态更改其他项目的配置。
随着 Gradle 的发展,它的目标是提供利用解耦项目的功能,同时为配置注入等常见用例提供解决方案,而无需引入耦合。
开发任务
了解任务
任务代表构建执行的某些独立工作单元,例如编译类、创建 JAR、生成 Javadoc 或将存档发布到存储库。

列出任务
项目中的所有可用任务都来自 Gradle 插件和构建脚本。
您可以通过在终端中运行以下命令来列出项目中的所有可用任务:
$ ./gradlew tasks让我们以一个非常基本的 Gradle 项目为例。该项目具有以下结构:
gradle-project
├── app
│ ├── build.gradle.kts // empty file - no build logic
│ └── ... // some java code
├── settings.gradle.kts // includes app subproject
├── gradle
│ └── ...
├── gradlew
└── gradlew.batgradle-project
├── app
│ ├── build.gradle // empty file - no build logic
│ └── ... // some java code
├── settings.gradle // includes app subproject
├── gradle
│ └── ...
├── gradlew
└── gradlew.bat设置文件包含以下内容:
rootProject.name = "gradle-project"
include("app")rootProject.name = 'gradle-project'
include('app')目前,app子项目的构建文件为空。
要查看子项目中可用的任务app,请运行./gradlew :app:tasks:
$ ./gradlew :app:tasks
> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
kotlinDslAccessorsReport - Prints the Kotlin code for accessing the currently available project extensions and conventions.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.我们观察到,目前只有少量的帮助任务可用。这是因为 Gradle 的核心仅提供分析构建的任务。其他任务,例如构建项目或编译代码的任务,是通过插件添加的。
让我们通过将Gradle 核心base插件添加到app构建脚本来探索这一点:
plugins {
id("base")
}plugins {
id('base')
}该base插件添加了中心生命周期任务。现在,当我们运行时./gradlew app:tasks,我们可以看到assemble和build任务可用:
$ ./gradlew :app:tasks
> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
clean - Deletes the build directory.
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.
Verification tasks
------------------
check - Runs all checks.
任务组和描述
任务组和描述用于组织和描述任务。
- 团体
-
任务组用于对任务进行分类。当您运行时
./gradlew tasks,任务会在各自的组下列出,从而更容易理解它们的目的以及与其他任务的关系。组是使用该group属性设置的。 - 描述
-
描述提供任务用途的简要说明。当您运行时
./gradlew tasks,每个任务旁边都会显示说明,帮助您了解其目的以及如何使用它。描述是使用description属性设置的。
让我们以一个基本的 Java 应用程序为例。该构建包含一个名为 的子项目app。
app让我们列出目前可用的任务:
$ ./gradlew :app:tasks
> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application.
Build tasks
-----------
assemble - Assembles the outputs of this project.在这里,任务是具有描述的组:run的一部分。在代码中,它看起来像这样:ApplicationRuns this project as a JVM application
tasks.register("run") {
group = "Application"
description = "Runs this project as a JVM application."
}tasks.register("run") {
group = "Application"
description = "Runs this project as a JVM application."
}私人和隐藏任务
Gradle 不支持将任务标记为private。
:tasks但是,只有在task.group设置了该值或者没有其他任务依赖于它时,任务才会在运行时显示。
例如,以下任务在运行时不会出现,./gradlew :app:tasks因为它没有组;它被称为隐藏任务:
tasks.register("helloTask") {
println("Hello")
}tasks.register("helloTask") {
println("Hello")
}虽然helloTask没有列出,但仍然可以通过Gradle执行:
$ ./gradlew :app:tasks
> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.让我们向同一任务添加一个组:
tasks.register("helloTask") {
group = "Other"
description = "Hello task"
println("Hello")
}tasks.register("helloTask") {
group = "Other"
description = "Hello task"
println("Hello")
}现在组已添加,任务可见:
$ ./gradlew :app:tasks
> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.
Other tasks
-----------
helloTask - Hello task反之,./gradlew tasks --all将显示所有任务;列出了隐藏和可见的任务。
任务分组
如果您想自定义在列出时向用户显示哪些任务,您可以对任务进行分组并设置每个组的可见性。
|
笔记
|
请记住,即使您隐藏任务,它们仍然可用,并且 Gradle 仍然可以运行它们。 |
init让我们从 Gradle为具有多个子项目的 Java 应用程序构建的示例开始。项目结构如下:
gradle-project
├── app
│ ├── build.gradle.kts
│ └── src // some java code
│ └── ...
├── utilities
│ ├── build.gradle.kts
│ └── src // some java code
│ └── ...
├── list
│ ├── build.gradle.kts
│ └── src // some java code
│ └── ...
├── buildSrc
│ ├── build.gradle.kts
│ ├── settings.gradle.kts
│ └── src // common build logic
│ └── ...
├── settings.gradle.kts
├── gradle
├── gradlew
└── gradlew.batgradle-project
├── app
│ ├── build.gradle
│ └── src // some java code
│ └── ...
├── utilities
│ ├── build.gradle
│ └── src // some java code
│ └── ...
├── list
│ ├── build.gradle
│ └── src // some java code
│ └── ...
├── buildSrc
│ ├── build.gradle
│ ├── settings.gradle
│ └── src // common build logic
│ └── ...
├── settings.gradle
├── gradle
├── gradlew
└── gradlew.bat运行app:tasks以查看app子项目中的可用任务:
$ ./gradlew :app:tasks
> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
buildDependents - Assembles and tests this project and all projects that depend on it.
buildNeeded - Assembles and tests this project and all projects it depends on.
classes - Assembles main classes.
clean - Deletes the build directory.
jar - Assembles a jar archive containing the classes of the 'main' feature.
testClasses - Assembles test classes.
Distribution tasks
------------------
assembleDist - Assembles the main distributions
distTar - Bundles the project as a distribution.
distZip - Bundles the project as a distribution.
installDist - Installs the project as a distribution as-is.
Documentation tasks
-------------------
javadoc - Generates Javadoc API documentation for the 'main' feature.
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
kotlinDslAccessorsReport - Prints the Kotlin code for accessing the currently available project extensions and conventions.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.
Verification tasks
------------------
check - Runs all checks.
test - Runs the test suite.如果我们查看可用任务列表,即使对于标准 Java 项目,也会发现它非常广泛。使用构建的开发人员很少直接需要其中许多任务。
我们可以配置:tasks任务并将任务限制为特定组显示。
让我们创建自己的组,以便通过更新构建脚本默认隐藏所有任务app:
val myBuildGroup = "my app build" // Create a group name
tasks.register<TaskReportTask>("tasksAll") { // Register the tasksAll task
group = myBuildGroup
description = "Show additional tasks."
setShowDetail(true)
}
tasks.named<TaskReportTask>("tasks") { // Move all existing tasks to the group
displayGroup = myBuildGroup
}def myBuildGroup = "my app build" // Create a group name
tasks.register(TaskReportTask, "tasksAll") { // Register the tasksAll task
group = myBuildGroup
description = "Show additional tasks."
setShowDetail(true)
}
tasks.named(TaskReportTask, "tasks") { // Move all existing tasks to the group
displayGroup = myBuildGroup
}现在,当我们列出 中可用的任务时app,列表会更短:
$ ./gradlew :app:tasks
> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
My app build tasks
------------------
tasksAll - Show additional tasks.任务类别
Gradle 区分两类任务:
-
生命周期任务
-
可操作的任务
生命周期任务定义您可以调用的目标,例如:build您的项目。生命周期任务不向 Gradle 提供操作。他们必须连接到可操作的任务。 Gradlebase插件仅添加生命周期任务。
可操作任务定义 Gradle 要执行的操作,例如:compileJava编译项目的 Java 代码。操作包括创建 JAR、压缩文件、发布档案等等。像java-library插件这样的插件添加了可操作的任务。
让我们更新上一个示例的构建脚本,该脚本当前是一个空文件,以便我们的app子项目是一个 Java 库:
plugins {
id("java-library")
}plugins {
id('java-library')
}我们再次列出可用的任务,看看有哪些新任务可用:
$ ./gradlew :app:tasks
> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
buildDependents - Assembles and tests this project and all projects that depend on it.
buildNeeded - Assembles and tests this project and all projects it depends on.
classes - Assembles main classes.
clean - Deletes the build directory.
jar - Assembles a jar archive containing the classes of the 'main' feature.
testClasses - Assembles test classes.
Documentation tasks
-------------------
javadoc - Generates Javadoc API documentation for the 'main' feature.
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.
Verification tasks
------------------
check - Runs all checks.
test - Runs the test suite.我们看到有许多新任务可用,例如jar和testClasses。
此外,该java-library插件还将可操作的任务连接到生命周期任务。如果我们调用该:build任务,我们可以看到包括该任务在内的多个任务已被执行:app:compileJava。
$./gradlew :app:build
> Task :app:compileJava
> Task :app:processResources NO-SOURCE
> Task :app:classes
> Task :app:jar
> Task :app:assemble
> Task :app:compileTestJava
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses
> Task :app:test
> Task :app:check
> Task :app:build可操作:compileJava任务连接到生命周期:build任务。
增量任务
Gradle 任务的一个关键特征是其增量性质。
Gradle 可以重用之前构建的结果。因此,如果我们之前已经构建了项目并且仅进行了较小的更改,则重新运行:build将不需要 Gradle 执行大量工作。
例如,如果我们只修改项目中的测试代码,而生产代码保持不变,则执行构建只会重新编译测试代码。 Gradle 将生产代码的任务标记为UP-TO-DATE,表示自上次成功构建以来它保持不变:
$./gradlew :app:build
lkassovic@MacBook-Pro temp1 % ./gradlew :app:build
> Task :app:compileJava UP-TO-DATE
> Task :app:processResources NO-SOURCE
> Task :app:classes UP-TO-DATE
> Task :app:jar UP-TO-DATE
> Task :app:assemble UP-TO-DATE
> Task :app:compileTestJava
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses
> Task :app:test
> Task :app:check UP-TO-DATE
> Task :app:build UP-TO-DATE缓存任务
Gradle 可以使用构建缓存重用过go构建的结果。
--build-cache 要启用此功能,请使用命令行org.gradle.caching=true参数或在文件中设置来激活构建缓存gradle.properties。
此优化有可能显着加速您的构建:
$./gradlew :app:clean :app:build --build-cache
> Task :app:compileJava FROM-CACHE
> Task :app:processResources NO-SOURCE
> Task :app:classes UP-TO-DATE
> Task :app:jar
> Task :app:assemble
> Task :app:compileTestJava FROM-CACHE
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses UP-TO-DATE
> Task :app:test FROM-CACHE
> Task :app:check UP-TO-DATE
> Task :app:build当 Gradle 可以从缓存中获取任务的输出时,它会使用 来标记该任务FROM-CACHE。
如果您定期在分支之间切换,构建缓存会很方便。 Gradle 支持本地和远程构建缓存。
开发任务
开发 Gradle 任务时,您有两种选择:
-
使用现有的 Gradle 任务类型,例如
Zip、Copy或Delete -
创建您自己的 Gradle 任务类型,例如
MyResolveTask或CustomTaskUsingToolchains。
任务类型只是 GradleTask类的子类。
对于 Gradle 任务,需要考虑三种状态:
-
注册任务 - 在构建逻辑中使用任务(由您实现或由 Gradle 提供)。
-
配置任务 - 定义已注册任务的输入和输出。
-
实现任务 - 创建自定义任务类(即自定义类类型)。
注册通常是用该register()方法完成的。
配置任务通常使用该named()方法完成。
实现任务通常是通过扩展 Gradle 的DefaultTask类来完成的:
tasks.register<Copy>("myCopy") // (1)
tasks.named<Copy>("myCopy") { // (2)
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}
abstract class MyCopyTask : DefaultTask() { // (3)
@TaskAction
fun copyFiles() {
val sourceDir = File("sourceDir")
val destinationDir = File("destinationDir")
sourceDir.listFiles()?.forEach { file ->
if (file.isFile && file.extension == "txt") {
file.copyTo(File(destinationDir, file.name))
}
}
}
}-
Register the
myCopytask of typeCopyto let Gradle know we intend to use it in our build logic. -
Configure the registered
myCopytask with the inputs and outputs it needs according to its API. -
Implement a custom task type called
MyCopyTaskwhich extendsDefaultTaskand defines thecopyFilestask action.
tasks.register(Copy, "myCopy") // (1)
tasks.named(Copy, "myCopy") { // (2)
from "resources"
into "target"
include "**/*.txt", "**/*.xml", "**/*.properties"
}
abstract class MyCopyTask extends DefaultTask { // (3)
@TaskAction
void copyFiles() {
fileTree('sourceDir').matching {
include '**/*.txt'
}.forEach { file ->
file.copyTo(file.path.replace('sourceDir', 'destinationDir'))
}
}
}-
Register the
myCopytask of typeCopyto let Gradle know we intend to use it in our build logic. -
Configure the registered
myCopytask with the inputs and outputs it needs according to its API. -
Implement a custom task type called
MyCopyTaskwhich extendsDefaultTaskand defines thecopyFilestask action.
1. 注册任务
您可以通过在构建脚本或插件中注册任务来定义 Gradle 要执行的操作。
任务是使用任务名称字符串定义的:
tasks.register("hello") {
doLast {
println("hello")
}
}tasks.register('hello') {
doLast {
println 'hello'
}
}在上面的示例中,任务被添加到TasksCollectionusingregister()中的方法中TaskContainer。
2. 配置任务
必须配置 Gradle 任务才能成功完成其操作。如果任务需要压缩文件,则必须配置文件名和位置。您可以参考Gradle 任务的APIZip以了解如何正确配置它。
我们Copy以 Gradle 提供的任务为例。我们首先在构建脚本中注册一个名为myCopyof 类型的任务:Copy
tasks.register<Copy>("myCopy")tasks.register('myCopy', Copy)这会注册一个没有默认行为的复制任务。由于任务的类型是CopyGradle 支持的任务类型,因此可以使用其API进行配置。
以下示例展示了实现相同配置的几种方法:
1、使用named()方法:
用于named()配置在其他地方注册的现有任务:
tasks.named<Copy>("myCopy") {
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}tasks.named('myCopy') {
from 'resources'
into 'target'
include('**/*.txt', '**/*.xml', '**/*.properties')
}2. 使用配置块:
注册任务后立即使用块来配置任务:
tasks.register<Copy>("copy") {
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}tasks.register('copy', Copy) {
from 'resources'
into 'target'
include('**/*.txt', '**/*.xml', '**/*.properties')
}3. 将方法命名为 call:
仅 Groovy 支持的一个流行选项是速记符号:
copy {
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}|
笔记
|
此选项会破坏任务配置避免,因此不推荐! |
无论选择哪种方法,任务都会配置要复制的文件的名称和文件的位置。
三、落实任务
Gradle 提供了许多任务类型,包括Delete、Javadoc、Copy、Exec、Tar和Pmd。如果 Gradle 没有提供满足您的构建逻辑需求的任务类型,您可以实现自定义任务类型。
要创建自定义任务类,您需要扩展DefaultTask并使扩展类抽象:
abstract class MyCopyTask extends DefaultTask {
}abstract class MyCopyTask : DefaultTask() {
}您可以在实现任务中了解有关开发自定义任务类型的更多信息。
userguide_single.adoc 中未解析的指令 - include::lifecycle_tasks.adoc[leveloffset=+2] userguide_single.adoc 中未解析的指令 - include::actionable_tasks.adoc[leveloffset=+2] :leveloffset: +2
延迟配置任务
随着构建复杂性的增加,很难跟踪了解配置特定值的时间和位置。 Gradle 提供了多种使用惰性配置来管理此问题的方法。

了解惰性属性
Gradle 提供了惰性属性,它会延迟计算属性的值,直到实际需要时才计算。
惰性属性提供了三个主要好处:
-
延迟值解析:允许连接 Gradle 模型,而无需知道属性值何时已知。例如,您可能希望根据扩展的源目录属性设置任务的输入源文件,但在构建脚本或其他插件配置它们之前,扩展属性值是未知的。
-
自动任务依赖性管理:将一个任务的输出连接到另一任务的输入,自动确定任务依赖性。属性实例携带有关哪个任务(如果有)产生其值的信息。构建作者无需担心任务依赖关系与配置更改保持同步。
-
改进的构建性能:避免配置期间的资源密集型工作,从而对构建性能产生积极影响。例如,当配置值来自解析文件但仅在运行功能测试时使用时,使用属性实例捕获该值意味着仅在运行功能测试时(而不是
clean运行时)解析文件例子)。
Gradle 用两个接口表示惰性属性:
- 提供者
-
代表一个值,只能查询,不能更改。
-
这些类型的属性是只读的。
-
Provider.get()方法返回属性的当前值。
-
可以使用Provider.map(Transformer)从另一个
Provider创建A。Provider -
许多其他类型都可以扩展并可以在任何需要的
Provider地方使用。Provider
-
- 财产
-
表示一个可以查询和更改的值。
-
这些类型的属性是可配置的。
-
Property扩展Provider接口。 -
Property.set(T)方法指定属性的值,覆盖可能存在的任何值。
-
Property.set(Provider)方法指定
Provider属性的值,覆盖可能存在的任何值。这允许您在配置值之前Provider将实例连接在一起。Property -
A可以通过工厂方法ObjectFactory.property(Class)
Property创建。
-
惰性属性旨在传递并仅在需要时进行查询。这通常发生在执行阶段。
下面演示了一个具有可配置greeting属性和只读message属性的任务:
abstract class Greeting : DefaultTask() { // (1)
@get:Input
abstract val greeting: Property<String> // (2)
@Internal
val message: Provider<String> = greeting.map { it + " from Gradle" } // (3)
@TaskAction
fun printMessage() {
logger.quiet(message.get())
}
}
tasks.register<Greeting>("greeting") {
greeting.set("Hi") // (4)
greeting = "Hi" // (5)
}abstract class Greeting extends DefaultTask { // (1)
@Input
abstract Property<String> getGreeting() // (2)
@Internal
final Provider<String> message = greeting.map { it + ' from Gradle' } // (3)
@TaskAction
void printMessage() {
logger.quiet(message.get())
}
}
tasks.register("greeting", Greeting) {
greeting.set('Hi') // (4)
greeting = 'Hi' // (5)
}-
显示问候语的任务
-
可配置的问候语
-
根据问候语计算的只读属性
-
配置问候语
-
调用 Property.set() 的替代表示法
$ gradle greeting > Task :greeting Hi from Gradle BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
该Greeting任务具有表示可配置问候语的 type 属性和表示计算的只读消息的Property<String>type 属性。Provider<String>该消息是使用以下方法Provider从问候语创建的;当问候语属性的值发生变化时,它的值会保持最新。Propertymap()
创建 Property 或 Provider 实例
Provider它及其子类型(例如)都不Property打算由构建脚本或插件实现。 Gradle 提供了工厂方法来创建这些类型的实例。
在前面的示例中,提供了两个工厂方法:
-
ObjectFactory.property(Class)创建一个新
Property实例。可以从Project.getObjects()引用或通过构造函数或方法注入来引用ObjectFactory的实例。ObjectFactory -
Provider.map(Transformer)
Provider从现有的Provider或实例创建一个新的Property。
请参阅快速参考了解所有可用的类型和工厂。
A也可以通过工厂方法ProviderFactory.provider(Callable)Provider创建。
|
笔记
|
没有使用 当使用 Groovy 编写插件或构建脚本时,您可以使用 同样,当使用 Kotlin 编写插件或构建脚本时,Kotlin 编译器会将 Kotlin 函数转换为 |
将属性连接在一起
惰性属性的一个重要特征是它们可以连接在一起,以便对一个属性的更改自动反映在其他属性中。
下面是一个示例,其中任务的属性连接到项目扩展的属性:
// A project extension
interface MessageExtension {
// A configurable greeting
abstract val greeting: Property<String>
}
// A task that displays a greeting
abstract class Greeting : DefaultTask() {
// Configurable by the user
@get:Input
abstract val greeting: Property<String>
// Read-only property calculated from the greeting
@Internal
val message: Provider<String> = greeting.map { it + " from Gradle" }
@TaskAction
fun printMessage() {
logger.quiet(message.get())
}
}
// Create the project extension
val messages = project.extensions.create<MessageExtension>("messages")
// Create the greeting task
tasks.register<Greeting>("greeting") {
// Attach the greeting from the project extension
// Note that the values of the project extension have not been configured yet
greeting = messages.greeting
}
messages.apply {
// Configure the greeting on the extension
// Note that there is no need to reconfigure the task's `greeting` property. This is automatically updated as the extension property changes
greeting = "Hi"
}// A project extension
interface MessageExtension {
// A configurable greeting
Property<String> getGreeting()
}
// A task that displays a greeting
abstract class Greeting extends DefaultTask {
// Configurable by the user
@Input
abstract Property<String> getGreeting()
// Read-only property calculated from the greeting
@Internal
final Provider<String> message = greeting.map { it + ' from Gradle' }
@TaskAction
void printMessage() {
logger.quiet(message.get())
}
}
// Create the project extension
project.extensions.create('messages', MessageExtension)
// Create the greeting task
tasks.register("greeting", Greeting) {
// Attach the greeting from the project extension
// Note that the values of the project extension have not been configured yet
greeting = messages.greeting
}
messages {
// Configure the greeting on the extension
// Note that there is no need to reconfigure the task's `greeting` property. This is automatically updated as the extension property changes
greeting = 'Hi'
}$ gradle greeting > Task :greeting Hi from Gradle BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
此示例调用Property.set(Provider)方法将 a 附加Provider到 aProperty以提供属性的值。在这种情况下,Provider恰好Property也是 a,但您可以连接任何Provider实现,例如使用创建的实现Provider.map()
处理文件
在使用文件中,我们为File类对象引入了四种集合类型:
| 只读类型 | 可配置类型 |
|---|---|
所有这些类型也被视为惰性类型。
有更强类型的模型用于表示文件系统的元素: Directory和RegularFile。这些类型不应与标准 Java文件类型混淆,因为它们用于告诉 Gradle 您需要更具体的值,例如目录或非目录、常规文件。
Gradle 提供了两个专门的Property子类型来处理这些类型的值:
RegularFileProperty和DirectoryProperty。ObjectFactory有方法来创建这些:ObjectFactory.fileProperty()和ObjectFactory.directoryProperty()。
ADirectoryProperty还可用于分别通过DirectoryProperty.dir(String)和DirectoryProperty.file(String)Provider创建对 a进行延迟计算的Directory值。这些方法创建的提供程序的值是相对于它们的创建位置来计算的。从这些提供程序返回的值将反映对.RegularFileDirectoryPropertyDirectoryProperty
// A task that generates a source file and writes the result to an output directory
abstract class GenerateSource : DefaultTask() {
// The configuration file to use to generate the source file
@get:InputFile
abstract val configFile: RegularFileProperty
// The directory to write source files to
@get:OutputDirectory
abstract val outputDir: DirectoryProperty
@TaskAction
fun compile() {
val inFile = configFile.get().asFile
logger.quiet("configuration file = $inFile")
val dir = outputDir.get().asFile
logger.quiet("output dir = $dir")
val className = inFile.readText().trim()
val srcFile = File(dir, "${className}.java")
srcFile.writeText("public class ${className} { }")
}
}
// Create the source generation task
tasks.register<GenerateSource>("generate") {
// Configure the locations, relative to the project and build directories
configFile = layout.projectDirectory.file("src/config.txt")
outputDir = layout.buildDirectory.dir("generated-source")
}
// Change the build directory
// Don't need to reconfigure the task properties. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir("output")// A task that generates a source file and writes the result to an output directory
abstract class GenerateSource extends DefaultTask {
// The configuration file to use to generate the source file
@InputFile
abstract RegularFileProperty getConfigFile()
// The directory to write source files to
@OutputDirectory
abstract DirectoryProperty getOutputDir()
@TaskAction
def compile() {
def inFile = configFile.get().asFile
logger.quiet("configuration file = $inFile")
def dir = outputDir.get().asFile
logger.quiet("output dir = $dir")
def className = inFile.text.trim()
def srcFile = new File(dir, "${className}.java")
srcFile.text = "public class ${className} { ... }"
}
}
// Create the source generation task
tasks.register('generate', GenerateSource) {
// Configure the locations, relative to the project and build directories
configFile = layout.projectDirectory.file('src/config.txt')
outputDir = layout.buildDirectory.dir('generated-source')
}
// Change the build directory
// Don't need to reconfigure the task properties. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir('output')$ gradle generate > Task :generate configuration file = /home/user/gradle/samples/src/config.txt output dir = /home/user/gradle/samples/output/generated-source BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
$ gradle generate > Task :generate configuration file = /home/user/gradle/samples/kotlin/src/config.txt output dir = /home/user/gradle/samples/kotlin/output/generated-source BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
此示例通过Project.getLayout()以及ProjectLayout.getBuildDirectory()和ProjectLayout.getProjectDirectory()创建表示项目中位置和构建目录的提供程序。
要关闭循环,请注意 aDirectoryProperty或简单的Directory可以转换为 a ,允许使用DirectoryProperty.getAsFileTree()或Directory.getAsFileTree()FileTree查询目录中包含的文件和目录。从 a或 a ,您可以使用DirectoryProperty.files(Object...)或Directory.files(Object...)创建包含目录中包含的一组文件的实例。DirectoryPropertyDirectoryFileCollection
使用任务输入和输出
许多构建都有多个连接在一起的任务,其中一个任务将另一个任务的输出用作输入。
为了实现这项工作,我们需要配置每个任务,以了解在哪里查找其输入以及在哪里放置其输出。确保生产任务和消费任务配置在相同的位置,并在任务之间附加任务依赖关系。如果这些值中的任何一个可由用户配置或由多个插件配置,则这可能会很麻烦且脆弱,因为任务属性需要以正确的顺序和位置进行配置,并且任务依赖项在值更改时保持同步。
APIProperty通过跟踪属性的值和生成该值的任务使这变得更容易。
作为示例,请考虑以下带有连接在一起的生产者和消费者任务的插件:
abstract class Producer : DefaultTask() {
@get:OutputFile
abstract val outputFile: RegularFileProperty
@TaskAction
fun produce() {
val message = "Hello, World!"
val output = outputFile.get().asFile
output.writeText( message)
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer : DefaultTask() {
@get:InputFile
abstract val inputFile: RegularFileProperty
@TaskAction
fun consume() {
val input = inputFile.get().asFile
val message = input.readText()
logger.quiet("Read '${message}' from ${input}")
}
}
val producer = tasks.register<Producer>("producer")
val consumer = tasks.register<Consumer>("consumer")
consumer {
// Connect the producer task output to the consumer task input
// Don't need to add a task dependency to the consumer task. This is automatically added
inputFile = producer.flatMap { it.outputFile }
}
producer {
// Set values for the producer lazily
// Don't need to update the consumer.inputFile property. This is automatically updated as producer.outputFile changes
outputFile = layout.buildDirectory.file("file.txt")
}
// Change the build directory.
// Don't need to update producer.outputFile and consumer.inputFile. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir("output")abstract class Producer extends DefaultTask {
@OutputFile
abstract RegularFileProperty getOutputFile()
@TaskAction
void produce() {
String message = 'Hello, World!'
def output = outputFile.get().asFile
output.text = message
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer extends DefaultTask {
@InputFile
abstract RegularFileProperty getInputFile()
@TaskAction
void consume() {
def input = inputFile.get().asFile
def message = input.text
logger.quiet("Read '${message}' from ${input}")
}
}
def producer = tasks.register("producer", Producer)
def consumer = tasks.register("consumer", Consumer)
consumer.configure {
// Connect the producer task output to the consumer task input
// Don't need to add a task dependency to the consumer task. This is automatically added
inputFile = producer.flatMap { it.outputFile }
}
producer.configure {
// Set values for the producer lazily
// Don't need to update the consumer.inputFile property. This is automatically updated as producer.outputFile changes
outputFile = layout.buildDirectory.file('file.txt')
}
// Change the build directory.
// Don't need to update producer.outputFile and consumer.inputFile. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir('output')$ gradle consumer > Task :producer Wrote 'Hello, World!' to /home/user/gradle/samples/output/file.txt > Task :consumer Read 'Hello, World!' from /home/user/gradle/samples/output/file.txt BUILD SUCCESSFUL in 0s 2 actionable tasks: 2 executed
$ gradle consumer > Task :producer Wrote 'Hello, World!' to /home/user/gradle/samples/kotlin/output/file.txt > Task :consumer Read 'Hello, World!' from /home/user/gradle/samples/kotlin/output/file.txt BUILD SUCCESSFUL in 0s 2 actionable tasks: 2 executed
在上面的示例中,任务输出和输入在定义任何位置之前就已连接。 setter 可以在任务执行之前随时调用,并且更改将自动影响所有相关的输入和输出属性。
此示例中需要注意的另一个重要事项是不存在任何显式任务依赖性。使用Providers跟踪哪个任务产生其值来表示任务输出,并将它们用作任务输入将隐式添加正确的任务依赖项。
隐式任务依赖项也适用于非文件的输入属性:
abstract class Producer : DefaultTask() {
@get:OutputFile
abstract val outputFile: RegularFileProperty
@TaskAction
fun produce() {
val message = "Hello, World!"
val output = outputFile.get().asFile
output.writeText( message)
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer : DefaultTask() {
@get:Input
abstract val message: Property<String>
@TaskAction
fun consume() {
logger.quiet(message.get())
}
}
val producer = tasks.register<Producer>("producer") {
// Set values for the producer lazily
// Don't need to update the consumer.inputFile property. This is automatically updated as producer.outputFile changes
outputFile = layout.buildDirectory.file("file.txt")
}
tasks.register<Consumer>("consumer") {
// Connect the producer task output to the consumer task input
// Don't need to add a task dependency to the consumer task. This is automatically added
message = producer.flatMap { it.outputFile }.map { it.asFile.readText() }
}abstract class Producer extends DefaultTask {
@OutputFile
abstract RegularFileProperty getOutputFile()
@TaskAction
void produce() {
String message = 'Hello, World!'
def output = outputFile.get().asFile
output.text = message
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer extends DefaultTask {
@Input
abstract Property<String> getMessage()
@TaskAction
void consume() {
logger.quiet(message.get())
}
}
def producer = tasks.register('producer', Producer) {
// Set values for the producer lazily
// Don't need to update the consumer.inputFile property. This is automatically updated as producer.outputFile changes
outputFile = layout.buildDirectory.file('file.txt')
}
tasks.register('consumer', Consumer) {
// Connect the producer task output to the consumer task input
// Don't need to add a task dependency to the consumer task. This is automatically added
message = producer.flatMap { it.outputFile }.map { it.asFile.text }
}$ gradle consumer > Task :producer Wrote 'Hello, World!' to /home/user/gradle/samples/build/file.txt > Task :consumer Hello, World! BUILD SUCCESSFUL in 0s 2 actionable tasks: 2 executed
$ gradle consumer > Task :producer Wrote 'Hello, World!' to /home/user/gradle/samples/kotlin/build/file.txt > Task :consumer Hello, World! BUILD SUCCESSFUL in 0s 2 actionable tasks: 2 executed
使用集合
Gradle 提供了两种惰性属性类型来帮助配置Collection属性。
它们的工作方式与任何其他提供程序完全相同Provider,并且就像文件提供程序一样,它们有额外的建模:
-
对于
List值,该接口称为ListProperty。
您可以ListProperty使用ObjectFactory.listProperty(Class)并指定元素类型来创建新的。 -
对于
Set值,该接口称为SetProperty。
您可以SetProperty使用ObjectFactory.setProperty(Class)并指定元素类型来创建新的。
这种类型的属性允许您使用HasMultipleValues.set(Iterable)和HasMultipleValues.set(Provider)覆盖整个集合值,或者通过各种add方法添加新元素:
-
HasMultipleValues.add(T) : 将单个元素添加到集合中
-
HasMultipleValues.add(Provider):将延迟计算的元素添加到集合中
-
HasMultipleValues.addAll(Provider):将延迟计算的元素集合添加到列表中
就像 every 一样Provider,集合是在调用Provider.get()时计算的。以下示例显示了ListProperty 的实际操作:
abstract class Producer : DefaultTask() {
@get:OutputFile
abstract val outputFile: RegularFileProperty
@TaskAction
fun produce() {
val message = "Hello, World!"
val output = outputFile.get().asFile
output.writeText( message)
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer : DefaultTask() {
@get:InputFiles
abstract val inputFiles: ListProperty<RegularFile>
@TaskAction
fun consume() {
inputFiles.get().forEach { inputFile ->
val input = inputFile.asFile
val message = input.readText()
logger.quiet("Read '${message}' from ${input}")
}
}
}
val producerOne = tasks.register<Producer>("producerOne")
val producerTwo = tasks.register<Producer>("producerTwo")
tasks.register<Consumer>("consumer") {
// Connect the producer task outputs to the consumer task input
// Don't need to add task dependencies to the consumer task. These are automatically added
inputFiles.add(producerOne.get().outputFile)
inputFiles.add(producerTwo.get().outputFile)
}
// Set values for the producer tasks lazily
// Don't need to update the consumer.inputFiles property. This is automatically updated as producer.outputFile changes
producerOne { outputFile = layout.buildDirectory.file("one.txt") }
producerTwo { outputFile = layout.buildDirectory.file("two.txt") }
// Change the build directory.
// Don't need to update the task properties. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir("output")abstract class Producer extends DefaultTask {
@OutputFile
abstract RegularFileProperty getOutputFile()
@TaskAction
void produce() {
String message = 'Hello, World!'
def output = outputFile.get().asFile
output.text = message
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer extends DefaultTask {
@InputFiles
abstract ListProperty<RegularFile> getInputFiles()
@TaskAction
void consume() {
inputFiles.get().each { inputFile ->
def input = inputFile.asFile
def message = input.text
logger.quiet("Read '${message}' from ${input}")
}
}
}
def producerOne = tasks.register('producerOne', Producer)
def producerTwo = tasks.register('producerTwo', Producer)
tasks.register('consumer', Consumer) {
// Connect the producer task outputs to the consumer task input
// Don't need to add task dependencies to the consumer task. These are automatically added
inputFiles.add(producerOne.get().outputFile)
inputFiles.add(producerTwo.get().outputFile)
}
// Set values for the producer tasks lazily
// Don't need to update the consumer.inputFiles property. This is automatically updated as producer.outputFile changes
producerOne.configure { outputFile = layout.buildDirectory.file('one.txt') }
producerTwo.configure { outputFile = layout.buildDirectory.file('two.txt') }
// Change the build directory.
// Don't need to update the task properties. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir('output')$ gradle consumer > Task :producerOne Wrote 'Hello, World!' to /home/user/gradle/samples/output/one.txt > Task :producerTwo Wrote 'Hello, World!' to /home/user/gradle/samples/output/two.txt > Task :consumer Read 'Hello, World!' from /home/user/gradle/samples/output/one.txt Read 'Hello, World!' from /home/user/gradle/samples/output/two.txt BUILD SUCCESSFUL in 0s 3 actionable tasks: 3 executed
$ gradle consumer > Task :producerOne Wrote 'Hello, World!' to /home/user/gradle/samples/kotlin/output/one.txt > Task :producerTwo Wrote 'Hello, World!' to /home/user/gradle/samples/kotlin/output/two.txt > Task :consumer Read 'Hello, World!' from /home/user/gradle/samples/kotlin/output/one.txt Read 'Hello, World!' from /home/user/gradle/samples/kotlin/output/two.txt BUILD SUCCESSFUL in 0s 3 actionable tasks: 3 executed
使用地图
Gradle 提供了一个惰性MapProperty类型来允许Map配置值。您可以MapProperty使用ObjectFactory.mapProperty(Class, Class)创建实例。
与其他属性类型类似,aMapProperty有一个set()方法,可用于指定属性的值。一些附加方法允许将具有惰性值的条目添加到映射中。
abstract class Generator: DefaultTask() {
@get:Input
abstract val properties: MapProperty<String, Int>
@TaskAction
fun generate() {
properties.get().forEach { entry ->
logger.quiet("${entry.key} = ${entry.value}")
}
}
}
// Some values to be configured later
var b = 0
var c = 0
tasks.register<Generator>("generate") {
properties.put("a", 1)
// Values have not been configured yet
properties.put("b", providers.provider { b })
properties.putAll(providers.provider { mapOf("c" to c, "d" to c + 1) })
}
// Configure the values. There is no need to reconfigure the task
b = 2
c = 3abstract class Generator extends DefaultTask {
@Input
abstract MapProperty<String, Integer> getProperties()
@TaskAction
void generate() {
properties.get().each { key, value ->
logger.quiet("${key} = ${value}")
}
}
}
// Some values to be configured later
def b = 0
def c = 0
tasks.register('generate', Generator) {
properties.put("a", 1)
// Values have not been configured yet
properties.put("b", providers.provider { b })
properties.putAll(providers.provider { [c: c, d: c + 1] })
}
// Configure the values. There is no need to reconfigure the task
b = 2
c = 3$ gradle generate > Task :generate a = 1 b = 2 c = 3 d = 4 BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
将约定应用于属性
通常,您希望对要在未配置值的情况下使用的属性应用一些约定或默认值。您可以使用该convention()方法来实现此目的。此方法接受一个值或 a Provider,并且这将用作该值,直到配置其他值。
tasks.register("show") {
val property = objects.property(String::class)
// Set a convention
property.convention("convention 1")
println("value = " + property.get())
// Can replace the convention
property.convention("convention 2")
println("value = " + property.get())
property.set("explicit value")
// Once a value is set, the convention is ignored
property.convention("ignored convention")
doLast {
println("value = " + property.get())
}
}tasks.register("show") {
def property = objects.property(String)
// Set a convention
property.convention("convention 1")
println("value = " + property.get())
// Can replace the convention
property.convention("convention 2")
println("value = " + property.get())
property.set("explicit value")
// Once a value is set, the convention is ignored
property.convention("ignored convention")
doLast {
println("value = " + property.get())
}
}$ gradle show value = convention 1 value = convention 2 > Task :show value = explicit value BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
使属性不可修改
任务或项目的大多数属性旨在通过插件或构建脚本进行配置,以便它们可以为该构建使用特定值。
例如,指定编译任务的输出目录的属性可能以插件指定的值开头。然后构建脚本可能会将该值更改为某个自定义位置,然后任务运行时将使用该值。但是,一旦任务开始运行,我们希望防止进一步的属性更改。通过这种方式,我们可以避免因不同的使用者(例如任务操作、Gradle 的最新检查、构建缓存或其他任务)使用不同的属性值而导致的错误。
惰性属性提供了多种方法,您可以使用这些方法在配置值后禁止更改其值。 FinalizeValue ()方法计算属性的最终值并防止对该属性进行进一步更改。
libVersioning.version.finalizeValue()当属性的值来自 a 时Provider,将向提供者查询其当前值,结果将成为该属性的最终值。此最终值取代了提供者,并且该属性不再跟踪提供者的值。调用此方法还会使属性实例不可修改,并且任何进一步更改该属性值的尝试都将失败。当任务开始执行时,Gradle 会自动将任务的属性设为最终属性。
FinalizeValueOnRead()方法类似,只不过在查询属性值之前不会计算属性的最终值。
modifiedFiles.finalizeValueOnRead()换句话说,该方法根据需要延迟计算最终值,而finalizeValue()急切地计算最终值。当该值的计算成本可能很高或尚未配置时,可以使用此方法。您还希望确保该属性的所有使用者在查询该值时看到相同的值。
使用提供商 API
成功使用 Provider API 的指南:
-
Property和Provider类型具有查询或配置值所需的所有重载。因此,您应该遵循以下准则:
-
对于可配置属性,直接通过单个 getter公开属性。
-
对于不可配置的属性,直接通过单个 getter公开Provider 。
-
-
避免通过引入额外的 getter 和 setter 来简化代码中的调用,例如
obj.getProperty().get()和。obj.getProperty().set(T) -
将插件迁移到使用提供程序时,请遵循以下准则:
惰性对象 API 参考
将这些类型用于只读值:
- 提供者<T>
-
其值为以下实例的属性
T- 工厂
-
-
ProviderFactory.provider(Callable)。始终优先选择其他工厂方法之一而不是此方法。
将这些类型用于可变值:
- 属性<T>
-
其值为以下实例的属性
T
开发并行任务
Gradle 提供了一个 API,可以将任务分割成可以并行执行的部分。

这使得 Gradle 能够充分利用可用资源并更快地完成构建。
工人API
Worker API 提供了将任务操作的执行分解为离散的工作单元,然后并发和异步执行该工作的能力。
工作线程 API 示例
了解如何使用 API 的最佳方法是完成将现有自定义任务转换为使用 Worker API 的过程:
-
您将首先创建一个自定义任务类,为一组可配置的文件生成 MD5 哈希值。
-
然后,您将转换此自定义任务以使用 Worker API。
-
然后,我们将探索以不同的隔离级别运行任务。
在此过程中,您将了解 Worker API 的基础知识及其提供的功能。
步骤 1. 创建自定义任务类
首先,创建一个自定义任务,生成一组可配置文件的 MD5 哈希值。
在新目录中,创建一个buildSrc/build.gradle(.kts)文件:
repositories {
mavenCentral()
}
dependencies {
implementation("commons-io:commons-io:2.5")
implementation("commons-codec:commons-codec:1.9") // (1)
}repositories {
mavenCentral()
}
dependencies {
implementation 'commons-io:commons-io:2.5'
implementation 'commons-codec:commons-codec:1.9' // (1)
}-
您的自定义任务类将使用Apache Commons Codec生成 MD5 哈希值。
接下来,在您的目录中创建一个自定义任务类buildSrc/src/main/java。你应该命名这个类CreateMD5:
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.commons.io.FileUtils;
import org.gradle.api.file.DirectoryProperty;
import org.gradle.api.file.RegularFile;
import org.gradle.api.provider.Provider;
import org.gradle.api.tasks.OutputDirectory;
import org.gradle.api.tasks.SourceTask;
import org.gradle.api.tasks.TaskAction;
import org.gradle.workers.WorkerExecutor;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
abstract public class CreateMD5 extends SourceTask { // (1)
@OutputDirectory
abstract public DirectoryProperty getDestinationDirectory(); // (2)
@TaskAction
public void createHashes() {
for (File sourceFile : getSource().getFiles()) { // (3)
try {
InputStream stream = new FileInputStream(sourceFile);
System.out.println("Generating MD5 for " + sourceFile.getName() + "...");
// Artificially make this task slower.
Thread.sleep(3000); // (4)
Provider<RegularFile> md5File = getDestinationDirectory().file(sourceFile.getName() + ".md5"); // (5)
FileUtils.writeStringToFile(md5File.get().getAsFile(), DigestUtils.md5Hex(stream), (String) null);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
}-
SourceTask是对一组源文件进行操作的任务的便捷类型。
-
任务输出将进入配置的目录。
-
该任务迭代所有定义为“源文件”的文件并创建每个文件的 MD5 哈希值。
-
插入人工睡眠来模拟对大文件进行哈希处理(示例文件不会那么大)。
-
每个文件的 MD5 哈希值将写入输出目录中,并写入具有“md5”扩展名的同名文件中。
接下来,创建一个build.gradle(.kts)注册新CreateMD5任务的任务:
plugins { id("base") } // (1)
tasks.register<CreateMD5>("md5") {
destinationDirectory = project.layout.buildDirectory.dir("md5") // (2)
source(project.layout.projectDirectory.file("src")) // (3)
}plugins { id 'base' } // (1)
tasks.register("md5", CreateMD5) {
destinationDirectory = project.layout.buildDirectory.dir("md5") // (2)
source(project.layout.projectDirectory.file('src')) // (3)
}-
应用该
base插件,以便您可以clean执行删除输出的任务。 -
MD5 哈希文件将被写入
build/md5. -
此任务将为
src目录中的每个文件生成 MD5 哈希文件。
您将需要一些源来生成 MD5 哈希值。在目录中创建三个文件src:
Intellectual growth should commence at birth and cease only at death.I was born not knowing and have had only a little time to change that here and there.Intelligence is the ability to adapt to change.此时,您可以通过运行来测试您的任务./gradlew md5:
$ gradle md5
输出应类似于:
> Task :md5 Generating MD5 for einstein.txt... Generating MD5 for feynman.txt... Generating MD5 for hawking.txt... BUILD SUCCESSFUL in 9s 3 actionable tasks: 3 executed
在该build/md5目录中,您现在应该看到相应的文件,其md5扩展名包含该目录中文件的 MD5 哈希值src。请注意,该任务至少需要 9 秒才能运行,因为它一次对每个文件进行哈希处理(即,每个文件约 3 秒对三个文件进行哈希处理)。
步骤 2. 转换为 Worker API
尽管此任务按顺序处理每个文件,但每个文件的处理独立于任何其他文件。这项工作可以并行完成并利用多个处理器。这就是 Worker API 可以提供帮助的地方。
要使用 Worker API,您需要定义一个接口来表示每个工作单元的参数并扩展org.gradle.workers.WorkParameters。
为了生成 MD5 哈希文件,工作单元需要两个参数:
-
要散列的文件,
-
要写入哈希值的文件。
不需要创建具体的实现,因为 Gradle 会在运行时为我们生成一个。
import org.gradle.api.file.RegularFileProperty;
import org.gradle.workers.WorkParameters;
public interface MD5WorkParameters extends WorkParameters {
RegularFileProperty getSourceFile(); // (1)
RegularFileProperty getMD5File();
}-
使用
Property对象来表示源文件和 MD5 哈希文件。
然后,您需要将自定义任务中为每个单独文件执行工作的部分重构为单独的类。这个类是您的“工作单元”实现,它应该是一个扩展的抽象类org.gradle.workers.WorkAction:
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.commons.io.FileUtils;
import org.gradle.workers.WorkAction;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public abstract class GenerateMD5 implements WorkAction<MD5WorkParameters> { // (1)
@Override
public void execute() {
try {
File sourceFile = getParameters().getSourceFile().getAsFile().get();
File md5File = getParameters().getMD5File().getAsFile().get();
InputStream stream = new FileInputStream(sourceFile);
System.out.println("Generating MD5 for " + sourceFile.getName() + "...");
// Artificially make this task slower.
Thread.sleep(3000);
FileUtils.writeStringToFile(md5File, DigestUtils.md5Hex(stream), (String) null);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}-
不要实现该
getParameters()方法 - Gradle 将在运行时注入该方法。
现在,更改您的自定义任务类以将工作提交到 WorkerExecutor,而不是自行执行工作。
import org.gradle.api.Action;
import org.gradle.api.file.RegularFile;
import org.gradle.api.provider.Provider;
import org.gradle.api.tasks.*;
import org.gradle.workers.*;
import org.gradle.api.file.DirectoryProperty;
import javax.inject.Inject;
import java.io.File;
abstract public class CreateMD5 extends SourceTask {
@OutputDirectory
abstract public DirectoryProperty getDestinationDirectory();
@Inject
abstract public WorkerExecutor getWorkerExecutor(); // (1)
@TaskAction
public void createHashes() {
WorkQueue workQueue = getWorkerExecutor().noIsolation(); // (2)
for (File sourceFile : getSource().getFiles()) {
Provider<RegularFile> md5File = getDestinationDirectory().file(sourceFile.getName() + ".md5");
workQueue.submit(GenerateMD5.class, parameters -> { // (3)
parameters.getSourceFile().set(sourceFile);
parameters.getMD5File().set(md5File);
});
}
}
}-
需要WorkerExecutor服务才能提交您的工作。创建一个带注释的抽象 getter 方法
javax.inject.Inject,Gradle 将在创建任务时在运行时注入服务。 -
在提交工作之前,获取
WorkQueue具有所需隔离模式的对象(如下所述)。 -
提交工作单元时,指定工作单元实现(在本例中为 )
GenerateMD5,并配置其参数。
此时,您应该能够重新运行您的任务:
$ gradle clean md5 > Task :md5 Generating MD5 for einstein.txt... Generating MD5 for feynman.txt... Generating MD5 for hawking.txt... BUILD SUCCESSFUL in 3s 3 actionable tasks: 3 executed
结果看起来应该与以前相同,但由于工作单元是并行执行的,MD5 哈希文件可能会以不同的顺序生成。然而,这一次任务运行得更快了。这是因为 Worker API 并行而不是顺序地对每个文件执行 MD5 计算。
步骤 3. 更改隔离模式
隔离模式控制 Gradle 将工作项彼此以及 Gradle 运行时的其余部分隔离的程度。
可以通过三种方法来WorkerExecutor控制:
-
noIsolation() -
classLoaderIsolation() -
processIsolation()
该noIsolation()模式是最低级别的隔离,将防止工作单元更改项目状态。这是最快的隔离模式,因为它需要最少的开销来设置和执行工作项。但是,它将使用单个共享类加载器来完成所有工作单元。这意味着每个工作单元都可以通过静态类状态相互影响。这也意味着每个工作单元在 buildscript 类路径上使用相同版本的库。如果您希望用户能够将任务配置为使用不同(但兼容)版本的
Apache Commons Codec库运行,则需要使用不同的隔离模式。
首先,您必须将依赖项更改为buildSrc/build.gradlebe compileOnly。这告诉 Gradle 在构建类时应该使用此依赖项,但不应将其放在构建脚本类路径中:
repositories {
mavenCentral()
}
dependencies {
implementation("commons-io:commons-io:2.5")
compileOnly("commons-codec:commons-codec:1.9")
}repositories {
mavenCentral()
}
dependencies {
implementation 'commons-io:commons-io:2.5'
compileOnly 'commons-codec:commons-codec:1.9'
}接下来,更改CreateMD5任务以允许用户配置他们想要使用的编解码器库的版本。它将在运行时解析库的适当版本并配置工作人员以使用该版本。
该classLoaderIsolation()方法告诉 Gradle 在具有隔离类加载器的线程中运行此工作:
import org.gradle.api.Action;
import org.gradle.api.file.ConfigurableFileCollection;
import org.gradle.api.file.DirectoryProperty;
import org.gradle.api.file.RegularFile;
import org.gradle.api.provider.Provider;
import org.gradle.api.tasks.*;
import org.gradle.process.JavaForkOptions;
import org.gradle.workers.*;
import javax.inject.Inject;
import java.io.File;
import java.util.Set;
abstract public class CreateMD5 extends SourceTask {
@InputFiles
abstract public ConfigurableFileCollection getCodecClasspath(); // (1)
@OutputDirectory
abstract public DirectoryProperty getDestinationDirectory();
@Inject
abstract public WorkerExecutor getWorkerExecutor();
@TaskAction
public void createHashes() {
WorkQueue workQueue = getWorkerExecutor().classLoaderIsolation(workerSpec -> {
workerSpec.getClasspath().from(getCodecClasspath()); // (2)
});
for (File sourceFile : getSource().getFiles()) {
Provider<RegularFile> md5File = getDestinationDirectory().file(sourceFile.getName() + ".md5");
workQueue.submit(GenerateMD5.class, parameters -> {
parameters.getSourceFile().set(sourceFile);
parameters.getMD5File().set(md5File);
});
}
}
}-
公开编解码器库类路径的输入属性。
-
创建工作队列时在ClassLoaderWorkerSpec上配置类路径。
接下来,您需要配置构建,以便它有一个存储库来在任务执行时查找编解码器版本。我们还创建一个依赖项来解析此存储库中的编解码器库:
plugins { id("base") }
repositories {
mavenCentral() // (1)
}
val codec = configurations.create("codec") { // (2)
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage.JAVA_RUNTIME))
}
isVisible = false
isCanBeConsumed = false
}
dependencies {
codec("commons-codec:commons-codec:1.10") // (3)
}
tasks.register<CreateMD5>("md5") {
codecClasspath.from(codec) // (4)
destinationDirectory = project.layout.buildDirectory.dir("md5")
source(project.layout.projectDirectory.file("src"))
}plugins { id 'base' }
repositories {
mavenCentral() // (1)
}
configurations.create('codec') { // (2)
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, Usage.JAVA_RUNTIME))
}
visible = false
canBeConsumed = false
}
dependencies {
codec 'commons-codec:commons-codec:1.10' // (3)
}
tasks.register('md5', CreateMD5) {
codecClasspath.from(configurations.codec) // (4)
destinationDirectory = project.layout.buildDirectory.dir('md5')
source(project.layout.projectDirectory.file('src'))
}-
添加一个存储库来解析编解码器库 - 这可以是与用于构建
CreateMD5任务类的存储库不同的存储库。 -
添加配置来解析我们的编解码器库版本。
-
配置Apache Commons Codec的备用兼容版本。
-
配置
md5任务以使用配置作为其类路径。请注意,直到任务执行后,配置才会被解析。
现在,如果您运行任务,它应该使用编解码器库的配置版本按预期工作:
$ gradle clean md5 > Task :md5 Generating MD5 for einstein.txt... Generating MD5 for feynman.txt... Generating MD5 for hawking.txt... BUILD SUCCESSFUL in 3s 3 actionable tasks: 3 executed
步骤 4. 创建一个工作守护进程
有时,在执行工作项时需要利用更高级别的隔离。例如,外部库可能依赖于要设置的某些系统属性,这可能会在工作项之间发生冲突。或者,库可能与 Gradle 运行的 JDK 版本不兼容,并且可能需要使用不同的版本运行。
Worker API 可以使用processIsolation()使工作在单独的“worker 守护进程”中执行的方法来适应这种情况。这些工作守护进程将在构建过程中持续存在,并且可以在后续构建过程中重用。但是,如果系统资源不足,Gradle 将停止未使用的工作守护进程。
要使用工作守护进程,请processIsolation()在创建WorkQueue.您可能还想为新流程配置自定义设置:
import org.gradle.api.Action;
import org.gradle.api.file.ConfigurableFileCollection;
import org.gradle.api.file.DirectoryProperty;
import org.gradle.api.file.RegularFile;
import org.gradle.api.provider.Provider;
import org.gradle.api.tasks.*;
import org.gradle.process.JavaForkOptions;
import org.gradle.workers.*;
import javax.inject.Inject;
import java.io.File;
import java.util.Set;
abstract public class CreateMD5 extends SourceTask {
@InputFiles
abstract public ConfigurableFileCollection getCodecClasspath(); // (1)
@OutputDirectory
abstract public DirectoryProperty getDestinationDirectory();
@Inject
abstract public WorkerExecutor getWorkerExecutor();
@TaskAction
public void createHashes() {
// (1)
WorkQueue workQueue = getWorkerExecutor().processIsolation(workerSpec -> {
workerSpec.getClasspath().from(getCodecClasspath());
workerSpec.forkOptions(options -> {
options.setMaxHeapSize("64m"); // (2)
});
});
for (File sourceFile : getSource().getFiles()) {
Provider<RegularFile> md5File = getDestinationDirectory().file(sourceFile.getName() + ".md5");
workQueue.submit(GenerateMD5.class, parameters -> {
parameters.getSourceFile().set(sourceFile);
parameters.getMD5File().set(md5File);
});
}
}
}-
将隔离模式更改为
PROCESS。 -
为新进程设置JavaForkOptions 。
现在,您应该能够运行您的任务,并且它将按预期工作,但使用工作守护进程:
$ gradle clean md5 > Task :md5 Generating MD5 for einstein.txt... Generating MD5 for feynman.txt... Generating MD5 for hawking.txt... BUILD SUCCESSFUL in 3s 3 actionable tasks: 3 executed
请注意,执行时间可能会很长。这是因为 Gradle 必须为每个工作守护进程启动一个新进程,这是昂贵的。
但是,如果您第二次运行任务,您会发现它运行得更快。这是因为在初始构建期间启动的工作守护进程已持续存在,并且可以在后续构建期间立即使用:
$ gradle clean md5 > Task :md5 Generating MD5 for einstein.txt... Generating MD5 for feynman.txt... Generating MD5 for hawking.txt... BUILD SUCCESSFUL in 1s 3 actionable tasks: 3 executed
隔离模式
Gradle 提供了三种隔离模式,可以在创建WorkQueue时进行配置,并在WorkerExecutor上使用以下方法之一指定:
WorkerExecutor.noIsolation()-
这表明工作应该在具有最小隔离的线程中运行。
例如,它将共享与任务加载相同的类加载器。这是最快的隔离级别。 WorkerExecutor.classLoaderIsolation()-
这表明工作应该在具有隔离类加载器的线程中运行。
类加载器将具有来自加载工作单元实现类的类加载器的类路径以及通过添加的任何其他类路径条目ClassLoaderWorkerSpec.getClasspath()。 WorkerExecutor.processIsolation()-
这表明工作应该通过在单独的进程中执行工作来以最大隔离级别运行。
该进程的类加载器将使用加载工作单元的类加载器中的类路径以及通过添加的任何其他类路径条目ClassLoaderWorkerSpec.getClasspath()。此外,该进程将是一个工作守护进程,它将保持活动状态,并且可以重用于具有相同要求的未来工作项。可以使用ProcessWorkerSpec.forkOptions(org.gradle.api.Action)使用与 Gradle JVM 不同的设置来配置此进程。
工人守护进程
使用 时processIsolation(),Gradle 将启动一个长期存在的工作守护进程,可以在未来的工作项中重用。
// Create a WorkQueue with process isolation
val workQueue = workerExecutor.processIsolation() {
// Configure the options for the forked process
forkOptions {
maxHeapSize = "512m"
systemProperty("org.gradle.sample.showFileSize", "true")
}
}
// Create and submit a unit of work for each file
source.forEach { file ->
workQueue.submit(ReverseFile::class) {
fileToReverse = file
destinationDir = outputDir
}
}// Create a WorkQueue with process isolation
WorkQueue workQueue = workerExecutor.processIsolation() { ProcessWorkerSpec spec ->
// Configure the options for the forked process
forkOptions { JavaForkOptions options ->
options.maxHeapSize = "512m"
options.systemProperty "org.gradle.sample.showFileSize", "true"
}
}
// Create and submit a unit of work for each file
source.each { file ->
workQueue.submit(ReverseFile.class) { ReverseParameters parameters ->
parameters.fileToReverse = file
parameters.destinationDir = outputDir
}
}当提交工作守护进程的工作单元时,Gradle 将首先查看是否已存在兼容的空闲守护进程。如果是,它会将工作单元发送到空闲守护进程,将其标记为忙碌。如果没有,它将启动一个新的守护进程。在评估兼容性时,Gradle 会考虑许多标准,所有这些标准都可以通过ProcessWorkerSpec.forkOptions(org.gradle.api.Action)进行控制。
默认情况下,工作守护进程以 512MB 的最大堆启动。这可以通过调整工人的分叉选项来改变。
- 可执行文件
-
仅当守护程序使用相同的 Java 可执行文件时,该守护程序才被视为兼容。
- 类路径
-
如果守护进程的类路径包含所请求的所有类路径条目,则该守护进程被认为是兼容的。
请注意,仅当类路径与请求的类路径完全匹配时,守护程序才被视为兼容。 - 堆设置
-
如果守护进程至少具有与请求相同的堆大小设置,则该守护进程被认为是兼容的。
换句话说,具有比请求更高的堆设置的守护进程将被视为兼容。 - jvm 参数
-
如果守护进程已设置了请求的所有 JVM 参数,则该守护进程是兼容的。
请注意,如果守护程序具有超出请求的其他 JVM 参数(除了那些特别处理的参数,例如堆设置、断言、调试等),则该守护程序是兼容的。 - 系统属性
-
如果守护程序已将请求的所有系统属性设置为相同的值,则该守护程序被视为兼容。
请注意,如果守护程序具有超出所要求的其他系统属性,则该守护程序是兼容的。 - 环境变量
-
如果守护进程已将请求的所有环境变量设置为相同的值,则该守护进程被认为是兼容的。
请注意,如果守护程序的环境变量多于请求的数量,则该守护程序是兼容的。 - 引导类路径
-
如果守护进程包含所请求的所有引导类路径条目,则该守护进程被认为是兼容的。
请注意,如果守护程序的引导类路径条目多于请求的数量,则该守护程序是兼容的。 - 调试
-
仅当 debug 设置为与请求的值相同(
true或false)时,守护程序才被视为兼容。 - 启用断言
-
仅当启用断言设置为与请求的值相同(
true或false)时,守护程序才被视为兼容。 - 默认字符编码
-
仅当默认字符编码设置为与请求的值相同时,守护程序才被视为兼容。
工作守护进程将保持运行,直到启动它们的构建守护进程停止或系统内存变得稀缺。当系统内存不足时,Gradle 将停止工作守护进程以最大程度地减少内存消耗。
|
笔记
|
有关将普通任务操作转换为使用辅助 API 的分步说明可以在开发并行任务部分中找到。 |
取消和超时
为了支持取消(例如,当用户使用 CTRL+C 停止构建时)和任务超时,自定义任务应该对中断其执行线程做出反应。对于通过工作 API 提交的工作项也是如此。如果任务在 10 秒内没有响应中断,守护进程将关闭以释放系统资源。
高级任务
增量任务
UP-TO-DATE在 Gradle 中,由于增量构建功能,实现在输入和输出已经存在时跳过执行的任务既简单又高效。
然而,有时自上次执行以来只有少数输入文件发生了变化,最好避免重新处理所有未更改的输入。这种情况在一对一地将输入文件转换为输出文件的任务中很常见。
要优化构建过程,您可以使用增量任务。这种方法可确保仅处理过时的输入文件,从而提高构建性能。
实施增量任务
对于增量处理输入的任务,该任务必须包含增量任务操作。
这是一个具有单个InputChanges参数的任务操作方法。该参数告诉 Gradle 该操作只想处理更改的输入。
此外,该任务需要使用@Incremental或声明至少一个增量文件输入属性@SkipWhenEmpty:
public class IncrementalReverseTask : DefaultTask() {
@get:Incremental
@get:InputDirectory
val inputDir: DirectoryProperty = project.objects.directoryProperty()
@get:OutputDirectory
val outputDir: DirectoryProperty = project.objects.directoryProperty()
@get:Input
val inputProperty: RegularFileProperty = project.objects.fileProperty() // File input property
@TaskAction
fun execute(inputs: InputChanges) { // InputChanges parameter
val msg = if (inputs.isIncremental) "CHANGED inputs are out of date"
else "ALL inputs are out of date"
println(msg)
}
}class IncrementalReverseTask extends DefaultTask {
@Incremental
@InputDirectory
def File inputDir
@OutputDirectory
def File outputDir
@Input
def inputProperty // File input property
@TaskAction
void execute(InputChanges inputs) { // InputChanges parameter
println inputs.incremental ? "CHANGED inputs are out of date"
: "ALL inputs are out of date"
}
}|
重要的
|
要查询输入文件属性的增量更改,该属性必须始终返回相同的实例。实现此目的的最简单方法是使用以下属性类型之一: 您可以在延迟配置中了解有关 |
增量任务操作可用于InputChanges.getFileChanges()找出给定的基于文件的输入属性(类型为或 )RegularFileProperty的文件已更改。DirectoryPropertyConfigurableFileCollection
该方法返回FileChangesIterable类型,进而可以查询以下内容:
以下示例演示了具有目录输入的增量任务。它假设该目录包含文本文件的集合,并将它们复制到输出目录,反转每个文件中的文本:
abstract class IncrementalReverseTask : DefaultTask() {
@get:Incremental
@get:PathSensitive(PathSensitivity.NAME_ONLY)
@get:InputDirectory
abstract val inputDir: DirectoryProperty
@get:OutputDirectory
abstract val outputDir: DirectoryProperty
@get:Input
abstract val inputProperty: Property<String>
@TaskAction
fun execute(inputChanges: InputChanges) {
println(
if (inputChanges.isIncremental) "Executing incrementally"
else "Executing non-incrementally"
)
inputChanges.getFileChanges(inputDir).forEach { change ->
if (change.fileType == FileType.DIRECTORY) return@forEach
println("${change.changeType}: ${change.normalizedPath}")
val targetFile = outputDir.file(change.normalizedPath).get().asFile
if (change.changeType == ChangeType.REMOVED) {
targetFile.delete()
} else {
targetFile.writeText(change.file.readText().reversed())
}
}
}
}abstract class IncrementalReverseTask extends DefaultTask {
@Incremental
@PathSensitive(PathSensitivity.NAME_ONLY)
@InputDirectory
abstract DirectoryProperty getInputDir()
@OutputDirectory
abstract DirectoryProperty getOutputDir()
@Input
abstract Property<String> getInputProperty()
@TaskAction
void execute(InputChanges inputChanges) {
println(inputChanges.incremental
? 'Executing incrementally'
: 'Executing non-incrementally'
)
inputChanges.getFileChanges(inputDir).each { change ->
if (change.fileType == FileType.DIRECTORY) return
println "${change.changeType}: ${change.normalizedPath}"
def targetFile = outputDir.file(change.normalizedPath).get().asFile
if (change.changeType == ChangeType.REMOVED) {
targetFile.delete()
} else {
targetFile.text = change.file.text.reverse()
}
}
}
}|
笔记
|
属性的类型inputDir、其注释以及execute()用于getFileChanges()处理自上次构建以来已更改的文件子集的操作。如果相应的输入文件已被删除,则该操作将删除目标文件。
|
如果由于某种原因,任务以非增量方式执行(--rerun-tasks例如,通过使用 运行),则所有文件都将报告为ADDED,无论之前的状态如何。在这种情况下,Gradle 会自动删除之前的输出,因此增量任务必须只处理给定的文件。
对于像上面的示例这样的简单转换器任务,任务操作必须为任何过时的输入生成输出文件,并为任何已删除的输入删除输出文件。
|
重要的
|
一个任务可能只包含一个增量任务操作。 |
哪些输入被认为是过时的?
当之前执行过某个任务,并且执行后唯一的更改是增量输入文件属性时,Gradle 可以智能地确定需要处理哪些输入文件,这一概念称为增量执行。
在这种情况下,类InputChanges.getFileChanges()中可用的方法org.gradle.work.InputChanges提供与给定属性关联的所有输入文件的详细信息,这些输入文件已被ADDED、REMOVED或MODIFIED。
然而,很多情况下Gradle无法确定哪些输入文件需要处理(即非增量执行)。示例包括:
-
没有先前执行的可用历史记录。
-
您正在使用不同版本的 Gradle 进行构建。目前,Gradle 不使用不同版本的任务历史记录。
-
upToDateWhen添加到任务中的条件返回false。 -
自上次执行以来,输入属性已更改。
-
自上次执行以来,非增量输入文件属性已更改。
-
自上次执行以来,一个或多个输出文件已更改。
在这些情况下,Gradle 会将所有输入文件报告为ADDED,并且该getFileChanges()方法将返回构成给定输入属性的所有文件的详细信息。
您可以使用该方法检查任务执行是否是增量的InputChanges.isIncremental()。
正在执行的增量任务
IncrementalReverseTask考虑第一次针对一组输入执行的实例。
在这种情况下,将考虑所有输入ADDED,如下所示:
tasks.register<IncrementalReverseTask>("incrementalReverse") {
inputDir = file("inputs")
outputDir = layout.buildDirectory.dir("outputs")
inputProperty = project.findProperty("taskInputProperty") as String? ?: "original"
}tasks.register('incrementalReverse', IncrementalReverseTask) {
inputDir = file('inputs')
outputDir = layout.buildDirectory.dir("outputs")
inputProperty = project.properties['taskInputProperty'] ?: 'original'
}构建布局:
.
├── build.gradle
└── inputs
├── 1.txt
├── 2.txt
└── 3.txt$ gradle -q incrementalReverse
Executing non-incrementally
ADDED: 1.txt
ADDED: 2.txt
ADDED: 3.txt当然,当任务没有任何改变地再次执行时,那么整个任务就是UP-TO-DATE,并且任务动作不会被执行:
$ gradle incrementalReverse
> Task :incrementalReverse UP-TO-DATE
BUILD SUCCESSFUL in 0s
1 actionable task: 1 up-to-date当以某种方式修改输入文件或添加新的输入文件时,重新执行任务会导致InputChanges.getFileChanges().
以下示例在运行增量任务之前修改一个文件的内容并添加另一个文件:
tasks.register("updateInputs") {
val inputsDir = layout.projectDirectory.dir("inputs")
outputs.dir(inputsDir)
doLast {
inputsDir.file("1.txt").asFile.writeText("Changed content for existing file 1.")
inputsDir.file("4.txt").asFile.writeText("Content for new file 4.")
}
}tasks.register('updateInputs') {
def inputsDir = layout.projectDirectory.dir('inputs')
outputs.dir(inputsDir)
doLast {
inputsDir.file('1.txt').asFile.text = 'Changed content for existing file 1.'
inputsDir.file('4.txt').asFile.text = 'Content for new file 4.'
}
}$ gradle -q updateInputs incrementalReverse Executing incrementally MODIFIED: 1.txt ADDED: 4.txt
|
笔记
|
各种突变任务(updateInputs、removeInput等)仅用于演示增量任务的行为。它们不应被视为您应该在自己的构建脚本中拥有的任务类型或任务实现。
|
InputChanges.getFileChanges()当删除现有输入文件时,重新执行任务会导致as返回该文件REMOVED。
以下示例在执行增量任务之前删除现有文件之一:
tasks.register<Delete>("removeInput") {
delete("inputs/3.txt")
}tasks.register('removeInput', Delete) {
delete 'inputs/3.txt'
}$ gradle -q removeInput incrementalReverse Executing incrementally REMOVED: 3.txt
当删除(或修改)输出文件时,Gradle 无法确定哪些输入文件已过期。在这种情况下,给定属性的所有输入文件的详细信息都由InputChanges.getFileChanges().
以下示例从构建目录中删除输出文件之一。但是,所有输入文件都被视为ADDED:
tasks.register<Delete>("removeOutput") {
delete(layout.buildDirectory.file("outputs/1.txt"))
}tasks.register('removeOutput', Delete) {
delete layout.buildDirectory.file("outputs/1.txt")
}$ gradle -q removeOutput incrementalReverse Executing non-incrementally ADDED: 1.txt ADDED: 2.txt ADDED: 3.txt
我们要介绍的最后一个场景涉及修改非基于文件的输入属性时会发生什么。在这种情况下,Gradle 无法确定该属性如何影响任务输出,因此任务以非增量方式执行。这意味着给定属性的所有InputChanges.getFileChanges()输入文件都由 返回,并且它们都被视为ADDED.
以下示例taskInputProperty在运行任务时将项目属性设置为新值incrementalReverse。该项目属性用于初始化任务的属性,如本节第一个示例inputProperty中所示。
这是本例中的预期输出:
$ gradle -q -PtaskInputProperty=changed incrementalReverse Executing non-incrementally ADDED: 1.txt ADDED: 2.txt ADDED: 3.txt
命令行选项
有时,用户希望在命令行而不是构建脚本上声明公开任务属性的值。如果属性值更改更频繁,则在命令行上传递属性值特别有用。
任务API支持标记属性的机制,以在运行时自动生成具有特定名称的相应命令行参数。
步骤 1. 声明命令行选项
要公开任务属性的新命令行选项,请使用Option注释属性的相应 setter 方法:
@Option(option = "flag", description = "Sets the flag")选项需要强制标识符。您可以提供可选的描述。
任务可以公开与类中可用属性一样多的命令行选项。
选项也可以在任务类的超级接口中声明。如果多个接口声明相同的属性但具有不同的选项标志,则它们都将用于设置该属性。
在下面的示例中,自定义任务UrlVerify通过进行 HTTP 调用并检查响应代码来验证是否可以解析 URL。要验证的 URL 可以通过 属性进行配置url。该属性的 setter 方法用@Option注释:
import org.gradle.api.tasks.options.Option;
public class UrlVerify extends DefaultTask {
private String url;
@Option(option = "url", description = "Configures the URL to be verified.")
public void setUrl(String url) {
this.url = url;
}
@Input
public String getUrl() {
return url;
}
@TaskAction
public void verify() {
getLogger().quiet("Verifying URL '{}'", url);
// verify URL by making a HTTP call
}
}为任务声明的所有选项都可以通过运行任务和选项呈现为控制台输出。help--task
步骤 2. 在命令行上使用选项
命令行上的选项有一些规则:
-
该选项使用双破折号作为前缀,例如
--url。单个破折号不符合任务选项的有效语法。 -
选项参数直接跟在任务声明之后,例如
verifyUrl --url=http://www.google.com/。 -
可以在命令行上紧跟任务名称的任意顺序声明多个任务选项。
在前面的示例的基础上,构建脚本创建一个类型的任务实例UrlVerify,并通过公开的选项从命令行提供一个值:
tasks.register<UrlVerify>("verifyUrl")tasks.register('verifyUrl', UrlVerify)$ gradle -q verifyUrl --url=http://www.google.com/ Verifying URL 'http://www.google.com/'
选项支持的数据类型
Gradle 限制了可用于声明命令行选项的数据类型。
命令行的使用因类型而异:
boolean,Boolean,Property<Boolean>-
true描述带有值或 的选项false。
在命令行上传递选项会将值视为true。例如,--foo等于true。
如果缺少该选项,则使用该属性的默认值。对于每个布尔选项,都会自动创建一个相反的选项。例如,--no-foo是为提供的选项创建的--foo,--bar是为 创建的--no-bar。名称以 开头的选项--no是禁用选项,并将选项值设置为false。仅当任务不存在同名选项时才会创建相反的选项。 Double,Property<Double>-
描述具有双精度值的选项。
在命令行上传递选项还需要一个值,例如--factor=2.2或--factor 2.2。 Integer,Property<Integer>-
描述具有整数值的选项。
在命令行上传递选项还需要一个值,例如--network-timeout=5000或--network-timeout 5000。 Long,Property<Long>-
描述具有长值的选项。
在命令行上传递选项还需要一个值,例如--threshold=2147483648或--threshold 2147483648。 String,Property<String>-
描述具有任意字符串值的选项。
在命令行上传递选项还需要一个值,例如--container-id=2x94held或--container-id 2x94held。 enum,Property<enum>-
将选项描述为枚举类型。
在命令行上传递选项还需要一个值,例如--log-level=DEBUG或--log-level debug。
该值不区分大小写。 List<T>哪里,,,,TDoubleIntegerLongStringenum-
描述可以采用给定类型的多个值的选项。
选项的值必须作为多个声明提供,例如--image-id=123 --image-id=456.
目前不支持其他表示法,例如逗号分隔的列表或由空格字符分隔的多个值。 ListProperty<T>,SetProperty<T>哪里,,,,TDoubleIntegerLongStringenum-
描述可以采用给定类型的多个值的选项。
选项的值必须作为多个声明提供,例如--image-id=123 --image-id=456.
目前不支持其他表示法,例如逗号分隔的列表或由空格字符分隔的多个值。 DirectoryProperty,RegularFileProperty-
描述带有文件系统元素的选项。
在命令行上传递选项还需要一个表示路径的值,例如--output-file=file.txt或--output-dir outputDir。
相对路径是相对于拥有此属性实例的项目的项目目录进行解析的。看FileSystemLocationProperty.set()。
记录选项的可用值
理论上,属性类型String或选项List<String>可以接受任何任意值。可以借助注释OptionValues以编程方式记录此类选项的可接受值:
@OptionValues('file')可以将此注释分配给返回List受支持数据类型之一的任何方法。您需要指定一个选项标识符来指示选项和可用值之间的关系。
|
笔记
|
在命令行上传递选项不支持的值不会使构建失败或引发异常。您必须在任务操作中实现此类行为的自定义逻辑。 |
下面的示例演示了对单个任务使用多个选项。任务实现提供了选项的可用值列表output-type:
import org.gradle.api.tasks.options.Option;
import org.gradle.api.tasks.options.OptionValues;
public abstract class UrlProcess extends DefaultTask {
private String url;
private OutputType outputType;
@Input
@Option(option = "http", description = "Configures the http protocol to be allowed.")
public abstract Property<Boolean> getHttp();
@Option(option = "url", description = "Configures the URL to send the request to.")
public void setUrl(String url) {
if (!getHttp().getOrElse(true) && url.startsWith("http://")) {
throw new IllegalArgumentException("HTTP is not allowed");
} else {
this.url = url;
}
}
@Input
public String getUrl() {
return url;
}
@Option(option = "output-type", description = "Configures the output type.")
public void setOutputType(OutputType outputType) {
this.outputType = outputType;
}
@OptionValues("output-type")
public List<OutputType> getAvailableOutputTypes() {
return new ArrayList<OutputType>(Arrays.asList(OutputType.values()));
}
@Input
public OutputType getOutputType() {
return outputType;
}
@TaskAction
public void process() {
getLogger().quiet("Writing out the URL response from '{}' to '{}'", url, outputType);
// retrieve content from URL and write to output
}
private static enum OutputType {
CONSOLE, FILE
}
}列出命令行选项
使用注释Option和OptionValues的命令行选项是自记录的。
$ gradle -q help --task processUrl
Detailed task information for processUrl
Path
:processUrl
Type
UrlProcess (UrlProcess)
Options
--http Configures the http protocol to be allowed.
--no-http Disables option --http.
--output-type Configures the output type.
Available values are:
CONSOLE
FILE
--url Configures the URL to send the request to.
--rerun Causes the task to be re-run even if up-to-date.
Description
-
Group
-
局限性
目前对声明命令行选项的支持存在一些限制。
-
只能通过注释为自定义任务声明命令行选项。没有用于定义选项的编程等效项。
-
选项不能全局声明,例如,在项目级别或作为插件的一部分。
-
当在命令行上分配选项时,需要明确说明暴露该选项的任务,例如,即使该任务依赖于该任务
gradle check --tests abc,也不起作用。checktest -
如果您指定的任务选项名称与内置 Gradle 选项的名称冲突,请
--在调用任务之前使用分隔符来引用该选项。有关详细信息,请参阅消除任务选项与内置选项的歧义。
验证失败
通常,任务执行期间引发的异常会导致失败并立即终止构建。任务的结果将为FAILED,构建的结果将为FAILED,并且不会执行进一步的任务。当使用标志运行--continue时,Gradle 在遇到任务失败后将继续运行构建中的其他请求的任务。但是,任何依赖于失败任务的任务都不会被执行。
有一种特殊类型的异常,当下游任务仅依赖于失败任务的输出时,其行为会有所不同。任务可以抛出VerificationException的子类型来指示它以受控方式失败,以便其输出对使用者仍然有效。当一个任务直接依赖于另一个任务的结果时,它依赖于另一个任务的结果dependsOn。当 Gradle 使用 运行时--continue,依赖于生产者任务输出(通过任务输入和输出之间的关系)的消费者任务在消费者失败后仍然可以运行。
例如,失败的单元测试将导致测试任务失败。但是,这并不能阻止另一个任务读取和处理该任务生成的(有效)测试结果。验证失败正是以这种方式使用的Test Report Aggregation Plugin。
验证失败对于即使在产生其他任务可消耗的有用输出之后也需要报告失败的任务也很有用。
val process = tasks.register("process") {
val outputFile = layout.buildDirectory.file("processed.log")
outputs.files(outputFile) // (1)
doLast {
val logFile = outputFile.get().asFile
logFile.appendText("Step 1 Complete.") // (2)
throw VerificationException("Process failed!") // (3)
logFile.appendText("Step 2 Complete.") // (4)
}
}
tasks.register("postProcess") {
inputs.files(process) // (5)
doLast {
println("Results: ${inputs.files.singleFile.readText()}") // (6)
}
}tasks.register("process") {
def outputFile = layout.buildDirectory.file("processed.log")
outputs.files(outputFile) // (1)
doLast {
def logFile = outputFile.get().asFile
logFile << "Step 1 Complete." // (2)
throw new VerificationException("Process failed!") // (3)
logFile << "Step 2 Complete." // (4)
}
}
tasks.register("postProcess") {
inputs.files(tasks.named("process")) // (5)
doLast {
println("Results: ${inputs.files.singleFile.text}") // (6)
}
}$ gradle postProcess --continue > Task :process FAILED > Task :postProcess Results: Step 1 Complete. 2 actionable tasks: 2 executed FAILURE: Build failed with an exception.
-
注册输出:
process任务将其输出写入日志文件。 -
修改输出:任务在执行时写入其输出文件。
-
任务失败:任务抛出 a
VerificationException并在此时失败。 -
继续修改输出:由于异常停止任务,该行永远不会运行。
-
使用输出:由于使用任务的输出作为其自己的输入,因此
postProcess任务取决于任务的输出。process -
使用部分结果:设置标志后,尽管任务失败,
--continueGradle 仍会运行请求的任务。可以读取并显示部分(尽管仍然有效)结果。postProcessprocesspostProcess
开发插件
了解插件
Gradle 附带了一套强大的核心系统,例如依赖管理、任务执行、项目配置等。但它能做的其他事情都是由插件提供的。
插件封装特定任务或集成的逻辑,例如编译代码、运行测试或部署工件。通过应用插件,用户可以轻松地将新功能添加到其构建过程中,而无需从头开始编写复杂的代码。
这种基于插件的方法使 Gradle 变得轻量级和模块化。它还促进了代码重用和可维护性,因为插件可以在项目之间或组织内共享。
插件介绍
插件可以来自 Gradle 或 Gradle 社区。但是,当用户想要组织他们的构建逻辑或需要现有插件未提供的特定构建功能时,他们可以开发自己的插件。
因此,我们区分三种不同类型的插件:
-
核心插件- 来自 Gradle 的插件。
-
社区插件- 来自Gradle 插件门户或公共存储库的插件。
-
本地或自定义插件- 您自己开发的插件。
社区插件
术语“社区插件”是指发布到 Gradle 插件门户(或其他公共存储库)的插件,例如Spotless 插件。
本地或自定义插件
术语本地或自定义插件是指您自己为自己的构建编写的插件。
自定义插件
自定义插件分为三种类型:
| # | 类型 | 地点: | 最有可能的: | 益处: |
|---|---|---|---|---|
构建脚本或脚本 |
本地插件 |
插件会自动编译并包含在构建脚本的类路径中。 |
||
一个约定插件 |
插件会自动编译、测试并在构建脚本的类路径上可用。该插件对于构建使用的每个构建脚本都是可见的。 |
|||
独立项目 |
一个共享插件 |
插件 JAR 已制作并发布。该插件可以在多个版本中使用并与其他人共享。 |
构建脚本和脚本插件
构建脚本插件通常是在构建文件中编写的小型本地插件,用于特定于单个构建或项目的任务,并且不需要在多个项目中重用。不推荐使用构建脚本插件,但许多其他形式的插件是从构建脚本插件演变而来的。
要创建 Gradle 插件,您需要在构建文件之一中编写一个实现Plugin接口的类。
以下示例创建一个GreetingPlugin,它将hello任务添加到项目中:
class GreetingPlugin : Plugin<Project> {
override fun apply(project: Project) {
project.task("hello") {
doLast {
println("Hello from the GreetingPlugin")
}
}
}
}
// Apply the plugin
apply<GreetingPlugin>()class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
project.task('hello') {
doLast {
println 'Hello from the GreetingPlugin'
}
}
}
}
// Apply the plugin
apply plugin: GreetingPlugin$ gradle -q hello Hello from the GreetingPlugin
该Project对象作为参数传递apply(),插件可以根据需要使用它来配置项目(例如添加任务、配置依赖项等)
脚本插件apply(from = " ")与构建脚本插件类似,但是,插件定义只是在单独的脚本中完成,然后使用或将其应用于构建文件apply from: '':不建议使用脚本插件。
class GreetingScriptPlugin : Plugin<Project> {
override fun apply(project: Project) {
project.task("hi") {
doLast {
println("Hi from the GreetingScriptPlugin")
}
}
}
}
// Apply the plugin
apply<GreetingScriptPlugin>()class GreetingScriptPlugin implements Plugin<Project> {
void apply(Project project) {
project.task('hi') {
doLast {
println 'Hi from the GreetingScriptPlugin'
}
}
}
}
// Apply the plugin
apply plugin: GreetingScriptPluginapply(from = "other.gradle.kts")apply from: 'other.gradle'$ gradle -q hi Hi from the GreetingScriptPlugin
预编译脚本插件
预编译脚本插件在执行之前会被编译成类文件并打包成 JAR。这些插件使用 Groovy 或 Kotlin DSL,而不是纯 Java、Kotlin 或 Groovy。它们最好用作跨项目共享构建逻辑的约定插件,或者作为整齐组织构建逻辑的一种方式。
要创建预编译脚本插件,您可以:
-
使用 Gradle 的 Kotlin DSL - 插件是一个
.gradle.kts文件,并应用id("kotlin-dsl"). -
使用 Gradle 的 Groovy DSL - 该插件是一个
.gradle文件,并应用id("groovy-gradle-plugin").
要应用预编译脚本插件,您需要知道其ID。 ID 源自插件脚本的文件名及其(可选)包声明。
例如,该脚本src/main/*/java-library.gradle(.kts)的插件 ID 为java-library(假设它没有包声明)。同样,只要它的包声明为 ,src/main/*/my/java-library.gradle(.kts)就有一个插件 ID 。my.java-librarymy
预编译脚本插件名称有两个重要的限制:
-
他们不能从 开始
org.gradle。 -
它们不能与核心插件同名。
当插件应用于项目时,Gradle 会创建插件类的实例并调用该实例的Plugin.apply()方法。
|
笔记
|
Plugin在应用该插件的每个项目中都会创建
一个新的 a 实例。 |
让我们将GreetingPlugin脚本插件重写为预编译脚本插件。由于我们使用的是 Groovy 或 Kotlin DSL,因此该文件本质上成为插件。原始脚本插件只是创建了一个hello打印问候语的任务,这就是我们将在预编译脚本插件中执行的操作:
tasks.register("hello") {
doLast {
println("Hello from the convention GreetingPlugin")
}
}tasks.register("hello") {
doLast {
println("Hello from the convention GreetingPlugin")
}
}现在可以使用其 ID将其GreetingPlugin应用于其他子项目的构建中:
plugins {
application
id("GreetingPlugin")
}plugins {
id 'application'
id('GreetingPlugin')
}$ gradle -q hello Hello from the convention GreetingPlugin
约定插件
约定插件通常是预编译的脚本插件,它使用您自己的约定(即默认值)配置现有的核心和社区插件,例如使用java.toolchain.languageVersion = JavaLanguageVersion.of(17).约定插件还用于执行项目标准并帮助简化构建过程。他们可以应用和配置插件、创建新任务和扩展、设置依赖项等等。
让我们以包含三个子项目的构建为例:一个用于data-model,一个用于database-logic,一个用于app代码。该项目具有以下结构:
.
├── buildSrc
│ ├── src
│ │ └──...
│ └── build.gradle.kts
├── data-model
│ ├── src
│ │ └──...
│ └── build.gradle.kts
├── database-logic
│ ├── src
│ │ └──...
│ └── build.gradle.kts
├── app
│ ├── src
│ │ └──...
│ └── build.gradle.kts
└── settings.gradle.kts子项目的build文件database-logic如下:
plugins {
id("java-library")
id("org.jetbrains.kotlin.jvm") version "1.9.23"
}
repositories {
mavenCentral()
}
java {
toolchain.languageVersion.set(JavaLanguageVersion.of(11))
}
tasks.test {
useJUnitPlatform()
}
kotlin {
jvmToolchain(11)
}
// More build logicplugins {
id 'java-library'
id 'org.jetbrains.kotlin.jvm' version '1.9.23'
}
repositories {
mavenCentral()
}
java {
toolchain.languageVersion.set(JavaLanguageVersion.of(11))
}
tasks.test {
useJUnitPlatform()
}
kotlin {
jvmToolchain {
languageVersion.set(JavaLanguageVersion.of(11))
}
}
// More build logic我们应用该java-library插件并添加该org.jetbrains.kotlin.jvm插件以支持 Kotlin。我们还配置 Kotlin、Java、测试等。
我们的构建文件开始增长......
我们应用的插件越多,配置的插件越多,它就越大。app和子项目的构建文件中也存在重复data-model,尤其是在配置常见扩展(例如设置 Java 版本和 Kotlin 支持)时。
为了解决这个问题,我们使用约定插件。这使我们能够避免在每个构建文件中重复配置,并使我们的构建脚本更加简洁和可维护。在约定插件中,我们可以封装任意构建配置或自定义构建逻辑。
要开发约定插件,我们建议使用buildSrc– 它代表完全独立的 Gradle 构建。
buildSrc有自己的设置文件来定义此构建的依赖项所在的位置。
my-java-library.gradle.kts我们在目录中添加一个名为的 Kotlin 脚本buildSrc/src/main/kotlin。或者相反,在目录my-java-library.gradle内调用 Groovy 脚本buildSrc/src/main/groovy。我们将构建文件中的所有插件应用程序和配置放入database-logic其中:
plugins {
id("java-library")
id("org.jetbrains.kotlin.jvm")
}
repositories {
mavenCentral()
}
java {
toolchain.languageVersion.set(JavaLanguageVersion.of(11))
}
tasks.test {
useJUnitPlatform()
}
kotlin {
jvmToolchain(11)
}plugins {
id 'java-library'
id 'org.jetbrains.kotlin.jvm'
}
repositories {
mavenCentral()
}
java {
toolchain.languageVersion.set(JavaLanguageVersion.of(11))
}
tasks.test {
useJUnitPlatform()
}
kotlin {
jvmToolchain {
languageVersion.set(JavaLanguageVersion.of(11))
}
}该文件的名称my-java-library是我们全新插件的 ID,我们现在可以在所有子项目中使用它。
|
提示
|
为什么版本id 'org.jetbrains.kotlin.jvm'不见了?请参阅将外部插件应用于预编译脚本插件。
|
database-logic通过删除所有冗余的构建逻辑并应用我们的约定插件,构建文件变得更加简单my-java-library:
plugins {
id("my-java-library")
}plugins {
id('my-java-library')
}这个约定插件使我们能够轻松地在所有构建文件之间共享通用配置。任何修改都可以在一处进行,从而简化了维护。
二进制插件
Gradle 中的二进制插件是作为独立 JAR 文件构建并使用plugins{}构建脚本中的块应用于项目的插件。
让我们将其转移GreetingPlugin到一个独立的项目,以便我们可以发布它并与其他人共享。该插件本质上是从该buildSrc文件夹移动到其自己的名为greeting-plugin.
|
笔记
|
您可以从 发布插件buildSrc,但不建议这样做。准备发布的插件应该是它们自己的版本。
|
greeting-plugin只是一个生成包含插件类的 JAR 的 Java 项目。
将插件打包并发布到存储库的最简单方法是使用Gradle Plugin Development Plugin。该插件提供了必要的任务和配置(包括插件元数据),将您的脚本编译为可应用于其他版本的插件。
greeting-plugin这是使用 Gradle Plugin 开发插件的项目的简单构建脚本:
plugins {
`java-gradle-plugin`
}
gradlePlugin {
plugins {
create("simplePlugin") {
id = "org.example.greeting"
implementationClass = "org.example.GreetingPlugin"
}
}
}plugins {
id 'java-gradle-plugin'
}
gradlePlugin {
plugins {
simplePlugin {
id = 'org.example.greeting'
implementationClass = 'org.example.GreetingPlugin'
}
}
}有关发布插件的更多信息,请参阅发布插件。
项目 vs 设置 vs 初始化插件
这几种插件的区别在于它们的应用范围:
- 项目插件
-
项目插件是应用于构建中的特定项目的插件。它可以自定义构建逻辑、添加任务以及配置特定于项目的设置。
- 设置插件
-
settings.gradle设置插件是在或文件中应用的插件settings.gradle.kts。它可以配置适用于整个构建的设置,例如定义构建中包含哪些项目、配置构建脚本存储库以及将通用配置应用于所有项目。 - 初始化插件
-
init.gradleinit 插件是在或文件中应用的插件init.gradle.kts。它可以配置全局适用于计算机上所有 Gradle 构建的设置,例如配置 Gradle 版本、设置默认存储库或将通用插件应用于所有构建。
了解插件的实施选项
脚本、预编译脚本或二进制插件之间的选择取决于您的具体要求和偏好。
脚本插件简单且易于编写,因为它们直接编写在构建脚本中。它们是用 Kotlin DSL 或 Groovy DSL 编写的。它们适合小型、一次性任务或快速实验。然而,随着构建脚本的大小和复杂性的增加,它们可能会变得难以维护。
预编译脚本插件是编译成打包在库中的 Java 类文件的 Kotlin DSL 脚本。与脚本插件相比,它们提供更好的性能和可维护性,并且可以在不同的项目中重用。您也可以用 Groovy DSL 编写它们,但不建议这样做。
二进制插件是用 Java 或 Kotlin 编写的成熟插件,编译成 JAR 文件并发布到存储库。它们提供最佳的性能、可维护性和可重用性。它们适用于需要在项目、构建和团队之间共享的复杂构建逻辑。您也可以用 Scala 或 Groovy 编写它们,但不建议这样做。
以下是实现 Gradle 插件的所有选项的细分:
| # | 使用: | 类型: | 该插件是: | 通过应用创建: | 受到推崇的? |
|---|---|---|---|---|---|
1 |
KotlinDSL |
脚本插件 |
作为实现接口方法的 |
|
否[ 1 ] |
2 |
Groovy DSL |
脚本插件 |
作为实现接口方法的 |
|
否[ 1 ] |
3 |
KotlinDSL |
预编译脚本插件 |
一份 |
|
是的[ 2 ] |
4 |
Groovy DSL |
预编译脚本插件 |
一份 |
|
否[ 3 ] |
5 |
KotlinDSL |
二进制插件 |
一份 |
|
是的[ 2 ] |
6 |
Groovy DSL |
二进制插件 |
一份 |
|
没有[ 2 ] |
7 |
Java |
二进制插件 |
|
|
是的[ 2 ] |
8 |
Kotlin |
二进制插件 |
|
|
是的[ 2 ] |
9 |
Groovy |
二进制插件 |
|
|
没有[ 2 ] |
10 |
Scala |
二进制插件 |
|
|
没有[ 2 ] |
实现预编译脚本插件
预编译脚本插件通常是 Kotlin 脚本,已编译并作为打包在库中的 Java 类文件分发。这些脚本旨在作为二进制 Gradle 插件使用,并建议用作约定插件。
约定插件是通常使用您自己的约定(即默认值)配置现有核心和社区插件的插件,例如使用java.toolchain.languageVersion = JavaLanguageVersion.of(17).约定插件还用于执行项目标准并帮助简化构建过程。他们可以应用和配置插件、创建新任务和扩展、设置依赖项等等。
设置插件ID
预编译脚本的插件 ID 源自其文件名和可选包声明。
例如,code-quality.gradle(.kts)位于src/main/groovy(或src/main/kotlin) 中但没有包声明的名为的脚本将作为code-quality插件公开:
plugins {
id("code-quality")
}另一方面,code-quality.gradle(.kts)位于src/main/groovy/my(或src/main/kotlin/my) 中且带有包声明的名为的脚本my将作为my.code-quality插件公开:
plugins {
id("my.code-quality")
}处理文件
让我们首先创建一个名为的约定插件greetings:
// Create extension object
interface GreetingPluginExtension {
val message: Property<String>
}// Create extension object
interface GreetingPluginExtension {
Property<String> getMessage()
}您可以在使用文件中找到有关延迟处理文件的更多信息。
使用扩展使插件可配置
扩展对象通常在插件中用于公开配置选项和附加功能来构建脚本。
当您应用定义扩展的插件时,您可以访问扩展对象并配置其属性或调用其方法来自定义插件的行为或插件提供的任务。
项目有一个关联的ExtensionContainer对象,其中包含已应用于项目的插件的所有设置和属性。您可以通过向此容器添加扩展对象来为您的插件提供配置。
让我们更新我们的greetings示例:
// Create extension object
interface GreetingPluginExtension {
val message: Property<String>
}
// Add the 'greeting' extension object to project
val extension = project.extensions.create<GreetingPluginExtension>("greeting")// Create extension object
interface GreetingPluginExtension {
Property<String> getMessage()
}
// Add the 'greeting' extension object to project
def extension = project.extensions.create("greeting", GreetingPluginExtension)message您可以直接使用 来设置属性的值extension.message.set("Hi from Gradle,")。
但是,该GreetingPluginExtension对象可用作与扩展对象同名的项目属性。您现在可以message像这样访问:
// Where the<GreetingPluginExtension>() is equivalent to project.extensions.getByType(GreetingPluginExtension::class.java)
the<GreetingPluginExtension>().message.set("Hi from Gradle")extensions.findByType(GreetingPluginExtension).message.set("Hi from Gradle")如果您应用该greetings插件,您可以在构建脚本中设置约定:
plugins {
application
id("greetings")
}
greeting {
message = "Hello from Gradle"
}plugins {
id 'application'
id('greetings')
}
configure(greeting) {
message = "Hello from Gradle"
}添加默认配置作为约定
在插件中,您可以使用对象定义默认值,也称为约定project。
约定属性是使用默认值初始化但可以覆盖的属性:
// Create extension object
interface GreetingPluginExtension {
val message: Property<String>
}
// Add the 'greeting' extension object to project
val extension = project.extensions.create<GreetingPluginExtension>("greeting")
// Set a default value for 'message'
extension.message.convention("Hello from Gradle")// Create extension object
interface GreetingPluginExtension {
Property<String> getMessage()
}
// Add the 'greeting' extension object to project
def extension = project.extensions.create("greeting", GreetingPluginExtension)
// Set a default value for 'message'
extension.message.convention("Hello from Gradle")extension.message.convention(…)message为扩展的属性设置约定。此约定指定 的值应默认为位于项目构建目录中的message名为的文件的内容。defaultGreeting.txt
如果message未显式设置该属性,则其值将自动设置为 的内容defaultGreeting.txt。
将扩展属性映射到任务属性
使用扩展并将其映射到自定义任务的输入/输出属性在插件中很常见。
在此示例中, 的 message 属性GreetingPluginExtension映射到GreetingTask作为输入的 的 message 属性:
// Create extension object
interface GreetingPluginExtension {
val message: Property<String>
}
// Add the 'greeting' extension object to project
val extension = project.extensions.create<GreetingPluginExtension>("greeting")
// Set a default value for 'message'
extension.message.convention("Hello from Gradle")
// Create a greeting task
abstract class GreetingTask : DefaultTask() {
@Input
val message = project.objects.property<String>()
@TaskAction
fun greet() {
println("Message: ${message.get()}")
}
}
// Register the task and set the convention
tasks.register<GreetingTask>("hello") {
message.convention(extension.message)
}// Create extension object
interface GreetingPluginExtension {
Property<String> getMessage()
}
// Add the 'greeting' extension object to project
def extension = project.extensions.create("greeting", GreetingPluginExtension)
// Set a default value for 'message'
extension.message.convention("Hello from Gradle")
// Create a greeting task
abstract class GreetingTask extends DefaultTask {
@Input
abstract Property<String> getMessage()
@TaskAction
void greet() {
println("Message: ${message.get()}")
}
}
// Register the task and set the convention
tasks.register("hello", GreetingTask) {
message.convention(extension.message)
}$ gradle -q hello Message: Hello from Gradle
这意味着对扩展message属性的更改将触发任务被视为过期,从而确保使用新消息重新执行任务。
您可以在延迟配置中找到有关可在任务实现和扩展中使用的类型的更多信息。
应用外部插件
为了在预编译脚本插件中应用外部插件,必须将其添加到插件构建文件中插件项目的实现类路径中:
plugins {
`kotlin-dsl`
}
repositories {
mavenCentral()
}
dependencies {
implementation("com.bmuschko:gradle-docker-plugin:6.4.0")
}plugins {
id 'groovy-gradle-plugin'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'com.bmuschko:gradle-docker-plugin:6.4.0'
}然后可以将其应用到预编译脚本插件中:
plugins {
id("com.bmuschko.docker-remote-api")
}plugins {
id 'com.bmuschko.docker-remote-api'
}这种情况下的插件版本是在依赖声明中定义的。
实施二进制插件
二进制插件是指以 JAR 文件形式编译和分发的插件。这些插件通常用 Java 或 Kotlin 编写,并为 Gradle 构建提供自定义功能或任务。
使用插件开发插件
Gradle Plugin Development 插件可用于协助开发 Gradle 插件。
该插件将自动应用Java Plugin,将gradleApi()依赖项添加到api配置中,在生成的 JAR 文件中生成所需的插件描述符,并配置发布时要使用的插件标记工件。
要应用和配置该插件,请将以下代码添加到您的构建文件中:
plugins {
`java-gradle-plugin`
}
gradlePlugin {
plugins {
create("simplePlugin") {
id = "org.example.greeting"
implementationClass = "org.example.GreetingPlugin"
}
}
}plugins {
id 'java-gradle-plugin'
}
gradlePlugin {
plugins {
simplePlugin {
id = 'org.example.greeting'
implementationClass = 'org.example.GreetingPlugin'
}
}
}开发插件时建议编写和使用自定义任务类型,因为它会自动受益于增量构建。将插件应用到项目的另一个好处是,该任务validatePlugins会自动检查自定义任务类型实现中定义的每个公共属性的现有输入/输出注释。
创建插件 ID
插件 ID 是全局唯一的,类似于 Java 包名称(即反向域名)。这种格式有助于防止命名冲突,并允许将具有相似所有权的插件分组。
显式插件标识符简化了将插件应用到项目的过程。您的插件 ID 应结合反映命名空间(指向您或您的组织的合理指针)及其提供的插件名称的组件。例如,如果您的 Github 帐户名为foo且您的插件名为bar,则合适的插件 ID 可能是com.github.foo.bar。同样,如果插件是在baz组织中开发的,则插件 ID 可能是org.baz.bar。
插件 ID 应遵循以下准则:
-
可以包含任何字母数字字符、“.”和“-”。
-
必须至少包含一个“.”将命名空间与插件名称分隔开的字符。
-
通常,命名空间使用小写反向域名约定。
-
通常,名称中仅使用小写字符。
-
org.gradle不能使用、com.gradle、 和命名空间。com.gradleware -
不能以“.”开头或结尾特点。
-
不能包含连续的“.”字符(即“..”)。
标识所有权和名称的命名空间对于插件 ID 来说就足够了。
将多个插件捆绑在单个 JAR 工件中时,建议遵循相同的命名约定。这种做法有助于对相关插件进行逻辑分组。
单个项目中可以定义和注册(通过不同标识符)的插件数量没有限制。
作为类编写的插件的标识符应在包含插件类的项目构建脚本中定义。为此,java-gradle-plugin需要应用:
plugins {
id("java-gradle-plugin")
}
gradlePlugin {
plugins {
create("androidApplicationPlugin") {
id = "com.android.application"
implementationClass = "com.android.AndroidApplicationPlugin"
}
create("androidLibraryPlugin") {
id = "com.android.library"
implementationClass = "com.android.AndroidLibraryPlugin"
}
}
}plugins {
id 'java-gradle-plugin'
}
gradlePlugin {
plugins {
androidApplicationPlugin {
id = 'com.android.application'
implementationClass = 'com.android.AndroidApplicationPlugin'
}
androidLibraryPlugin {
id = 'com.android.library'
implementationClass = 'com.android.AndroidLibraryPlugin'
}
}
}处理文件
开发插件时,在接受文件位置的输入配置时保持灵活性是个好主意。
建议使用 Gradle 的托管属性并project.layout选择文件或目录位置。这将启用延迟配置,以便仅在需要文件时才会解析实际位置,并且可以在构建配置期间随时重新配置。
此 Gradle 构建文件定义了一个GreetingToFileTask将问候语写入文件的任务。它还注册了两个任务:greet,它创建带有问候语的文件,以及sayGreeting,它打印文件的内容。该greetingFile属性用于指定问候语的文件路径:
abstract class GreetingToFileTask : DefaultTask() {
@get:OutputFile
abstract val destination: RegularFileProperty
@TaskAction
fun greet() {
val file = destination.get().asFile
file.parentFile.mkdirs()
file.writeText("Hello!")
}
}
val greetingFile = objects.fileProperty()
tasks.register<GreetingToFileTask>("greet") {
destination = greetingFile
}
tasks.register("sayGreeting") {
dependsOn("greet")
val greetingFile = greetingFile
doLast {
val file = greetingFile.get().asFile
println("${file.readText()} (file: ${file.name})")
}
}
greetingFile = layout.buildDirectory.file("hello.txt")abstract class GreetingToFileTask extends DefaultTask {
@OutputFile
abstract RegularFileProperty getDestination()
@TaskAction
def greet() {
def file = getDestination().get().asFile
file.parentFile.mkdirs()
file.write 'Hello!'
}
}
def greetingFile = objects.fileProperty()
tasks.register('greet', GreetingToFileTask) {
destination = greetingFile
}
tasks.register('sayGreeting') {
dependsOn greet
doLast {
def file = greetingFile.get().asFile
println "${file.text} (file: ${file.name})"
}
}
greetingFile = layout.buildDirectory.file('hello.txt')$ gradle -q sayGreeting Hello! (file: hello.txt)
在此示例中,我们将greet任务destination属性配置为闭包/提供程序,并使用Project.file(java.lang.Object)File方法对其进行评估,以在最后一刻将闭包/提供程序的返回值转换为对象。请注意,我们在任务配置之后greetingFile指定属性值。这种惰性评估是在设置文件属性时接受任何值然后在读取属性时解析该值的一个关键好处。
您可以在使用文件中了解有关延迟处理文件的更多信息。
使用扩展使插件可配置
大多数插件都提供构建脚本和其他插件的配置选项,以自定义插件的工作方式。插件使用扩展对象来完成此操作。
项目有一个关联的ExtensionContainer对象,其中包含已应用于项目的插件的所有设置和属性。您可以通过向此容器添加扩展对象来为您的插件提供配置。
扩展对象只是一个具有表示配置的 Java Bean 属性的对象。
让我们greeting向项目添加一个扩展对象,它允许您配置问候语:
interface GreetingPluginExtension {
val message: Property<String>
}
class GreetingPlugin : Plugin<Project> {
override fun apply(project: Project) {
// Add the 'greeting' extension object
val extension = project.extensions.create<GreetingPluginExtension>("greeting")
// Add a task that uses configuration from the extension object
project.task("hello") {
doLast {
println(extension.message.get())
}
}
}
}
apply<GreetingPlugin>()
// Configure the extension
the<GreetingPluginExtension>().message = "Hi from Gradle"interface GreetingPluginExtension {
Property<String> getMessage()
}
class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
// Add the 'greeting' extension object
def extension = project.extensions.create('greeting', GreetingPluginExtension)
// Add a task that uses configuration from the extension object
project.task('hello') {
doLast {
println extension.message.get()
}
}
}
}
apply plugin: GreetingPlugin
// Configure the extension
greeting.message = 'Hi from Gradle'$ gradle -q hello Hi from Gradle
在此示例中,GreetingPluginExtension是一个具有名为 的属性的对象message。扩展对象将添加到名为 的项目中greeting。该对象可用作与扩展对象同名的项目属性。
the<GreetingPluginExtension>()相当于project.extensions.getByType(GreetingPluginExtension::class.java).
通常,您需要在单个插件上指定多个相关属性。 Gradle 为每个扩展对象添加了一个配置块,因此您可以对设置进行分组:
interface GreetingPluginExtension {
val message: Property<String>
val greeter: Property<String>
}
class GreetingPlugin : Plugin<Project> {
override fun apply(project: Project) {
val extension = project.extensions.create<GreetingPluginExtension>("greeting")
project.task("hello") {
doLast {
println("${extension.message.get()} from ${extension.greeter.get()}")
}
}
}
}
apply<GreetingPlugin>()
// Configure the extension using a DSL block
configure<GreetingPluginExtension> {
message = "Hi"
greeter = "Gradle"
}interface GreetingPluginExtension {
Property<String> getMessage()
Property<String> getGreeter()
}
class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
def extension = project.extensions.create('greeting', GreetingPluginExtension)
project.task('hello') {
doLast {
println "${extension.message.get()} from ${extension.greeter.get()}"
}
}
}
}
apply plugin: GreetingPlugin
// Configure the extension using a DSL block
greeting {
message = 'Hi'
greeter = 'Gradle'
}$ gradle -q hello Hi from Gradle
在此示例中,可以将多个设置分组在configure<GreetingPluginExtension>块内。该configure函数用于配置扩展对象。它提供了一种设置属性或将配置应用于这些对象的便捷方法。构建脚本的configure函数 ( )中使用的类型GreetingPluginExtension必须与扩展类型匹配。然后,当块被执行时,块的接收者就是扩展。
在此示例中,可以将多个设置分组在greeting闭包内。构建脚本 ( ) 中闭包块的名称greeting必须与扩展对象名称匹配。然后,当执行闭包时,扩展对象上的字段将根据标准 Groovy 闭包委托功能映射到闭包内的变量。
声明 DSL 配置容器
使用扩展对象扩展Gradle DSL 来为插件添加项目属性和 DSL 块。由于扩展对象是常规对象,因此您可以通过向扩展对象添加属性和方法来提供嵌套在插件块内的自己的 DSL。
为了说明目的,我们考虑以下构建脚本。
plugins {
id("org.myorg.server-env")
}
environments {
create("dev") {
url = "http://localhost:8080"
}
create("staging") {
url = "http://staging.enterprise.com"
}
create("production") {
url = "http://prod.enterprise.com"
}
}plugins {
id 'org.myorg.server-env'
}
environments {
dev {
url = 'http://localhost:8080'
}
staging {
url = 'http://staging.enterprise.com'
}
production {
url = 'http://prod.enterprise.com'
}
}插件公开的 DSL 公开了一个用于定义一组环境的容器。用户配置的每个环境都有一个任意但声明性的名称,并用其自己的 DSL 配置块表示。上面的示例实例化了开发、暂存和生产环境,包括其各自的 URL。
每个环境都必须有代码中的数据表示形式来捕获值。环境的名称是不可变的,可以作为构造函数参数传入。目前,数据对象存储的唯一其他参数是 URL。
以下ServerEnvironment对象满足这些要求:
abstract public class ServerEnvironment {
private final String name;
@javax.inject.Inject
public ServerEnvironment(String name) {
this.name = name;
}
public String getName() {
return name;
}
abstract public Property<String> getUrl();
}Gradle 公开工厂方法 ObjectFactory.domainObjectContainer(Class, NamedDomainObjectFactory) 来创建数据对象的容器。该方法采用的参数是表示数据的类。创建的NamedDomainObjectContainer类型实例可以通过将其添加到具有特定名称的扩展容器来向最终用户公开。
插件通常会在插件实现中对捕获的值进行后处理,例如配置任务:
public class ServerEnvironmentPlugin implements Plugin<Project> {
@Override
public void apply(final Project project) {
ObjectFactory objects = project.getObjects();
NamedDomainObjectContainer<ServerEnvironment> serverEnvironmentContainer =
objects.domainObjectContainer(ServerEnvironment.class, name -> objects.newInstance(ServerEnvironment.class, name));
project.getExtensions().add("environments", serverEnvironmentContainer);
serverEnvironmentContainer.all(serverEnvironment -> {
String env = serverEnvironment.getName();
String capitalizedServerEnv = env.substring(0, 1).toUpperCase() + env.substring(1);
String taskName = "deployTo" + capitalizedServerEnv;
project.getTasks().register(taskName, Deploy.class, task -> task.getUrl().set(serverEnvironment.getUrl()));
});
}
}在上面的示例中,为每个用户配置的环境动态创建部署任务。
您可以在开发自定义 Gradle 类型中找到有关实现项目扩展的更多信息。
对类似 DSL 的 API 进行建模
插件公开的 DSL 应该可读且易于理解。
例如,让我们考虑插件提供的以下扩展。在当前形式中,它提供了一个“平面”属性列表,用于配置网站的创建:
plugins {
id("org.myorg.site")
}
site {
outputDir = layout.buildDirectory.file("mysite")
websiteUrl = "https://gradle.org"
vcsUrl = "https://github.com/gradle/gradle-site-plugin"
}plugins {
id 'org.myorg.site'
}
site {
outputDir = layout.buildDirectory.file("mysite")
websiteUrl = 'https://gradle.org'
vcsUrl = 'https://github.com/gradle/gradle-site-plugin'
}随着公开属性数量的增加,您应该引入一个嵌套的、更具表现力的结构。
以下代码片段添加了一个名为customData扩展的一部分的新配置块。这更有力地表明了这些属性的含义:
plugins {
id("org.myorg.site")
}
site {
outputDir = layout.buildDirectory.file("mysite")
customData {
websiteUrl = "https://gradle.org"
vcsUrl = "https://github.com/gradle/gradle-site-plugin"
}
}plugins {
id 'org.myorg.site'
}
site {
outputDir = layout.buildDirectory.file("mysite")
customData {
websiteUrl = 'https://gradle.org'
vcsUrl = 'https://github.com/gradle/gradle-site-plugin'
}
}实现此类扩展的支持对象很简单。首先,引入一个新的数据对象来管理属性websiteUrl和vcsUrl:
abstract public class CustomData {
abstract public Property<String> getWebsiteUrl();
abstract public Property<String> getVcsUrl();
}在扩展中,创建CustomData类的实例和方法以将捕获的值委托给数据实例。
要配置基础数据对象,请定义Action类型的参数。
Action以下示例演示了在扩展定义中的使用:
abstract public class SiteExtension {
abstract public RegularFileProperty getOutputDir();
@Nested
abstract public CustomData getCustomData();
public void customData(Action<? super CustomData> action) {
action.execute(getCustomData());
}
}将扩展属性映射到任务属性
插件通常使用扩展来捕获来自构建脚本的用户输入并将其映射到自定义任务的输入/输出属性。构建脚本作者与扩展的 DSL 交互,而插件实现则处理底层逻辑:
// Extension class to capture user input
class MyExtension {
@Input
var inputParameter: String? = null
}
// Custom task that uses the input from the extension
class MyCustomTask : org.gradle.api.DefaultTask() {
@Input
var inputParameter: String? = null
@TaskAction
fun executeTask() {
println("Input parameter: $inputParameter")
}
}
// Plugin class that configures the extension and task
class MyPlugin : Plugin<Project> {
override fun apply(project: Project) {
// Create and configure the extension
val extension = project.extensions.create("myExtension", MyExtension::class.java)
// Create and configure the custom task
project.tasks.register("myTask", MyCustomTask::class.java) {
group = "custom"
inputParameter = extension.inputParameter
}
}
}// Extension class to capture user input
class MyExtension {
@Input
String inputParameter = null
}
// Custom task that uses the input from the extension
class MyCustomTask extends DefaultTask {
@Input
String inputParameter = null
@TaskAction
def executeTask() {
println("Input parameter: $inputParameter")
}
}
// Plugin class that configures the extension and task
class MyPlugin implements Plugin<Project> {
void apply(Project project) {
// Create and configure the extension
def extension = project.extensions.create("myExtension", MyExtension)
// Create and configure the custom task
project.tasks.register("myTask", MyCustomTask) {
group = "custom"
inputParameter = extension.inputParameter
}
}
}在此示例中,MyExtension该类定义了一个inputParameter可以在构建脚本中设置的属性。该类MyPlugin配置此扩展并使用其inputParameter值来配置MyCustomTask任务。然后,任务MyCustomTask在其逻辑中使用此输入参数。
您可以在延迟配置中了解有关可在任务实现和扩展中使用的类型的更多信息。
添加带有约定的默认配置
插件应该在特定上下文中提供合理的默认值和标准,从而减少用户需要做出的决策数量。使用该project对象,您可以定义默认值。这些被称为约定。
约定是使用默认值初始化的属性,并且可以由用户在其构建脚本中覆盖。例如:
interface GreetingPluginExtension {
val message: Property<String>
}
class GreetingPlugin : Plugin<Project> {
override fun apply(project: Project) {
// Add the 'greeting' extension object
val extension = project.extensions.create<GreetingPluginExtension>("greeting")
extension.message.convention("Hello from GreetingPlugin")
// Add a task that uses configuration from the extension object
project.task("hello") {
doLast {
println(extension.message.get())
}
}
}
}
apply<GreetingPlugin>()interface GreetingPluginExtension {
Property<String> getMessage()
}
class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
// Add the 'greeting' extension object
def extension = project.extensions.create('greeting', GreetingPluginExtension)
extension.message.convention('Hello from GreetingPlugin')
// Add a task that uses configuration from the extension object
project.task('hello') {
doLast {
println extension.message.get()
}
}
}
}
apply plugin: GreetingPlugin$ gradle -q hello Hello from GreetingPlugin
在此示例中,GreetingPluginExtension是一个表示约定的类。 message 属性是约定属性,默认值为“Hello from GreetingPlugin”。
用户可以在其构建脚本中覆盖此值:
GreetingPluginExtension {
message = "Custom message"
}GreetingPluginExtension {
message = 'Custom message'
}$ gradle -q hello
Custom message将功能与约定分开
将插件中的功能与约定分开允许用户选择要应用的任务和约定。
例如,Java Base 插件提供了非固定(即通用)功能,如SourceSets,而 Java 插件添加了 Java 开发人员熟悉的任务和约定,如classes、jar或javadoc。
在设计自己的插件时,请考虑开发两个插件 - 一个用于功能,另一个用于约定 - 为用户提供灵活性。
在下面的示例中,MyPlugin包含约定并MyBasePlugin定义功能。然后,MyPlugin应用MyBasePlugin,这就是所谓的插件组合。要应用另一个插件的插件:
import org.gradle.api.Plugin;
import org.gradle.api.Project;
public class MyBasePlugin implements Plugin<Project> {
public void apply(Project project) {
// define capabilities
}
}import org.gradle.api.Plugin;
import org.gradle.api.Project;
public class MyPlugin implements Plugin<Project> {
public void apply(Project project) {
project.getPlugins().apply(MyBasePlugin.class);
// define conventions
}
}对插件做出反应
Gradle 插件实现中的一个常见模式是配置构建中现有插件和任务的运行时行为。
例如,插件可以假设它应用于基于 Java 的项目并自动重新配置标准源目录:
public class InhouseStrongOpinionConventionJavaPlugin implements Plugin<Project> {
public void apply(Project project) {
// Careful! Eagerly appyling plugins has downsides, and is not always recommended.
project.getPlugins().apply(JavaPlugin.class);
SourceSetContainer sourceSets = project.getExtensions().getByType(SourceSetContainer.class);
SourceSet main = sourceSets.getByName(SourceSet.MAIN_SOURCE_SET_NAME);
main.getJava().setSrcDirs(Arrays.asList("src"));
}
}这种方法的缺点是它会自动强制项目应用Java插件,对其施加强烈的意见(即降低灵活性和通用性)。实际上,应用该插件的项目甚至可能不处理 Java 代码。
该插件可以对使用项目应用 Java 插件的事实做出反应,而不是自动应用 Java 插件。只有在这种情况下,才会应用特定的配置:
public class InhouseConventionJavaPlugin implements Plugin<Project> {
public void apply(Project project) {
project.getPlugins().withType(JavaPlugin.class, javaPlugin -> {
SourceSetContainer sourceSets = project.getExtensions().getByType(SourceSetContainer.class);
SourceSet main = sourceSets.getByName(SourceSet.MAIN_SOURCE_SET_NAME);
main.getJava().setSrcDirs(Arrays.asList("src"));
});
}
}如果没有充分的理由假设使用的项目具有预期的设置,则对插件做出反应优于应用插件。
同样的概念也适用于任务类型:
public class InhouseConventionWarPlugin implements Plugin<Project> {
public void apply(Project project) {
project.getTasks().withType(War.class).configureEach(war ->
war.setWebXml(project.file("src/someWeb.xml")));
}
}响应构建功能
有两个主要用例:
-
在报告或统计数据中使用构建功能的状态。
-
通过禁用不兼容的插件功能来逐步采用实验性 Gradle 功能。
下面是一个使用这两种情况的插件示例。
public abstract class MyPlugin implements Plugin<Project> {
@Inject
protected abstract BuildFeatures getBuildFeatures(); // (1)
@Override
public void apply(Project p) {
BuildFeatures buildFeatures = getBuildFeatures();
Boolean configCacheRequested = buildFeatures.getConfigurationCache().getRequested() // (2)
.getOrNull(); // could be null if user did not opt in nor opt out
String configCacheUsage = describeFeatureUsage(configCacheRequested);
MyReport myReport = new MyReport();
myReport.setConfigurationCacheUsage(configCacheUsage);
boolean isolatedProjectsActive = buildFeatures.getIsolatedProjects().getActive() // (3)
.get(); // the active state is always defined
if (!isolatedProjectsActive) {
myOptionalPluginLogicIncompatibleWithIsolatedProjects();
}
}
private String describeFeatureUsage(Boolean requested) {
return requested == null ? "no preference" : requested ? "opt-in" : "opt-out";
}
private void myOptionalPluginLogicIncompatibleWithIsolatedProjects() {
}
}-
该
BuildFeatures服务可以注入插件、任务和其他托管类型。 -
访问
requested功能的状态以进行报告。 -
使用
active功能的状态来禁用不兼容的功能。
构建特征属性
状态BuildFeature属性用类型表示Provider<Boolean>。
构建功能的状态BuildFeature.getRequested()决定用户是否请求启用或禁用该功能。
当requested提供者值为:
-
true— 用户选择使用该功能 -
false— 用户选择不使用该功能 -
undefined— 用户既没有选择加入也没有选择退出使用该功能
BuildFeature.getActive()构建功能的状态始终是已定义的。它代表构建中功能的有效状态。
当active提供者值为:
-
true- 该功能可能会以特定于该功能的方式影响构建行为 -
false— 该功能不会影响构建行为
请注意,active状态不依赖于requested状态。即使用户请求某个功能,由于构建中使用了其他构建选项,该功能仍然可能未激活。即使用户没有指定首选项,Gradle 也可以默认激活某项功能。
提供默认依赖项
插件的实现有时需要使用外部依赖项。
您可能希望使用 Gradle 的依赖管理机制自动下载工件,然后在插件中声明的任务类型的操作中使用它。理想情况下,插件实现不需要询问用户该依赖项的坐标 - 它可以简单地预定义一个合理的默认版本。
让我们看一个插件示例,该插件下载包含数据以供进一步处理的文件。插件实现声明了一个自定义配置,允许使用依赖坐标分配这些外部依赖项:
public class DataProcessingPlugin implements Plugin<Project> {
public void apply(Project project) {
Configuration dataFiles = project.getConfigurations().create("dataFiles", c -> {
c.setVisible(false);
c.setCanBeConsumed(false);
c.setCanBeResolved(true);
c.setDescription("The data artifacts to be processed for this plugin.");
c.defaultDependencies(d -> d.add(project.getDependencies().create("org.myorg:data:1.4.6")));
});
project.getTasks().withType(DataProcessing.class).configureEach(
dataProcessing -> dataProcessing.getDataFiles().from(dataFiles));
}
}abstract public class DataProcessing extends DefaultTask {
@InputFiles
abstract public ConfigurableFileCollection getDataFiles();
@TaskAction
public void process() {
System.out.println(getDataFiles().getFiles());
}
}这种方法对于最终用户来说很方便,因为不需要主动声明依赖项。该插件已经提供了有关此实现的所有详细信息。
但是如果用户想要重新定义默认依赖项怎么办?
没问题。该插件还公开了可用于分配不同依赖项的自定义配置。实际上,默认依赖项被覆盖:
plugins {
id("org.myorg.data-processing")
}
dependencies {
dataFiles("org.myorg:more-data:2.6")
}plugins {
id 'org.myorg.data-processing'
}
dependencies {
dataFiles 'org.myorg:more-data:2.6'
}您会发现此模式非常适合执行任务操作时需要外部依赖项的任务。您可以通过公开扩展属性(例如toolVersion在JaCoCo 插件中)进一步抽象用于外部依赖项的版本
。
尽量减少外部库的使用
在 Gradle 项目中使用外部库可以带来很大的便利,但请注意它们可能会引入复杂的依赖关系图。 Gradle 的buildEnvironment任务可以帮助您可视化这些依赖关系,包括插件的依赖关系。请记住,插件共享相同的类加载器,因此同一库的不同版本可能会出现冲突。
为了演示,我们假设以下构建脚本:
plugins {
id("org.asciidoctor.jvm.convert") version "4.0.2"
}plugins {
id 'org.asciidoctor.jvm.convert' version '4.0.2'
}任务的输出清楚地指示了classpath配置的类路径:
$ gradle buildEnvironment
> Task :buildEnvironment
------------------------------------------------------------
Root project 'external-libraries'
------------------------------------------------------------
classpath
\--- org.asciidoctor.jvm.convert:org.asciidoctor.jvm.convert.gradle.plugin:4.0.2
\--- org.asciidoctor:asciidoctor-gradle-jvm:4.0.2
+--- org.ysb33r.gradle:grolifant-rawhide:3.0.0
| \--- org.tukaani:xz:1.6
+--- org.ysb33r.gradle:grolifant-herd:3.0.0
| +--- org.tukaani:xz:1.6
| +--- org.ysb33r.gradle:grolifant40:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.apache.commons:commons-collections4:4.4
| | +--- org.ysb33r.gradle:grolifant-core:3.0.0
| | | +--- org.tukaani:xz:1.6
| | | +--- org.apache.commons:commons-collections4:4.4
| | | \--- org.ysb33r.gradle:grolifant-rawhide:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant-rawhide:3.0.0 (*)
| +--- org.ysb33r.gradle:grolifant50:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.ysb33r.gradle:grolifant40:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant40-legacy-api:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.apache.commons:commons-collections4:4.4
| | +--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant40:3.0.0 (*)
| +--- org.ysb33r.gradle:grolifant60:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.ysb33r.gradle:grolifant40:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant50:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant-rawhide:3.0.0 (*)
| +--- org.ysb33r.gradle:grolifant70:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.ysb33r.gradle:grolifant40:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant50:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant60:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| +--- org.ysb33r.gradle:grolifant80:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.ysb33r.gradle:grolifant40:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant50:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant60:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant70:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| +--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| \--- org.ysb33r.gradle:grolifant-rawhide:3.0.0 (*)
+--- org.asciidoctor:asciidoctor-gradle-base:4.0.2
| \--- org.ysb33r.gradle:grolifant-herd:3.0.0 (*)
\--- org.asciidoctor:asciidoctorj-api:2.5.7
(*) - Indicates repeated occurrences of a transitive dependency subtree. Gradle expands transitive dependency subtrees only once per project; repeat occurrences only display the root of the subtree, followed by this annotation.
A web-based, searchable dependency report is available by adding the --scan option.
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed
Gradle 插件不会在其自己的独立类加载器中运行,因此您必须考虑是否确实需要一个库,或者一个更简单的解决方案是否足够。
对于作为任务执行的一部分执行的逻辑,请使用允许您隔离库的Worker API 。
提供插件的多个变体
配置其他插件变体的最便捷方法是使用功能变体,这是应用 Java 插件之一的所有 Gradle 项目中都可用的概念:
dependencies {
implementation 'com.google.guava:guava:30.1-jre' // Regular dependency
featureVariant 'com.google.guava:guava-gwt:30.1-jre' // Feature variant dependency
}在以下示例中,每个插件变体都是单独开发的。为每个变体编译单独的源集并将其打包在单独的 jar 中。
以下示例演示了如何添加与 Gradle 7.0+ 兼容的变体,同时“主”变体与旧版本兼容:
val gradle7 = sourceSets.create("gradle7")
java {
registerFeature(gradle7.name) {
usingSourceSet(gradle7)
capability(project.group.toString(), project.name, project.version.toString()) // (1)
}
}
configurations.configureEach {
if (isCanBeConsumed && name.startsWith(gradle7.name)) {
attributes {
attribute(GradlePluginApiVersion.GRADLE_PLUGIN_API_VERSION_ATTRIBUTE, // (2)
objects.named("7.0"))
}
}
}
tasks.named<Copy>(gradle7.processResourcesTaskName) { // (3)
val copyPluginDescriptors = rootSpec.addChild()
copyPluginDescriptors.into("META-INF/gradle-plugins")
copyPluginDescriptors.from(tasks.pluginDescriptors)
}
dependencies {
"gradle7CompileOnly"(gradleApi()) // (4)
}def gradle7 = sourceSets.create('gradle7')
java {
registerFeature(gradle7.name) {
usingSourceSet(gradle7)
capability(project.group.toString(), project.name, project.version.toString()) // (1)
}
}
configurations.configureEach {
if (canBeConsumed && name.startsWith(gradle7.name)) {
attributes {
attribute(GradlePluginApiVersion.GRADLE_PLUGIN_API_VERSION_ATTRIBUTE, // (2)
objects.named(GradlePluginApiVersion, '7.0'))
}
}
}
tasks.named(gradle7.processResourcesTaskName) { // (3)
def copyPluginDescriptors = rootSpec.addChild()
copyPluginDescriptors.into('META-INF/gradle-plugins')
copyPluginDescriptors.from(tasks.pluginDescriptors)
}
dependencies {
gradle7CompileOnly(gradleApi()) // (4)
}|
笔记
|
只有 Gradle 版本 7 或更高版本可以明确作为变体的目标,因为仅在 Gradle 7 中添加了对此的支持。 |
首先,我们为 Gradle7 插件变体声明一个单独的源集和一个功能变体。然后,我们进行一些特定的连接,将该功能转换为适当的 Gradle 插件变体:
-
将与组件 GAV 相对应的隐式功能分配给变体。
-
将Gradle API 版本属性分配给Gradle7 变体的所有可用配置。 Gradle 使用此信息来确定在插件解析期间选择哪个变体。
-
配置
processGradle7Resources任务以确保插件描述符文件添加到 Gradle7 变体 Jar 中。 -
为我们的新变体添加依赖项
gradleApi(),以便 API 在编译期间可见。
请注意,目前没有方便的方法来访问其他 Gradle 版本的 API,就像您用来构建插件的 API 一样。理想情况下,每个变体都应该能够声明对其支持的最小 Gradle 版本的 API 的依赖关系。今后这一点将会得到改善。
上面的代码片段假设插件的所有变体都在同一位置具有插件类。也就是说,如果您的插件类是org.example.GreetingPlugin,您需要在 中创建该类的第二个变体src/gradle7/java/org/example。
使用多变体插件的版本特定变体
鉴于对多变体插件的依赖,Gradle 在解决以下任一问题时将自动选择与当前 Gradle 版本最匹配的变体:
-
plugins {}块中指定的插件; -
buildscript类路径依赖; -
出现在编译或运行时类路径上的构建源 (
buildSrc)根项目中的依赖项; -
应用Java Gradle Plugin Development 插件或Kotlin DSL 插件的项目中的依赖项出现在编译或运行时类路径中。
最佳匹配变体是针对最高 Gradle API 版本且不超过当前构建的 Gradle 版本的变体。
在所有其他情况下,如果存在未指定支持的 Gradle API 版本的插件变体,则首选该变体。
在使用插件作为依赖项的项目中,可以请求支持不同 Gradle 版本的插件依赖项的变体。这允许依赖其他插件的多变体插件访问其 API,这些 API 专门在其特定于版本的变体中提供。
此代码片段使上面定义的插件变体gradle7消耗其对其他多变体插件的依赖项的匹配变体:
configurations.configureEach {
if (isCanBeResolved && name.startsWith(gradle7.name)) {
attributes {
attribute(GradlePluginApiVersion.GRADLE_PLUGIN_API_VERSION_ATTRIBUTE,
objects.named("7.0"))
}
}
}configurations.configureEach {
if (canBeResolved && name.startsWith(gradle7.name)) {
attributes {
attribute(GradlePluginApiVersion.GRADLE_PLUGIN_API_VERSION_ATTRIBUTE,
objects.named(GradlePluginApiVersion, '7.0'))
}
}
}报告问题
插件可以通过 Gradle 的问题报告 API 报告问题。 API 报告有关构建过程中发生的问题的丰富的结构化信息。不同的用户界面(例如 Gradle 的控制台输出、构建扫描或 IDE)可以使用此信息以最合适的方式向用户传达问题。
以下示例显示了插件报告的问题:
public class ProblemReportingPlugin implements Plugin<Project> {
private final ProblemReporter problemReporter;
@Inject
public ProblemReportingPlugin(Problems problems) { // (1)
this.problemReporter = problems.forNamespace("org.myorg"); // (2)
}
public void apply(Project project) {
this.problemReporter.reporting(builder -> builder // (3)
.label("Plugin 'x' is deprecated")
.details("The plugin 'x' is deprecated since version 2.5")
.solution("Please use plugin 'y'")
.severity(Severity.WARNING)
);
}
}-
该
Problem服务被注入到插件中。 -
为插件创建了一个问题报告器。虽然命名空间由插件作者决定,但建议使用插件 ID。
-
报告有问题。此问题是可以恢复的,因此构建将继续。
有关完整示例,请参阅我们的端到端示例。
问题聚合
报告问题时,Gradle 会根据问题的类别标签,通过 Tooling API 发送类似的问题来进行聚合。
-
当报告问题时,第一次出现的问题将被报告为ProblemDescriptor,其中包含有关问题的完整信息。
-
任何后续出现的相同问题都将报告为ProblemAggregationDescriptor。该描述符将在构建结束时到达并包含问题发生的次数。
-
如果对于任何存储桶(即类别和标签配对),收集的出现次数大于 10.000,则将立即发送,而不是在构建结束时发送。
测试 Gradle 插件
测试通过确保可靠和高质量的软件在开发过程中发挥着至关重要的作用。此原则适用于构建代码,包括 Gradle 插件。
示例项目
本节围绕一个名为“URL 验证器插件”的示例项目展开。该插件创建一个名为verifyUrl检查给定 URL 是否可以通过 HTTP GET 解析的任务。最终用户可以通过名为 的扩展名提供 URL verification。
以下构建脚本假定插件 JAR 文件已发布到二进制存储库。该脚本演示了如何将插件应用到项目并配置其公开的扩展:
plugins {
id("org.myorg.url-verifier") // (1)
}
verification {
url = "https://www.google.com/" // (2)
}plugins {
id 'org.myorg.url-verifier' // (1)
}
verification {
url = 'https://www.google.com/' // (2)
}-
将插件应用到项目中
-
配置要通过公开的扩展进行验证的 URL
verifyUrl如果对配置的 URL 的 HTTP GET 调用返回 200 响应代码,则执行任务会呈现成功消息:
$ gradle verifyUrl
> Task :verifyUrl
Successfully resolved URL 'https://www.google.com/'
BUILD SUCCESSFUL in 0s
5 actionable tasks: 5 executed在深入研究代码之前,我们首先回顾一下不同类型的测试以及支持实现它们的工具。
测试的重要性
测试是软件开发生命周期的重要组成部分,确保软件在发布前正确运行并满足质量标准。自动化测试使开发人员能够充满信心地重构和改进代码。
测试金字塔
- 手动测试
-
虽然手动测试很简单,但很容易出错并且需要人力。对于 Gradle 插件,手动测试涉及在构建脚本中使用插件。
- 自动化测试
-
自动化测试包括单元测试、集成测试和功能测试。

Mike Cohen 在他的《成功敏捷:使用 Scrum 进行软件开发》一书中介绍的测试金字塔描述了三种类型的自动化测试:
-
单元测试:单独验证最小的代码单元,通常是方法。它使用存根或模拟将代码与外部依赖项隔离。
-
集成测试:验证多个单元或组件是否可以协同工作。
-
功能测试:从最终用户的角度测试系统,确保功能正确。 Gradle 插件的端到端测试模拟构建、应用插件并执行特定任务以验证功能。
工装支持
使用适当的工具可以简化手动和自动测试 Gradle 插件的过程。下表提供了每种测试方法的摘要。您可以选择任何您喜欢的测试框架。
详细解释和代码示例请参考以下具体章节:
| 测试类型 | 工装支持 |
|---|---|
任何基于 JVM 的测试框架 |
|
任何基于 JVM 的测试框架 |
|
任何基于 JVM 的测试框架和Gradle TestKit |
设置手动测试
Gradle 的复合构建功能使手动测试插件变得很容易。独立插件项目和使用项目可以组合成一个单元,从而可以轻松尝试或调试更改,而无需重新发布二进制文件:
.
├── include-plugin-build // (1)
│ ├── build.gradle
│ └── settings.gradle
└── url-verifier-plugin // (2)
├── build.gradle
├── settings.gradle
└── src
-
使用包含插件项目的项目
-
插件项目
有两种方法可以将插件项目包含在使用项目中:
-
通过使用命令行选项
--include-build。 -
includeBuild通过使用中的方法settings.gradle。
以下代码片段演示了设置文件的使用:
pluginManagement {
includeBuild("../url-verifier-plugin")
}pluginManagement {
includeBuild '../url-verifier-plugin'
}verifyUrl项目中任务的命令行输出include-plugin-build 看起来与简介中所示的完全相同,只是它现在作为复合构建的一部分执行。
手动测试在开发过程中占有一席之地,但它并不能替代自动化测试。
设置自动化测试
尽早设置一套测试对于插件的成功至关重要。当将插件升级到新的 Gradle 版本或增强/重构代码时,自动化测试成为宝贵的安全网。
整理测试源代码
我们建议实施良好的单元、集成和功能测试分布,以涵盖最重要的用例。自动分离每种测试类型的源代码会导致项目更易于维护和管理。
默认情况下,Java 项目创建一个用于在目录中组织单元测试的约定src/test/java。另外,如果应用Groovy插件,则src/test/groovy考虑编译该目录下的源代码(与该目录下的Kotlin标准相同src/test/kotlin)。因此,其他测试类型的源代码目录应遵循类似的模式:
.
└── src
├── functionalTest
│ └── groovy // (1)
├── integrationTest
│ └── groovy // (2)
├── main
│ ├── java // (3)
└── test
└── groovy // (4)
-
包含功能测试的源目录
-
包含集成测试的源目录
-
包含生产源代码的源目录
-
包含单元测试的源目录
|
笔记
|
这些目录src/integrationTest/groovy并不src/functionalTest/groovy基于 Gradle 项目的现有标准约定。您可以自由选择最适合您的项目布局。
|
您可以配置编译和测试执行的源目录。
测试套件插件提供了 DSL 和 API,用于将多组自动化测试建模到基于 JVM 的项目中的测试套件中。为了方便起见,您还可以依赖第三方插件,例如Nebula Facet 插件或TestSets 插件。
建模测试类型
|
笔记
|
通过孵化JVM 测试套件integrationTest插件,可以使用
用于建模以下套件的新配置 DSL 。
|
在 Gradle 中,源代码目录使用源集的概念来表示。源集配置为指向一个或多个包含源代码的目录。当您定义源集时,Gradle 会自动为指定目录设置编译任务。
可以使用一行构建脚本代码来创建预配置的源集。源集自动注册配置来定义源集源的依赖关系:
// Define a source set named 'test' for test sources
sourceSets {
test {
java {
srcDirs = ['src/test/java']
}
}
}
// Specify a test implementation dependency on JUnit
dependencies {
testImplementation 'junit:junit:4.12'
}我们用它来定义integrationTestImplementation对项目本身的依赖,它代表我们项目的“主要”变体(即编译的插件代码):
val integrationTest by sourceSets.creating
dependencies {
"integrationTestImplementation"(project)
}def integrationTest = sourceSets.create("integrationTest")
dependencies {
integrationTestImplementation(project)
}源集负责编译源代码,但不处理字节码的执行。为了执行测试,需要建立相应的Test类型的任务。以下设置显示了集成测试的执行,引用了集成测试源集的类和运行时类路径:
val integrationTestTask = tasks.register<Test>("integrationTest") {
description = "Runs the integration tests."
group = "verification"
testClassesDirs = integrationTest.output.classesDirs
classpath = integrationTest.runtimeClasspath
mustRunAfter(tasks.test)
}
tasks.check {
dependsOn(integrationTestTask)
}def integrationTestTask = tasks.register("integrationTest", Test) {
description = 'Runs the integration tests.'
group = "verification"
testClassesDirs = integrationTest.output.classesDirs
classpath = integrationTest.runtimeClasspath
mustRunAfter(tasks.named('test'))
}
tasks.named('check') {
dependsOn(integrationTestTask)
}配置测试框架
下面的代码片段展示了如何使用Spock来实现测试:
repositories {
mavenCentral()
}
dependencies {
testImplementation(platform("org.spockframework:spock-bom:2.2-groovy-3.0"))
testImplementation("org.spockframework:spock-core")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
"integrationTestImplementation"(platform("org.spockframework:spock-bom:2.2-groovy-3.0"))
"integrationTestImplementation"("org.spockframework:spock-core")
"integrationTestRuntimeOnly"("org.junit.platform:junit-platform-launcher")
"functionalTestImplementation"(platform("org.spockframework:spock-bom:2.2-groovy-3.0"))
"functionalTestImplementation"("org.spockframework:spock-core")
"functionalTestRuntimeOnly"("org.junit.platform:junit-platform-launcher")
}
tasks.withType<Test>().configureEach {
// Using JUnitPlatform for running tests
useJUnitPlatform()
}repositories {
mavenCentral()
}
dependencies {
testImplementation platform("org.spockframework:spock-bom:2.2-groovy-3.0")
testImplementation 'org.spockframework:spock-core'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
integrationTestImplementation platform("org.spockframework:spock-bom:2.2-groovy-3.0")
integrationTestImplementation 'org.spockframework:spock-core'
integrationTestRuntimeOnly 'org.junit.platform:junit-platform-launcher'
functionalTestImplementation platform("org.spockframework:spock-bom:2.2-groovy-3.0")
functionalTestImplementation 'org.spockframework:spock-core'
functionalTestRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
tasks.withType(Test).configureEach {
// Using JUnitPlatform for running tests
useJUnitPlatform()
}|
笔记
|
Spock 是一个基于 Groovy 的 BDD 测试框架,甚至包括用于创建 Stub 和 Mock 的 API。 Gradle 团队更喜欢 Spock 而不是其他选项,因为它的表现力和简洁性。 |
实施自动化测试
本节讨论单元、集成和功能测试的代表性实现示例。所有测试类都基于 Spock 的使用,尽管使代码适应不同的测试框架应该相对容易。
实施单元测试
URL 验证器插件发出 HTTP GET 调用来检查 URL 是否可以成功解析。该方法DefaultHttpCaller.get(String)负责调用给定的 URL 并返回类型的实例HttpResponse。HttpResponse是一个 POJO,包含有关 HTTP 响应代码和消息的信息:
package org.myorg.http;
public class HttpResponse {
private int code;
private String message;
public HttpResponse(int code, String message) {
this.code = code;
this.message = message;
}
public int getCode() {
return code;
}
public String getMessage() {
return message;
}
@Override
public String toString() {
return "HTTP " + code + ", Reason: " + message;
}
}该类HttpResponse代表单元测试的良好候选者。它不涉及任何其他类,也不使用 Gradle API。
package org.myorg.http
import spock.lang.Specification
class HttpResponseTest extends Specification {
private static final int OK_HTTP_CODE = 200
private static final String OK_HTTP_MESSAGE = 'OK'
def "can access information"() {
when:
def httpResponse = new HttpResponse(OK_HTTP_CODE, OK_HTTP_MESSAGE)
then:
httpResponse.code == OK_HTTP_CODE
httpResponse.message == OK_HTTP_MESSAGE
}
def "can get String representation"() {
when:
def httpResponse = new HttpResponse(OK_HTTP_CODE, OK_HTTP_MESSAGE)
then:
httpResponse.toString() == "HTTP $OK_HTTP_CODE, Reason: $OK_HTTP_MESSAGE"
}
}|
重要的
|
编写单元测试时,测试边界条件和各种形式的无效输入非常重要。尝试从使用 Gradle API 的类中提取尽可能多的逻辑,使其可作为单元测试进行测试。它将产生可维护的代码和更快的测试执行。 |
您可以使用ProjectBuilder类创建Project实例,以便在测试插件实现时使用。
public class GreetingPluginTest {
@Test
public void greeterPluginAddsGreetingTaskToProject() {
Project project = ProjectBuilder.builder().build();
project.getPluginManager().apply("org.example.greeting");
assertTrue(project.getTasks().getByName("hello") instanceof GreetingTask);
}
}实施集成测试
让我们看一下一个连接到另一个系统的类,即发出 HTTP 调用的代码段。在对类执行测试时DefaultHttpCaller,运行时环境需要能够连接到互联网:
package org.myorg.http;
import java.io.IOException;
import java.net.HttpURLConnection;
import java.net.URL;
public class DefaultHttpCaller implements HttpCaller {
@Override
public HttpResponse get(String url) {
try {
HttpURLConnection connection = (HttpURLConnection) new URL(url).openConnection();
connection.setConnectTimeout(5000);
connection.setRequestMethod("GET");
connection.connect();
int code = connection.getResponseCode();
String message = connection.getResponseMessage();
return new HttpResponse(code, message);
} catch (IOException e) {
throw new HttpCallException(String.format("Failed to call URL '%s' via HTTP GET", url), e);
}
}
}实现集成测试看起来DefaultHttpCaller与上一节中所示的单元测试没有太大区别:
package org.myorg.http
import spock.lang.Specification
import spock.lang.Subject
class DefaultHttpCallerIntegrationTest extends Specification {
@Subject HttpCaller httpCaller = new DefaultHttpCaller()
def "can make successful HTTP GET call"() {
when:
def httpResponse = httpCaller.get('https://www.google.com/')
then:
httpResponse.code == 200
httpResponse.message == 'OK'
}
def "throws exception when calling unknown host via HTTP GET"() {
when:
httpCaller.get('https://www.wedonotknowyou123.com/')
then:
def t = thrown(HttpCallException)
t.message == "Failed to call URL 'https://www.wedonotknowyou123.com/' via HTTP GET"
t.cause instanceof UnknownHostException
}
}实施功能测试
功能测试验证插件端到端的正确性。实际上,这意味着应用、配置和执行插件实现的功能。该类UrlVerifierPlugin公开一个扩展和一个使用最终用户配置的 URL 值的任务实例:
package org.myorg;
import org.gradle.api.Plugin;
import org.gradle.api.Project;
import org.myorg.tasks.UrlVerify;
public class UrlVerifierPlugin implements Plugin<Project> {
@Override
public void apply(Project project) {
UrlVerifierExtension extension = project.getExtensions().create("verification", UrlVerifierExtension.class);
UrlVerify verifyUrlTask = project.getTasks().create("verifyUrl", UrlVerify.class);
verifyUrlTask.getUrl().set(extension.getUrl());
}
}每个 Gradle 插件项目都应该应用插件开发插件来减少样板代码。通过应用插件开发插件,测试源集被预先配置为与 TestKit 一起使用。如果我们想使用自定义源集进行功能测试并保留默认测试源集仅用于单元测试,我们可以配置插件开发插件以在其他地方查找 TestKit 测试。
gradlePlugin {
testSourceSets(functionalTest)
}gradlePlugin {
testSourceSets(sourceSets.functionalTest)
}Gradle 插件的功能测试使用 的实例来GradleRunner执行测试下的构建。
GradleRunner是TestKit提供的API,内部使用Tooling API来执行构建。
以下示例将插件应用于正在测试的构建脚本,配置扩展并使用任务执行构建verifyUrl。请参阅TestKit 文档以更熟悉 TestKit 的功能。
package org.myorg
import org.gradle.testkit.runner.GradleRunner
import spock.lang.Specification
import spock.lang.TempDir
import static org.gradle.testkit.runner.TaskOutcome.SUCCESS
class UrlVerifierPluginFunctionalTest extends Specification {
@TempDir File testProjectDir
File buildFile
def setup() {
buildFile = new File(testProjectDir, 'build.gradle')
buildFile << """
plugins {
id 'org.myorg.url-verifier'
}
"""
}
def "can successfully configure URL through extension and verify it"() {
buildFile << """
verification {
url = 'https://www.google.com/'
}
"""
when:
def result = GradleRunner.create()
.withProjectDir(testProjectDir)
.withArguments('verifyUrl')
.withPluginClasspath()
.build()
then:
result.output.contains("Successfully resolved URL 'https://www.google.com/'")
result.task(":verifyUrl").outcome == SUCCESS
}
}IDE集成
TestKit 通过运行特定的 Gradle 任务来确定插件类路径。assemble即使从 IDE 运行基于 TestKit 的功能测试,您也需要执行任务来最初生成插件类路径或反映对其的更改。
一些 IDE 提供了一个方便的选项来将“测试类路径生成和执行”委托给构建。在 IntelliJ 中,您可以在“首选项...”>“构建、执行、部署”>“构建工具”>“Gradle”>“运行器”>“将 IDE 构建/运行操作委托给 Gradle”下找到此选项。

将插件发布到 Gradle 插件门户
发布插件是使其可供其他人使用的主要方式。虽然您可以发布到私有存储库以限制访问,但发布到Gradle 插件门户可以让世界上的任何人都可以使用您的插件。

本指南向您展示如何使用插件通过方便的 DSLcom.gradle.plugin-publish将插件发布到Gradle 插件门户。这种方法简化了配置步骤并提供验证检查,以确保您的插件满足 Gradle 插件门户的标准。
先决条件
本教程需要一个现有的 Gradle 插件项目。如果您没有,请使用Greeting 插件示例。
尝试发布此插件将安全地失败并出现权限错误,因此不必担心 Gradle 插件门户会因为一个简单的示例插件而变得混乱。
账户设置
在发布插件之前,您必须在 Gradle 插件门户上创建一个帐户。按照注册页面上的说明创建帐户并从个人资料页面的“API 密钥”选项卡获取 API 密钥。

将 API 密钥存储在 Gradle 配置中(gradle.publish.key 和 gradle.publish.secret),或使用 Seauc Credentials 插件或 Gradle Credentials 插件等插件进行安全管理。

通常的做法是将文本复制并粘贴到$HOME/.gradle/gradle.properties文件中,但您也可以将其放置在任何其他有效位置。该插件所需要的只是在执行适当的插件门户任务时,gradle.publish.key和可以作为项目属性使用。gradle.publish.secret
如果您担心放置凭据gradle.properties,请查看Seauc Credentials 插件或Gradle Credentials 插件。
添加插件发布插件
要发布您的插件,请将com.gradle.plugin-publish插件添加到您的项目build.gradle或build.gradle.kts文件中:
plugins {
id("com.gradle.plugin-publish") version "1.2.1"
}plugins {
id 'com.gradle.plugin-publish' version '1.2.1'
}最新版本的插件发布插件可以在Gradle 插件门户上找到。
|
笔记
|
从版本 1.0.0 开始,Plugin Publish Plugin 自动应用 Java Gradle Plugin Development Plugin(协助开发 Gradle 插件)和 Maven Publish Plugin(生成插件发布元数据)。如果使用旧版本的插件发布插件,则必须显式应用这些帮助器插件。 |
配置插件发布插件
com.gradle.plugin-publish在您的build.gradle或文件中配置插件build.gradle.kts。
group = "io.github.johndoe" // (1)
version = "1.0" // (2)
gradlePlugin { // (3)
website = "<substitute your project website>" // (4)
vcsUrl = "<uri to project source repository>" // (5)
// ... // (6)
}group = 'io.github.johndoe' // (1)
version = '1.0' // (2)
gradlePlugin { // (3)
website = '<substitute your project website>' // (4)
vcsUrl = '<uri to project source repository>' // (5)
// ... // (6)
}-
确保您的项目有一个
group集合,用于识别您在 Gradle 插件门户存储库中为插件发布的工件(jar 和元数据),并且描述插件作者或插件所属的组织。 -
设置项目的版本,该版本也将用作插件的版本。
-
使用Java Gradle 插件开发插件
gradlePlugin提供的块 为您的插件发布配置更多选项。 -
为您的插件项目设置网站。
-
提供源存储库 URI,以便其他想要贡献的人可以找到它。
-
为您要发布的每个插件设置特定属性;请参阅下一节。
使用块定义所有插件的通用属性,例如组、版本、网站和源存储库gradlePlugin{}:
gradlePlugin { // (1)
// ... // (2)
plugins { // (3)
create("greetingsPlugin") { // (4)
id = "<your plugin identifier>" // (5)
displayName = "<short displayable name for plugin>" // (6)
description = "<human-readable description of what your plugin is about>" // (7)
tags = listOf("tags", "for", "your", "plugins") // (8)
implementationClass = "<your plugin class>"
}
}
}gradlePlugin { // (1)
// ... // (2)
plugins { // (3)
greetingsPlugin { // (4)
id = '<your plugin identifier>' // (5)
displayName = '<short displayable name for plugin>' // (6)
description = '<human-readable description of what your plugin is about>' // (7)
tags.set(['tags', 'for', 'your', 'plugins']) // (8)
implementationClass = '<your plugin class>'
}
}
}-
插件特定配置也进入该
gradlePlugin块。 -
这是我们之前添加全局属性的地方。
-
您发布的每个插件都会有自己的内部块
plugins。 -
对于您发布的每个插件,插件块的名称必须是唯一的;这是仅由您的构建在本地使用的属性,不会成为发布的一部分。
-
设置插件的唯一性
id,因为它将在出版物中标识。 -
以人类可读的形式设置插件名称。
-
设置要在门户上显示的说明。它为想要使用您的插件的人提供有用的信息。
-
指定您的插件涵盖的类别。它使插件更有可能被需要其功能的人发现。
例如,考虑已发布到 Gradle 插件门户的GradleTest 插件的配置。
gradlePlugin {
website = "https://github.com/ysb33r/gradleTest"
vcsUrl = "https://github.com/ysb33r/gradleTest.git"
plugins {
create("gradletestPlugin") {
id = "org.ysb33r.gradletest"
displayName = "Plugin for compatibility testing of Gradle plugins"
description = "A plugin that helps you test your plugin against a variety of Gradle versions"
tags = listOf("testing", "integrationTesting", "compatibility")
implementationClass = "org.ysb33r.gradle.gradletest.GradleTestPlugin"
}
}
}gradlePlugin {
website = 'https://github.com/ysb33r/gradleTest'
vcsUrl = 'https://github.com/ysb33r/gradleTest.git'
plugins {
gradletestPlugin {
id = 'org.ysb33r.gradletest'
displayName = 'Plugin for compatibility testing of Gradle plugins'
description = 'A plugin that helps you test your plugin against a variety of Gradle versions'
tags.addAll('testing', 'integrationTesting', 'compatibility')
implementationClass = 'org.ysb33r.gradle.gradletest.GradleTestPlugin'
}
}
}如果您浏览 Gradle 插件门户上GradleTest 插件的关联页面,您将看到指定元数据的显示方式。

来源和 Javadoc
插件发布插件会自动生成并发布Javadoc,以及插件发布的源 JAR。
影子依赖
从 Plugin Publish Plugin 版本 1.0.0 开始,隐藏插件的依赖项(即,将其发布为 fat jar)已自动实现。要启用它,所需要做的就是com.github.johnrengelman.shadow在您的构建中应用该插件。
发布插件
如果您有兴趣发布您的插件以供更广泛的 Gradle 社区使用,您可以将其发布到Gradle Plugin Portal。该站点提供搜索和收集有关 Gradle 社区贡献的插件信息的功能。请参阅有关在本网站上提供您的插件的相应部分。
本地发布
要检查已发布插件的工件外观或仅在本地或公司内部使用它,您可以将其发布到任何 Maven 存储库,包括本地文件夹。您只需要配置用于发布的存储库。然后,您可以运行publish任务将插件发布到您定义的所有存储库(但不是 Gradle 插件门户)。
publishing {
repositories {
maven {
name = "localPluginRepository"
url = uri("../local-plugin-repository")
}
}
}publishing {
repositories {
maven {
name = 'localPluginRepository'
url = '../local-plugin-repository'
}
}
}要在另一个版本中使用该存储库,请将其添加到文件中块的存储库pluginManagement {}settings.gradle(.kts)中。
发布到插件门户
使用publishPlugin任务发布插件:
$ ./gradlew publishPlugins
您可以在发布之前使用该标志验证您的插件--validate-only:
$ ./gradlew publishPlugins --validate-only
如果您尚未配置gradle.propertiesGradle 插件门户,您可以在命令行上指定它们:
$ ./gradlew publishPlugins -Pgradle.publish.key=<key> -Pgradle.publish.secret=<secret>
|
笔记
|
如果您尝试使用本节中使用的 ID 发布示例 Greeting 插件,您将遇到权限失败。这是预期的,并确保门户不会被多个实验性和重复的问候类型插件淹没。 |
批准后,您的插件将在 Gradle 插件门户上提供,供其他人发现和使用。
使用已发布的插件
成功发布插件后,它不会立即出现在门户上。它还需要通过审批流程,对于插件的初始版本来说,这是手动的并且相对较慢,但对于后续版本来说是全自动的。有关更多详细信息,请参阅此处。
一旦您的插件获得批准,您可以在https://plugins.gradle.org/plugin/<your-plugin-id>形式的 URL 中找到其使用说明。例如,Greeting 插件示例已位于门户网站https://plugins.gradle.org/plugin/org.example.greeting上。
没有 Gradle 插件门户发布的插件
如果您的插件是在没有使用Java Gradle Plugin Development Plugin 的情况下发布的,则该发布将缺少Plugin Marker Artifact ,插件 DSL需要它来定位插件。在这种情况下,解决另一个项目中的插件的推荐方法是将一个resolutionStrategy部分添加到pluginManagement {}项目设置文件的块中,如下所示。
resolutionStrategy {
eachPlugin {
if (requested.id.namespace == "org.example") {
useModule("org.example:custom-plugin:${requested.version}")
}
}
}resolutionStrategy {
eachPlugin {
if (requested.id.namespace == 'org.example') {
useModule("org.example:custom-plugin:${requested.version}")
}
}
}最佳实践
组织 Gradle 项目
每个软件项目的源代码和构建逻辑都应该以有意义的方式组织。本页列出了可实现可读、可维护项目的最佳实践。以下各节还介绍了常见问题以及如何避免这些问题。
单独的特定于语言的源文件
Gradle 的语言插件建立了发现和编译源代码的约定。例如,应用Java插件的项目会自动编译目录中的代码src/main/java。其他语言插件遵循相同的模式。目录路径的最后部分通常指示源文件的预期语言。
有些编译器能够在同一源目录中交叉编译多种语言。 Groovy 编译器可以处理混合位于src/main/groovy. Gradle 建议您根据源语言将源代码放置在目录中,因为构建的性能更高,并且用户和构建都可以做出更强有力的假设。
以下源代码树包含 Java 和 Kotlin 源文件。 Java 源文件位于src/main/java,而 Kotlin 源文件位于src/main/kotlin.
.
├── build.gradle.kts
└── src
└── main
├── java
│ └── HelloWorld.java
└── kotlin
└── Utils.kt.
├── build.gradle
└── src
└── main
├── java
│ └── HelloWorld.java
└── kotlin
└── Utils.kt每个测试类型单独的源文件
项目定义和执行不同类型的测试是很常见的,例如单元测试、集成测试、功能测试或冒烟测试。最佳情况下,每种测试类型的测试源代码应存储在专用的源目录中。分离的测试源代码对可维护性和关注点分离具有积极影响,因为您可以彼此独立地运行测试类型。
查看演示 如何将单独的集成测试配置添加到基于 Java 的项目的示例。
尽可能使用标准约定
-
它将目录定义
src/main/java为编译的默认源目录。 -
已编译源代码和其他工件(如 JAR 文件)的输出目录是
build.
通过坚持默认约定,项目的新开发人员可以立即知道如何找到解决办法。虽然这些约定可以重新配置,但这使得构建脚本用户和作者来管理构建逻辑及其结果变得更加困难。尝试尽可能坚持默认约定,除非您需要适应遗留项目的布局。请参阅相关插件的参考页面以了解其默认约定。
始终定义一个设置文件
每次调用构建时,Gradle 都会尝试定位settings.gradle(Groovy DSL) 或(Kotlin DSL) 文件。settings.gradle.kts为此,运行时将目录树的层次结构向上移动到根目录。一旦找到设置文件,算法就会停止搜索。
始终将 a 添加settings.gradle到构建的根目录以避免初始性能影响。该文件可以为空,也可以定义所需的项目名称。
多项目构建必须settings.gradle(.kts)在多项目层次结构的根项目中有一个文件。这是必需的,因为设置文件定义了哪些项目正在参与多项目构建。除了定义包含的项目之外,您可能还需要它将库添加到构建脚本类路径中。
以下示例显示了标准 Gradle 项目布局:
.
├── settings.gradle.kts
├── subproject-one
│ └── build.gradle.kts
└── subproject-two
└── build.gradle.kts.
├── settings.gradle
├── subproject-one
│ └── build.gradle
└── subproject-two
└── build.gradle用于buildSrc抽象命令式逻辑
复杂的构建逻辑通常适合封装为自定义任务或二进制插件。自定义任务和插件实现不应存在于构建脚本中。buildSrc只要代码不需要在多个独立项目之间共享,就可以非常方便地用于此目的。
该目录buildSrc被视为包含的构建。发现该目录后,Gradle 会自动编译和测试此代码,并将其放入构建脚本的类路径中。对于多项目构建,只能有一个buildSrc目录,该目录必须位于根项目目录中。
buildSrc应该优先于脚本插件,因为它更容易维护、重构和测试代码。
buildSrc使用适用于 Java 和 Groovy 项目的相同源代码约定。它还提供对 Gradle API 的直接访问。额外的依赖项可以在专用build.gradle的buildSrc.
repositories {
mavenCentral()
}
dependencies {
testImplementation("junit:junit:4.13")
}repositories {
mavenCentral()
}
dependencies {
testImplementation 'junit:junit:4.13'
}一个典型的项目包括buildSrc以下布局。下面的任何代码buildSrc都应该使用与应用程序代码类似的包。或者,如果需要额外的配置(例如应用插件或声明依赖项),该buildSrc目录可以托管构建脚本。
.
├── buildSrc
│ ├── build.gradle.kts
│ └── src
│ ├── main
│ │ └── java
│ │ └── com
│ │ └── enterprise
│ │ ├── Deploy.java
│ │ └── DeploymentPlugin.java
│ └── test
│ └── java
│ └── com
│ └── enterprise
│ └── DeploymentPluginTest.java
├── settings.gradle.kts
├── subproject-one
│ └── build.gradle.kts
└── subproject-two
└── build.gradle.kts.
├── buildSrc
│ ├── build.gradle
│ └── src
│ ├── main
│ │ └── java
│ │ └── com
│ │ └── enterprise
│ │ ├── Deploy.java
│ │ └── DeploymentPlugin.java
│ └── test
│ └── java
│ └── com
│ └── enterprise
│ └── DeploymentPluginTest.java
├── settings.gradle
├── subproject-one
│ └── build.gradle
└── subproject-two
└── build.gradle|
笔记
|
更改 因此,当进行小的增量更改时, |
gradle.properties在文件中声明属性
gradle.properties在 Gradle 中,属性可以在构建脚本、文件中或命令行上的参数中定义。
对于临时场景,在命令行上声明属性是很常见的。例如,您可能希望传入一个特定的属性值来控制构建的这一次调用的运行时行为。构建脚本中的属性很容易成为维护难题,并使构建脚本逻辑变得复杂。这gradle.properties有助于将属性与构建脚本分开,应该将其作为可行的选项进行探索。这是放置控制构建环境的属性的好位置。
典型的项目设置将该gradle.properties文件放置在构建的根目录中。或者,GRADLE_USER_HOME如果您希望该文件应用于计算机上的所有版本,则该文件也可以位于该目录中。
.
├── gradle.properties
└── settings.gradle.kts
├── subproject-a
│ └── build.gradle.kts
└── subproject-b
└── build.gradle.kts.
├── gradle.properties
└── settings.gradle
├── subproject-a
│ └── build.gradle
└── subproject-b
└── build.gradle避免任务输出重叠
任务应该定义输入和输出以获得增量构建功能的性能优势。声明任务的输出时,请确保用于写入输出的目录在项目中的所有任务中是唯一的。
混合或覆盖不同任务生成的输出文件会损害最新检查,导致构建速度变慢。反过来,这些文件系统更改可能会阻止 Gradle 的构建缓存正确识别和缓存本来可缓存的任务。
使用自定义 Gradle 发行版标准化构建
企业通常希望通过定义通用约定或规则来标准化组织中所有项目的构建平台。您可以借助初始化脚本来实现这一点。 初始化脚本使得在单台机器上的所有项目中应用构建逻辑变得非常容易。例如,声明内部存储库及其凭据。
该方法有一些缺点。首先,您必须与公司的所有开发人员沟通设置过程。此外,统一更新初始化脚本逻辑可能具有挑战性。
自定义 Gradle 发行版是解决这个问题的实用方法。自定义 Gradle 发行版由标准 Gradle 发行版以及一个或多个自定义初始化脚本组成。初始化脚本与发行版捆绑在一起,并在每次运行构建时应用。开发人员只需将签入的Wrapper文件指向自定义 Gradle 发行版的 URL。
自定义 Gradle 发行版还可能gradle.properties在发行版的根目录中包含一个文件,该文件提供了一组组织范围内的属性来控制构建环境。
以下步骤是创建自定义 Gradle 发行版的典型步骤:
-
实现下载和重新打包 Gradle 发行版的逻辑。
-
使用所需逻辑定义一个或多个初始化脚本。
-
将初始化脚本与 Gradle 发行版捆绑在一起。
-
将 Gradle 分发存档上传到 HTTP 服务器。
-
更改所有项目的 Wrapper 文件以指向自定义 Gradle 发行版的 URL。
plugins {
id 'base'
}
// This is defined in buildSrc
import org.gradle.distribution.DownloadGradle
version = '0.1'
tasks.register('downloadGradle', DownloadGradle) {
description = 'Downloads the Gradle distribution with a given version.'
gradleVersion = '4.6'
}
tasks.register('createCustomGradleDistribution', Zip) {
description = 'Builds custom Gradle distribution and bundles initialization scripts.'
dependsOn downloadGradle
def projectVersion = project.version
archiveFileName = downloadGradle.gradleVersion.map { gradleVersion ->
"mycompany-gradle-${gradleVersion}-${projectVersion}-bin.zip"
}
from zipTree(downloadGradle.destinationFile)
from('src/init.d') {
into "${downloadGradle.distributionNameBase.get()}/init.d"
}
}编写可维护构建的最佳实践
Gradle 拥有丰富的 API,提供多种创建构建逻辑的方法。相关的灵活性很容易导致不必要的复杂构建,而自定义代码通常直接添加到构建脚本中。在本章中,我们将介绍几种最佳实践,帮助您开发易于使用、富有表现力且可维护的构建。
|
笔记
|
如果您感兴趣的话, 第三方Gradle lint 插件有助于在构建脚本中强制执行所需的代码样式。 |
避免在脚本中使用命令式逻辑
Gradle 运行时不强制构建逻辑的特定样式。正是出于这个原因,很容易最终得到一个将声明性 DSL 元素与命令式过程代码混合在一起的构建脚本。我们来谈谈一些具体的例子。
-
声明性代码:内置的、与语言无关的 DSL 元素(例如Project.dependency{}或Project.repositories{})或插件公开的 DSL
-
命令式代码:条件逻辑或非常复杂的任务操作实现
每个构建脚本的最终目标应该是仅包含声明性语言元素,这使得代码更易于理解和维护。命令式逻辑应该存在于二进制插件中,然后应用于构建脚本。作为副产品,如果您将工件发布到二进制存储库,您将自动使您的团队能够在其他项目中重用插件逻辑。
以下示例构建显示了直接在构建脚本中使用条件逻辑的反面示例。虽然此代码片段很小,但很容易想象一个使用大量过程语句的完整构建脚本及其对可读性和可维护性的影响。通过将代码移动到一个类中,也可以单独进行测试。
if (project.findProperty("releaseEngineer") != null) {
tasks.register("release") {
doLast {
logger.quiet("Releasing to production...")
// release the artifact to production
}
}
}if (project.findProperty('releaseEngineer') != null) {
tasks.register('release') {
doLast {
logger.quiet 'Releasing to production...'
// release the artifact to production
}
}
}让我们将构建脚本与作为二进制插件实现的相同逻辑进行比较。该代码乍一看可能看起来更复杂,但显然看起来更像典型的应用程序代码。这个特定的插件类位于buildSrc目录中,这使得构建脚本可以自动使用它。
package com.enterprise;
import org.gradle.api.Action;
import org.gradle.api.Plugin;
import org.gradle.api.Project;
import org.gradle.api.Task;
import org.gradle.api.tasks.TaskProvider;
public class ReleasePlugin implements Plugin<Project> {
private static final String RELEASE_ENG_ROLE_PROP = "releaseEngineer";
private static final String RELEASE_TASK_NAME = "release";
@Override
public void apply(Project project) {
if (project.findProperty(RELEASE_ENG_ROLE_PROP) != null) {
Task task = project.getTasks().create(RELEASE_TASK_NAME);
task.doLast(new Action<Task>() {
@Override
public void execute(Task task) {
task.getLogger().quiet("Releasing to production...");
// release the artifact to production
}
});
}
}
}现在构建逻辑已转换为插件,您可以将其应用到构建脚本中。构建脚本已从 8 行代码缩减为一行。
plugins {
id("com.enterprise.release")
}plugins {
id 'com.enterprise.release'
}避免使用内部 Gradle API
当 Gradle 或插件发生更改时,在插件和构建脚本中使用 Gradle 内部 API 可能会破坏构建。
Gradle 公共 API 定义
和
Kotlin DSL API 定义中列出了以下包
,internal名称中带有 的任何子包除外。
org.gradle org.gradle.api.* org.gradle.authentication.* org.gradle.build.* org.gradle.buildinit.* org.gradle.caching.* org.gradle.concurrent.* org.gradle.deployment.* org.gradle.external.javadoc.* org.gradle.ide.* org.gradle.ivy.* org.gradle.jvm.* org.gradle.language.* org.gradle.maven.* org.gradle.nativeplatform.* org.gradle.normalization.* org.gradle.platform.* org.gradle.plugin.devel.* org.gradle.plugin.use org.gradle.plugin.management org.gradle.plugins.* org.gradle.process.* org.gradle.testfixtures.* org.gradle.testing.jacoco.* org.gradle.tooling.* org.gradle.swiftpm.* org.gradle.model.* org.gradle.testkit.* org.gradle.testing.* org.gradle.vcs.* org.gradle.work.* org.gradle.workers.* org.gradle.util.*
org.gradle.kotlin.dsl org.gradle.kotlin.dsl.precompile
常用内部 API 的替代方案
要为您的自定义任务提供嵌套 DSL,请勿使用org.gradle.internal.reflect.Instantiator;请改用ObjectFactory。阅读有关延迟配置的章节也可能会有所帮助。
代替org.gradle.internal.os.OperatingSystem,使用另一种方法来检测操作系统,例如Apache commons-lang SystemUtils或System.getProperty("os.name").
使用其他集合或 I/O 框架代替org.gradle.util.CollectionUtils、org.gradle.util.internal.GFileUtils和 下的其他类org.gradle.util.*。
声明任务时遵循约定
任务 API 为构建作者在构建脚本中声明任务提供了很大的灵活性。为了获得最佳的可读性和可维护性,请遵循以下规则:
-
任务类型应该是任务名称后面括号内的唯一键值对。
-
其他配置应在任务的配置块内完成。
-
声明任务时添加的任务操作只能使用方法Task.doFirst{}或Task.doLast{}声明。
-
声明临时任务(没有显式类型的任务)时,如果您仅声明单个操作,则应使用Task.doLast{} 。
-
任务应该定义组和描述。
import com.enterprise.DocsGenerate
tasks.register<DocsGenerate>("generateHtmlDocs") {
group = JavaBasePlugin.DOCUMENTATION_GROUP
description = "Generates the HTML documentation for this project."
title = "Project docs"
outputDir = layout.buildDirectory.dir("docs")
}
tasks.register("allDocs") {
group = JavaBasePlugin.DOCUMENTATION_GROUP
description = "Generates all documentation for this project."
dependsOn("generateHtmlDocs")
doLast {
logger.quiet("Generating all documentation...")
}
}import com.enterprise.DocsGenerate
def generateHtmlDocs = tasks.register('generateHtmlDocs', DocsGenerate) {
group = JavaBasePlugin.DOCUMENTATION_GROUP
description = 'Generates the HTML documentation for this project.'
title = 'Project docs'
outputDir = layout.buildDirectory.dir('docs')
}
tasks.register('allDocs') {
group = JavaBasePlugin.DOCUMENTATION_GROUP
description = 'Generates all documentation for this project.'
dependsOn generateHtmlDocs
doLast {
logger.quiet('Generating all documentation...')
}
}提高任务的可发现性
即使是构建的新用户也应该能够快速、轻松地找到关键信息。在 Gradle 中,您可以为构建的任何任务声明一个组和描述。任务报告使用分配的值来组织和呈现任务,以便于发现。分配组和描述对于您希望构建用户调用的任何任务最有帮助。
该示例任务generateDocs以 HTML 页面的形式生成项目文档。任务应该组织在桶下面Documentation。描述应表达其意图。
tasks.register("generateDocs") {
group = "Documentation"
description = "Generates the HTML documentation for this project."
doLast {
// action implementation
}
}tasks.register('generateDocs') {
group = 'Documentation'
description = 'Generates the HTML documentation for this project.'
doLast {
// action implementation
}
}任务报告的输出反映了分配的值。
> gradle tasks > Task :tasks Documentation tasks ------------------- generateDocs - Generates the HTML documentation for this project.
最小化配置阶段执行的逻辑
对于每个构建脚本开发人员来说,了解构建生命周期的不同阶段及其对构建逻辑的性能和评估顺序的影响非常重要。在配置阶段,应该配置项目及其域对象,而执行阶段仅执行命令行上请求的任务的操作及其依赖项。请注意,任何不属于任务操作的代码都将在每次构建运行时执行。构建扫描可以帮助您确定每个生命周期阶段所花费的时间。它是诊断常见性能问题的宝贵工具。
让我们考虑一下上述反模式的以下咒语。在构建脚本中,您可以看到分配给配置的依赖项printArtifactNames是在任务操作之外解析的。
dependencies {
implementation("log4j:log4j:1.2.17")
}
tasks.register("printArtifactNames") {
// always executed
val libraryNames = configurations.compileClasspath.get().map { it.name }
doLast {
logger.quiet(libraryNames.joinToString())
}
}dependencies {
implementation 'log4j:log4j:1.2.17'
}
tasks.register('printArtifactNames') {
// always executed
def libraryNames = configurations.compileClasspath.collect { it.name }
doLast {
logger.quiet libraryNames
}
}用于解决依赖关系的代码应移至任务操作中,以避免在实际需要依赖关系之前解决依赖关系对性能造成影响。
dependencies {
implementation("log4j:log4j:1.2.17")
}
tasks.register("printArtifactNames") {
val compileClasspath: FileCollection = configurations.compileClasspath.get()
doLast {
val libraryNames = compileClasspath.map { it.name }
logger.quiet(libraryNames.joinToString())
}
}dependencies {
implementation 'log4j:log4j:1.2.17'
}
tasks.register('printArtifactNames') {
FileCollection compileClasspath = configurations.compileClasspath
doLast {
def libraryNames = compileClasspath.collect { it.name }
logger.quiet libraryNames
}
}避免使用GradleBuild任务类型
GradleBuild任务类型允许构建脚本定义调用另一个 Gradle 构建的任务。通常不鼓励使用这种类型。在某些特殊情况下,调用的构建不会公开与命令行或工具 API 相同的运行时行为,从而导致意外结果。
通常,有更好的方法来对需求进行建模。适当的方法取决于当前的问题。这里有一些选项:
避免项目间配置
Gradle 不限制构建脚本作者在多项目构建中从一个项目进入另一个项目的域模型。强耦合的项目会损害构建执行性能以及代码的可读性和可维护性。
应避免以下做法:
-
通过Task.dependsOn(java.lang.Object...)显式依赖于另一个项目的任务。
-
从另一个项目设置属性值或调用域对象的方法。
-
使用GradleBuild执行构建的另一部分。
-
声明不必要的项目依赖关系。
外部化并加密您的密码
大多数构建需要使用一个或多个密码。这种需要的原因可能有所不同。某些构建需要密码才能将工件发布到安全的二进制存储库,其他构建需要密码才能下载二进制文件。密码应始终安全,以防止欺诈。在任何情况下都不应将密码以纯文本形式添加到构建脚本中或在gradle.properties项目目录的文件中声明它。这些文件通常位于版本控制存储库中,任何有权访问它的人都可以查看。
密码和任何其他敏感数据应保存在版本控制项目文件的外部。 Gradle 公开了一个 API,用于在ProviderFactory
和Artifact Repositories中提供凭证
,允许
在构建需要时使用Gradle 属性提供凭证值。这样,凭据可以存储在gradle.properties驻留在用户主目录中的文件中,或者使用命令行参数或环境变量注入到构建中。
如果您将敏感凭据存储在用户 home 中gradle.properties,请考虑对其进行加密。目前 Gradle 不提供用于加密、存储和访问密码的内置机制。解决这个问题的一个很好的解决方案是Gradle Credentials 插件。
不要预期配置创建
Gradle 将使用“如果需要则检查”策略创建某些配置,例如default或。archives这意味着它只会创建这些配置(如果它们尚不存在)。
您不应该自己创建这些配置。诸如此类的名称以及与源集关联的配置的名称应被视为隐式“保留”。保留名称的确切列表取决于应用的插件以及构建的配置方式。
这种情况将通过以下弃用警告来宣布:
Configuration customCompileClasspath already exists with permitted usage(s):
Consumable - this configuration can be selected by another project as a dependency
Resolvable - this configuration can be resolved by this project to a set of files
Declarable - this configuration can have dependencies added to it
Yet Gradle expected to create it with the usage(s):
Resolvable - this configuration can be resolved by this project to a set of files然后,Gradle 将尝试改变允许的用法以匹配预期的用法,并发出第二个警告:
Gradle will mutate the usage of this configuration to match the expected usage. This may cause unexpected behavior. Creating configurations with reserved names has been deprecated. This is scheduled to be removed in Gradle 9.0. Create source sets prior to creating or accessing the configurations associated with them.某些配置可能会锁定其用途以防止突变。在这种情况下,您的构建将失败,并且此警告之后将立即出现带有以下消息的异常:
Gradle cannot mutate the usage of configuration 'customCompileClasspath' because it is locked.如果您遇到此错误,您必须:
-
更改配置的名称以避免冲突。
-
如果无法更改名称,请确保配置允许的用途(可消耗的、可解析的、可声明的)与 Gradle 的期望一致。
作为最佳实践,您不应该“预期”配置创建 - 让 Gradle 首先创建配置,然后调整它。或者,如果可能,请在看到此警告时重命名自定义配置,使用不冲突的名称。
其他主题
Gradle 管理的目录
Gradle 使用两个主要目录来执行和管理其工作:Gradle 用户主目录和项目根目录。
Gradle 用户主目录
默认情况下,Gradle 用户主页(~/.gradle或C:\Users\<USERNAME>\.gradle)存储全局配置属性、初始化脚本、缓存和日志文件。
可以通过环境变量来设置GRADLE_USER_HOME。
|
提示
|
GRADLE_HOME不要与Gradle 的可选安装目录
混淆。 |
其结构大致如下:
├── caches // (1) │ ├── 4.8 // (2) │ ├── 4.9 // (2) │ ├── ⋮ │ ├── jars-3 // (3) │ └── modules-2 // (3) ├── daemon // (4) │ ├── ⋮ │ ├── 4.8 │ └── 4.9 ├── init.d // (5) │ └── my-setup.gradle ├── jdks // (6) │ ├── ⋮ │ └── jdk-14.0.2+12 ├── wrapper │ └── dists // (7) │ ├── ⋮ │ ├── gradle-4.8-bin │ ├── gradle-4.9-all │ └── gradle-4.9-bin └── gradle.properties // (8)
-
全局缓存目录(用于所有非项目特定的内容)。
-
版本特定的缓存(例如,支持增量构建)。
-
共享缓存(例如,用于依赖项的工件)。
-
Gradle Daemon的注册表和日志。
-
全局初始化脚本。
-
通过工具链支持下载的 JDK 。
-
由Gradle Wrapper下载的发行版。
-
全局Gradle 配置属性。
清理缓存和分发
Gradle 会自动清理其用户主目录。
默认情况下,当 Gradle 守护程序停止或关闭时,清理工作在后台运行。
如果使用--no-daemon,它会在构建会话后在前台运行。
定期应用以下清理策略(默认情况下,每 24 小时一次):
-
检查所有目录中特定于版本的缓存
caches/<GRADLE_VERSION>/是否仍在使用。否则,发布版本的目录将在 30 天不活动后被删除,快照版本的目录将在 7 天后被删除。
-
caches/检查(例如)中的共享缓存jars-*是否仍在使用。如果没有 Gradle 版本仍在使用它们,它们将被删除。
-
检查当前 Gradle 版本
caches/(例如jars-3或)中使用的共享缓存中的文件的上次访问时间。modules-2根据文件是否可以在本地重新创建或从远程存储库下载,该文件将分别在 7 天或 30 天后删除。
-
检查Gradle 发行版
wrapper/dists/是否仍在使用,即是否存在相应的特定于版本的缓存目录。未使用的发行版将被删除。
配置缓存和分发的清理
可以配置各种缓存的保留期限。
缓存分为四类:
-
已发布的包装器发行版:与已发行版本相对应的发行版和相关版本特定缓存(例如,
4.6.2或8.0)。未使用版本的默认保留期为 30 天。
-
快照包装器发行版:与快照版本相对应的发行版和相关版本特定缓存(例如
7.6-20221130141522+0000)。未使用版本的默认保留期为 7 天。
-
下载的资源:从远程存储库下载的共享缓存(例如,缓存的依赖项)。
未使用资源的默认保留期为 30 天。
-
创建的资源: Gradle 在构建期间创建的共享缓存(例如,工件转换)。
未使用资源的默认保留期为 7 天。
每个类别的保留期可以通过 Gradle 用户主页中的 init 脚本独立配置:
beforeSettings {
caches {
releasedWrappers.setRemoveUnusedEntriesAfterDays(45)
snapshotWrappers.setRemoveUnusedEntriesAfterDays(10)
downloadedResources.setRemoveUnusedEntriesAfterDays(45)
createdResources.setRemoveUnusedEntriesAfterDays(10)
}
}beforeSettings { settings ->
settings.caches {
releasedWrappers.removeUnusedEntriesAfterDays = 45
snapshotWrappers.removeUnusedEntriesAfterDays = 10
downloadedResources.removeUnusedEntriesAfterDays = 45
createdResources.removeUnusedEntriesAfterDays = 10
}
}调用缓存清理的频率也是可配置的。
有三种可能的设置:
-
默认:在后台定期执行清理(目前每 24 小时一次)。
-
禁用:切勿清理 Gradle 用户主页。
这在 Gradle User Home 是短暂的或者需要延迟清理直到明确的点的情况下非常有用。
-
始终:在每个构建会话结束时执行清理。
这在需要确保在继续之前进行清理的情况下非常有用。
但是,这会在构建期间(而不是在后台)执行缓存清理,这可能会很昂贵,因此仅应在必要时使用此选项。
要禁用缓存清理:
beforeSettings {
caches {
cleanup = Cleanup.DISABLED
}
}beforeSettings { settings ->
settings.caches {
cleanup = Cleanup.DISABLED
}
}|
笔记
|
缓存清理设置只能通过 init 脚本进行配置,并且应放置init.d在 Gradle User Home 的目录下。这有效地将缓存清理的配置耦合到这些设置所应用的 Gradle 用户主页,并限制了将来自不同项目的不同冲突设置应用于同一目录的可能性。
|
多个版本的 Gradle 共享一个 Gradle 用户主页
在多个版本的 Gradle 之间共享一个 Gradle 用户主页是很常见的。
如上所述,Gradle User Home 中的缓存是特定于版本的。不同版本的 Gradle 将仅对与每个版本关联的特定于版本的缓存执行维护。
另一方面,一些缓存在版本之间共享(例如,依赖性工件缓存或工件变换缓存)。
从 Gradle 版本 8.0 开始,可以将缓存清理设置配置为自定义保留期。但是,旧版本有固定的保留期(7 或 30 天,具体取决于缓存)。这些共享缓存可以通过具有不同设置的 Gradle 版本来访问,以保留缓存工件。
这意味着:
-
如果未自定义保留期,则所有执行清理的版本将具有相同的保留期。多个版本共享一个 Gradle User Home 不会有任何影响。
-
如果为大于或等于版本 8.0 的 Gradle 版本自定义保留期以使用比之前固定期限更短的保留期,也不会产生任何影响。
了解这些设置的 Gradle 版本将比之前固定的保留期更早地清理工件,而旧版本实际上不会参与共享缓存的清理。
-
如果为大于或等于版本 8.0 的 Gradle 版本自定义保留期以使用比之前固定期限更长的保留期,则旧版本的 Gradle 可能会比配置的更早清理共享缓存。
在这种情况下,如果需要为新版本维护这些共享缓存条目更长的保留期,它们将无法与旧版本共享 Gradle 用户主页。他们将需要使用单独的目录。
与 8.0 之前的 Gradle 版本共享 Gradle 用户主页时的另一个考虑因素是,用于配置缓存保留设置的 DSL 元素在早期版本中不可用,因此必须在版本之间共享的任何初始化脚本中考虑到这一点。这可以通过有条件地应用版本兼容的脚本来轻松处理。
|
笔记
|
版本兼容的脚本应该驻留在init.d目录之外的其他位置(例如子目录),因此不会自动应用它。
|
要以版本安全的方式配置缓存清理:
if (GradleVersion.current() >= GradleVersion.version("8.0")) {
apply(from = "gradle8/cache-settings.gradle.kts")
}if (GradleVersion.current() >= GradleVersion.version('8.0')) {
apply from: "gradle8/cache-settings.gradle"
}版本兼容的缓存配置脚本:
beforeSettings {
caches {
releasedWrappers { setRemoveUnusedEntriesAfterDays(45) }
snapshotWrappers { setRemoveUnusedEntriesAfterDays(10) }
downloadedResources { setRemoveUnusedEntriesAfterDays(45) }
createdResources { setRemoveUnusedEntriesAfterDays(10) }
}
}beforeSettings { settings ->
settings.caches {
releasedWrappers.removeUnusedEntriesAfterDays = 45
snapshotWrappers.removeUnusedEntriesAfterDays = 10
downloadedResources.removeUnusedEntriesAfterDays = 45
createdResources.removeUnusedEntriesAfterDays = 10
}
}缓存标记
从 Gradle 版本 8.1 开始,Gradle 支持使用CACHEDIR.TAG文件标记缓存。
它遵循缓存目录标记规范中描述的格式。该文件的目的是让工具能够识别不需要搜索或备份的目录。
默认情况下, Gradle 用户主页中的目录caches、wrapper/dists、daemon、 和都标有此文件。jdks
配置缓存标记
缓存标记功能可以通过 Gradle 用户主页中的 init 脚本进行配置:
beforeSettings {
caches {
// Disable cache marking for all caches
markingStrategy = MarkingStrategy.NONE
}
}beforeSettings { settings ->
settings.caches {
// Disable cache marking for all caches
markingStrategy = MarkingStrategy.NONE
}
}|
笔记
|
缓存标记设置只能通过 init 脚本进行配置,并且应放置init.d在 Gradle User Home 的目录下。这有效地将缓存标记的配置耦合到应用这些设置的 Gradle 用户主页,并限制将来自不同项目的不同冲突设置应用于同一目录的可能性。
|
项目根目录
项目根目录包含项目中的所有源文件。
它还包含 Gradle 生成的文件和目录,例如.gradle和build。
虽然前者通常会签入源代码管理,但后者是 Gradle 用于支持增量构建等功能的临时文件。
典型项目根目录的剖析如下:
├── .gradle // (1) │ ├── 4.8 // (2) │ ├── 4.9 // (2) │ └── ⋮ ├── build // (3) ├── gradle │ └── wrapper // (4) ├── gradle.properties // (5) ├── gradlew // (6) ├── gradlew.bat // (6) ├── settings.gradle.kts // (7) ├── subproject-one // (8) | └── build.gradle.kts // (9) ├── subproject-two // (8) | └── build.gradle.kts // (9) └── ⋮
-
Gradle 生成的项目特定的缓存目录。
-
版本特定的缓存(例如,支持增量构建)。
-
该项目的构建目录,Gradle 在其中生成所有构建工件。
-
包含Gradle Wrapper的 JAR 文件和配置。
-
项目特定的Gradle 配置属性。
-
使用Gradle Wrapper执行构建的脚本。
-
定义子项目列表的项目设置文件。
-
通常,一个项目被组织成一个或多个子项目。
-
每个子项目都有自己的 Gradle 构建脚本。
项目缓存清理
从版本 4.10 开始,Gradle 会自动清理项目特定的缓存目录。
构建项目后,.gradle/8.7/会定期(最多每 24 小时)检查 中特定于版本的缓存目录,以确定它们是否仍在使用。如果 7 天未使用,它们将被删除。
下一步: 了解 Gradle 构建生命周期>>
使用文件
几乎每个 Gradle 构建都以某种方式与文件交互:想想源文件、文件依赖项、报告等。这就是 Gradle 提供全面 API 的原因,可以让您轻松执行所需的文件操作。
API 有两个部分:
-
指定要处理的文件和目录
-
指定如何处理它们
复制单个文件
您可以通过创建 Gradle 内置复制任务的实例并使用文件的位置和要放置文件的位置来配置它来复制文件。此示例模拟将生成的报告复制到将打包到存档中的目录,例如 ZIP 或 TAR:
tasks.register<Copy>("copyReport") {
from(layout.buildDirectory.file("reports/my-report.pdf"))
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyReport', Copy) {
from layout.buildDirectory.file("reports/my-report.pdf")
into layout.buildDirectory.dir("toArchive")
}ProjectLayout类用于查找相对于当前项目的文件或目录路径。这是使构建脚本无论项目路径如何都能正常工作的常用方法。然后,文件和目录路径用于指定使用Copy.from(java.lang.Object…)复制哪个文件以及使用Copy.into(java.lang.Object)将其复制到哪个目录。
尽管硬编码路径可以提供简单的示例,但它们也会使构建变得脆弱。最好使用可靠的单一事实来源,例如任务或共享项目属性。在下面的修改示例中,我们使用在其他地方定义的报告任务,该任务将报告的位置存储在其outputFile属性中:
tasks.register<Copy>("copyReport2") {
from(myReportTask.flatMap { it.outputFile })
into(archiveReportsTask.flatMap { it.dirToArchive })
}tasks.register('copyReport2', Copy) {
from myReportTask.outputFile
into archiveReportsTask.dirToArchive
}我们还假设报告将由 存档archiveReportsTask,这为我们提供了将存档的目录,以及我们想要放置报告副本的位置。
复制多个文件
您可以通过提供多个参数来轻松地将前面的示例扩展到多个文件from():
tasks.register<Copy>("copyReportsForArchiving") {
from(layout.buildDirectory.file("reports/my-report.pdf"), layout.projectDirectory.file("src/docs/manual.pdf"))
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyReportsForArchiving', Copy) {
from layout.buildDirectory.file("reports/my-report.pdf"), layout.projectDirectory.file("src/docs/manual.pdf")
into layout.buildDirectory.dir("toArchive")
}现在有两个文件被复制到存档目录中。您还可以使用多个语句来执行相同的操作,如深度文件复制from()部分的第一个示例所示。
现在考虑另一个例子:如果您想复制目录中的所有 PDF 而不必指定每个 PDF,该怎么办?为此,请将包含和/或排除模式附加到复制规范。这里我们使用字符串模式仅包含 PDF:
tasks.register<Copy>("copyPdfReportsForArchiving") {
from(layout.buildDirectory.dir("reports"))
include("*.pdf")
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyPdfReportsForArchiving', Copy) {
from layout.buildDirectory.dir("reports")
include "*.pdf"
into layout.buildDirectory.dir("toArchive")
}需要注意的一件事是,如下图所示,仅reports复制直接驻留在该目录中的 PDF:

您可以使用 Ant 风格的 glob 模式 ( **/*) 将文件包含在子目录中,如本更新示例中所示:
tasks.register<Copy>("copyAllPdfReportsForArchiving") {
from(layout.buildDirectory.dir("reports"))
include("**/*.pdf")
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyAllPdfReportsForArchiving', Copy) {
from layout.buildDirectory.dir("reports")
include "**/*.pdf"
into layout.buildDirectory.dir("toArchive")
}该任务有以下效果:

reports需要记住的一件事是,像这样的深层过滤器会产生复制下面的目录结构以及文件的副作用。如果只想复制没有目录结构的文件,则需要使用显式表达式。我们在文件树部分详细讨论文件树和文件集合之间的区别。fileTree(dir) { includes }.files
这只是在 Gradle 构建中处理文件操作时可能遇到的行为变化之一。幸运的是,Gradle 为几乎所有这些用例提供了优雅的解决方案。请阅读本章后面的深入部分,了解有关 Gradle 中文件操作如何工作以及配置它们的选项的更多详细信息。
复制目录层次结构
您可能不仅需要复制文件,还需要复制它们所在的目录结构。这是指定目录作为参数时的默认行为from(),如以下示例所示,该示例将reports目录中的所有内容(包括其所有子目录)复制到目标:
tasks.register<Copy>("copyReportsDirForArchiving") {
from(layout.buildDirectory.dir("reports"))
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyReportsDirForArchiving', Copy) {
from layout.buildDirectory.dir("reports")
into layout.buildDirectory.dir("toArchive")
}用户面临的关键问题是控制有多少目录结构到达目的地。在上面的示例中,您是否获得一个toArchive/reports目录,或者其中的所有内容都reports直接进入toArchive?答案是后者。如果目录是from()路径的一部分,那么它不会出现在目标中。
那么如何确保reports自身被复制,而不是 中的任何其他目录${layout.buildDirectory}?答案是将其添加为包含模式:
tasks.register<Copy>("copyReportsDirForArchiving2") {
from(layout.buildDirectory) {
include("reports/**")
}
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyReportsDirForArchiving2', Copy) {
from(layout.buildDirectory) {
include "reports/**"
}
into layout.buildDirectory.dir("toArchive")
}您将得到与以前相同的行为,除了在目标中多了一层目录,即toArchive/reports.
需要注意的一件事是该include()指令仅适用于from(),而上一节中的指令适用于整个任务。复制规范中的这些不同粒度级别使您能够轻松处理您将遇到的大多数需求。您可以在子规范部分了解更多相关信息。
创建档案(zip、tar 等)
从 Gradle 的角度来看,将文件打包到存档中实际上是一个副本,其中目标是存档文件而不是文件系统上的目录。这意味着创建档案看起来很像复制,并且具有所有相同的功能!
最简单的情况涉及归档目录的全部内容,本示例通过创建目录的 ZIP 来演示toArchive:
tasks.register<Zip>("packageDistribution") {
archiveFileName = "my-distribution.zip"
destinationDirectory = layout.buildDirectory.dir("dist")
from(layout.buildDirectory.dir("toArchive"))
}tasks.register('packageDistribution', Zip) {
archiveFileName = "my-distribution.zip"
destinationDirectory = layout.buildDirectory.dir('dist')
from layout.buildDirectory.dir("toArchive")
}请注意我们如何指定存档的目标和名称而不是into():两者都是必需的。您通常不会看到它们被显式设置,因为大多数项目都应用Base Plugin。它为这些属性提供了一些常规值。下一个示例演示了这一点,您可以了解有关存档命名部分中的约定的更多信息。
最常见的场景之一是将文件复制到存档的指定子目录中。例如,假设您要将所有 PDF 打包到docs存档根目录中的一个目录中。源位置中不存在此docs目录,因此您必须将其创建为存档的一部分。您可以通过into()仅添加 PDF 声明来完成此操作:
plugins {
base
}
version = "1.0.0"
tasks.register<Zip>("packageDistribution") {
from(layout.buildDirectory.dir("toArchive")) {
exclude("**/*.pdf")
}
from(layout.buildDirectory.dir("toArchive")) {
include("**/*.pdf")
into("docs")
}
}plugins {
id 'base'
}
version = "1.0.0"
tasks.register('packageDistribution', Zip) {
from(layout.buildDirectory.dir("toArchive")) {
exclude "**/*.pdf"
}
from(layout.buildDirectory.dir("toArchive")) {
include "**/*.pdf"
into "docs"
}
}正如您所看到的,您可以from()在副本规范中拥有多个声明,每个声明都有自己的配置。有关此功能的更多信息,请参阅使用子副本规范。
解压档案
存档实际上是独立的文件系统,因此解压它们就是将文件从该文件系统复制到本地文件系统,甚至复制到另一个存档中。 Gradle 通过提供一些包装函数来实现这一点,这些函数使档案可以作为文件的分层集合(文件树)使用。
感兴趣的两个函数是Project.zipTree(java.lang.Object)和Project.tarTree(java.lang.Object) ,它们从相应的归档文件生成FileTree 。然后可以在规范中使用该文件树from(),如下所示:
tasks.register<Copy>("unpackFiles") {
from(zipTree("src/resources/thirdPartyResources.zip"))
into(layout.buildDirectory.dir("resources"))
}tasks.register('unpackFiles', Copy) {
from zipTree("src/resources/thirdPartyResources.zip")
into layout.buildDirectory.dir("resources")
}更高级的处理可以通过eachFile()方法进行。例如,您可能需要将存档的不同子树提取到目标目录中的不同路径中。以下示例使用该方法将存档libs目录中的文件提取到根目标目录中,而不是提取到libs子目录中:
tasks.register<Copy>("unpackLibsDirectory") {
from(zipTree("src/resources/thirdPartyResources.zip")) {
include("libs/**") // (1)
eachFile {
relativePath = RelativePath(true, *relativePath.segments.drop(1).toTypedArray()) // (2)
}
includeEmptyDirs = false // (3)
}
into(layout.buildDirectory.dir("resources"))
}tasks.register('unpackLibsDirectory', Copy) {
from(zipTree("src/resources/thirdPartyResources.zip")) {
include "libs/**" // (1)
eachFile { fcd ->
fcd.relativePath = new RelativePath(true, fcd.relativePath.segments.drop(1)) // (2)
}
includeEmptyDirs = false // (3)
}
into layout.buildDirectory.dir("resources")
}-
libs仅提取驻留在目录中的文件子集 -
libs通过从文件路径中删除段,将提取文件的路径重新映射到目标目录 -
忽略重新映射产生的空目录,请参阅下面的注意事项
|
警告
|
您无法使用此技术更改空目录的目标路径。您可以在本期了解更多信息。 |
如果您是一名 Java 开发人员并且想知道为什么没有jarTree()方法,那是因为zipTree()它非常适合 JAR、WAR 和 EAR。
创建“uber”或“fat”JAR
在 Java 领域,应用程序及其依赖项通常打包为单个分发存档中的单独 JAR。这种情况仍然会发生,但现在还有另一种常见的方法:将依赖项的类和资源直接放入应用程序 JAR 中,创建所谓的 uber 或 fat JAR。
Gradle 使这种方法很容易实现。考虑目标:将其他 JAR 文件的内容复制到应用程序 JAR 中。为此,您需要的只是Project.zipTree(java.lang.Object)方法和JaruberJar任务,如以下示例中的任务所示:
plugins {
java
}
version = "1.0.0"
repositories {
mavenCentral()
}
dependencies {
implementation("commons-io:commons-io:2.6")
}
tasks.register<Jar>("uberJar") {
archiveClassifier = "uber"
from(sourceSets.main.get().output)
dependsOn(configurations.runtimeClasspath)
from({
configurations.runtimeClasspath.get().filter { it.name.endsWith("jar") }.map { zipTree(it) }
})
}plugins {
id 'java'
}
version = '1.0.0'
repositories {
mavenCentral()
}
dependencies {
implementation 'commons-io:commons-io:2.6'
}
tasks.register('uberJar', Jar) {
archiveClassifier = 'uber'
from sourceSets.main.output
dependsOn configurations.runtimeClasspath
from {
configurations.runtimeClasspath.findAll { it.name.endsWith('jar') }.collect { zipTree(it) }
}
}在本例中,我们将获取项目的运行时依赖项 —configurations.runtimeClasspath.files并使用该方法包装每个 JAR 文件zipTree()。结果是 ZIP 文件树的集合,其内容与应用程序类一起复制到 uber JAR 中。
创建目录
许多任务需要创建目录来存储它们生成的文件,这就是为什么 Gradle 在显式定义文件和目录输出时自动管理任务的这方面。您可以在用户手册的增量构建部分了解此功能。所有核心 Gradle 任务都确保在必要时使用此机制创建它们所需的任何输出目录。
如果您需要手动创建目录,您可以使用构建脚本或自定义任务实现中的标准Files.createDirectories或方法。这是一个在项目文件夹中File.mkdirs创建单个目录的简单示例:images
tasks.register("ensureDirectory") {
// Store target directory into a variable to avoid project reference in the configuration cache
val directory = file("images")
doLast {
Files.createDirectories(directory.toPath())
}
}tasks.register('ensureDirectory') {
// Store target directory into a variable to avoid project reference in the configuration cache
def directory = file("images")
doLast {
Files.createDirectories(directory.toPath())
}
}正如Apache Ant 手册中所述,该mkdir任务将自动在给定路径中创建所有必需的目录,如果该目录已存在,则不会执行任何操作。
移动文件和目录
Gradle 没有用于移动文件和目录的 API,但您可以使用Apache Ant 集成轻松做到这一点,如本示例所示:
tasks.register("moveReports") {
// Store the build directory into a variable to avoid project reference in the configuration cache
val dir = buildDir
doLast {
ant.withGroovyBuilder {
"move"("file" to "${dir}/reports", "todir" to "${dir}/toArchive")
}
}
}tasks.register('moveReports') {
// Store the build directory into a variable to avoid project reference in the configuration cache
def dir = buildDir
doLast {
ant.move file: "${dir}/reports",
todir: "${dir}/toArchive"
}
}这不是一个常见的要求,应该谨慎使用,因为您会丢失信息并且很容易破坏构建。通常最好是复制目录和文件。
重命名副本上的文件
构建使用和生成的文件有时没有合适的名称,在这种情况下,您需要在复制这些文件时重命名它们。 Gradle 允许您使用配置将其作为复制规范的一部分来执行rename()。
以下示例从包含“-staging”标记的任何文件的名称中删除该标记:
tasks.register<Copy>("copyFromStaging") {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
rename("(.+)-staging(.+)", "$1$2")
}tasks.register('copyFromStaging', Copy) {
from "src/main/webapp"
into layout.buildDirectory.dir('explodedWar')
rename '(.+)-staging(.+)', '$1$2'
}您可以使用正则表达式(如上面的示例所示),或者使用更复杂的逻辑来确定目标文件名的闭包。例如,以下任务截断文件名:
tasks.register<Copy>("copyWithTruncate") {
from(layout.buildDirectory.dir("reports"))
rename { filename: String ->
if (filename.length > 10) {
filename.slice(0..7) + "~" + filename.length
}
else filename
}
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyWithTruncate', Copy) {
from layout.buildDirectory.dir("reports")
rename { String filename ->
if (filename.size() > 10) {
return filename[0..7] + "~" + filename.size()
}
else return filename
}
into layout.buildDirectory.dir("toArchive")
}与过滤一样,您还可以通过将文件子集配置为from().
删除文件和目录
您可以使用删除任务或Project.delete(org.gradle.api.Action)方法轻松删除文件和目录。在这两种情况下,您都可以以Project.files(java.lang.Object…)方法支持的方式指定要删除的文件和目录。
例如,以下任务删除构建输出目录的全部内容:
tasks.register<Delete>("myClean") {
delete(buildDir)
}tasks.register('myClean', Delete) {
delete buildDir
}如果您想要更好地控制删除哪些文件,则不能像复制文件一样使用包含和排除。相反,您必须使用FileCollection和的内置过滤机制FileTree。以下示例就是从源目录中清除临时文件:
tasks.register<Delete>("cleanTempFiles") {
delete(fileTree("src").matching {
include("**/*.tmp")
})
}tasks.register('cleanTempFiles', Delete) {
delete fileTree("src").matching {
include "**/*.tmp"
}
}您将在下一节中了解有关文件集合和文件树的更多信息。
深度文件路径
为了对文件执行某些操作,您需要知道它在哪里,这就是文件路径提供的信息。 Gradle 构建在标准 JavaFile类的基础上,该类表示单个文件的位置,并提供新的 API 来处理路径集合。本部分向您展示如何使用 Gradle API 指定用于任务和文件操作的文件路径。
但首先,关于在构建中使用硬编码文件路径的重要说明。
在硬编码文件路径上
本章中的许多示例使用硬编码路径作为字符串文字。这使得它们很容易理解,但这对于真正的构建来说并不是一个好的实践。问题是路径经常改变,并且需要改变路径的地方越多,就越有可能错过一个路径并破坏构建。
如果可能,您应该使用任务、任务属性和项目属性(按优先顺序)来配置文件路径。例如,如果您要创建一个打包 Java 应用程序的已编译类的任务,那么您的目标应该是这样的:
val archivesDirPath = layout.buildDirectory.dir("archives")
tasks.register<Zip>("packageClasses") {
archiveAppendix = "classes"
destinationDirectory = archivesDirPath
from(tasks.compileJava)
}def archivesDirPath = layout.buildDirectory.dir('archives')
tasks.register('packageClasses', Zip) {
archiveAppendix = "classes"
destinationDirectory = archivesDirPath
from compileJava
}了解我们如何使用该compileJava任务作为要打包的文件的源,并且我们创建了一个项目属性archivesDirPath来存储放置档案的位置,基于我们可能在构建中的其他地方使用它。
像这样直接使用任务作为参数依赖于它已定义的输出,因此它并不总是可能的。此外,这个示例可以通过依赖 Java 插件的约定而destinationDirectory不是覆盖它来进一步改进,但它确实演示了项目属性的使用。
单个文件和目录
Gradle 提供了Project.file(java.lang.Object)方法来指定单个文件或目录的位置。相对路径是相对于项目目录解析的,而绝对路径保持不变。
|
警告
|
|
以下是使用file()具有不同类型参数的方法的一些示例:
// Using a relative path
var configFile = file("src/config.xml")
// Using an absolute path
configFile = file(configFile.absolutePath)
// Using a File object with a relative path
configFile = file(File("src/config.xml"))
// Using a java.nio.file.Path object with a relative path
configFile = file(Paths.get("src", "config.xml"))
// Using an absolute java.nio.file.Path object
configFile = file(Paths.get(System.getProperty("user.home")).resolve("global-config.xml"))// Using a relative path
File configFile = file('src/config.xml')
// Using an absolute path
configFile = file(configFile.absolutePath)
// Using a File object with a relative path
configFile = file(new File('src/config.xml'))
// Using a java.nio.file.Path object with a relative path
configFile = file(Paths.get('src', 'config.xml'))
// Using an absolute java.nio.file.Path object
configFile = file(Paths.get(System.getProperty('user.home')).resolve('global-config.xml'))正如您所看到的,您可以将字符串、File实例和Path实例传递给file()方法,所有这些都会产生绝对File对象。您可以在上一段中链接的参考指南中找到参数类型的其他选项。
在多项目构建的情况下会发生什么?该file()方法始终将相对路径转换为相对于当前项目目录(可能是子项目)的路径。如果要使用相对于项目根目录的路径,则需要使用特殊的Project.getRootDir()属性来构造绝对路径,如下所示:
val configFile = file("$rootDir/shared/config.xml")File configFile = file("$rootDir/shared/config.xml")假设您正在目录中进行多项目构建dev/projects/AcmeHealth。您可以在正在修复的库的构建中使用上面的示例 - at AcmeHealth/subprojects/AcmePatientRecordLib/build.gradle。文件路径将解析为dev/projects/AcmeHealth/shared/config.xml.
该file()方法可用于配置具有 type 属性的任何任务File。不过,许多任务都处理多个文件,因此我们接下来看看如何指定文件集。
文件收藏
文件集合只是由FileCollection接口表示的一组文件路径。任何文件路径。重要的是要了解文件路径不必以任何方式相关,因此它们不必位于同一目录中,甚至不必具有共享的父目录。您还会发现 Gradle API 的许多部分都被使用FileCollection,例如本章后面讨论的复制 API 和依赖项配置。
指定文件集合的推荐方法是使用ProjectLayout.files(java.lang.Object...)方法,该方法返回一个FileCollection实例。此方法非常灵活,允许您传递多个字符串、File实例、字符串集合、s 集合File等。如果任务已定义输出,您甚至可以将其作为参数传递。在参考指南中了解所有支持的参数类型。
|
警告
|
files()正确处理相对路径和File(relative path)实例,相对于项目目录解析它们。
|
与上一节中介绍的Project.file(java.lang.Object)方法一样,所有相对路径都是相对于当前项目目录进行评估的。以下示例演示了您可以使用的一些参数类型 - 字符串、实例、列表和 a :FilePath
val collection: FileCollection = layout.files(
"src/file1.txt",
File("src/file2.txt"),
listOf("src/file3.csv", "src/file4.csv"),
Paths.get("src", "file5.txt")
)FileCollection collection = layout.files('src/file1.txt',
new File('src/file2.txt'),
['src/file3.csv', 'src/file4.csv'],
Paths.get('src', 'file5.txt'))文件集合在 Gradle 中具有一些重要的属性。他们可以:
-
懒惰地创建
-
迭代
-
过滤的
-
合并的
当您需要在构建运行时评估组成集合的文件时,延迟创建文件集合非常有用。在下面的示例中,我们查询文件系统以找出特定目录中存在哪些文件,然后将它们放入文件集合中:
tasks.register("list") {
val projectDirectory = layout.projectDirectory
doLast {
var srcDir: File? = null
val collection = projectDirectory.files({
srcDir?.listFiles()
})
srcDir = projectDirectory.file("src").asFile
println("Contents of ${srcDir.name}")
collection.map { it.relativeTo(projectDirectory.asFile) }.sorted().forEach { println(it) }
srcDir = projectDirectory.file("src2").asFile
println("Contents of ${srcDir.name}")
collection.map { it.relativeTo(projectDirectory.asFile) }.sorted().forEach { println(it) }
}
}tasks.register('list') {
Directory projectDirectory = layout.projectDirectory
doLast {
File srcDir
// Create a file collection using a closure
collection = projectDirectory.files { srcDir.listFiles() }
srcDir = projectDirectory.file('src').asFile
println "Contents of $srcDir.name"
collection.collect { projectDirectory.asFile.relativePath(it) }.sort().each { println it }
srcDir = projectDirectory.file('src2').asFile
println "Contents of $srcDir.name"
collection.collect { projectDirectory.asFile.relativePath(it) }.sort().each { println it }
}
}gradle -q list> gradle -q list Contents of src src/dir1 src/file1.txt Contents of src2 src2/dir1 src2/dir2
延迟创建的关键是将闭包(在 Groovy 中)或 a Provider(在 Kotlin 中)传递给files()方法。您的闭包/提供者只需要返回 接受的类型的值files(),例如List<File>、String、FileCollection等。
可以通过集合上的each()方法(在 Groovy 中)或forEach方法(在 Kotlin 中)或在循环中使用集合来迭代文件集合for。在这两种方法中,文件集合都被视为一组File实例,即迭代变量的类型为File。
以下示例演示了此类迭代以及如何使用as运算符或支持的属性将文件集合转换为其他类型:
// Iterate over the files in the collection
collection.forEach { file: File ->
println(file.name)
}
// Convert the collection to various types
val set: Set<File> = collection.files
val list: List<File> = collection.toList()
val path: String = collection.asPath
val file: File = collection.singleFile
// Add and subtract collections
val union = collection + projectLayout.files("src/file2.txt")
val difference = collection - projectLayout.files("src/file2.txt")// Iterate over the files in the collection
collection.each { File file ->
println file.name
}
// Convert the collection to various types
Set set = collection.files
Set set2 = collection as Set
List list = collection as List
String path = collection.asPath
File file = collection.singleFile
// Add and subtract collections
def union = collection + projectLayout.files('src/file2.txt')
def difference = collection - projectLayout.files('src/file2.txt')您还可以在示例的末尾看到如何使用+和-运算符来合并和减go文件集合。生成的文件集合的一个重要特征是它们是实时的。换句话说,当您以这种方式组合文件集合时,结果始终反映源文件集合中当前的内容,即使它们在构建过程中发生了变化。
例如,假设在上面的示例中创建collection后获得一两个额外的文件。union只要您union将这些文件添加到后使用collection,union也会包含那些附加文件。文件收集也是如此different。
在过滤方面,实时收藏也很重要。如果要使用文件集合的子集,可以利用FileCollection.filter(org.gradle.api.specs.Spec)方法来确定要“保留”哪些文件。在以下示例中,我们创建一个新集合,其中仅包含源集合中以 .txt 结尾的文件:
val textFiles: FileCollection = collection.filter { f: File ->
f.name.endsWith(".txt")
}FileCollection textFiles = collection.filter { File f ->
f.name.endsWith(".txt")
}gradle -q filterTextFiles> gradle -q filterTextFiles src/file1.txt src/file2.txt src/file5.txt
如果collection任何时候发生更改,无论是通过添加或删除文件本身,textFiles都会立即反映更改,因为它也是一个实时集合。请注意,您传递给的闭包filter()采用 aFile作为参数,并且应该返回一个布尔值。
文件树
文件树是一个文件集合,保留其包含的文件的目录结构并具有FileTree类型。这意味着文件树中的所有路径都必须有一个共享的父目录。下图强调了在复制文件的常见情况下文件树和文件集合之间的区别:

|
笔记
|
虽然FileTree扩展FileCollection(is-a 关系),但它们的行为确实不同。换句话说,只要需要文件集合,您就可以使用文件树,但请记住:文件集合是文件的平面列表/集,而文件树是文件和目录层次结构。要将文件树转换为平面集合,请使用FileTree.getFiles()属性。
|
创建文件树的最简单方法是将文件或目录路径传递给Project.fileTree(java.lang.Object)方法。这将创建该基目录中所有文件和目录的树(但不是基目录本身)。以下示例演示了如何使用基本方法,以及如何使用 Ant 样式模式过滤文件和目录:
// Create a file tree with a base directory
var tree: ConfigurableFileTree = fileTree("src/main")
// Add include and exclude patterns to the tree
tree.include("**/*.java")
tree.exclude("**/Abstract*")
// Create a tree using closure
tree = fileTree("src") {
include("**/*.java")
}
// Create a tree using a map
tree = fileTree("dir" to "src", "include" to "**/*.java")
tree = fileTree("dir" to "src", "includes" to listOf("**/*.java", "**/*.xml"))
tree = fileTree("dir" to "src", "include" to "**/*.java", "exclude" to "**/*test*/**")// Create a file tree with a base directory
ConfigurableFileTree tree = fileTree(dir: 'src/main')
// Add include and exclude patterns to the tree
tree.include '**/*.java'
tree.exclude '**/Abstract*'
// Create a tree using closure
tree = fileTree('src') {
include '**/*.java'
}
// Create a tree using a map
tree = fileTree(dir: 'src', include: '**/*.java')
tree = fileTree(dir: 'src', includes: ['**/*.java', '**/*.xml'])
tree = fileTree(dir: 'src', include: '**/*.java', exclude: '**/*test*/**')您可以在PatternFilterable的 API 文档中查看支持模式的更多示例。另外,请参阅 API 文档,fileTree()了解可以作为基本目录传递的类型。
默认情况下,为了方便起见,fileTree()返回一个FileTree应用一些默认排除模式的实例——实际上与 Ant 的默认值相同。有关完整的默认排除列表,请参阅Ant 手册。
如果这些默认排除被证明有问题,您可以通过更改设置脚本中的默认排除来解决该问题:
import org.apache.tools.ant.DirectoryScanner
DirectoryScanner.removeDefaultExclude("**/.git")
DirectoryScanner.removeDefaultExclude("**/.git/**")import org.apache.tools.ant.DirectoryScanner
DirectoryScanner.removeDefaultExclude('**/.git')
DirectoryScanner.removeDefaultExclude('**/.git/**')|
笔记
|
目前,Gradle 的默认排除是通过 Ant 的DirectoryScanner类配置的。
|
|
重要的
|
Gradle 不支持在执行阶段更改默认排除。 |
您可以使用文件树执行许多与文件集合相同的操作:
-
迭代它们(深度优先)
-
过滤它们(使用FileTree.matching(org.gradle.api.Action)和 Ant 风格模式)
-
合并它们
您还可以使用FileTree.visit(org.gradle.api.Action)方法遍历文件树。以下示例演示了所有这些技术:
// Iterate over the contents of a tree
tree.forEach{ file: File ->
println(file)
}
// Filter a tree
val filtered: FileTree = tree.matching {
include("org/gradle/api/**")
}
// Add trees together
val sum: FileTree = tree + fileTree("src/test")
// Visit the elements of the tree
tree.visit {
println("${this.relativePath} => ${this.file}")
}// Iterate over the contents of a tree
tree.each {File file ->
println file
}
// Filter a tree
FileTree filtered = tree.matching {
include 'org/gradle/api/**'
}
// Add trees together
FileTree sum = tree + fileTree(dir: 'src/test')
// Visit the elements of the tree
tree.visit {element ->
println "$element.relativePath => $element.file"
}我们已经讨论了如何创建自己的文件树和文件集合,但还值得记住的是,许多 Gradle 插件提供了自己的文件树实例,例如Java 的源集。它们的使用和操作方式与您自己创建的文件树完全相同。
用户通常需要的另一种特定类型的文件树是存档,即 ZIP 文件、TAR 文件等。接下来我们将讨论这些文件。
使用档案作为文件树
存档是打包到单个文件中的目录和文件层次结构。换句话说,它是文件树的特例,这正是 Gradle 处理档案的方式。您不使用fileTree()仅适用于普通文件系统的方法,而是使用Project.zipTree(java.lang.Object)和Project.tarTree(java.lang.Object)方法来包装相应类型的存档文件(请注意JAR、WAR 和 EAR 文件是 ZIP)。这两种方法都会返回FileTree实例,然后您可以像普通文件树一样使用这些实例。例如,您可以通过将存档的内容复制到文件系统上的某个目录来提取存档的部分或全部文件。或者您可以将一个存档合并到另一个存档中。
以下是创建基于存档的文件树的一些简单示例:
// Create a ZIP file tree using path
val zip: FileTree = zipTree("someFile.zip")
// Create a TAR file tree using path
val tar: FileTree = tarTree("someFile.tar")
// tar tree attempts to guess the compression based on the file extension
// however if you must specify the compression explicitly you can:
val someTar: FileTree = tarTree(resources.gzip("someTar.ext"))// Create a ZIP file tree using path
FileTree zip = zipTree('someFile.zip')
// Create a TAR file tree using path
FileTree tar = tarTree('someFile.tar')
//tar tree attempts to guess the compression based on the file extension
//however if you must specify the compression explicitly you can:
FileTree someTar = tarTree(resources.gzip('someTar.ext'))您可以在我们介绍的常见场景中看到提取存档文件的实际示例。
了解到文件集合的隐式转换
Gradle 中的许多对象都具有接受一组输入文件的属性。例如,JavaCompile任务有一个source定义要编译的源文件的属性。您可以使用files()方法支持的任何类型来设置此属性的值,如 API 文档中所述。这意味着您可以将属性设置为File、String、 集合,FileCollection甚至是闭包 或Provider。
这是特定任务的一个特点!这意味着隐式转换不会发生在任何具有FileCollection或FileTree属性的任务上。如果你想知道在特定情况下是否发生隐式转换,你需要阅读相关文档,例如相应任务的API文档。或者,您可以通过在构建中显式使用ProjectLayout.files(java.lang.Object...) 来消除所有疑问。
以下是该属性可以采用的不同类型参数的一些示例source:
tasks.register<JavaCompile>("compile") {
// Use a File object to specify the source directory
source = fileTree(file("src/main/java"))
// Use a String path to specify the source directory
source = fileTree("src/main/java")
// Use a collection to specify multiple source directories
source = fileTree(listOf("src/main/java", "../shared/java"))
// Use a FileCollection (or FileTree in this case) to specify the source files
source = fileTree("src/main/java").matching { include("org/gradle/api/**") }
// Using a closure to specify the source files.
setSource({
// Use the contents of each zip file in the src dir
file("src").listFiles().filter { it.name.endsWith(".zip") }.map { zipTree(it) }
})
}tasks.register('compile', JavaCompile) {
// Use a File object to specify the source directory
source = file('src/main/java')
// Use a String path to specify the source directory
source = 'src/main/java'
// Use a collection to specify multiple source directories
source = ['src/main/java', '../shared/java']
// Use a FileCollection (or FileTree in this case) to specify the source files
source = fileTree(dir: 'src/main/java').matching { include 'org/gradle/api/**' }
// Using a closure to specify the source files.
source = {
// Use the contents of each zip file in the src dir
file('src').listFiles().findAll {it.name.endsWith('.zip')}.collect { zipTree(it) }
}
}另一件需要注意的事情是,诸如此类的属性source在核心 Gradle 任务中具有相应的方法。这些方法遵循附加到值集合而不是替换它们的约定。同样,此方法接受files()方法支持的任何类型,如下所示:
tasks.named<JavaCompile>("compile") {
// Add some source directories use String paths
source("src/main/java", "src/main/groovy")
// Add a source directory using a File object
source(file("../shared/java"))
// Add some source directories using a closure
setSource({ file("src/test/").listFiles() })
}compile {
// Add some source directories use String paths
source 'src/main/java', 'src/main/groovy'
// Add a source directory using a File object
source file('../shared/java')
// Add some source directories using a closure
source { file('src/test/').listFiles() }
}由于这是常见约定,我们建议您在自己的自定义任务中遵循它。具体来说,如果您计划添加一个方法来配置基于集合的属性,请确保该方法附加而不是替换值。
文件深度复制
在 Gradle 中复制文件的基本过程很简单:
-
定义复制类型的任务
-
指定要复制的文件(以及可能的目录)
-
指定复制文件的目的地
但这种表面上的简单性隐藏了丰富的 API,它允许对哪些文件被复制、它们go哪里以及复制时发生的情况进行细粒度控制 - 例如,文件重命名和文件内容的令牌替换都是可能的。
让我们从列表中的最后两项开始,它们构成了所谓的复制规范。这正式基于任务实现的CopySpec接口Copy,并提供:
-
一个CopySpec.from(java.lang.Object...)方法来定义要复制的内容
-
用于定义目标的CopySpec.into(java.lang.Object)方法
CopySpec有几个附加方法可以让您控制复制过程,但这两个是唯一需要的。很简单,需要一个目录路径作为其参数,采用Project.file(java.lang.Object)into()方法支持的任何形式。配置更加灵活。from()
不仅from()接受多个参数,还允许多种不同类型的参数。例如,一些最常见的类型是:
-
A
String— 视为文件路径,或者如果以“file://”开头,则视为文件 URI -
A
File— 用作文件路径 -
A
FileCollection或FileTree— 集合中的所有文件都包含在副本中 -
任务 -包含形成任务定义输出的文件或目录
事实上,它接受与Project.files(java.lang.Object...)from()相同的所有参数,因此请参阅该方法以获取可接受类型的更详细列表。
其他需要考虑的是文件路径指的是什么类型:
-
文件 — 文件按原样复制
-
目录 — 这实际上被视为文件树:其中的所有内容(包括子目录)都会被复制。但是,目录本身不包含在副本中。
-
不存在的文件 - 路径被忽略
下面是一个使用多个规范的示例from(),每个规范都有不同的参数类型。您可能还会注意到,它是into()使用闭包(在 Groovy 中)或 Provider(在 Kotlin 中)进行延迟配置的——这种技术也适用于from():
tasks.register<Copy>("anotherCopyTask") {
// Copy everything under src/main/webapp
from("src/main/webapp")
// Copy a single file
from("src/staging/index.html")
// Copy the output of a task
from(copyTask)
// Copy the output of a task using Task outputs explicitly.
from(tasks["copyTaskWithPatterns"].outputs)
// Copy the contents of a Zip file
from(zipTree("src/main/assets.zip"))
// Determine the destination directory later
into({ getDestDir() })
}tasks.register('anotherCopyTask', Copy) {
// Copy everything under src/main/webapp
from 'src/main/webapp'
// Copy a single file
from 'src/staging/index.html'
// Copy the output of a task
from copyTask
// Copy the output of a task using Task outputs explicitly.
from copyTaskWithPatterns.outputs
// Copy the contents of a Zip file
from zipTree('src/main/assets.zip')
// Determine the destination directory later
into { getDestDir() }
}请注意, 的惰性配置与子规范into()不同,尽管语法相似。请注意参数的数量以区分它们。
过滤文件
您已经看到,您可以直接在任务中过滤文件集合和文件树,但您也可以通过CopySpec.include(java.lang.String…)和CopySpec.exclude(java.lang.StringCopy )在任何复制规范中应用过滤。lang.String...)方法。
这两种方法通常与 Ant 风格的包含或排除模式一起使用,如PatternFilterable中所述。您还可以使用闭包来执行更复杂的逻辑,该闭包采用FileTreeElement并返回true是否应包含文件或false其他内容。以下示例演示了这两种形式,确保仅复制 .html 和 .jsp 文件,但内容中包含单词“DRAFT”的 .html 文件除外:
tasks.register<Copy>("copyTaskWithPatterns") {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
include("**/*.html")
include("**/*.jsp")
exclude { details: FileTreeElement ->
details.file.name.endsWith(".html") &&
details.file.readText().contains("DRAFT")
}
}tasks.register('copyTaskWithPatterns', Copy) {
from 'src/main/webapp'
into layout.buildDirectory.dir('explodedWar')
include '**/*.html'
include '**/*.jsp'
exclude { FileTreeElement details ->
details.file.name.endsWith('.html') &&
details.file.text.contains('DRAFT')
}
}此时您可能会问自己一个问题:当包含和排除模式重叠时会发生什么?哪种模式获胜?以下是基本规则:
-
如果没有明确包含或排除,则所有内容都包含在内
-
如果至少指定了一项包含,则仅包含与模式匹配的文件和目录
-
任何排除模式都会覆盖所有包含模式,因此,如果文件或目录至少匹配一种排除模式,则无论包含模式如何,都不会包含该文件或目录
创建组合的包含和排除规范时请记住这些规则,以便最终获得您想要的确切行为。
请注意,上例中的包含和排除内容将适用于所有 from()配置。如果您想对复制文件的子集应用过滤,则需要使用子规范。
重命名文件
如何重命名副本上的文件的示例为您提供了执行此操作所需的大部分信息。它演示了重命名的两个选项:
-
使用正则表达式
-
使用闭包
正则表达式是一种灵活的重命名方法,特别是因为 Gradle 支持正则表达式组,允许您删除和替换部分源文件名。以下示例显示如何使用简单的正则表达式从包含字符串“-staging”的任何文件名中删除该字符串:
tasks.register<Copy>("rename") {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
// Use a regular expression to map the file name
rename("(.+)-staging(.+)", "$1$2")
rename("(.+)-staging(.+)".toRegex().pattern, "$1$2")
// Use a closure to convert all file names to upper case
rename { fileName: String ->
fileName.toUpperCase()
}
}tasks.register('rename', Copy) {
from 'src/main/webapp'
into layout.buildDirectory.dir('explodedWar')
// Use a regular expression to map the file name
rename '(.+)-staging(.+)', '$1$2'
rename(/(.+)-staging(.+)/, '$1$2')
// Use a closure to convert all file names to upper case
rename { String fileName ->
fileName.toUpperCase()
}
}您可以使用 JavaPattern类支持的任何正则表达式和替换字符串( 的第二个参数rename()与该方法的工作原理相同Matcher.appendReplacement()。
在这种情况下使用正则表达式时,人们会遇到两个常见问题:
-
如果您使用斜杠字符串(由“/”分隔)作为第一个参数,则必须包含括号,
rename()如上例所示。 -
对第二个参数使用单引号是最安全的,否则您需要在组替换中转义 '$',即
"\$1\$2"。
第一个是轻微的不便,但斜杠字符串的优点是您不必在正则表达式中转义反斜杠('\')字符。第二个问题源于 Groovy 对使用${ }双引号和斜杠字符串中的语法的嵌入式表达式的支持。
的闭包语法rename()非常简单,可用于简单正则表达式无法处理的任何要求。您将获得一个文件的名称,然后返回该文件的新名称,或者null如果您不想更改该名称。请注意,将为复制的每个文件执行闭包,因此请尽可能避免昂贵的操作。
过滤文件内容(令牌替换、模板化等)
不要与过滤要复制的文件混淆,文件内容过滤允许您在复制文件时转换文件的内容。这可能涉及使用标记替换的基本模板、删除文本行,甚至使用成熟的模板引擎进行更复杂的过滤。
以下示例演示了多种形式的过滤,包括使用CopySpec.expand(java.util.Map)方法的标记替换以及使用CopySpec.filter(java.lang.Class)和Ant 过滤器的另一种方法:
import org.apache.tools.ant.filters.FixCrLfFilter
import org.apache.tools.ant.filters.ReplaceTokens
tasks.register<Copy>("filter") {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
// Substitute property tokens in files
expand("copyright" to "2009", "version" to "2.3.1")
// Use some of the filters provided by Ant
filter(FixCrLfFilter::class)
filter(ReplaceTokens::class, "tokens" to mapOf("copyright" to "2009", "version" to "2.3.1"))
// Use a closure to filter each line
filter { line: String ->
"[$line]"
}
// Use a closure to remove lines
filter { line: String ->
if (line.startsWith('-')) null else line
}
filteringCharset = "UTF-8"
}import org.apache.tools.ant.filters.FixCrLfFilter
import org.apache.tools.ant.filters.ReplaceTokens
tasks.register('filter', Copy) {
from 'src/main/webapp'
into layout.buildDirectory.dir('explodedWar')
// Substitute property tokens in files
expand(copyright: '2009', version: '2.3.1')
// Use some of the filters provided by Ant
filter(FixCrLfFilter)
filter(ReplaceTokens, tokens: [copyright: '2009', version: '2.3.1'])
// Use a closure to filter each line
filter { String line ->
"[$line]"
}
// Use a closure to remove lines
filter { String line ->
line.startsWith('-') ? null : line
}
filteringCharset = 'UTF-8'
}该filter()方法有两个变体,其行为不同:
-
一个采用 a
FilterReader,旨在与 Ant 过滤器一起使用,例如ReplaceTokens -
一个采用闭包或Transformer来定义源文件每一行的转换
请注意,这两种变体都假设源文件是基于文本的。当您将ReplaceTokens类与 一起使用时filter(),结果是一个模板引擎,它将表单的标记@tokenName@(Ant 样式标记)替换为您定义的值。
该expand()方法将源文件视为Groovy 模板,它计算并扩展表单的表达式${expression}。您可以传入属性名称和值,然后在源文件中扩展它们。expand()由于嵌入的表达式是成熟的 Groovy 表达式,因此允许进行的不仅仅是基本的标记替换。
|
笔记
|
读取和写入文件时最好指定字符集,否则转换将无法正确处理非 ASCII 文本。您可以使用CopySpec.setFilteringCharset(String)属性配置字符集。如果未指定,则使用 JVM 默认字符集,该字符集可能与您想要的不同。 |
设置文件权限
对于任何CopySpec涉及复制文件的内容,无论是Copy任务本身还是任何子规范,您都可以通过 CopySpec.filePermissions {}配置块显式设置目标文件将具有的权限。您也可以通过CopySpec.dirPermissions {}配置块对目录执行相同的操作,而与文件无关。
|
笔记
|
不显式设置权限将保留原始文件或目录的权限。 |
tasks.register<Copy>("permissions") {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
filePermissions {
user {
read = true
execute = true
}
other.execute = false
}
dirPermissions {
unix("r-xr-x---")
}
}tasks.register('permissions', Copy) {
from 'src/main/webapp'
into layout.buildDirectory.dir('explodedWar')
filePermissions {
user {
read = true
execute = true
}
other.execute = false
}
dirPermissions {
unix('r-xr-x---')
}
}有关文件权限的详细说明,请参阅FilePermissions和UserClassFilePermissions。有关示例中使用的便捷方法的详细信息,请参阅ConfigurableFilePermissions.unix(String)。
对文件或目录权限使用空配置块仍然会显式地设置它们,只是固定的默认值。事实上,这些配置块之一内的所有内容都与默认值相关。文件和目录的默认权限不同:
-
文件:为所有者读取和写入,为组读取,为其他读取(0644,rw-r—r--)
-
目录:所有者读取、写入和执行,组读取和执行,其他读取和执行(0755,rwxr-xr-x)
使用CopySpec类
复制规范(或简称复制规范)决定将什么内容复制到何处,以及在复制过程中文件会发生什么情况。您已经看到了许多配置Copy和归档任务形式的示例。但复制规范有两个属性值得更详细地介绍:
-
它们可以独立于任务
-
他们是有等级制度的
第一个属性允许您在构建中共享复制规范。第二个在整个复制规范中提供细粒度的控制。
共享复印规格
考虑一个包含多个任务的构建,这些任务复制项目的静态网站资源或将它们添加到存档中。一项任务可能会将资源复制到本地 HTTP 服务器的文件夹中,另一项任务可能会将它们打包到发行版中。您可以在每次需要时手动指定文件位置和适当的包含内容,但人为错误更有可能蔓延,导致任务之间不一致。
Gradle 提供的一种解决方案是Project.copySpec(org.gradle.api.Action)方法。这允许您在任务之外创建复制规范,然后可以使用 CopySpec.with (org.gradle.api.file.CopySpec…)方法将其附加到适当的任务。以下示例演示了这是如何完成的:
val webAssetsSpec: CopySpec = copySpec {
from("src/main/webapp")
include("**/*.html", "**/*.png", "**/*.jpg")
rename("(.+)-staging(.+)", "$1$2")
}
tasks.register<Copy>("copyAssets") {
into(layout.buildDirectory.dir("inPlaceApp"))
with(webAssetsSpec)
}
tasks.register<Zip>("distApp") {
archiveFileName = "my-app-dist.zip"
destinationDirectory = layout.buildDirectory.dir("dists")
from(appClasses)
with(webAssetsSpec)
}CopySpec webAssetsSpec = copySpec {
from 'src/main/webapp'
include '**/*.html', '**/*.png', '**/*.jpg'
rename '(.+)-staging(.+)', '$1$2'
}
tasks.register('copyAssets', Copy) {
into layout.buildDirectory.dir("inPlaceApp")
with webAssetsSpec
}
tasks.register('distApp', Zip) {
archiveFileName = 'my-app-dist.zip'
destinationDirectory = layout.buildDirectory.dir('dists')
from appClasses
with webAssetsSpec
}copyAssets和任务都distApp将处理 下的静态资源src/main/webapp,如 指定的webAssetsSpec。
|
笔记
|
定义的配置 这可能会令人难以理解,因此最好将其视为任务中的 |
如果遇到要将相同的复制配置应用于不同文件集的场景,那么您可以直接共享配置块,而无需使用copySpec().下面是一个示例,其中有两个独立任务恰好只想处理图像文件:
val webAssetPatterns = Action<CopySpec> {
include("**/*.html", "**/*.png", "**/*.jpg")
}
tasks.register<Copy>("copyAppAssets") {
into(layout.buildDirectory.dir("inPlaceApp"))
from("src/main/webapp", webAssetPatterns)
}
tasks.register<Zip>("archiveDistAssets") {
archiveFileName = "distribution-assets.zip"
destinationDirectory = layout.buildDirectory.dir("dists")
from("distResources", webAssetPatterns)
}def webAssetPatterns = {
include '**/*.html', '**/*.png', '**/*.jpg'
}
tasks.register('copyAppAssets', Copy) {
into layout.buildDirectory.dir("inPlaceApp")
from 'src/main/webapp', webAssetPatterns
}
tasks.register('archiveDistAssets', Zip) {
archiveFileName = 'distribution-assets.zip'
destinationDirectory = layout.buildDirectory.dir('dists')
from 'distResources', webAssetPatterns
}在这种情况下,我们将复制配置分配给它自己的变量,并将其应用于from()我们想要的任何规范。这不仅适用于包含,还适用于排除、文件重命名和文件内容过滤。
使用子规范
如果您仅使用单个复制规范,则文件过滤和重命名将应用于所有复制的文件。有时这就是您想要的,但并非总是如此。考虑以下示例,该示例将文件复制到可供 Java Servlet 容器用来交付网站的目录结构中:

这不是一个简单的复制,因为WEB-INF项目中不存在该目录及其子目录,因此必须在复制过程中创建它们。此外,我们只希望 HTML 和图像文件直接进入根文件夹,build/explodedWar并且只希望 JavaScript 文件进入该js目录。因此,我们需要为这两组文件提供单独的过滤模式。
解决方案是使用子规范,它可以应用于from()和into()声明。以下任务定义完成了必要的工作:
tasks.register<Copy>("nestedSpecs") {
into(layout.buildDirectory.dir("explodedWar"))
exclude("**/*staging*")
from("src/dist") {
include("**/*.html", "**/*.png", "**/*.jpg")
}
from(sourceSets.main.get().output) {
into("WEB-INF/classes")
}
into("WEB-INF/lib") {
from(configurations.runtimeClasspath)
}
}tasks.register('nestedSpecs', Copy) {
into layout.buildDirectory.dir("explodedWar")
exclude '**/*staging*'
from('src/dist') {
include '**/*.html', '**/*.png', '**/*.jpg'
}
from(sourceSets.main.output) {
into 'WEB-INF/classes'
}
into('WEB-INF/lib') {
from configurations.runtimeClasspath
}
}请注意配置如何src/dist具有嵌套包含规范:这就是子副本规范。您当然可以根据需要在此处添加内容过滤和重命名。子副本规范仍然是副本规范。
上面的示例还演示了如何通过使用into()a 上的子目录from()或.这两种方法都是可以接受的,但您可能需要创建并遵循约定以确保构建文件之间的一致性。from()into()
|
笔记
|
不要 |
最后要注意的一件事是,子复制规范从其父级继承其目标路径,包括模式、排除模式、复制操作、名称映射和过滤器。因此要小心放置配置的位置。
在您自己的任务中复制文件
|
警告
|
Project.copy如此处所述,在执行时
使用该方法与配置缓存不兼容。一种可能的解决方案是将任务实现为适当的类,并使用FileSystemOperations.copy方法代替,如配置缓存章节中所述。
|
有时您可能想要复制文件或目录作为任务的一部分。例如,基于不受支持的存档格式的自定义存档任务可能需要在存档之前将文件复制到临时目录。您仍然想利用 Gradle 的复制 API,但不想引入额外的Copy任务。
解决方案是使用Project.copy(org.gradle.api.Action)方法。它的工作方式与Copy任务相同,通过使用复制规范对其进行配置。这是一个简单的例子:
tasks.register("copyMethod") {
doLast {
copy {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
include("**/*.html")
include("**/*.jsp")
}
}
}tasks.register('copyMethod') {
doLast {
copy {
from 'src/main/webapp'
into layout.buildDirectory.dir('explodedWar')
include '**/*.html'
include '**/*.jsp'
}
}
}上面的示例演示了基本语法,并强调了使用该copy()方法的两个主要限制:
-
该
copy()方法不是渐进的。该示例的copyMethod任务将始终执行,因为它没有有关哪些文件构成任务输入的信息。您必须手动定义任务输入和输出。 -
使用任务作为复制源,即作为 的参数
from(),不会在您的任务和该复制源之间设置自动任务依赖关系。因此,如果您将该copy()方法用作任务操作的一部分,则必须显式声明所有输入和输出以获得正确的行为。
以下示例向您展示如何通过使用任务输入和输出的动态 API来解决这些限制:
tasks.register("copyMethodWithExplicitDependencies") {
// up-to-date check for inputs, plus add copyTask as dependency
inputs.files(copyTask)
.withPropertyName("inputs")
.withPathSensitivity(PathSensitivity.RELATIVE)
outputs.dir("some-dir") // up-to-date check for outputs
.withPropertyName("outputDir")
doLast {
copy {
// Copy the output of copyTask
from(copyTask)
into("some-dir")
}
}
}tasks.register('copyMethodWithExplicitDependencies') {
// up-to-date check for inputs, plus add copyTask as dependency
inputs.files(copyTask)
.withPropertyName("inputs")
.withPathSensitivity(PathSensitivity.RELATIVE)
outputs.dir('some-dir') // up-to-date check for outputs
.withPropertyName("outputDir")
doLast {
copy {
// Copy the output of copyTask
from copyTask
into 'some-dir'
}
}
}这些限制使得Copy尽可能使用该任务更好,因为它内置支持增量构建和任务依赖性推断。这就是为什么该copy()方法旨在供需要复制文件作为其功能一部分的自定义任务使用。使用该方法的自定义任务copy()应声明与复制操作相关的必要输入和输出。
Sync使用任务镜像目录和文件集合
同步任务扩展了该任务Copy,将源文件复制到目标目录,然后从目标目录中删除未复制的所有文件。换句话说,它将目录的内容与其源同步。这对于执行诸如安装应用程序、创建存档的分解副本或维护项目依赖项的副本等操作非常有用。
下面是一个在目录中维护项目运行时依赖项的副本的示例build/libs。
tasks.register<Sync>("libs") {
from(configurations["runtime"])
into(layout.buildDirectory.dir("libs"))
}tasks.register('libs', Sync) {
from configurations.runtime
into layout.buildDirectory.dir('libs')
}您还可以使用Project.sync(org.gradle.api.Action)方法在自己的任务中执行相同的功能。
将单个文件部署到应用程序服务器中
使用应用程序服务器时,您可以使用Copy任务来部署应用程序存档(例如 WAR 文件)。由于您正在部署单个文件,因此该文件的目标目录Copy是整个部署目录。部署目录有时确实包含不可读的文件,例如命名管道,因此 Gradle 可能在进行最新检查时遇到问题。为了支持此用例,您可以使用Task.doNotTrackState()。
plugins {
war
}
tasks.register<Copy>("deployToTomcat") {
from(tasks.war)
into(layout.projectDirectory.dir("tomcat/webapps"))
doNotTrackState("Deployment directory contains unreadable files")
}plugins {
id 'war'
}
tasks.register("deployToTomcat", Copy) {
from war
into layout.projectDirectory.dir('tomcat/webapps')
doNotTrackState("Deployment directory contains unreadable files")
}安装可执行文件
当您构建独立的可执行文件时,您可能希望在系统上安装此文件,因此它最终会出现在您的路径中。您可以使用Copy任务将可执行文件安装到共享目录中,例如/usr/local/bin.安装目录可能包含许多其他可执行文件,其中一些甚至可能无法被 Gradle 读取。为了支持任务目标目录中的不可读文件Copy并避免耗时的最新检查,您可以使用Task.doNotTrackState()。
tasks.register<Copy>("installExecutable") {
from("build/my-binary")
into("/usr/local/bin")
doNotTrackState("Installation directory contains unrelated files")
}tasks.register("installExecutable", Copy) {
from "build/my-binary"
into "/usr/local/bin"
doNotTrackState("Installation directory contains unrelated files")
}深入档案创建
档案本质上是独立的文件系统,Gradle 也这样对待它们。这就是为什么处理档案与处理文件和目录非常相似,包括文件权限之类的事情。
Gradle 开箱即用,支持创建 ZIP 和 TAR 存档,并扩展了 Java 的 JAR、WAR 和 EAR 格式——Java 的存档格式都是 ZIP。每种格式都有相应的任务类型来创建它们:Zip、Tar、Jar、War和Ear。这些都以相同的方式工作,并且基于副本规范,就像Copy任务一样。
创建归档文件本质上是一个文件副本,其中目标是隐式的,即归档文件本身。下面是一个指定目标存档文件的路径和名称的基本示例:
tasks.register<Zip>("packageDistribution") {
archiveFileName = "my-distribution.zip"
destinationDirectory = layout.buildDirectory.dir("dist")
from(layout.buildDirectory.dir("toArchive"))
}tasks.register('packageDistribution', Zip) {
archiveFileName = "my-distribution.zip"
destinationDirectory = layout.buildDirectory.dir('dist')
from layout.buildDirectory.dir("toArchive")
}在下一节中,您将了解基于约定的存档名称,这可以使您免于总是配置目标目录和存档名称。
创建存档时,您可以使用复制规范的全部功能,这意味着您可以执行内容过滤、文件重命名或上一节中介绍的任何其他操作。一个特别常见的要求是将文件复制到源文件夹中不存在的存档子目录中,这可以通过into() 子规范来实现。
Gradle 当然允许您创建任意数量的存档任务,但值得记住的是,许多基于约定的插件都提供了自己的任务。例如,Java 插件添加了一个jar任务,用于将项目的已编译类和资源打包到 JAR 中。其中许多插件为档案名称以及所使用的复制规范提供了合理的约定。我们建议您尽可能使用这些任务,而不是用自己的任务覆盖它们。
档案命名
Gradle 对于档案的命名以及根据项目使用的插件创建档案的位置有多种约定。主要约定由Base Plugin提供,它默认在目录中创建存档,并且通常使用[projectName]-[version].[type]layout.buildDirectory.dir("distributions")形式的存档名称。
以下示例来自名为 的项目archive-naming,因此该myZip任务创建一个名为 的存档archive-naming-1.0.zip:
plugins {
base
}
version = "1.0"
tasks.register<Zip>("myZip") {
from("somedir")
val projectDir = layout.projectDirectory.asFile
doLast {
println(archiveFileName.get())
println(destinationDirectory.get().asFile.relativeTo(projectDir))
println(archiveFile.get().asFile.relativeTo(projectDir))
}
}plugins {
id 'base'
}
version = 1.0
tasks.register('myZip', Zip) {
from 'somedir'
File projectDir = layout.projectDirectory.asFile
doLast {
println archiveFileName.get()
println projectDir.relativePath(destinationDirectory.get().asFile)
println projectDir.relativePath(archiveFile.get().asFile)
}
}gradle -q myZip> gradle -q myZip archive-naming-1.0.zip build/distributions build/distributions/archive-naming-1.0.zip
请注意,存档的名称并非源自创建它的任务的名称。
如果要更改生成的存档文件的名称和位置,可以为相应任务的archiveFileName和属性提供值。destinationDirectory这些规则会覆盖任何原本适用的约定。
或者,您可以使用AbstractArchiveTask.getArchiveFileName()提供的默认存档名称模式:[archiveBaseName]-[archiveAppendix]-[archiveVersion]-[archiveClassifier].[archiveExtension]。如果您愿意,您可以单独设置任务的每个属性。请注意,基础插件使用以下约定:archiveBaseName为项目名称、 archiveVersion为项目版本、 archiveExtension为存档类型。它不提供其他属性的值。
此示例(与上面的项目来自同一项目)仅配置属性archiveBaseName,覆盖项目名称的默认值:
tasks.register<Zip>("myCustomZip") {
archiveBaseName = "customName"
from("somedir")
doLast {
println(archiveFileName.get())
}
}tasks.register('myCustomZip', Zip) {
archiveBaseName = 'customName'
from 'somedir'
doLast {
println archiveFileName.get()
}
}gradle -q myCustomZip> gradle -q myCustomZip customName-1.0.zip
您还可以使用项目属性覆盖构建中所有archiveBaseName存档任务的默认值,如以下示例所示:archivesBaseName
plugins {
base
}
version = "1.0"
base {
archivesName = "gradle"
distsDirectory = layout.buildDirectory.dir("custom-dist")
libsDirectory = layout.buildDirectory.dir("custom-libs")
}
val myZip by tasks.registering(Zip::class) {
from("somedir")
}
val myOtherZip by tasks.registering(Zip::class) {
archiveAppendix = "wrapper"
archiveClassifier = "src"
from("somedir")
}
tasks.register("echoNames") {
val projectNameString = project.name
val archiveFileName = myZip.flatMap { it.archiveFileName }
val myOtherArchiveFileName = myOtherZip.flatMap { it.archiveFileName }
doLast {
println("Project name: $projectNameString")
println(archiveFileName.get())
println(myOtherArchiveFileName.get())
}
}plugins {
id 'base'
}
version = 1.0
base {
archivesName = "gradle"
distsDirectory = layout.buildDirectory.dir('custom-dist')
libsDirectory = layout.buildDirectory.dir('custom-libs')
}
def myZip = tasks.register('myZip', Zip) {
from 'somedir'
}
def myOtherZip = tasks.register('myOtherZip', Zip) {
archiveAppendix = 'wrapper'
archiveClassifier = 'src'
from 'somedir'
}
tasks.register('echoNames') {
def projectNameString = project.name
def archiveFileName = myZip.flatMap { it.archiveFileName }
def myOtherArchiveFileName = myOtherZip.flatMap { it.archiveFileName }
doLast {
println "Project name: $projectNameString"
println archiveFileName.get()
println myOtherArchiveFileName.get()
}
}gradle -q echoNames> gradle -q echoNames Project name: archives-changed-base-name gradle-1.0.zip gradle-wrapper-1.0-src.zip
您可以在AbstractArchiveTask的 API 文档中找到所有可能的归档任务属性,但我们还在这里总结了主要属性:
archiveFileName-Property<String>, 默认:archiveBaseName-archiveAppendix-archiveVersion-archiveClassifier.archiveExtension-
生成的存档的完整文件名。如果默认值中的任何属性为空,则它们的“-”分隔符将被删除。
archiveFile—Provider<RegularFile>,只读,默认:destinationDirectory/archiveFileName-
生成的存档的绝对文件路径。
destinationDirectory—DirectoryProperty,默认值:取决于存档类型-
放置生成的存档的目标目录。默认情况下,JAR 和 WAR 进入
layout.buildDirectory.dir("libs"). ZIP 和 TAR 进入layout.buildDirectory.dir("distributions"). archiveBaseName-Property<String>, 默认:project.name-
存档文件名的基本名称部分,通常是项目名称或它所包含内容的其他描述性名称。
archiveAppendix-Property<String>, 默认:null-
紧随基本名称之后的存档文件名的附录部分。它通常用于区分不同形式的内容,例如代码和文档,或者最小分发与完整分发。
archiveVersion-Property<String>, 默认:project.version-
存档文件名的版本部分,通常采用正常项目或产品版本的形式。
archiveClassifier-Property<String>, 默认:null-
归档文件名的分类器部分。通常用于区分针对不同平台的档案。
archiveExtension—Property<String>,默认值:取决于存档类型和压缩类型-
存档的文件扩展名。默认情况下,这是根据存档任务类型和压缩类型(如果您正在创建 TAR)进行设置的。将是以下之一:
zip、jar、war、tar或tgz。tbz2如果您愿意,您当然可以将其设置为自定义扩展。
在多个档案之间共享内容
如前所述,您可以使用Project.copySpec(org.gradle.api.Action)方法在存档之间共享内容。
可重复的构建
有时需要在不同的机器上逐字节地重新创建完全相同的存档。您希望确保从源代码构建工件无论何时何地构建都会产生相同的结果。这对于像reproducible-builds.org这样的项目是必要的。
逐字节复制相同的存档会带来一些挑战,因为存档中文件的顺序受到底层文件系统的影响。每次从源代码构建 ZIP、TAR、JAR、WAR 或 EAR 时,存档内文件的顺序可能会发生变化。仅具有不同时间戳的文件也会导致构建与构建之间的存档存在差异。Gradle 附带的所有AbstractArchiveTask (例如 Jar、Zip)任务都包含对生成可重现档案的支持。
例如,要使Zip任务可重复,您需要将Zip.isReproducibleFileOrder()设置为true并将Zip.isPreserveFileTimestamps()设置为false。为了使构建中的所有存档任务可重现,请考虑将以下配置添加到构建文件中:
tasks.withType<AbstractArchiveTask>().configureEach {
isPreserveFileTimestamps = false
isReproducibleFileOrder = true
}tasks.withType(AbstractArchiveTask).configureEach {
preserveFileTimestamps = false
reproducibleFileOrder = true
}通常,您会想要发布存档,以便可以在其他项目中使用它。跨项目出版物中描述了此过程。
记录
日志是构建工具的主要“UI”。如果太冗长,真正的警告和问题很容易被隐藏。另一方面,您需要相关信息来确定是否出了问题。 Gradle定义了6个日志级别,如日志级别所示。除了您通常看到的日志级别之外,还有两个特定于 Gradle 的日志级别。这些级别是QUIET和LIFECYCLE。后者是默认值,用于报告构建进度。
日志级别
| 错误 |
错误信息 |
| 安静的 |
重要信息消息 |
| 警告 |
警告信息 |
| 生命周期 |
进度信息消息 |
| 信息 |
信息消息 |
| 调试 |
调试消息 |
|
笔记
|
无论使用何种日志级别,都会显示控制台的丰富组件(构建状态和正在进行的工作区域)。在 Gradle 4.0 之前,这些丰富的组件仅在日志级别LIFECYCLE或以下级别
显示。 |
选择日志级别
您可以使用日志级别命令行选项中显示的命令行开关来选择不同的日志级别。您还可以使用配置日志级别gradle.properties,请参阅Gradle 属性。在Stacktrace 命令行选项中,您可以找到影响堆栈跟踪日志记录的命令行开关。
| 选项 | 输出日志级别 |
|---|---|
|
安静且更高 |
|
警告及更高级别 |
没有日志记录选项 |
生命周期及更高 |
|
信息及更高级别 |
|
DEBUG 及更高版本(即所有日志消息) |
|
警告
|
日志DEBUG级别可以向控制台公开安全敏感信息。
|
堆栈跟踪命令行选项
-s或者--stacktrace-
打印截断的堆栈跟踪。我们建议在完整的堆栈跟踪中使用此方法。 Groovy 完整堆栈跟踪非常冗长(由于底层的动态调用机制。但它们通常不包含代码中出现问题的相关信息。)此选项呈现堆栈跟踪以显示弃用警告。
-S或者--full-stacktrace-
打印出完整的堆栈跟踪。此选项呈现堆栈跟踪以获取弃用警告。
- <无堆栈跟踪选项>
-
如果出现构建错误(例如编译错误),则不会将堆栈跟踪打印到控制台。仅在出现内部异常的情况下才会打印堆栈跟踪。如果
DEBUG选择了日志级别,则始终打印截断的堆栈跟踪。
记录敏感信息
使用DEBUG日志级别运行 Gradle 可能会将安全敏感信息暴露给控制台和构建日志。
这些信息可以包括但不限于:
-
环境变量
-
私有存储库凭据
-
构建缓存和开发凭证
-
插件 Portal发布凭证
在公共持续集成服务上运行时不应使用DEBUG 日志级别。公共持续集成服务的构建日志是全世界可见的,并且可能会暴露这些敏感信息。根据您组织的威胁模型,在私有 CI 中记录敏感凭据也可能是一个漏洞。请与您组织的安全团队讨论此问题。
一些 CI 提供商尝试从日志中清除敏感凭据;然而,这并不完美,通常只会删除预先配置的秘密的精确匹配。
如果您认为 Gradle 插件可能会泄露敏感信息,请联系security@gradle.com寻求披露帮助。
编写您自己的日志消息
登录构建文件的一个简单选项是将消息写入标准输出。 Gradle 将任何写入标准输出的内容重定向到其QUIET日志级别的日志系统。
println("A message which is logged at QUIET level")println 'A message which is logged at QUIET level'Gradle 还为构建脚本提供了一个属性,它是Loggerlogger的实例。该接口扩展了 SLF4J接口,并向其中添加了一些 Gradle 特定方法。以下是如何在构建脚本中使用它的示例:Logger
logger.quiet("An info log message which is always logged.")
logger.error("An error log message.")
logger.warn("A warning log message.")
logger.lifecycle("A lifecycle info log message.")
logger.info("An info log message.")
logger.debug("A debug log message.")
logger.trace("A trace log message.") // Gradle never logs TRACE level logslogger.quiet('An info log message which is always logged.')
logger.error('An error log message.')
logger.warn('A warning log message.')
logger.lifecycle('A lifecycle info log message.')
logger.info('An info log message.')
logger.debug('A debug log message.')
logger.trace('A trace log message.') // Gradle never logs TRACE level logs使用典型的 SLF4J 模式将占位符替换为实际值作为日志消息的一部分。
logger.info("A {} log message", "info")logger.info('A {} log message', 'info')您还可以从构建中使用的其他类(buildSrc例如目录中的类)连接到 Gradle 的日志系统。只需使用 SLF4J 记录器即可。您可以像在构建脚本中使用提供的记录器一样使用此记录器。
import org.slf4j.LoggerFactory
val slf4jLogger = LoggerFactory.getLogger("some-logger")
slf4jLogger.info("An info log message logged using SLF4j")import org.slf4j.LoggerFactory
def slf4jLogger = LoggerFactory.getLogger('some-logger')
slf4jLogger.info('An info log message logged using SLF4j')从外部工具和库记录
在内部,Gradle 使用 Ant 和 Ivy。两者都有自己的日志系统。 Gradle 将其日志输出重定向到 Gradle 日志系统。 Ant/Ivy 日志级别与 Gradle 日志级别之间存在 1:1 映射,但 Ant/IvyTRACE日志级别除外,它映射到 GradleDEBUG日志级别。这意味着默认的 Gradle 日志级别不会显示任何 Ant/Ivy 输出,除非它是错误或警告。
有许多工具仍然使用标准输出进行日志记录。默认情况下,Gradle 将标准输出重定向到QUIET日志级别,将标准错误重定向到该ERROR级别。此行为是可配置的。项目对象提供了一个LoggingManager,它允许您更改在评估构建脚本时标准输出或错误重定向到的日志级别。
logging.captureStandardOutput(LogLevel.INFO)
println("A message which is logged at INFO level")logging.captureStandardOutput LogLevel.INFO
println 'A message which is logged at INFO level'要更改任务执行期间标准输出或错误的日志级别,任务还提供LoggingManager。
tasks.register("logInfo") {
logging.captureStandardOutput(LogLevel.INFO)
doFirst {
println("A task message which is logged at INFO level")
}
}tasks.register('logInfo') {
logging.captureStandardOutput LogLevel.INFO
doFirst {
println 'A task message which is logged at INFO level'
}
}Gradle 还提供与 Java Util Logging、Jakarta Commons Logging 和 Log4j 日志记录工具包的集成。您的构建类使用这些日志工具包编写的任何日志消息都将被重定向到 Gradle 的日志系统。
更改 Gradle 记录的内容
您可以用自己的 UI 替换 Gradle 的大部分日志记录 UI。例如,如果您想以某种方式自定义 UI - 记录更多或更少的信息,或者更改格式,您可以这样做。您可以使用Gradle.useLogger(java.lang.Object)方法替换日志记录。这可以从构建脚本、初始化脚本或通过嵌入 API 访问。请注意,这会完全禁用 Gradle 的默认输出。下面是一个示例初始化脚本,它更改了任务执行和构建完成的记录方式。
useLogger(CustomEventLogger())
@Suppress("deprecation")
class CustomEventLogger() : BuildAdapter(), TaskExecutionListener {
override fun beforeExecute(task: Task) {
println("[${task.name}]")
}
override fun afterExecute(task: Task, state: TaskState) {
println()
}
override fun buildFinished(result: BuildResult) {
println("build completed")
if (result.failure != null) {
(result.failure as Throwable).printStackTrace()
}
}
}useLogger(new CustomEventLogger())
@SuppressWarnings("deprecation")
class CustomEventLogger extends BuildAdapter implements TaskExecutionListener {
void beforeExecute(Task task) {
println "[$task.name]"
}
void afterExecute(Task task, TaskState state) {
println()
}
void buildFinished(BuildResult result) {
println 'build completed'
if (result.failure != null) {
result.failure.printStackTrace()
}
}
}$ gradle -I customLogger.init.gradle.kts build > Task :compile [compile] compiling source > Task :testCompile [testCompile] compiling test source > Task :test [test] running unit tests > Task :build [build] build completed 3 actionable tasks: 3 executed
$ gradle -I customLogger.init.gradle build > Task :compile [compile] compiling source > Task :testCompile [testCompile] compiling test source > Task :test [test] running unit tests > Task :build [build] build completed 3 actionable tasks: 3 executed
您的记录器可以实现下面列出的任何侦听器接口。当您注册记录器时,仅替换其实现的接口的日志记录。其他接口的日志记录保持不变。您可以在构建生命周期事件中找到有关侦听器接口的更多信息。
避免陷阱
Groovy 脚本变量
对于 Groovy DSL 用户来说,了解 Groovy 如何处理脚本变量非常重要。 Groovy 有两种类型的脚本变量。一种具有本地范围,一种具有脚本范围范围。
示例:变量范围:本地和脚本范围
String localScope1 = 'localScope1'
def localScope2 = 'localScope2'
scriptScope = 'scriptScope'
println localScope1
println localScope2
println scriptScope
closure = {
println localScope1
println localScope2
println scriptScope
}
def method() {
try {
localScope1
} catch (MissingPropertyException e) {
println 'localScope1NotAvailable'
}
try {
localScope2
} catch(MissingPropertyException e) {
println 'localScope2NotAvailable'
}
println scriptScope
}
closure.call()
method()groovy scope.groovy> groovy scope.groovy localScope1 localScope2 scriptScope localScope1 localScope2 scriptScope localScope1NotAvailable localScope2NotAvailable scriptScope
使用类型修饰符声明的变量在闭包中可见,但在方法中不可见。
配置和执行阶段
请务必记住,Gradle 具有独特的配置和执行阶段(请参阅构建生命周期)。
val classesDir = file("build/classes")
classesDir.mkdirs()
tasks.register<Delete>("clean") {
delete("build")
}
tasks.register("compile") {
dependsOn("clean")
val classesDir = classesDir
doLast {
if (!classesDir.isDirectory) {
println("The class directory does not exist. I can not operate")
// do something
}
// do something
}
}def classesDir = file('build/classes')
classesDir.mkdirs()
tasks.register('clean', Delete) {
delete 'build'
}
tasks.register('compile') {
dependsOn 'clean'
def localClassesDir = classesDir
doLast {
if (!localClassesDir.isDirectory()) {
println 'The class directory does not exist. I can not operate'
// do something
}
// do something
}
}gradle -q compile> gradle -q compile The class directory does not exist. I can not operate
由于目录的创建发生在配置阶段,因此clean任务会在执行阶段删除该目录。
配置构建环境
Gradle 提供了多种机制来配置 Gradle 本身和特定项目的行为。
以下是使用这些机制的参考:
| 机制 | 信息 | 例子 |
|---|---|---|
配置构建行为和 Gradle 功能的标志 |
|
|
特定于您的 Gradle 项目的属性 |
|
|
传递到 Gradle 运行时 (JVM) 的属性 |
|
|
配置 Gradle 设置的属性 |
|
|
根据环境配置构建行为的属性 |
|
配置优先级
配置 Gradle 行为时,您可以使用这些方法,但必须考虑它们的优先级。下表按优先级从高到低的顺序列出了这些方法(第一个获胜):
| 优先事项 | 方法 | 地点 | 例子 | 细节 |
|---|---|---|---|---|
1 |
命令行 |
|
它们优先于属性和环境变量。 |
|
2 |
项目根目录 |
|
存储在 |
|
3 |
|
|
存储在 |
|
4 |
环境 |
|
来自执行 Gradle 的环境。 |
项目属性
项目属性特定于您的 Gradle 项目。它们是使用构建脚本中的块或直接在project对象中定义的。
例如,项目属性myProperty是在构建文件中创建的:
ext {
myProperty = findProperty('myProperty') ?: 'Hello, world!'
}
println "My property value: ${project.ext.myProperty}"您有两个选项来添加项目属性,按优先级顺序列出:
-
命令行:您可以通过命令行选项直接向项目
-P对象添加属性。$ ./gradlew build -PmyProperty='Hi, world' -
系统属性或环境变量:您可以使用专门命名的系统属性或环境变量来设置项目属性。
$ ./gradlew build -Dorg.gradle.project.myProperty='Hi, world'
如果环境变量名称看起来像,那么 Gradle 将在您的项目对象上设置一个属性,其值为。 Gradle 也支持系统属性,但具有不同的命名模式,看起来像.ORG_GRADLE_PROJECT_prop=somevaluepropsomevalueorg.gradle.project.prop
以下示例将fooProject 对象的属性设置为"bar"。
示例 1:通过命令行设置项目属性。
$ ./gradlew build -Pfoo=bar示例 2:通过系统属性设置项目属性。
org.gradle.project.foo=bar示例 3:通过环境变量设置项目属性。
$ export ORG_GRADLE_PROJECT_foo=bar当您没有持续集成服务器的管理员权限并且需要设置不易可见的属性值时,此功能非常有用。由于您无法-P在该场景中使用该选项,也无法更改系统级配置文件,因此正确的策略是更改持续集成构建作业的配置,添加与预期模式匹配的环境变量设置。这对于系统上的普通用户来说是不可见的。
您只需使用名称即可访问构建脚本中的项目属性,就像访问变量一样。
系统属性
系统属性是在 JVM 级别设置的变量,可供 Gradle 构建过程访问。可以使用System构建脚本中的类来访问系统属性。下面列出了常见的系统属性。
您有两个选项来添加按优先级列出的系统属性:
-
命令行:使用
-D命令行选项,您可以将系统属性传递给运行 Gradle 的 JVM。-D该命令的选项与该命令的选项gradle具有相同的效果。-Djava$ ./gradlew build -Dgradle.wrapperUser=myuser -
gradle.properties文件:您还可以在gradle.properties带有前缀的文件中设置系统属性systemProp:gradle.propertiessystemProp.gradle.wrapperUser=myuser systemProp.gradle.wrapperPassword=mypassword
以下是常见的系统属性:
gradle.wrapperUser=(myuser)-
指定用户名以使用 HTTP 基本身份验证从服务器下载 Gradle 发行版。
gradle.wrapperPassword=(mypassword)-
指定使用 Gradle 包装器下载 Gradle 发行版的密码。
gradle.user.home=(path to directory)-
指定
GRADLE_USER_HOME目录。 https.protocols-
以逗号分隔的格式指定支持的 TLS 版本。例如,
TLSv1.2,TLSv1.3。
此处列出了其他 Java 系统属性。
在多项目构建中,systemProp除根项目之外的任何项目中设置的属性都将被忽略。仅gradle.properties检查根项目的文件中以 开头的属性systemProp。
以下示例演示了如何使用系统属性:
示例 1:使用文件设置系统属性gradle.properties:
systemProp.system=gradlePropertiesValue示例 2:在配置时读取系统属性:
// Using the Java API
println(System.getProperty("system"))// Using the Java API
println(System.getProperty("system"))
// Using the Gradle API, provides a lazy Provider<String>
println(providers.systemProperty("system").get())// Using the Java API
println(System.getProperty("system"))
// Using the Gradle API, provides a lazy Provider<String>
println(providers.systemProperty("system").get())// Using the Java API
println System.getProperty('system')// Using the Java API
println System.getProperty('system')
// Using the Gradle API, provides a lazy Provider<String>
println providers.systemProperty('system').get()// Using the Java API
println System.getProperty('system')
// Using the Gradle API, provides a lazy Provider<String>
println providers.systemProperty('system').get()示例 3:读取系统属性以供执行时使用:
tasks.register<PrintValue>("printProperty") {
// Using the Gradle API, provides a lazy Provider<String> wired to a task input
inputValue = providers.systemProperty("system")
}tasks.register('printProperty', PrintValue) {
// Using the Gradle API, provides a lazy Provider<String> wired to a task input
inputValue = providers.systemProperty('system')
}示例 4:从命令行设置系统属性-D gradle.wrapperUser=username:
$ gradle -Dsystem=commandLineValue
等级属性
Gradle 提供了多个选项,可以轻松配置用于执行构建的 Java 进程。虽然可以通过GRADLE_OPTS或在本地环境中配置这些JAVA_OPTS,但能够JAVA_HOME在版本控制中存储某些设置(例如 JVM 内存配置和位置)非常有用,以便整个团队可以在一致的环境中工作。
您有一种选择来添加 gradle 属性:
-
gradle.properties文件:将这些设置放入gradle.properties文件中并将其提交到版本控制系统。gradle.propertiesorg.gradle.caching.debug=false
Gradle 考虑的最终配置是命令行和文件上设置的所有 Gradle 属性的组合gradle.properties。如果在多个位置配置了一个选项,则在以下任何位置找到的第一个选项获胜:
| 优先事项 | 方法 | 地点 | 细节 |
|---|---|---|---|
1 |
命令行界面 |
。 |
在命令行中使用 |
2 |
|
|
存储 |
3 |
|
项目根目录 |
存储在 |
4 |
|
|
存储在可选 Gradle 安装目录 |
|
笔记
|
的位置可能已通过命令行上传递的系统属性
GRADLE_USER_HOME预先更改。-Dgradle.user.home |
以下属性是常见的 Gradle 属性:
org.gradle.caching=(true,false)-
当设置为 时
true,Gradle 将尽可能重用任何先前构建的任务输出,从而加快构建速度。默认为
false;构建缓存未启用。 org.gradle.caching.debug=(true,false)-
当设置为 时
true,每个任务的各个输入属性哈希值和构建缓存键都会记录在控制台上。默认为
false. org.gradle.configuration-cache=(true,false)-
启用配置缓存。 Gradle 将尝试重用以前构建的构建配置。
默认为
false. org.gradle.configureondemand=(true,false)-
启用按需孵化配置,Gradle 将尝试仅配置必要的项目。
默认为
false. org.gradle.console=(auto,plain,rich,verbose)-
自定义控制台输出颜色或详细程度。
默认值取决于 Gradle 的调用方式。
org.gradle.continue=(true,false)-
如果启用,则在任务失败后继续任务执行,否则在任务失败后停止任务执行。
默认为
false. org.gradle.daemon=(true,false)-
true设置为Gradle Daemon时用于运行构建。默认为
true. org.gradle.daemon.idletimeout=(# of idle millis)-
Gradle Daemon 将在指定的空闲毫秒数后自行终止。
默认值为
10800000(3 小时)。 org.gradle.debug=(true,false)-
当设置为 时
true,Gradle 将在启用远程调试的情况下运行构建,并侦听端口 5005。请注意,这相当于添加-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005到 JVM 命令行,并将挂起虚拟机,直到连接调试器。默认为
false. org.gradle.java.home=(path to JDK home)-
指定 Gradle 构建过程的 Java 主目录。该值可以设置为 a
jdk或jrelocation;但是,使用 JDK 更安全,具体取决于您的构建用途。这不会影响用于启动Gradle 客户端 VM的 Java 版本。如果未指定设置,则默认值源自您的环境(
JAVA_HOME或路径)。java org.gradle.jvmargs=(JVM arguments)-
指定用于 Gradle 守护程序的 JVM 参数。该设置对于配置 JVM 内存设置以提高构建性能特别有用。这不会影响 Gradle 客户端 VM 的 JVM 设置。
默认为
-Xmx512m "-XX:MaxMetaspaceSize=384m". org.gradle.logging.level=(quiet,warn,lifecycle,info,debug)-
当设置为安静、警告、信息或调试时,Gradle 将使用此日志级别。这些值不区分大小写。
默认为
lifecycle水平。 org.gradle.parallel=(true,false)-
配置完成后,Gradle 将分叉多个
org.gradle.workers.maxJVM 来并行执行项目。默认为
false. org.gradle.priority=(low,normal)-
指定Gradle 守护进程及其启动的所有进程的调度优先级。
默认为
normal. org.gradle.projectcachedir=(directory)-
指定项目特定的缓存目录。默认位于
.gradle根项目目录中。”默认为
.gradle. org.gradle.unsafe.isolated-projects=(true,false)-
启用项目隔离,从而启用配置缓存。
默认为
false. org.gradle.vfs.verbose=(true,false)-
在监视文件系统时配置详细日志记录。
默认为
false. org.gradle.vfs.watch=(true,false)-
切换监视文件系统。启用后,Gradle 会在构建之间重用其收集的有关文件系统的信息。
默认值是
true在 Gradle 支持此功能的操作系统上。 org.gradle.warning.mode=(all,fail,summary,none)-
当设置为
all、、summary或时none,Gradle 将使用不同的警告类型显示。默认为
summary. org.gradle.workers.max=(max # of worker processes)-
配置后,Gradle 将使用给定数量的最大工作人员。
默认值是 CPU 处理器的数量。
以下示例演示了如何使用 Gradle 属性。
示例 1:使用文件设置 Gradle 属性gradle.properties:
gradlePropertiesProp=gradlePropertiesValue
gradleProperties.with.dots=gradlePropertiesDottedValue示例 2:在配置时读取 Gradle 属性:
// Using the API, provides a lazy Provider<String>
println(providers.gradleProperty("gradlePropertiesProp").get())
// Using Kotlin delegated properties on `settings`
val gradlePropertiesProp: String by settings
println(gradlePropertiesProp)// Using the API, provides a lazy Provider<String>
println(providers.gradleProperty("gradlePropertiesProp").get())
// Using Kotlin delegated properties on `project`
val gradlePropertiesProp: String by project
println(gradlePropertiesProp)// Using the API, provides a lazy Provider<String>
println providers.gradleProperty('gradlePropertiesProp').get()
// Using Groovy dynamic names
println gradlePropertiesProp
println settings.gradlePropertiesProp
// Using Groovy dynamic array notation on `settings`
println settings['gradlePropertiesProp']// Using the API, provides a lazy Provider<String>
println providers.gradleProperty('gradlePropertiesProp').get()
// Using Groovy dynamic names
println gradlePropertiesProp
println project.gradlePropertiesProp
// Using Groovy dynamic array notation on `project`
println project['gradlePropertiesProp']Kotlin委托属性是 Gradle Kotlin DSL 的一部分。您需要明确指定类型为String。如果您需要根据属性的存在进行分支,您还可以使用String?并检查null.
请注意,如果 Gradle 属性名称中包含点,则不可能使用动态 Groovy 名称。您必须改用 API 或动态数组表示法。
示例 3:读取 Gradle 属性以供执行时使用:
tasks.register<PrintValue>("printProperty") {
// Using the API, provides a lazy Provider<String> wired to a task input
inputValue = providers.gradleProperty("gradlePropertiesProp")
}tasks.register('printProperty', PrintValue) {
// Using the API, provides a lazy Provider<String> wired to a task input
inputValue = providers.gradleProperty('gradlePropertiesProp')
}示例 4:从命令行设置 Gradle 属性:
$ gradle -DgradlePropertiesProp=commandLineValue
请注意,初始化脚本无法直接读取 Gradle 属性。最早可以在初始化脚本中读取的 Gradle 属性是settingsEvaluated {}:
示例 5:从初始化脚本读取 Gradle 属性:
settingsEvaluated {
// Using the API, provides a lazy Provider<String>
println(providers.gradleProperty("gradlePropertiesProp").get())
// Using Kotlin delegated properties on `settings`
val gradlePropertiesProp: String by this
println(gradlePropertiesProp)
}settingsEvaluated { settings ->
// Using the API, provides a lazy Provider<String>
println settings.providers.gradleProperty('gradlePropertiesProp').get()
// Using Groovy dynamic names
println settings.gradlePropertiesProp
// Using Groovy dynamic array notation on `settings`
println settings['gradlePropertiesProp']
}子项目目录中的文件中声明的属性gradle.properties仅适用于该项目及其子项目。
环境变量
Gradle 提供了许多环境变量,如下所示。您可以使用该方法将环境变量作为构建脚本中的属性进行访问System.getenv()。
以下环境变量可用于该gradle命令。
GRADLE_HOME-
Gradle 的安装目录。
可用于指定本地 Gradle 版本,而不是使用包装器。
您可以添加
GRADLE_HOME/bin到您的PATH特定应用程序和用例(例如测试 Gradle 的早期版本)。 JAVA_OPTS-
用于将 JVM 选项和自定义设置传递给 JVM。
GRADLE_OPTS-
指定启动 Gradle 客户端 VM 时要使用的 JVM 参数。
客户端虚拟机仅处理命令行输入/输出,因此很少需要更改其虚拟机选项。
实际构建由 Gradle 守护进程运行,不受此环境变量的影响。
GRADLE_USER_HOME-
指定
GRADLE_USER_HOMEGradle 存储其全局配置属性、初始化脚本、缓存、日志文件等的目录。USER_HOME/.gradle如果未设置则默认为。 JAVA_HOME-
指定用于客户端 VM 的 JDK 安装目录。
该 VM 也用于守护进程,除非在 Gradle 属性文件中使用
org.gradle.java.home. GRADLE_LIBS_REPO_OVERRIDE-
覆盖默认 Gradle 库存储库。
可用于指定 .gradle 中的默认 Gradle 存储库 URL
org.gradle.plugins.ide.internal.resolver。如果您的公司使用防火墙/代理,则可用于指定内部托管存储库的有用覆盖。
以下示例演示了如何使用环境变量。
示例1:配置时读取环境变量:
// Using the Java API
println(System.getenv("ENVIRONMENTAL"))// Using the Java API
println(System.getenv("ENVIRONMENTAL"))
// Using the Gradle API, provides a lazy Provider<String>
println(providers.environmentVariable("ENVIRONMENTAL").get())// Using the Java API
println(System.getenv("ENVIRONMENTAL"))
// Using the Gradle API, provides a lazy Provider<String>
println(providers.environmentVariable("ENVIRONMENTAL").get())// Using the Java API
println System.getenv('ENVIRONMENTAL')// Using the Java API
println System.getenv('ENVIRONMENTAL')
// Using the Gradle API, provides a lazy Provider<String>
println providers.environmentVariable('ENVIRONMENTAL').get()// Using the Java API
println System.getenv('ENVIRONMENTAL')
// Using the Gradle API, provides a lazy Provider<String>
println providers.environmentVariable('ENVIRONMENTAL').get()示例2:读取环境变量以供执行时使用:
tasks.register<PrintValue>("printValue") {
// Using the Gradle API, provides a lazy Provider<String> wired to a task input
inputValue = providers.environmentVariable("ENVIRONMENTAL")
}tasks.register('printValue', PrintValue) {
// Using the Gradle API, provides a lazy Provider<String> wired to a task input
inputValue = providers.environmentVariable('ENVIRONMENTAL')
}初始化脚本
Gradle 提供了一种强大的机制,用于根据当前环境自定义构建。
该机制还支持希望与 Gradle 集成的工具。
基本用法
初始化脚本(又名init 脚本)与 Gradle 中的其他脚本类似。但是,这些脚本是在构建开始之前运行的。
以下是几种可能的用途:
-
设置企业范围的配置,例如在哪里可以找到自定义插件。
-
根据当前环境设置属性,例如开发人员的计算机与持续集成服务器。
-
提供构建所需的有关用户的个人信息,例如存储库或数据库身份验证凭据。
-
定义特定于计算机的详细信息,例如 JDK 的安装位置。
-
注册构建监听器。希望监听 Gradle 事件的外部工具可能会发现这很有用。
-
注册构建记录器。您可以自定义 Gradle 如何记录它生成的事件。
初始化脚本的一个主要限制是它们无法访问buildSrc项目中的类。
使用初始化脚本
使用 init 脚本有多种方法:
-
在命令行上指定一个文件。命令行选项后面是
-I脚本--init-script的路径。命令行选项可以出现多次,每次都会添加另一个初始化脚本。如果命令行上指定的任何文件不存在,构建将失败。
-
init.gradle将一个名为(或init.gradle.ktsKotlin)的文件放入该目录中。$GRADLE_USER_HOME/ -
.gradle将以(或.init.gradle.ktsKotlin)结尾的文件放入目录中。$GRADLE_USER_HOME/init.d/ -
.gradle将以(或.init.gradle.ktsKotlin)结尾的文件放入Gradle 发行版的目录中。$GRADLE_HOME/init.d/这使您可以打包包含自定义构建逻辑和插件的自定义 Gradle 发行版。您可以将其与Gradle 包装器结合起来,使自定义逻辑可用于企业中的所有构建。
如果找到多个 init 脚本,它们都将按照上面指定的顺序执行。
给定目录中的脚本按字母顺序执行。例如,工具可以在命令行上指定一个 init 脚本,并在主目录中指定另一个 init 脚本来定义环境。这两个脚本都会在 Gradle 执行时运行。
编写初始化脚本
与 Gradle 构建脚本一样,init 脚本是 Groovy 或 Kotlin 脚本。每个 init 脚本都有一个与其关联的Gradle实例。初始化脚本中的任何属性引用和方法调用都将委托给此Gradle实例。
每个 init 脚本还实现Script接口。
|
笔记
|
编写初始化脚本时,请注意您尝试访问的引用的范围。例如,加载的属性在或实例 |
从初始化脚本配置项目
您可以使用 init 脚本来配置构建中的项目。这与在多项目构建中配置项目类似。
以下示例展示了如何在评估项目之前从 init 脚本执行额外配置:
repositories {
mavenCentral()
}
tasks.register("showRepos") {
val repositoryNames = repositories.map { it.name }
doLast {
println("All repos:")
println(repositoryNames)
}
}allprojects {
repositories {
mavenLocal()
}
}repositories {
mavenCentral()
}
tasks.register('showRepos') {
def repositoryNames = repositories.collect { it.name }
doLast {
println "All repos:"
println repositoryNames
}
}allprojects {
repositories {
mavenLocal()
}
}此示例使用此功能来配置仅用于特定环境的附加存储库。
应用 init 脚本时的输出
> gradle --init-script init.gradle.kts -q showRepos
All repos:
[MavenLocal, MavenRepo]> gradle --init-script init.gradle -q showRepos
All repos:
[MavenLocal, MavenRepo]init 脚本的外部依赖项
Init 脚本还可以声明与该initscript()方法的依赖关系,传入一个声明 init 脚本类路径的闭包。
声明 init 脚本的外部依赖项:
initscript {
repositories {
mavenCentral()
}
dependencies {
classpath("org.apache.commons:commons-math:2.0")
}
}initscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'org.apache.commons:commons-math:2.0'
}
}传递给该方法的闭包initscript()配置一个ScriptHandler实例。您可以通过向配置添加依赖项来声明 init 脚本类路径classpath。
例如,这与声明 Java 编译类路径的方式相同。您可以使用声明依赖项中描述的任何依赖项类型,项目依赖项除外。
声明 init 脚本类路径后,您可以像使用类路径上的任何其他类一样使用 init 脚本中的类。以下示例添加到前面的示例中,并使用 init 脚本类路径中的类。
具有外部依赖项的初始化脚本:
import org.apache.commons.math.fraction.Fraction
initscript {
repositories {
mavenCentral()
}
dependencies {
classpath("org.apache.commons:commons-math:2.0")
}
}
println(Fraction.ONE_FIFTH.multiply(2))tasks.register("doNothing")import org.apache.commons.math.fraction.Fraction
initscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'org.apache.commons:commons-math:2.0'
}
}
println Fraction.ONE_FIFTH.multiply(2)tasks.register('doNothing')应用 init 脚本时的输出:
> gradle --init-script init.gradle.kts -q doNothing
2 / 5> gradle --init-script init.gradle -q doNothing
2 / 5初始化脚本插件
与 Gradle 构建脚本或 Gradle 设置文件一样,插件可以应用于 init 脚本。
在初始化脚本中使用插件:
apply<EnterpriseRepositoryPlugin>()
class EnterpriseRepositoryPlugin : Plugin<Gradle> {
companion object {
const val ENTERPRISE_REPOSITORY_URL = "https://repo.gradle.org/gradle/repo"
}
override fun apply(gradle: Gradle) {
// ONLY USE ENTERPRISE REPO FOR DEPENDENCIES
gradle.allprojects {
repositories {
// Remove all repositories not pointing to the enterprise repository url
all {
if (this !is MavenArtifactRepository || url.toString() != ENTERPRISE_REPOSITORY_URL) {
project.logger.lifecycle("Repository ${(this as? MavenArtifactRepository)?.url ?: name} removed. Only $ENTERPRISE_REPOSITORY_URL is allowed")
remove(this)
}
}
// add the enterprise repository
add(maven {
name = "STANDARD_ENTERPRISE_REPO"
url = uri(ENTERPRISE_REPOSITORY_URL)
})
}
}
}
}repositories{
mavenCentral()
}
data class RepositoryData(val name: String, val url: URI)
tasks.register("showRepositories") {
val repositoryData = repositories.withType<MavenArtifactRepository>().map { RepositoryData(it.name, it.url) }
doLast {
repositoryData.forEach {
println("repository: ${it.name} ('${it.url}')")
}
}
}apply plugin: EnterpriseRepositoryPlugin
class EnterpriseRepositoryPlugin implements Plugin<Gradle> {
private static String ENTERPRISE_REPOSITORY_URL = "https://repo.gradle.org/gradle/repo"
void apply(Gradle gradle) {
// ONLY USE ENTERPRISE REPO FOR DEPENDENCIES
gradle.allprojects { project ->
project.repositories {
// Remove all repositories not pointing to the enterprise repository url
all { ArtifactRepository repo ->
if (!(repo instanceof MavenArtifactRepository) ||
repo.url.toString() != ENTERPRISE_REPOSITORY_URL) {
project.logger.lifecycle "Repository ${repo.url} removed. Only $ENTERPRISE_REPOSITORY_URL is allowed"
remove repo
}
}
// add the enterprise repository
maven {
name "STANDARD_ENTERPRISE_REPO"
url ENTERPRISE_REPOSITORY_URL
}
}
}
}
}repositories{
mavenCentral()
}
@Immutable
class RepositoryData {
String name
URI url
}
tasks.register('showRepositories') {
def repositoryData = repositories.collect { new RepositoryData(it.name, it.url) }
doLast {
repositoryData.each {
println "repository: ${it.name} ('${it.url}')"
}
}
}应用 init 脚本时的输出:
> gradle --init-script init.gradle.kts -q showRepositories
repository: STANDARD_ENTERPRISE_REPO ('https://repo.gradle.org/gradle/repo')> gradle --init-script init.gradle -q showRepositories
repository: STANDARD_ENTERPRISE_REPO ('https://repo.gradle.org/gradle/repo')初始化脚本中的插件可确保运行构建时仅使用指定的存储库。
当在 init 脚本中应用插件时,Gradle 会实例化插件并调用插件实例的Plugin.apply(T)方法。
该gradle对象作为参数传递,可用于配置构建的各个方面。当然,所应用的插件可以解析为外部依赖项,如init 脚本的外部依赖项中所述
开发自定义 Gradle 类型
您可以开发多种不同类型的 Gradle“附加组件”,例如插件、任务、 项目扩展或工件转换,它们全部实现为可以在 JVM 上运行的类和其他类型。本章讨论这些类型的一些共同特征和概念。您可以使用这些功能来帮助实现自定义 Gradle 类型并为您的用户提供一致的 DSL。
本章适用于以下类型:
-
插件类型。
-
任务类型。
-
工件变换参数类型。
-
Worker API 工作操作参数类型。
-
使用 创建的扩展对象
ExtensionContainer.create(),例如由插件注册的项目扩展。 -
使用创建的对象
ObjectFactory.newInstance()。 -
为托管嵌套属性创建的对象。
-
a 的元素
NamedDomainObjectContainer。
使用属性进行配置
您实现的自定义 Gradle 类型通常包含一些您希望可用于构建脚本和其他插件的配置。例如,下载任务可能具有指定从中下载的 URL 以及将结果写入的文件系统位置的配置。
托管物业
Gradle 提供了自己的托管属性概念,允许您将每个属性声明为抽象 getter(Java、Groovy)或抽象属性(Kotlin)。然后 Gradle 自动提供此类属性的实现。它称为托管属性,因为 Gradle 负责管理该属性的状态。属性可以是可变的,这意味着它同时具有get()方法和set()方法,也可以是只读的,这意味着它只有一个get()方法。
只读属性也称为providers。
可变的托管属性
要声明可变托管属性,请添加类型的抽象 getter 方法Property<T>- 其中T可以是任何可序列化类型或完全 Gradle托管类型。 (有关更具体的属性类型,请参阅下面的列表。)该属性不得具有任何 setter 方法。以下是具有uritype 属性的任务类型示例URI:
public abstract class Download extends DefaultTask {
@Input
public abstract Property<URI> getUri(); // abstract getter of type Property<T>
@TaskAction
void run() {
System.out.println("Downloading " + getUri().get()); // Use the `uri` property
}
}请注意,对于要被视为可变托管属性的属性,该属性的 getter 方法必须是abstract且 具有public或protected可见性。属性类型必须是以下类型之一:
-
Property<T> -
RegularFileProperty -
DirectoryProperty -
ListProperty<T> -
SetProperty<T> -
MapProperty<K, V> -
ConfigurableFileCollection -
ConfigurableFileTree -
DomainObjectSet<T> -
NamedDomainObjectContainer<T> -
ExtensiblePolymorphicDomainObjectContainer<T> -
DependencyCollector
Gradle 以与ObjectFactory相同的方式为托管属性创建值。
只读托管属性
要声明只读托管属性(也称为提供程序),请添加类型的 getter 方法Provider<T>。然后,方法实现需要派生值,例如从其他属性派生值。
uri以下是具有从属性派生的提供程序的任务类型的示例location:
public abstract class Download extends DefaultTask {
@Input
public abstract Property<String> getLocation();
@Internal
public Provider<URI> getUri() {
return getLocation().map(l -> URI.create("https://" + l));
}
@TaskAction
void run() {
System.out.println("Downloading " + getUri().get()); // Use the `uri` provider (read-only property)
}
}只读托管嵌套属性
要声明只读托管嵌套属性,请将该属性的抽象 getter 方法添加到用 注释的类型。该属性不应有任何 setter 方法。 Gradle 提供了 getter 方法的实现,并且还为属性创建了一个值。嵌套类型也被视为自定义类型,并且可以使用本章中讨论的功能。@Nested
当自定义类型具有具有相同生命周期的嵌套复杂类型时,此模式非常有用。如果生命周期不同,请考虑改用Property<NestedType>。
以下是具有属性的任务类型的示例resource。该Resource类型也是自定义 Gradle 类型,并定义了一些托管属性:
public abstract class Download extends DefaultTask {
@Nested
public abstract Resource getResource(); // Use an abstract getter method annotated with @Nested
@TaskAction
void run() {
// Use the `resource` property
System.out.println("Downloading https://" + getResource().getHostName().get() + "/" + getResource().getPath().get());
}
}
public interface Resource {
@Input
Property<String> getHostName();
@Input
Property<String> getPath();
}请注意,对于要被视为只读托管嵌套属性的属性,该属性的 getter 方法必须是abstract和public或protected可见性。该属性不得有任何 setter 方法。此外,属性获取器必须用 进行注释。@Nested
只读托管“名称”属性
如果类型包含类型的名为“name”的抽象属性String,Gradle 会提供 getter 方法的实现,并使用“name”参数扩展每个构造函数,该参数位于所有其他构造函数参数之前。如果类型是接口,Gradle 将提供具有单个“名称”参数和@Inject语义的构造函数。
您可以让您的类型实现或扩展Named接口,该接口定义了这样一个只读“name”属性。
托管类型
托管类型是没有字段且其属性全部托管的抽象类或接口。也就是说,它是一种状态完全由 Gradle 管理的类型。
命名托管类型是另外具有 type 的抽象属性“name”的托管类型String。命名托管类型作为NamedDomainObjectContainer的元素类型特别有用(见下文)。
public interface Resource {
@Input
Property<String> getHostName();
@Input
Property<String> getPath();
}Java bean 属性。
有时您可能会看到以 Java bean 属性样式实现的属性。也就是说,它们不使用 aProperty<T>或Provider<T>类型,而是使用具体的 setter 和 getter 方法(或 Groovy 或 Kotlin 中的相应便利方法)实现。这种属性定义风格是 Gradle 中的遗留问题,不鼓励使用。 Gradle 核心插件中仍属于这种风格的属性将在未来版本中迁移到托管属性。
DSL 支持和可扩展性
当 Gradle 创建自定义类型的实例时,它会装饰该实例以混合 DSL 和可扩展性支持。
每个修饰实例都实现ExtensionAware,因此可以附加扩展对象。
请注意,由于向后兼容性问题,使用Project.container()创建的插件和容器元素目前尚未修饰。
服务注入
Gradle 提供了许多有用的服务,可供自定义 Gradle 类型使用。例如,任务可以使用WorkerExecutor服务来并行运行工作,如工作 API部分所示。这些服务是通过服务注入提供的。
可用服务
可提供以下注射服务:
-
ObjectFactory - 允许创建模型对象。有关更多详细信息,请参阅显式创建对象。
-
ProjectLayout - 提供对关键项目位置的访问。有关更多详细信息,请参阅惰性配置。此服务在 Worker API 操作中不可用。
-
BuildLayout - 提供对 Gradle 构建重要位置的访问。该服务仅可用于在设置插件中注入。
-
ProviderFactory - 创建
Provider实例。有关更多详细信息,请参阅惰性配置。 -
WorkerExecutor - 允许任务并行运行。有关更多详细信息,请参阅工作 API 。
-
FileSystemOperations - 允许任务在文件系统上运行操作,例如删除文件、复制文件或同步目录。
-
ArchiveOperations - 允许任务对存档文件(例如 ZIP 或 TAR 文件)运行操作。
-
ExecOperations - 允许任务运行外部进程,并专门支持运行外部
java程序。 -
ToolingModelBuilderRegistry - 允许插件注册 Gradle 工具 API 模型。
除上述之外,ProjectLayout服务WorkerExecutor仅可用于项目插件中的注入。
构造函数注入
对象可以通过两种方式接收其所需的服务。第一个选项是将服务添加为类构造函数的参数。构造函数必须带有注解javax.inject.Inject。 Gradle 使用每个构造函数参数的声明类型来确定对象所需的服务。构造函数参数的顺序及其名称并不重要,可以是您喜欢的任何顺序。
下面是一个示例,显示了通过其构造函数接收的任务类型ObjectFactory:
public class Download extends DefaultTask {
private final DirectoryProperty outputDirectory;
// Inject an ObjectFactory into the constructor
@Inject
public Download(ObjectFactory objectFactory) {
// Use the factory
outputDirectory = objectFactory.directoryProperty();
}
@OutputDirectory
public DirectoryProperty getOutputDirectory() {
return outputDirectory;
}
@TaskAction
void run() {
// ...
}
}财产注入
javax.inject.Inject或者,可以通过向类添加使用注释进行注释的属性 getter 方法来注入服务。例如,当由于向后兼容性限制而无法更改类的构造函数时,这可能很有用。此模式还允许 Gradle 推迟服务的创建,直到调用 getter 方法,而不是创建实例时。这有助于提高性能。 Gradle 使用 getter 方法声明的返回类型来确定要提供的服务。属性的名称并不重要,可以是您喜欢的任何名称。
属性 getter 方法必须是publicor protected。该方法可以有abstract一个虚拟方法体,或者在不可能的情况下,可以有一个虚拟方法体。方法主体被丢弃。
下面的示例显示了通过属性 getter 方法接收两个服务的任务类型:
public abstract class Download extends DefaultTask {
// Use an abstract getter method
@Inject
protected abstract ObjectFactory getObjectFactory();
// Alternatively, use a getter method with a dummy implementation
@Inject
protected WorkerExecutor getWorkerExecutor() {
// Method body is ignored
throw new UnsupportedOperationException();
}
@TaskAction
void run() {
WorkerExecutor workerExecutor = getWorkerExecutor();
ObjectFactory objectFactory = getObjectFactory();
// Use the executor and factory ...
}
}显式创建对象
|
笔记
|
更喜欢让 Gradle 使用托管属性自动创建对象。 |
自定义 Gradle 类型可以使用ObjectFactory服务创建 Gradle 类型的实例以用于其属性值。这些实例可以利用本章讨论的功能,允许您创建对象和嵌套 DSL。
在以下示例中,项目扩展ObjectFactory通过其构造函数接收实例。构造函数使用它来创建一个嵌套Resource对象(也是一个自定义 Gradle 类型),并通过该属性使该对象可用resource。
public class DownloadExtension {
// A nested instance
private final Resource resource;
@Inject
public DownloadExtension(ObjectFactory objectFactory) {
// Use an injected ObjectFactory to create a Resource object
resource = objectFactory.newInstance(Resource.class);
}
public Resource getResource() {
return resource;
}
}
public interface Resource {
Property<URI> getUri();
}收藏类型
Gradle 提供了用于维护对象集合的类型,旨在很好地扩展 Gradle 的 DSL 并提供有用的功能,例如延迟配置。
命名域对象容器
NamedDomainObjectContainer管理一组对象,其中每个元素都有一个与其关联的名称。容器负责创建和配置元素,并提供构建脚本可用于定义和配置元素的 DSL。它旨在保存本身可配置的对象,例如一组自定义 Gradle 对象。
GradleNamedDomainObjectContainer在整个 API 中广泛使用类型。例如,project.tasks用于管理项目任务的对象是NamedDomainObjectContainer<Task>.
您可以使用ObjectFactory服务创建容器实例,该服务提供ObjectFactory.domainObjectContainer()方法。这也可以使用Project.container()方法来实现,但是在自定义 Gradle 类型中,通常最好使用注入的ObjectFactory服务而不是传递Project实例。
您还可以使用如上所述的只读托管属性创建容器实例。
为了将类型与任何domainObjectContainer()方法一起使用,它必须
-
是命名的托管类型;或者
-
将名为“name”的属性公开为对象的唯一且常量名称。该方法的变
domainObjectContainer(Class)体通过调用带有字符串参数(即所需的对象名称)的类的构造函数来创建新实例。
以这种方式创建的对象被视为自定义 Gradle 类型,因此可以利用本章中讨论的功能,例如服务注入或托管属性。
请参阅上面的链接,了解domainObjectContainer()允许自定义实例化策略的方法变体。
public interface DownloadExtension {
NamedDomainObjectContainer<Resource> getResources();
}
public interface Resource {
// Type must have a read-only 'name' property
String getName();
Property<URI> getUri();
Property<String> getUserName();
}对于每个容器属性,Gradle 会自动向 Groovy 和 Kotlin DSL 添加一个块,您可以使用它来配置容器的内容:
plugins {
id("org.gradle.sample.download")
}
download {
// Can use a block to configure the container contents
resources {
register("gradle") {
uri = uri("https://gradle.org")
}
}
}plugins {
id("org.gradle.sample.download")
}
download {
// Can use a block to configure the container contents
resources {
register('gradle') {
uri = uri('https://gradle.org')
}
}
}可扩展多态域对象容器
ExtensiblePolymorphicDomainObjectContainer允许您为不同类型NamedDomainObjectContainer的对象定义实例化策略。
命名域对象集
NamedDomainObjectSet保存一组可配置对象,其中每个元素都有一个与其关联的名称。这与 类似NamedDomainObjectContainer,但是 aNamedDomainObjectSet不管理集合中的对象。它们需要手动创建和添加。
命名域对象列表
NamedDomainObjectList保存可配置对象的列表,其中每个元素都有一个与其关联的名称。这与 类似NamedDomainObjectContainer,但是 aNamedDomainObjectList不管理集合中的对象。它们需要手动创建和添加。
共享构建服务
有时,多个任务共享某些状态或资源很有用。例如,任务可能会共享预先计算值的缓存,以便更快地完成工作。或者任务可能使用 Web 服务或数据库实例来完成其工作。
Gradle 允许您声明构建服务来表示此状态。构建服务只是一个保存任务使用状态的对象。 Gradle 负责服务生命周期,并且仅在需要时创建服务实例,并在不再需要时将其清除。 Gradle 还可以选择负责协调对构建服务的访问,以便不超过指定数量的任务可以同时使用该服务。
实施构建服务
要实现构建服务,请创建一个实现BuildService的抽象类。定义您希望任务使用的此类型的方法。构建服务实现被视为自定义 Gradle 类型,并且可以使用自定义 Gradle 类型可用的任何功能。
构建服务可以选择接受参数,Gradle 在创建服务实例时将其注入到服务实例中。要提供参数,您需要定义一个保存参数的抽象类(或接口)。参数类型必须实现(或扩展)BuildServiceParameters。服务实现可以使用访问参数this.getParameters()。参数类型也是自定义的Gradle类型。
当构建服务不需要任何参数时,可以使用BuildServiceParameters.None作为参数类型。
构建服务实现也可以选择实现,在这种情况下,Gradle 将在丢弃服务实例时AutoCloseable调用构建服务实例的方法。close()这种情况发生在使用构建服务的最后一个任务完成和构建结束之间的一段时间内。
下面是一个接受参数且可关闭的服务示例:
import org.gradle.api.file.DirectoryProperty;
import org.gradle.api.provider.Property;
import org.gradle.api.services.BuildService;
import org.gradle.api.services.BuildServiceParameters;
import java.net.URI;
import java.net.URISyntaxException;
public abstract class WebServer implements BuildService<WebServer.Params>, AutoCloseable {
// Some parameters for the web server
interface Params extends BuildServiceParameters {
Property<Integer> getPort();
DirectoryProperty getResources();
}
private final URI uri;
public WebServer() throws URISyntaxException {
// Use the parameters
int port = getParameters().getPort().get();
uri = new URI(String.format("https://localhost:%d/", port));
// Start the server ...
System.out.println(String.format("Server is running at %s", uri));
}
// A public method for tasks to use
public URI getUri() {
return uri;
}
@Override
public void close() {
// Stop the server ...
}
}请注意,您不应实现BuildService.getParameters ()方法,因为 Gradle 将提供此方法的实现。
构建服务实现必须是线程安全的,因为它可能会被多个任务同时使用。
使用任务中的构建服务
要使用任务中的构建服务,您需要:
-
向类型 的任务添加属性
Property<MyServiceType>。 -
@Internal使用或注释该属性@ServiceReference(自 8.0 起)。 -
将共享构建服务提供者分配给该属性(使用时可选
@ServiceReference(<serviceName>))。 -
声明任务和服务之间的关联,以便 Gradle 可以正确遵守构建服务生命周期及其使用约束(在使用时也是可选的
@ServiceReference)。
请注意,当前不支持将服务与任何其他注释一起使用。例如,当前无法将服务标记为任务的输入。
使用注释共享构建服务属性@Internal
当您使用 注释共享构建服务属性时@Internal,您还需要做两件事:
-
将使用BuildServiceRegistry.registerIfAbsent()注册服务时获得的构建服务提供者显式分配给该属性。
-
通过Task.usesService显式声明任务和服务之间的关联。
下面是一个任务示例,该任务通过带有 注释的属性来使用先前的服务@Internal:
import org.gradle.api.DefaultTask;
import org.gradle.api.file.RegularFileProperty;
import org.gradle.api.provider.Property;
import org.gradle.api.tasks.Internal;
import org.gradle.api.tasks.OutputFile;
import org.gradle.api.tasks.TaskAction;
import java.net.URI;
public abstract class Download extends DefaultTask {
// This property provides access to the service instance
@Internal
abstract Property<WebServer> getServer();
@OutputFile
abstract RegularFileProperty getOutputFile();
@TaskAction
public void download() {
// Use the server to download a file
WebServer server = getServer().get();
URI uri = server.getUri().resolve("somefile.zip");
System.out.println(String.format("Downloading %s", uri));
}
}使用注释共享构建服务属性@ServiceReference
|
笔记
|
该@ServiceReference注释是一个正在孵化的API,在未来的版本中可能会发生变化。
|
否则,当您使用 注释共享构建服务属性时@ServiceReference,无需显式声明任务和服务之间的关联;此外,如果您向注释提供服务名称,并且使用该名称注册共享构建服务,则在创建任务时它将自动分配给该属性。
下面是一个任务示例,该任务通过带有 注释的属性来使用先前的服务@ServiceReference:
import org.gradle.api.DefaultTask;
import org.gradle.api.file.RegularFileProperty;
import org.gradle.api.provider.Property;
import org.gradle.api.services.ServiceReference;
import org.gradle.api.tasks.OutputFile;
import org.gradle.api.tasks.TaskAction;
import java.net.URI;
public abstract class Download extends DefaultTask {
// This property provides access to the service instance
@ServiceReference("web")
abstract Property<WebServer> getServer();
@OutputFile
abstract RegularFileProperty getOutputFile();
@TaskAction
public void download() {
// Use the server to download a file
WebServer server = getServer().get();
URI uri = server.getUri().resolve("somefile.zip");
System.out.println(String.format("Downloading %s", uri));
}
}注册构建服务并将其连接到任务
要创建构建服务,请使用 BuildServiceRegistry.registerIfAbsent ()方法注册服务实例。注册服务不会创建服务实例。当任务首次使用该服务时,这种情况会按需发生。如果构建期间没有任务使用该服务,则不会创建该服务实例。
目前,构建服务的范围仅限于构建,而不是项目,并且这些服务可供所有项目的任务共享。您可以通过访问共享构建服务的注册表Project.getGradle().getSharedServices()。
以下是一个插件示例,当使用该服务的任务属性注释为 时,该插件会注册先前的服务@Internal:
import org.gradle.api.Plugin;
import org.gradle.api.Project;
import org.gradle.api.provider.Provider;
public class DownloadPlugin implements Plugin<Project> {
public void apply(Project project) {
// Register the service
Provider<WebServer> serviceProvider = project.getGradle().getSharedServices().registerIfAbsent("web", WebServer.class, spec -> {
// Provide some parameters
spec.getParameters().getPort().set(5005);
});
project.getTasks().register("download", Download.class, task -> {
// Connect the service provider to the task
task.getServer().set(serviceProvider);
// Declare the association between the task and the service
task.usesService(serviceProvider);
task.getOutputFile().set(project.getLayout().getBuildDirectory().file("result.zip"));
});
}
}该插件注册服务并接收返回Provider<WebService>。该提供程序可以连接到任务属性以将服务传递给任务。请注意,对于使用 注释的任务属性@Internal,该任务属性需要 (1) 显式分配注册期间获取的提供程序,并且 (2) 您必须通过Task.usesService告诉 Gradle 该任务使用该服务。
与使用服务的任务属性注释为以下情况进行比较@ServiceReference:
import org.gradle.api.Plugin;
import org.gradle.api.Project;
import org.gradle.api.provider.Provider;
public class DownloadPlugin implements Plugin<Project> {
public void apply(Project project) {
// Register the service
project.getGradle().getSharedServices().registerIfAbsent("web", WebServer.class, spec -> {
// Provide some parameters
spec.getParameters().getPort().set(5005);
});
project.getTasks().register("download", Download.class, task -> {
task.getOutputFile().set(project.getLayout().getBuildDirectory().file("result.zip"));
});
}
}正如您所看到的,不需要为任务分配构建服务提供者,也不需要显式声明任务使用该服务。
通过配置操作使用共享构建服务
通常,构建服务旨在由任务使用,因为它们通常表示创建成本可能很高的某种状态,并且您应该避免在配置时使用它们。然而,有时在配置时使用该服务是有意义的。这是可能的,只需致电get()提供商即可。
使用构建服务的其他方式
例如,要将MyServiceType服务传递给辅助 API 操作,您可以将 type 属性添加Property<MyServiceType>到操作的参数对象,然后将Provider<MyServiceType>在将服务注册到此属性时收到的连接。
import org.gradle.api.DefaultTask;
import org.gradle.api.provider.Property;
import org.gradle.api.services.ServiceReference;
import org.gradle.api.tasks.TaskAction;
import org.gradle.workers.WorkAction;
import org.gradle.workers.WorkParameters;
import org.gradle.workers.WorkQueue;
import org.gradle.workers.WorkerExecutor;
import javax.inject.Inject;
import java.net.URI;
public abstract class Download extends DefaultTask {
public static abstract class DownloadWorkAction implements WorkAction<DownloadWorkAction.Parameters> {
interface Parameters extends WorkParameters {
// This property provides access to the service instance from the work action
abstract Property<WebServer> getServer();
}
@Override
public void execute() {
// Use the server to download a file
WebServer server = getParameters().getServer().get();
URI uri = server.getUri().resolve("somefile.zip");
System.out.println(String.format("Downloading %s", uri));
}
}
@Inject
abstract public WorkerExecutor getWorkerExecutor();
// This property provides access to the service instance from the task
@ServiceReference("web")
abstract Property<WebServer> getServer();
@TaskAction
public void download() {
WorkQueue workQueue = getWorkerExecutor().noIsolation();
workQueue.submit(DownloadWorkAction.class, parameter -> {
parameter.getServer().set(getServer());
});
}
}目前,无法将构建服务与使用 ClassLoader 或进程隔离模式的辅助 API 操作结合使用。
并发访问服务
您可以在注册服务时使用从BuildServiceSpec.getMaxParallelUsages()Property返回的对象来限制并发执行。当此属性没有值时(默认情况下),Gradle 不会限制对服务的访问。当此属性的值 > 0 时,Gradle 将允许不超过指定数量的任务同时使用该服务。
|
重要的
|
当使用任务属性使用 进行注释时@Internal,为了使约束生效,构建服务必须通过Task.usesService(Provider<? extends BuildService<?>>)向使用任务注册
。如果消费属性用 进行注释,则不需要这样做@ServiceReference。
|
接收有关任务执行的信息
构建服务可用于在执行任务时接收事件。为此,创建并注册一个实现OperationCompletionListener的构建服务:
import org.gradle.api.services.BuildService;
import org.gradle.api.services.BuildServiceParameters;
import org.gradle.tooling.events.FinishEvent;
import org.gradle.tooling.events.OperationCompletionListener;
import org.gradle.tooling.events.task.TaskFinishEvent;
public abstract class TaskEventsService implements BuildService<BuildServiceParameters.None>,
OperationCompletionListener { // (1)
@Override
public void onFinish(FinishEvent finishEvent) {
if (finishEvent instanceof TaskFinishEvent) { // (2)
// Handle task finish event...
}
}
}-
OperationCompletionListener除了接口之外还要实现接口BuildService。 -
检查完成事件是否是TaskFinishEvent。
然后,在插件中,您可以使用BuildEventsListenerRegistry服务上的方法开始接收事件:
import org.gradle.api.Plugin;
import org.gradle.api.Project;
import org.gradle.api.provider.Provider;
import org.gradle.build.event.BuildEventsListenerRegistry;
import javax.inject.Inject;
public abstract class TaskEventsPlugin implements Plugin<Project> {
@Inject
public abstract BuildEventsListenerRegistry getEventsListenerRegistry(); // (1)
@Override
public void apply(Project project) {
Provider<TaskEventsService> serviceProvider =
project.getGradle().getSharedServices().registerIfAbsent(
"taskEvents", TaskEventsService.class, spec -> {}); // (2)
getEventsListenerRegistry().onTaskCompletion(serviceProvider); // (3)
}
}-
使用服务注入来获取
BuildEventsListenerRegistry. -
像往常一样注册构建服务。
-
使用该服务
Provider订阅构建服务来构建事件。
数据流操作
|
笔记
|
数据流操作支持是一项孵化功能,此处描述的详细信息可能会发生变化。 |
在 Gradle 构建中执行工作的首选方式是使用任务。然而,有些工作并不适合任务,例如构建失败的自定义处理。如果您想在构建成功时播放欢快的声音,在构建失败时播放悲伤的声音,该怎么办?该工件要处理任务执行结果,因此它本身不能是任务。
数据流操作 API 提供了一种安排此类工作的方法。数据流操作是一个参数化的隔离工作,一旦其所有输入参数可用,就可以执行。
实施数据流操作
第一步是实施行动本身。为此,您创建一个实现FlowAction接口的类。该execute方法必须被实现,因为这是工作发生的地方。操作实现被视为自定义 Gradle 类型,并且可以使用自定义 Gradle 类型可用的任何功能。特别是,一些 Gradle 服务可以注入到实现中。
数据流操作可以接受参数。要提供参数,您需要定义一个抽象类(或接口)来保存参数。参数类型必须实现(或扩展)FlowParameters。操作实现获取参数作为execute方法的参数。参数类型也是自定义的Gradle类型。
当操作不需要参数时,您可以使用FlowParameters.None作为参数类型。
以下是采用共享构建服务和文件路径作为参数的数据流操作示例。
package org.gradle.sample.sound;
import org.gradle.api.flow.FlowAction;
import org.gradle.api.flow.FlowParameters;
import org.gradle.api.provider.Property;
import org.gradle.api.services.ServiceReference;
import org.gradle.api.tasks.Input;
import java.io.File;
public abstract class SoundPlay implements FlowAction<SoundPlay.Parameters> {
interface Parameters extends FlowParameters {
@ServiceReference // (1)
Property<SoundService> getSoundService();
@Input // (2)
Property<File> getMediaFile();
}
@Override
public void execute(Parameters parameters) {
parameters.getSoundService().get().playSoundFile(parameters.getMediaFile().get());
}
}-
参数类型中的参数必须被注释。如果参数带有注释,
@ServiceReference则在创建操作时,根据通常的规则,会自动将合适的共享构建服务实现分配给该参数。 -
所有其他参数必须用 注释
@Input。
生命周期事件提供者
除了通常的值提供程序之外,Gradle 还为构建生命周期事件(例如构建完成)提供了专用提供程序。这些提供程序旨在用于数据流操作,并在用作输入时提供额外的排序保证。如果您通过调用map或 等方式从事件提供程序派生提供程序,则该顺序也适用flatMap。您可以从FlowProviders类获取这些提供程序。
|
警告
|
如果您不使用生命周期事件提供程序作为数据流操作的输入,则执行操作的确切时间未定义,并且可能会在下一版本的 Gradle 中发生变化。 |
提供执行操作
您不应该FlowAction手动创建对象。相反,您请求在适当的范围内执行它们FlowScope。执行此操作时,您可以配置要使用的任务的参数。
package org.gradle.sample.sound;
import org.gradle.api.Plugin;
import org.gradle.api.flow.FlowProviders;
import org.gradle.api.flow.FlowScope;
import org.gradle.api.initialization.Settings;
import javax.inject.Inject;
import java.io.File;
public abstract class SoundFeedbackPlugin implements Plugin<Settings> {
@Inject
protected abstract FlowScope getFlowScope(); // (1)
@Inject
protected abstract FlowProviders getFlowProviders(); // (1)
@Override
public void apply(Settings settings) {
final File soundsDir = new File(settings.getSettingsDir(), "sounds");
getFlowScope().always( // (2)
SoundPlay.class, // (3)
spec -> // (4)
spec.getParameters().getMediaFile().set(
getFlowProviders().getBuildWorkResult().map(result -> // (5)
new File(
soundsDir,
result.getFailure().isPresent() ? "sad-trombone.mp3" : "tada.mp3"
)
)
)
);
}
}-
使用服务注入来获取
FlowScope实例FlowProviders。它们可用于项目和设置插件。 -
使用适当的范围来运行您的操作。顾名思义,
always每次构建运行时都会执行范围内的操作。 -
指定实现该操作的类。
-
使用spec参数来配置操作参数。
-
生命周期事件提供者可以映射到其他东西,同时保留操作顺序。
因此,当您运行构建并成功完成时,该操作将播放“tada”声音。如果构建在配置或执行时失败,那么您会听到“悲伤的长号”——当然,假设构建配置进行得足够远,足以注册操作。
使用 TestKit 测试构建逻辑
Gradle TestKit(又名 TestKit)是一个帮助测试 Gradle 插件和构建逻辑的库。此时,重点是功能测试。也就是说,通过将构建逻辑作为以编程方式执行的构建的一部分来进行测试。随着时间的推移,TestKit 可能会扩展以促进其他类型的测试。
用法
要使用 TestKit,请在插件的构建中包含以下内容:
dependencies {
testImplementation(gradleTestKit())
}dependencies {
testImplementation gradleTestKit()
}其中gradleTestKit()包含 TestKit 的类以及Gradle Tooling API 客户端。它不包括JUnit、TestNG或任何其他测试执行框架的版本。必须显式声明此类依赖关系。
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
tasks.named<Test>("test") {
useJUnitPlatform()
}dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
tasks.named('test', Test) {
useJUnitPlatform()
}使用 Gradle 运行程序进行功能测试
GradleRunner有助于以编程方式执行 Gradle 构建并检查结果。
可以创建一个人为的构建(例如以编程方式或从模板)来执行“被测试的逻辑”。然后可以以多种方式(例如任务和参数的不同组合)执行构建。然后可以通过断言以下内容(可能组合使用)来验证逻辑的正确性:
-
构建的输出;
-
构建的日志记录(即控制台输出);
-
构建执行的任务集及其结果(例如失败、最新等)。
创建并配置运行器实例后,可以根据预期结果通过GradleRunner.build()或GradleRunner.buildAndFail()方法执行构建。
下面演示了 Gradle runner 在 Java JUnit 测试中的用法:
示例:将 GradleRunner 与 Java 和 JUnit 结合使用
import org.gradle.testkit.runner.BuildResult;
import org.gradle.testkit.runner.GradleRunner;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import static org.gradle.testkit.runner.TaskOutcome.SUCCESS;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertTrue;
public class BuildLogicFunctionalTest {
@TempDir File testProjectDir;
private File settingsFile;
private File buildFile;
@BeforeEach
public void setup() {
settingsFile = new File(testProjectDir, "settings.gradle");
buildFile = new File(testProjectDir, "build.gradle");
}
@Test
public void testHelloWorldTask() throws IOException {
writeFile(settingsFile, "rootProject.name = 'hello-world'");
String buildFileContent = "task helloWorld {" +
" doLast {" +
" println 'Hello world!'" +
" }" +
"}";
writeFile(buildFile, buildFileContent);
BuildResult result = GradleRunner.create()
.withProjectDir(testProjectDir)
.withArguments("helloWorld")
.build();
assertTrue(result.getOutput().contains("Hello world!"));
assertEquals(SUCCESS, result.task(":helloWorld").getOutcome());
}
private void writeFile(File destination, String content) throws IOException {
BufferedWriter output = null;
try {
output = new BufferedWriter(new FileWriter(destination));
output.write(content);
} finally {
if (output != null) {
output.close();
}
}
}
}可以使用任何测试执行框架。
由于 Gradle 构建脚本也可以使用 Groovy 编程语言编写,因此使用 Groovy 编写 Gradle 功能测试通常是一个富有成效的选择。此外,建议使用(基于 Groovy 的)Spock 测试执行框架,因为与使用 JUnit 相比,它提供了许多引人注目的功能。
下面演示了Gradle runner在Groovy Spock测试中的用法:
示例:将 GradleRunner 与 Groovy 和 Spock 结合使用
import org.gradle.testkit.runner.GradleRunner
import static org.gradle.testkit.runner.TaskOutcome.*
import spock.lang.TempDir
import spock.lang.Specification
class BuildLogicFunctionalTest extends Specification {
@TempDir File testProjectDir
File settingsFile
File buildFile
def setup() {
settingsFile = new File(testProjectDir, 'settings.gradle')
buildFile = new File(testProjectDir, 'build.gradle')
}
def "hello world task prints hello world"() {
given:
settingsFile << "rootProject.name = 'hello-world'"
buildFile << """
task helloWorld {
doLast {
println 'Hello world!'
}
}
"""
when:
def result = GradleRunner.create()
.withProjectDir(testProjectDir)
.withArguments('helloWorld')
.build()
then:
result.output.contains('Hello world!')
result.task(":helloWorld").outcome == SUCCESS
}
}在独立项目中实现任何本质上更复杂的自定义构建逻辑(例如插件和任务类型)是一种常见的做法。这种方法背后的主要驱动力是将编译后的代码捆绑到 JAR 文件中,将其发布到二进制存储库并在各个项目中重用它。
将待测插件放入测试版本中
GradleRunner 使用工具 API来执行构建。这意味着构建是在单独的进程中执行的(即与执行测试的进程不同)。因此,测试构建不会与测试进程共享相同的类路径或类加载器,并且被测代码不会隐式地可供测试构建使用。
|
笔记
|
GradleRunner 支持与 Tooling API 相同范围的 Gradle 版本。支持的版本在兼容性矩阵中定义。 使用较旧的 Gradle 版本进行构建可能仍然有效,但不能保证。 |
从版本 2.13 开始,Gradle 提供了一种传统机制将测试代码注入到测试构建中。
使用 Java Gradle Plugin 开发插件自动注入
Java Gradle Plugin开发插件可以用来辅助Gradle插件的开发。从 Gradle 版本 2.13 开始,该插件提供了与 TestKit 的直接集成。当应用于项目时,插件会自动将gradleTestKit()依赖项添加到testApi配置中。此外,它会自动为被测代码生成类路径,并通过GradleRunner.withPluginClasspath()GradleRunner为用户创建的任何实例注入它。需要注意的是,该机制目前仅在使用插件 DSL应用被测插件时才有效。如果目标 Gradle 版本早于 2.8,则不会执行自动插件类路径注入。
该插件使用以下约定来应用 TestKit 依赖项并注入类路径:
-
包含被测试代码的源集:
sourceSets.main -
用于注入插件类路径的源集:
sourceSets.test
以下基于 Groovy 的示例演示了如何使用 Java Gradle 插件开发插件应用的标准约定自动注入插件类路径。
plugins {
groovy
`java-gradle-plugin`
}
dependencies {
testImplementation("org.spockframework:spock-core:2.2-groovy-3.0") {
exclude(group = "org.codehaus.groovy")
}
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}plugins {
id 'groovy'
id 'java-gradle-plugin'
}
dependencies {
testImplementation('org.spockframework:spock-core:2.2-groovy-3.0') {
exclude group: 'org.codehaus.groovy'
}
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}示例:自动将测试类下的代码注入到测试构建中
def "hello world task prints hello world"() {
given:
settingsFile << "rootProject.name = 'hello-world'"
buildFile << """
plugins {
id 'org.gradle.sample.helloworld'
}
"""
when:
def result = GradleRunner.create()
.withProjectDir(testProjectDir)
.withArguments('helloWorld')
.withPluginClasspath()
.build()
then:
result.output.contains('Hello world!')
result.task(":helloWorld").outcome == SUCCESS
}以下构建脚本演示了如何为使用自定义源集的项目重新配置 Java Gradle Plugin Development 插件提供的约定Test。
|
笔记
|
通过孵化JVM 测试套件functionalTest插件,可以使用
用于建模以下套件的新配置 DSL 。
|
plugins {
groovy
`java-gradle-plugin`
}
val functionalTest = sourceSets.create("functionalTest")
val functionalTestTask = tasks.register<Test>("functionalTest") {
group = "verification"
testClassesDirs = functionalTest.output.classesDirs
classpath = functionalTest.runtimeClasspath
useJUnitPlatform()
}
tasks.check {
dependsOn(functionalTestTask)
}
gradlePlugin {
testSourceSets(functionalTest)
}
dependencies {
"functionalTestImplementation"("org.spockframework:spock-core:2.2-groovy-3.0") {
exclude(group = "org.codehaus.groovy")
}
"functionalTestRuntimeOnly"("org.junit.platform:junit-platform-launcher")
}plugins {
id 'groovy'
id 'java-gradle-plugin'
}
def functionalTest = sourceSets.create('functionalTest')
def functionalTestTask = tasks.register('functionalTest', Test) {
group = 'verification'
testClassesDirs = sourceSets.functionalTest.output.classesDirs
classpath = sourceSets.functionalTest.runtimeClasspath
useJUnitPlatform()
}
tasks.named("check") {
dependsOn functionalTestTask
}
gradlePlugin {
testSourceSets sourceSets.functionalTest
}
dependencies {
functionalTestImplementation('org.spockframework:spock-core:2.2-groovy-3.0') {
exclude group: 'org.codehaus.groovy'
}
functionalTestRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}控制构建环境
运行程序通过在 JVM 临时目录(即由系统java.io.tmpdir属性指定的位置,通常为/tmp)内的目录中指定专用“工作目录”,在隔离环境中执行测试构建。默认 Gradle 用户主页(例如~/.gradle/gradle.properties)中的任何配置都不用于测试执行。 TestKit 没有公开对环境(例如,JDK)所有方面进行细粒度控制的机制。 TestKit 的未来版本将提供改进的配置选项。
TestKit 使用专用的守护进程,这些进程在测试执行后会自动关闭。
构建后,运行程序不会删除专用工作目录。 TestKit 提供了两种方法来指定定期清理的位置,例如项目的构建文件夹:
-
系统
org.gradle.testkit.dir属性; -
GradleRunner.withTestKitDir (file testKitDir)方法。
用于测试的Gradle版本
Gradle 运行程序需要 Gradle 发行版才能执行构建。 TestKit 并不依赖于 Gradle 的所有实现。
默认情况下,运行程序将尝试根据类GradleRunner的加载位置查找 Gradle 发行版。也就是说,预计该类是从 Gradle 发行版加载的,就像使用gradleTestKit()依赖项声明时的情况一样。
当使用运行器作为Gradle 执行的测试的一部分(例如执行test插件项目的任务)时,运行器将使用用于执行测试的相同发行版。当使用运行器作为IDE 执行的测试的一部分时,将使用导入项目时使用的同一 Gradle 发行版。这意味着该插件将使用与其构建时相同版本的 Gradle 进行有效测试。
或者,可以通过以下任一方法指定要使用的不同且特定的 Gradle 版本GradleRunner:
这有可能用于测试跨 Gradle 版本的构建逻辑。下面演示了一个编写为 Groovy Spock 测试的跨版本兼容性测试:
示例:指定测试执行的 Gradle 版本
import org.gradle.testkit.runner.GradleRunner
import static org.gradle.testkit.runner.TaskOutcome.*
import spock.lang.TempDir
import spock.lang.Specification
class BuildLogicFunctionalTest extends Specification {
@TempDir File testProjectDir
File settingsFile
File buildFile
def setup() {
settingsFile = new File(testProjectDir, 'settings.gradle')
buildFile = new File(testProjectDir, 'build.gradle')
}
def "can execute hello world task with Gradle version #gradleVersion"() {
given:
buildFile << """
task helloWorld {
doLast {
logger.quiet 'Hello world!'
}
}
"""
settingsFile << ""
when:
def result = GradleRunner.create()
.withGradleVersion(gradleVersion)
.withProjectDir(testProjectDir)
.withArguments('helloWorld')
.build()
then:
result.output.contains('Hello world!')
result.task(":helloWorld").outcome == SUCCESS
where:
gradleVersion << ['5.0', '6.0.1']
}
}使用不同 Gradle 版本进行测试时的功能支持
可以使用 GradleRunner 通过 Gradle 1.0 及更高版本执行构建。但是,早期版本不支持某些运行程序功能。在这种情况下,运行者在尝试使用该功能时将引发异常。
下表列出了对所使用的 Gradle 版本敏感的功能。
| 特征 | 最低版本 | 描述 |
|---|---|---|
检查执行的任务 |
2.5 |
使用BuildResult.getTasks()和类似方法检查已执行的任务。 |
2.8 |
通过GradleRunner.withPluginClasspath(java.lang.Iterable)注入测试代码。 |
|
2.9 |
在调试模式下运行时使用BuildResult.getOutput()检查构建的文本输出。 |
|
2.13 |
通过应用 Java Gradle Plugin Development 插件,通过GradleRunner.withPluginClasspath()自动注入被测代码。 |
|
设置构建要使用的环境变量。 |
3.5 |
Gradle Tooling API 仅支持在更高版本中设置环境变量。 |
调试构建逻辑
运行程序使用Tooling API来执行构建。这意味着构建是在单独的进程中执行的(即与执行测试的进程不同)。因此,在调试模式下执行测试不允许您按照预期调试构建逻辑。测试构建所执行的代码不会触发 IDE 中设置的任何断点。
TestKit 提供了两种不同的方式来启用调试模式:
-
使用JVM设置“
org.gradle.testkit.debug”系统属性(即不是使用运行器执行构建);trueGradleRunner
当需要启用调试支持而不对运行器配置进行临时更改时,可以使用系统属性方法。大多数 IDE 都提供为测试执行设置 JVM 系统属性的功能,并且可以使用这样的功能来设置此系统属性。
使用构建缓存进行测试
要在测试中启用构建缓存--build-cache,您可以将参数传递给GradleRunner或使用启用构建缓存中描述的其他方法之一。然后,当插件的自定义任务被缓存时,您可以检查任务结果TaskOutcome.FROM_CACHE 。此结果仅对 Gradle 3.5 及更高版本有效。
示例:测试可缓存任务
def "cacheableTask is loaded from cache"() {
given:
buildFile << """
plugins {
id 'org.gradle.sample.helloworld'
}
"""
when:
def result = runner()
.withArguments( '--build-cache', 'cacheableTask')
.build()
then:
result.task(":cacheableTask").outcome == SUCCESS
when:
new File(testProjectDir, 'build').deleteDir()
result = runner()
.withArguments( '--build-cache', 'cacheableTask')
.build()
then:
result.task(":cacheableTask").outcome == FROM_CACHE
}请注意,TestKit 在测试之间重复使用 Gradle User Home(请参阅GradleRunner.withTestKitDir(java.io.File)),其中包含本地构建缓存的默认位置。对于使用构建缓存进行测试,应在测试之间清理构建缓存目录。完成此操作的最简单方法是将本地构建缓存配置为使用临时目录。
示例:在测试之间清理构建缓存
@TempDir File testProjectDir
File buildFile
File localBuildCacheDirectory
def setup() {
localBuildCacheDirectory = new File(testProjectDir, 'local-cache')
buildFile = new File(testProjectDir,'settings.gradle') << """
buildCache {
local {
directory '${localBuildCacheDirectory.toURI()}'
}
}
"""
buildFile = new File(testProjectDir,'build.gradle')
}从 Gradle 使用 Ant
Gradle 提供了与 Ant 的出色集成。您可以在 Gradle 构建中使用单个 Ant 任务或整个 Ant 构建。事实上,您会发现在 Gradle 构建脚本中使用 Ant 任务比使用 Ant 的 XML 格式更容易、更强大。您甚至可以将 Gradle 简单地用作强大的 Ant 任务脚本工具。
Ant可以分为两层。第一层是Ant语言。它提供文件的语法build.xml、目标的处理、宏定义等特殊结构等。换句话说,除了 Ant 任务和类型之外的所有内容。 Gradle 理解这种语言,并允许您将 Antbuild.xml直接导入到 Gradle 项目中。然后,您可以使用 Ant 构建的目标,就好像它们是 Gradle 任务一样。
Ant 的第二层是其丰富的 Ant 任务和类型,例如javac、copy或jar。对于这一层,Gradle 只需依赖 Groovy 和出色的AntBuilder.
最后,由于构建脚本是 Groovy 脚本,因此您始终可以将 Ant 构建作为外部进程执行。您的构建脚本可能包含以下语句"ant clean compile".execute():[ 5 ]
您可以使用 Gradle 的 Ant 集成作为将构建从 Ant 迁移到 Gradle 的路径。例如,您可以首先导入现有的 Ant 构建。然后,您可以将依赖项声明从 Ant 脚本移至构建文件。最后,您可以将任务移至构建文件,或用 Gradle 的一些插件替换它们。这个过程可以随着时间的推移分部分完成,并且您可以在整个过程中构建一个有效的 Gradle。
|
警告
|
Ant 集成与配置缓存 不完全兼容。使用Task.ant在任务操作中运行 Ant 任务可能有效,但不支持导入 Ant 构建。 |
在构建中使用 Ant 任务和类型
ant在您的构建脚本中, Gradle 提供了一个名为 的属性。这是对AntBuilder实例的引用。这AntBuilder用于从构建脚本访问 Ant 任务、类型和属性。从 Antbuild.xml格式到 Groovy 有一个非常简单的映射,如下所述。
您可以通过调用实例上的方法来执行 Ant 任务AntBuilder。您使用任务名称作为方法名称。例如,您echo通过调用该ant.echo()方法来执行 Ant 任务。 Ant 任务的属性作为 Map 参数传递给该方法。下面是该任务的示例echo。请注意,我们还可以混合 Groovy 代码和 Ant 任务标记。这可能非常强大。
tasks.register("hello") {
doLast {
val greeting = "hello from Ant"
ant.withGroovyBuilder {
"echo"("message" to greeting)
}
}
}tasks.register('hello') {
doLast {
String greeting = 'hello from Ant'
ant.echo(message: greeting)
}
}gradle hello> gradle hello > Task :hello [ant:echo] hello from Ant BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
您可以将嵌套文本作为任务方法调用的参数传递给 Ant 任务。在此示例中,我们将任务消息echo作为嵌套文本传递:
tasks.register("hello") {
doLast {
ant.withGroovyBuilder {
"echo"("message" to "hello from Ant")
}
}
}tasks.register('hello') {
doLast {
ant.echo('hello from Ant')
}
}gradle hello> gradle hello > Task :hello [ant:echo] hello from Ant BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
您将嵌套元素传递给闭包内的 Ant 任务。嵌套元素的定义方式与任务相同,通过调用与我们要定义的元素同名的方法。
tasks.register("zip") {
doLast {
ant.withGroovyBuilder {
"zip"("destfile" to "archive.zip") {
"fileset"("dir" to "src") {
"include"("name" to "**.xml")
"exclude"("name" to "**.java")
}
}
}
}
}tasks.register('zip') {
doLast {
ant.zip(destfile: 'archive.zip') {
fileset(dir: 'src') {
include(name: '**.xml')
exclude(name: '**.java')
}
}
}
}您可以像访问任务一样访问 Ant 类型,使用类型名称作为方法名称。该方法调用返回 Ant 数据类型,然后您可以直接在构建脚本中使用该数据类型。在下面的示例中,我们创建一个 Antpath对象,然后迭代它的内容。
import org.apache.tools.ant.types.Path
tasks.register("list") {
doLast {
val path = ant.withGroovyBuilder {
"path" {
"fileset"("dir" to "libs", "includes" to "*.jar")
}
} as Path
path.list().forEach {
println(it)
}
}
}tasks.register('list') {
doLast {
def path = ant.path {
fileset(dir: 'libs', includes: '*.jar')
}
path.list().each {
println it
}
}
}有关更多信息,AntBuilder请参阅“Groovy in Action”8.4 或Groovy Wiki。
在构建中使用自定义 Ant 任务
要使自定义任务在您的构建中可用,您可以使用taskdef(通常更容易)或typedefAnt 任务,就像在文件中一样build.xml。然后,您可以像引用内置 Ant 任务一样引用自定义 Ant 任务。
tasks.register("check") {
val checkstyleConfig = file("checkstyle.xml")
doLast {
ant.withGroovyBuilder {
"taskdef"("resource" to "com/puppycrawl/tools/checkstyle/ant/checkstyle-ant-task.properties") {
"classpath" {
"fileset"("dir" to "libs", "includes" to "*.jar")
}
}
"checkstyle"("config" to checkstyleConfig) {
"fileset"("dir" to "src")
}
}
}
}tasks.register('check') {
def checkstyleConfig = file('checkstyle.xml')
doLast {
ant.taskdef(resource: 'com/puppycrawl/tools/checkstyle/ant/checkstyle-ant-task.properties') {
classpath {
fileset(dir: 'libs', includes: '*.jar')
}
}
ant.checkstyle(config: checkstyleConfig) {
fileset(dir: 'src')
}
}
}您可以使用 Gradle 的依赖项管理来组装类路径以用于自定义任务。为此,您需要为类路径定义自定义配置,然后向该配置添加一些依赖项。这在声明依赖关系中有更详细的描述。
val pmd = configurations.create("pmd")
dependencies {
pmd(group = "pmd", name = "pmd", version = "4.2.5")
}configurations {
pmd
}
dependencies {
pmd group: 'pmd', name: 'pmd', version: '4.2.5'
}要使用类路径配置,请使用asPath自定义配置的属性。
tasks.register("check") {
doLast {
ant.withGroovyBuilder {
"taskdef"("name" to "pmd",
"classname" to "net.sourceforge.pmd.ant.PMDTask",
"classpath" to pmd.asPath)
"pmd"("shortFilenames" to true,
"failonruleviolation" to true,
"rulesetfiles" to file("pmd-rules.xml").toURI().toString()) {
"formatter"("type" to "text", "toConsole" to "true")
"fileset"("dir" to "src")
}
}
}
}tasks.register('check') {
doLast {
ant.taskdef(name: 'pmd',
classname: 'net.sourceforge.pmd.ant.PMDTask',
classpath: configurations.pmd.asPath)
ant.pmd(shortFilenames: 'true',
failonruleviolation: 'true',
rulesetfiles: file('pmd-rules.xml').toURI().toString()) {
formatter(type: 'text', toConsole: 'true')
fileset(dir: 'src')
}
}
}导入 Ant 构建
您可以使用该ant.importBuild()方法将 Ant 构建导入到 Gradle 项目中。当您导入 Ant 构建时,每个 Ant 目标都被视为一个 Gradle 任务。这意味着您可以按照与 Gradle 任务完全相同的方式操作和执行 Ant 目标。
ant.importBuild("build.xml")ant.importBuild 'build.xml'<project>
<target name="hello">
<echo>Hello, from Ant</echo>
</target>
</project>gradle hello> gradle hello > Task :hello [ant:echo] Hello, from Ant BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
您可以添加依赖于 Ant 目标的任务:
ant.importBuild("build.xml")
tasks.register("intro") {
dependsOn("hello")
doLast {
println("Hello, from Gradle")
}
}ant.importBuild 'build.xml'
tasks.register('intro') {
dependsOn("hello")
doLast {
println 'Hello, from Gradle'
}
}gradle intro> gradle intro > Task :hello [ant:echo] Hello, from Ant > Task :intro Hello, from Gradle BUILD SUCCESSFUL in 0s 2 actionable tasks: 2 executed
或者,您可以向 Ant 目标添加行为:
ant.importBuild("build.xml")
tasks.named("hello") {
doLast {
println("Hello, from Gradle")
}
}ant.importBuild 'build.xml'
hello {
doLast {
println 'Hello, from Gradle'
}
}gradle hello> gradle hello > Task :hello [ant:echo] Hello, from Ant Hello, from Gradle BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
Ant 目标也可以依赖于 Gradle 任务:
ant.importBuild("build.xml")
tasks.register("intro") {
doLast {
println("Hello, from Gradle")
}
}ant.importBuild 'build.xml'
tasks.register('intro') {
doLast {
println 'Hello, from Gradle'
}
}<project>
<target name="hello" depends="intro">
<echo>Hello, from Ant</echo>
</target>
</project>gradle hello> gradle hello > Task :intro Hello, from Gradle > Task :hello [ant:echo] Hello, from Ant BUILD SUCCESSFUL in 0s 2 actionable tasks: 2 executed
有时可能需要“重命名”为 Ant 目标生成的任务,以避免与现有 Gradle 任务发生命名冲突。为此,请使用AntBuilder.importBuild(java.lang.Object, org.gradle.api.Transformer)方法。
ant.importBuild("build.xml") { antTargetName ->
"a-" + antTargetName
}ant.importBuild('build.xml') { antTargetName ->
'a-' + antTargetName
}<project>
<target name="hello">
<echo>Hello, from Ant</echo>
</target>
</project>gradle a-hello> gradle a-hello > Task :a-hello [ant:echo] Hello, from Ant BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
请注意,虽然此方法的第二个参数应该是Transformer,但在 Groovy 中编程时,我们可以简单地使用闭包而不是匿名内部类(或类似的),因为Groovy 支持自动将闭包强制转换为单一抽象方法类型。
Ant 属性和参考
有多种方法可以设置 Ant 属性,以便 Ant 任务可以使用该属性。您可以直接在实例上设置属性AntBuilder。 Ant 属性也可以作为您可以更改的 Map 提供。您还可以使用 Antproperty任务。以下是如何执行此操作的一些示例。
ant.setProperty("buildDir", buildDir)
ant.properties.set("buildDir", buildDir)
ant.properties["buildDir"] = buildDir
ant.withGroovyBuilder {
"property"("name" to "buildDir", "location" to "buildDir")
}ant.buildDir = buildDir
ant.properties.buildDir = buildDir
ant.properties['buildDir'] = buildDir
ant.property(name: 'buildDir', location: buildDir)许多 Ant 任务在执行时都会设置属性。有多种方法可以获取这些属性的值。您可以直接从实例获取属性AntBuilder。 Ant 属性也可以作为 Map 提供。以下是一些示例。
<property name="antProp" value="a property defined in an Ant build"/>println(ant.getProperty("antProp"))
println(ant.properties.get("antProp"))
println(ant.properties["antProp"])println ant.antProp
println ant.properties.antProp
println ant.properties['antProp']有多种方法可以设置 Ant 引用:
ant.withGroovyBuilder { "path"("id" to "classpath", "location" to "libs") }
ant.references.set("classpath", ant.withGroovyBuilder { "path"("location" to "libs") })
ant.references["classpath"] = ant.withGroovyBuilder { "path"("location" to "libs") }ant.path(id: 'classpath', location: 'libs')
ant.references.classpath = ant.path(location: 'libs')
ant.references['classpath'] = ant.path(location: 'libs')<path refid="classpath"/>有多种方法可以获取 Ant 引用:
<path id="antPath" location="libs"/>println(ant.references.get("antPath"))
println(ant.references["antPath"])println ant.references.antPath
println ant.references['antPath']蚂蚁日志记录
Gradle 将 Ant 消息优先级映射到 Gradle 日志级别,以便从 Ant 记录的消息出现在 Gradle 输出中。默认情况下,它们映射如下:
| 蚂蚁消息优先级 | Gradle 日志级别 |
|---|---|
详细 |
|
调试 |
|
信息 |
|
警告 |
|
错误 |
|
微调 Ant 日志记录
Ant 消息优先级到 Gradle 日志级别的默认映射有时可能会出现问题。例如,没有直接映射到LIFECYCLE日志级别的消息优先级,这是 Gradle 的默认设置。许多 Ant 任务以INFO优先级记录消息,这意味着要公开来自 Gradle 的这些消息,必须在日志级别设置为 的情况下运行构建INFO,可能会记录比所需多得多的输出。
相反,如果 Ant 任务以过高的级别记录消息,则要抑制这些消息将需要构建在更高的日志级别运行,例如QUIET.然而,这可能会导致其他所需的输出被抑制。
为了解决这个问题,Gradle 允许用户微调 Ant 日志记录并控制消息优先级到 Gradle 日志级别的映射。这是通过使用AntBuilder.setLifecycleLogLevel(java.lang.String)LIFECYCLE方法设置应映射到默认 Gradle日志级别的优先级来完成的。设置此值后,以配置的优先级或以上优先级记录的任何 Ant 消息将至少在 处记录。低于此优先级记录的任何 Ant 消息最多将被记录。LIFECYCLEINFO
例如,以下更改映射,以便在日志级别公开Ant INFOLIFECYCLE优先级消息。
ant.lifecycleLogLevel = AntBuilder.AntMessagePriority.INFO
tasks.register("hello") {
doLast {
ant.withGroovyBuilder {
"echo"("level" to "info", "message" to "hello from info priority!")
}
}
}ant.lifecycleLogLevel = "INFO"
tasks.register('hello') {
doLast {
ant.echo(level: "info", message: "hello from info priority!")
}
}gradle hello> gradle hello > Task :hello [ant:echo] hello from info priority! BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
另一方面,如果lifecycleLogLevel被设置为ERROR ,则以WARN优先级记录的 Ant 消息将不再在WARN日志级别记录。它们现在将被记录在该INFO级别,并且默认情况下将被抑制。
应用程序编程接口
Ant 集成由AntBuilder提供。
编写 JVM 构建
构建 Java 和 JVM 项目
Gradle 使用约定优于配置的方法来构建基于 JVM 的项目,该项目借用了 Apache Maven 的多种约定。特别是,它对源文件和资源使用相同的默认目录结构,并且可以与 Maven 兼容的存储库配合使用。
我们将在本章中详细介绍 Java 项目,但大多数主题也适用于其他受支持的 JVM 语言,例如Kotlin、Groovy和Scala。如果您没有太多使用 Gradle 构建基于 JVM 的项目的经验,请查看Java 示例,获取有关如何构建各种类型的基本 Java 项目的分步说明。
|
笔记
|
本节中的示例使用 Java 库插件。然而,所描述的功能是所有 JVM 插件共享的。不同插件的具体信息可在其专用文档中找到。 |
|
提示
|
您可以探索许多Java、Groovy、Scala和Kotlin 的实践示例。 |
介绍
plugins {
`java-library`
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
version = "1.2.1"plugins {
id 'java-library'
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
version = '1.2.1'通过应用 Java 库插件,您可以获得一系列功能:
-
编译src/main/java
compileJava下所有 Java 源文件的任务 -
src/test/java
compileTestJava下源文件的任务 -
从src/test/java
test运行测试的任务 -
将src/main/resources中已编译的类和资源
jar打包到名为<project>-<version>.jar的单个 JAR 中的任务main -
为类
javadoc生成 Javadoc 的任务main
这不足以构建任何重要的 Java 项目——至少,您可能会有一些文件依赖项。但这意味着您的构建脚本只需要特定于您的项目的信息。
|
笔记
|
尽管示例中的属性是可选的,但我们建议您在项目中指定它们。配置工具链可以防止使用不同 Java 版本构建的项目出现问题。版本字符串对于跟踪项目的进度非常重要。默认情况下,项目版本也用于存档名称。 |
Java Library Plugin 还将上述任务集成到标准Base Plugin 生命周期任务中:
-
jar附于assemble -
test附于check
本章的其余部分解释了根据您的要求定制构建的不同途径。稍后您还将看到如何调整库、应用程序、Web 应用程序和企业应用程序的构建。
通过源集声明您的源文件
Gradle 的 Java 支持首先引入了构建基于源代码的项目的新概念:源集。主要思想是源文件和资源通常按类型进行逻辑分组,例如应用程序代码、单元测试和集成测试。每个逻辑组通常都有自己的文件依赖项、类路径等集。值得注意的是,构成源集的文件不必位于同一目录中!
源集是一个强大的概念,它将编译的几个方面联系在一起:
-
源文件及其所在位置
-
编译类路径,包括任何必需的依赖项(通过 Gradle配置)
-
编译后的类文件放置的位置
您可以在此图中看到它们之间的相互关系:

阴影框表示源集本身的属性。最重要的是,Java 库插件会自动为您或插件定义的每个源集创建一个编译任务(已命名)以及多个依赖项配置。compileSourceSetJava
main集大多数语言插件(包括 Java)都会自动创建一个名为 的源集main,用于项目的生产代码。该源集的特殊之处在于它的名称不包含在配置和任务的名称中,因此您只有任务compileJava和compileOnly配置,implementation而不是分别有和。compileMainJavamainCompileOnlymainImplementation
Java 项目通常包括源文件以外的资源,例如属性文件,这些资源可能需要处理(例如通过替换文件中的标记)并打包到最终的 JAR 中。 Java 库插件通过自动为每个定义的调用的源集(或源集)创建专用任务来处理此问题。下图显示了源集如何适应此任务:processSourceSetResourcesprocessResourcesmain

与之前一样,阴影框表示源集的属性,在本例中包括资源文件的位置及其复制到的位置。
除了main源集之外,Java 库插件还定义了test代表项目测试的源集。该源集由test运行测试的任务使用。您可以在Java 测试章节中了解有关此任务和相关主题的更多信息。
项目通常使用此源集进行单元测试,但如果您愿意,您也可以将其用于集成、验收和其他类型的测试。另一种方法是为每个其他测试类型定义一个新的源集,这通常是出于以下一个或两个原因:
-
为了美观和可管理性,您希望将测试彼此分开
-
不同的测试类型需要不同的编译或运行时类路径或设置中的其他差异
您可以在 Java 测试章节中看到此方法的示例,该示例向您展示了如何在项目中设置集成测试。
您将了解有关源集及其提供的功能的更多信息:
源集配置
创建源集时,它还会创建许多如上所述的配置。在源集首次创建这些配置之前,构建逻辑不应尝试创建或访问这些配置。
创建源集时,如果这些自动创建的配置之一已存在,Gradle 将发出弃用警告。如果现有配置的角色与源集分配的角色不同,则其角色将更改为正确的值,并且将发出另一个弃用警告。
下面的构建演示了这种不需要的行为。
configurations {
val myCodeCompileClasspath: Configuration by creating
}
sourceSets {
val myCode: SourceSet by creating
}configurations {
myCodeCompileClasspath
}
sourceSets {
myCode
}在这种情况下,会发出以下弃用警告:
When creating configurations during sourceSet custom setup, Gradle found that configuration customCompileClasspath already exists with permitted usage(s):
Consumable - this configuration can be selected by another project as a dependency
Resolvable - this configuration can be resolved by this project to a set of files
Declarable - this configuration can have dependencies added to it
Yet Gradle expected to create it with the usage(s):
Resolvable - this configuration can be resolved by this project to a set of files以下两个简单的最佳实践将避免此问题:
-
不要使用源集将使用的名称创建配置,例如以、
Api、Implementation、ApiElements、CompileOnly、CompileOnlyApi或RuntimeOnly结尾的名称。 (此列表并不详尽。)RuntimeClasspathRuntimeElements -
在任何自定义配置之前创建任何自定义源集。
请记住,任何时候您在容器内引用配置configurations(无论是否提供初始化操作),Gradle 都会创建该配置。有时,当使用 Groovy DSL 时,这种创建并不明显,如下面的示例所示,wheremyCustomConfiguration是在调用extendsFrom.
configurations {
myCustomConfiguration.extendsFrom(implementation)
}有关详细信息,请参阅不要预期配置创建。
管理您的依赖项
绝大多数 Java 项目都依赖于库,因此管理项目的依赖关系是构建 Java 项目的重要部分。依赖管理是一个很大的话题,所以我们在这里将重点关注 Java 项目的基础知识。如果您想深入了解细节,请查看依赖管理简介。
指定 Java 项目的依赖项只需要三部分信息:
-
您需要哪个依赖项,例如名称和版本
-
它需要什么,例如编译或运行
-
在哪里寻找它
前两个在dependencies {}块中指定,第三个在repositories {}块中指定。例如,要告诉 Gradle 您的项目需要 3.6.7 版本的Hibernate Core 来编译和运行您的生产代码,并且您想要从 Maven 中央存储库下载该库,您可以使用以下片段:
repositories {
mavenCentral()
}
dependencies {
implementation("org.hibernate:hibernate-core:3.6.7.Final")
}repositories {
mavenCentral()
}
dependencies {
implementation 'org.hibernate:hibernate-core:3.6.7.Final'
}这三个元素的 Gradle 术语如下:
-
存储库(例如:
mavenCentral())——在哪里查找您声明为依赖项的模块 -
配置(例如:
implementation)——命名的依赖项集合,为了特定目标(例如编译或运行模块)而分组在一起——一种更灵活的 Maven 范围形式 -
模块坐标(ex: ) — 依赖项的 ID,通常采用 ' <group> : <module> : <version>
org.hibernate:hibernate-core-3.6.7.Final'形式(或Maven 术语中的' <groupId> : <artifactId> : <version> ')
您可以在此处找到更全面的依赖管理术语表。
就配置而言,主要感兴趣的是:
-
compileOnly- 对于编译生产代码所必需的依赖项,但不应成为运行时类路径的一部分 -
implementation(取代compile) — 用于编译和运行时 -
runtimeOnly(取代runtime) — 仅在运行时使用,不用于编译 -
testCompileOnlycompileOnly- 与除了用于测试之外相同 -
testImplementation— 测试等效于implementation -
testRuntimeOnly— 测试等效于runtimeOnly
您可以在插件参考章节中了解有关这些内容以及它们之间如何相互关联的更多信息。
请注意,Java 库插件提供了两种额外的配置 -api和compileOnlyApi- 用于编译模块和依赖于它的任何模块所需的依赖项。
compile配置?Java 库插件历来使用compile编译和运行项目生产代码所需的依赖项配置。它现已被弃用,并且在使用时会发出警告,因为它不区分影响 Java 库项目公共 API 的依赖项和不影响的依赖项。您可以在构建 Java 库中详细了解这种区别的重要性。
我们在这里只触及了表面,因此我们建议您在熟悉了使用 Gradle 构建 Java 项目的基础知识后,再阅读专门的依赖关系管理章节。需要进一步阅读的一些常见场景包括:
-
将同级项目声明为依赖项
-
通过复合构建测试对第 3 方依赖项的修复(发布到 Maven Local 和从Maven Local消费的更好替代方案)
您会发现 Gradle 拥有丰富的 API 来处理依赖项——需要一些时间来掌握,但对于常见场景来说使用起来很简单。
编译你的代码
如果遵循以下约定,编译生产代码和测试代码会变得非常简单:
-
将您的生产源代码放在src/main/java目录下
-
将您的测试源代码放在src/test/java下
-
compileOnly在或配置中声明您的生产编译依赖项implementation(请参阅上一节) -
testCompileOnly在或testImplementation配置中声明您的测试编译依赖项 -
运行
compileJava生产代码和compileTestJava测试的任务
其他 JVM 语言插件(例如Groovy的插件)遵循相同的约定模式。我们建议您尽可能遵循这些约定,但并非必须这样做。有多种自定义选项,您将在接下来看到。
自定义文件和目录位置
想象一下,您有一个遗留项目,它使用src目录来存储生产代码,并使用 test来存储测试代码。传统的目录结构不起作用,因此您需要告诉 Gradle 在哪里可以找到源文件。您可以通过源集配置来完成此操作。
每个源集定义其源代码所在的位置,以及类文件的资源和输出目录。您可以使用以下语法覆盖约定值:
sourceSets {
main {
java {
setSrcDirs(listOf("src"))
}
}
test {
java {
setSrcDirs(listOf("test"))
}
}
}sourceSets {
main {
java {
srcDirs = ['src']
}
}
test {
java {
srcDirs = ['test']
}
}
}现在 Gradle 只会直接在src中搜索并测试相应的源代码。如果您不想覆盖约定,而只是想添加一个额外的源目录(也许包含一些您想要单独保留的第三方源代码),该怎么办?语法类似:
sourceSets {
main {
java {
srcDir("thirdParty/src/main/java")
}
}
}sourceSets {
main {
java {
srcDir 'thirdParty/src/main/java'
}
}
}至关重要的是,我们使用此处的方法 srcDir()附加目录路径,而设置srcDirs属性会替换任何现有值。这是 Gradle 中的常见约定:设置属性会替换值,而相应的方法会附加值。
您可以在SourceSet和SourceDirectorySet的 DSL 参考中查看源集上可用的所有属性和方法。请注意,srcDirs和srcDir()均处于打开状态SourceDirectorySet。
更改编译器选项
大多数编译器选项都可以通过相应的任务访问,例如compileJava和compileTestJava。这些任务的类型为JavaCompile,因此请阅读任务参考以获取最新且全面的选项列表。
例如,如果您想为编译器使用单独的 JVM 进程并防止编译失败而导致构建失败,则可以使用以下配置:
tasks.compileJava {
options.isIncremental = true
options.isFork = true
options.isFailOnError = false
}compileJava {
options.incremental = true
options.fork = true
options.failOnError = false
}这也是您可以更改编译器的详细程度、禁用字节代码中的调试输出以及配置编译器可以找到注释处理器的位置的方法。
针对特定 Java 版本
默认情况下,Gradle 会将 Java 代码编译到运行 Gradle 的 JVM 的语言级别。如果编译时需要针对特定版本的 Java,Gradle 提供了多个选项:
使用工具链
当使用特定工具链编译Java代码时,实际编译是由指定Java版本的编译器执行的。编译器提供对所请求的 Java 语言版本的语言功能和 JDK API 的访问。
在最简单的情况下,可以使用扩展为项目配置工具链java。这样,不仅编译可以从中受益,其他任务(例如test和 )javadoc也将始终使用相同的工具链。
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}您可以在Java 工具链指南中了解更多相关信息。
使用Java发行版
Gradle 支持使用 Java 10 中的发布标志。它可以在编译任务上进行如下配置。
tasks.compileJava {
options.release = 7
}compileJava {
options.release = 7
}发布标志提供类似于工具链的保证。它验证 Java 源代码没有使用后续 Java 版本中引入的语言功能,并且代码不会访问较新的 JDK 中的 API。编译器生成的字节码也与请求的 Java 版本相对应,这意味着编译后的代码无法在较旧的 JVM 上执行。
Java 编译器选项是在 Java 9 中引入的。但是,由于Java 9 中的错误release,只能从 Java 10 开始在 Gradle 中使用此选项。
使用 Java 兼容性选项
和sourceCompatibility选项targetCompatibility对应于 Java 编译器选项-source和-target。它们被认为是针对特定 Java 版本的遗留机制。但是,这些选项不能防止使用后续 Java 版本中引入的 API。
sourceCompatibility-
定义源文件中使用的 Java 语言版本。
targetCompatibility-
定义代码应运行的最低 JVM 版本,即它确定编译器生成的字节码的版本。
可以使用具有相同名称的属性为每个JavaCompile任务设置这些选项,也可以在所有编译任务的扩展上设置这些选项。java { }
针对 Java 6 和 Java 7
Gradle 本身只能在 Java 版本 8 或更高版本的 JVM 上运行。但是,Gradle 仍然支持 Java 6 和 Java 7 的编译、测试、生成 Javadoc 和执行应用程序。不支持 Java 5 及更低版本。
|
笔记
|
如果使用 Java 10+,利用该release标志可能是一个更简单的解决方案,请参见上文。
|
要使用Java 6或Java 7,需要配置以下任务:
-
JavaCompile分叉并使用正确的 Java home 的任务 -
Javadoc使用正确的javadoc可执行文件的任务 -
Test以及JavaExec使用正确的java可执行文件的任务。
通过使用 Java 工具链,可以按如下方式完成此操作:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(7)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(7)
}
}单独编译独立源
大多数项目至少有两组独立的源:生产代码和测试代码。 Gradle 已经将此场景纳入其 Java 约定的一部分,但如果您有其他源集怎么办?最常见的场景之一是当您进行某种形式的单独集成测试时。在这种情况下,自定义源集可能正是您所需要的。
您可以在Java 测试章节中看到设置集成测试的完整示例。您可以以相同的方式设置履行不同角色的其他源集。那么问题就变成了:什么时候应该定义自定义源集?
要回答这个问题,请考虑来源是否:
-
需要使用唯一的类路径进行编译
-
生成处理方式与
main和不同的test类 -
成为项目的自然组成部分
如果您对 3 个以及其他任何一个的答案都是肯定的,那么自定义源集可能是正确的方法。例如,集成测试通常是项目的一部分,因为它们测试main.此外,它们通常具有独立于test源集的自己的依赖项,或者需要与自定义Test任务一起运行。
其他常见场景不太明确,可能有更好的解决方案。例如:
-
单独的 API 和实现 JAR - 将它们作为单独的项目可能是有意义的,特别是如果您已经有一个多项目构建
-
生成的源 - 如果生成的源应使用生产代码进行编译,请将其路径添加到
main源集,并确保任务compileJava依赖于生成源的任务
如果您不确定是否创建自定义源集,请继续创建。它应该是简单的,如果不是,那么它可能不是适合这项工作的工具。
管理资源
许多 Java 项目都使用源文件之外的资源,例如图像、配置文件和本地化数据。有时,这些文件只需原样打包,有时需要作为模板文件或以其他方式处理。无论哪种方式,Java 库插件都会为每个源集添加一个特定的复制任务,以处理其关联资源。
该任务的名称遵循- 或源集 -的约定,并且它将自动将src/[sourceSet]/resources中的任何文件复制到将包含在生产 JAR 中的目录。该目标目录也将包含在测试的运行时类路径中。processSourceSetResourcesprocessResourcesmain
由于processResources是该任务的一个实例,因此您可以执行“使用文件”ProcessResources一章中描述的任何处理。
Java 属性文件和可重现的构建
您可以通过WriteProperties任务轻松创建 Java 属性文件,该任务修复了一个众所周知的问题,该问题可能会降低增量构建Properties.store()的有用性。
用于写入属性文件的标准 Java API 每次都会生成一个唯一的文件,即使使用相同的属性和值也是如此,因为它在注释中包含时间戳。如果没有任何属性发生更改, Gradle 的WriteProperties任务会逐字节生成完全相同的输出。这是通过对属性文件的生成方式进行一些调整来实现的:
-
输出中未添加时间戳注释
-
行分隔符与系统无关,但可以显式配置(默认为
'\n') -
属性按字母顺序排序
有时可能需要在不同的机器上以逐字节的方式重新创建存档。您希望确保从源代码构建工件会产生相同的结果,逐字节生成,无论它是何时何地构建的。这对于像 reproducible-builds.org 这样的项目是必要的。
这些调整不仅可以带来更好的增量构建集成,而且还有助于可重复的构建。从本质上讲,可重现的构建保证您将从构建执行中看到相同的结果 - 包括测试结果和生产二进制文件 - 无论何时或在什么系统上运行它。
运行测试
除了在src/test/java中提供单元测试的自动编译之外,Java 库插件还原生支持运行使用 JUnit 3、4 和 5(Gradle 4.6 中提供了JUnit 5 支持)和 TestNG 的测试。你得到:
-
使用源集的Test
test类型的自动任务test -
包含所有
Test运行任务的结果的 HTML 测试报告 -
轻松过滤要运行的测试
-
对测试运行方式的细粒度控制
-
有机会创建您自己的测试执行和测试报告任务
您不会Test为声明的每个源集获得任务,因为并非每个源集都代表测试!这就是为什么您通常需要为集成和验收测试等任务创建自己的Test任务(如果它们无法包含在test源集中)。
由于测试涉及很多内容,因此该主题有其自己的章节,我们将在其中查看:
-
测试如何运行
-
如何通过过滤运行测试子集
-
Gradle 如何发现测试
-
如何配置测试报告并添加您自己的报告任务
-
如何利用特定的 JUnit 和 TestNG 功能
您还可以在Test的 DSL 参考中了解有关配置测试的更多信息。
包装出版
如何打包和发布 Java 项目取决于项目的类型。库、应用程序、Web 应用程序和企业应用程序都有不同的要求。在本节中,我们将重点关注 Java 库插件提供的基本框架。
默认情况下,Java Library Plugin 提供jar将所有已编译的生产类和资源打包到单个 JAR 中的任务。这个 JAR 也是由任务自动构建的assemble。此外,如果需要,可以配置该插件来提供打包 Javadoc 和源代码的javadocJar任务。sourcesJar如果使用发布插件,这些任务将在发布过程中自动运行或可以直接调用。
java {
withJavadocJar()
withSourcesJar()
}java {
withJavadocJar()
withSourcesJar()
}如果您想创建一个“uber”(又名“fat”)JAR,那么您可以使用如下任务定义:
plugins {
java
}
version = "1.0.0"
repositories {
mavenCentral()
}
dependencies {
implementation("commons-io:commons-io:2.6")
}
tasks.register<Jar>("uberJar") {
archiveClassifier = "uber"
from(sourceSets.main.get().output)
dependsOn(configurations.runtimeClasspath)
from({
configurations.runtimeClasspath.get().filter { it.name.endsWith("jar") }.map { zipTree(it) }
})
}plugins {
id 'java'
}
version = '1.0.0'
repositories {
mavenCentral()
}
dependencies {
implementation 'commons-io:commons-io:2.6'
}
tasks.register('uberJar', Jar) {
archiveClassifier = 'uber'
from sourceSets.main.output
dependsOn configurations.runtimeClasspath
from {
configurations.runtimeClasspath.findAll { it.name.endsWith('jar') }.collect { zipTree(it) }
}
}有关可用配置选项的更多详细信息,请参阅Jar 。请注意,您需要使用archiveClassifier而不是archiveAppendix此处来正确发布 JAR。
您可以使用发布插件之一来发布由 Java 项目创建的 JAR:
修改 JAR 清单
Jar、War和任务的每个实例Ear都有一个manifest属性,允许您自定义进入相应存档的MANIFEST.MF文件。以下示例演示了如何在 JAR 清单中设置属性:
tasks.jar {
manifest {
attributes(
"Implementation-Title" to "Gradle",
"Implementation-Version" to archiveVersion
)
}
}jar {
manifest {
attributes("Implementation-Title": "Gradle",
"Implementation-Version": archiveVersion)
}
}请参阅清单以了解它提供的配置选项。
您还可以创建 的独立实例Manifest。这样做的原因之一是在 JAR 之间共享清单信息。以下示例演示了如何在 JAR 之间共享公共属性:
val sharedManifest = java.manifest {
attributes (
"Implementation-Title" to "Gradle",
"Implementation-Version" to version
)
}
tasks.register<Jar>("fooJar") {
manifest = java.manifest {
from(sharedManifest)
}
}def sharedManifest = java.manifest {
attributes("Implementation-Title": "Gradle",
"Implementation-Version": version)
}
tasks.register('fooJar', Jar) {
manifest = java.manifest {
from sharedManifest
}
}您可以使用的另一个选项是将清单合并到单个Manifest对象中。这些源清单可以采用文本或其他对象的形式Manifest。在以下示例中,源清单都是文本文件,除了sharedManifest,它是Manifest上一个示例中的对象:
tasks.register<Jar>("barJar") {
manifest {
attributes("key1" to "value1")
from(sharedManifest, "src/config/basemanifest.txt")
from(listOf("src/config/javabasemanifest.txt", "src/config/libbasemanifest.txt")) {
eachEntry(Action<ManifestMergeDetails> {
if (baseValue != mergeValue) {
value = baseValue
}
if (key == "foo") {
exclude()
}
})
}
}
}tasks.register('barJar', Jar) {
manifest {
attributes key1: 'value1'
from sharedManifest, 'src/config/basemanifest.txt'
from(['src/config/javabasemanifest.txt', 'src/config/libbasemanifest.txt']) {
eachEntry { details ->
if (details.baseValue != details.mergeValue) {
details.value = baseValue
}
if (details.key == 'foo') {
details.exclude()
}
}
}
}
}清单按照在语句中声明的顺序合并from。如果基本清单和合并清单都定义了同一键的值,则默认情况下合并清单获胜。您可以通过添加操作来完全自定义合并行为,eachEntry在这些操作中您可以访问生成清单的每个条目的ManifestMergeDetails实例。请注意,合并是延迟完成的,无论是在生成 JAR 时还是在调用Manifest.writeTo()或时。Manifest.getEffectiveManifest()
说到writeTo(),您可以随时使用它轻松地将清单写入磁盘,如下所示:
tasks.jar { manifest.writeTo(layout.buildDirectory.file("mymanifest.mf")) }tasks.named('jar') { manifest.writeTo(layout.buildDirectory.file('mymanifest.mf')) }生成API文档
Java 库插件提供了Javadocjavadoc类型的任务,它将为您的所有生产代码(即源集中的任何源)生成标准 Javadoc 。该任务支持Javadoc 参考文档中描述的核心 Javadoc 和标准 doclet 选项。有关这些选项的完整列表,请参阅CoreJavadocOptions和StandardJavadocDocletOptions 。main
作为您可以执行的操作的示例,假设您想要在 Javadoc 注释中使用 Asciidoc 语法。为此,您需要将 Asciidoclet 添加到 Javadoc 的 doclet 路径中。这是一个执行此操作的示例:
val asciidoclet by configurations.creating
dependencies {
asciidoclet("org.asciidoctor:asciidoclet:1.+")
}
tasks.register("configureJavadoc") {
doLast {
tasks.javadoc {
options.doclet = "org.asciidoctor.Asciidoclet"
options.docletpath = asciidoclet.files.toList()
}
}
}
tasks.javadoc {
dependsOn("configureJavadoc")
}configurations {
asciidoclet
}
dependencies {
asciidoclet 'org.asciidoctor:asciidoclet:1.+'
}
tasks.register('configureJavadoc') {
doLast {
javadoc {
options.doclet = 'org.asciidoctor.Asciidoclet'
options.docletpath = configurations.asciidoclet.files.toList()
}
}
}
javadoc {
dependsOn configureJavadoc
}您不必为此创建配置,但这是一种处理特定目的所需的依赖关系的优雅方法。
您可能还想创建自己的 Javadoc 任务,例如为测试生成 API 文档:
tasks.register<Javadoc>("testJavadoc") {
source = sourceSets.test.get().allJava
}tasks.register('testJavadoc', Javadoc) {
source = sourceSets.test.allJava
}这些只是您可能遇到的两个重要但常见的自定义。
清理构建
Java Library Pluginclean通过应用Base Plugin将任务添加到您的项目中。此任务只是删除layout.buildDirectory目录中的所有内容,因此您应该始终将构建生成的文件放在那里。该任务是删除dir的一个实例,您可以通过设置其属性来更改它删除的目录。
构建 JVM 组件
所有特定的 JVM 插件都构建在Java 插件之上。上面的示例仅说明了该基本插件提供的概念并与所有 JVM 插件共享。
请继续阅读以了解哪些插件适合哪种项目类型,因为建议选择特定的插件而不是直接应用 Java 插件。
构建 Java 库
库项目的独特之处在于它们被其他 Java 项目使用(或“消耗”)。这意味着随 JAR 文件发布的依赖元数据(通常以 Maven POM 的形式)至关重要。特别是,您的库的使用者应该能够区分两种不同类型的依赖项:仅编译您的库所需的依赖项和编译使用者也需要的依赖项。
Gradle 通过Java Library Plugin管理这种区别,除了本章介绍的实现之外,它还引入了api配置。如果依赖项中的类型出现在库的公共类的公共字段或方法中,则该依赖项将通过库的公共 API 公开,因此应将其添加到api配置中。否则,依赖项是内部实现细节,应添加到实现中。
如果您不确定 API 和实现依赖项之间的区别,Java 库插件一章有详细的解释。此外,您还可以探索构建 Java 库的基本实用示例。
构建 Java 应用程序
打包为 JAR 的 Java 应用程序无法从命令行或桌面环境轻松启动。应用程序插件通过创建一个包含生产 JAR、其依赖项以及类 Unix 和 Windows 系统启动脚本的发行版来解决命令行方面的问题。
有关更多详细信息,请参阅插件的章节,但以下是您所获得内容的快速摘要:
-
assemble创建应用程序的 ZIP 和 TAR 发行版,其中包含运行该应用程序所需的所有内容 -
run从构建启动应用程序的任务(为了方便测试) -
用于启动应用程序的 Shell 和 Windows 批处理脚本
您可以在相应的示例中查看构建 Java 应用程序的基本示例。
构建 Java Web 应用程序
Java Web 应用程序可以通过多种方式打包和部署,具体取决于您使用的技术。例如,您可以将Spring Boot与 fat JAR 或在Netty上运行的基于Reactive的系统结合使用。无论您使用什么技术,Gradle 及其庞大的插件社区都将满足您的需求。不过,Core Gradle 仅直接支持部署为 WAR 文件的传统基于 Servlet 的 Web 应用程序。
该支持来自War Plugin,它会自动应用 Java 插件并添加一个额外的打包步骤,该步骤执行以下操作:
-
将静态资源从src/main/webapp复制到 WAR 的根目录中
-
将编译后的生产类复制到WAR 的WEB-INF/classes子目录中
-
将库依赖项复制到WAR 的WEB-INF/lib子目录中
这是由war任务完成的,该任务有效地替换了该jar任务(尽管该任务仍然存在)并附加到assemble生命周期任务。有关更多详细信息和配置选项,请参阅插件的章节。
没有直接从构建运行 Web 应用程序的核心支持,但我们建议您尝试Gretty社区插件,它提供了嵌入式 Servlet 容器。
构建 Java EE 应用程序
Java 企业系统多年来发生了很大变化,但如果您仍在部署到 JEE 应用程序服务器,则可以使用Ear Plugin。这添加了构建 EAR 文件的约定和任务。该插件的章节有更多详细信息。
构建 Java 平台
Java 平台代表一组依赖声明和约束,它们形成了一个应用于消费项目的内聚单元。该平台没有来源,也没有自己的工件。它在 Maven 世界中映射到BOM。
该支持通过Java 平台插件提供,该插件设置不同的配置和发布组件。
|
笔记
|
此插件是例外,因为它不应用 Java 插件。 |
启用 Java 预览功能
|
警告
|
使用 Java 预览功能很可能会使您的代码与没有功能预览的编译代码不兼容。因此,我们强烈建议您不要发布使用预览功能编译的库,并将功能预览限制在玩具项目中。 |
要启用编译、测试执行和运行时的 Java预览功能,您可以使用以下 DSL 片段:
tasks.withType<JavaCompile>().configureEach {
options.compilerArgs.add("--enable-preview")
}
tasks.withType<Test>().configureEach {
jvmArgs("--enable-preview")
}
tasks.withType<JavaExec>().configureEach {
jvmArgs("--enable-preview")
}tasks.withType(JavaCompile).configureEach {
options.compilerArgs += "--enable-preview"
}
tasks.withType(Test).configureEach {
jvmArgs += "--enable-preview"
}
tasks.withType(JavaExec).configureEach {
jvmArgs += "--enable-preview"
}构建其他 JVM 语言项目
如果您想利用 JVM 的多语言功能,此处描述的大部分内容仍然适用。
语言之间的编译依赖
java这些插件在 Groovy/Scala 编译和 Java 编译(源集文件夹中的源代码)之间创建依赖关系。您可以通过调整所涉及的编译任务的类路径来更改此默认行为,如下例所示:
tasks.named<AbstractCompile>("compileGroovy") {
// Groovy only needs the declared dependencies
// (and not longer the output of compileJava)
classpath = sourceSets.main.get().compileClasspath
}
tasks.named<AbstractCompile>("compileJava") {
// Java also depends on the result of Groovy compilation
// (which automatically makes it depend of compileGroovy)
classpath += files(sourceSets.main.get().groovy.classesDirectory)
}tasks.named('compileGroovy') {
// Groovy only needs the declared dependencies
// (and not longer the output of compileJava)
classpath = sourceSets.main.compileClasspath
}
tasks.named('compileJava') {
// Java also depends on the result of Groovy compilation
// (which automatically makes it depend of compileGroovy)
classpath += files(sourceSets.main.groovy.classesDirectory)
}-
通过将
compileGroovy类路径设置为 onlysourceSets.main.compileClasspath,我们可以有效地消除先前对compileJava通过将类路径也考虑在内而声明的依赖关系sourceSets.main.java.classesDirectory -
通过添加
sourceSets.main.groovy.classesDirectory到,我们有效地声明了对任务compileJavaclasspath的依赖compileGroovy
所有这一切都可以通过使用目录属性来实现。
Java 和 JVM 项目中的测试
JVM 测试是一个丰富的主题。有许多不同的测试库和框架,以及许多不同类型的测试。所有这些都需要成为构建的一部分,无论它们是频繁执行还是不频繁执行。本章致力于解释 Gradle 如何处理构建之间和构建内部的不同需求,并重点介绍它如何与两个最常见的测试框架:JUnit和TestNG集成。
它解释说:
但首先,让我们看一下 Gradle 中 JVM 测试的基础知识。
|
笔记
|
通过孵化JVM 测试套件插件 可以使用新的配置 DSL,用于对测试执行阶段进行建模。 |
基础
所有 JVM 测试都围绕一个任务类型:测试。这将使用任何受支持的测试库(JUnit、JUnit Platform 或 TestNG)运行测试用例集合,并整理结果。然后,您可以通过TestReport任务类型的实例将这些结果转换为报告。
为了进行操作,Test任务类型只需要两条信息:
-
在哪里可以找到已编译的测试类(属性:Test.getTestClassesDirs())
-
执行类路径,应包括被测试的类以及您正在使用的测试库(属性:Test.getClasspath())
当您使用 JVM 语言插件(例如Java 插件)时,您将自动获得以下内容:
-
test用于单元测试的专用源集 -
运行这些单元测试的任务
test类型Test
JVM 语言插件使用源集通过适当的执行类路径和包含已编译测试类的目录来配置任务。此外,他们还将test任务附加到check 生命周期任务中。
还值得记住的是,test源集会自动创建相应的依赖项配置(其中最有用的是testImplementation和testRuntimeOnly),插件将其绑定到test任务的类路径中。
在大多数情况下,您所需要做的就是配置适当的编译和运行时依赖项,并向test任务添加任何必要的配置。以下示例显示了一个使用 JUnit Platform 并将测试 JVM 的最大堆大小更改为 1 GB 的简单设置:
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
tasks.named<Test>("test") {
useJUnitPlatform()
maxHeapSize = "1G"
testLogging {
events("passed")
}
}dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter:5.7.1'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
tasks.named('test', Test) {
useJUnitPlatform()
maxHeapSize = '1G'
testLogging {
events "passed"
}
}测试任务有许多通用配置选项以及几个特定于框架的选项,您可以在JUnitOptions、JUnitPlatformOptions和TestNGOptions中找到这些选项的描述。我们将在本章的其余部分介绍其中的大量内容。
如果您想使用自己的测试类集来设置自己的Test任务,那么最简单的方法是创建自己的源集和Test任务实例,如配置集成测试中所示。
测试执行
Gradle 在单独的(“分叉的”)JVM 中执行测试,与主构建过程隔离。这可以防止构建过程中的类路径污染和过多的内存消耗。它还允许您使用与构建所使用的不同的 JVM 参数来运行测试。
您可以通过任务的多个属性来控制测试流程的启动方式Test,包括以下属性:
maxParallelForks— 默认:1-
您可以通过将此属性设置为大于 1 的值来并行运行测试。这可能会使您的测试套件完成得更快,特别是当您在多核 CPU 上运行它们时。使用并行测试执行时,请确保您的测试彼此正确隔离。与文件系统交互的测试特别容易发生冲突,导致间歇性测试失败。
您的测试可以通过使用该属性的值来区分并行测试进程
org.gradle.test.worker,该属性对于每个进程都是唯一的。您可以将其用于任何您想要的地方,但它对于文件名和其他资源标识符特别有用,可以防止我们刚才提到的那种冲突。 forkEvery— 默认值:0(无最大值)-
此属性指定 Gradle 在释放测试进程并创建新测试进程之前应在测试进程上运行的测试类的最大数量。这主要用作管理泄漏测试或具有无法在测试之间清除或重置的静态状态的框架的方法。
警告:较低的值(0 以外)可能会严重损害测试的性能
ignoreFailures— 默认值:假-
如果此属性为
true,Gradle 将在测试完成后继续项目的构建,即使其中一些测试失败。请注意,默认情况下,Test任务始终执行它检测到的每个测试,无论此设置如何。 failFast—(自 Gradle 4.6 起)默认值: false-
true如果您希望构建失败并在其中一个测试失败时立即完成,请将此设置为。当您有一个长时间运行的测试套件时,这可以节省大量时间,并且在持续集成服务器上运行构建时特别有用。当构建在所有测试运行之前失败时,测试报告仅包含已完成的测试的结果(无论成功与否)。您还可以使用
--fail-fast命令行选项启用此行为,或使用 分别禁用它--no-fail-fast。 testLogging— 默认值:未设置-
此属性代表一组选项,用于控制记录哪些测试事件以及记录的级别。您还可以通过此属性配置其他日志记录行为。有关更多详细信息,请参阅TestLoggingContainer 。
dryRun— 默认值:假-
如果此属性为
true,Gradle 将模拟测试的执行,而不实际运行它们。这仍然会生成报告,以便检查选择了哪些测试。这可用于验证您的测试过滤配置是否正确,而无需实际运行测试。您还可以使用
--test-dry-run命令行选项启用此行为,或使用 分别禁用它--no-test-dry-run。
有关所有可用配置选项的详细信息,请参阅测试。
如果配置不正确,测试进程可能会意外退出。例如,如果 Java 可执行文件不存在或提供了无效的 JVM 参数,则测试过程将无法启动。同样,如果测试对测试过程进行编程更改,这也可能导致意外失败。
例如,如果SecurityManager在测试中修改 a ,则可能会出现问题,因为 Gradle 的内部消息传递依赖于反射和套接字通信,如果安全管理器上的权限发生更改,则可能会中断。在这种特殊情况下,您应该SecurityManager在测试后恢复原始状态,以便gradle测试工作进程可以继续运行。
测试过滤
运行测试套件的子集是一种常见的要求,例如当您修复错误或开发新的测试用例时。 Gradle 提供了两种机制来执行此操作:
-
过滤(首选)
-
测试包含/排除
过滤取代了包含/排除机制,但您仍然可能会在野外遇到后者。
通过 Gradle 的测试过滤,您可以根据以下条件选择要运行的测试:
-
完全限定的类名或完全限定的方法名称,例如
org.gradle.SomeTest,org.gradle.SomeTest.someMethod -
简单的类名或方法名,如果模式以大写字母开头,例如
SomeTest,SomeTest.someMethod(自 Gradle 4.7 起) -
'*' 通配符匹配
您可以在构建脚本中或通过--tests命令行选项启用过滤。以下是每次构建运行时应用的一些过滤器的示例:
tasks.test {
filter {
//include specific method in any of the tests
includeTestsMatching("*UiCheck")
//include all tests from package
includeTestsMatching("org.gradle.internal.*")
//include all integration tests
includeTestsMatching("*IntegTest")
}
}test {
filter {
//include specific method in any of the tests
includeTestsMatching "*UiCheck"
//include all tests from package
includeTestsMatching "org.gradle.internal.*"
//include all integration tests
includeTestsMatching "*IntegTest"
}
}有关在构建脚本中声明过滤器的更多详细信息和示例,请参阅TestFilter参考。
命令行选项对于执行单个测试方法特别有用。当您使用 时--tests,请注意构建脚本中声明的包含内容仍然受到尊重。还可以提供多个--tests选项,所有模式都将生效。以下部分提供了几个使用命令行选项的示例。
|
笔记
|
并非所有测试框架都能很好地进行过滤。一些先进的综合测试可能不完全兼容。然而,绝大多数测试和用例都可以与 Gradle 的过滤机制完美配合。 |
以下两节介绍简单类/方法名称和完全限定名称的具体情况。
简单的名字模式
从 4.7 开始,Gradle 将以大写字母开头的模式视为简单的类名,或类名 + 方法名。例如,以下命令行运行测试用例中的所有测试或仅运行其中一个测试SomeTestClass,无论它位于哪个包中:
# Executes all tests in SomeTestClass
gradle test --tests SomeTestClass
# Executes a single specified test in SomeTestClass
gradle test --tests SomeTestClass.someSpecificMethod
gradle test --tests SomeTestClass.*someMethod*完全限定名称模式
在 4.7 之前,或者如果模式不以大写字母开头,Gradle 会将该模式视为完全限定。因此,如果您想使用测试类名称而不考虑其包,则可以使用--tests *.SomeTestClass.这里还有一些例子:
# specific class
gradle test --tests org.gradle.SomeTestClass
# specific class and method
gradle test --tests org.gradle.SomeTestClass.someSpecificMethod
# method name containing spaces
gradle test --tests "org.gradle.SomeTestClass.some method containing spaces"
# all classes at specific package (recursively)
gradle test --tests 'all.in.specific.package*'
# specific method at specific package (recursively)
gradle test --tests 'all.in.specific.package*.someSpecificMethod'
gradle test --tests '*IntegTest'
gradle test --tests '*IntegTest*ui*'
gradle test --tests '*ParameterizedTest.foo*'
# the second iteration of a parameterized test
gradle test --tests '*ParameterizedTest.*[2]'注意通配符‘*’对‘.’没有特殊的理解包分隔符。它纯粹基于文本。因此--tests *.SomeTestClass将匹配任何包,无论其“深度”如何。
您还可以将在命令行定义的过滤器与连续构建结合起来,以便在每次更改生产或测试源文件后立即重新执行测试子集。每当更改触发测试运行时,以下代码都会执行“com.mypackage.foo”包或子包中的所有测试:
gradle test --continuous --tests "com.mypackage.foo.*"测试报告
该Test任务默认生成以下结果:
-
HTML 测试报告
-
XML 测试结果的格式与 Ant JUnit 报告任务兼容 - 许多其他工具(例如 CI 服务器)都支持这种格式
-
任务使用结果的高效二进制格式
Test来生成其他格式
在大多数情况下,您将使用标准 HTML 报告,该报告自动包含所有任务的结果Test,甚至是您自己明确添加到构建中的任务的结果。例如,如果您添加Test集成测试任务,则报告将包含单元测试和集成测试的结果(如果这两个任务都运行)。
|
笔记
|
要聚合多个子项目的测试结果,请参阅测试报告聚合插件。 |
与许多测试配置选项不同,有几个项目级约定属性会影响测试报告。例如,您可以更改测试结果和报告的目的地,如下所示:
reporting.baseDir = file("my-reports")
java.testResultsDir = layout.buildDirectory.dir("my-test-results")
tasks.register("showDirs") {
val rootDir = project.rootDir
val reportsDir = project.reporting.baseDirectory
val testResultsDir = project.java.testResultsDir
doLast {
logger.quiet(rootDir.toPath().relativize(reportsDir.get().asFile.toPath()).toString())
logger.quiet(rootDir.toPath().relativize(testResultsDir.get().asFile.toPath()).toString())
}
}reporting.baseDir = "my-reports"
java.testResultsDir = layout.buildDirectory.dir("my-test-results")
tasks.register('showDirs') {
def rootDir = project.rootDir
def reportsDir = project.reporting.baseDirectory
def testResultsDir = project.java.testResultsDir
doLast {
logger.quiet(rootDir.toPath().relativize(reportsDir.get().asFile.toPath()).toString())
logger.quiet(rootDir.toPath().relativize(testResultsDir.get().asFile.toPath()).toString())
}
}gradle -q showDirs> gradle -q showDirs my-reports build/my-test-results
单击约定属性的链接了解更多详细信息。
还有一个独立的TestReport任务类型,可用于生成自定义 HTML 测试报告。它所需要的只是一个值destinationDir以及您想要包含在报告中的测试结果。以下是为所有子项目的单元测试生成合并报告的示例:
plugins {
id("java")
}
// Disable the test report for the individual test task
tasks.named<Test>("test") {
reports.html.required = false
}
// Share the test report data to be aggregated for the whole project
configurations.create("binaryTestResultsElements") {
isCanBeResolved = false
isCanBeConsumed = true
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named("test-report-data"))
}
outgoing.artifact(tasks.test.map { task -> task.getBinaryResultsDirectory().get() })
}val testReportData by configurations.creating {
isCanBeConsumed = false
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named("test-report-data"))
}
}
dependencies {
testReportData(project(":core"))
testReportData(project(":util"))
}
tasks.register<TestReport>("testReport") {
destinationDirectory = reporting.baseDirectory.dir("allTests")
// Use test results from testReportData configuration
testResults.from(testReportData)
}plugins {
id 'java'
}
// Disable the test report for the individual test task
test {
reports.html.required = false
}
// Share the test report data to be aggregated for the whole project
configurations {
binaryTestResultsElements {
canBeResolved = false
canBeConsumed = true
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named(DocsType, 'test-report-data'))
}
outgoing.artifact(test.binaryResultsDirectory)
}
}// A resolvable configuration to collect test reports data
configurations {
testReportData {
canBeConsumed = false
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named(DocsType, 'test-report-data'))
}
}
}
dependencies {
testReportData project(':core')
testReportData project(':util')
}
tasks.register('testReport', TestReport) {
destinationDirectory = reporting.baseDirectory.dir('allTests')
// Use test results from testReportData configuration
testResults.from(configurations.testReportData)
}在此示例中,我们使用约定插件myproject.java-conventions将项目的测试结果公开给 Gradle 的变体感知依赖管理引擎。
该插件声明一个可使用的binaryTestResultsElements配置,表示任务的二进制测试结果test。在聚合项目的构建文件中,我们声明配置testReportData并依赖于我们想要聚合结果的所有项目。 Gradle 会自动从每个子项目中选择二进制测试结果变体,而不是项目的 jar 文件。最后,我们添加一个testReport任务来聚合属性的测试结果testResultsDirs,其中包含从配置解析的所有二进制测试结果testReportData。
您应该注意,该TestReport类型组合了多个测试任务的结果,并且需要聚合各个测试类的结果。这意味着,如果给定的测试类由多个测试任务执行,则测试报告将包括该类的执行,但很难区分该类的各个执行及其输出。
通过 XML 文件将测试结果传递给 CI 服务器和其他工具
测试任务按照“JUnit XML”伪标准创建描述测试结果的 XML 文件。 CI 服务器和其他工具通常通过这些 XML 文件观察测试结果。
layout.buildDirectory.dir("test-results/$testTaskName")默认情况下,每个测试类都有一个文件写入文件。可以为项目的所有测试任务更改位置,也可以为每个测试任务单独更改位置。
java.testResultsDir = layout.buildDirectory.dir("junit-xml")java.testResultsDir = layout.buildDirectory.dir("junit-xml")通过上述配置,XML 文件将被写入到layout.buildDirectory.dir("junit-xml/$testTaskName").
tasks.test {
reports {
junitXml.outputLocation = layout.buildDirectory.dir("test-junit-xml")
}
}test {
reports {
junitXml.outputLocation = layout.buildDirectory.dir("test-junit-xml")
}
}通过上述配置,任务的 XML 文件test将被写入layout.buildDirectory.dir("test-results/test-junit-xml").其他测试任务的 XML 文件的位置将保持不变。
配置选项
通过配置JUnitXmlReport选项,还可以配置 XML 文件的内容以不同方式传达结果 。
tasks.test {
reports {
junitXml.apply {
isOutputPerTestCase = true // defaults to false
mergeReruns = true // defaults to false
}
}
}test {
reports {
junitXml {
outputPerTestCase = true // defaults to false
mergeReruns = true // defaults to false
}
}
}启用该outputPerTestCase选项后,会将测试用例期间生成的任何输出日志记录与结果中的该测试用例关联起来。当禁用(默认)时,输出与整个测试类相关联,而不是与生成日志输出的各个测试用例(例如测试方法)相关联。大多数观察 JUnit XML 文件的现代工具都支持“每个测试用例的输出”格式。
如果您使用 XML 文件来传达测试结果,建议启用此选项,因为它提供更有用的报告。
启用后mergeReruns,如果测试失败但随后重试并成功,则其失败将被记录为,<flakyFailure>而不是<failure>, 在 1 内<testcase>。这实际上是Apache Maven™ 的 Surefire 插件在启用重新运行时生成的报告。如果你的 CI 服务器能够理解这种格式,它将表明测试是不稳定的。如果没有,则表明测试成功,因为它将忽略该<flakyFailure>信息。如果测试不成功(即每次重试都失败),则无论您的工具是否理解此格式,都会指示为失败。
当mergeReruns禁用(默认)时,测试的每次执行将被列为单独的测试用例。
如果您使用构建扫描或Develocity,则无论此设置如何,都将检测到不稳定的测试。
当使用 CI 工具时,启用此选项特别有用,该工具使用 XML 测试结果来确定构建失败,而不是依赖 Gradle 来确定构建是否失败,并且如果所有失败的测试都通过,您希望不认为构建失败重试了。 Jenkins CI 服务器及其JUnit 插件就是这种情况。启用后mergeReruns,传递重试的测试将不再导致此 Jenkins 插件认为构建失败。但是,失败的测试执行将从 Jenkins 测试结果可视化中省略,因为它不考虑<flakyFailure>信息。除了 JUnit Jenkins 插件之外,还可以使用单独的Flaky Test Handler Jenkins 插件来可视化此类“片状故障”。
测试根据报告的名称进行分组和合并。当使用影响报告的测试名称的任何类型的测试参数化,或生成潜在动态测试名称的任何其他类型的机制时,应注意确保测试名称稳定并且不会发生不必要的更改。
启用该mergeReruns选项不会为测试执行添加任何重试/重新运行功能。重新运行可以通过测试执行框架(例如 JUnit 的@RepeatedTest)或通过单独的Test Retry Gradle 插件来启用。
测试检测
默认情况下,Gradle 将运行它检测到的所有测试,这是通过检查编译的测试类来实现的。根据所使用的测试框架,此检测使用不同的标准。
对于JUnit,Gradle 扫描 JUnit 3 和 4 测试类。如果一个类满足以下条件,则该类被视为 JUnit 测试:
-
最终继承自
TestCase或GroovyTestCase -
注释为
@RunWith -
包含带有注释的方法
@Test或超类
对于TestNG,Gradle 会扫描带有 注释的方法@Test。
请注意,抽象类不会被执行。此外,请注意 Gradle 会将继承树扫描到测试类路径上的 jar 文件中。因此,如果这些 JAR 包含测试类,它们也将运行。
如果您不想使用测试类检测,可以通过将TestscanForTestClasses上的属性设置为来禁用它。当您这样做时,测试任务仅使用和属性来查找测试类。falseincludesexcludes
如果scanForTestClasses为 false 并且未指定包含或排除模式,Gradle 默认运行与模式**/*Tests.class和匹配的任何类**/*Test.class,但不包括与 匹配的类**/Abstract*.class。
|
笔记
|
对于JUnit Platform,仅includes和excludes用于过滤测试类 —scanForTestClasses没有效果。
|
测试记录
Gradle 允许对记录到控制台的事件进行微调控制。日志记录可按日志级别进行配置,默认情况下,会记录以下事件:
当日志级别为 |
记录的事件 |
附加配置 |
|
没有任何 |
没有任何 |
|
异常格式为SHORT |
|
|
堆栈跟踪被截断。 |
|
|
记录完整的堆栈跟踪。 |
通过调整测试任务的testLogging属性中适当的TestLogging实例,可以按日志级别修改测试日志记录。例如,要调整级别测试日志记录配置,请修改
TestLoggingContainer.getInfo()属性。INFO
测试分组
JUnit、JUnit Platform 和 TestNG 允许对测试方法进行复杂的分组。
|
笔记
|
本节适用于对服务于相同测试目的(单元测试、集成测试、验收测试等)的测试集合中的各个测试类或方法进行分组。要根据用途划分测试类,请参阅孵化JVM 测试套件插件。 |
JUnit 4.8 引入了类别的概念,用于对 JUnit 4 测试类和方法进行分组。[ 6 ] Test.useJUnit(org.gradle.api.Action)允许您指定要包含和排除的 JUnit 类别。例如,以下配置包含任务中的测试CategoryA并排除任务中的CategoryB测试test:
tasks.test {
useJUnit {
includeCategories("org.gradle.junit.CategoryA")
excludeCategories("org.gradle.junit.CategoryB")
}
}test {
useJUnit {
includeCategories 'org.gradle.junit.CategoryA'
excludeCategories 'org.gradle.junit.CategoryB'
}
}JUnit Platform引入了标记来替换类别。您可以通过Test.useJUnitPlatform(org.gradle.api.Action)指定包含/排除的标签,如下所示:
TestNG 框架使用测试组的概念来达到类似的效果。[ 7 ]您可以通过Test.useTestNG(org.gradle.api.Action)设置配置在测试执行期间包含或排除哪些测试组,如下所示:
tasks.named<Test>("test") {
useTestNG {
val options = this as TestNGOptions
options.excludeGroups("integrationTests")
options.includeGroups("unitTests")
}
}test {
useTestNG {
excludeGroups 'integrationTests'
includeGroups 'unitTests'
}
}使用 JUnit 5
JUnit 5是著名的 JUnit 测试框架的最新版本。与它的前身不同,JUnit 5 是模块化的,由多个模块组成:
JUnit 5 = JUnit Platform + JUnit Jupiter + JUnit Vintage
JUnit 平台是在 JVM 上启动测试框架的基础。 JUnit Jupiter 是新的编程模型
和扩展模型的组合,用于在 JUnit 5 中编写测试和扩展。JUnit Vintage 提供了一个TestEngine用于在平台上运行基于 JUnit 3 和 JUnit 4 的测试。
以下代码启用 JUnit Platform 支持build.gradle:
tasks.named<Test>("test") {
useJUnitPlatform()
}tasks.named('test', Test) {
useJUnitPlatform()
}有关更多详细信息,请参阅Test.useJUnitPlatform() 。
编译和执行 JUnit Jupiter 测试
要在 Gradle 中启用 JUnit Jupiter 支持,您需要做的就是添加以下依赖项:
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter:5.7.1'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}然后,您可以像平常一样将测试用例放入src/test/java并使用gradle test.
使用 JUnit Vintage 执行遗留测试
如果您想在 JUnit 平台上运行 JUnit 3/4 测试,甚至将它们与 Jupiter 测试混合,您应该添加额外的 JUnit Vintage Engine 依赖项:
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
testCompileOnly("junit:junit:4.13")
testRuntimeOnly("org.junit.vintage:junit-vintage-engine")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter:5.7.1'
testCompileOnly 'junit:junit:4.13'
testRuntimeOnly 'org.junit.vintage:junit-vintage-engine'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}这样,您就可以gradle test在 JUnit 平台上使用 JUnit 3/4 测试进行测试,而无需重写它们。
过滤测试引擎
JUnit Platform 允许您使用不同的测试引擎。 JUnit 目前提供了两种TestEngine开箱即用的实现:
junit-jupiter-engine和junit-vintage-engine。您还可以编写并插入您自己的TestEngine实现,如此处所述。
默认情况下,将使用测试运行时类路径上的所有测试引擎。要显式控制特定测试引擎的实现,您可以将以下设置添加到构建脚本中:
tasks.withType<Test>().configureEach {
useJUnitPlatform {
includeEngines("junit-vintage")
// excludeEngines("junit-jupiter")
}
}tasks.withType(Test).configureEach {
useJUnitPlatform {
includeEngines 'junit-vintage'
// excludeEngines 'junit-jupiter'
}
}TestNG 中的测试执行顺序
当您使用testng.xml文件时,TestNG 允许显式控制测试的执行顺序。如果没有这样的文件(或者由TestNGOptions.getSuiteXmlBuilder()配置的等效文件),您将无法指定测试执行顺序。但是,您可以做的是控制是否 在下一个测试开始之前执行测试的所有方面(包括其关联的@BeforeXXX和@AfterXXX方法,例如用@Before/AfterClassand注释的方法)。@Before/AfterMethod您可以通过将TestNGOptions.getPreserveOrder()属性设置为 来执行此操作true。如果设置为false,则可能会遇到执行顺序类似于:TestA.doBeforeClass()→ TestB.doBeforeClass()→TestA测试的场景。
虽然保留测试顺序是直接使用testng.xml文件时的默认行为,但Gradle 的 TestNG 集成使用的TestNG API默认情况下以不可预测的顺序执行测试。 [ 8 ] TestNG 版本 5.14.5 引入了保留测试执行顺序的功能。将preserveOrder属性设置true为较旧的 TestNG 版本将导致构建失败。
tasks.test {
useTestNG {
preserveOrder = true
}
}test {
useTestNG {
preserveOrder true
}
}该groupByInstance属性控制测试是否应按实例而不是按类分组。TestNG 文档更详细地解释了差异,但本质上,如果您有一个A()依赖于 的测试方法B(),则按实例分组可确保每个 AB 配对(例如B(1)- A(1))在下一个配对之前执行。对于按类分组,B()先运行所有方法,然后运行所有A()方法。
请注意,如果您使用数据提供程序对其进行参数化,则通常只有多个测试实例。此外,TestNG 版本 6.1 还引入了按实例对测试进行分组的功能。将groupByInstances属性设置true为较旧的 TestNG 版本将导致构建失败。
tasks.test {
useTestNG {
groupByInstances = true
}
}test {
useTestNG {
groupByInstances = true
}
}TestNG 参数化方法和报告
TestNG 支持参数化测试方法,允许使用不同的输入多次执行特定的测试方法。 Gradle 在其测试方法执行报告中包含参数值。
给定一个名为 的参数化测试方法aTestMethod,它带有两个参数,它将以名称 进行报告aTestMethod(toStringValueOfParam1, toStringValueOfParam2)。这使得识别特定迭代的参数值变得容易。
配置集成测试
项目的一个常见要求是以一种或另一种形式合并集成测试。他们的目的是验证项目的各个部分是否正常协同工作。这通常意味着与单元测试相比,它们需要特殊的执行设置和依赖项。
将集成测试添加到构建的最简单方法是利用孵化JVM 测试套件插件。如果孵化解决方案不适合您,以下是您在构建中需要执行的步骤:
-
为他们创建一个新的源集
-
将您需要的依赖项添加到该源集的适当配置中
-
配置该源集的编译和运行时类路径
-
创建一个任务来运行集成测试
您可能还需要执行一些额外的配置,具体取决于集成测试采用的形式。我们将边讨论边讨论这些内容。
让我们从一个实际示例开始,该示例实现构建脚本中的前三个步骤,以新的源集为中心intTest:
sourceSets {
create("intTest") {
compileClasspath += sourceSets.main.get().output
runtimeClasspath += sourceSets.main.get().output
}
}
val intTestImplementation by configurations.getting {
extendsFrom(configurations.implementation.get())
}
val intTestRuntimeOnly by configurations.getting
configurations["intTestRuntimeOnly"].extendsFrom(configurations.runtimeOnly.get())
dependencies {
intTestImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
intTestRuntimeOnly("org.junit.platform:junit-platform-launcher")
}sourceSets {
intTest {
compileClasspath += sourceSets.main.output
runtimeClasspath += sourceSets.main.output
}
}
configurations {
intTestImplementation.extendsFrom implementation
intTestRuntimeOnly.extendsFrom runtimeOnly
}
dependencies {
intTestImplementation 'org.junit.jupiter:junit-jupiter:5.7.1'
intTestRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}这将设置一个名为的新源集,intTest该源集会自动创建:
-
intTestImplementation、intTestCompileOnly、intTestRuntimeOnly配置(以及其他一些不太常用的配置) -
一个任务,将编译src/intTest/java
compileIntTestJava下的所有源文件
|
笔记
|
如果您正在使用 IntelliJ IDE,您可能希望将这些附加源集中的目录标记为包含测试源而不是生产源,如Idea 插件文档中所述。 |
该示例还执行以下操作,并非您的特定集成测试可能需要的所有操作:
-
将源集中的生产类添加
main到集成测试的编译和运行时类路径 -sourceSets.main.output是包含已编译生产类和资源的所有目录的文件集合 -
使
intTestImplementation配置扩展自implementation,这意味着生产代码的所有声明的依赖项也成为集成测试的依赖项 -
intTestRuntimeOnly对配置执行同样的操作
在大多数情况下,您希望集成测试能够访问被测类,这就是为什么我们确保这些类包含在本示例中的编译和运行时类路径中。但某些类型的测试以不同的方式与生产代码交互。例如,您可能有将应用程序作为可执行文件运行并验证输出的测试。对于 Web 应用程序,测试可能通过 HTTP 与您的应用程序交互。由于在这种情况下测试不需要直接访问被测类,因此您不需要将生产类添加到测试类路径中。
另一个常见的步骤是将所有单元测试依赖项也附加到集成测试(通过),但只有当集成测试需要与单元测试具有的所有intTestImplementation.extendsFrom testImplementation或几乎所有相同的依赖项时,这才有意义。
您应该注意该示例的其他几个方面:
-
+=允许您附加路径和路径集合compileClasspath,而runtimeClasspath不是覆盖它们 -
如果要使用基于约定的配置,例如
intTestImplementation,则必须在新源集之后声明依赖项
创建和配置源集会自动设置编译阶段,但它对于运行集成测试没有任何作用。因此,最后一个难题是一个自定义测试任务,它使用新源集中的信息来配置其运行时类路径和测试类:
val integrationTest = task<Test>("integrationTest") {
description = "Runs integration tests."
group = "verification"
testClassesDirs = sourceSets["intTest"].output.classesDirs
classpath = sourceSets["intTest"].runtimeClasspath
shouldRunAfter("test")
useJUnitPlatform()
testLogging {
events("passed")
}
}
tasks.check { dependsOn(integrationTest) }tasks.register('integrationTest', Test) {
description = 'Runs integration tests.'
group = 'verification'
testClassesDirs = sourceSets.intTest.output.classesDirs
classpath = sourceSets.intTest.runtimeClasspath
shouldRunAfter test
useJUnitPlatform()
testLogging {
events "passed"
}
}
check.dependsOn integrationTest同样,我们访问源集以获取相关信息,即编译的测试类在哪里 - 属性testClassesDirs- 以及运行它们时类路径上需要什么 - classpath。
用户通常希望在单元测试之后运行集成测试,因为它们通常运行速度较慢,并且您希望构建在单元测试早期失败,而不是在集成测试后期失败。这就是上面的示例添加shouldRunAfter()声明的原因。这是首选方法,mustRunAfter()因此 Gradle 在并行执行构建方面具有更大的灵活性。
有关如何确定其他源集中测试的代码覆盖率的信息,请参阅JaCoCo 插件和JaCoCo 报告聚合插件章节。
测试 Java 模块
如果您正在开发 Java 模块,本章中描述的所有内容仍然适用,并且可以使用任何受支持的测试框架。但是,根据您是否需要在测试执行期间提供可用的模块信息以及是否需要强制执行模块边界,需要考虑一些事项。在这种情况下,经常使用术语白盒测试(模块边界被停用或放宽)和黑盒测试(模块边界到位)。白盒测试用于/需要单元测试,黑盒测试适合功能或集成测试要求。
在类路径上执行白盒单元测试
为模块中的函数或类编写单元测试的最简单设置是在测试执行期间不使用模块细节。为此,您只需像为普通库编写测试一样编写测试即可。如果module-info.java您的测试源集 ( ) 中没有文件src/test/java,则该源集在编译和测试运行时将被视为传统 Java 库。这意味着,所有依赖项(包括带有模块信息的 Jars)都放在类路径中。优点是您的(或其他)模块的所有内部类都可以在测试中直接访问。这对于单元测试来说可能是一个完全有效的设置,我们不关心更大的模块结构,而只关心测试单个功能。
|
笔记
|
如果您使用的是 Eclipse:默认情况下,Eclipse 还使用模块修补将单元测试作为模块运行(请参见下文)。在导入的 Gradle 项目中,使用 Eclipse 测试运行程序对模块进行单元测试可能会失败。然后,您需要手动调整测试运行配置中的类路径/模块路径或将测试执行委托给 Gradle。 这仅涉及测试执行。单元测试编译和开发在 Eclipse 中运行良好。 |
黑盒集成测试
对于集成测试,您可以选择将测试集本身定义为附加模块。您执行此操作的方式与将主要源代码转换为模块的方式类似:通过将module-info.java文件添加到相应的源代码集(例如integrationTests/java/module-info.java)。
您可以在此处找到包含黑盒集成测试的完整示例。
|
笔记
|
在Eclipse中,目前不支持 在一个项目中编译多个模块。因此,如果测试移至单独的子项目,则此处描述的集成测试(黑盒)设置仅适用于 Eclipse。 |
通过模块修补执行白盒测试
白盒测试的另一种方法是通过将测试修补到被测模块中来留在模块世界中。这样,模块边界保持不变,但测试本身成为被测模块的一部分,然后可以访问模块的内部结构。
这对于哪些用例相关以及如何最好地完成是讨论的主题。目前还没有通用的最佳方法。因此,Gradle 目前没有对此提供特殊支持。
但是,您可以为测试设置模块修补,如下所示:
-
将 a 添加
module-info.java到您的测试源集,该源集是主源集的副本module-info.java,其中包含测试所需的其他依赖项(例如requires org.junit.jupiter.api)。 -
使用参数配置
testCompileJava和test任务,以使用测试类修补主类,如下所示。
val moduleName = "org.gradle.sample"
val patchArgs = listOf("--patch-module", "$moduleName=${tasks.compileJava.get().destinationDirectory.asFile.get().path}")
tasks.compileTestJava {
options.compilerArgs.addAll(patchArgs)
}
tasks.test {
jvmArgs(patchArgs)
}def moduleName = "org.gradle.sample"
def patchArgs = ["--patch-module", "$moduleName=${tasks.compileJava.destinationDirectory.asFile.get().path}"]
tasks.named('compileTestJava') {
options.compilerArgs += patchArgs
}
tasks.named('test') {
jvmArgs += patchArgs
}|
笔记
|
如果使用自定义参数进行修补,则 Eclipse 和 IDEA 不会拾取这些参数。您很可能会在 IDE 中看到无效的编译错误。 |
跳过测试
gradle build -x test
这排除了该任务以及它专门test依赖的任何其他任务,即没有其他任务依赖于同一任务。这些任务不会被 Gradle 标记为“SKIPPED”,但不会出现在已执行的任务列表中。
通过构建脚本跳过测试可以通过几种方式完成。一种常见的方法是通过Task.onlyIf(String, org.gradle.api.specs.Spec)方法使测试执行有条件。test如果项目具有名为 的属性,以下示例将跳过该任务mySkipTests:
tasks.test {
val skipTestsProvider = providers.gradleProperty("mySkipTests")
onlyIf("mySkipTests property is not set") {
!skipTestsProvider.isPresent()
}
}def skipTestsProvider = providers.gradleProperty('mySkipTests')
test.onlyIf("mySkipTests property is not set") {
!skipTestsProvider.present
}在这种情况下,Gradle 会将跳过的测试标记为“SKIPPED”,而不是将它们从构建中排除。
强制测试运行
在定义良好的构建中,您可以依靠 Gradle 仅在测试本身或生产代码发生更改时才运行测试。但是,您可能会遇到测试依赖于第三方服务或其他可能会发生变化但无法在构建中建模的情况。
您始终可以使用--rerun 内置任务选项强制重新运行任务。
gradle test --rerun
或者,如果未启用构建缓存,您还可以通过清理相关任务的输出Test(例如test)并再次运行测试来强制运行测试,如下所示:
gradle cleanTest test
cleanTest基于Base Plugin提供的任务规则。您可以将它用于任何任务。
运行测试时进行调试
在少数情况下,您想要在测试运行时调试代码,如果此时可以附加调试器,将会很有帮助。您可以将Test.getDebug()属性设置为true或使用--debug-jvm命令行选项,或者使用--no-debug-jvm将其设置为 false。
当启用测试调试时,Gradle 将启动暂停的测试进程并在端口 5005 上侦听。
您还可以在 DSL 中启用调试,您还可以在其中配置其他属性:
test {
debugOptions {
enabled = true
host = 'localhost'
port = 4455
server = true
suspend = true
}
}
使用此配置,测试 JVM 的行为就像传递参数时一样,--debug-jvm但它将侦听端口 4455。
要通过网络远程调试测试过程,需要host设置为机器的IP地址或"*"(监听所有接口)。
使用测试夹具
在单个项目中生产和使用测试夹具
测试装置通常用于设置被测代码,或提供旨在促进组件测试的实用程序。java-test-fixtures除了 或java插件之外,Java 项目还可以通过应用插件来启用测试装置支持java-library:
plugins {
// A Java Library
`java-library`
// which produces test fixtures
`java-test-fixtures`
// and is published
`maven-publish`
}plugins {
// A Java Library
id 'java-library'
// which produces test fixtures
id 'java-test-fixtures'
// and is published
id 'maven-publish'
}这将自动创建一个testFixtures源集,您可以在其中编写测试装置。测试夹具的配置使得:
-
他们可以看到主要的源集类
-
测试源可以看到测试装置类
例如对于这个主类:
public class Person {
private final String firstName;
private final String lastName;
public Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
// ...测试夹具可以写成src/testFixtures/java:
public class Simpsons {
private static final Person HOMER = new Person("Homer", "Simpson");
private static final Person MARGE = new Person("Marjorie", "Simpson");
private static final Person BART = new Person("Bartholomew", "Simpson");
private static final Person LISA = new Person("Elisabeth Marie", "Simpson");
private static final Person MAGGIE = new Person("Margaret Eve", "Simpson");
private static final List<Person> FAMILY = new ArrayList<Person>() {{
add(HOMER);
add(MARGE);
add(BART);
add(LISA);
add(MAGGIE);
}};
public static Person homer() { return HOMER; }
public static Person marge() { return MARGE; }
public static Person bart() { return BART; }
public static Person lisa() { return LISA; }
public static Person maggie() { return MAGGIE; }
// ...声明测试装置的依赖关系
与Java Library Plugin类似,测试装置公开 API 和实现配置:
dependencies {
testImplementation("junit:junit:4.13")
// API dependencies are visible to consumers when building
testFixturesApi("org.apache.commons:commons-lang3:3.9")
// Implementation dependencies are not leaked to consumers when building
testFixturesImplementation("org.apache.commons:commons-text:1.6")
}dependencies {
testImplementation 'junit:junit:4.13'
// API dependencies are visible to consumers when building
testFixturesApi 'org.apache.commons:commons-lang3:3.9'
// Implementation dependencies are not leaked to consumers when building
testFixturesImplementation 'org.apache.commons:commons-text:1.6'
}值得注意的是,如果依赖项是测试装置的实现依赖项,那么在编译依赖于这些测试装置的测试时,实现依赖项将不会泄漏到编译类路径中。这会改善关注点分离并更好地避免编译。
使用另一个项目的测试装置
测试装置不限于单个项目。通常情况下,依赖项目的测试也需要依赖项的测试装置。使用关键字可以很容易地实现这一点testFixtures:
dependencies {
implementation(project(":lib"))
testImplementation("junit:junit:4.13")
testImplementation(testFixtures(project(":lib")))
}dependencies {
implementation(project(":lib"))
testImplementation 'junit:junit:4.13'
testImplementation(testFixtures(project(":lib")))
}发布测试夹具
使用该插件的优点之一java-test-fixtures是可以发布测试装置。按照惯例,测试装置将与具有分类器的工件一起发布test-fixtures。对于 Maven 和 Ivy,带有该分类器的工件只需与常规工件一起发布即可。但是,如果您使用maven-publish或插件,测试装置将作为Gradle 模块元数据ivy-publish中的附加变体发布,并且您可以直接依赖另一个 Gradle 项目中的外部库的测试装置:
dependencies {
// Adds a dependency on the test fixtures of Gson, however this
// project doesn't publish such a thing
functionalTest(testFixtures("com.google.code.gson:gson:2.8.5"))
}dependencies {
// Adds a dependency on the test fixtures of Gson, however this
// project doesn't publish such a thing
functionalTest testFixtures("com.google.code.gson:gson:2.8.5")
}值得注意的是,如果外部项目未发布 Gradle 模块元数据,则解析将失败,并显示错误,指示找不到此类变体:
gradle dependencyInsight --configuration functionalTestClasspath --dependency gson> gradle dependencyInsight --configuration functionalTestClasspath --dependency gson
> Task :dependencyInsight
com.google.code.gson:gson:2.8.5 FAILED
Failures:
- Could not resolve com.google.code.gson:gson:2.8.5.
- Unable to find a variant of com.google.code.gson:gson:2.8.5 providing the requested capability com.google.code.gson:gson-test-fixtures:
- Variant compile provides com.google.code.gson:gson:2.8.5
- Variant enforced-platform-compile provides com.google.code.gson:gson-derived-enforced-platform:2.8.5
- Variant enforced-platform-runtime provides com.google.code.gson:gson-derived-enforced-platform:2.8.5
- Variant javadoc provides com.google.code.gson:gson:2.8.5
- Variant platform-compile provides com.google.code.gson:gson-derived-platform:2.8.5
- Variant platform-runtime provides com.google.code.gson:gson-derived-platform:2.8.5
- Variant runtime provides com.google.code.gson:gson:2.8.5
- Variant sources provides com.google.code.gson:gson:2.8.5
com.google.code.gson:gson:2.8.5 FAILED
\--- functionalTestClasspath
A web-based, searchable dependency report is available by adding the --scan option.
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed
错误消息提到了缺少的com.google.code.gson:gson-test-fixtures功能,该功能确实没有为此库定义。这是因为按照惯例,对于使用该java-test-fixtures插件的项目,Gradle 会自动创建测试装置变体,其功能名称是主要组件的名称,并带有附录-test-fixtures.
|
笔记
|
如果您发布库并使用测试装置,但不想发布这些装置,则可以停用测试装置变体的发布,如下所示。 |
val javaComponent = components["java"] as AdhocComponentWithVariants
javaComponent.withVariantsFromConfiguration(configurations["testFixturesApiElements"]) { skip() }
javaComponent.withVariantsFromConfiguration(configurations["testFixturesRuntimeElements"]) { skip() }components.java.withVariantsFromConfiguration(configurations.testFixturesApiElements) { skip() }
components.java.withVariantsFromConfiguration(configurations.testFixturesRuntimeElements) { skip() }管理 JVM 项目的依赖关系
本章介绍如何将基本的依赖关系管理概念应用于基于 JVM 的项目。有关依赖管理的详细介绍,请参阅Gradle 中的依赖管理。
剖析典型的构建脚本
让我们看一下基于 JVM 项目的非常简单的构建脚本。它应用Java 库插件,该插件自动引入标准项目布局,提供执行典型工作的任务以及对依赖关系管理的充分支持。
plugins {
`java-library`
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.hibernate:hibernate-core:3.6.7.Final")
api("com.google.guava:guava:23.0")
testImplementation("junit:junit:4.+")
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.hibernate:hibernate-core:3.6.7.Final'
api 'com.google.guava:guava:23.0'
testImplementation 'junit:junit:4.+'
}Project.dependency {}代码块声明编译项目的生产源代码需要 Hibernate 核心 3.6.7.Final。它还指出编译项目的测试需要 junit >= 4.0。所有依赖项都应该在Project.repositories{}定义的 Maven 中央存储库中查找。以下部分更详细地解释了每个方面。
声明模块依赖关系
您可以声明多种类型的依赖关系。其中一种类型是模块依赖性。模块依赖项表示对在当前构建之外构建的特定版本的模块的依赖项。模块通常存储在存储库中,例如 Maven Central、企业 Maven 或 Ivy 存储库,或者本地文件系统中的目录。
要定义模块依赖项,请将其添加到依赖项配置中:
dependencies {
implementation("org.hibernate:hibernate-core:3.6.7.Final")
}dependencies {
implementation 'org.hibernate:hibernate-core:3.6.7.Final'
}要了解有关定义依赖项的更多信息,请查看声明依赖项。
使用依赖配置
配置是一组命名的依赖项和工件。配置有三个主要目的:
- 声明依赖关系
-
插件使用配置使构建作者可以轻松声明在执行插件定义的任务期间出于各种目的需要哪些其他子项目或外部工件。例如,插件可能需要 Spring Web 框架依赖项来编译源代码。
- 解决依赖关系
-
插件使用配置来查找(并可能下载)其定义的任务的输入。例如,Gradle 需要从 Maven Central 下载 Spring Web 框架 JAR 文件。
- 暴露文物以供消费
-
插件使用配置来定义它生成哪些工件供其他项目使用。例如,该项目希望将打包在 JAR 文件中的已编译源代码发布到内部 Artifactory 存储库。
考虑到这三个目的,让我们看一下Java Library Plugin 定义的一些标准配置。
- 执行
-
编译项目生产源所需的依赖项不属于项目公开的 API 的一部分。例如,该项目使用 Hibernate 来实现其内部持久层。
- 应用程序编程接口
-
编译项目的生产源所需的依赖项是项目公开的 API 的一部分。例如,该项目使用 Guava 并在其方法签名中公开带有 Guava 类的公共接口。
- 测试实施
-
编译和运行项目的测试源所需的依赖项。例如,该项目决定使用测试框架 JUnit 编写测试代码。
各种插件添加了更多标准配置。您还可以通过Project.configurations{}在构建中定义自己的自定义配置。有关定义和自定义依赖项配置的详细信息,请参阅什么是依赖项配置。
声明公共 Java 存储库
Gradle 如何知道在哪里可以找到外部依赖项的文件? Gradle 在存储库中查找它们。存储库是模块的集合,由group、name和组织version。 Gradle 理解不同的存储库类型,例如 Maven 和 Ivy,并支持通过 HTTP 或其他协议访问存储库的各种方式。
默认情况下,Gradle 不定义任何存储库。您需要在Project.repositories{}的帮助下至少定义一个,然后才能使用模块依赖项。一种选择是使用 Maven 中央存储库:
repositories {
mavenCentral()
}repositories {
mavenCentral()
}您还可以在本地文件系统上拥有存储库。这适用于 Maven 和 Ivy 存储库。
repositories {
ivy {
// URL can refer to a local directory
url = uri("../local-repo")
}
}repositories {
ivy {
// URL can refer to a local directory
url "../local-repo"
}
}一个项目可以有多个存储库。 Gradle 将按照指定的顺序在每个存储库中查找依赖项,并在包含所请求模块的第一个存储库处停止。
要了解有关定义存储库的更多信息,请查看声明存储库。
Java工具链
JVM 项目的工具链
处理多个项目可能需要与多个版本的 Java 语言进行交互。即使在单个项目中,由于向后兼容性要求,代码库的不同部分也可能被固定到特定的语言级别。这意味着必须在构建项目的每台计算机上安装和管理相同工具(工具链)的不同版本。
Java工具链是一组用于构建和运行 Java 项目的工具,通常由环境通过本地 JRE 或 JDK 安装提供。编译任务可以使用javac其编译器,测试和执行任务可以使用命令java,而javadoc将用于生成文档。
默认情况下,Gradle 使用相同的 Java 工具链来运行 Gradle 本身和构建 JVM 项目。然而,这可能只是有时是可取的。在不同的开发人员机器和 CI 服务器上构建具有不同 Java 版本的项目可能会导致意外问题。此外,您可能想要使用不支持运行 Gradle 的 Java 版本来构建项目。
为了提高构建的可重复性并使构建需求更加清晰,Gradle 允许在项目和任务级别上配置工具链。
项目工具链
您可以通过在扩展块中声明 Java 语言版本来定义项目使用的工具链java:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}执行构建(例如使用gradle check)现在将为您和其他运行构建的人处理一些事情:
|
笔记
|
Java 插件及其定义的任务中提供了工具链支持。 对于 Groovy 插件,支持编译,但尚不支持 Groovydoc 生成。对于Scala插件,支持编译和Scaladoc生成。 |
按供应商选择工具链
如果您的构建对所使用的 JRE/JDK 有特定要求,您可能还需要定义工具链的供应商。
JvmVendorSpec拥有 Gradle 认可的知名 JVM 供应商列表。优点是 Gradle 可以处理 JDK 版本之间 JVM 对供应商信息编码方式的任何不一致。
java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.ADOPTIUM
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.ADOPTIUM
}
}如果您要定位的供应商不是已知供应商,您仍然可以将工具链限制为与java.vendor可用工具链的系统属性相匹配的工具链。
以下代码片段使用过滤来包含可用工具链的子集。此示例仅包含java.vendor属性包含给定匹配字符串的工具链。匹配以不区分大小写的方式完成。
java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.matching("customString")
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.matching("customString")
}
}通过虚拟机实现选择工具链
如果您的项目需要特定的实现,您也可以根据实现进行过滤。目前可供选择的实现有:
VENDOR_SPECIFIC-
充当占位符并匹配任何供应商的任何实现(例如热点、zulu,...)
J9-
仅匹配使用 OpenJ9/IBM J9 运行时引擎的虚拟机实现。
例如,要使用通过AdoptOpenJDK分发的IBM JVM ,您可以指定过滤器,如下例所示。
java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.IBM
implementation = JvmImplementation.J9
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.IBM
implementation = JvmImplementation.J9
}
}|
笔记
|
Java 主要版本、供应商(如果指定)和实现(如果指定)将作为编译和测试执行的输入进行跟踪。 |
配置工具链规范
Gradle 允许配置影响工具链选择的多个属性,例如语言版本或供应商。尽管这些属性可以独立配置,但配置必须遵循一定的规则才能形成有效的规范。
A在两种情况下JavaToolchainSpec被认为是有效的:
-
当没有设置任何属性时,即规范为空;
-
languageVersion设置后,可以选择设置任何其他属性。
换句话说,如果指定了供应商或实现,则它们必须附有语言版本。 Gradle 区分配置语言版本的工具链规范和不配置语言版本的工具链规范。在大多数情况下,没有语言版本的规范将被视为选择当前构建的工具链。
自 Gradle 8.0 起,使用无效实例JavaToolchainSpec会导致构建错误。
任务工具链
如果您想调整用于特定任务的工具链,您可以指定任务正在使用的确切工具。例如,该Test任务公开一个JavaLauncher属性,该属性定义用于启动测试的 java 可执行文件。
在下面的示例中,我们将所有 java 编译任务配置为使用 Java 8。此外,我们引入了一个新Test任务,该任务将使用 JDK 17 运行我们的单元测试。
tasks.withType<JavaCompile>().configureEach {
javaCompiler = javaToolchains.compilerFor {
languageVersion = JavaLanguageVersion.of(8)
}
}
tasks.register<Test>("testsOn17") {
javaLauncher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(17)
}
}tasks.withType(JavaCompile).configureEach {
javaCompiler = javaToolchains.compilerFor {
languageVersion = JavaLanguageVersion.of(8)
}
}
task('testsOn17', type: Test) {
javaLauncher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(17)
}
}此外,在application子项目中,我们添加了另一个 Java 执行任务来使用 JDK 17 运行我们的应用程序。
tasks.register<JavaExec>("runOn17") {
javaLauncher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(17)
}
classpath = sourceSets["main"].runtimeClasspath
mainClass = application.mainClass
}task('runOn17', type: JavaExec) {
javaLauncher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(17)
}
classpath = sourceSets.main.runtimeClasspath
mainClass = application.mainClass
}根据任务的不同,JRE 可能就足够了,而对于其他任务(例如编译),则需要 JDK。默认情况下,如果安装的 JDK 能够满足要求,Gradle 会优先选择安装的 JDK 而不是 JRE。
Toolchains工具提供者可以从扩展中获得javaToolchains。
三个工具可用:
-
A这是JavaCompile任务
JavaCompiler使用的工具 -
A这是Javadoc任务
JavadocTool使用的工具
与依赖 Java 可执行文件或 Java home 的任务集成
任何可以配置 Java 可执行文件路径或 Java 主位置的任务都可以从工具链中受益。
虽然您无法直接连接工具链工具,但它们都具有元数据,可以访问它们的完整路径或它们所属的 Java 安装的路径。
例如,您可以java按如下方式配置任务的可执行文件:
val launcher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.sampleTask {
javaExecutable = launcher.map { it.executablePath }
}def launcher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.named('sampleTask') {
javaExecutable = launcher.map { it.executablePath }
}作为另一个示例,您可以为任务配置Java Home ,如下所示:
val launcher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.anotherSampleTask {
javaHome = launcher.map { it.metadata.installationPath }
}def launcher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.named('anotherSampleTask') {
javaHome = launcher.map { it.metadata.installationPath }
}如果您需要特定工具(例如Java编译器)的路径,可以通过以下方式获取:
val compiler = javaToolchains.compilerFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.yetAnotherSampleTask {
javaCompilerExecutable = compiler.map { it.executablePath }
}def compiler = javaToolchains.compilerFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.named('yetAnotherSampleTask') {
javaCompilerExecutable = compiler.map { it.executablePath }
}|
警告
|
上面的示例使用带有允许延迟配置的属性的RegularFileProperty任务。DirectoryProperty分别执行launcher.get().executablePath或将为您提供给定工具链的完整路径,但请注意,这可能会急切地实现(并提供)工具链
launcher.get().metadata.installationPath。compiler.get().executablePath |
自动检测已安装的工具链
默认情况下,Gradle 会自动检测本地 JRE/JDK 安装,因此用户无需进一步配置。以下是 JVM 自动检测支持的常见包管理器、工具和位置的列表。
JVM 自动检测知道如何使用:
-
操作系统特定位置:Linux、macOS、Windows
在所有检测到的 JRE/JDK 安装集合中,将根据工具链优先规则选择一个。
|
笔记
|
无论您是使用工具链自动检测还是配置自定义工具链位置,不存在或没有bin/java可执行文件的安装都将被忽略并显示警告,但不会生成错误。
|
如何禁用自动检测
为了禁用自动检测,您可以使用org.gradle.java.installations.auto-detectGradle 属性:
-
要么使用 gradle 启动
-Porg.gradle.java.installations.auto-detect=false -
或者放入你的文件
org.gradle.java.installations.auto-detect=false中。gradle.properties
自动配置
如果 Gradle 无法在本地找到符合构建要求的工具链,它可以自动下载一个(只要已经配置了工具链下载存储库;详细信息请参阅相关部分)。 Gradle 将下载的 JDK 安装在Gradle 用户主页中。
|
笔记
|
Gradle 仅下载 GA 版本的 JDK 版本。不支持下载早期访问版本。 |
一旦安装在Gradle User Home中,预配的 JDK 就会成为自动检测可见的 JDK 之一,并且可以由任何后续构建使用,就像系统上安装的任何其他 JDK 一样。
由于自动配置仅在自动检测无法找到匹配的 JDK 时才会启动,因此自动配置只能下载新的 JDK,而不会参与更新任何已安装的 JDK。任何自动配置的 JDK 都不会被自动配置重新访问和自动更新,即使有更新的次要版本可供使用。
工具链下载存储库
通过应用特定的设置插件将工具链下载存储库定义添加到构建中。有关编写此类插件的详细信息,请参阅工具链解析器插件页面。
工具链解析器插件的一个示例是Disco Toolchains Plugin,它基于foojay Disco API。它甚至还有一个约定变体,只需应用即可自动处理所有所需的配置:
plugins {
id("org.gradle.toolchains.foojay-resolver-convention") version("0.8.0")
}plugins {
id 'org.gradle.toolchains.foojay-resolver-convention' version '0.8.0'
}一般来说,在应用工具链解析器插件时,还需要配置其提供的工具链下载解析器。我们用一个例子来说明一下。考虑构建应用的两个工具链解析器插件:
-
一种是上面提到的 Foojay 插件,它通过它
FoojayToolchainResolver提供的下载工具链。 -
另一个包含一个名为 的虚构解析器
MadeUpResolver。
以下示例通过toolchainManagement设置文件中的块在构建中使用这些工具链解析器:
toolchainManagement {
jvm { // (1)
javaRepositories {
repository("foojay") { // (2)
resolverClass = org.gradle.toolchains.foojay.FoojayToolchainResolver::class.java
}
repository("made_up") { // (3)
resolverClass = MadeUpResolver::class.java
credentials {
username = "user"
password = "password"
}
authentication {
create<DigestAuthentication>("digest")
} // (4)
}
}
}
}toolchainManagement {
jvm { // (1)
javaRepositories {
repository('foojay') { // (2)
resolverClass = org.gradle.toolchains.foojay.FoojayToolchainResolver
}
repository('made_up') { // (3)
resolverClass = MadeUpResolver
credentials {
username "user"
password "password"
}
authentication {
digest(BasicAuthentication)
} // (4)
}
}
}
}-
在该
toolchainManagement块中,该jvm块包含Java工具链的配置。 -
该
javaRepositories块定义了命名的 Java 工具链存储库配置。使用该resolverClass属性将这些配置链接到插件。 -
工具链声明顺序很重要。 Gradle 从提供匹配的第一个存储库下载,从列表中的第一个存储库开始。
-
您可以使用用于依赖项管理的同一组身份验证和授权选项来配置工具链存储库。
|
警告
|
仅在应用工具链解析器插件后才能解析
该jvm块。toolchainManagement |
查看和调试工具链
Gradle 可以显示所有检测到的工具链的列表,包括其元数据。
例如,要显示项目的所有工具链,请运行:
gradle -q javaToolchainsgradle -q javaToolchains> gradle -q javaToolchains
+ Options
| Auto-detection: Enabled
| Auto-download: Enabled
+ AdoptOpenJDK 1.8.0_242
| Location: /Users/username/myJavaInstalls/8.0.242.hs-adpt/jre
| Language Version: 8
| Vendor: AdoptOpenJDK
| Architecture: x86_64
| Is JDK: false
| Detected by: Gradle property 'org.gradle.java.installations.paths'
+ Microsoft JDK 16.0.2+7
| Location: /Users/username/.sdkman/candidates/java/16.0.2.7.1-ms
| Language Version: 16
| Vendor: Microsoft
| Architecture: aarch64
| Is JDK: true
| Detected by: SDKMAN!
+ OpenJDK 15-ea
| Location: /Users/user/customJdks/15.ea.21-open
| Language Version: 15
| Vendor: AdoptOpenJDK
| Architecture: x86_64
| Is JDK: true
| Detected by: environment variable 'JDK16'
+ Oracle JDK 1.7.0_80
| Location: /Library/Java/JavaVirtualMachines/jdk1.7.0_80.jdk/Contents/Home/jre
| Language Version: 7
| Vendor: Oracle
| Architecture: x86_64
| Is JDK: false
| Detected by: MacOS java_home
这可以帮助调试哪些工具链可用于构建、如何检测它们以及 Gradle 了解这些工具链的元数据类型。
如何禁用自动配置
为了禁用自动配置,您可以使用org.gradle.java.installations.auto-downloadGradle 属性:
-
要么使用 gradle 启动
-Porg.gradle.java.installations.auto-download=false -
或者放入文件
org.gradle.java.installations.auto-download=false中gradle.properties。
自定义工具链位置
如果自动检测本地工具链不够或被禁用,您可以通过其他方式让 Gradle 了解已安装的工具链。
如果您的设置已经提供了指向已安装 JVM 的环境变量,您还可以让 Gradle 知道要考虑哪些环境变量。假设环境变量JDK8并JRE17指向有效的 java 安装,以下内容指示 Gradle 解析这些环境变量并在寻找匹配的工具链时考虑这些安装。
org.gradle.java.installations.fromEnv=JDK8,JRE17
此外,您可以使用该属性提供特定安装的以逗号分隔的路径列表org.gradle.java.installations.paths。例如,在您的gradle.properties遗嘱中使用以下内容,让 Gradle 知道在检测工具链时要查看哪些目录。 Gradle 会将这些目录视为可能的安装,但不会下降到任何嵌套目录。
org.gradle.java.installations.paths=/custom/path/jdk1.8,/shared/jre11
工具链安装优先级
Gradle 将对与构建的工具链规范匹配的所有 JDK/JRE 安装进行排序,并选择第一个。排序是根据以下规则进行的:
-
当前运行 Gradle 的安装优先于任何其他安装
-
JDK 安装优于 JRE 安装
-
某些供应商优先于其他供应商;它们的顺序(从最高优先级到最低优先级):
-
领养
-
采用OpenJDK
-
亚马逊
-
苹果
-
蔚蓝
-
贝尔软件公司
-
GRAAL_VM
-
惠普_派克
-
国际商业机器公司
-
捷布恩斯
-
微软
-
Oracle公司
-
树液
-
腾讯
-
其他一切
-
-
较高的主要版本优先于较低的版本
-
较高的次要版本优先于较低的次要版本
-
安装路径根据其字典顺序优先(确定性地决定来自同一供应商和同一版本的相同类型的安装的最后手段)
所有这些规则都按照所示的顺序作为多级排序标准应用。我们用一个例子来说明一下。工具链规范要求 Java 版本 17。Gradle 检测以下匹配的安装:
-
Oracle JRE v17.0.1
-
Oracle JDK v17.0.0
-
微软JDK 17.0.0
-
微软JRE 17.0.1
-
微软JDK 17.0.1
假设 Gradle 在除 17 之外的主要 Java 版本上运行。否则,该安装将具有优先权。
当我们应用上述规则对该集合进行排序时,我们最终将得到以下排序:
-
微软JDK 17.0.1
-
微软JDK 17.0.0
-
Oracle JDK v17.0.0
-
微软JRE v17.0.1
-
Oracle JRE v17.0.1
Gradle 更喜欢 JDK 而不是 JRE,因此 JRE 排在最后。 Gradle 更喜欢 Microsoft 供应商而不是 Oracle,因此 Microsoft 安装排在第一位。 Gradle 更喜欢更高的版本号,因此 JDK 17.0.1 位于 JDK 17.0.0 之前。
因此 Gradle 按此顺序选择第一个匹配项:Microsoft JDK 17.0.1。
插件作者的工具链
创建使用工具链的插件或任务时,必须提供合理的默认值并允许用户覆盖它们。
对于 JVM 项目,通常可以安全地假设java插件已应用于项目。该java插件会自动应用于核心 Groovy 和 Scala 插件以及 Kotlin 插件。在这种情况下,使用通过扩展定义的工具链java作为工具属性的默认值是合适的。这样,用户只需在项目级别配置工具链一次。
下面的示例展示了如何使用默认工具链作为约定,同时允许用户针对每个任务单独配置工具链。
abstract class CustomTaskUsingToolchains : DefaultTask() {
@get:Nested
abstract val launcher: Property<JavaLauncher> // (1)
init {
val toolchain = project.extensions.getByType<JavaPluginExtension>().toolchain // (2)
val defaultLauncher = javaToolchainService.launcherFor(toolchain) // (3)
launcher.convention(defaultLauncher) // (4)
}
@TaskAction
fun showConfiguredToolchain() {
println(launcher.get().executablePath)
println(launcher.get().metadata.installationPath)
}
@get:Inject
protected abstract val javaToolchainService: JavaToolchainService
}abstract class CustomTaskUsingToolchains extends DefaultTask {
@Nested
abstract Property<JavaLauncher> getLauncher() // (1)
CustomTaskUsingToolchains() {
def toolchain = project.extensions.getByType(JavaPluginExtension.class).toolchain // (2)
Provider<JavaLauncher> defaultLauncher = getJavaToolchainService().launcherFor(toolchain) // (3)
launcher.convention(defaultLauncher) // (4)
}
@TaskAction
def showConfiguredToolchain() {
println launcher.get().executablePath
println launcher.get().metadata.installationPath
}
@Inject
protected abstract JavaToolchainService getJavaToolchainService()
}-
我们声明
JavaLauncher任务的属性。该属性必须标记为@Nested输入,以确保任务响应工具链更改。 -
我们从扩展中获取工具链规范,
java并将其用作默认值。 -
使用 ,我们可以获得与工具链匹配
JavaToolchainService的 提供者。JavaLauncher -
最后,我们连接启动器提供程序作为我们财产的约定。
在应用了该插件的项目中java,我们可以按如下方式使用该任务:
plugins {
java
}
java {
toolchain { // (1)
languageVersion = JavaLanguageVersion.of(8)
}
}
tasks.register<CustomTaskUsingToolchains>("showDefaultToolchain") // (2)
tasks.register<CustomTaskUsingToolchains>("showCustomToolchain") {
launcher = javaToolchains.launcherFor { // (3)
languageVersion = JavaLanguageVersion.of(17)
}
}plugins {
id 'java'
}
java {
toolchain { // (1)
languageVersion = JavaLanguageVersion.of(8)
}
}
tasks.register('showDefaultToolchain', CustomTaskUsingToolchains) // (2)
tasks.register('showCustomToolchain', CustomTaskUsingToolchains) {
launcher = javaToolchains.launcherFor { // (3)
languageVersion = JavaLanguageVersion.of(17)
}
}-
java默认情况下,使用扩展上定义的工具链来解析启动器。 -
无需额外配置的自定义任务将使用默认的 Java 8 工具链。
-
另一个任务通过使用
javaToolchains服务选择不同的工具链来覆盖启动器的值。
当任务需要访问工具链而不java应用插件时,可以直接使用工具链服务。如果向服务提供了未配置的工具链规范,它将始终返回运行 Gradle 的工具链的工具提供程序。这可以通过在请求工具时传递一个空的 lambda 来实现:javaToolchainService.launcherFor({})。
您可以在创作任务文档中找到有关定义自定义任务的更多详细信息。
工具链解析器插件
在 Gradle 7.6 及更高版本中,Gradle 提供了一种在插件中定义 Java 工具链自动配置逻辑的方法。本页面介绍了如何编写工具链解析器插件。有关工具链自动配置如何与这些插件交互的详细信息,请参阅工具链。
提供下载 URI
工具链解析器插件提供将工具链请求映射到下载响应的逻辑。目前下载响应仅包含下载 URL,但将来可能会扩展。
|
警告
|
对于下载 URL,仅https接受此类安全协议。这是为了确保没有人可以篡改正在下载的内容所必需的。
|
这些插件通过JavaToolchainResolver的实现提供映射逻辑:
public abstract class JavaToolchainResolverImplementation
implements JavaToolchainResolver { // (1)
public Optional<JavaToolchainDownload> resolve(JavaToolchainRequest request) { // (2)
return Optional.empty(); // custom mapping logic goes here instead
}
}-
这个类是
abstract因为JavaToolchainResolver它是一个构建服务。 Gradle 在运行时为某些抽象方法提供动态实现。 -
映射方法返回包装在
Optional.如果解析器实现无法提供匹配的工具链,则封闭内容Optional包含空值。
在插件中注册解析器
使用设置插件 ( Plugin<Settings>) 来注册JavaToolchainResolver实现:
public abstract class JavaToolchainResolverPlugin implements Plugin<Settings> { // (1)
@Inject
protected abstract JavaToolchainResolverRegistry getToolchainResolverRegistry(); // (2)
public void apply(Settings settings) {
settings.getPlugins().apply("jvm-toolchain-management"); // (3)
JavaToolchainResolverRegistry registry = getToolchainResolverRegistry();
registry.register(JavaToolchainResolverImplementation.class);
}
}-
该插件使用属性注入,因此它必须是
abstract一个设置插件。 -
要注册解析器实现,请使用属性注入来访问JavaToolchainResolverRegistry Gradle 服务。
-
解析器插件必须应用
jvm-toolchain-management基本插件。这会动态地将jvm块添加到toolchainManagement,这使得注册的工具链存储库可以在构建中使用。
JVM 插件
Java 库插件
Java 库插件通过提供有关 Java 库的特定知识来扩展Java 插件 ( java)的功能。特别是,Java 库向消费者(即使用 Java 或 Java 库插件的其他项目)公开 API。使用此插件时,Java 插件公开的所有源集、任务和配置都隐式可用。
用法
要使用 Java 库插件,请在构建脚本中包含以下内容:
plugins {
`java-library`
}plugins {
id 'java-library'
}API 和实现分离
标准 Java 插件和 Java 库插件之间的主要区别在于后者引入了向消费者公开的API的概念。库是一个供其他组件使用的 Java 组件。这是多项目构建中非常常见的用例,而且只要您有外部依赖项也是如此。
该插件公开了两个可用于声明依赖项的配置api:和implementation。配置api应该用于声明库 API 导出的依赖项,而配置implementation应该用于声明组件内部的依赖项。
dependencies {
api("org.apache.httpcomponents:httpclient:4.5.7")
implementation("org.apache.commons:commons-lang3:3.5")
}dependencies {
api 'org.apache.httpcomponents:httpclient:4.5.7'
implementation 'org.apache.commons:commons-lang3:3.5'
}配置中出现的依赖关系api将传递给库的使用者,因此将出现在使用者的编译类路径中。implementation另一方面,在配置中找到的依赖项不会暴露给消费者,因此不会泄漏到消费者的编译类路径中。这有几个好处:
-
依赖项不再泄漏到消费者的编译类路径中,因此您永远不会意外依赖传递依赖项
-
由于类路径大小减小,编译速度更快
-
当实现依赖关系发生变化时,重新编译次数减少:消费者不需要重新编译
-
更干净的发布:当与新插件结合使用时
maven-publish,Java 库会生成 POM 文件,这些文件准确区分针对库进行编译所需的内容和运行时使用库所需的内容(换句话说,不要混合编译库本身所需的内容以及针对库进行编译所需的内容)。
|
笔记
|
Gradle 7.0 中已删除compile和
配置。runtime请参阅升级指南如何迁移implementation和api配置`。
|
如果您的构建使用带有 POM 元数据的已发布模块,则 Java 和 Java 库插件都会通过 POM 中使用的范围来实现 api 和实现分离。这意味着编译类路径仅包含 Maven范围的依赖项,而运行时类路径也compile添加 Maven范围的依赖项。runtime
这通常不会对使用 Maven 发布的模块产生影响,其中定义项目的 POM 直接作为元数据发布。在那里,编译范围包括编译项目所需的依赖项(即实现依赖项)和针对已发布的库进行编译所需的依赖项(即 API 依赖项)。对于大多数已发布的库,这意味着所有依赖项都属于编译范围。如果您在现有库中遇到此类问题,您可以考虑使用组件元数据规则来修复构建中的错误元数据。但是,如上所述,如果使用 Gradle 发布库,则生成的 POM 文件仅将api依赖项放入编译范围,将其余implementation依赖项放入运行时范围。
如果您的构建使用带有 Ivy 元数据的模块,并且所有模块都遵循特定的结构,那么您可能能够按照此处所述激活 api 和实现分离。
|
笔记
|
在 Gradle 5.0+ 中,默认情况下,模块的编译范围和运行时范围分离处于活动状态。在 Gradle 4.6+ 中,您需要通过添加enableFeaturePreview('IMPROVED_POM_SUPPORT')settings.gradle来激活它。
|
识别 API 和实现依赖性
本节将帮助您使用简单的经验法则识别代码中的 API 和实现依赖关系。其中第一个是:
-
尽可能优先选择
implementation配置api
这使得依赖项远离使用者的编译类路径。此外,如果任何实现类型意外泄漏到公共 API 中,使用者将立即无法编译。
那么什么时候应该使用该api配置呢? API 依赖项是一种至少包含一种在库二进制接口中公开的类型的依赖项,通常称为 ABI(应用程序二进制接口)。这包括但不限于:
-
超类或接口中使用的类型
-
公共方法参数中使用的类型,包括泛型参数类型(其中public是编译器可见的东西。即Java 世界中的public、protected和包私有成员)
-
公共领域使用的类型
-
公共注释类型
相比之下,以下列表中使用的任何类型都与 ABI 无关,因此应将其声明为implementation依赖项:
-
方法体中专用的类型
-
专用于私有成员的类型
-
专门在内部类中找到的类型(Gradle 的未来版本将允许您声明哪些包属于公共 API)
下面的类使用了几个第三方库,其中一个在类的公共 API 中公开,另一个仅在内部使用。 import 语句不能帮助我们确定哪个是哪个,所以我们必须查看字段、构造函数和方法:
示例:区分 API 和实现
// The following types can appear anywhere in the code
// but say nothing about API or implementation usage
import org.apache.commons.lang3.exception.ExceptionUtils;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
public class HttpClientWrapper {
private final HttpClient client; // private member: implementation details
// HttpClient is used as a parameter of a public method
// so "leaks" into the public API of this component
public HttpClientWrapper(HttpClient client) {
this.client = client;
}
// public methods belongs to your API
public byte[] doRawGet(String url) {
HttpGet request = new HttpGet(url);
try {
HttpEntity entity = doGet(request);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
entity.writeTo(baos);
return baos.toByteArray();
} catch (Exception e) {
ExceptionUtils.rethrow(e); // this dependency is internal only
} finally {
request.releaseConnection();
}
return null;
}
// HttpGet and HttpEntity are used in a private method, so they don't belong to the API
private HttpEntity doGet(HttpGet get) throws Exception {
HttpResponse response = client.execute(get);
if (response.getStatusLine().getStatusCode() != HttpStatus.SC_OK) {
System.err.println("Method failed: " + response.getStatusLine());
}
return response.getEntity();
}
}的公共构造函数作为参数HttpClientWrapper使用HttpClient,因此暴露给消费者,因此属于API。请注意,HttpGet和HttpEntity用于私有方法的签名,因此它们不会计入使 HttpClient 成为 API 依赖项。
另一方面,ExceptionUtils来自commons-lang库的类型仅在方法主体中使用(不在其签名中),因此它是实现依赖项。
因此,我们可以推断出httpclient是 API 依赖,而commons-lang是实现依赖。这个结论转化为构建脚本中的以下声明:
dependencies {
api("org.apache.httpcomponents:httpclient:4.5.7")
implementation("org.apache.commons:commons-lang3:3.5")
}dependencies {
api 'org.apache.httpcomponents:httpclient:4.5.7'
implementation 'org.apache.commons:commons-lang3:3.5'
}Java 库插件配置
下图描述了使用 Java 库插件时如何设置配置。

-
绿色的配置是用户应该用来声明依赖项的配置
-
粉红色的配置是组件编译或针对库运行时使用的配置
-
蓝色的配置是组件内部的,供其自己使用
下图描述了测试配置设置:

下表描述了每个配置的作用:
| 配置名称 | 角色 | 消耗品? | 可以解决吗? | 描述 |
|---|---|---|---|---|
|
声明 API 依赖项 |
不 |
不 |
您可以在此处声明依赖项,这些依赖项会在编译时和运行时传递给使用者。 |
|
声明实现依赖关系 |
不 |
不 |
在这里您可以声明纯粹内部的依赖项,并不意味着暴露给消费者(它们仍然在运行时暴露给消费者)。 |
|
声明仅编译依赖项 |
不 |
不 |
您可以在此处声明编译时所需的依赖项,但运行时不需要。这通常包括在运行时发现时被隐藏的依赖项。 |
|
声明仅编译 API 依赖项 |
不 |
不 |
您可以在此处声明模块和使用者在编译时所需的依赖项,但在运行时不需要。这通常包括在运行时发现时被隐藏的依赖项。 |
|
声明运行时依赖 |
不 |
不 |
您可以在此处声明仅在运行时而不是在编译时需要的依赖项。 |
|
测试依赖关系 |
不 |
不 |
您可以在此处声明用于编译测试的依赖项。 |
|
声明仅测试编译依赖项 |
不 |
不 |
您可以在此处声明仅在测试编译时需要的依赖项,但不应泄漏到运行时。这通常包括在运行时发现时被隐藏的依赖项。 |
|
声明测试运行时依赖项 |
不 |
不 |
您可以在此处声明仅在测试运行时而不是在测试编译时需要的依赖项。 |
| 配置名称 | 角色 | 消耗品? | 可以解决吗? | 描述 |
|---|---|---|---|---|
|
用于针对该库进行编译 |
是的 |
不 |
此配置供消费者使用,以检索针对此库进行编译所需的所有元素。 |
|
用于执行该库 |
是的 |
不 |
此配置供消费者使用,以检索针对此库运行所需的所有元素。 |
| 配置名称 | 角色 | 消耗品? | 可以解决吗? | 描述 |
|---|---|---|---|---|
编译类路径 |
用于编译这个库 |
不 |
是的 |
该配置包含该库的编译类路径,因此在调用java编译器对其进行编译时使用。 |
运行时类路径 |
用于执行该库 |
不 |
是的 |
该配置包含该库的运行时类路径 |
测试编译类路径 |
用于编译该库的测试 |
不 |
是的 |
此配置包含该库的测试编译类路径。 |
测试运行时类路径 |
用于执行该库的测试 |
不 |
是的 |
此配置包含该库的测试运行时类路径 |
为 Java 模块系统构建模块
从Java 9开始,Java本身提供了一个模块系统,允许在编译和运行时进行严格的封装。您可以通过在源文件夹中创建文件将 Java 库转换为Java 模块。module-info.javamain/java
src
└── main
└── java
└── module-info.java在模块信息文件中,您声明模块名称、要导出的模块的哪些包以及需要哪些其他模块。
module org.gradle.sample {
requires com.google.gson; // real module
requires org.apache.commons.lang3; // automatic module
// commons-cli-1.4.jar is not a module and cannot be required
}为了告诉 Java 编译器 Jar 是一个模块,而不是传统的 Java 库,Gradle 需要将其放置在所谓的模块路径上。它是类路径的替代方案,类路径是告诉编译器有关已编译依赖项的传统方法。如果满足以下三个条件,Gradle 会自动将依赖项的 Jar 放在模块路径上,而不是类路径上:
-
java.modularity.inferModulePath没有关闭 -
我们实际上正在构建一个模块(而不是传统的库),我们通过添加文件来表达它
module-info.java。 (另一个选项是添加Automatic-Module-NameJar 清单属性,如下所述。) -
我们的模块所依赖的 Jar 本身就是一个模块,Gradles 根据
module-info.classJar 中是否存在 a(模块描述符的编译版本)来决定该模块。 (或者,Automatic-Module-NameJar 清单中是否存在某个属性)
下面,描述了有关定义 Java 模块以及如何与 Gradle 的依赖项管理交互的更多细节。您还可以查看现成的示例来直接尝试 Java 模块支持。
声明模块依赖关系
与您在构建文件中声明的依赖项和您在文件中声明的模块依赖项有直接关系module-info.java。理想情况下,声明应保持同步,如下表所示。
| Java 模块指令 | 等级配置 | 目的 |
|---|---|---|
|
|
声明实现依赖关系 |
|
|
声明 API 依赖项 |
|
|
声明仅编译依赖项 |
|
|
声明仅编译 API 依赖项 |
Gradle 目前不会自动检查依赖项声明是否同步。这可能会在未来版本中添加。
有关声明模块依赖关系的更多详细信息,请参阅Java 模块系统 上的文档。
声明包可见性和服务
Java 模块系统支持比 Gradle 本身当前更精细的封装概念。例如,您明确需要声明哪些包是 API 的一部分,哪些包仅在模块内可见。其中一些功能可能会在未来版本中添加到 Gradle 本身中。目前,请参阅Java 模块系统的文档,了解如何在 Java 模块中使用这些功能。
声明模块版本
Java 模块还有一个版本,该版本被编码为文件中模块标识的一部分module-info.class。当模块运行时可以检查此版本。
version = "1.2"
tasks.compileJava {
// use the project's version or define one directly
options.javaModuleVersion = provider { version as String }
}version = '1.2'
tasks.named('compileJava') {
// use the project's version or define one directly
options.javaModuleVersion = provider { version }
}使用非模块的库
您可能希望在模块化 Java 项目中使用外部库,例如来自 Maven Central 的 OSS 库。有些库在较新的版本中已经是带有模块描述符的完整模块。例如,com.google.code.gson:gson:2.8.9模块名称为com.google.gson。
其他的,例如org.apache.commons:commons-lang3:3.10,可能不提供完整的模块描述符,但至少会Automatic-Module-Name在其清单文件中包含一个条目来定义模块的名称(org.apache.commons.lang3在示例中)。这种只有名称作为模块描述的模块称为自动模块,它导出所有包并可以读取模块路径上的所有模块。
第三种情况是根本不提供模块信息的传统库——例如commons-cli:commons-cli:1.4。 Gradle 将此类库放在类路径而不是模块路径上。然后,Java将类路径视为一个模块(所谓的未命名模块)。
dependencies {
implementation("com.google.code.gson:gson:2.8.9") // real module
implementation("org.apache.commons:commons-lang3:3.10") // automatic module
implementation("commons-cli:commons-cli:1.4") // plain library
}dependencies {
implementation 'com.google.code.gson:gson:2.8.9' // real module
implementation 'org.apache.commons:commons-lang3:3.10' // automatic module
implementation 'commons-cli:commons-cli:1.4' // plain library
}module org.gradle.sample.lib {
requires com.google.gson; // real module
requires org.apache.commons.lang3; // automatic module
// commons-cli-1.4.jar is not a module and cannot be required
}虽然真实模块不能直接依赖未命名模块(只能通过添加命令行标志),但自动模块也可以看到未命名模块。因此,如果您无法避免依赖没有模块信息的库,则可以将该库包装在自动模块中作为项目的一部分。下一节将介绍如何执行此操作。
禁用 Java 模块支持
在极少数情况下,您可能希望禁用内置 Java 模块支持并通过其他方式定义模块路径。为此,您可以禁用自动将任何 Jar 放在模块路径上的功能。然后 Gradle 将带有模块信息的 Jars 放在类路径上,即使您module-info.java的源集中有一个。这对应于 Gradle 版本 <7.0 的行为。
要实现此功能,您需要modularity.inferModulePath = false对 Java 扩展(针对所有任务)或单个任务进行设置。
java {
modularity.inferModulePath = false
}
tasks.compileJava {
modularity.inferModulePath = false
}java {
modularity.inferModulePath = false
}
tasks.named('compileJava') {
modularity.inferModulePath = false
}构建自动化模块
如果可以的话,您应该始终module-info.java为模块编写完整的描述符。尽管如此,在某些情况下您可能会考虑(最初)只为自动模块提供模块名称:
-
您正在开发一个不是模块的库,但您希望使其在下一个版本中可用。添加
Automatic-Module-Name是一个很好的第一步(Maven 中心上最流行的 OSS 库现在已经完成了)。 -
正如上一节中所讨论的,自动模块可以用作实际模块和类路径上的传统库之间的适配器。
要将普通的 Java 项目转换为自动模块,只需添加带有模块名称的清单条目:
tasks.jar {
manifest {
attributes("Automatic-Module-Name" to "org.gradle.sample")
}
}tasks.named('jar') {
manifest {
attributes('Automatic-Module-Name': 'org.gradle.sample')
}
}|
笔记
|
=== 您可以将自动模块定义为多项目的一部分,否则定义实际模块(例如,作为另一个库的适配器)。虽然这在 Gradle 构建中运行良好,但目前 IDEA/Eclipse 无法正确识别此类自动模块项目。您可以通过手动将为自动模块构建的 Jar 添加到在 IDE 的 UI 中找不到它的项目的依赖项来解决此问题。 === |
使用类代替jar进行编译
该插件的一个功能java-library是使用该库的项目仅需要类文件夹进行编译,而不是完整的 JAR。这使得项目间的依赖更轻,因为在开发过程中只进行Java代码编译时,不再执行资源处理(processResources任务)和归档构建(任务)。jar
|
笔记
|
是否使用类输出而不是 JAR 由消费者决定。例如,Groovy 使用者将请求类和已处理资源,因为在编译过程中执行 AST 转换可能需要这些资源。 |
增加消费者的内存使用量
间接后果是最新检查将需要更多内存,因为 Gradle 将对单个类文件而不是单个 jar 进行快照。这可能会导致大型项目的内存消耗增加,好处是compileJava在更多情况下使任务保持最新(例如,更改资源不再更改compileJava上游项目任务的输入)
对于大型多项目,Windows 上的构建性能显着下降
单个类文件快照的另一个副作用(仅影响 Windows 系统)是,在编译类路径上处理大量类文件时,性能会显着下降。这只涉及非常大的多项目,其中通过使用许多api或(已弃用的)依赖项,在类路径上存在大量类compile。为了缓解这种情况,您可以将org.gradle.java.compile-classpath-packaging系统属性设置为 来true更改 Java 库插件的行为,以便对编译类路径上的所有内容使用 jar 而不是类文件夹。请注意,由于这会产生其他性能影响和潜在的副作用,因此通过在编译时触发所有 jar 任务,仅建议您在 Windows 上遇到所描述的性能问题时激活此功能。
应用程序插件
应用程序插件有助于创建可执行的 JVM 应用程序。它使得在开发过程中本地启动应用程序变得容易,并将应用程序打包为 TAR 和/或 ZIP(包括操作系统特定的启动脚本)。
应用应用程序插件也隐式应用Java 插件。源main集实际上是“应用程序”。
应用应用程序插件也会隐式应用分发插件。创建一个main分发包来打包应用程序,包括代码依赖项和生成的启动脚本。
构建 JVM 应用程序
要使用应用程序插件,请在构建脚本中包含以下内容:
plugins {
application
}plugins {
id 'application'
}插件的唯一强制配置是应用程序主类(即入口点)的规范。
application {
mainClass = "org.gradle.sample.Main"
}application {
mainClass = 'org.gradle.sample.Main'
}run您可以通过执行任务(类型:JavaExec )来运行应用程序。这将编译主源集,并启动一个新的 JVM,以其类(以及所有运行时依赖项)作为类路径并使用指定的主类。您可以gradle run --debug-jvm使用(请参阅JavaExec.setDebug(boolean) )以调试模式启动应用程序。
从 Gradle 4.9 开始,命令行参数可以通过--args.例如,如果您想使用命令行参数启动应用程序foo --bar,则可以使用gradle run --args="foo --bar"(请参阅JavaExec.setArgsString(java.lang.String)。
如果您的应用程序需要一组特定的 JVM 设置或系统属性,您可以配置该applicationDefaultJvmArgs属性。这些 JVM 参数将应用于run任务,并在您的发行版生成的启动脚本中予以考虑。
application {
applicationDefaultJvmArgs = listOf("-Dgreeting.language=en")
}application {
applicationDefaultJvmArgs = ['-Dgreeting.language=en']
}如果您的应用程序的启动脚本应位于与 不同的目录中bin,您可以配置该executableDir属性。
application {
executableDir = "custom_bin_dir"
}application {
executableDir = 'custom_bin_dir'
}使用 Java 模块系统构建应用程序
Gradle 支持Java 模块的构建,如Java 库插件文档的相应部分所述。 Java 模块也可以是可运行的,您可以使用应用程序插件来运行和打包这样的模块化应用程序。为此,除了对非模块化应用程序所做的操作之外,您还需要做两件事。
首先,您需要添加一个module-info.java文件来描述您的应用程序模块。有关此主题的更多详细信息,请参阅Java 库插件文档。
其次,除了主类名称之外,您还需要告诉 Gradle 您想要运行的模块的名称,如下所示:
application {
mainModule = "org.gradle.sample.app" // name defined in module-info.java
mainClass = "org.gradle.sample.Main"
}application {
mainModule = 'org.gradle.sample.app' // name defined in module-info.java
mainClass = 'org.gradle.sample.Main'
}就这样。如果您通过执行run任务或通过生成的启动脚本来运行应用程序,它将作为模块运行并在运行时遵守模块边界。例如,从另一个模块反射访问内部包可能会失败。
配置的主类也被烘焙到module-info.class应用程序 Jar 的文件中。如果直接使用命令运行模块化应用程序java,则提供模块名称就足够了。
您还可以查看一个现成的示例,其中包含作为多项目一部分的模块化应用程序。
构建发行版
可以通过分发插件(自动应用)来创建应用程序的分发。main使用以下内容创建分配:
| 地点 | 内容 |
|---|---|
(根目录) |
|
|
所有运行时依赖项和主要源集类文件。 |
|
启动脚本(由 |
要添加到发行版的静态文件可以简单地添加到src/dist.可以通过配置主发行版公开的CopySpec来完成更高级的自定义。
val createDocs by tasks.registering {
val docs = layout.buildDirectory.dir("docs")
outputs.dir(docs)
doLast {
docs.get().asFile.mkdirs()
docs.get().file("readme.txt").asFile.writeText("Read me!")
}
}
distributions {
main {
contents {
from(createDocs) {
into("docs")
}
}
}
}tasks.register('createDocs') {
def docs = layout.buildDirectory.dir('docs')
outputs.dir docs
doLast {
docs.get().asFile.mkdirs()
docs.get().file('readme.txt').asFile.write('Read me!')
}
}
distributions {
main {
contents {
from(createDocs) {
into 'docs'
}
}
}
}通过指定分发应包含任务的输出文件(请参阅增量构建),Gradle 知道必须在组装分发之前调用生成文件的任务,并将为您处理此问题。
您可以运行gradle installDist以在 中创建应用程序的映像。您可以运行来创建包含发行版的 ZIP、创建应用程序 TAR 或构建两者。build/install/projectNamegradle distZipgradle distTargradle assemble
自定义启动脚本生成
该应用程序插件可以生成开箱即用的 Unix(适用于 Linux、macOS 等)和 Windows 启动脚本。启动脚本使用定义为原始构建和运行时环境(例如JAVA_OPTSenv var)一部分的指定设置来启动JVM 。默认脚本模板基于用于启动 Gradle 本身的相同脚本,这些脚本作为 Gradle 发行版的一部分提供。
启动脚本是完全可定制的。请参阅CreateStartScripts的文档以获取更多详细信息和自定义示例。
任务
应用程序插件将以下任务添加到项目中。
应用扩展
应用程序插件向项目添加扩展,您可以使用它来配置其行为。有关扩展上可用属性的更多信息,请参阅JavaApplication DSL 文档。
您可以通过前面显示的块配置扩展application {},例如在构建脚本中使用以下内容:
application {
executableDir = "custom_bin_dir"
}application {
executableDir = 'custom_bin_dir'
}启动脚本的许可
为应用程序生成的启动脚本已获得Apache 2.0 软件许可证的许可。
约定属性(已弃用)
该插件还向项目添加了一些约定属性,您可以使用它们来配置其行为。这些已被弃用并由上述扩展取代。有关它们的信息,请参阅Project DSL 文档。
与扩展属性不同,这些属性在构建脚本中显示为顶级项目属性。例如,要更改应用程序名称,您只需将以下内容添加到构建脚本中:
application.applicationName = "my-app"application.applicationName = 'my-app'Java 平台插件
Java 平台插件提供了为 Java 生态系统声明平台的能力。一个平台可以用于不同的目的:
-
一起发布的模块的描述(例如,共享相同的版本)
-
一组异构库的推荐版本。一个典型的例子包括Spring Boot BOM
-
在子项目之间共享一组依赖版本
平台是一种特殊的软件组件,不包含任何源:它仅用于引用其他库,以便它们在依赖关系解析期间可以很好地协同工作。
平台可以发布为Gradle 模块元数据和Maven BOM。
|
笔记
|
该插件不能与给定项目中的或插件java-platform结合使用。从概念上讲,项目要么是一个没有二进制文件的平台,要么生成二进制文件。
javajava-library |
用法
要使用 Java 平台插件,请在构建脚本中包含以下内容:
plugins {
`java-platform`
}plugins {
id 'java-platform'
}API 和运行时分离
Maven BOM 和 Java 平台之间的主要区别在于,在 Gradle 中声明依赖项和约束,并将其范围限定为配置和扩展它的配置。虽然许多用户只关心声明编译时依赖项的约束,从而由运行时和测试依赖项继承,但它允许声明仅适用于运行时或测试的依赖项或约束。
为此,该插件公开了两个可用于声明依赖项的配置api:和runtime。配置api应该用于声明针对平台进行编译时应该使用的约束和依赖项,而配置runtime应该用于声明在运行时可见的约束或依赖项。
dependencies {
constraints {
api("commons-httpclient:commons-httpclient:3.1")
runtime("org.postgresql:postgresql:42.2.5")
}
}dependencies {
constraints {
api 'commons-httpclient:commons-httpclient:3.1'
runtime 'org.postgresql:postgresql:42.2.5'
}
}请注意,此示例使用约束而不是依赖关系。一般来说,这就是您想要做的:仅当此类组件直接或传递地添加到依赖关系图中时,约束才会适用。这意味着平台中列出的所有约束都不会添加依赖项,除非另一个组件将其引入:它们可以被视为建议。
|
笔记
|
例如,如果一个平台声明了对 的约束 |
默认情况下,为了避免在平台中添加依赖项而不是约束的常见错误,如果您尝试这样做,Gradle 将失败。如果由于某种原因,除了约束之外,您还想添加依赖项,则需要显式启用它:
javaPlatform {
allowDependencies()
}javaPlatform {
allowDependencies()
}当地项目限制
如果您有一个多项目构建并想要发布一个链接到子项目的平台,您可以通过声明属于该平台的子项目的约束来实现,如下例所示:
dependencies {
constraints {
api(project(":core"))
api(project(":lib"))
}
}dependencies {
constraints {
api project(":core")
api project(":lib")
}
}项目符号将成为group:name:version已发布元数据中的经典符号。
来自另一个平台的采购限制
有时,您定义的平台是另一个现有平台的扩展。
为了让您的平台包含来自第三方平台的约束,需要将其作为platform 依赖项导入:
javaPlatform {
allowDependencies()
}
dependencies {
api(platform("com.fasterxml.jackson:jackson-bom:2.9.8"))
}javaPlatform {
allowDependencies()
}
dependencies {
api platform('com.fasterxml.jackson:jackson-bom:2.9.8')
}发布平台
发布 Java 平台是通过应用maven-publish插件并配置使用该组件的 Maven 发布来完成的javaPlatform:
publishing {
publications {
create<MavenPublication>("myPlatform") {
from(components["javaPlatform"])
}
}
}publishing {
publications {
myPlatform(MavenPublication) {
from components.javaPlatform
}
}
}这将为平台生成一个 BOM 文件,其中包含一个与平台模块中定义的约束相对应的<dependencyManagement>块。<dependencies>
消费平台
由于 Java 平台是一种特殊类型的组件,因此必须使用platformorenforcedPlatform关键字声明对 Java 平台的依赖关系,如管理传递依赖关系部分中所述。例如,如果您想在子项目之间共享依赖版本,您可以定义一个平台模块来声明所有版本:
dependencies {
constraints {
// Platform declares some versions of libraries used in subprojects
api("commons-httpclient:commons-httpclient:3.1")
api("org.apache.commons:commons-lang3:3.8.1")
}
}dependencies {
constraints {
// Platform declares some versions of libraries used in subprojects
api 'commons-httpclient:commons-httpclient:3.1'
api 'org.apache.commons:commons-lang3:3.8.1'
}
}然后让子项目依赖于平台来获取推荐:
dependencies {
// get recommended versions from the platform project
api(platform(project(":platform")))
// no version required
api("commons-httpclient:commons-httpclient")
}dependencies {
// get recommended versions from the platform project
api platform(project(':platform'))
// no version required
api 'commons-httpclient:commons-httpclient'
}Groovy 插件
Groovy 插件扩展了Java 插件以添加对Groovy项目的支持。它可以处理 Groovy 代码、混合 Groovy 和 Java 代码,甚至纯 Java 代码(尽管我们不一定建议将它用于后者)。该插件支持联合编译,允许您自由地混合和匹配 Groovy 和 Java 代码,并具有双向依赖关系。例如,Groovy 类可以扩展 Java 类,而 Java 类又扩展 Groovy 类。这使得可以使用最适合工作的语言,并在需要时用其他语言重写任何类。
请注意,如果您想从API/实现分离中受益,您还可以将该java-library插件应用到您的 Groovy 项目中。
用法
要使用 Groovy 插件,请在构建脚本中包含以下内容:
plugins {
groovy
}plugins {
id 'groovy'
}任务
Groovy 插件将以下任务添加到项目中。有关更改 Java 编译任务的依赖关系的信息可在此处找到。
Groovy 插件将以下依赖项添加到 Java 插件添加的任务中。
| 任务名称 | 依赖于取决于 |
|---|---|
|
|
|
|
|
|

项目布局
Groovy 插件采用Groovy Layout中显示的项目布局。所有 Groovy 源目录都可以包含 Groovy和Java 代码。 Java 源目录可能仅包含 Java 源代码。[ 9 ]这些目录都不需要存在或包含任何内容; Groovy 插件将简单地编译它找到的任何内容。
src/main/java-
生产 Java 源代码。
src/main/resources-
生产资源,例如 XML 和属性文件。
src/main/groovy-
生产 Groovy 源代码。还可能包含用于联合编译的 Java 源文件。
src/test/java-
测试 Java 源。
src/test/resources-
测试资源。
src/test/groovy-
测试 Groovy 源。还可能包含用于联合编译的 Java 源文件。
src/sourceSet/java-
名为sourceSet的源集的 Java 源。
src/sourceSet/resources-
名为sourceSet的源集的资源。
src/sourceSet/groovy-
给定源集的 Groovy 源文件。还可能包含用于联合编译的 Java 源文件。
更改项目布局
就像 Java 插件一样,Groovy 插件允许您为 Groovy 生产和测试源文件配置自定义位置。
sourceSets {
main {
groovy {
setSrcDirs(listOf("src/groovy"))
}
}
test {
groovy {
setSrcDirs(listOf("test/groovy"))
}
}
}sourceSets {
main {
groovy {
srcDirs = ['src/groovy']
}
}
test {
groovy {
srcDirs = ['test/groovy']
}
}
}依赖管理
由于 Gradle 的构建语言基于 Groovy,并且 Gradle 的部分内容是用 Groovy 实现的,因此 Gradle 已经附带了 Groovy 库。尽管如此,Groovy 项目需要显式声明 Groovy 依赖项。然后,此依赖项将用于编译和运行时类路径。它还将分别用于获取 Groovy 编译器和 Groovydoc 工具。
如果 Groovy 用于生产代码,则应将 Groovy 依赖项添加到配置中implementation:
repositories {
mavenCentral()
}
dependencies {
implementation("org.codehaus.groovy:groovy-all:2.4.15")
}repositories {
mavenCentral()
}
dependencies {
implementation 'org.codehaus.groovy:groovy-all:2.4.15'
}如果 Groovy 仅用于测试代码,则应将 Groovy 依赖项添加到配置中testImplementation:
dependencies {
testImplementation("org.codehaus.groovy:groovy-all:2.4.15")
}dependencies {
testImplementation 'org.codehaus.groovy:groovy-all:2.4.15'
}要使用 Gradle 附带的 Groovy 库,请声明localGroovy()依赖项。请注意,不同的 Gradle 版本附带不同的 Groovy 版本;因此,使用的localGroovy()安全性不如声明常规 Groovy 依赖项。
dependencies {
implementation(localGroovy())
}dependencies {
implementation localGroovy()
}自动配置groovyClasspath
GroovyCompile和任务Groovydoc以两种方式使用 Groovy 代码:在它们的classpath和 在它们的groovyClasspath.前者用于定位源代码引用的类,通常包含 Groovy 库以及其他库。后者分别用于加载和执行 Groovy 编译器和 Groovydoc 工具,并且应该只包含 Groovy 库及其依赖项。
除非显式配置任务groovyClasspath,否则 Groovy(基本)插件将尝试从任务的classpath.这是按如下方式完成的:
-
如果
groovy-all(-indy)在 上找到 Jarclasspath,则该 Jar 将被添加到groovyClasspath。 -
如果
groovy(-indy)在 上找到一个 jarclasspath,并且该项目至少声明了一个存储库,groovy(-indy)则会将相应的存储库依赖项添加到 中groovyClasspath。 -
否则,任务执行将失败,并显示一条消息,指出
groovyClasspath无法推断。
请注意,每个 jar 的“ -indy”变体是指支持的版本invokedynamic。
约定属性
Groovy 插件不会向项目添加任何约定属性。
源集属性
Groovy 插件将以下扩展添加到项目中的每个源集。您可以在构建脚本中使用这些属性,就像它们是源集对象的属性一样。
Groovy Plugin — 源集属性
groovy— GroovySourceDirectorySet(只读)-
默认值:不为空
该源集的 Groovy 源文件。包含在 Groovy 源目录中找到的所有文件,并排除所有其他类型的文件
.groovy。.java groovy.srcDirs—Set<File>-
默认值:
[projectDir/src/name/groovy]包含此源集的 Groovy 源文件的源目录。还可能包含用于联合编译的 Java 源文件。可以使用指定多个文件中描述的任何内容进行设置。
allGroovy—文件树(只读)-
默认值:不为空
该源集的所有 Groovy 源文件。仅包含
.groovy在 Groovy 源目录中找到的文件。
这些属性由GroovySourceSet类型的约定对象提供。
Groovy 插件还修改了一些源集属性:
Groovy 插件 - 修改源集属性
| 物业名称 | 改变 |
|---|---|
|
添加 |
|
添加在 Groovy 源目录中找到的所有源文件。 |
Groovy编译
Groovy 插件为项目中的每个源集添加一个GroovyCompileJavaCompile任务。通过扩展,任务类型与任务有很多共享AbstractCompile(请参阅相关的 Java 插件部分)。该GroovyCompile任务支持官方 Groovy 编译器的大多数配置选项。该任务还可以利用Java 工具链支持。
| 任务属性 | 类型 | 默认值 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果在扩展上定义了工具链,则不会配置任何内容 |
避免编译
注意:Groovy 编译避免是自 Gradle 5.6 以来的一个孵化功能。存在已知的不准确之处,因此请自行承担启用它的风险。
要启用对避免 Groovy 编译的孵化支持,请enableFeaturePreview在您的设置文件中添加:
enableFeaturePreview('GROOVY_COMPILATION_AVOIDANCE')enableFeaturePreview("GROOVY_COMPILATION_AVOIDANCE")如果依赖项目以ABI兼容方式发生更改(仅其私有 API 发生更改),则 Groovy 编译任务将是最新的。这意味着,如果项目A依赖于项目B,并且其中的类B以 ABI 兼容的方式更改(通常仅更改方法的主体),则 Gradle 将不会重新编译A.
有关不影响 ABI 且被忽略的更改类型的详细列表,请参阅Java 编译避免。
然而,与Java的注释处理类似,有多种方法可以定制Groovy编译过程,其中实现细节很重要。一些著名的例子是Groovy AST 转换。在这些情况下,必须在名为的类路径中单独声明这些依赖项astTransformationClasspath:
val astTransformation by configurations.creating
dependencies {
astTransformation(project(":ast-transformation"))
}
tasks.withType<GroovyCompile>().configureEach {
astTransformationClasspath.from(astTransformation)
}configurations { astTransformation }
dependencies {
astTransformation(project(":ast-transformation"))
}
tasks.withType(GroovyCompile).configureEach {
astTransformationClasspath.from(configurations.astTransformation)
}增量 Groovy 编译
从 5.6 开始,Gradle 引入了一个实验性增量 Groovy 编译器。要为 Groovy 启用增量编译,您需要:
-
启用Groovy 编译避免。
-
在构建脚本中显式启用增量 Groovy 编译:
tasks.withType<GroovyCompile>().configureEach {
options.isIncremental = true
options.incrementalAfterFailure = true
}tasks.withType(GroovyCompile).configureEach {
options.incremental = true
options.incrementalAfterFailure = true
}这会给您带来以下好处:
-
增量构建要快得多。
-
如果仅更改一小部分 Groovy 源文件,则仅重新编译受影响的源文件。不需要重新编译的类在输出目录中保持不变。例如,如果您只更改了几个 Groovy 测试类,则无需重新编译所有 Groovy 测试源文件 — 只需重新编译更改的文件。
要了解增量编译的工作原理,请参阅增量 Java 编译以获取详细概述。请注意,与 Java 增量编译有几个不同之处:
Groovy 编译器不会保留@Retention生成的注释类字节码 ( GROOVY-9185 ),因此所有注释都是RUNTIME.这意味着对源保留注释的更改不会触发完全重新编译。
针对 Java 6 或 Java 7 的编译和测试
添加工具链支持后GroovyCompile,可以使用与运行 Gradle 不同的 Java 版本来编译 Groovy 代码。如果您还有 Java 源文件,这也将配置为使用正确的 Java 编译器,如Java 插件JavaCompile文档中所示。
示例:为 Groovy 配置 Java 7 构建
java {
toolchain {
languageVersion = JavaLanguageVersion.of(7)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(7)
}
}Scala 插件
Scala 插件扩展了Java 插件以添加对Scala项目的支持。该插件还支持联合编译,允许您自由地混合和匹配 Scala 和 Java 代码,并具有双向依赖关系。例如,Scala 类可以扩展 Java 类,而 Java 类又扩展 Scala 类。这使得可以使用最适合工作的语言,并在需要时用其他语言重写任何类。
请注意,如果您想从API/实现分离中受益,您还可以将该java-library插件应用到您的 Scala 项目中。
用法
要使用 Scala 插件,请在构建脚本中包含以下内容:
plugins {
scala
}plugins {
id 'scala'
}任务
Scala 插件将以下任务添加到项目中。有关更改 Java 编译任务的依赖关系的信息可在此处找到。
ScalaCompile和任务ScalaDoc支持开箱即用的Java 工具链。
Scala 插件将以下依赖项添加到 Java 插件添加的任务中。
| 任务名称 | 依赖于取决于 |
|---|---|
|
|
|
|
|
|

项目布局
Scala 插件采用如下所示的项目布局。所有 Scala 源目录都可以包含 Scala和Java 代码。 Java 源目录可能仅包含 Java 源代码。这些目录都不需要存在或包含任何内容; Scala 插件将简单地编译它找到的任何内容。
src/main/java-
生产 Java 源代码。
src/main/resources-
生产资源,例如 XML 和属性文件。
src/main/scala-
生产 Scala 源代码。还可能包含用于联合编译的 Java 源文件。
src/test/java-
测试 Java 源。
src/test/resources-
测试资源。
src/test/scala-
测试 Scala 源。还可能包含用于联合编译的 Java 源文件。
src/sourceSet/java-
名为sourceSet的源集的 Java 源。
src/sourceSet/resources-
名为sourceSet的源集的资源。
src/sourceSet/scala-
给定源集的 Scala 源文件。还可能包含用于联合编译的 Java 源文件。
更改项目布局
就像 Java 插件一样,Scala 插件允许您为 Scala 生产和测试源文件配置自定义位置。
sourceSets {
main {
scala {
setSrcDirs(listOf("src/scala"))
}
}
test {
scala {
setSrcDirs(listOf("test/scala"))
}
}
}sourceSets {
main {
scala {
srcDirs = ['src/scala']
}
}
test {
scala {
srcDirs = ['test/scala']
}
}
}依赖管理
Scala 项目需要声明scala-library依赖项。然后,此依赖项将用于编译和运行时类路径。它还将分别用于获取 Scala 编译器和 Scaladoc 工具。[ 10 ]
如果 Scala 用于生产代码,scala-library则应将依赖项添加到implementation配置中:
repositories {
mavenCentral()
}
dependencies {
implementation("org.scala-lang:scala-library:2.13.12")
testImplementation("junit:junit:4.13")
}repositories {
mavenCentral()
}
dependencies {
implementation 'org.scala-lang:scala-library:2.13.12'
testImplementation 'junit:junit:4.13'
}如果您想使用 Scala 3 而不是依赖scala-library项,您应该添加scala3-library_3依赖项:
plugins {
scala
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.scala-lang:scala3-library_3:3.0.1")
testImplementation("org.scalatest:scalatest_3:3.2.9")
testImplementation("junit:junit:4.13")
}
dependencies {
implementation("commons-collections:commons-collections:3.2.2")
}plugins {
id 'scala'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.scala-lang:scala3-library_3:3.0.1'
implementation 'commons-collections:commons-collections:3.2.2'
testImplementation 'org.scalatest:scalatest_3:3.2.9'
testImplementation 'junit:junit:4.13'
}如果Scala仅用于测试代码,scala-library则应将依赖项添加到testImplementation配置中:
dependencies {
testImplementation("org.scala-lang:scala-library:2.13.12")
}dependencies {
testImplementation 'org.scala-lang:scala-library:2.13.12'
}scalaClasspath的自动配置
ScalaCompile和任务ScalaDoc以两种方式使用 Scala 代码:在它们的 上classpath,以及在它们的scalaClasspath.前者用于定位源代码引用的类,并且通常包含scala-library其他库。后者分别用于加载和执行 Scala 编译器和 Scaladoc 工具,并且应该只包含scala-compiler库及其依赖项。
除非显式配置任务scalaClasspath,否则 Scala(基本)插件将尝试从任务的classpath.这是按如下方式完成的:
-
如果
scala-library在 上找到一个 jarclasspath,并且该项目至少声明了一个存储库,scala-compiler则会将相应的存储库依赖项添加到 中scalaClasspath。 -
否则,任务执行将失败,并显示一条消息,指出
scalaClasspath无法推断。
配置 Zinc 编译器
Scala 插件使用名为 的配置zinc来解析Zinc 编译器及其依赖项。 Gradle 将提供默认版本的 Zinc,但如果您需要使用特定的 Zinc 版本,则可以更改它。 Gradle 支持 Zinc 1.6.0 及以上版本。
scala {
zincVersion = "1.9.3"
}scala {
zincVersion = "1.9.3"
}Zinc 编译器本身需要一个兼容版本,scala-library该版本可能与您的应用程序所需的版本不同。 Gradle 负责scala-library为您指定兼容版本。
您可以通过运行dependencyInsight进行配置来诊断所选 Zinc 编译器版本的问题zinc。
| 摇篮版本 | 支持的锌版本 | 锌坐标 | 所需的 Scala 版本 | 支持的Scala编译版本 |
|---|---|---|---|---|
7.5 及更高版本 |
SBT 锌。 1.6.0 及以上版本。 |
|
运行 |
Scala |
6.0 至 7.5 |
SBT 锌。 1.2.0 及以上版本。 |
|
运行 |
Scala |
1.x 至 5.x |
已弃用Typesafe Zinc 编译器。版本 0.3.0 及更高版本,0.3.2 至 0.3.5.2 除外。 |
|
运行 |
Scala |
向 Scala 编译器添加插件
Scala 插件添加了一个名为 的配置scalaCompilerPlugins,用于声明和解析可选的编译器插件。
dependencies {
implementation("org.scala-lang:scala-library:2.13.12")
scalaCompilerPlugins("org.typelevel:kind-projector_2.13.12:0.13.2")
}dependencies {
implementation "org.scala-lang:scala-library:2.13.12"
scalaCompilerPlugins "org.typelevel:kind-projector_2.13.12:0.13.2"
}约定属性
Scala 插件不会向项目添加任何约定属性。
源集属性
Scala 插件将以下扩展添加到项目中的每个源集。您可以在构建脚本中使用它们,就像它们是源集对象的属性一样。
scala— SourceDirectorySet(只读)-
该源集的 Scala 源文件。包含在 Scala 源目录中找到的所有文件,并排除所有其他类型的文件
.scala。默认值:非空。.java scala.srcDirs—Set<File>-
包含此源集的 Scala 源文件的源目录。还可能包含用于联合编译的 Java 源文件。可以使用了解文件集合的隐式转换中描述的任何内容进行设置。 默认值: 。
[projectDir/src/name/scala] allScala—文件树(只读)-
该源集的所有 Scala 源文件。仅包含
.scalaScala 源目录中找到的文件。默认值:非空。
这些扩展由ScalaSourceSet类型的对象支持。
Scala 插件还修改了一些源集属性:
| 物业名称 | 改变 |
|---|---|
|
添加 |
|
添加在 Scala 源目录中找到的所有源文件。 |
目标字节码级别和 Java API 版本
运行 Scala 编译任务时,Gradle 始终会添加一个参数来配置从 Gradle 配置派生的 Scala 编译器的 Java 目标:
-
使用工具链时,选择该
-release选项,或者target对于较旧的 Scala 版本,选择与配置的工具链的 Java 语言级别匹配的版本。 -
当不使用工具链时,Gradle 将始终传递一个
target标志(其确切值取决于 Scala 版本)来编译为 Java 8 字节码。
|
笔记
|
这意味着使用具有最新 Java 版本和旧 Scala 版本的工具链可能会导致失败,因为 Scala 在一段时间内仅支持 Java 8 字节码。然后,解决方案是在工具链中使用正确的 Java 版本,或者在需要时显式降级目标。 |
下表解释了 Gradle 计算的值:
| Scala版本 | 使用中的工具链 | 参数值 |
|---|---|---|
版本< |
是的 |
|
不 |
|
|
|
是的 |
|
不 |
|
|
|
是的 |
|
不 |
|
|
|
是的 |
|
不 |
|
显式设置任何这些标志,或使用包含java-output-version, on 的标志ScalaCompile.scalaCompileOptions.additionalParameters会禁用该逻辑,转而使用显式标志。
在外部进程中编译
Scala 编译在外部进程中进行。
外部进程的内存设置默认为 JVM 的默认值。要调整内存设置,请scalaCompileOptions.forkOptions根据需要配置属性:
tasks.withType<ScalaCompile>().configureEach {
scalaCompileOptions.forkOptions.apply {
memoryMaximumSize = "1g"
jvmArgs = listOf("-XX:MaxMetaspaceSize=512m")
}
}tasks.withType(ScalaCompile) {
scalaCompileOptions.forkOptions.with {
memoryMaximumSize = '1g'
jvmArgs = ['-XX:MaxMetaspaceSize=512m']
}
}增量编译
通过仅编译自上次编译以来源代码发生更改的类以及受这些更改影响的类,增量编译可以显着减少 Scala 编译时间。当频繁编译小代码增量时(开发时经常这样做),它特别有效。
Scala 插件默认通过与Zinc集成进行增量编译,Zinc 是sbt增量 Scala 编译器的独立版本。如果要禁用增量编译,请force = true在构建文件中设置:
tasks.withType<ScalaCompile>().configureEach {
scalaCompileOptions.apply {
isForce = true
}
}tasks.withType(ScalaCompile) {
scalaCompileOptions.with {
force = true
}
}注意:只有当至少一个输入源文件发生更改时,这才会导致所有类重新编译。如果源文件没有更改,compileScala任务仍将被视为UP-TO-DATE正常。
基于Zinc的Scala编译器支持Java和Scala代码的联合编译。默认情况下,所有Java和Scala下的代码src/main/scala都会参与联合编译。甚至Java代码也会被增量编译。
增量编译需要对源代码进行依赖分析。该分析的结果存储在指定的文件中scalaCompileOptions.incrementalOptions.analysisFile(具有合理的默认值)。在多项目构建中,分析文件将传递到下游ScalaCompile任务,以实现跨项目边界的增量编译。对于ScalaCompileScala 插件添加的任务,无需配置即可完成此操作。对于您可能添加的其他ScalaCompile任务,需要将该属性scalaCompileOptions.incrementalOptions.publishedCode配置为指向类文件夹或 Jar 存档,代码将通过该文件夹或 Jar 存档传递以编译下游ScalaCompile任务的类路径。请注意,如果publishedCode设置不正确,下游任务可能不会重新编译受上游更改影响的代码,从而导致编译结果不正确。
请注意,不支持 Zinc 的基于 Nailgun 的守护进程模式。相反,我们计划增强 Gradle 自己的编译器守护进程,以便在 Gradle 调用之间保持活动状态,重用相同的 Scala 编译器。预计这将为 Scala 编译带来另一次显着的加速。
Eclipse 集成
当 Eclipse 插件遇到 Scala 项目时,它会添加额外的配置以使该项目开箱即用地与 Scala IDE 一起使用。具体来说,该插件添加了 Scala 性质和依赖项容器。
IntelliJ IDEA 集成
当IDEA插件遇到Scala项目时,它会添加额外的配置以使该项目开箱即用地与IDEA一起使用。具体来说,该插件添加了一个 Scala SDK (IntelliJ IDEA 14+) 和一个与项目类路径上的 Scala 版本相匹配的 Scala 编译器库。 Scala 插件向后兼容早期版本的 IntelliJ IDEA,并且可以通过在IdeaModeltargetVersion上进行配置来添加 Scala 方面而不是默认的 Scala SDK 。
idea {
targetVersion = "13"
}idea {
targetVersion = '13'
}使用依赖项
依赖管理术语
依赖管理有大量的术语。在这里您可以找到最常用的术语,包括参考用户指南以了解其实际应用。
人工制品
由构建生成的文件或目录,例如 JAR、ZIP 发行版或本机可执行文件。
工件通常设计为供用户或其他项目使用或消耗,或部署到托管系统。在这种情况下,工件是单个文件。在项目间依赖的情况下,目录很常见,以避免产生可发布工件的成本。
配置
配置是为了特定目标而分组在一起的一组指定的依赖项。配置提供对底层、已解析模块及其工件的访问。有关更多信息,请参阅有关依赖项配置以及可解析和可使用配置的部分。
|
笔记
|
“配置”这个词是一个重载的术语,在依赖关系管理的上下文之外具有不同的含义。 |
依赖性
依赖项是指向构建、测试或运行模块所需的另一软件的指针。有关更多信息,请参阅声明依赖项部分。
特征变体
特征变体是表示可以单独选择或不单独选择的组件特征的变体。功能变体由一个或多个功能来标识。有关更多信息,请参阅有关建模特征变体和可选依赖项的部分。
模块
一个随着时间的推移而发展的软件,例如Google Guava。每个模块都有一个名称。模块的每个版本都由模块版本最佳地表示。为了方便使用,模块可以托管在存储库中。
模块元数据
模块的发布提供元数据。元数据是更详细地描述模块的数据,例如有关工件位置或所需传递依赖项的信息。 Gradle 提供了自己的元数据格式,称为Gradle 模块元数据(.module文件),但也支持 Maven ( .pom) 和 Ivy ( ivy.xml) 元数据。有关支持的元数据格式的更多信息,请参阅了解 Gradle 模块元数据部分。
组件元数据规则
组件元数据规则是在从存储库获取组件的元数据之后修改组件的元数据的规则,例如添加缺失的信息或纠正错误的信息。与解析规则相反,组件元数据规则在解析开始之前应用。组件元数据规则被定义为构建逻辑的一部分,并且可以通过插件共享。有关更多信息,请参阅有关使用组件元数据规则修复元数据的部分。
平台
平台是一组旨在一起使用的模块。平台有不同类别,对应不同的用例:
-
模块集:通常是作为一个整体发布的一组模块。使用该集合中的一个模块通常意味着我们希望对该集合中的所有模块使用相同的版本。例如,如果使用
groovy1.2,则也使用groovy-json1.2。 -
运行时环境:一组已知可以很好地协同工作的库。例如,Spring 平台,推荐 Spring 以及与 Spring 配合良好的组件的版本。
-
部署环境:Java运行时、应用程序服务器……
此外Gradle还定义了虚拟平台。
|
笔记
|
Maven 的 BOM(物料清单)是Gradle 支持的一种流行平台。 |
决议规则
解析规则影响直接解析依赖关系的行为。解析规则被定义为构建逻辑的一部分。有关更多信息,请参阅直接自定义依赖项解析部分。
基础
依赖管理
软件项目很少单独工作。项目通常依赖于库中的可重用功能。一些项目将不相关的功能组织到模块化系统的单独部分中。
依赖管理是一种用于声明、解析和使用项目所需功能的自动化技术。
|
提示
|
有关依赖关系管理术语的概述,请参阅依赖关系管理术语。 |
Gradle 中的依赖管理
Gradle 内置了对依赖管理的支持。
让我们借助一个理论但常见的项目来探讨主要概念:
-
该项目构建 Java 源代码。
-
本项目使用JUnit进行测试。
Gradle 构建文件可能如下所示:
plugins {
`java-library`
}
repositories { // (1)
google() // (2)
mavenCentral()
}
dependencies { // (3)
implementation("com.google.guava:guava:32.1.2-jre") // (4)
testImplementation("junit:junit:4.13.2")
}plugins {
id 'java-library'
}
repositories { // (1)
google() // (2)
mavenCentral()
}
dependencies { // (3)
implementation 'com.google.guava:guava:32.1.2-jre' // (4)
testImplementation 'junit:junit:4.13.2'
}-
这里我们为项目定义存储库。
-
在这里,我们为依赖位置声明远程和本地存储库。
您可以声明存储库来告诉 Gradle 在哪里获取本地或远程依赖项。
在此示例中,Gradle从Maven Central和Google存储库获取依赖项。 在构建过程中,Gradle 会查找并下载依赖项,这个过程称为依赖项解析。然后,Gradle将解析的依赖项存储在称为依赖项缓存的本地缓存中。后续构建使用此缓存来避免不必要的网络调用并加快构建过程。 -
这里我们定义项目使用的依赖项。
-
这里我们声明了一个范围内的具体依赖名称和版本。
存储库提供多种格式的依赖项。有关 Gradle 支持的格式的信息,请参阅依赖项类型。
元数据描述依赖关系。元数据的一些示例包括:
-
用于在存储库中查找依赖项的坐标
-
有关创建依赖项的项目的信息
-
依赖项的作者
-
依赖项正常工作所需的其他依赖项,称为传递依赖项
您可以根据项目的要求自定义 Gradle 对传递依赖项的处理。
具有数百个已声明依赖项的项目可能很难调试。 Gradle 提供了可视化和分析项目依赖关系图(即依赖关系树)的工具。您可以使用Build Scan™或内置任务。

声明存储库
Gradle 可以基于 Maven、Ivy 或平面目录格式解析一个或多个存储库的依赖关系。查看所有类型存储库的完整参考以获取更多信息。
声明一个公开可用的存储库
构建软件的组织可能希望利用公共二进制存储库来下载和使用开源依赖项。流行的公共存储库包括Maven Central和Google Android存储库。 Gradle 为这些广泛使用的存储库提供了内置的速记符号。

在幕后,Gradle 解析由速记符号定义的公共存储库的相应 URL 的依赖关系。所有速记符号均可通过RepositoryHandler API 获得。或者,您可以拼出存储库的 URL以进行更细粒度的控制。
Maven 中央存储库
Maven Central 是一个流行的存储库,托管供 Java 项目使用的开源库。
要为您的构建声明Maven 中央存储库,请将其添加到您的脚本中:
repositories {
mavenCentral()
}repositories {
mavenCentral()
}谷歌 Maven 存储库
Google 存储库托管 Android 特定的工件,包括 Android SDK。有关使用示例,请参阅相关的 Android 文档。
要声明Google Maven 存储库,请将其添加到您的构建脚本中:
repositories {
google()
}repositories {
google()
}通过 URL 声明自定义存储库
大多数企业项目都会设置仅在 Intranet 内可用的二进制存储库。内部存储库使团队能够发布内部二进制文件、设置用户管理和安全措施并确保正常运行时间和可用性。如果您想要声明一个不太受欢迎但可公开访问的存储库,则指定自定义 URL 也很有帮助。
通过调用RepositoryHandler API上可用的相应方法,可以将具有自定义 URL 的存储库指定为 Maven 或 Ivy 存储库。 Gradle 支持除自定义 URL 之外的其他协议http或https作为自定义 URL 的一部分,例如file,sftp或s3。有关完整的内容,请参阅有关支持的存储库类型的部分。
您还可以使用存储库来定义自己的存储库布局ivy { },因为它们在存储库中的模块组织方式方面非常灵活。
声明多个存储库
您可以定义多个存储库来解决依赖关系。如果某些依赖项仅在一个存储库中可用而在另一个存储库中不可用,则声明多个存储库会很有帮助。您可以混合参考部分中描述的任何类型的存储库。
此示例演示如何为项目声明各种命名和自定义 URL 存储库:
repositories {
mavenCentral()
maven {
url = uri("https://repo.spring.io/release")
}
maven {
url = uri("https://repository.jboss.org/maven2")
}
}repositories {
mavenCentral()
maven {
url "https://repo.spring.io/release"
}
maven {
url "https://repository.jboss.org/maven2"
}
}|
笔记
|
声明的顺序决定了 Gradle 在运行时如何检查依赖关系。如果 Gradle 在特定存储库中找到模块描述符,它将尝试从同一存储库下载该模块的所有工件。您可以了解有关依赖项下载的内部工作原理的更多信息。 |
对声明的存储库的严格限制
Maven POM 元数据可以引用其他存储库。 Gradle将忽略这些,它只会使用构建本身中声明的存储库。
|
笔记
|
这是可重复性的保障,也是安全的保障。如果没有它,依赖项的更新版本可能会从任何地方将工件拉入您的构建中。 |
支持的存储库类型
Gradle 在格式和连接方面支持广泛的依赖项源。您可以通过以下方式解决依赖关系:
-
不同的格式
-
具有不同的连接性
平面目录存储库
某些项目可能更喜欢将依赖项存储在共享驱动器上或作为项目源代码的一部分,而不是二进制存储库产品。如果您想使用(平面)文件系统目录作为存储库,只需键入:
repositories {
flatDir {
dirs("lib")
}
flatDir {
dirs("lib1", "lib2")
}
}repositories {
flatDir {
dirs 'lib'
}
flatDir {
dirs 'lib1', 'lib2'
}
}这会添加存储库,这些存储库会查找一个或多个目录以查找依赖项。
这种类型的存储库不支持任何元数据格式,例如 Ivy XML 或 Maven POM 文件。相反,Gradle 将根据工件的存在动态生成模块描述符(没有任何依赖信息)。
|
笔记
|
由于 Gradle 更喜欢使用其描述符是从真实元数据创建而不是生成的模块,因此平面目录存储库不能用于使用构建中声明的其他存储库中的真实元数据覆盖工件。 例如,如果 Gradle 仅 对于用本地工件覆盖远程工件的用例,请考虑使用 Ivy 或 Maven 存储库,而不是其 URL 指向本地目录。 |
如果您仅使用平面目录存储库,则无需设置依赖项的所有属性。
Maven 存储库
许多组织将依赖项托管在只能在公司网络内访问的内部 Maven 存储库中。 Gradle 可以通过 URL 声明 Maven 存储库。
要添加自定义 Maven 存储库,您可以执行以下操作:
repositories {
maven {
url = uri("http://repo.mycompany.com/maven2")
}
}repositories {
maven {
url "http://repo.mycompany.com/maven2"
}
}设置复合 Maven 存储库
有时,存储库会将 POM 发布到一个位置,并将 JAR 和其他工件发布到另一位置。要定义这样的存储库,您可以执行以下操作:
repositories {
maven {
// Look for POMs and artifacts, such as JARs, here
url = uri("http://repo2.mycompany.com/maven2")
// Look for artifacts here if not found at the above location
artifactUrls("http://repo.mycompany.com/jars")
artifactUrls("http://repo.mycompany.com/jars2")
}
}repositories {
maven {
// Look for POMs and artifacts, such as JARs, here
url "http://repo2.mycompany.com/maven2"
// Look for artifacts here if not found at the above location
artifactUrls "http://repo.mycompany.com/jars"
artifactUrls "http://repo.mycompany.com/jars2"
}
}Gradle 将查看urlPOM 和 JAR 的基本位置。如果在那里找不到 JAR,则artifactUrls使用额外的 JAR 来查找 JAR。
本地 Maven 存储库
Gradle 可以使用本地 Maven 存储库中可用的依赖项。声明此存储库对于将一个项目发布到本地 Maven 存储库并在另一个项目中使用 Gradle 的工件的团队来说是有益的。
|
笔记
|
Gradle 将解析的依赖项存储在它自己的缓存中。即使您从基于 Maven 的远程存储库解析依赖项,构建也不需要声明本地 Maven 存储库。 |
|
警告
|
在将 Maven local 添加为存储库之前,您应该确保这确实是必需的。 |
要将本地 Maven 缓存声明为存储库,请将其添加到您的构建脚本中:
repositories {
mavenLocal()
}repositories {
mavenLocal()
}Gradle 使用与 Maven 相同的逻辑来识别本地 Maven 缓存的位置。如果在 a 中定义了本地存储库位置settings.xml,则将使用该位置。 in优先于settings.xmlin 。如果没有可用的位置,Gradle 将使用默认位置。<home directory of the current user>/.m2settings.xmlM2_HOME/confsettings.xml<home directory of the current user>/.m2/repository
mavenLocal() 的情况
作为一般建议,您应该避免添加mavenLocal()为存储库。mavenLocal()您应该注意使用中的不同问题:
-
Maven 将其用作缓存,而不是存储库,这意味着它可以包含部分模块。
-
例如,如果 Maven 从未下载过给定模块的源文件或 javadoc 文件,Gradle 也不会找到它们,因为一旦找到模块,它就会在单个存储库中搜索文件。
-
-
作为本地存储库,Gradle 不信任其内容,因为:
-
无法追踪工件的来源,这是一个正确性和安全性问题
-
工件很容易被覆盖,这是一个安全性、正确性和再现性问题
-
-
为了减轻元数据和/或工件可以更改的事实,Gradle 不会对本地存储库执行任何缓存
-
因此,你的构建速度会变慢
-
鉴于存储库的顺序很重要,
mavenLocal()首先添加意味着您的所有构建都会变慢
-
在某些情况下您可能需要使用mavenLocal():
-
为了与 Maven 互操作
-
例如,项目A使用Maven构建,项目B使用Gradle构建,开发过程中需要共享工件
-
最好使用内部全功能存储库
-
如果这是不可能的,您应该仅限于本地构建
-
-
与 Gradle 本身的互操作性
-
在多存储库世界中,您想要检查项目 A 的更改是否适用于项目 B
-
对于此用例,最好使用复合构建
-
如果由于某种原因,复合构建和全功能存储库都不可能,那么这
mavenLocal()是最后的选择
-
在所有这些警告之后,如果您最终使用mavenLocal(),请考虑将其与存储库过滤器结合起来。这将确保它只提供预期的内容,而不提供其他内容。
常春藤存储库
组织可能决定将依赖项托管在内部 Ivy 存储库中。 Gradle 可以通过 URL 声明 Ivy 存储库。
使用标准布局定义 Ivy 存储库
要使用标准布局声明 Ivy 存储库,不需要额外的自定义。您只需声明 URL 即可。
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
}
}repositories {
ivy {
url "http://repo.mycompany.com/repo"
}
}为 Ivy 存储库定义命名布局
您可以使用命名布局来指定您的存储库符合 Ivy 或 Maven 默认布局。
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
layout("maven")
}
}repositories {
ivy {
url "http://repo.mycompany.com/repo"
layout "maven"
}
}有效的命名布局值为'gradle'(默认值)'maven'和'ivy'。有关这些命名布局的详细信息,请参阅API 文档中的IvyArtifactRepository.layout(java.lang.String) 。
为 Ivy 存储库定义自定义模式布局
要定义具有非标准布局的 Ivy 存储库,您可以为存储库定义模式布局:
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
patternLayout {
artifact("[module]/[revision]/[type]/[artifact].[ext]")
}
}
}repositories {
ivy {
url "http://repo.mycompany.com/repo"
patternLayout {
artifact "[module]/[revision]/[type]/[artifact].[ext]"
}
}
}要定义从不同位置获取 Ivy 文件和工件的 Ivy 存储库,您可以定义单独的模式以用于定位 Ivy 文件和工件:
为存储库指定的每个artifact或指定都会添加一个要使用的附加模式。这些模式按照定义的顺序使用。ivy
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
patternLayout {
artifact("3rd-party-artifacts/[organisation]/[module]/[revision]/[artifact]-[revision].[ext]")
artifact("company-artifacts/[organisation]/[module]/[revision]/[artifact]-[revision].[ext]")
ivy("ivy-files/[organisation]/[module]/[revision]/ivy.xml")
}
}
}repositories {
ivy {
url "http://repo.mycompany.com/repo"
patternLayout {
artifact "3rd-party-artifacts/[organisation]/[module]/[revision]/[artifact]-[revision].[ext]"
artifact "company-artifacts/[organisation]/[module]/[revision]/[artifact]-[revision].[ext]"
ivy "ivy-files/[organisation]/[module]/[revision]/ivy.xml"
}
}
}或者,具有模式布局的存储库可以将其'organisation'部分以 Maven 风格布局,并用正斜杠替换点作为分隔符。例如,该组织my.company将表示为my/company。
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
patternLayout {
artifact("[organisation]/[module]/[revision]/[artifact]-[revision].[ext]")
setM2compatible(true)
}
}
}repositories {
ivy {
url "http://repo.mycompany.com/repo"
patternLayout {
artifact "[organisation]/[module]/[revision]/[artifact]-[revision].[ext]"
m2compatible = true
}
}
}访问经过身份验证的 Ivy 存储库
您可以指定受基本身份验证保护的 Ivy 存储库的凭据。
repositories {
ivy {
url = uri("http://repo.mycompany.com")
credentials {
username = "user"
password = "password"
}
}
}repositories {
ivy {
url "http://repo.mycompany.com"
credentials {
username "user"
password "password"
}
}
}有关身份验证选项,请参阅支持的存储库传输协议。
存储库内容过滤
Gradle 公开一个 API 来声明存储库可能包含或不包含的内容。它有不同的用例:
-
性能,当您知道在特定存储库中永远找不到依赖项时
-
安全性,避免泄露私有项目中使用的依赖项
-
可靠性,当某些存储库包含损坏的元数据或工件时
当考虑到存储库的声明顺序很重要时,这一点甚至更为重要。
声明存储库过滤器
repositories {
maven {
url = uri("https://repo.mycompany.com/maven2")
content {
// this repository *only* contains artifacts with group "my.company"
includeGroup("my.company")
}
}
mavenCentral {
content {
// this repository contains everything BUT artifacts with group starting with "my.company"
excludeGroupByRegex("my\\.company.*")
}
}
}repositories {
maven {
url "https://repo.mycompany.com/maven2"
content {
// this repository *only* contains artifacts with group "my.company"
includeGroup "my.company"
}
}
mavenCentral {
content {
// this repository contains everything BUT artifacts with group starting with "my.company"
excludeGroupByRegex "my\\.company.*"
}
}
}默认情况下,存储库包含所有内容且不排除任何内容:
-
如果您声明包含,那么它会排除除包含内容之外的所有内容。
-
如果您声明排除,则它包括除排除之外的所有内容。
-
如果您同时声明包含和排除,则它仅包含显式包含但未排除的内容。
可以通过显式的group、module或version进行过滤,无论是严格的还是使用正则表达式。当使用严格版本时,可以使用版本范围,使用Gradle支持的格式。此外,还有按解析上下文的过滤选项:配置名称甚至配置属性。有关详细信息,请参阅RepositoryContentDescriptor。
声明仅在一个存储库中找到的内容
使用存储库级别内容过滤器声明的过滤器不是排他性的。这意味着声明存储库包含工件并不意味着其他存储库也不能拥有它:您必须声明每个存储库在扩展中包含的内容。
或者,Gradle 提供了一个 API,可让您声明存储库专门包含一个工件。如果您这样做:
-
在存储库中声明的工件无法在任何其他存储库中找到
-
专有存储库内容必须在扩展中声明(就像存储库级别内容一样)
repositories {
// This repository will _not_ be searched for artifacts in my.company
// despite being declared first
mavenCentral()
exclusiveContent {
forRepository {
maven {
url = uri("https://repo.mycompany.com/maven2")
}
}
filter {
// this repository *only* contains artifacts with group "my.company"
includeGroup("my.company")
}
}
}repositories {
// This repository will _not_ be searched for artifacts in my.company
// despite being declared first
mavenCentral()
exclusiveContent {
forRepository {
maven {
url "https://repo.mycompany.com/maven2"
}
}
filter {
// this repository *only* contains artifacts with group "my.company"
includeGroup "my.company"
}
}
}可以通过显式的group、module或version进行过滤,无论是严格的还是使用正则表达式。有关详细信息,请参阅InclusiveRepositoryContentDescriptor。
|
笔记
|
您的选择是在设置中声明所有存储库或使用非独占内容过滤。 |
Maven 存储库过滤
对于Maven 存储库,通常情况下存储库将包含版本或快照。 Gradle 允许您使用以下 DSL 声明在存储库中找到了哪种工件:
repositories {
maven {
url = uri("https://repo.mycompany.com/releases")
mavenContent {
releasesOnly()
}
}
maven {
url = uri("https://repo.mycompany.com/snapshots")
mavenContent {
snapshotsOnly()
}
}
}repositories {
maven {
url "https://repo.mycompany.com/releases"
mavenContent {
releasesOnly()
}
}
maven {
url "https://repo.mycompany.com/snapshots"
mavenContent {
snapshotsOnly()
}
}
}支持的元数据源
在存储库中搜索模块时,Gradle 默认情况下会检查该存储库中支持的元数据文件格式。在 Maven 存储库中,Gradle 查找.pom文件,在 ivy 存储库中查找ivy.xml文件,在平面目录存储库中直接查找.jar文件,因为它不需要任何元数据。从 5.0 开始,Gradle 还会查找.module(Gradle 模块元数据)文件。
但是,如果您定义自定义存储库,您可能需要配置此行为。例如,您可以定义一个没有.pom文件而只有 jar 的 Maven 存储库。为此,您可以为任何存储库配置元数据源。
repositories {
maven {
url = uri("http://repo.mycompany.com/repo")
metadataSources {
mavenPom()
artifact()
}
}
}repositories {
maven {
url "http://repo.mycompany.com/repo"
metadataSources {
mavenPom()
artifact()
}
}
}您可以指定多个源来告诉 Gradle 在未找到文件时继续查找。在这种情况下,检查源的顺序是预先定义的。
支持以下元数据源:
| 元数据源 | 描述 | 命令 | 梅文 | 常春藤/平面目录 |
|---|---|---|---|---|
|
查找 Gradle |
第一名 |
是的 |
是的 |
|
查找 Maven |
第二名 |
是的 |
是的 |
|
寻找 |
第二名 |
不 |
是的 |
|
直接寻找神器 |
第三名 |
是的 |
是的 |
Gradle 6.0 中 Ivy 和 Maven 存储库的默认设置发生了变化。在 6.0 之前,artifact()包含在默认值中。当模块完全缺失时会导致效率低下。
例如,要恢复此行为,对于 Maven 中心,您可以使用:
mavenCentral { metadataSources { mavenPom(); artifact() } }以类似的方式,您可以使用以下命令选择旧 Gradle 版本中的新行为:
mavenCentral { metadataSources { mavenPom() } }从 Gradle 5.3 开始,当解析元数据文件时,无论是 Ivy 还是 Maven,Gradle 都会寻找一个标记,指示存在匹配的 Gradle 模块元数据文件。如果找到,将使用它将代替 Ivy 或 Maven 文件。
从 Gradle 5.6 开始,您可以通过添加ignoreGradleMetadataRedirection()到metadataSources 声明来禁用此行为。
repositories {
maven {
url = uri("http://repo.mycompany.com/repo")
metadataSources {
mavenPom()
artifact()
ignoreGradleMetadataRedirection()
}
}
}repositories {
maven {
url "http://repo.mycompany.com/repo"
metadataSources {
mavenPom()
artifact()
ignoreGradleMetadataRedirection()
}
}
}插件存储库与构建存储库
Gradle 将在构建过程中的两个不同阶段使用存储库。
第一阶段是配置构建并加载它应用的插件。为此,Gradle 将使用一组特殊的存储库。
第二阶段是依赖解析期间。此时 Gradle 将使用项目中声明的存储库,如前面部分所示。
插件存储库
默认情况下,Gradle 将使用Gradle 插件门户来查找插件。
但是,由于不同的原因,其他(公共或非公共)存储库中也有可用的插件。当构建需要这些插件之一时,需要指定其他存储库,以便 Gradle 知道在哪里搜索。
由于声明存储库的方式及其预期包含的内容取决于插件的应用方式,因此最好参考 自定义插件存储库。
集中存储库声明
allprojectsGradle 提供了一种在所有项目的中心位置声明存储库的方法,而不是在构建的每个子项目中或通过块声明存储库。
|
笔记
|
存储库的集中声明是一个孵化功能。 |
每个子项目中按惯例使用的存储库可以在settings.gradle(.kts)文件中声明:
dependencyResolutionManagement {
repositories {
mavenCentral()
}
}dependencyResolutionManagement {
repositories {
mavenCentral()
}
}存储dependencyResolutionManagement库块接受与项目中相同的符号。这包括 Maven 或 Ivy 存储库,有或没有凭证等。
默认情况下,项目声明的存储库build.gradle(.kts)将覆盖声明的任何内容settings.gradle(.kts):
dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.PREFER_PROJECT
}dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.PREFER_PROJECT
}依赖解析管理有以下三种模式:
| 模式 | 描述 | 默认? | 用例 |
|---|---|---|---|
|
项目上声明的任何存储库都会导致项目使用该项目声明的存储库,忽略设置中声明的存储库。 |
是的 |
当团队需要使用子项目中不常见的不同存储库时非常有用。 |
|
直接在项目中声明的任何存储库(无论是直接声明还是通过插件声明)都将被忽略。 |
不 |
对于强制大型团队仅使用批准的存储库很有用,但当项目或插件声明存储库时不会使构建失败。 |
|
直接在项目中声明的任何存储库(无论是直接声明还是通过插件声明)都将触发构建错误。 |
不 |
对于强制大型团队仅使用批准的存储库很有用。 |
settings.gradle(.kts)您可以使用以下命令更改行为以首选文件中的存储库repositoriesMode:
dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.PREFER_SETTINGS
}dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.PREFER_SETTINGS
}如果项目或插件在项目中声明了存储库,Gradle 会警告您。
如果您想强制只使用设置存储库,您可以强制 Gradle 使构建失败:
dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.FAIL_ON_PROJECT_REPOS
}dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.FAIL_ON_PROJECT_REPOS
}支持的存储库传输协议
Maven 和 Ivy 存储库支持使用各种传输协议。目前支持以下协议:
| 类型 | 凭证类型 | 关联 |
|---|---|---|
|
没有任何 |
|
|
用户名密码 |
|
|
用户名密码 |
|
|
用户名密码 |
|
|
访问密钥/秘密密钥/会话令牌或环境变量 |
|
|
来自众所周知的文件、环境变量等的默认应用程序凭据。 |
|
笔记
|
用户名和密码永远不应该作为构建文件的一部分以纯文本形式签入版本控制。您可以将凭证存储在本地gradle.properties文件中,并使用开源 Gradle 插件之一来加密和使用凭证,例如凭证插件。
|
传输协议是存储库 URL 定义的一部分。以下构建脚本演示了如何创建基于 HTTP 的 Maven 和 Ivy 存储库:
repositories {
maven {
url = uri("http://repo.mycompany.com/maven2")
}
ivy {
url = uri("http://repo.mycompany.com/repo")
}
}repositories {
maven {
url "http://repo.mycompany.com/maven2"
}
ivy {
url "http://repo.mycompany.com/repo"
}
}以下示例显示如何声明 SFTP 存储库:
repositories {
maven {
url = uri("sftp://repo.mycompany.com:22/maven2")
credentials {
username = "user"
password = "password"
}
}
ivy {
url = uri("sftp://repo.mycompany.com:22/repo")
credentials {
username = "user"
password = "password"
}
}
}repositories {
maven {
url "sftp://repo.mycompany.com:22/maven2"
credentials {
username "user"
password "password"
}
}
ivy {
url "sftp://repo.mycompany.com:22/repo"
credentials {
username "user"
password "password"
}
}
}使用 AWS S3 支持的存储库时,您需要使用AwsCredentials进行身份验证,提供访问密钥和私钥。以下示例展示了如何声明 S3 支持的存储库并提供 AWS 凭证:
repositories {
maven {
url = uri("s3://myCompanyBucket/maven2")
credentials(AwsCredentials::class) {
accessKey = "someKey"
secretKey = "someSecret"
// optional
sessionToken = "someSTSToken"
}
}
ivy {
url = uri("s3://myCompanyBucket/ivyrepo")
credentials(AwsCredentials::class) {
accessKey = "someKey"
secretKey = "someSecret"
// optional
sessionToken = "someSTSToken"
}
}
}repositories {
maven {
url "s3://myCompanyBucket/maven2"
credentials(AwsCredentials) {
accessKey "someKey"
secretKey "someSecret"
// optional
sessionToken "someSTSToken"
}
}
ivy {
url "s3://myCompanyBucket/ivyrepo"
credentials(AwsCredentials) {
accessKey "someKey"
secretKey "someSecret"
// optional
sessionToken "someSTSToken"
}
}
}您还可以使用 AwsImAuthentication 将所有凭证委托给 AWS sdk。以下示例显示了如何操作:
repositories {
maven {
url = uri("s3://myCompanyBucket/maven2")
authentication {
create<AwsImAuthentication>("awsIm") // load from EC2 role or env var
}
}
ivy {
url = uri("s3://myCompanyBucket/ivyrepo")
authentication {
create<AwsImAuthentication>("awsIm")
}
}
}repositories {
maven {
url "s3://myCompanyBucket/maven2"
authentication {
awsIm(AwsImAuthentication) // load from EC2 role or env var
}
}
ivy {
url "s3://myCompanyBucket/ivyrepo"
authentication {
awsIm(AwsImAuthentication)
}
}
}当使用 Google Cloud Storage 支持的存储库时,将使用默认应用程序凭据,无需进一步配置:
repositories {
maven {
url = uri("gcs://myCompanyBucket/maven2")
}
ivy {
url = uri("gcs://myCompanyBucket/ivyrepo")
}
}repositories {
maven {
url "gcs://myCompanyBucket/maven2"
}
ivy {
url "gcs://myCompanyBucket/ivyrepo"
}
}HTTP(S) 身份验证方案配置
使用 HTTP 或 HTTPS 传输协议配置存储库时,可以使用多种身份验证方案。默认情况下,Gradle 将尝试使用 Apache HttpClient 库支持的所有方案(此处记录)。在某些情况下,在与远程服务器交换凭证时,最好明确指定应使用哪些身份验证方案。当显式声明时,在对远程存储库进行身份验证时仅使用这些方案。
您可以使用PasswordCredentials为受基本身份验证保护的 Maven 存储库指定凭据。
repositories {
maven {
url = uri("http://repo.mycompany.com/maven2")
credentials {
username = "user"
password = "password"
}
}
}repositories {
maven {
url "http://repo.mycompany.com/maven2"
credentials {
username "user"
password "password"
}
}
}以下示例显示如何将存储库配置为仅使用DigestAuthentication:
repositories {
maven {
url = uri("https://repo.mycompany.com/maven2")
credentials {
username = "user"
password = "password"
}
authentication {
create<DigestAuthentication>("digest")
}
}
}repositories {
maven {
url 'https://repo.mycompany.com/maven2'
credentials {
username "user"
password "password"
}
authentication {
digest(DigestAuthentication)
}
}
}目前支持的认证方案有:
- 基本身份验证
-
通过 HTTP 的基本访问身份验证。使用此方案时,会抢先发送凭证。
- 摘要验证
-
通过 HTTP 进行摘要式访问身份验证。
- HttpHeader认证
-
基于任何自定义 HTTP 标头的身份验证,例如私有令牌、OAuth 令牌等。
使用抢占式身份验证
Gradle 的默认行为是仅当服务器以 HTTP 401 响应形式响应身份验证质询时才提交凭据。在某些情况下,服务器将使用不同的代码进行响应(例如,对于 GitHub 上托管的存储库,返回 404),导致依赖项解析失败。为了解决此问题,可以先将凭据发送到服务器。要启用抢占式身份验证,只需配置您的存储库以显式使用BasicAuthentication方案:
repositories {
maven {
url = uri("https://repo.mycompany.com/maven2")
credentials {
username = "user"
password = "password"
}
authentication {
create<BasicAuthentication>("basic")
}
}
}repositories {
maven {
url 'https://repo.mycompany.com/maven2'
credentials {
username "user"
password "password"
}
authentication {
basic(BasicAuthentication)
}
}
}使用 HTTP 标头身份验证
您可以使用HttpHeaderCredentials和HttpHeaderAuthentication为需要令牌、OAuth2 或其他基于 HTTP 标头的身份验证的安全 Maven 存储库指定任何 HTTP 标头。
repositories {
maven {
url = uri("http://repo.mycompany.com/maven2")
credentials(HttpHeaderCredentials::class) {
name = "Private-Token"
value = "TOKEN"
}
authentication {
create<HttpHeaderAuthentication>("header")
}
}
}repositories {
maven {
url "http://repo.mycompany.com/maven2"
credentials(HttpHeaderCredentials) {
name = "Private-Token"
value = "TOKEN"
}
authentication {
header(HttpHeaderAuthentication)
}
}
}AWS S3 存储库配置
S3 配置属性
以下系统属性可用于配置与 s3 存储库的交互:
org.gradle.s3.endpoint-
用于在使用非 AWS、S3 API 兼容的存储服务时覆盖 AWS S3 终端节点。
org.gradle.s3.maxErrorRetry-
指定在 S3 服务器响应 HTTP 5xx 状态代码时重试请求的最大次数。如果未指定,则使用默认值 3。
S3 URL 格式
S3 URL 是“虚拟托管样式”,并且必须采用以下格式
s3://<bucketName>[.<regionSpecificEndpoint>]/<s3Key>
例如s3://myBucket.s3.eu-central-1.amazonaws.com/maven/release
-
myBucket是 AWS S3 存储桶名称。 -
s3.eu-central-1.amazonaws.com是可选的 区域特定端点。 -
/maven/release是 AWS S3 密钥(存储桶中对象的唯一标识符)
S3 代理设置
可以使用以下系统属性配置 S3 代理:
-
https.proxyHost -
https.proxyPort -
https.proxyUser -
https.proxyPassword -
http.nonProxyHosts(注意:这不是拼写错误。)
如果org.gradle.s3.endpoint已使用 HTTP(而非 HTTPS)URI 指定属性,则可以使用以下系统代理设置:
-
http.proxyHost -
http.proxyPort -
http.proxyUser -
http.proxyPassword -
http.nonProxyHosts
AWS S3 V4 签名 (AWS4-HMAC-SHA256)
某些 AWS S3 区域(eu-central-1 - 法兰克福)要求所有 HTTP 请求均按照 AWS 的签名版本 4进行签名。当使用需要 V4 签名的存储桶时,建议指定包含区域特定端点的 S3 URL。例如
s3://somebucket.s3.eu-central-1.amazonaws.com/maven/release
当未为需要 V4 签名的存储桶指定特定于区域的终端节点时,Gradle 将使用默认 AWS 区域 (us-east-1),并且控制台上将显示以下警告:
Attempting to re-send the request to .... with AWS V4 authentication. To avoid this warning in the future, use region-specific endpoint to access buckets located in regions that require V4 signing.未能为需要 V4 签名的存储桶指定特定于区域的端点意味着:
-
每次文件上传和下载需要 3 次往返 AWS,而不是一次。
-
根据位置 - 网络延迟增加且构建速度变慢。
-
传输失败的可能性增加。
AWS S3 跨账户访问
某些组织可能拥有多个 AWS 账户,例如每个团队一个。存储桶所有者的 AWS 账户通常与工件发布者和消费者不同。存储桶所有者需要能够授予消费者访问权限,否则工件将只能由发布者的帐户使用。这是通过将bucket-owner-full-control 预设 ACL添加到上传的对象来完成的。 Gradle 会在每次上传时执行此操作。确保发布者直接或通过假定的 IAM 角色(取决于您的情况)拥有所需的 IAM 权限PutObjectAcl(并且如果启用了存储桶版本控制)。PutObjectVersionAcl您可以在AWS S3 访问权限中了解更多信息。
Google 云存储存储库配置
GCS 配置属性
以下系统属性可用于配置与Google Cloud Storage存储库的交互:
org.gradle.gcs.endpoint-
用于在使用非 Google Cloud Platform、Google Cloud Storage API 兼容的存储服务时覆盖 Google Cloud Storage 端点。
org.gradle.gcs.servicePath-
用于覆盖 Google Cloud Storage 客户端构建请求的 Google Cloud Storage 根服务路径,默认为
/.
GCS URL 格式
Google Cloud Storage URL 为“虚拟托管样式”,并且必须采用以下格式gcs://<bucketName>/<objectKey>
例如gcs://myBucket/maven/release
-
myBucket是 Google Cloud Storage 存储桶名称。 -
/maven/release是 Google Cloud Storage 密钥(存储桶中对象的唯一标识符)
处理凭证
存储库凭据永远不应该成为构建脚本的一部分,而应该保留在外部。 Gradle在工件存储库中提供了一个 API ,允许您仅声明所需凭据的类型。 在需要凭证值的构建过程中,会从Gradle 属性中查找凭证值。
例如,给定存储库配置:
repositories {
maven {
name = "mySecureRepository"
credentials(PasswordCredentials::class)
// url = uri(<<some repository url>>)
}
}repositories {
maven {
name = 'mySecureRepository'
credentials(PasswordCredentials)
// url = uri(<<some repository url>>)
}
}mySecureRepositoryUsername将从和属性中查找用户名和密码mySecureRepositoryPassword。
请注意,配置属性前缀(身份)是根据存储库名称确定的。然后可以通过 Gradle 属性支持的任何方式提供凭据 -
gradle.properties文件、命令行参数、环境变量或这些选项的组合。
另请注意,仅当调用的构建需要凭据时才需要凭据。例如,如果项目配置为将工件发布到安全存储库,但构建不会调用发布任务,则 Gradle 将不需要提供发布凭据。另一方面,如果构建需要在某个时刻执行需要凭据的任务,Gradle 将首先检查凭据是否存在,并且如果知道构建稍后会失败,则不会开始运行任何任务,因为缺少凭据。
这是一个可下载的示例,更详细地演示了该概念。
仅表 19中列出的凭据支持查找。
| 类型 | 争论 | 基础属性名称 | 必需的? |
|---|---|---|---|
|
|
必需的 |
|
|
|
必需的 |
|
|
|
必需的 |
|
|
|
必需的 |
|
|
|
选修的 |
|
|
|
必需的 |
|
|
|
必需的 |
声明依赖关系
在查看依赖项声明本身之前,需要定义依赖项配置的概念。
什么是依赖配置
为 Gradle 项目声明的每个依赖项都适用于特定范围。例如,一些依赖项应该用于编译源代码,而其他依赖项只需要在运行时可用。 Gradle 在Configuration的帮助下表示依赖项的范围。每个配置都可以通过唯一的名称来标识。
许多 Gradle 插件都会向您的项目添加预定义的配置。例如,Java 插件添加配置来表示源代码编译、执行测试等所需的各种类路径。有关示例,请参阅Java 插件章节。

有关使用配置来导航、检查和后处理分配的依赖项的元数据和工件的更多示例,请查看解析结果 API。
配置继承和组合
一个配置可以扩展其他配置以形成继承层次结构。子配置继承为其任何超级配置声明的整套依赖项。
配置继承被 Gradle 核心插件(例如Java 插件)大量使用。例如,testImplementation配置扩展implementation配置。配置层次结构有一个实际目的:编译测试需要在编写测试类所需的依赖项之上添加被测源代码的依赖项。使用 JUnit 编写和执行测试代码的 Java 项目如果在生产源代码中导入其类,也需要 Guava。

在底层,配置testImplementation通过implementation调用方法Configuration.extendsFrom(org.gradle.api.artifacts.Configuration[])形成继承层次结构。配置可以扩展任何其他配置,无论其在构建脚本或插件中的定义如何。
假设您想编写一套冒烟测试。每个冒烟测试都会进行 HTTP 调用来验证 Web 服务端点。该项目已经使用 JUnit 作为底层测试框架。您可以定义一个名为的新配置smokeTest,该配置从testImplementation配置扩展以重用现有的测试框架依赖项。
val smokeTest by configurations.creating {
extendsFrom(configurations.testImplementation.get())
}
dependencies {
testImplementation("junit:junit:4.13")
smokeTest("org.apache.httpcomponents:httpclient:4.5.5")
}configurations {
smokeTest.extendsFrom testImplementation
}
dependencies {
testImplementation 'junit:junit:4.13'
smokeTest 'org.apache.httpcomponents:httpclient:4.5.5'
}可解析和消耗性配置
配置是 Gradle 中依赖解析的基本部分。在依赖性解析的上下文中,区分消费者和生产者很有用。沿着这些思路,配置至少有 3 个不同的角色:
-
声明依赖关系
-
作为消费者,解决一组对文件的依赖关系
-
作为生产者,公开工件及其依赖项以供其他项目使用(此类消耗性配置通常代表生产者向其消费者提供的变体)
例如,要表达一个应用程序app 依赖于library lib,至少需要一项配置:
// declare a "configuration" named "someConfiguration"
val someConfiguration by configurations.creating
dependencies {
// add a project dependency to the "someConfiguration" configuration
someConfiguration(project(":lib"))
}configurations {
// declare a "configuration" named "someConfiguration"
someConfiguration
}
dependencies {
// add a project dependency to the "someConfiguration" configuration
someConfiguration project(":lib")
}配置可以通过扩展来继承其他配置的依赖关系。现在,请注意,上面的代码没有告诉我们有关此配置的预期使用者的任何信息。特别是,它没有告诉我们如何使用该配置。假设这lib是一个 Java 库:它可能会公开不同的内容,例如 API、实现或测试装置。可能有必要app根据我们正在执行的任务(根据 的 API 进行编译lib、执行应用程序、编译测试等)来更改解决依赖关系的方式。为了解决这个问题,您经常会找到配套配置,它们旨在明确声明用法:
configurations {
// declare a configuration that is going to resolve the compile classpath of the application
compileClasspath {
extendsFrom(someConfiguration)
}
// declare a configuration that is going to resolve the runtime classpath of the application
runtimeClasspath {
extendsFrom(someConfiguration)
}
}configurations {
// declare a configuration that is going to resolve the compile classpath of the application
compileClasspath.extendsFrom(someConfiguration)
// declare a configuration that is going to resolve the runtime classpath of the application
runtimeClasspath.extendsFrom(someConfiguration)
}此时,我们有 3 种不同的配置,具有不同的角色:
-
someConfiguration声明我的应用程序的依赖项。它只是依赖项的集合。 -
compileClasspath和是要解析的runtimeClasspath配置:解析后它们应分别包含应用程序的编译类路径和运行时类路径。
canBeResolved这种区别由类型中的标志来表示Configuration。可以解析的配置是我们可以计算依赖图的配置,因为它包含解析发生的所有必要信息。也就是说,我们将计算依赖图,解析图中的组件,并最终获得工件。已canBeResolved设置为 的配置false并不意味着将被解析。这样的配置只是为了声明依赖关系。原因是根据使用情况(编译类路径、运行时类路径),它可以解析为不同的图。尝试解析已canBeResolved设置为 的配置是错误的false。在某种程度上,这类似于不应该被实例化的抽象类( = false ) 和扩展抽象类 ( = true ) 的具体类。可解析配置将扩展至少一种不可解析配置(并且可以扩展多个)。canBeResolvedcanBeResolved
另一方面,在库项目端(生产者),我们也使用配置来表示可以使用的内容。例如,库可能会公开 API 或运行时,我们会将工件附加到其中之一、另一个或两者。通常,要针对 进行编译lib,我们需要 的 API lib,但不需要其运行时依赖项。因此该lib项目将公开一个apiElements配置,该配置针对寻找其 API 的消费者。这样的配置是可消耗的,但并不意味着要解决。这是通过a 的canBeConsumedConfiguration标志来表达的:
configurations {
// A configuration meant for consumers that need the API of this component
create("exposedApi") {
// This configuration is an "outgoing" configuration, it's not meant to be resolved
isCanBeResolved = false
// As an outgoing configuration, explain that consumers may want to consume it
assert(isCanBeConsumed)
}
// A configuration meant for consumers that need the implementation of this component
create("exposedRuntime") {
isCanBeResolved = false
assert(isCanBeConsumed)
}
}configurations {
// A configuration meant for consumers that need the API of this component
exposedApi {
// This configuration is an "outgoing" configuration, it's not meant to be resolved
canBeResolved = false
// As an outgoing configuration, explain that consumers may want to consume it
assert canBeConsumed
}
// A configuration meant for consumers that need the implementation of this component
exposedRuntime {
canBeResolved = false
assert canBeConsumed
}
}canBeResolved简而言之,配置的角色由和canBeConsumed标志组合确定:
配置角色 |
可以解决 |
可以食用 |
依赖范围 |
错误的 |
错误的 |
解决特定用途 |
真的 |
错误的 |
暴露给消费者 |
错误的 |
真的 |
旧版,请勿使用 |
真的 |
真的 |
为了向后兼容,两个标志都有一个默认值true,但作为插件作者,您应该始终确定这些标志的正确值,否则您可能会意外地引入解析错误。
为依赖项选择正确的配置
选择声明依赖项的配置非常重要。然而,没有固定的规则依赖项必须进入哪个配置。它主要取决于配置的组织方式,这通常是所应用插件的属性。
例如,在java插件中,创建的配置被记录下来,并且应该作为根据其在代码中的角色确定在何处声明依赖项的基础。
作为建议,插件应清楚地记录其配置链接在一起的方式,并应尽可能努力隔离其角色。
已弃用的配置
配置旨在用于单个角色:声明依赖项、执行解析或定义可使用的变体。过go,某些配置没有定义它们的用途。当以非预期方式使用配置时,会发出弃用警告。要修复弃用问题,您需要停止使用已弃用角色中的配置。所需的确切更改取决于配置的使用方式以及是否存在应使用的替代配置。
定义自定义配置
您可以自己定义配置,即所谓的自定义配置。自定义配置对于分离专用目的所需的依赖关系范围非常有用。
假设您想要声明对Jasper Ant 任务的依赖关系,以便预编译 JSP 文件,这些文件不应出现在编译源代码的类路径中。通过引入自定义配置并在任务中使用它来实现该目标相当简单。
val jasper by configurations.creating
repositories {
mavenCentral()
}
dependencies {
jasper("org.apache.tomcat.embed:tomcat-embed-jasper:9.0.2")
}
tasks.register("preCompileJsps") {
val jasperClasspath = jasper.asPath
val projectLayout = layout
doLast {
ant.withGroovyBuilder {
"taskdef"("classname" to "org.apache.jasper.JspC",
"name" to "jasper",
"classpath" to jasperClasspath)
"jasper"("validateXml" to false,
"uriroot" to projectLayout.projectDirectory.file("src/main/webapp").asFile,
"outputDir" to projectLayout.buildDirectory.file("compiled-jsps").get().asFile)
}
}
}configurations {
jasper
}
repositories {
mavenCentral()
}
dependencies {
jasper 'org.apache.tomcat.embed:tomcat-embed-jasper:9.0.2'
}
tasks.register('preCompileJsps') {
def jasperClasspath = configurations.jasper.asPath
def projectLayout = layout
doLast {
ant.taskdef(classname: 'org.apache.jasper.JspC',
name: 'jasper',
classpath: jasperClasspath)
ant.jasper(validateXml: false,
uriroot: projectLayout.projectDirectory.file('src/main/webapp').asFile,
outputDir: projectLayout.buildDirectory.file("compiled-jsps").get().asFile)
}
}您可以使用对象管理项目配置configurations。配置有一个名称并且可以相互扩展。要了解有关此 API 的更多信息,请查看ConfigurationContainer。
不同类型的依赖关系
模块依赖
模块依赖是最常见的依赖。它们引用存储库中的模块。
dependencies {
runtimeOnly(group = "org.springframework", name = "spring-core", version = "2.5")
runtimeOnly("org.springframework:spring-aop:2.5")
runtimeOnly("org.hibernate:hibernate:3.0.5") {
isTransitive = true
}
runtimeOnly(group = "org.hibernate", name = "hibernate", version = "3.0.5") {
isTransitive = true
}
}dependencies {
runtimeOnly group: 'org.springframework', name: 'spring-core', version: '2.5'
runtimeOnly 'org.springframework:spring-core:2.5',
'org.springframework:spring-aop:2.5'
runtimeOnly(
[group: 'org.springframework', name: 'spring-core', version: '2.5'],
[group: 'org.springframework', name: 'spring-aop', version: '2.5']
)
runtimeOnly('org.hibernate:hibernate:3.0.5') {
transitive = true
}
runtimeOnly group: 'org.hibernate', name: 'hibernate', version: '3.0.5', transitive: true
runtimeOnly(group: 'org.hibernate', name: 'hibernate', version: '3.0.5') {
transitive = true
}
}有关更多示例和完整参考,请参阅API 文档中的DependencyHandler类。
Gradle 为模块依赖项提供了不同的表示法。有字符串符号和地图符号。模块依赖项有一个允许进一步配置的 API。查看ExternalModuleDependency以了解有关 API 的所有信息。该API提供属性和配置方法。通过字符串表示法,您可以定义属性的子集。使用地图符号,您可以定义所有属性。要使用映射或字符串表示法访问完整的 API,您可以将单个依赖项与闭包一起分配给配置。
|
笔记
|
如果您声明模块依赖项,Gradle 会在存储库中查找模块元数据文件( |
|
重要的
|
在 Maven 中,一个模块只能有一个工件。 在 Gradle 和 Ivy 中,一个模块可以有多个工件。每个工件可以有一组不同的依赖关系。 |
文件依赖关系
项目有时不依赖二进制存储库产品(例如 JFrog Artifactory 或 Sonatype Nexus)来托管和解决外部依赖项。通常的做法是将这些依赖项托管在共享驱动器上,或者将它们与项目源代码一起签入版本控制。这些依赖项被称为文件依赖项,原因是它们代表一个没有附加任何元数据(如有关传递依赖项、来源或其作者的信息)的文件。

以下示例解析目录ant、libs和中的文件依赖性tools。
configurations {
create("antContrib")
create("externalLibs")
create("deploymentTools")
}
dependencies {
"antContrib"(files("ant/antcontrib.jar"))
"externalLibs"(files("libs/commons-lang.jar", "libs/log4j.jar"))
"deploymentTools"(fileTree("tools") { include("*.exe") })
}configurations {
antContrib
externalLibs
deploymentTools
}
dependencies {
antContrib files('ant/antcontrib.jar')
externalLibs files('libs/commons-lang.jar', 'libs/log4j.jar')
deploymentTools(fileTree('tools') { include '*.exe' })
}正如您在代码示例中看到的,每个依赖项都必须定义其在文件系统中的确切位置。创建文件引用最重要的方法是 Project.files(java.lang.Object…)、 ProjectLayout.files(java.lang.Object…) 和Project.fileTree(java.lang.Object) 或者,您可以还以平面目录存储库的形式定义一个或多个文件依赖项的源目录。
|
笔记
|
a 中的文件顺序 |
文件依赖项允许您直接将一组文件添加到配置中,而无需先将它们添加到存储库中。如果您不能或不想将某些文件放入存储库中,这会很有用。或者,如果您根本不想使用任何存储库来存储依赖项。
要添加一些文件作为配置的依赖项,您只需将文件集合作为依赖项传递即可:
dependencies {
runtimeOnly(files("libs/a.jar", "libs/b.jar"))
runtimeOnly(fileTree("libs") { include("*.jar") })
}dependencies {
runtimeOnly files('libs/a.jar', 'libs/b.jar')
runtimeOnly fileTree('libs') { include '*.jar' }
}文件依赖项不包含在项目的已发布依赖项描述符中。但是,文件依赖项包含在同一构建内的传递项目依赖项中。这意味着它们不能在当前构建之外使用,但可以在同一构建内使用。
您可以声明哪些任务为文件依赖项生成文件。例如,当文件由构建生成时,您可以执行此操作。
dependencies {
implementation(files(layout.buildDirectory.dir("classes")) {
builtBy("compile")
})
}
tasks.register("compile") {
doLast {
println("compiling classes")
}
}
tasks.register("list") {
val compileClasspath: FileCollection = configurations["compileClasspath"]
dependsOn(compileClasspath)
doLast {
println("classpath = ${compileClasspath.map { file: File -> file.name }}")
}
}dependencies {
implementation files(layout.buildDirectory.dir('classes')) {
builtBy 'compile'
}
}
tasks.register('compile') {
doLast {
println 'compiling classes'
}
}
tasks.register('list') {
FileCollection compileClasspath = configurations.compileClasspath
dependsOn compileClasspath
doLast {
println "classpath = ${compileClasspath.collect { File file -> file.name }}"
}
}$ gradle -q list compiling classes classpath = [classes]
文件依赖项的版本控制
建议明确表达文件依赖关系的意图和具体版本。 Gradle 的版本冲突解决不考虑文件依赖关系。因此,为文件名分配一个版本以指示其附带的不同更改集非常重要。例如,commons-beanutils-1.3.jar让您可以通过发行说明跟踪库的更改。
因此,项目的依赖关系更容易维护和组织。通过分配的版本更容易发现潜在的 API 不兼容性。
项目依赖
软件项目通常将软件组件分解为模块,以提高可维护性并防止强耦合。模块可以定义彼此之间的依赖关系,以便在同一项目中重用代码。

Gradle 可以对模块之间的依赖关系进行建模。这些依赖项称为项目依赖项,因为每个模块都由一个 Gradle 项目表示。
dependencies {
implementation(project(":shared"))
}dependencies {
implementation project(':shared')
}在运行时,构建会自动确保项目依赖项以正确的顺序构建并添加到类路径中进行编译。创作多项目构建一章更详细地讨论了如何设置和配置多项目构建。
有关更多信息,请参阅ProjectDependency的 API 文档。
以下示例声明了项目对utils和api项目的依赖关系web-service。方法Project.project(java.lang.String)通过路径创建对特定子项目的引用。
dependencies {
implementation(project(":utils"))
implementation(project(":api"))
}dependencies {
implementation project(':utils')
implementation project(':api')
}类型安全的项目依赖项
类型安全的项目访问器是一项必须显式启用的孵化功能。实施可能随时改变。
要添加对类型安全项目访问器的支持,请将其添加到您的settings.gradle(.kts)文件中:
enableFeaturePreview("TYPESAFE_PROJECT_ACCESSORS")该表示法的一个问题project(":some:path")是您必须记住您想要依赖的每个项目的路径。另外,更改项目路径需要您更改所有使用项目依赖项的地方,但很容易错过一个或多个出现的地方(因为您必须依赖于搜索和替换)。
从 Gradle 7 开始,Gradle 为项目依赖项提供了一个实验性的类型安全 API。与上面相同的示例现在可以重写为:
dependencies {
implementation(projects.utils)
implementation(projects.api)
}dependencies {
implementation projects.utils
implementation projects.api
}类型安全 API 的优点是提供 IDE 完成功能,因此您无需弄清楚项目的实际名称。
如果您添加或删除使用 Kotlin DSL 的项目,并且忘记更新依赖项,构建脚本编译将会失败。
项目访问器是从项目路径映射的。例如,如果项目路径为,:commons:utils:some:lib则项目访问器将为projects.commons.utils.some.lib(这是 的简写符号projects.getCommons().getUtils().getSome().getLib())。
some-lib带有 kebab case ( ) 或 Snake case ( )的项目名称some_lib将在访问器中转换为驼峰式大小写:projects.someLib。
Gradle 发行版特定的依赖项
Gradle API 依赖
您可以使用DependencyHandler.gradleApi()方法声明对当前版本 Gradle 的 API 的依赖关系。当您开发自定义 Gradle 任务或插件时,这非常有用。
dependencies {
implementation(gradleApi())
}dependencies {
implementation gradleApi()
}Gradle TestKit 依赖项
您可以使用 DependencyHandler.gradleTestKit ()方法声明对当前版本 Gradle 的 TestKit API 的依赖项。这对于编写和执行 Gradle 插件和构建脚本的功能测试非常有用。
dependencies {
testImplementation(gradleTestKit())
}dependencies {
testImplementation gradleTestKit()
}TestKit章节通过示例解释了TestKit的使用。
本地 Groovy 依赖
您可以使用DependencyHandler.localGroovy()方法声明对随 Gradle 分发的 Groovy 的依赖项。当您在 Groovy 中开发自定义 Gradle 任务或插件时,这非常有用。
dependencies {
implementation(localGroovy())
}dependencies {
implementation localGroovy()
}记录依赖关系
plugins {
`java-library`
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.ow2.asm:asm:7.1") {
because("we require a JDK 9 compatible bytecode generator")
}
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
implementation('org.ow2.asm:asm:7.1') {
because 'we require a JDK 9 compatible bytecode generator'
}
}示例:使用具有自定义原因的依赖性洞察报告
gradle -q dependencyInsight --dependency asm> gradle -q dependencyInsight --dependency asm
org.ow2.asm:asm:7.1
Variant compile:
| Attribute Name | Provided | Requested |
|--------------------------------|----------|--------------|
| org.gradle.status | release | |
| org.gradle.category | library | library |
| org.gradle.libraryelements | jar | classes |
| org.gradle.usage | java-api | java-api |
| org.gradle.dependency.bundling | | external |
| org.gradle.jvm.environment | | standard-jvm |
| org.gradle.jvm.version | | 11 |
Selection reasons:
- Was requested: we require a JDK 9 compatible bytecode generator
org.ow2.asm:asm:7.1
\--- compileClasspath
A web-based, searchable dependency report is available by adding the --scan option.
解决模块依赖项中的特定工件
每当 Gradle 尝试解析 Maven 或 Ivy 存储库中的模块时,它都会查找元数据文件和默认工件文件(JAR)。如果无法解析这些工件文件,则构建将失败。在某些情况下,您可能需要调整 Gradle 解析依赖项的工件的方式。
-
该依赖项仅提供不带任何元数据(例如 ZIP 文件)的非标准工件。
-
模块元数据声明多个工件,例如作为 Ivy 依赖描述符的一部分。
-
您只想下载特定的工件,而无需在元数据中声明任何传递依赖项。
Gradle 是一种多语言构建工具,不仅限于解析 Java 库。假设您想要使用 JavaScript 作为客户端技术来构建 Web 应用程序。大多数项目将外部 JavaScript 库签入版本控制。外部 JavaScript 库与可重用 Java 库没有什么不同,那么为什么不从存储库下载它呢?
Google Hosted Libraries是流行的开源 JavaScript 库的分发平台。借助仅工件符号,您可以下载 JavaScript 库文件,例如 JQuery。该@字符将依赖项的坐标与工件的文件扩展名分开。
repositories {
ivy {
url = uri("https://ajax.googleapis.com/ajax/libs")
patternLayout {
artifact("[organization]/[revision]/[module].[ext]")
}
metadataSources {
artifact()
}
}
}
configurations {
create("js")
}
dependencies {
"js"("jquery:jquery:3.2.1@js")
}repositories {
ivy {
url 'https://ajax.googleapis.com/ajax/libs'
patternLayout {
artifact '[organization]/[revision]/[module].[ext]'
}
metadataSources {
artifact()
}
}
}
configurations {
js
}
dependencies {
js 'jquery:jquery:3.2.1@js'
}某些模块提供同一工件的不同“风格”,或者它们发布属于特定模块版本但具有不同用途的多个工件。 Java 库通常会发布包含已编译类文件的工件,另一个库仅包含源代码,第三个库包含 Javadoc。
在 JavaScript 中,库可能以未压缩或缩小的工件形式存在。在 Gradle 中,特定的工件标识符称为classifier,该术语通常用于 Maven 和 Ivy 依赖项管理。
假设我们想要下载 JQuery 库的缩小版而不是未压缩的文件。您可以提供分类器min作为依赖项声明的一部分。
repositories {
ivy {
url = uri("https://ajax.googleapis.com/ajax/libs")
patternLayout {
artifact("[organization]/[revision]/[module](.[classifier]).[ext]")
}
metadataSources {
artifact()
}
}
}
configurations {
create("js")
}
dependencies {
"js"("jquery:jquery:3.2.1:min@js")
}repositories {
ivy {
url 'https://ajax.googleapis.com/ajax/libs'
patternLayout {
artifact '[organization]/[revision]/[module](.[classifier]).[ext]'
}
metadataSources {
artifact()
}
}
}
configurations {
js
}
dependencies {
js 'jquery:jquery:3.2.1:min@js'
}支持的元数据格式
外部模块依赖项需要模块元数据(因此,通常,Gradle 可以找出模块的传递依赖项)。为此,Gradle 支持不同的元数据格式。
您还可以调整在存储库定义中查找的格式。
Gradle 模块元数据文件
Gradle 模块元数据经过专门设计,支持 Gradle 依赖管理模型的所有功能,因此是首选格式。您可以在此处找到其规格。
POM文件
Gradle 原生支持Maven POM 文件。值得注意的是,默认情况下 Gradle 将首先查找 POM 文件,但如果该文件包含特殊标记,Gradle 将改用Gradle 模块元数据。
常春藤档案
同样,Gradle 支持Apache Ivy 元数据文件。同样,Gradle 将首先查找一个ivy.xml文件,但如果该文件包含特殊标记,Gradle 将使用Gradle 模块元数据。
了解库和应用程序之间的区别
生产者与消费者
Gradle 依赖管理的一个关键概念是消费者和生产者之间的区别。
当您构建库时,您实际上是生产者一方:您正在生产将被其他人(即消费者)使用的工件。
传统构建系统的许多问题是它们无法区分生产者和消费者。
消费者需要从广义上理解:
-
依赖于另一个项目的项目是消费者
-
依赖于工件的任务是更细粒度的消费者
生产者变种
生产者可能希望为不同类型的消费者生成不同的工件:对于相同的源代码,会生成不同的二进制文件。或者,一个项目可能会生成供其他项目(同一存储库)使用但不供外部使用的工件。
Java 世界中的一个典型例子是 Guava 库,它发布了不同的版本:一个用于 Java 项目,一个用于 Android 项目。
但是,消费者有责任告知要使用哪个版本,依赖管理引擎有责任确保图的一致性(例如,确保您的类路径上不会同时出现 Java 和 Android 版本的 Guava) 。这就是Gradle变体模型发挥作用的地方。
在 Gradle 中,生产者变体通过消耗品配置公开。
封装性强
为了让生产者编译库,它需要编译类路径上的所有实现依赖项。有些依赖项仅需要作为库的实现细节,有些库实际上是 API 的一部分。
然而,依赖于这个生成的库的库只需要“查看”您的库的公共 API 以及该 API 的依赖项。它是生产者的编译类路径的子集:这是依赖项的强封装。
结果是分配给implementation库配置的依赖项不会最终出现在使用者的编译类路径上。另一方面,分配给api库配置的依赖项最终将出现在消费者的编译类路径上。然而,在运行时,所有依赖项都是必需的。即使在单个项目中,Gradle 也会区分不同类型的使用者:例如,Java 编译任务与 Java 执行任务是不同的使用者。
有关 Java 世界中 API 和运行时依赖项隔离的更多详细信息,请参见此处。
尊重消费者
作为开发人员,每当您决定包含依赖项时,您都必须了解这会给您的消费者带来后果。例如,如果您向项目添加依赖项,它就会成为使用者的传递依赖项,因此如果使用者需要不同的版本,则可能会参与冲突解决。
Gradle 处理的许多问题都是为了解决消费者和生产者期望之间的不匹配问题。
然而,有些项目比其他项目更容易:
请始终记住,您选择解决问题的解决方案可能会“泄漏”给您的消费者。本文档旨在指导您找到正确问题的正确解决方案,更重要的是,做出有助于解决引擎在发生冲突时做出正确决策的决策。
查看和调试依赖关系
Gradle 提供了导航依赖关系图和缓解依赖地狱的工具。用户可以呈现完整的依赖关系图,并确定依赖关系的选择原因和来源。依赖关系可以通过构建脚本声明的依赖关系或传递依赖关系产生。您可以使用以下方式可视化依赖关系:
-
内置 Gradle CLI
dependencies任务 -
内置 Gradle CLI
dependencyInsight任务
列出项目依赖项
dependenciesGradle 提供了从命令行渲染依赖关系树的内置任务。默认情况下,依赖关系树呈现单个项目中所有配置的依赖关系。依赖关系树指示每个依赖关系的选定版本。它还显示有关依赖项冲突解决的信息。
该dependencies任务对于与传递依赖项相关的问题特别有帮助。您的构建文件列出了直接依赖项,但该dependencies任务可以帮助您了解构建期间解决了哪些传递依赖项。
|
笔记
|
配置中声明的buildscript classpath
依赖关系图可以使用任务buildEnvironment来呈现。
|
输出注释
该dependencies任务使用以下注释标记依赖关系树:
指定依赖配置
要重点关注有关一个依赖项配置的信息,请提供可选参数--configuration。就像项目和任务名称一样,Gradle 接受缩写名称来选择依赖项配置。例如,您可以指定模式tRC是否testRuntimeClasspath与单个依赖项配置匹配。以下两个示例显示了testRuntimeClasspathJava 项目的依赖项配置中的依赖项:
> gradle -q dependencies --configuration testRuntimeClasspath
> gradle -q dependencies --configuration tRC
要查看项目中所有可用配置的列表(包括由任何插件添加的配置),您可以运行报告resolvableConfigurations。
有关更多信息,请参阅该插件的文档(例如,Java 插件记录在此处)。
例子
考虑一个使用JGit 库来执行发布过程的源代码控制管理 (SCM) 操作的项目。您可以借助自定义依赖项配置来声明外部工具的依赖项。这可以避免污染其他上下文,例如生产源代码的编译类路径。
以下示例声明一个名为“scm”的自定义依赖项配置,其中包含 JGit 依赖项:
repositories {
mavenCentral()
}
configurations {
create("scm")
}
dependencies {
"scm"("org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r")
}repositories {
mavenCentral()
}
configurations {
scm
}
dependencies {
scm 'org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r'
}使用以下命令查看scm依赖关系配置的依赖关系树:
> gradle -q dependencies --configuration scm
------------------------------------------------------------
Root project 'dependencies-report'
------------------------------------------------------------
scm
\--- org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r
+--- com.jcraft:jsch:0.1.54
+--- com.googlecode.javaewah:JavaEWAH:1.1.6
+--- org.apache.httpcomponents:httpclient:4.3.6
| +--- org.apache.httpcomponents:httpcore:4.3.3
| +--- commons-logging:commons-logging:1.1.3
| \--- commons-codec:commons-codec:1.6
\--- org.slf4j:slf4j-api:1.7.2
A web-based, searchable dependency report is available by adding the --scan option.
确定所选的依赖项版本
项目可以直接或传递地请求同一依赖项的两个不同版本。 Gradle 应用版本冲突解决方案来确保依赖关系图中仅存在一个版本的依赖关系。以下示例引入了与 的冲突commons-codec:commons-codec,添加为 JGit 的直接依赖项和传递依赖项:
repositories {
mavenCentral()
}
configurations {
create("scm")
}
dependencies {
"scm"("org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r")
"scm"("commons-codec:commons-codec:1.7")
}repositories {
mavenCentral()
}
configurations {
scm
}
dependencies {
scm 'org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r'
scm 'commons-codec:commons-codec:1.7'
}构建扫描中的依赖关系树显示有关冲突的信息。单击依赖项并选择“Required By”选项卡以查看依赖项的选择原因和来源。
依赖性洞察
Gradle 提供了内置任务来从命令行dependencyInsight呈现依赖关系洞察报告。依赖关系洞察提供有关单个配置中的单个依赖关系的信息。给定依赖关系,您可以确定选择原因和来源。
dependencyInsight接受以下参数:
--dependency <dependency>(强制的)-
要调查的依赖性。您可以提供完整的
group:name或部分的。如果多个依赖项匹配,Gradle 会生成一份涵盖所有匹配依赖项的报告。 --configuration <name>(强制的)-
解决给定依赖关系的依赖关系配置。对于使用Java 插件的项目,此参数是可选的,因为该插件提供了默认值
compileClasspath。 --single-path(选修的)-
仅渲染依赖项的单个路径。
以下代码片段演示了如何针对“scm”配置中名为“commons-codec”的依赖项的所有路径运行依赖项洞察报告:
> gradle -q dependencyInsight --dependency commons-codec --configuration scm
commons-codec:commons-codec:1.7
Variant default:
| Attribute Name | Provided | Requested |
|-------------------|----------|-----------|
| org.gradle.status | release | |
Selection reasons:
- By conflict resolution: between versions 1.7 and 1.6
commons-codec:commons-codec:1.7
\--- scm
commons-codec:commons-codec:1.6 -> 1.7
\--- org.apache.httpcomponents:httpclient:4.3.6
\--- org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r
\--- scm
A web-based, searchable dependency report is available by adding the --scan option.
有关配置的更多信息,请参阅依赖配置文档。
选择理由
依赖项洞察报告的“选择原因”部分列出了选择依赖项的原因。查看下表以了解所使用的不同术语的含义:
| 原因 | 意义 |
|---|---|
(缺席的) |
除了直接或传递的引用之外,没有其他任何原因。 |
请求:<文本> |
依赖关系出现在图中,并且包含内容带有 |
已请求:与版本 <versions> 不匹配 |
依赖项以动态版本显示,但不包括列出的版本。后面可能会附有一段 |
被请求:拒绝版本 <versions> |
该依赖项以包含一个或多个 |
通过冲突解决:版本 <version> 之间 |
该依赖项出现多次,并具有不同的版本请求。这导致解决冲突以选择最合适的版本。 |
通过约束 |
依赖约束参与了版本选择。后面可能会附有一段 |
由祖先 |
有一个丰富的版本,它 |
按规则选择 |
依赖性解析规则推翻了默认选择过程。后面可能会附有一段 |
拒绝:按规则 <version> 因为 <text> |
A |
拒绝:版本<版本>:<属性信息> |
|
被迫 |
构建通过强制平台或解析策略强制实施依赖项的版本。 |
如果存在多个选择原因,洞察报告会列出所有原因。
故障排除
不安全配置解析错误
解析配置可能会对 Gradle 的项目模型产生副作用。因此,Gradle 必须管理对每个项目配置的访问。有多种方法可以不安全地解析配置。例如:
-
一个项目中的任务直接在任务操作中解析另一个项目中的配置。
-
任务将另一个项目的配置指定为输入文件集合。
-
一个项目的构建脚本在评估期间解析另一个项目中的配置。
-
项目配置在设置文件中解决。
Gradle 会为每次不安全访问生成弃用警告。不安全的访问可能会导致不确定的错误。您应该修复构建中的不安全访问警告。
在大多数情况下,您可以通过创建对其他项目的跨项目依赖关系来解决不安全访问。有关更多信息,请参阅有关在项目之间共享输出的文档。
如果您发现使用这些技术无法解决的用例,请通过提交GitHub Issue告知我们。
了解依赖解析
依赖解析是一个由两个阶段组成的过程,这两个阶段会重复进行,直到依赖图完成:
-
当新的依赖项添加到图中时,执行冲突解决以确定应将哪个版本添加到图中。
-
当特定依赖项(即具有版本的模块)被识别为图的一部分时,检索其元数据,以便可以依次添加其依赖项。
以下部分将描述 Gradle 识别的冲突以及它如何自动解决这些冲突。之后,将介绍元数据的检索,解释 Gradle 如何跟踪依赖关系链接。
Gradle 如何处理冲突?
在进行依赖项解析时,Gradle 会处理两种类型的冲突:
- 版本冲突
-
即两个或多个依赖项需要给定依赖项但具有不同版本的情况。
- 实施冲突
-
也就是说,依赖关系图包含多个提供相同实现或 Gradle 术语中的功能的模块。
以下部分将详细解释 Gradle 如何尝试解决这些冲突。
依赖性解析过程是高度可定制的,可以满足企业需求。有关更多信息,请参阅控制传递依赖性一章。
版本冲突解决
当两个组件出现以下情况时,就会发生版本冲突:
-
依赖同一个模块,比方说
com.google.guava:guava -
但在不同的版本上,我们可以
20.0说25.1-android-
我们的项目本身取决于
com.google.guava:guava:20.0 -
我们的项目还取决于
com.google.inject:guice:4.2.2哪个本身取决于com.google.guava:guava:25.1-android
-
解决策略
鉴于上述冲突,有多种方法可以处理它,要么选择版本,要么失败解决。处理依赖关系管理的不同工具有不同的方法来处理这些类型的冲突。
Apache Maven使用最近优先策略。
Maven 将采用到依赖项的最短路径并使用该版本。如果有多条长度相同的路径,则第一个路径获胜。
这意味着在上面的示例中,guavawill 的版本是20.0因为直接依赖关系比依赖关系更接近guice。
该方法的主要缺点是它依赖于顺序。在非常大的图中保持顺序可能是一个挑战。例如,如果依赖项的新版本最终具有其自己的依赖项声明,其顺序与先前版本不同怎么办?
对于 Maven,这可能会对已解析的版本产生不必要的影响。
|
笔记
|
Apache Ivy是一个非常灵活的依赖管理工具。它提供了自定义依赖性解决方案的可能性,包括冲突解决方案。 这种灵活性的代价是难以推理。 |
Gradle 将考虑所有请求的版本,无论它们出现在依赖关系图中的任何位置。在这些版本中,它将选择最高的版本。有关版本订购的更多信息, 请参见此处。
正如您所看到的,Gradle 支持丰富版本声明的概念,因此最高版本取决于版本声明的方式:
-
如果不涉及范围,则选择未被拒绝的最高版本。
-
如果声明的版本
strictly低于该版本,选择将失败。
-
-
如果涉及范围:
-
如果存在落在指定范围内或高于其上限的非范围版本,则会选择该版本。
-
如果只有范围,则选择将取决于范围的交集:
-
如果所有范围相交,则将选择交集的现有最高版本。
-
如果所有范围之间没有明确的交集,将从最高范围中选择现有的最高版本。如果没有适用于最高范围的版本,分辨率将会失败。
-
-
如果声明的版本
strictly低于该版本,选择将失败。
-
请注意,在范围发挥作用的情况下,Gradle 需要元数据来确定所考虑的范围确实存在哪些版本。这会导致元数据的中间查找,如Gradle 如何检索依赖项元数据?中所述。 。
预选赛
在选择最高版本时,需要比较版本。所有版本排序规则仍然适用,但冲突解决程序偏向于没有限定符的版本。
版本的“限定符”(如果存在)是版本字符串的尾部,从其中找到的第一个非点分隔符开始。版本字符串的另一(第一)部分称为版本的“基本形式”。下面举一些例子来说明:
| 原版 | 基础版本 | 预选赛 |
|---|---|---|
1.2.3 |
1.2.3 |
<无> |
1.2-3 |
1.2 |
3 |
1_阿尔法 |
1 |
α |
ABC |
ABC |
<无> |
1.2b3 |
1.2 |
b3 |
abc.1+3 |
abc.1 |
3 |
b1-2-3.3 |
乙 |
1-2-3.3 |
正如您所看到的,分隔符是任何., -, _,+字符,加上版本的数字和非数字部分彼此相邻时的空字符串。
解决竞争版本之间的冲突时,适用以下逻辑:
-
首先选择具有最高基础版本的版本,其余的被丢弃
-
如果仍然存在多个竞争版本,则优先选择没有资格赛或具有发布状态的版本。
实施冲突解决
Gradle 使用变体和功能来识别模块提供的内容。
这是一个独特的功能,值得单独用一章来理解它的含义和功能。
当两个模块出现以下任一情况时就会发生冲突:
-
尝试选择不兼容的变体,
-
声明相同的能力
在“在候选人之间进行选择”中了解有关处理此类冲突的更多信息。
Gradle 如何检索依赖元数据?
Gradle 需要有关依赖关系图中包含的模块的元数据。需要这些信息的主要有两点:
-
当声明的版本是动态的时,确定模块的现有版本。
-
确定给定版本的模块的依赖关系。
发现版本
面对动态版本,Gradle需要识别具体的匹配版本:
-
检查每个存储库,Gradle 不会在第一个返回一些元数据时停止。当定义多个时,将按照添加的顺序检查它们。
-
对于 Maven 存储库,Gradle 将使用它
maven-metadata.xml提供有关可用版本的信息。 -
对于 Ivy 存储库,Gradle 将诉诸目录列表。
此过程会产生候选版本列表,然后将其与所表达的动态版本进行匹配。至此,版本冲突解决重新开始。
请注意,Gradle 会缓存版本信息,更多信息可以在控制动态版本缓存部分中找到。
获取模块元数据
给定所需的依赖项和版本,Gradle 尝试通过搜索依赖项指向的模块来解决依赖项。
-
每个存储库都按顺序进行检查。
-
根据存储库的类型,Gradle 查找描述模块的元数据文件(或
.module文件)或直接查找工件文件。.pomivy.xml -
具有模块元数据文件(或文件)的模块
.module优先于仅具有工件文件的模块.pom。ivy.xml -
一旦存储库返回元数据结果,以下存储库将被忽略。
-
-
检索并解析依赖项的元数据(如果找到)
-
如果模块元数据是声明了父 POM 的 POM 文件,Gradle 将递归尝试解析 POM 的每个父模块。
-
-
然后,从在上述过程中选择的同一存储库请求该模块的所有工件。
-
然后,所有这些数据(包括存储库源和潜在的缺失)都存储在依赖项缓存中。
|
笔记
|
上面的倒数第二点可能会导致与Maven Local的集成出现问题。由于它是 Maven 的缓存,因此有时会丢失给定模块的一些工件。如果 Gradle 从 Maven Local 采购这样的模块,它将认为丢失的工件完全丢失。 |
依赖缓存
Gradle 包含高度复杂的依赖项缓存机制,该机制旨在最大限度地减少依赖项解析中发出的远程请求的数量,同时努力保证依赖项解析的结果是正确且可重现的。
Gradle 依赖项缓存由两种存储类型组成,位于:$GRADLE_USER_HOME/caches
-
基于文件的下载工件存储,包括 jar 等二进制文件以及 POM 文件和 Ivy 文件等原始下载元数据。下载工件的存储路径包含 SHA1 校验和,这意味着可以轻松缓存 2 个具有相同名称但内容不同的工件。
-
已解析模块元数据的二进制存储,包括解析动态版本、模块描述符和工件的结果。
Gradle 缓存不允许本地缓存隐藏问题并创建其他神秘且难以调试的行为。 Gradle 支持可靠且可重复的企业构建,重点关注带宽和存储效率。
独立的元数据缓存
Gradle 在元数据缓存中以二进制格式保存依赖关系解析的各个方面的记录。元数据缓存中存储的信息包括:
-
1.+将动态版本(例如)解析为具体版本(例如)的结果1.2。 -
特定模块的已解析模块元数据,包括模块工件和模块依赖项。
-
特定工件的解析工件元数据,包括指向下载的工件文件的指针。
-
特定存储库中缺少特定模块或工件,从而消除了重复尝试访问不存在的资源的情况。
元数据缓存中的每个条目都包含提供信息的存储库的记录以及可用于缓存到期的时间戳。
存储库缓存是独立的
如上所述,每个存储库都有一个单独的元数据缓存。存储库由其 URL、类型和布局来标识。如果之前未从该存储库解析某个模块或工件,Gradle 将尝试根据该存储库解析该模块。这始终涉及对存储库的远程查找,但在许多情况下不需要下载。
如果所需的工件在构建指定的任何存储库中不可用,即使本地缓存具有从不同存储库检索的该工件的副本,依赖关系解析也会失败。存储库独立性允许构建以以前没有构建工具做过的高级方式彼此隔离。这是创建在任何环境中可靠且可重现的构建的关键功能。
工件复用
在下载工件之前,Gradle 尝试通过下载与该工件关联的 sha 文件来确定所需工件的校验和。如果可以检索校验和,并且已存在具有相同 ID 和校验和的工件,则不会下载工件。如果无法从远程服务器检索校验和,则将下载工件(如果与现有工件匹配,则忽略该工件)。
除了考虑从不同存储库下载的工件之外,Gradle 还将尝试重用本地 Maven 存储库中找到的工件。如果 Maven 下载了候选工件,并且可以验证该工件是否与远程服务器声明的校验和相匹配,则 Gradle 将使用该工件。
基于校验和的存储
不同的存储库可以响应相同的工件标识符来提供不同的二进制工件。 Maven SNAPSHOT 工件经常出现这种情况,但对于任何在不更改其标识符的情况下重新发布的工件也可能如此。通过根据 SHA1 校验和缓存工件,Gradle 能够维护同一工件的多个版本。这意味着当针对一个存储库进行解析时,Gradle 永远不会覆盖来自不同存储库的缓存工件文件。完成此操作不需要每个存储库单独的工件文件存储。
处理短暂的构建
在临时容器中运行构建是一种常见的做法。容器通常生成后仅执行一次构建,然后被销毁。当构建依赖于每个容器必须重新下载的大量依赖项时,这可能会成为一个实际问题。为了帮助解决这种情况,Gradle 提供了几个选项:
复制并重用缓存
依赖项缓存(文件和元数据部分)均使用相对路径进行完全编码。这意味着完全可以复制缓存并让 Gradle 从中受益。
可以复制的路径是$GRADLE_USER_HOME/caches/modules-<version>。唯一的限制是在目的地使用相同的结构,其中 的值GRADLE_USER_HOME可以不同。
*.lock如果或gc.properties文件存在,请勿复制。
请注意,创建缓存并使用它应该使用兼容的 Gradle 版本来完成,如下表所示。否则,构建可能仍需要与远程存储库进行一些交互才能完成缺失的信息,这些信息可能在不同的版本中可用。如果正在使用多个不兼容的 Gradle 版本,则在播种缓存时应使用所有版本。
| 模块缓存版本 | 文件缓存版本 | 元数据缓存版本 | Gradle 版本 |
|---|---|---|---|
|
|
|
Gradle 6.1 到 Gradle 6.3 |
|
|
|
Gradle 6.4 到 Gradle 6.7 |
|
|
|
Gradle 6.8 到 Gradle 7.4 |
|
|
|
Gradle 7.5 到 Gradle 7.6.1 |
|
|
|
摇篮7.6.2 |
|
|
|
摇篮8.0 |
|
|
|
摇篮8.1 |
|
|
|
等级 8.2 及以上 |
与其他 Gradle 实例共享依赖项缓存
无需将依赖项缓存复制到每个容器中,而是可以挂载一个共享的只读目录,该目录将充当所有容器的依赖项缓存。与经典的依赖项缓存不同,此缓存的访问无需锁定,从而可以同时从缓存中读取多个构建。重要的是,当其他构建可能正在读取只读缓存时,不要写入只读缓存。
使用共享只读缓存时,Gradle 会在本地 Gradle 用户主目录中的可写缓存和共享只读缓存中查找依赖项(工件或元数据)。如果只读缓存中存在依赖项,则不会下载该依赖项。如果只读缓存中缺少依赖项,则会下载该依赖项并将其添加到可写缓存中。实际上,这意味着可写缓存将仅包含只读缓存中不可用的依赖项。
只读缓存应源自已包含一些所需依赖项的 Gradle 依赖项缓存。缓存可能不完整;然而,空的共享缓存只会增加开销。
|
笔记
|
共享只读依赖项缓存是一项正在孵化的功能。 |
使用共享依赖项缓存的第一步是通过复制现有本地缓存来创建共享依赖项缓存。为此,您需要按照上面的说明进行操作。
然后设置GRADLE_RO_DEP_CACHE环境变量指向包含缓存的目录:
$GRADLE_RO_DEP_CACHE
|-- modules-2 : the read-only dependency cache, should be mounted with read-only privileges
$GRADLE_HOME
|-- caches
|-- modules-2 : the container specific dependency cache, should be writable
|-- ...
|-- ...
在 CI 环境中,最好有一个构建“播种”Gradle 依赖项缓存,然后将其复制到另一个目录。然后,该目录可以用作其他构建的只读缓存。您不应该使用现有的 Gradle 安装缓存作为只读缓存,因为该目录可能包含锁并且可能会被种子构建修改。
以编程方式访问解析结果
虽然大多数用户只需要访问文件的“平面列表”,但在某些情况下,在图表上进行推理并获取有关解析结果的更多信息可能会很有趣:
-
对于工具集成,需要依赖图模型
-
用于生成依赖图的视觉表示(图像、
.dot文件……)的任务 -
用于提供诊断的任务(类似于
dependencyInsight任务) -
对于需要在执行时执行依赖性解析的任务(例如,按需下载文件)
对于这些用例,Gradle 提供了惰性、线程安全的 API,可通过调用 Configuration.getIncoming ()方法进行访问:
|
笔记
|
有关如何在任务中使用结果的更多详细信息, 请参阅有关使用依赖项解析结果 的文档。 |
验证依赖关系
使用第三方存储库上发布的外部依赖项和插件会使您的构建面临风险。特别是,您需要了解传递引入的二进制文件以及它们是否合法。为了降低安全风险并避免在项目中集成受损的依赖项,Gradle 支持依赖项验证。
从本质上讲,依赖性验证是一个使用起来不方便的功能。这意味着每当您要更新依赖项时,构建都可能会失败。这意味着合并分支将变得更加困难,因为每个分支可以具有不同的依赖关系。这意味着您会很想将其关闭。
那么你为什么要费心呢?
依赖性验证是关于对您所获得和所交付的内容的信任。
如果没有依赖性验证,攻击者很容易破坏您的供应链。现实世界中有许多工具因添加恶意依赖项而受到损害的例子。依赖性验证旨在通过强制您确保构建中包含的工件是您所期望的工件来保护您自己免受这些攻击。但是,这并不意味着阻止您包含易受攻击的依赖项。
在安全性和便利性之间找到适当的平衡很难,但 Gradle 会尽力让您选择适合您的“正确级别”。
依赖性验证由两个不同且互补的操作组成:
-
校验和验证,允许断言依赖项的完整性
-
签名验证,允许断言依赖项的来源
Gradle 支持开箱即用的校验和和签名验证,但默认情况下不执行依赖项验证。本节将指导您根据需要正确配置依赖项验证。
此功能可用于:
-
检测受损的依赖项
-
检测受损插件
-
检测本地依赖项缓存中被篡改的依赖项
启用依赖性验证
验证元数据文件
|
笔记
|
目前依赖项验证元数据的唯一来源是此 XML 配置文件。 Gradle 的未来版本可能包括其他来源(例如通过外部服务)。 |
一旦发现依赖验证的配置文件,就会自动启用依赖验证。该配置文件位于$PROJECT_ROOT/gradle/verification-metadata.xml.该文件至少包含以下内容:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>false</verify-signatures>
</configuration>
</verification-metadata>-
构建过程中使用的工件文件(例如 jar 文件、zip 等)
-
元数据工件(POM 文件、ivy 描述符、Gradle 模块元数据)
-
插件(项目和设置插件)
-
使用高级依赖项解析 API 解析的工件
Gradle 不会验证更改的依赖项(特别是SNAPSHOT依赖项)或本地生成的工件(通常是在构建本身期间生成的 jar),因为本质上它们的校验和和签名总是会发生变化。
使用这样一个最小的配置文件,使用任何外部依赖项或插件的项目将立即开始失败,因为它不包含任何要验证的校验和。
依赖性验证的范围
依赖项验证配置是全局的:使用单个文件来配置整个构建的验证。特别是,(子)项目和buildSrc.
如果使用包含的版本:
-
当前构建的配置文件用于验证
-
因此,如果包含的构建本身使用验证,则其配置将被忽略,以支持当前配置
-
这意味着包含构建的工作方式与升级依赖项类似:它可能需要您更新当前的验证元数据
因此,一个简单的入门方法是为现有构建生成最小配置。
配置控制台输出
默认情况下,如果依赖项验证失败,Gradle 将生成有关验证失败的小摘要以及包含有关失败的完整信息的 HTML 报告。如果您的环境阻止您阅读此 HTML 报告文件(例如,如果您在 CI 上运行构建并且获取远程工件并不容易),Gradle 提供了一种选择加入详细控制台报告的方法。为此,您需要将此 Gradle 属性添加到您的gradle.properties文件中:
org.gradle.dependency.verification.console=verbose
引导依赖验证
值得一提的是,虽然 Gradle 可以为您生成依赖项验证文件,但您应该始终检查 Gradle 为您生成的任何内容,因为您的构建可能已经包含受损的依赖项,而您却不知道。请参阅相应的校验和验证或签名验证部分以了解更多信息。
引导可以用于从头开始创建文件,也可以使用新信息更新现有文件。因此,建议在开始引导后始终使用相同的参数。
可以使用以下 CLI 指令生成依赖性验证文件:
gradle --write-verification-metadata sha256 help
执行此命令行将导致 Gradle:
-
解析所有可解析的配置,其中包括:
-
来自根项目的配置
-
所有子项目的配置
-
配置来自
buildSrc -
包含的构建配置
-
插件使用的配置
-
-
下载解决过程中发现的所有工件
-
计算请求的校验和并可能根据您的要求验证签名
-
构建结束时,生成配置文件,其中将包含推断的验证元数据
因此,该verification-metadata.xml文件将在后续构建中用于验证依赖关系。
Gradle无法通过这种方式发现某些依赖项。特别是,您会注意到上面的 CLI 使用该help任务。如果您没有指定任何任务,Gradle 将自动运行默认任务并在构建结束时生成配置文件。
不同之处在于,Gradle可能会根据您执行的任务发现更多依赖项和工件。事实上,Gradle 无法自动发现分离的配置,这些配置基本上是解析为任务执行的内部实现细节的依赖图:特别是,它们没有声明为任务的输入,因为它们实际上依赖于任务在执行时的配置。
一个好的开始方法是使用最简单的任务,help它将尽可能多地发现,并且如果后续构建因验证错误而失败,您可以使用适当的任务重新执行生成以“发现”更多依赖项。
Gradle 不会验证使用自己的 HTTP 客户端的插件的校验和或签名。只有使用 Gradle 提供的基础设施来执行请求的插件才会看到其请求经过验证。
使用生成进行增量更新
Gradle生成的验证文件对其所有内容都有严格的排序。它还使用现有状态的信息将更改限制在严格的最低限度。
这意味着生成实际上是更新验证文件的便捷工具:
-
Gradle 生成的校验和条目将有一个明确的
origin开头“由 Gradle 生成”,这是一个很好的指示,表明条目需要审查, -
手动添加的条目将立即被记录,并在写入文件后出现在正确的位置,
-
文件的标头注释将被保留,即根 XML 节点之前的注释。这允许您拥有许可证标头或有关用于生成该文件的任务和参数的说明。
有了上述好处,只需再次生成文件并检查更改,就可以轻松地考虑新的依赖项或依赖项版本。
使用干燥模式
默认情况下,引导是增量的,这意味着如果您多次运行它,信息会添加到文件中,特别是您可以依靠 VCS 来检查差异。在某些情况下,您只想看看生成的验证元数据文件是什么样子,而不实际更改现有文件或覆盖它。
为此,您只需添加--dry-run:
gradle --write-verification-metadata sha256 help --dry-run
然后将生成verification-metadata.xml一个新文件verification-metadata.dryrun.xml,称为.
|
笔记
|
因为--dry-run不执行任务,所以这会快得多,但它会错过任务执行时发生的任何解析。
|
禁用元数据验证
默认情况下,Gradle 不仅会验证工件(jar 等),还会验证与这些工件相关的元数据(通常是 POM 文件)。验证这一点可确保最高级别的安全性:元数据文件通常会告诉将包含哪些传递依赖项,因此受损的元数据文件可能会导致在图中引入不需要的依赖项。但是,由于所有工件都经过验证,因此此类工件通常很容易被您发现,因为它们会导致校验和验证失败(验证元数据中会丢失校验和)。由于元数据验证会显着增加配置文件的大小,因此您可能需要禁用元数据验证。如果您了解这样做的风险,请在配置文件中将<verify-metadata>标志设置为:false
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>false</verify-metadata>
<verify-signatures>false</verify-signatures>
</configuration>
<!-- the rest of this file doesn't need to declare anything about metadata files -->
</verification-metadata>验证依赖性校验和
校验和验证使您能够确保工件的完整性。这是 Gradle 可以为您做的最简单的事情,以确保您使用的工件不被篡改。
Gradle 支持 MD5、SHA1、SHA-256 和 SHA-512 校验和。然而,目前只有 SHA-256 和 SHA-512 校验和被认为是安全的。
添加工件的校验和
外部组件由 GAV 坐标标识,然后每个工件由文件名标识。要声明工件的校验和,您需要在验证元数据文件中添加相应的部分。例如,声明Apache PDFBox的校验和。 GAV 坐标为:
-
团体
org.apache.pdfbox -
姓名
pdfbox -
版本
2.0.17
使用此依赖项将触发 2 个不同文件的下载:
-
pdfbox-2.0.17.jar这是主要的工件 -
pdfbox-2.0.17.pom这是与此工件关联的元数据文件
因此,您需要声明它们的校验和(除非您禁用元数据验证):
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>false</verify-signatures>
</configuration>
<components>
<component group="org.apache.pdfbox" name="pdfbox" version="2.0.17">
<artifact name="pdfbox-2.0.17.jar">
<sha512 value="7e11e54a21c395d461e59552e88b0de0ebaf1bf9d9bcacadf17b240d9bbc29bf6beb8e36896c186fe405d287f5d517b02c89381aa0fcc5e0aa5814e44f0ab331" origin="PDFBox Official site (https://pdfbox.apache.org/download.cgi)"/>
</artifact>
<artifact name="pdfbox-2.0.17.pom">
<sha512 value="82de436b38faf6121d8d2e71dda06e79296fc0f7bc7aba0766728c8d306fd1b0684b5379c18808ca724bf91707277eba81eb4fe19518e99e8f2a56459b79742f" origin="Generated by Gradle"/>
</artifact>
</component>
</components>
</verification-metadata>从哪里获取校验和?
一般来说,校验和与公共存储库上的工件一起发布。但是,如果存储库中的依赖项受到损害,其校验和很可能也会受到损害,因此最好从其他位置(通常是库本身的网站)获取校验和。
事实上,在与托管工件本身的服务器不同的服务器上发布工件的校验和是一种很好的安全实践:在存储库和官方网站上都更难破坏库。
在上面的示例中,JAR 的校验和已发布在网站上,但 POM 文件并未发布。这就是为什么让 Gradle 生成校验和并通过仔细检查生成的文件进行验证通常更容易。
在这个例子中,我们不仅可以检查校验和是否正确,而且还可以在官方网站上找到它,这就是为什么我们将元素origin上的 of 属性的值sha512从更改Generated by Gradle为PDFBox Official site。更改origin可以让用户感觉到您的构建有多值得信赖。
有趣的是,使用pdfbox需要的不仅仅是这两个工件,因为它还会带来传递依赖。如果依赖项验证文件仅包含您使用的主要工件的校验和,则构建将失败并出现如下错误:
Execution failed for task ':compileJava'.
> Dependency verification failed for configuration ':compileClasspath':
- On artifact commons-logging-1.2.jar (commons-logging:commons-logging:1.2) in repository 'MavenRepo': checksum is missing from verification metadata.
- On artifact commons-logging-1.2.pom (commons-logging:commons-logging:1.2) in repository 'MavenRepo': checksum is missing from verification metadata.
这表明您的构建commons-logging在执行时需要compileJava,但是验证文件没有包含足够的信息供 Gradle 验证依赖项的完整性,这意味着您需要将所需的信息添加到验证元数据文件中。
请参阅对依赖项验证进行故障排除,以获取有关在这种情况下该怎么做的更多见解。
验证哪些校验和?
如果依赖项验证元数据文件为依赖项声明了多个校验和,Gradle 将验证所有这些校验和,如果其中任何一个失败,则 Gradle 将失败。例如,以下配置将检查md5和sha1校验和:
<component group="org.apache.pdfbox" name="pdfbox" version="2.0.17">
<artifact name="pdfbox-2.0.17.jar">
<md5 value="c713a8e252d0add65e9282b151adf6b4" origin="official site"/>
<sha1 value="b5c8dff799bd967c70ccae75e6972327ae640d35" origin="official site" reason="Additional check for this artifact"/>
</artifact>
</component>您想要这样做的原因有多种:
-
官方网站不发布安全校验和(SHA-256、SHA-512),但发布多个不安全校验和(MD5、SHA1)。虽然伪造 MD5 校验和很容易,而伪造 SHA1 校验和虽然困难但可能,但对于同一个工件来说,伪造这两种校验和却更困难。
-
您可能想将生成的校验和添加到上面的列表中
-
当使用更安全的校验和更新依赖性验证文件时,您不希望意外删除校验和
验证依赖签名
除了校验和之外,Gradle 还支持签名验证。签名用于评估依赖项的来源(它告诉谁签署了工件,这通常对应于谁生成了它)。
由于启用签名验证通常意味着更高级别的安全性,因此您可能希望用签名验证替换校验和验证。
|
警告
|
与校验和类似,签名也可用于评估依赖项的完整性。签名是工件散列的签名,而不是工件本身。这意味着,如果签名是在不安全的哈希(甚至 SHA1)上完成的,那么您就无法正确评估文件的完整性。因此,如果您同时关心两者,则需要将签名和校验和添加到验证元数据中。 |
然而:
-
Gradle 仅支持验证远程存储库上作为 ASCII 防护 PGP 文件发布的签名
-
并非所有工件都带有签名发布
-
良好的签名并不意味着签名人是合法的
因此,签名验证通常与校验和验证一起使用。
发现使用过期密钥签名的工件是很常见的。这对于验证来说不是问题:密钥过期主要用于避免使用被盗密钥进行签名。如果工件在过期之前签署,它仍然有效。
启用签名验证
由于验证签名的成本更高(I/O 和 CPU 方面)并且更难以手动检查,因此默认情况下不启用它。
启用它需要您更改verification-metadata.xml文件中的配置选项:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-signatures>true</verify-signatures>
</configuration>
</verification-metadata>了解签名验证
启用签名验证后,对于每个工件,Gradle 将:
-
尝试下载对应的
.asc文件 -
如果它存在
-
自动下载执行签名验证所需的密钥
-
使用下载的公钥验证工件
-
如果签名验证通过,则执行额外请求的校验和验证
-
-
如果不存在,则回退到校验和验证
也就是说,如果启用签名验证,Gradle 的验证机制比仅使用校验和验证要强大得多。尤其:
-
如果一个工件使用多个密钥进行签名,则所有密钥都必须通过验证,否则构建将失败
-
如果工件通过验证,还将检查为该工件配置的任何附加校验和
然而,并不是因为工件通过了签名验证,您就可以信任它:您需要信任密钥。
在实践中,这意味着您需要列出您信任的每个工件的密钥,这是通过添加条目pgp而不是添加条目来完成的sha1,例如:
<component group="com.github.javaparser" name="javaparser-core" version="3.6.11">
<artifact name="javaparser-core-3.6.11.jar">
<pgp value="8756c4f765c9ac3cb6b85d62379ce192d401ab61"/>
</artifact>
</component>|
警告
|
对于 目前,V4 密钥指纹的长度为 160 位(40 个字符)。我们接受更长的密钥,以防万一引入更长的密钥指纹。 在 |
这实际上意味着您信任com.github.javaparser:javaparser-core:3.6.11它是否使用密钥签名8756c4f765c9ac3cb6b85d62379ce192d401ab61。
如果没有这个,构建将失败并出现以下错误:
> Dependency verification failed for configuration ':compileClasspath':
- On artifact javaparser-core-3.6.11.jar (com.github.javaparser:javaparser-core:3.6.11) in repository 'MavenRepo': Artifact was signed with key '8756c4f765c9ac3cb6b85d62379ce192d401ab61' (Bintray (by JFrog) <****>) and passed verification but the key isn't in your trusted keys list.
|
笔记
|
Gradle 在错误消息中显示的密钥 ID 是它尝试验证的签名文件中找到的密钥 ID。这并不意味着它一定是您应该信任的密钥。特别是,如果签名正确但由恶意实体完成,Gradle 不会告诉您。 |
全局信任密钥
签名验证的优点是,它可以使依赖性验证的配置变得更容易,因为不必显式列出所有工件(例如仅用于校验和验证)。事实上,相同的密钥可用于对多个工件进行签名是很常见的。如果是这种情况,您可以将可信密钥从工件级别移至全局配置块:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>true</verify-signatures>
<trusted-keys>
<trusted-key id="8756c4f765c9ac3cb6b85d62379ce192d401ab61" group="com.github.javaparser"/>
</trusted-keys>
</configuration>
<components/>
</verification-metadata>上面的配置意味着对于属于该组的任何工件com.github.javaparser,如果它是用8756c4f765c9ac3cb6b85d62379ce192d401ab61指纹签名的,我们就信任它。
该元素的工作方式与trust-artifacttrusted-key元素类似:
-
group,可信任的工件组 -
name,要信任的工件的名称 -
version,要信任的工件版本 -
file,要信任的工件文件的名称 -
regex,一个布尔值,表示、 和group属性name是否需要解释为正则表达式(默认为)versionfilefalse
在全局信任密钥时应该小心。
尝试将其限制为适当的组或工件:
-
有效的密钥可能已用于签署
A您信任的工件 -
后来,密钥被盗并用于签署神器
B
这意味着您可以信任第一个工件的密钥A,可能只能信任密钥被盗之前的发布版本,但不能信任B.
请记住,任何人都可以在生成 PGP 密钥时输入任意名称,因此切勿仅根据密钥名称信任该密钥。验证密钥是否在官方网站上列出。例如,Apache 项目通常会提供您可以信任的 KEYS.txt 文件。
指定密钥服务器并忽略密钥
Gradle 将自动下载验证签名所需的公钥。为此,它使用众所周知且受信任的密钥服务器列表(该列表可能会在 Gradle 版本之间发生变化,请参阅实现以找出默认使用的服务器)。
您可以通过将要使用的密钥服务器添加到配置中来显式设置它们:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>true</verify-signatures>
<key-servers>
<key-server uri="hkp://my-key-server.org"/>
<key-server uri="https://my-other-key-server.org"/>
</key-servers>
</configuration>
</verification-metadata>尽管如此,密钥也可能不可用:
-
因为它没有发布到公钥服务器
-
因为它丢失了
在这种情况下,您可以忽略配置块中的某个键:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>true</verify-signatures>
<ignored-keys>
<ignored-key id="abcdef1234567890" reason="Key is not available in any key server"/>
</ignored-keys>
</configuration>
</verification-metadata>一旦密钥被忽略,即使签名文件提到它,它也不会用于验证。但是,如果无法使用至少一个其他密钥验证签名,Gradle 将要求您提供校验和。
|
笔记
|
如果 Gradle 在引导时无法下载密钥,它会将其标记为忽略。如果您可以找到密钥但 Gradle 找不到,您可以手动将其添加到密钥环文件中。 |
导出密钥以加快验证速度
Gradle 会自动下载所需的密钥,但此操作可能会非常慢,并且需要每个人都下载密钥。为了避免这种情况,Gradle 提供了使用包含所需公钥的本地密钥环文件的功能。请注意,仅存储和使用公钥数据包和每个密钥的单个 userId。所有其他信息(用户属性、签名等)都将从下载或导出的密钥中删除。
Gradle 支持 2 种不同的密钥环文件格式:二进制格式 ( .gpgfile) 和纯文本格式 ( .keys),也称为 ASCII 装甲格式。
每种格式都有优点和缺点:二进制格式更紧凑,可以直接通过 GPG 命令更新,但完全不透明(二进制)。相反,ASCII 装甲格式是人类可读的,可以轻松地手动更新,并且由于可读的差异而使代码审查变得更容易。
您可以通过添加配置选项来配置将使用哪种文件类型keyring-format:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>true</verify-signatures>
<keyring-format>armored</keyring-format>
</configuration>
</verification-metadata>密钥环格式的可用选项有armored和binary。
如果没有keyring-format,如果gradle/verification-keyring.gpg或gradle/verification-keyring.keys文件存在,Gradle 将优先搜索其中的键。如果已有文件,纯文本文件将被忽略.gpg(二进制版本优先)。
您可以要求 Gradle在引导期间将用于验证此构建的所有密钥导出到密钥环:
./gradlew --write-verification-metadata pgp,sha256 --export-keys
除非keyring-format指定,否则此命令将生成二进制版本和 ASCII 防护文件。使用此选项选择首选格式。您应该只为您的项目选择一个。
最好将此文件提交到 VCS(只要您信任您的 VCS)。如果您使用 git 并使用二进制版本,请确保将此文件视为二进制文件,方法是将其添加到您的.gitattributes文件中:
*.gpg binary
您还可以要求 Gradle 导出所有可信密钥而不更新验证元数据文件:
./gradlew --export-keys
|
笔记
|
该命令不会报告验证错误,只会导出密钥。 |
引导和签名验证
|
警告
|
签名验证引导采取乐观的观点,即签名验证就足够了。因此,如果您也关心完整性,则必须首先使用校验和验证进行引导,然后使用签名验证。 |
与校验和引导类似,Gradle 为引导启用签名验证的配置文件提供了便利。为此,只需将该pgp选项添加到要生成的验证列表中即可。但是,由于可能会出现验证失败、密钥丢失或签名文件丢失的情况,因此您必须提供后备校验和验证算法:
./gradlew --write-verification-metadata pgp,sha256
这意味着 Gradle 将验证签名并在出现问题时回退到 SHA-256 校验和。
引导时,Gradle 会执行乐观验证,因此假设有一个健全的构建环境。因此,它将:
-
验证通过后自动添加可信密钥
-
自动为无法从公钥服务器下载的密钥添加忽略的密钥。请参阅此处如何根据需要手动添加密钥
-
自动为没有签名或忽略密钥的工件生成校验和
如果由于某种原因,在生成过程中验证失败,Gradle 将自动生成一个被忽略的密钥条目,但警告您必须绝对检查发生了什么。
这种情况很常见,如本节所述:典型情况是一个依赖项的 POM 文件与另一个存储库不同(通常以一种无意义的方式)。
此外,Gradle 会尝试自动对键进行分组并生成trusted-keys尽可能减少配置文件大小的块。
仅强制使用本地密钥环
本地密钥环文件(.gpg或.keys)可用于避免在需要密钥来验证工件时联系密钥服务器。但是,本地密钥环可能不包含密钥,在这种情况下,Gradle 将使用密钥服务器来获取丢失的密钥。例如,如果本地密钥环文件未使用密钥导出定期更新,那么您的 CI 构建可能会过于频繁地访问密钥服务器(特别是如果您使用一次性容器进行构建)。
为了避免这种情况,Gradle 提供了完全禁止使用密钥服务器的功能:仅使用本地密钥环文件,如果该文件中缺少密钥,则构建将失败。
要启用此模式,您需要在配置文件中禁用密钥服务器:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<key-servers enabled="false"/>
...
</configuration>
...
</verification-metadata>|
笔记
|
如果您要求 Gradle生成验证元数据文件并且现有验证元数据文件设置enabled为false,则该标志将被忽略,以便下载可能丢失的密钥。
|
禁用验证或放宽验证
依赖项验证可能会很昂贵,或者有时验证可能会妨碍日常开发(例如,由于频繁的依赖项升级)。
或者,您可能希望在 CI 服务器上启用验证,但不在本地计算机上启用验证。
Gradle实际上提供了3种不同的验证模式:
-
strict,这是默认值。验证尽早失败,以避免在构建过程中使用受损的依赖项。 -
lenient,即使验证失败也会运行构建。验证错误将在构建过程中显示,而不会导致构建失败。 -
off当验证被完全忽略时。
所有这些模式都可以使用该标志在 CLI 上激活--dependency-verification,例如:
./gradlew --dependency-verification lenient build
或者,您可以org.gradle.dependency.verification在 CLI 上设置系统属性:
./gradlew -Dorg.gradle.dependency.verification=lenient build
或在gradle.properties文件中:
org.gradle.dependency.verification=lenient
仅对某些配置禁用依赖性验证
为了提供尽可能最强的安全级别,全局启用依赖性验证。例如,这将确保您信任您使用的所有插件。但是,插件本身可能需要解决额外的依赖关系,而要求用户接受这些依赖关系是没有意义的。为此,Gradle 提供了一个 API,允许禁用某些特定配置的依赖项验证。
|
警告
|
如果您关心安全性,则禁用依赖项验证并不是一个好主意。这个 API 主要用于检查依赖关系没有意义的情况。但是,为了安全起见,每当特定配置禁用验证时,Gradle 都会系统地打印警告。 |
例如,插件可能想要检查是否有可用的较新版本的库并列出这些版本。在这种情况下,要求用户放置较新版本的 POM 文件的校验和是没有意义的,因为根据定义,他们不知道它们。因此,插件可能需要独立于依赖项验证配置来运行其代码。
为此,您需要调用该ResolutionStrategy#disableDependencyVerification方法:
configurations {
"myPluginClasspath" {
resolutionStrategy {
disableDependencyVerification()
}
}
}configurations {
myPluginClasspath {
resolutionStrategy {
disableDependencyVerification()
}
}
}还可以禁用对分离配置的验证,如下例所示:
tasks.register("checkDetachedDependencies") {
val detachedConf: FileCollection = configurations.detachedConfiguration(dependencies.create("org.apache.commons:commons-lang3:3.3.1")).apply {
resolutionStrategy.disableDependencyVerification()
}
doLast {
println(detachedConf.files)
}
}tasks.register("checkDetachedDependencies") {
def detachedConf = configurations.detachedConfiguration(dependencies.create("org.apache.commons:commons-lang3:3.3.1"))
detachedConf.resolutionStrategy.disableDependencyVerification()
doLast {
println(detachedConf.files)
}
}信任某些特定的工件
您可能比其他工件更愿意信任某些工件。例如,可以合理地认为您公司中生成的、仅在内部存储库中找到的工件是安全的,但您想要检查每个外部组件。
|
笔记
|
这是典型的公司政策。实际上,没有什么可以阻止您的内部存储库受到损害,因此检查您的内部工件也是一个好主意! |
为此,Gradle 提供了一种自动信任某些工件的方法。您可以通过将其添加到配置中来信任组中的所有工件:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<trusted-artifacts>
<trust group="com.mycompany" reason="We trust mycompany artifacts"/>
</trusted-artifacts>
</configuration>
</verification-metadata>这意味着该组所属的所有组件com.mycompany都将自动受到信任。受信任意味着 Gradle 不会执行任何验证。
该trust元素接受这些属性:
-
group,可信任的工件组 -
name,要信任的工件的名称 -
version,要信任的工件版本 -
file,要信任的工件文件的名称 -
regex,一个布尔值,表示、 和group属性name是否需要解释为正则表达式(默认为)versionfilefalse -
reason,一个可选原因,为什么匹配的工件是可信的
在上面的示例中,这意味着受信任的工件将是com.mycompany但不是中的工件com.mycompany.other。要信任com.mycompany所有子组中的所有工件,您可以使用:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<trusted-artifacts>
<trust group="^com[.]mycompany($|([.].*))" regex="true" reason="We trust all mycompany artifacts"/>
</trusted-artifacts>
</configuration>
</verification-metadata>信任工件的多个校验和
在野外,同一工件具有不同的校验和是很常见的。这怎么可能?尽管取得了进展,但开发人员通常会使用不同的版本分别发布到 Maven Central 和另一个存储库。一般来说,这不是问题,但有时这意味着元数据文件会有所不同(不同的时间戳、额外的空格……)。除此之外,您的构建可能会使用多个存储库或存储库镜像,这使得单个构建很可能可以“看到”同一组件的不同元数据文件!一般来说,它不是恶意的(但您必须验证该工件实际上是正确的),因此 Gradle 允许您声明额外的工件校验和。例如:
<component group="org.apache" name="apache" version="13">
<artifact name="apache-13.pom">
<sha256 value="2fafa38abefe1b40283016f506ba9e844bfcf18713497284264166a5dbf4b95e">
<also-trust value="ff513db0361fd41237bef4784968bc15aae478d4ec0a9496f811072ccaf3841d"/>
</sha256>
</artifact>
</component>您可以also-trust根据需要添加任意数量的条目,但一般情况下不应超过 2 个。
跳过 Javadoc 和源代码
默认情况下,Gradle 将验证所有下载的工件,其中包括 Javadoc 和源代码。一般来说,这不是问题,但您可能会遇到 IDE 的问题,这些 IDE 在导入期间会自动尝试下载它们:如果您也没有为这些设置校验和,导入将会失败。
为了避免这种情况,您可以将 Gradle 配置为自动信任所有 javadocs/源:
<trusted-artifacts>
<trust file=".*-javadoc[.]jar" regex="true"/>
<trust file=".*-sources[.]jar" regex="true"/>
</trusted-artifacts>手动将密钥添加到密钥环
将密钥添加到 ASCII 铠装密钥环
添加的密钥必须是 ASCII-armored 格式,并且可以简单地添加到文件末尾。如果您已经以正确的格式下载了密钥,则只需将其附加到文件中即可。
或者您可以通过发出以下命令来修改现有的 KEYS 文件:
$ gpg --no-default-keyring --keyring /tmp/keyring.gpg --recv-keys 8756c4f765c9ac3cb6b85d62379ce192d401ab61
gpg: keybox '/tmp/keyring.gpg' created
gpg: key 379CE192D401AB61: public key "Bintray (by JFrog) <****>" imported
gpg: Total number processed: 1
gpg: imported: 1
# Write its ASCII-armored version
$ gpg --keyring /tmp/keyring.gpg --export --armor 8756c4f765c9ac3cb6b85d62379ce192d401ab61 > gradle/verification-keyring.keys完成后,请确保再次运行生成命令,以便 Gradle 处理密钥。这将执行以下操作:
-
向密钥添加标准标头
-
使用 Gradle 自己的格式重写密钥,这会将密钥修剪到最低限度
-
将密钥移至已排序的位置,保持文件的可重复性
将密钥添加到二进制密钥环
您可以使用 GPG 将密钥添加到二进制版本,例如发出以下命令(语法可能取决于您使用的工具):
$ gpg --no-default-keyring --keyring gradle/verification-keyring.gpg --recv-keys 8756c4f765c9ac3cb6b85d62379ce192d401ab61
gpg: keybox 'gradle/verification-keyring.gpg' created
gpg: key 379CE192D401AB61: public key "Bintray (by JFrog) <****>" imported
gpg: Total number processed: 1
gpg: imported: 1
$ gpg --no-default-keyring --keyring gradle/verification-keyring.gpg --recv-keys 6f538074ccebf35f28af9b066a0975f8b1127b83
gpg: key 0729A0AFF8999A87: public key "Kotlin Release <****>" imported
gpg: Total number processed: 1
gpg: imported: 1处理验证失败
依赖项验证可能会以不同的方式失败,本节说明您应该如何处理各种情况。
缺少验证元数据
最简单的失败是依赖项验证文件中缺少验证元数据。例如,如果您使用校验和验证,则更新依赖项并引入该依赖项的新版本(以及可能的传递依赖项)。
Gradle 会告诉您缺少哪些元数据:
Execution failed for task ':compileJava'.
> Dependency verification failed for configuration ':compileClasspath':
- On artifact commons-logging-1.2.jar (commons-logging:commons-logging:1.2) in repository 'MavenRepo': checksum is missing from verification metadata.
-
缺少的模块组是
commons-logging,其工件名称是commons-logging,其版本是1.2。相应的工件是commons-logging-1.2.jar,因此您需要将以下条目添加到验证文件中:
<component group="commons-logging" name="commons-logging" version="1.2">
<artifact name="commons-logging-1.2.jar">
<sha256 value="daddea1ea0be0f56978ab3006b8ac92834afeefbd9b7e4e6316fca57df0fa636" origin="official distribution"/>
</artifact>
</component>或者,您可以要求 Gradle 使用引导机制生成缺失的信息:元数据文件中的现有信息将被保留,Gradle 只会添加缺失的验证元数据。
校验和不正确
一个更成问题的问题是实际校验和验证失败时:
Execution failed for task ':compileJava'.
> Dependency verification failed for configuration ':compileClasspath':
- On artifact commons-logging-1.2.jar (commons-logging:commons-logging:1.2) in repository 'MavenRepo': expected a 'sha256' checksum of '91f7a33096ea69bac2cbaf6d01feb934cac002c48d8c8cfa9c240b40f1ec21df' but was 'daddea1ea0be0f56978ab3006b8ac92834afeefbd9b7e4e6316fca57df0fa636'
这次,Gradle 会告诉您哪个依赖项出了问题、预期的校验和(您在验证元数据文件中声明的校验和)以及在验证期间实际计算的校验和是什么。
此类失败表明依赖关系可能已受到损害。在此阶段,您必须执行手动验证并检查会发生什么情况。可能会发生以下几种情况:
-
Gradle 的本地依赖项缓存中的依赖项被篡改。这通常是无害的:从缓存中删除文件,Gradle 将重新下载依赖项。
-
依赖项可在多个源中使用,二进制文件略有不同(额外的空格,...)
-
请告知图书馆的维护者他们有这样的问题
-
您可以用来
also-trust接受额外的校验和
-
-
依赖性受到损害
-
立即通知图书馆的维护人员
-
通知受感染库的存储库维护者
-
请注意,受损库的一种变体通常是名称抢注,即黑客使用看似合法但实际上有一个字符不同的 GAV 坐标,或存储库阴影,即在恶意存储库中发布与官方 GAV 坐标的依赖关系,其中在你的构建中排在第一位。
不可信签名
如果您启用了签名验证,Gradle 将执行签名验证,但不会自动信任它们:
> Dependency verification failed for configuration ':compileClasspath':
- On artifact javaparser-core-3.6.11.jar (com.github.javaparser:javaparser-core:3.6.11) in repository 'MavenRepo': Artifact was signed with key '379ce192d401ab61' (Bintray (by JFrog) <****>) and passed verification but the key isn't in your trusted keys list.
在这种情况下,这意味着您需要检查自己用于验证的密钥(以及签名)是否可信,在这种情况下,请参阅文档的此部分以了解如何声明可信密钥。
签名验证失败
如果 Gradle 无法验证签名,您将需要采取行动并手动验证工件,因为这可能表明依赖关系受到损害。
如果发生这种情况,Gradle 将失败并显示:
> Dependency verification failed for configuration ':compileClasspath':
- On artifact javaparser-core-3.6.11.jar (com.github.javaparser:javaparser-core:3.6.11) in repository 'MavenRepo': Artifact was signed with key '379ce192d401ab61' (Bintray (by JFrog) <****>) but signature didn't match
有几种选择:
-
签名首先就是错误的,这种情况经常发生在不同存储库上发布的依赖项上。
-
签名是正确的,但工件已被破坏(在本地依赖项缓存中或远程)
这里正确的方法是访问依赖项的官方网站,看看他们是否发布了其工件的签名。如果是,请验证 Gradle 下载的签名与发布的签名是否匹配。
如果您已检查依赖项没有受到损害,并且“仅”签名是错误的,则您应该声明工件级别密钥排除:
<components>
<component group="com.github.javaparser" name="javaparser-core" version="3.6.11">
<artifact name="javaparser-core-3.6.11.pom">
<ignored-keys>
<ignored-key id="379ce192d401ab61" reason="internal repo has corrupted POM"/>
</ignored-keys>
</artifact>
</component>
</components>但是,如果您只这样做,Gradle 仍然会失败,因为该工件的所有键都将被忽略,并且您没有提供校验和:
<components>
<component group="com.github.javaparser" name="javaparser-core" version="3.6.11">
<artifact name="javaparser-core-3.6.11.pom">
<ignored-keys>
<ignored-key id="379ce192d401ab61" reason="internal repo has corrupted POM"/>
</ignored-keys>
<sha256 value="a2023504cfd611332177f96358b6f6db26e43d96e8ef4cff59b0f5a2bee3c1e1"/>
</artifact>
</component>
</components>手动验证依赖关系
您可能会面临依赖项验证失败(校验和验证或签名验证),并且需要确定依赖项是否已受到损害。
在本节中,我们将举例说明如何手动检查依赖项是否受到损害。
为此,我们将采用以下失败示例:
> Dependency verification failed for configuration ':compileClasspath': - On artifact j2objc-annotations-1.1.jar (com.google.j2objc:j2objc-annotations:1.1) in repository 'MyCompany Mirror': Artifact was signed with key '29579f18fa8fd93b' but signature didn't match
此错误消息为我们提供了有问题的依赖项的 GAV 坐标,以及从何处获取依赖项的指示。这里,依赖项来自MyCompany Mirror,它是我们的构建中声明的存储库。
因此,要做的第一件事就是从镜像手动下载工件及其签名:
$ curl https://my-company-mirror.com/repo/com/google/j2objc/j2objc-annotations/1.1/j2objc-annotations-1.1.jar --output j2objc-annotations-1.1.jar $ curl https://my-company-mirror.com/repo/com/google/j2objc/j2objc-annotations/1.1/j2objc-annotations-1.1.jar.asc --output j2objc-annotations-1.1.jar.asc
然后我们可以使用错误消息中提供的密钥信息在本地导入密钥:
$ gpg --recv-keys B801E2F8EF035068EC1139CC29579F18FA8FD93B
并进行验证:
$ gpg --verify j2objc-annotations-1.1.jar.asc gpg: assuming signed data in 'j2objc-annotations-1.1.jar' gpg: Signature made Thu 19 Jan 2017 12:06:51 AM CET gpg: using RSA key 29579F18FA8FD93B gpg: BAD signature from "Tom Ball <****>" [unknown]
这告诉我们问题不在本地计算机上:存储库已经包含错误的签名。
下一步是通过下载 Maven Central 上实际的内容来执行相同的操作:
$ curl https://my-company-mirror.com/repo/com/google/j2objc/j2objc-annotations/1.1/j2objc-annotations-1.1.jar --output central-j2objc-annotations-1.1.jar $ curl https://my-company-mirror.com/repo/com/google/j2objc/j2objc-annotations/1/1/j2objc-annotations-1.1.jar.asc --output central-j2objc-annotations-1.1.jar.asc
现在我们可以再次检查签名:
$ gpg --verify central-j2objc-annotations-1.1.jar.asc gpg: assuming signed data in 'central-j2objc-annotations-1.1.jar' gpg: Signature made Thu 19 Jan 2017 12:06:51 AM CET gpg: using RSA key 29579F18FA8FD93B gpg: Good signature from "Tom Ball <****>" [unknown] gpg: WARNING: This key is not certified with a trusted signature! gpg: There is no indication that the signature belongs to the owner. Primary key fingerprint: B801 E2F8 EF03 5068 EC11 39CC 2957 9F18 FA8F D93B
这表明依赖关系在 Maven Central 上有效。在这个阶段,我们已经知道问题存在于镜像中,它可能已被泄露,但我们需要验证。
一个好主意是比较这两个工件,您可以使用像diffscope这样的工具来完成。
然后我们发现其意图并不是恶意的,而是不知何故构建已被较新的版本覆盖(Central 中的版本比我们存储库中的版本新)。
在这种情况下,您可以决定:
-
忽略此工件的签名并信任不同的可能校验和(对于旧工件和新版本)
-
或清理您的镜像,使其包含与 Maven Central 中相同的版本
值得注意的是,如果您选择从存储库中删除该版本,您还需要将其从本地 Gradle 缓存中删除。
错误消息告诉您文件所在的位置,这有助于做到这一点:
> Dependency verification failed for configuration ':compileClasspath':
- On artifact j2objc-annotations-1.1.jar (com.google.j2objc:j2objc-annotations:1.1) in repository 'MyCompany Mirror': Artifact was signed with key '29579f18fa8fd93b' but signature didn't match
This can indicate that a dependency has been compromised. Please carefully verify the signatures and checksums.
For your information here are the path to the files which failed verification:
- $<<directory_layout.adoc#dir:gradle_user_home,GRADLE_USER_HOME>>/caches/modules-2/files-2.1/com.google.j2objc/j2objc-annotations/1.1/976d8d30bebc251db406f2bdb3eb01962b5685b3/j2objc-annotations-1.1.jar (signature: GRADLE_USER_HOME/caches/modules-2/files-2.1/com.google.j2objc/j2objc-annotations/1.1/82e922e14f57d522de465fd144ec26eb7da44501/j2objc-annotations-1.1.jar.asc)
GRADLE_USER_HOME = /home/jiraya/.gradle
您可以安全地删除工件文件,因为 Gradle 会自动重新下载它:
rm -rf ~/.gradle/caches/modules-2/files-2.1/com.google.j2objc/j2objc-annotations/1.1
清理验证文件
如果您不采取任何措施,随着您添加新的依赖项或更改版本,依赖项验证元数据将随着时间的推移而增长:Gradle 不会自动从此文件中删除未使用的条目。原因是 Gradle 无法预先知道依赖项是否会在构建过程中有效使用。
因此,添加依赖项或更改依赖项版本很容易导致文件中出现更多条目,同时留下不必要的条目。
清理文件的一种选择是将现有verification-metadata.xml文件移动到其他位置并使用以下--dry-run模式调用 Gradle :虽然不完美(它不会注意到仅在配置时解决的依赖关系),但它会生成一个新文件,您可以将其与现有的一个。
我们需要移动现有文件,因为引导模式和试运行模式都是增量的:它们从现有元数据验证文件(特别是可信密钥)复制信息。
声明版本
声明版本和范围
最简单的版本声明是一个表示要使用的版本的简单字符串。 Gradle 支持声明版本字符串的不同方式:
-
精确版本:例如
1.3,1.3.0-beta3,1.0-20150201.131010-1 -
Maven 风格的版本范围:例如
[1.0,),[1.1, 2.0),(1.2, 1.5]-
和
[符号]表示包含边界;(并)指示排它边界。 -
当上限或下限缺失时,范围没有上限或下限。
-
该符号
]可以用来代替(排它下界,也[可以代替)排它上限。例如]1.0, 2.0[ -
上限排除充当前缀排除。这意味着
[1.0, 2.0[还将排除所有以2.0小于2.0.例如,类似2.0-dev1或 的版本2.0-SNAPSHOT不再包含在该范围内。
-
-
前缀版本范围:例如
1.`, `1.3.-
+仅包含与之前部分完全匹配的版本。 -
该范围
+本身将包括任何版本。
-
-
一个
latest-status版本:例如latest.integration,latest.release-
将匹配具有指定状态的最高版本模块。请参阅ComponentMetadata.getStatus()。
-
-
Maven
SNAPSHOT版本标识符:例如1.0-SNAPSHOT,1.4.9-beta1-SNAPSHOT
版本订购
版本具有隐式排序。版本排序用于:
-
确定特定版本是否包含在范围内。
-
执行冲突解决时确定哪个版本是“最新”(但请注意,冲突解决使用 “基本版本”)。
版本根据以下规则排序:
-
每个版本都分为其组成“部分”:
-
这些字符
[. - _ +]用于分隔版本的不同“部分”。 -
任何包含数字和字母的部分都会被分成单独的部分:
1a1 == 1.a.1 -
仅比较版本的部分内容。实际的分隔符并不重要:(
1.a.1 == 1-a+1 == 1.a-1 == 1a1但请注意,在冲突解决的上下文中,此规则有例外)。
-
-
使用以下规则比较 2 个版本的等效部分:
-
如果两个部分都是数字,则最高的数值较高:
1.1<1.2 -
如果其中一部分是数字,则认为它高于非数字部分:
1.a<1.1 -
如果两者都是非数字,则按字母顺序比较各部分,并区分大小写:
1.A<1.B<1.a<1.b -
具有额外数字部分的版本被认为比不具有额外数字部分的版本更高(即使它为零):
1.1<1.1.0 -
具有额外非数字部分的版本被认为低于没有以下内容的版本:
1.1.a<1.1
-
-
某些非数字部分对于订购而言具有特殊含义:
-
dev被认为低于任何其他非数字部分:1.0-dev<1.0-ALPHA<1.0-alpha<1.0-rc。 -
字符串
rc,snapshot,final,ga,release和sp被认为高于任何其他字符串部分(按此顺序排序):1.0-zeta<1.0-rc<1.0-snapshot<1.0-final<1.0-ga< <1.0-release<1.0-sp<1.0。 -
与常规字符串部分相反,这些特殊值不区分大小写
1.0-RC-1,并且它们不依赖于它们周围使用的分隔符: ==1.0.rc.1
-
简单版本声明语义
当您使用简写符号声明版本时,例如:
dependencies {
implementation("org.slf4j:slf4j-api:1.7.15")
}dependencies {
implementation('org.slf4j:slf4j-api:1.7.15')
}然后该版本被认为是必需版本,这意味着它至少应该是1.7.15但可以由引擎升级(乐观升级)。
然而,严格版本有一个简写符号,使用以下!!符号:
dependencies {
// short-hand notation with !!
implementation("org.slf4j:slf4j-api:1.7.15!!")
// is equivalent to
implementation("org.slf4j:slf4j-api") {
version {
strictly("1.7.15")
}
}
// or...
implementation("org.slf4j:slf4j-api:[1.7, 1.8[!!1.7.25")
// is equivalent to
implementation("org.slf4j:slf4j-api") {
version {
strictly("[1.7, 1.8[")
prefer("1.7.25")
}
}
}dependencies {
// short-hand notation with !!
implementation('org.slf4j:slf4j-api:1.7.15!!')
// is equivalent to
implementation("org.slf4j:slf4j-api") {
version {
strictly '1.7.15'
}
}
// or...
implementation('org.slf4j:slf4j-api:[1.7, 1.8[!!1.7.25')
// is equivalent to
implementation('org.slf4j:slf4j-api') {
version {
strictly '[1.7, 1.8['
prefer '1.7.25'
}
}
}严格版本无法升级,并且会覆盖源自此依赖项提供的任何传递依赖项。建议对严格版本使用范围。
上面的符号[1.7, 1.8[!!1.7.25相当于:
-
严格地
[1.7, 1.8[ -
更喜欢
1.7.25
这意味着引擎必须选择 1.7(包含)和 1.8(排除)之间的版本,并且如果图中没有其他组件需要不同的版本,则它应该更喜欢 1.7.25.
声明没有版本的依赖项
对于较大的项目,推荐的做法是声明不带版本的依赖项,并使用依赖项约束进行版本声明。优点是依赖项约束允许您在一个地方管理所有依赖项的版本,包括传递依赖项。
dependencies {
implementation("org.springframework:spring-web")
}
dependencies {
constraints {
implementation("org.springframework:spring-web:5.0.2.RELEASE")
}
}dependencies {
implementation 'org.springframework:spring-web'
}
dependencies {
constraints {
implementation 'org.springframework:spring-web:5.0.2.RELEASE'
}
}声明丰富的版本
Gradle 支持丰富的版本声明模型,允许组合不同级别的版本信息。这些术语及其含义按从最强到最弱的顺序解释如下:
strictly-
任何与此版本符号不匹配的版本都将被排除。这是最强版本宣言。对于已声明的依赖项,
strictly可以降级版本。当存在传递依赖时,如果无法选择此子句可接受的版本,则会导致依赖解析失败。有关详细信息,请参阅覆盖依赖项版本。该术语支持动态版本。定义后,它将覆盖任何先前的
require声明并清除先前的reject。
require-
意味着所选版本不能低于
require接受的版本,但可以通过冲突解决方案更高,即使更高版本具有独占的上限。这就是直接依赖的含义。该术语支持动态版本。定义后,它将覆盖任何先前的
strictly声明并清除先前的reject。
prefer-
这是一个非常软的版本声明。仅当对该模块的版本没有更强的非动态意见时才适用。该术语不支持动态版本。
定义可以补足
strictlyorrequire。定义后,它将覆盖任何先前的
prefer声明并清除先前的reject。
在级别层次结构之外还有一个附加术语:
reject-
声明该模块不接受特定版本。如果唯一可选的版本也被拒绝,这将导致依赖性解析失败。该术语支持动态版本。
下表说明了许多用例以及如何组合不同术语以进行丰富版本声明:
| 该依赖项的哪些版本是可以接受的? | strictly |
require |
prefer |
rejects |
评选结果 |
|---|---|---|---|---|---|
使用 version 进行测试 |
1.5 |
从 开始的任何版本 |
|||
经测试 |
[1.0, 2.0[ |
1.5 |
|
||
使用 进行测试 |
[1.0, 2.0[ |
1.5 |
|
||
与上面相同, |
[1.0, 2.0[ |
1.5 |
1.4 |
|
|
没有意见,与 一起工作 |
1.5 |
|
|||
没有意见,更喜欢最新版本。 |
|
构建时的最新版本。 |
|||
在边缘,最新版本,没有降级。 |
|
构建时的最新版本。 |
|||
除了 1.5 之外没有其他版本。 |
1.5 |
1.5,或者如果另一个 |
|||
|
[1.5,1.6[ |
最新 |
使用strictly,尤其是对于图书馆来说,必须是一个深思熟虑的过程,因为它会对下游消费者产生影响。同时,如果使用得当,它将帮助消费者了解哪些库组合在他们的环境中不能协同工作。有关详细信息,请参阅覆盖依赖项版本。
|
笔记
|
丰富的版本信息将以 Gradle 模块元数据格式保存。然而,转换为 Ivy 或 Maven 元数据格式将会有损。将发布最高级别,即 |
丰富版本声明是通过version依赖项或约束声明上的 DSL 方法访问的,该声明允许访问MutableVersionConstraint。
dependencies {
implementation("org.slf4j:slf4j-api") {
version {
strictly("[1.7, 1.8[")
prefer("1.7.25")
}
}
constraints {
add("implementation", "org.springframework:spring-core") {
version {
require("4.2.9.RELEASE")
reject("4.3.16.RELEASE")
}
}
}
}dependencies {
implementation('org.slf4j:slf4j-api') {
version {
strictly '[1.7, 1.8['
prefer '1.7.25'
}
}
constraints {
implementation('org.springframework:spring-core') {
version {
require '4.2.9.RELEASE'
reject '4.3.16.RELEASE'
}
}
}
}处理随时间变化的版本
在很多情况下,您想要使用特定模块依赖项的最新版本,或一系列版本中的最新版本。这可能是开发过程中的要求,或者您可能正在开发一个旨在与一系列依赖项版本一起使用的库。通过使用动态版本,您可以轻松地依赖这些不断变化的依赖项。动态版本可以是版本范围(例如2.+),也可以是可用的最新版本的占位符,例如latest.integration。
或者,即使对于同一版本,您请求的模块也可能随着时间的推移而更改,即所谓的更改版本。这种类型的更改模块的一个示例是 MavenSNAPSHOT模块,它始终指向最新发布的工件。换句话说,一个标准的Maven快照是一个不断演化的模块,它是一个“变化的模块”。
|
警告
|
使用动态版本和更改模块可能会导致无法重现的构建。随着特定模块的新版本发布,其 API 可能会与您的源代码不兼容。请谨慎使用此功能! |
声明动态版本
项目可能会采用更积极的方法来消耗对模块的依赖关系。例如,您可能希望始终集成最新版本的依赖项,以便在任何给定时间使用尖端功能。动态版本允许解析给定模块的最新版本或版本范围的最新版本。
|
警告
|
在构建中使用动态版本可能会带来破坏构建的风险。一旦发布包含不兼容的 API 更改的新版本依赖项,您的源代码可能会停止编译。 |
plugins {
`java-library`
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.springframework:spring-web:5.+")
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework:spring-web:5.+'
}构建扫描可以有效地可视化动态依赖版本及其各自的选定版本。

默认情况下,Gradle 会缓存依赖项的动态版本 24 小时。在此时间范围内,Gradle 不会尝试从声明的存储库中解析较新的版本。可以根据需要配置阈值,例如,如果您想更早地解析新版本。
声明更改版本
团队可能会决定在发布新版本的应用程序或库之前实现一系列功能。允许消费者尽早集成其工件的未完成版本的常见策略是发布具有所谓的更改版本的模块。更改版本表明该功能集仍在积极开发中,尚未发布可供普遍使用的稳定版本。
在 Maven 存储库中,更改版本通常称为快照版本。快照版本包含后缀-SNAPSHOT.以下示例演示了如何在 Spring 依赖项上声明快照版本。
plugins {
`java-library`
}
repositories {
mavenCentral()
maven {
url = uri("https://repo.spring.io/snapshot/")
}
}
dependencies {
implementation("org.springframework:spring-web:5.0.3.BUILD-SNAPSHOT")
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
maven {
url 'https://repo.spring.io/snapshot/'
}
}
dependencies {
implementation 'org.springframework:spring-web:5.0.3.BUILD-SNAPSHOT'
}默认情况下,Gradle 会缓存更改版本的依赖项 24 小时。在此时间范围内,Gradle 不会尝试从声明的存储库中解析较新的版本。可以根据需要配置阈值,例如,如果您想更早地解析新的快照版本。
Gradle 足够灵活,可以将任何版本视为更改版本,例如,如果您想为 Ivy 模块建模快照行为。您需要做的就是将属性ExternalModuleDependency.setChanging(boolean)设置为true。
控制动态版本缓存
默认情况下,Gradle 会缓存动态版本和更改模块 24 小时。在此期间,Gradle 不会联系任何已声明的远程存储库以获取新版本。如果您希望 Gradle 更频繁地或在每次执行构建时检查远程存储库,那么您将需要更改生存时间 (TTL) 阈值。
|
笔记
|
对动态或更改版本使用较短的 TTL 阈值可能会因 HTTP(s) 调用数量增加而导致构建时间延长。 |
您可以使用命令行选项覆盖默认缓存模式。您还可以使用解析策略以编程方式更改构建中的缓存过期时间。
以编程方式控制依赖项缓存
您可以使用配置的ResolutionStrategy以编程方式微调缓存的某些方面。如果您想永久更改设置,则编程方法非常有用。
默认情况下,Gradle 会缓存动态版本 24 小时。要更改 Gradle 缓存动态版本的已解析版本的时间,请使用:
configurations.all {
resolutionStrategy.cacheDynamicVersionsFor(10, "minutes")
}configurations.all {
resolutionStrategy.cacheDynamicVersionsFor 10, 'minutes'
}默认情况下,Gradle 会缓存更改的模块 24 小时。要更改 Gradle 为更改的模块缓存元数据和工件的时间,请使用:
configurations.all {
resolutionStrategy.cacheChangingModulesFor(4, "hours")
}configurations.all {
resolutionStrategy.cacheChangingModulesFor 4, 'hours'
}从命令行控制依赖项缓存
使用离线模式避免网络访问
命令--offline行开关告诉 Gradle 始终使用缓存中的依赖模块,无论它们是否需要再次检查。当离线运行时,Gradle 永远不会尝试访问网络来执行依赖关系解析。如果依赖项缓存中不存在所需的模块,则构建执行将失败。
刷新依赖关系
您可以从命令行控制不同构建调用的依赖项缓存行为。命令行选项有助于为构建的单次执行做出选择性的、临时的选择。
有时,Gradle 依赖项缓存可能与配置的存储库的实际状态不同步。也许存储库最初配置错误,或者“不变”模块发布不正确。要刷新依赖项缓存中的所有依赖项,请使用--refresh-dependencies命令行上的选项。
该--refresh-dependencies选项告诉 Gradle 忽略已解析模块和工件的所有缓存条目。将针对所有配置的存储库执行新的解析,重新计算动态版本,刷新模块并下载工件。但是,在可能的情况下,Gradle 会在再次下载之前检查先前下载的工件是否有效。这是通过将存储库中已发布的 SHA1 值与现有下载工件的 SHA1 值进行比较来完成的。
-
新版本的动态依赖关系
-
更改模块的新版本(使用相同版本字符串但可以具有不同内容的模块)
刷新依赖项将导致 Gradle 使其列表缓存无效。然而:
-
它将对元数据文件执行 HTTP HEAD 请求,但如果它们相同,则不会重新下载它们
-
它将对工件文件执行 HTTP HEAD 请求,但如果它们相同,则不会重新下载它们
换句话说,只有当您实际使用动态依赖项或您不知道正在更改的依赖项时,刷新依赖项才会产生影响(在这种情况下,您有责任将它们正确地向 Gradle 声明为更改的依赖项)。
认为使用--refresh-dependencies会强制下载依赖项是一种常见的误解。情况并非如此: Gradle 只会执行刷新动态依赖项严格要求的操作。这可能涉及下载新的列表或元数据文件,甚至工件,但如果没有任何改变,影响很小。
使用组件选择规则
当有多个版本与版本选择器匹配时,组件选择规则可能会影响应该选择哪个组件实例。规则适用于每个可用版本,并允许规则明确拒绝该版本。这允许 Gradle 忽略任何不满足规则设置条件的组件实例。示例包括:
-
对于像某些版本这样的动态版本,
1.+可能会明确拒绝选择。 -
对于像实例这样的静态版本,
1.4可能会基于额外的组件元数据(例如 Ivy 分支属性)而被拒绝,从而允许使用后续存储库中的实例。
规则是通过ComponentSelectionRules对象配置的。配置的每个规则都将使用ComponentSelection对象作为参数来调用,该对象包含有关正在考虑的候选版本的信息。调用ComponentSelection.reject(java.lang.String)会导致给定的候选版本被显式拒绝,在这种情况下,该候选版本将不会被考虑用于选择器。
以下示例显示了一条规则,该规则不允许模块的特定版本,但允许动态版本选择下一个最佳候选模块。
configurations {
create("rejectConfig") {
resolutionStrategy {
componentSelection {
// Accept the highest version matching the requested version that isn't '1.5'
all {
if (candidate.group == "org.sample" && candidate.module == "api" && candidate.version == "1.5") {
reject("version 1.5 is broken for 'org.sample:api'")
}
}
}
}
}
}
dependencies {
"rejectConfig"("org.sample:api:1.+")
}configurations {
rejectConfig {
resolutionStrategy {
componentSelection {
// Accept the highest version matching the requested version that isn't '1.5'
all { ComponentSelection selection ->
if (selection.candidate.group == 'org.sample' && selection.candidate.module == 'api' && selection.candidate.version == '1.5') {
selection.reject("version 1.5 is broken for 'org.sample:api'")
}
}
}
}
}
}
dependencies {
rejectConfig "org.sample:api:1.+"
}请注意,版本选择首先从最高版本开始应用。所选版本将是所有组件选择规则接受的第一个版本。如果没有规则明确拒绝某个版本,则该版本被视为已接受。
同样,规则可以针对特定模块。模块必须以 的形式指定group:module。
configurations {
create("targetConfig") {
resolutionStrategy {
componentSelection {
withModule("org.sample:api") {
if (candidate.version == "1.5") {
reject("version 1.5 is broken for 'org.sample:api'")
}
}
}
}
}
}configurations {
targetConfig {
resolutionStrategy {
componentSelection {
withModule("org.sample:api") { ComponentSelection selection ->
if (selection.candidate.version == "1.5") {
selection.reject("version 1.5 is broken for 'org.sample:api'")
}
}
}
}
}
}组件选择规则在选择版本时还可以考虑组件元数据。可以考虑的可能的附加元数据是ComponentMetadata和IvyModuleDescriptor。请注意,此额外信息可能并不总是可用,因此应检查null值。
configurations {
create("metadataRulesConfig") {
resolutionStrategy {
componentSelection {
// Reject any versions with a status of 'experimental'
all {
if (candidate.group == "org.sample" && metadata?.status == "experimental") {
reject("don't use experimental candidates from 'org.sample'")
}
}
// Accept the highest version with either a "release" branch or a status of 'milestone'
withModule("org.sample:api") {
if (getDescriptor(IvyModuleDescriptor::class)?.branch != "release" && metadata?.status != "milestone") {
reject("'org.sample:api' must have testing branch or milestone status")
}
}
}
}
}
}configurations {
metadataRulesConfig {
resolutionStrategy {
componentSelection {
// Reject any versions with a status of 'experimental'
all { ComponentSelection selection ->
if (selection.candidate.group == 'org.sample' && selection.metadata?.status == 'experimental') {
selection.reject("don't use experimental candidates from 'org.sample'")
}
}
// Accept the highest version with either a "release" branch or a status of 'milestone'
withModule('org.sample:api') { ComponentSelection selection ->
if (selection.getDescriptor(IvyModuleDescriptor)?.branch != "release" && selection.metadata?.status != 'milestone') {
selection.reject("'org.sample:api' must be a release branch or have milestone status")
}
}
}
}
}
}请注意,在声明组件选择规则时,始终需要ComponentSelection参数作为参数。
锁定依赖版本
使用动态依赖版本(例如1.+或[1.0,2.0))会使构建变得不确定。这会导致构建在没有任何明显更改的情况下中断,更糟糕的是,可能是由构建作者无法控制的传递依赖引起的。
为了实现可重现的构建,有必要锁定依赖项和传递依赖项的版本,以便具有相同输入的构建始终解析相同的模块版本。这称为依赖锁定。
除其他外,它还支持以下场景:
-
处理多存储库的公司不再需要依赖
-SNAPSHOT或更改依赖项,当依赖项引入错误或不兼容时,这有时会导致级联故障。现在可以针对主要或次要版本范围声明依赖项,从而能够在 CI 上使用最新版本进行测试,同时利用锁定来实现稳定的开发人员版本。 -
希望始终使用最新依赖项的团队可以使用动态版本,仅锁定版本的依赖项。发布标签将包含锁定状态,以便在需要开发错误修复时可以完全重现该构建。
结合发布已解析版本,您还可以在发布时替换声明的动态版本部分。相反,消费者将看到您的版本已解决的版本。
根据依赖项配置启用锁定。启用后,您必须创建初始锁定状态。它将导致 Gradle 验证解析结果不会更改,从而导致即使生成了更新版本,也会产生相同的选定依赖项。对构建的修改会影响已解析的依赖项集,从而导致构建失败。这可以确保发布的依赖项或构建定义中的更改不会在不调整锁定状态的情况下改变分辨率。
|
笔记
|
依赖锁定仅对动态版本有意义。尽管内容可能会发生变化,但它不会对坐标保持不变的更改版本(例如)产生影响。 |
启用配置锁定
配置的锁定是通过 ResolutionStrategy 进行的:
configurations {
compileClasspath {
resolutionStrategy.activateDependencyLocking()
}
}configurations {
compileClasspath {
resolutionStrategy.activateDependencyLocking()
}
}|
笔记
|
只有可以解析的配置才会附加锁定状态。对不可解析的配置应用锁定只是一个无操作。 |
或者使用以下方法来锁定所有配置:
dependencyLocking {
lockAllConfigurations()
}dependencyLocking {
lockAllConfigurations()
}|
笔记
|
上面的代码将锁定所有项目配置,但不会锁定构建脚本的配置。 |
您还可以禁用特定配置的锁定。如果插件配置了对所有配置的锁定,但您碰巧添加了不应锁定的配置,这可能会很有用。
configurations.compileClasspath {
resolutionStrategy.deactivateDependencyLocking()
}configurations {
compileClasspath {
resolutionStrategy.deactivateDependencyLocking()
}
}锁定 buildscript 类路径配置
如果您将插件应用到您的构建中,您可能还想利用依赖锁定。要锁定用于脚本插件的classpath配置,请执行以下操作:
buildscript {
configurations.classpath {
resolutionStrategy.activateDependencyLocking()
}
}buildscript {
configurations.classpath {
resolutionStrategy.activateDependencyLocking()
}
}生成和更新依赖锁
为了生成或更新锁定状态,--write-locks除了会触发配置被解析的正常任务之外,您还可以指定命令行参数。这将导致在该构建执行中为每个已解析的配置创建锁定状态。请注意,如果锁定状态先前存在,则会被覆盖。
|
笔记
|
如果构建失败,Gradle 不会将锁定状态写入磁盘。这可以防止持续存在可能无效的状态。 |
在一次构建执行中锁定所有配置
锁定多个配置时,您可能希望在一次构建执行期间一次性锁定所有配置。
为此,您有两种选择:
-
运行
gradle dependencies --write-locks。这将有效地锁定所有启用了锁定的可解析配置。请注意,在多项目设置中,仅在一个项目(本例中为根项目)dependencies上执行。 -
声明一个解决所有配置的自定义任务。这不适用于 Android 项目。
tasks.register("resolveAndLockAll") {
notCompatibleWithConfigurationCache("Filters configurations at execution time")
doFirst {
require(gradle.startParameter.isWriteDependencyLocks) { "$path must be run from the command line with the `--write-locks` flag" }
}
doLast {
configurations.filter {
// Add any custom filtering on the configurations to be resolved
it.isCanBeResolved
}.forEach { it.resolve() }
}
}tasks.register('resolveAndLockAll') {
notCompatibleWithConfigurationCache("Filters configurations at execution time")
doFirst {
assert gradle.startParameter.writeDependencyLocks : "$path must be run from the command line with the `--write-locks` flag"
}
doLast {
configurations.findAll {
// Add any custom filtering on the configurations to be resolved
it.canBeResolved
}.each { it.resolve() }
}
}通过正确选择配置,第二种选择可能是本机世界中的唯一选择,因为并非所有配置都可以在单个平台上解决。
锁定状态位置和格式
锁定状态将保留在位于项目或子项目目录根目录的文件中。每个文件都被命名为gradle.lockfile.此规则的一个例外是构建脚本本身的锁定文件。在这种情况下,该文件将被命名为buildscript-gradle.lockfile.
锁定文件将包含以下内容:
# This is a Gradle generated file for dependency locking. # Manual edits can break the build and are not advised. # This file is expected to be part of source control. org.springframework:spring-beans:5.0.5.RELEASE=compileClasspath, runtimeClasspath org.springframework:spring-core:5.0.5.RELEASE=compileClasspath, runtimeClasspath org.springframework:spring-jcl:5.0.5.RELEASE=compileClasspath, runtimeClasspath empty=annotationProcessor
-
group:artifact:version每行仍然代表符号中的单个依赖项 -
然后它列出包含给定依赖项的所有配置
-
模块和配置按字母顺序排列,以简化差异
-
文件的最后一行列出了所有空配置,即已知没有依赖项的配置
它匹配以下依赖声明:
configurations {
compileClasspath {
resolutionStrategy.activateDependencyLocking()
}
runtimeClasspath {
resolutionStrategy.activateDependencyLocking()
}
annotationProcessor {
resolutionStrategy.activateDependencyLocking()
}
}
dependencies {
implementation("org.springframework:spring-beans:[5.0,6.0)")
}configurations {
compileClasspath {
resolutionStrategy.activateDependencyLocking()
}
runtimeClasspath {
resolutionStrategy.activateDependencyLocking()
}
annotationProcessor {
resolutionStrategy.activateDependencyLocking()
}
}
dependencies {
implementation 'org.springframework:spring-beans:[5.0,6.0)'
}从每个配置格式的锁定文件迁移
如果您的项目使用每个锁定配置的文件的旧锁定文件格式,请按照以下说明迁移到新格式:
|
笔记
|
一次可以完成一项配置的迁移。只要单个锁定文件中没有该配置的信息,Gradle 就会继续从每个配置文件中获取锁定状态。 |
配置每个项目的锁定文件名和位置
当每个项目使用单个锁定文件时,您可以配置其名称和位置。提供此功能的主要原因是允许具有由某些项目属性确定的文件名,从而有效地允许单个项目为不同的执行上下文存储不同的锁定状态。 JVM 生态系统中的一个简单示例是经常在工件坐标中找到的 Scala 版本。
val scalaVersion = "2.12"
dependencyLocking {
lockFile = file("$projectDir/locking/gradle-${scalaVersion}.lockfile")
}def scalaVersion = "2.12"
dependencyLocking {
lockFile = file("$projectDir/locking/gradle-${scalaVersion}.lockfile")
}在存在锁定状态的情况下运行构建
当构建需要解析启用了锁定的配置并且找到匹配的锁定状态时,它将使用它来验证给定的配置是否仍然解析相同的版本。
成功的构建表明,无论是否已生成与动态选择器匹配的新版本,都会使用与锁定状态中存储的相同的依赖项。
完整验证如下:
-
处于锁定状态的现有条目必须在构建中匹配
-
版本不匹配或缺少解析的模块会导致构建失败
-
-
与锁定状态相比,解析结果不得包含额外的依赖项
使用锁定模式微调依赖锁定行为
虽然默认锁定模式的行为如上所述,但还有其他两种模式可用:
- 严格模式
-
在此模式下,除了上述验证之外,如果标记为锁定的配置没有与其关联的锁定状态,则依赖项锁定将失败。
- 宽松模式
-
在此模式下,依赖项锁定仍将固定动态版本,但对依赖项解析的其他更改不再是错误。
锁定模式可以从dependencyLocking块控制,如下所示:
dependencyLocking {
lockMode = LockMode.STRICT
}dependencyLocking {
lockMode = LockMode.STRICT
}有选择地更新锁定状态条目
为了仅更新配置的特定模块,您可以使用--update-locks命令行标志。它采用逗号 ( ,) 分隔的模块符号列表。在此模式下,现有的锁定状态仍用作解析的输入,过滤掉更新目标的模块。
❯ gradle classes --update-locks org.apache.commons:commons-lang3,org.slf4j:slf4j-api
用 表示的通配符*可以在组或模块名称中使用。它们可以是唯一的字符,也可以分别出现在组或模块的末尾。以下通配符示例有效:
-
org.apache.commons:*:会让属于组的所有模块org.apache.commons更新 -
*:guava:将让所有名为 的模块guava(无论其组如何)更新 -
org.springframework.spring*:spring*:将让所有模块的组以 update 开头org.springframework.spring且名称以springupdate开头
|
笔记
|
根据 Gradle 解析规则的规定,该解析可能会导致其他模块版本更新。 |
忽略锁定状态的特定依赖关系
当可重复性不是主要目标时,可以使用依赖锁定。作为构建作者,您可能希望有不同的依赖版本更新频率,例如根据其来源。在这种情况下,忽略某些依赖项可能会很方便,因为您始终希望对这些依赖项使用最新版本。一个示例是组织中的内部依赖项应始终使用最新版本,而不是具有不同升级周期的第三方依赖项。
|
警告
|
此功能可能会破坏再现性,应谨慎使用。在某些情况下,利用不同的锁定模式或使用不同的锁定文件名称可以更好地服务。 |
您可以在dependencyLocking项目扩展中配置忽略的依赖项:
dependencyLocking {
ignoredDependencies.add("com.example:*")
}dependencyLocking {
ignoredDependencies.add('com.example:*')
}该符号是<group>:<name>依赖符号,其中*可以用作尾随通配符。有关更多详细信息,请参阅有关更新锁定文件的说明。请注意,该值*:*不被接受,因为它相当于禁用锁定。
忽略依赖关系将产生以下影响:
-
忽略的依赖关系适用于所有锁定的配置。该设置是项目范围内的。
-
忽略依赖关系并不意味着锁状态忽略其传递依赖关系。
-
没有验证任何配置解析中是否存在被忽略的依赖项。
-
如果依赖项处于锁定状态,加载它将过滤掉依赖项。
-
如果解析结果中存在依赖关系,则在验证解析与锁定状态匹配时将忽略该依赖关系。
-
最后,如果解析结果中存在依赖关系并且锁状态被持久化,则写入锁状态中将不存在依赖关系。
锁定限制
-
锁定尚不能应用于源依赖项。
星云锁定插件
该功能的灵感来自Nebula Gradle 依赖锁插件。
控制传递性
升级传递依赖的版本
直接依赖与依赖约束
一个组件可能有两种不同类型的依赖关系:
-
直接依赖项是组件直接需要的。直接依赖性也称为第一级依赖性。例如,如果您的项目源代码需要 Guava,则应将 Guava 声明为直接依赖。
-
传递依赖项是您的组件需要的依赖项,但只是因为另一个依赖项需要它们。
依赖管理的问题与传递依赖有关,这是很常见的。开发人员常常通过添加直接依赖项来错误地修复传递依赖项问题。为了避免这种情况,Gradle 提供了依赖约束的概念。
添加传递依赖的约束
依赖项约束允许您定义构建脚本中声明的依赖项和传递依赖项的版本或版本范围。它是表达应应用于配置的所有依赖项的约束的首选方法。当 Gradle 尝试解析对模块版本的依赖关系时,会考虑该模块的所有依赖关系声明、所有传递依赖关系以及该模块的所有依赖关系约束。选择符合所有条件的最高版本。如果找不到这样的版本,Gradle 将失败并显示冲突声明的错误。如果发生这种情况,您可以调整依赖项或依赖项约束声明,或者根据需要对传递依赖项进行其他调整。与依赖项声明类似,依赖项约束声明的范围由配置决定,因此可以为构建的各个部分选择性地定义。如果依赖性约束影响了解析结果,则之后仍可以应用任何类型的依赖性解析规则。
dependencies {
implementation("org.apache.httpcomponents:httpclient")
constraints {
implementation("org.apache.httpcomponents:httpclient:4.5.3") {
because("previous versions have a bug impacting this application")
}
implementation("commons-codec:commons-codec:1.11") {
because("version 1.9 pulled from httpclient has bugs affecting this application")
}
}
}dependencies {
implementation 'org.apache.httpcomponents:httpclient'
constraints {
implementation('org.apache.httpcomponents:httpclient:4.5.3') {
because 'previous versions have a bug impacting this application'
}
implementation('commons-codec:commons-codec:1.11') {
because 'version 1.9 pulled from httpclient has bugs affecting this application'
}
}
}在示例中,依赖项声明中省略了所有版本。相反,版本是在约束块中定义的。仅当作为传递依赖项引入commons-codec:1.11时,才会考虑的版本定义,因为在项目中未定义为依赖项。否则,约束无效。依赖约束还可以定义丰富的版本约束并支持严格版本来强制执行版本,即使它与传递依赖定义的版本相矛盾(例如,如果版本需要降级)。commons-codeccommons-codec
|
笔记
|
仅当使用Gradle 模块元数据 时才会发布依赖关系约束。这意味着目前只有当 Gradle 用于发布和使用时它们才得到完全支持(即当使用 Maven 或 Ivy 消费模块时它们会“丢失”)。 |
依赖约束本身也可以被传递地添加。
降级版本并排除依赖项
覆盖传递依赖版本
Gradle 通过选择依赖关系图中找到的最新版本来解决任何依赖关系版本冲突。某些项目可能需要偏离默认行为并强制执行早期版本的依赖项,例如,如果项目的源代码依赖于比某些外部库更旧的依赖项 API。
|
警告
|
强制依赖某个版本需要有意识的决定。如果外部库没有它们就无法正常运行,则更改传递依赖项的版本可能会导致运行时错误。考虑升级源代码以使用较新版本的库作为替代方法。 |
一般来说,强制依赖关系是为了降级依赖关系。降级可能有不同的用例:
-
在最新版本中发现了一个错误
-
您的代码依赖于不兼容二进制的较低版本
-
您的代码不依赖于需要更高版本依赖项的代码路径
在所有情况下,最好的表达是您的代码严格依赖于传递的版本。使用strict versions,您将有效地依赖于您声明的版本,即使传递依赖另有说明。
|
笔记
|
严格依赖在某种程度上类似于 Maven 的最近优先策略,但也有细微的差别:
|
假设一个项目使用HttpClient 库来执行 HTTP 调用。 HttpClient在版本 1.10 中引入Commons Codec作为传递依赖项。但是,该项目的生产源代码需要 Commons Codec 1.9 中的 API,该 API 在 1.10 中不再可用。可以通过在构建脚本中将其声明为 strict 来强制执行依赖版本:
dependencies {
implementation("org.apache.httpcomponents:httpclient:4.5.4")
implementation("commons-codec:commons-codec") {
version {
strictly("1.9")
}
}
}dependencies {
implementation 'org.apache.httpcomponents:httpclient:4.5.4'
implementation('commons-codec:commons-codec') {
version {
strictly '1.9'
}
}
}使用严格版本的后果
使用严格版本必须仔细考虑,尤其是库作者。作为生产者,严格版本将有效地表现得像一个力量:版本声明优先于传递依赖图中找到的任何内容。特别是,严格版本将覆盖可传递找到的同一模块上的任何其他严格版本。
然而,对于消费者来说,在图形解析过程中仍然全局考虑严格版本,如果消费者不同意,可能会触发错误。
例如,假设您的项目B 严格依赖于C:1.0.现在,消费者A取决于B和C:1.1。
那么这将触发解析错误,因为A它表示需要,C:1.1但在其子图中,严格需要。这意味着,如果您在严格约束中选择单个版本,那么该版本将无法再升级,除非消费者也对同一个模块设置了严格版本约束。B1.0
在上面的例子中,A不得不说它严格依赖于 1.1。
因此,一个好的做法是,如果您使用严格版本,则应该用范围和此范围内的首选版本来表达它们。例如,B可能会说,而不是strictly 1.0,它严格取决于范围[1.0, 2.0[,但更喜欢 1.0。然后,如果消费者选择 1.1(或该范围内的任何其他版本),构建将不再失败(约束已解决)。
强制依赖与严格依赖
如果项目在配置级别需要特定版本的依赖项,则可以通过调用方法ResolutionStrategy.force(java.lang.Object[])来实现。
configurations {
"compileClasspath" {
resolutionStrategy.force("commons-codec:commons-codec:1.9")
}
}
dependencies {
implementation("org.apache.httpcomponents:httpclient:4.5.4")
}configurations {
compileClasspath {
resolutionStrategy.force 'commons-codec:commons-codec:1.9'
}
}
dependencies {
implementation 'org.apache.httpcomponents:httpclient:4.5.4'
}排除传递依赖
虽然上一节展示了如何强制执行特定版本的传递依赖项,但本节介绍了排除作为完全删除传递依赖项的方法。
|
警告
|
与强制依赖版本类似,完全排除依赖需要有意识的决定。如果外部库在没有传递依赖的情况下无法正常运行,则排除传递依赖可能会导致运行时错误。如果您使用排除,请确保您没有利用任何需要通过足够的测试覆盖率排除依赖项的代码路径。 |
可以在声明的依赖级别上排除传递依赖。排除项通过属性group和/或以键/值对的形式拼写出来module,如下例所示。有关更多信息,请参阅ModuleDependency.exclude(java.util.Map)。
dependencies {
implementation("commons-beanutils:commons-beanutils:1.9.4") {
exclude(group = "commons-collections", module = "commons-collections")
}
}dependencies {
implementation('commons-beanutils:commons-beanutils:1.9.4') {
exclude group: 'commons-collections', module: 'commons-collections'
}
}在此示例中,我们添加依赖项commons-beanutils但排除传递依赖项commons-collections。在我们的代码中,如下所示,我们仅使用 beanutils 库中的一种方法,PropertyUtils.setSimpleProperty().对于现有设置器使用此方法不需要commons-collections我们通过测试覆盖率验证的任何功能。
import org.apache.commons.beanutils.PropertyUtils;
public class Main {
public static void main(String[] args) throws Exception {
Object person = new Person();
PropertyUtils.setSimpleProperty(person, "name", "Bart Simpson");
PropertyUtils.setSimpleProperty(person, "age", 38);
}
}实际上,我们表达的是我们只使用该库的一个子集,这不需要该commons-collection库。这可以看作是隐式定义了一个尚未被自身显式声明的特征变体commons-beanutils。然而,这样做会增加破坏未经测试的代码路径的风险。
例如,这里我们使用setSimpleProperty()方法来修改类中setter定义的属性Person,效果很好。如果我们尝试设置类中不存在的属性,我们应该会收到类似 的错误Unknown property on class Person。但是,因为错误处理路径使用了 中的类commons-collections,所以我们现在得到的错误是NoClassDefFoundError: org/apache/commons/collections/FastHashMap。因此,如果我们的代码更加动态,并且我们忘记充分覆盖错误情况,那么我们库的使用者可能会遇到意想不到的错误。
这只是说明潜在陷阱的示例。在实践中,较大的库或框架可能会带来大量的依赖项。如果这些库无法单独声明功能,并且只能以“全有或全无”的方式使用,则排除可能是将库缩减为实际所需的功能集的有效方法。
从好的方面来说,与 Maven 相比,Gradle 的排除处理考虑了整个依赖关系图。因此,如果某个库存在多个依赖项,则仅当所有依赖项都同意时才会执行排除。例如,如果我们将opencsv另一个依赖项添加到上面的项目中,该依赖项也依赖于commons-beanutils,commons-collection则不再排除它,因为opencsv它本身不排除它。
dependencies {
implementation("commons-beanutils:commons-beanutils:1.9.4") {
exclude(group = "commons-collections", module = "commons-collections")
}
implementation("com.opencsv:opencsv:4.6") // depends on 'commons-beanutils' without exclude and brings back 'commons-collections'
}dependencies {
implementation('commons-beanutils:commons-beanutils:1.9.4') {
exclude group: 'commons-collections', module: 'commons-collections'
}
implementation 'com.opencsv:opencsv:4.6' // depends on 'commons-beanutils' without exclude and brings back 'commons-collections'
}如果我们仍然想commons-collections排除它,因为我们组合使用commons-beanutils和opencsv不需要它,我们opencsv也需要将它从 的传递依赖中排除。
dependencies {
implementation("commons-beanutils:commons-beanutils:1.9.4") {
exclude(group = "commons-collections", module = "commons-collections")
}
implementation("com.opencsv:opencsv:4.6") {
exclude(group = "commons-collections", module = "commons-collections")
}
}dependencies {
implementation('commons-beanutils:commons-beanutils:1.9.4') {
exclude group: 'commons-collections', module: 'commons-collections'
}
implementation('com.opencsv:opencsv:4.6') {
exclude group: 'commons-collections', module: 'commons-collections'
}
}从历史上看,排除也被用作解决某些依赖管理系统不支持的其他问题的创可贴。然而,Gradle 提供了多种可能更适合解决特定用例的功能。您可以考虑研究以下功能:
-
更新或降级依赖项版本:如果依赖项的版本发生冲突,通常最好通过依赖项约束来调整版本,而不是尝试排除具有不需要的版本的依赖项。
-
组件元数据规则:如果库的元数据明显错误,例如,如果它包含编译时永远不需要的编译时依赖项,则可能的解决方案是删除组件元数据规则中的依赖项。通过这种方式,你告诉 Gradle 两个模块之间的依赖关系是不需要的——即元数据是错误的——因此永远不应该考虑。如果您正在开发一个库,则必须注意此信息未发布,因此有时排除可能是更好的选择。
-
解决互斥依赖冲突:您经常看到的通过排除解决的另一种情况是两个依赖项不能一起使用,因为它们代表同一事物(相同功能)的两种实现。一些流行的示例是冲突的日志 API 实现(如
log4j和log4j-over-slf4j)或在不同版本中具有不同坐标的模块(如com.google.collections和guava)。在这些情况下,如果 Gradle 不知道此信息,建议通过组件元数据规则添加缺少的功能信息,如声明组件功能部分中所述。即使您正在开发一个库,而您的消费者将不得不再次解决冲突,将决定权留给库的最终消费者通常是正确的解决方案。即,作为库作者,您不必决定您的消费者最终使用哪种日志记录实现。
在项目之间共享依赖版本
依赖关系的中央声明
使用版本目录
版本目录是依赖项列表,表示为依赖项坐标,用户在构建脚本中声明依赖项时可以从中选择。
例如,可以从版本目录中选取依赖项坐标,而不是使用字符串表示法声明依赖项:
dependencies {
implementation(libs.groovy.core)
}dependencies {
implementation(libs.groovy.core)
}在此上下文中,libs是一个目录,groovy表示该目录中可用的依赖项。与直接在构建脚本中声明依赖项相比,版本目录具有许多优点:
使用符号添加依赖项的libs.someLib工作方式与直接在构建脚本中硬编码组、工件和版本的工作方式完全相同。
声明版本目录
版本目录可以在settings.gradle(.kts)文件中声明。在上面的示例中,为了groovy通过libs目录提供可用,我们需要将别名与 GAV(组、工件、版本)坐标相关联:
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
library("groovy-core", "org.codehaus.groovy:groovy:3.0.5")
library("groovy-json", "org.codehaus.groovy:groovy-json:3.0.5")
library("groovy-nio", "org.codehaus.groovy:groovy-nio:3.0.5")
library("commons-lang3", "org.apache.commons", "commons-lang3").version {
strictly("[3.8, 4.0[")
prefer("3.9")
}
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
library('groovy-core', 'org.codehaus.groovy:groovy:3.0.5')
library('groovy-json', 'org.codehaus.groovy:groovy-json:3.0.5')
library('groovy-nio', 'org.codehaus.groovy:groovy-nio:3.0.5')
library('commons-lang3', 'org.apache.commons', 'commons-lang3').version {
strictly '[3.8, 4.0['
prefer '3.9'
}
}
}
}别名及其到类型安全访问器的映射
别名必须由一系列由破折号(-推荐)、下划线(_)或点(.)分隔的标识符组成。标识符本身必须由 ascii 字符组成,最好是小写,最后跟数字。
例如:
-
guava是一个有效的别名 -
groovy-core是一个有效的别名 -
commons-lang3是一个有效的别名 -
androidx.awesome.lib也是一个有效的别名 -
但
this.#is.not!
然后为每个子组生成类型安全访问器。例如,在名为 的版本目录中给出以下别名libs:
guava, groovy-core, groovy-xml, groovy-json,androidx.awesome.lib
我们将生成以下类型安全访问器:
-
libs.guava -
libs.groovy.core -
libs.groovy.xml -
libs.groovy.json -
libs.androidx.awesome.lib
其中libs前缀来自版本目录名称。
如果您想避免生成子组访问器,我们建议依靠大小写来区分。例如,别名groovyCore,groovyJson和groovyXml将分别映射到libs.groovyCore,libs.groovyJson和libs.groovyXml访问器。
声明别名时,值得注意的是,任何-,_和.字符都可以用作分隔符,但生成的目录将全部标准化为.: 例如,foo-bar作为别名自动转换为foo.bar。
有些关键字是保留的,因此不能用作别名。接下来的单词不能用作别名:
-
扩展
-
班级
-
习俗
除此之外,下一个单词不能用作依赖项别名的第一个子组(对于捆绑包、版本和插件,此限制不适用):
-
捆绑
-
版本
-
插件
例如,对于依赖项,别名versions-dependency无效,但versionsDependency或dependency-versions有效。
具有相同版本号的依赖项
在声明版本目录的第一个示例中,我们可以看到我们为groovy库的各个组件声明了 3 个别名,并且它们都共享相同的版本号。
我们可以声明一个版本并引用它,而不是重复相同的版本号:
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
version("groovy", "3.0.5")
version("checkstyle", "8.37")
library("groovy-core", "org.codehaus.groovy", "groovy").versionRef("groovy")
library("groovy-json", "org.codehaus.groovy", "groovy-json").versionRef("groovy")
library("groovy-nio", "org.codehaus.groovy", "groovy-nio").versionRef("groovy")
library("commons-lang3", "org.apache.commons", "commons-lang3").version {
strictly("[3.8, 4.0[")
prefer("3.9")
}
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
version('groovy', '3.0.5')
version('checkstyle', '8.37')
library('groovy-core', 'org.codehaus.groovy', 'groovy').versionRef('groovy')
library('groovy-json', 'org.codehaus.groovy', 'groovy-json').versionRef('groovy')
library('groovy-nio', 'org.codehaus.groovy', 'groovy-nio').versionRef('groovy')
library('commons-lang3', 'org.apache.commons', 'commons-lang3').version {
strictly '[3.8, 4.0['
prefer '3.9'
}
}
}
}单独声明的版本也可以通过类型安全访问器使用,这使得它们比依赖版本可用于更多用例,特别是对于工具:
checkstyle {
// will use the version declared in the catalog
toolVersion = libs.versions.checkstyle.get()
}checkstyle {
// will use the version declared in the catalog
toolVersion = libs.versions.checkstyle.get()
}如果声明版本的别名也是一些更具体别名的前缀,如 和 中libs.versions.zinc,libs.versions.zinc.apiinfo则更通用版本的值可通过asProvider()类型安全访问器获得:
scala {
zincVersion = libs.versions.zinc.asProvider().get()
}scala {
zincVersion = libs.versions.zinc.asProvider().get()
}目录中声明的依赖项通过与其名称相对应的扩展名公开给构建脚本。在上面的示例中,因为在设置中声明的目录名为named ,所以可以通过当前构建的所有构建脚本中的libs名称使用扩展。libs使用以下符号声明依赖关系...
dependencies {
implementation(libs.groovy.core)
implementation(libs.groovy.json)
implementation(libs.groovy.nio)
}dependencies {
implementation libs.groovy.core
implementation libs.groovy.json
implementation libs.groovy.nio
}...与写作完全相同的效果:
dependencies {
implementation("org.codehaus.groovy:groovy:3.0.5")
implementation("org.codehaus.groovy:groovy-json:3.0.5")
implementation("org.codehaus.groovy:groovy-nio:3.0.5")
}dependencies {
implementation 'org.codehaus.groovy:groovy:3.0.5'
implementation 'org.codehaus.groovy:groovy-json:3.0.5'
implementation 'org.codehaus.groovy:groovy-nio:3.0.5'
}目录中声明的版本是丰富版本。请参阅版本目录生成器 API以获取完整的版本声明支持文档。
依赖包
由于某些依赖项经常在不同的项目中系统地一起使用,因此版本目录提供了“依赖项包”的概念。捆绑包基本上是多个依赖项的别名。例如,您可以编写以下代码,而不是像上面那样声明 3 个单独的依赖项:
dependencies {
implementation(libs.bundles.groovy)
}dependencies {
implementation libs.bundles.groovy
}名为的包groovy需要在目录中声明:
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
version("groovy", "3.0.5")
version("checkstyle", "8.37")
library("groovy-core", "org.codehaus.groovy", "groovy").versionRef("groovy")
library("groovy-json", "org.codehaus.groovy", "groovy-json").versionRef("groovy")
library("groovy-nio", "org.codehaus.groovy", "groovy-nio").versionRef("groovy")
library("commons-lang3", "org.apache.commons", "commons-lang3").version {
strictly("[3.8, 4.0[")
prefer("3.9")
}
bundle("groovy", listOf("groovy-core", "groovy-json", "groovy-nio"))
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
version('groovy', '3.0.5')
version('checkstyle', '8.37')
library('groovy-core', 'org.codehaus.groovy', 'groovy').versionRef('groovy')
library('groovy-json', 'org.codehaus.groovy', 'groovy-json').versionRef('groovy')
library('groovy-nio', 'org.codehaus.groovy', 'groovy-nio').versionRef('groovy')
library('commons-lang3', 'org.apache.commons', 'commons-lang3').version {
strictly '[3.8, 4.0['
prefer '3.9'
}
bundle('groovy', ['groovy-core', 'groovy-json', 'groovy-nio'])
}
}
}语义再次是等效的:添加单个包相当于添加单独属于该包的所有依赖项。
插件
除了库之外,版本目录还支持声明插件版本。虽然库由其组、工件和版本坐标表示,但 Gradle 插件仅由其 id 和版本标识。因此,它们需要单独声明:
|
警告
|
您不能在设置文件或设置插件中使用在版本目录中声明的插件(因为目录是在设置本身中定义的,这将是一个先有鸡还是先有蛋的问题)。 |
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
plugin("versions", "com.github.ben-manes.versions").version("0.45.0")
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
plugin('versions', 'com.github.ben-manes.versions').version('0.45.0')
}
}
}然后可以在plugins块中访问该插件,并且可以使用以下方式在构建的任何项目中使用:
plugins {
`java-library`
checkstyle
alias(libs.plugins.versions)
}plugins {
id 'java-library'
id 'checkstyle'
// Use the plugin `versions` as declared in the `libs` version catalog
alias(libs.plugins.versions)
}使用多个目录
除了常规libs目录之外,您还可以通过 API 声明任意数量的目录Settings。这允许您以对您的项目有意义的方式分离多个源中的依赖项声明。
dependencyResolutionManagement {
versionCatalogs {
create("testLibs") {
val junit5 = version("junit5", "5.7.1")
library("junit-api", "org.junit.jupiter", "junit-jupiter-api").versionRef(junit5)
library("junit-engine", "org.junit.jupiter", "junit-jupiter-engine").versionRef(junit5)
}
}
}dependencyResolutionManagement {
versionCatalogs {
testLibs {
def junit5 = version('junit5', '5.7.1')
library('junit-api', 'org.junit.jupiter', 'junit-jupiter-api').versionRef(junit5)
library('junit-engine', 'org.junit.jupiter', 'junit-jupiter-engine').versionRef(junit5)
}
}
}|
笔记
|
每个目录都会生成一个应用于所有项目的扩展,以访问其内容。因此,通过选择一个可以减少潜在冲突的名称来减少冲突的机会是有意义的。例如,一个选项是选择一个以 结尾的名称 |
libs.versions.toml 文件
除了上面的设置 API 之外,Gradle 还提供了一个常规文件来声明目录。如果在根构建的子目录libs.versions.toml中找到文件gradle,则会自动使用该文件的内容声明一个目录。
声明libs.versions.toml文件并不使其成为依赖项的单一事实来源:它是可以声明依赖项的常规位置。一旦开始使用目录,强烈建议在目录中声明所有依赖项,而不是在构建脚本中硬编码组/工件/版本字符串。请注意,插件可能会添加依赖项,这些依赖项是在此文件外部定义的依赖项。
就像src/main/java查找 Java 源代码的约定一样,它不会阻止声明其他源目录(在构建脚本或插件中),文件的存在libs.versions.toml不会阻止在其他地方声明依赖项。
然而,该文件的存在确实表明大多数依赖项(如果不是全部)将在此文件中声明。因此,对于大多数用户来说,更新依赖项版本应该只包含更改此文件中的一行。
默认情况下,该libs.versions.toml文件将作为目录的输入libs。可以更改默认目录的名称,例如,如果您已经有同名的扩展:
dependencyResolutionManagement {
defaultLibrariesExtensionName = "projectLibs"
}dependencyResolutionManagement {
defaultLibrariesExtensionName = 'projectLibs'
}版本目录TOML文件格式
TOML文件由 4 个主要部分组成:
-
该
[versions]部分用于声明可以被依赖项引用的版本 -
该
[libraries]部分用于声明坐标的别名 -
该
[bundles]部分用于声明依赖包 -
该
[plugins]部分用于声明插件
例如:
[versions]
groovy = "3.0.5"
checkstyle = "8.37"
[libraries]
groovy-core = { module = "org.codehaus.groovy:groovy", version.ref = "groovy" }
groovy-json = { module = "org.codehaus.groovy:groovy-json", version.ref = "groovy" }
groovy-nio = { module = "org.codehaus.groovy:groovy-nio", version.ref = "groovy" }
commons-lang3 = { group = "org.apache.commons", name = "commons-lang3", version = { strictly = "[3.8, 4.0[", prefer="3.9" } }
[bundles]
groovy = ["groovy-core", "groovy-json", "groovy-nio"]
[plugins]
versions = { id = "com.github.ben-manes.versions", version = "0.45.0" }
版本可以声明为单个字符串(在这种情况下它们被解释为必需版本),也可以声明为丰富版本:
[versions]
my-lib = { strictly = "[1.0, 2.0[", prefer = "1.2" }版本声明支持的成员有:
依赖项声明可以声明为简单字符串(在这种情况下它们被解释为group:artifact:version坐标),也可以将版本声明与组和名称分开:
|
笔记
|
对于别名,别名部分中描述的规则及其到类型安全访问器的映射也适用。 |
[versions]
common = "1.4"
[libraries]
my-lib = "com.mycompany:mylib:1.4"
my-other-lib = { module = "com.mycompany:other", version = "1.4" }
my-other-lib2 = { group = "com.mycompany", name = "alternate", version = "1.4" }
mylib-full-format = { group = "com.mycompany", name = "alternate", version = { require = "1.4" } }
[plugins]
short-notation = "some.plugin.id:1.4"
long-notation = { id = "some.plugin.id", version = "1.4" }
reference-notation = { id = "some.plugin.id", version.ref = "common" }
如果您想引用该[versions]部分中声明的版本,您应该使用以下version.ref属性:
[versions]
some = "1.4"
[libraries]
my-lib = { group = "com.mycompany", name="mylib", version.ref="some" }TOML 文件格式非常宽松,允许您编写“点式”属性作为完整对象声明的快捷方式。例如,这个:
a.b.c="d"相当于:
a.b = { c = "d" }或者
a = { b = { c = "d" } }有关详细信息,请参阅TOML 规范。
类型不安全 API
可以通过类型不安全的 API 访问版本目录。此 API 在生成的访问器不可用的情况下可用。它可以通过版本目录扩展来访问:
val versionCatalog = extensions.getByType<VersionCatalogsExtension>().named("libs")
println("Library aliases: ${versionCatalog.libraryAliases}")
dependencies {
versionCatalog.findLibrary("groovy-json").ifPresent {
implementation(it)
}
}def versionCatalog = extensions.getByType(VersionCatalogsExtension).named("libs")
println "Library aliases: ${versionCatalog.libraryAliases}"
dependencies {
versionCatalog.findLibrary("groovy-json").ifPresent {
implementation(it)
}
}检查版本目录 API以了解所有支持的方法。
共享目录
版本目录用于单个构建(可能是多项目构建),但也可以在构建之间共享。例如,组织可能想要创建来自不同团队的不同项目可以使用的依赖项目录。
从 TOML 文件导入目录
版本目录构建器 API支持包含外部文件中的模型。如果需要的话,这使得可以重用主构建的目录buildSrc。例如,该buildSrc/settings.gradle(.kts)文件可以使用以下命令包含该文件:
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
from(files("../gradle/libs.versions.toml"))
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
from(files("../gradle/libs.versions.toml"))
}
}
}|
警告
|
使用VersionCatalogBuilder.from(Object dependencyNotation)方法时,仅接受单个文件。这意味着像Project.files(java.lang.Object…)这样的符号必须引用单个文件,否则构建将失败。 如果需要更复杂的结构(从多个文件导入的版本目录),建议使用基于代码的方法,而不是 TOML 文件。 |
因此,该技术可用于声明来自不同文件的多个目录:
dependencyResolutionManagement {
versionCatalogs {
// declares an additional catalog, named 'testLibs', from the 'test-libs.versions.toml' file
create("testLibs") {
from(files("gradle/test-libs.versions.toml"))
}
}
}dependencyResolutionManagement {
versionCatalogs {
// declares an additional catalog, named 'testLibs', from the 'test-libs.versions.toml' file
testLibs {
from(files('gradle/test-libs.versions.toml'))
}
}
}版本目录插件
虽然从本地文件导入目录很方便,但它并不能解决在组织中或外部消费者共享目录的问题。共享目录的一种选择是编写一个设置插件,将其发布到 Gradle 插件门户或内部存储库上,并让使用者在其设置文件上应用该插件。
或者,Gradle 提供版本目录插件,它提供声明然后发布目录的功能。
为此,您需要应用该version-catalog插件:
plugins {
`version-catalog`
`maven-publish`
}plugins {
id 'version-catalog'
id 'maven-publish'
}然后,该插件将公开可用于声明目录的目录扩展:
catalog {
// declare the aliases, bundles and versions in this block
versionCatalog {
library("my-lib", "com.mycompany:mylib:1.2")
}
}catalog {
// declare the aliases, bundles and versions in this block
versionCatalog {
library('my-lib', 'com.mycompany:mylib:1.2')
}
}maven-publish然后可以通过应用或ivy-publish插件并配置发布以使用该组件来发布这样的目录versionCatalog:
publishing {
publications {
create<MavenPublication>("maven") {
from(components["versionCatalog"])
}
}
}publishing {
publications {
maven(MavenPublication) {
from components.versionCatalog
}
}
}发布此类项目时,libs.versions.toml将自动生成(并上传)一个文件,然后可以从其他 Gradle 构建中使用该文件。
导入已发布的目录
版本目录插件生成的目录可以通过设置 API 导入:
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
from("com.mycompany:catalog:1.0")
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
from("com.mycompany:catalog:1.0")
}
}
}覆盖目录版本
如果目录声明了版本,您可以在导入目录时覆盖该版本:
dependencyResolutionManagement {
versionCatalogs {
create("amendedLibs") {
from("com.mycompany:catalog:1.0")
// overwrite the "groovy" version declared in the imported catalog
version("groovy", "3.0.6")
}
}
}dependencyResolutionManagement {
versionCatalogs {
amendedLibs {
from("com.mycompany:catalog:1.0")
// overwrite the "groovy" version declared in the imported catalog
version("groovy", "3.0.6")
}
}
}在上面的示例中,任何使用groovy版本作为参考的依赖项都将自动更新为使用3.0.6.
|
笔记
|
同样,覆盖版本并不意味着实际解析的依赖项版本将相同:这只会更改导入的内容,也就是说声明依赖项时使用的内容。实际版本将遵循传统的冲突解决方案(如果有)。 |
使用平台来控制传递版本
平台是一种特殊的软件组件,可用于控制传递依赖版本。在大多数情况下,它完全由依赖项约束组成,这些依赖项约束将建议依赖项版本或强制执行某些版本。因此,每当您需要在项目之间共享依赖项版本时,这都是一个完美的工具。在这种情况下,项目通常会这样组织:
-
一个
platform项目,它定义了不同子项目中发现的各种依赖项的约束 -
一些依赖于平台并声明无版本依赖关系的子项目
在Java生态系统中,Gradle为此提供了一个插件。
发现Gradle 原生支持的以 Maven BOM 形式发布的平台也很常见。
使用关键字创建对平台的依赖关系platform:
dependencies {
// get recommended versions from the platform project
api(platform(project(":platform")))
// no version required
api("commons-httpclient:commons-httpclient")
}dependencies {
// get recommended versions from the platform project
api platform(project(':platform'))
// no version required
api 'commons-httpclient:commons-httpclient'
}该platform表示法是一种简写表示法,实际上在幕后执行了多种操作:
-
它将org.gradle.category 属性设置为
platform,这意味着 Gradle 将选择依赖项的平台组件。 -
它默认设置endorsStrictVersions行为,这意味着如果平台声明严格依赖关系,它们将被强制执行。
这意味着默认情况下,对平台的依赖会触发该平台中定义的所有严格版本的继承,这对于平台作者确保所有消费者尊重他们在依赖项版本方面的决定非常有用。可以通过显式调用该方法来关闭此功能doNotEndorseStrictVersions。
导入 Maven BOM
Gradle 提供对导入物料清单 (BOM) 文件的支持,这些文件是用于控制直接依赖项和传递依赖项的依赖项版本的有效.pom文件。 <dependencyManagement>Gradle 中的 BOM 支持的工作方式与<scope>import</scope>依赖 Maven 中的 BOM 时的使用类似。然而,在 Gradle 中,这是通过 BOM 上的常规依赖项声明来完成的:
dependencies {
// import a BOM
implementation(platform("org.springframework.boot:spring-boot-dependencies:1.5.8.RELEASE"))
// define dependencies without versions
implementation("com.google.code.gson:gson")
implementation("dom4j:dom4j")
}dependencies {
// import a BOM
implementation platform('org.springframework.boot:spring-boot-dependencies:1.5.8.RELEASE')
// define dependencies without versions
implementation 'com.google.code.gson:gson'
implementation 'dom4j:dom4j'
}在示例中,gson和的版本dom4j由 Spring Boot BOM 提供。这样,如果您正在为像 Spring Boot 这样的平台进行开发,则不必自己声明任何版本,而是可以依赖平台提供的版本。
Gradle 对待 BOM 块中的所有条目的方式与Gradle 的依赖关系约束<dependencyManagement>类似。这意味着块中定义的任何版本都可能影响依赖项解析结果。为了符合 BOM 的资格,需要设置一个文件。<dependencyManagement>.pom<packaging>pom</packaging>
然而,BOM 通常不仅提供版本作为建议,而且还提供一种覆盖图中发现的任何其他版本的方法。您可以在导入 BOM 时使用enforcedPlatform关键字而不是 来启用此行为:platform
dependencies {
// import a BOM. The versions used in this file will override any other version found in the graph
implementation(enforcedPlatform("org.springframework.boot:spring-boot-dependencies:1.5.8.RELEASE"))
// define dependencies without versions
implementation("com.google.code.gson:gson")
implementation("dom4j:dom4j")
// this version will be overridden by the one found in the BOM
implementation("org.codehaus.groovy:groovy:1.8.6")
}dependencies {
// import a BOM. The versions used in this file will override any other version found in the graph
implementation enforcedPlatform('org.springframework.boot:spring-boot-dependencies:1.5.8.RELEASE')
// define dependencies without versions
implementation 'com.google.code.gson:gson'
implementation 'dom4j:dom4j'
// this version will be overridden by the one found in the BOM
implementation 'org.codehaus.groovy:groovy:1.8.6'
}|
警告
|
|
我应该使用平台还是目录?
由于平台和目录都讨论依赖项版本,并且都可以用于在项目中共享依赖项版本,因此可能会出现关于使用什么以及其中一个是否优于另一个的混淆。
简而言之,您应该:
-
使用目录仅定义项目的依赖项及其版本并生成类型安全的访问器
-
使用平台将版本应用于依赖关系图并影响依赖关系解析
目录有助于集中依赖项版本,顾名思义,它只是您可以从中选择的依赖项目录。在所有情况下,我们建议使用它来声明依赖项的坐标。 Gradle 将使用它来生成类型安全的访问器,为外部依赖项提供简写符号,并允许在不同项目之间轻松共享这些坐标。使用目录不会对下游消费者产生任何后果:它对他们来说是透明的。
平台是一个更重量级的构造:它是依赖图的组件,就像任何其他库一样。如果您依赖于某个平台,那么该平台本身就是图中的一个组件。这尤其意味着:
总之,使用目录始终是一种良好的工程实践,因为它集中了通用定义,允许共享依赖项版本或插件版本,但它是构建的“实现细节”:它对消费者和未使用的元素不可见。目录被忽略。
平台旨在影响依赖关系解析图,例如通过添加对传递依赖关系的约束:它是构建依赖关系图并影响解析结果的解决方案。
实际上,您的项目既可以使用目录,又可以声明一个本身使用该目录的平台:
plugins {
`java-platform`
}
dependencies {
constraints {
api(libs.mylib)
}
}plugins {
id 'java-platform'
}
dependencies {
constraints {
api(libs.mylib)
}
}调整依赖版本
依赖版本对齐允许属于同一逻辑组(平台)的不同模块在依赖图中具有相同的版本。
处理不一致的模块版本
Gradle 支持对齐属于同一“平台”的模块版本。例如,组件的 API 和实现模块通常最好使用相同的版本。然而,由于传递依赖解析的游戏,属于同一平台的不同模块最终可能使用不同的版本。例如,您的项目可能依赖于jackson-databind和vert.x库,如下所示:
dependencies {
// a dependency on Jackson Databind
implementation("com.fasterxml.jackson.core:jackson-databind:2.8.9")
// and a dependency on vert.x
implementation("io.vertx:vertx-core:3.5.3")
}dependencies {
// a dependency on Jackson Databind
implementation 'com.fasterxml.jackson.core:jackson-databind:2.8.9'
// and a dependency on vert.x
implementation 'io.vertx:vertx-core:3.5.3'
}因为vert.x依赖于jackson-core,我们实际上会解析以下依赖版本:
-
jackson-core版本2.9.5(由 带来vertx-core) -
jackson-databind版本2.9.5(通过冲突解决) -
jackson-annotation版本2.9.0( 的依赖项jackson-databind:2.9.5)
很容易最终得到一组不能很好地协同工作的版本。为了解决这个问题,Gradle 支持依赖版本对齐,这是由平台概念支持的。平台代表一组“协同工作”的模块。要么是因为它们实际上是作为一个整体发布的(当平台的一个成员发布时,所有其他模块也以相同的版本发布),要么是因为有人测试了这些模块并表明它们可以很好地协同工作(通常,春季平台)。
使用 Gradle 本地调整版本
Gradle 本身支持 Gradle 生成的模块的对齐。这是依赖约束传递性的直接结果。因此,如果您有一个多项目构建,并且希望消费者获得所有模块的相同版本,Gradle 提供了一种使用Java Platform Plugin来实现此目的的简单方法。
例如,如果您有一个由 3 个模块组成的项目:
-
lib -
utils -
core,取决于lib和utils
以及声明以下依赖项的消费者:
-
core1.0版 -
lib1.1版
那么默认情况下解析将选择core:1.0和lib:1.1,因为lib不依赖于core。我们可以通过在项目中添加一个新模块来解决这个问题,即一个平台,它将对项目的所有模块添加约束:
plugins {
`java-platform`
}
dependencies {
// The platform declares constraints on all components that
// require alignment
constraints {
api(project(":core"))
api(project(":lib"))
api(project(":utils"))
}
}plugins {
id 'java-platform'
}
dependencies {
// The platform declares constraints on all components that
// require alignment
constraints {
api(project(":core"))
api(project(":lib"))
api(project(":utils"))
}
}完成此操作后,我们需要确保所有模块现在都依赖于平台,如下所示:
dependencies {
// Each project has a dependency on the platform
api(platform(project(":platform")))
// And any additional dependency required
implementation(project(":lib"))
implementation(project(":utils"))
}dependencies {
// Each project has a dependency on the platform
api(platform(project(":platform")))
// And any additional dependency required
implementation(project(":lib"))
implementation(project(":utils"))
}重要的是,平台包含对所有组件的约束,而且每个组件都对平台具有依赖性。通过这样做,每当 Gradle 在图表上添加对平台模块的依赖项时,它还将包括对平台其他模块的约束。这意味着,如果我们看到属于同一平台的另一个模块,我们将自动升级到同一版本。
在我们的示例中,这意味着我们首先看到,它带来了一个对和进行约束的core:1.0平台。然后我们添加它依赖于.通过冲突解决,我们选择平台,该平台对.然后我们解决和之间的冲突,这意味着和现在正确对齐。1.0lib:1.0lib:1.0lib:1.1platform:1.11.1core:1.1core:1.0core:1.1corelib
|
笔记
|
仅当您使用 Gradle 模块元数据时,才会对已发布的组件强制执行此行为。 |
对齐未使用 Gradle 发布的模块版本
每当发布者不使用 Gradle 时(就像我们的 Jackson 示例一样),我们可以向 Gradle 解释所有 Jackson 模块“属于”同一平台,并受益于与本机对齐相同的行为。有两种选项可以表达一组模块属于一个平台:
-
平台作为BOM发布并可以使用:例如,可以用作平台。在这种情况下,Gradle 缺少的信息是,如果使用平台的成员之一,则应将平台添加到依赖项中。
com.fasterxml.jackson:jackson-bom -
无法使用现有平台。相反,一个虚拟平台应该由 Gradle 创建:在这种情况下,Gradle 基于所有使用的成员构建平台本身。
要向 Gradle 提供缺失的信息,您可以定义组件元数据规则,如下所述。
使用已发布的 BOM 调整模块的版本
abstract class JacksonBomAlignmentRule: ComponentMetadataRule {
override fun execute(ctx: ComponentMetadataContext) {
ctx.details.run {
if (id.group.startsWith("com.fasterxml.jackson")) {
// declare that Jackson modules belong to the platform defined by the Jackson BOM
belongsTo("com.fasterxml.jackson:jackson-bom:${id.version}", false)
}
}
}
}abstract class JacksonBomAlignmentRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext ctx) {
ctx.details.with {
if (id.group.startsWith("com.fasterxml.jackson")) {
// declare that Jackson modules belong to the platform defined by the Jackson BOM
belongsTo("com.fasterxml.jackson:jackson-bom:${id.version}", false)
}
}
}
}通过使用belongsTowith false(不是虚拟的),我们声明所有模块都属于同一个发布平台。在这种情况下,平台是com.fasterxml.jackson:jackson-bom,Gradle 将在声明的存储库中查找它,就像任何其他模块一样。
dependencies {
components.all<JacksonBomAlignmentRule>()
}dependencies {
components.all(JacksonBomAlignmentRule)
}使用该规则,上例中的版本将与所选的定义版本对齐com.fasterxml.jackson:jackson-bom。在这种情况下,com.fasterxml.jackson:jackson-bom:2.9.5将选择2.9.5所选模块的最高版本。在该 BOM 中,定义并将使用以下版本:
jackson-core:2.9.5、
jackson-databind:2.9.5和
jackson-annotation:2.9.0。此处的较低版本jackson-annotation可能是所需的结果,因为这是 BOM 推荐的结果。
|
笔记
|
从 Gradle 6.1 开始,这种行为就可靠了。实际上,它类似于组件元数据规则,该规则将平台依赖项添加到使用withDependencies.
|
在没有发布平台的情况下调整模块版本
abstract class JacksonAlignmentRule: ComponentMetadataRule {
override fun execute(ctx: ComponentMetadataContext) {
ctx.details.run {
if (id.group.startsWith("com.fasterxml.jackson")) {
// declare that Jackson modules all belong to the Jackson virtual platform
belongsTo("com.fasterxml.jackson:jackson-virtual-platform:${id.version}")
}
}
}
}abstract class JacksonAlignmentRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext ctx) {
ctx.details.with {
if (id.group.startsWith("com.fasterxml.jackson")) {
// declare that Jackson modules all belong to the Jackson virtual platform
belongsTo("com.fasterxml.jackson:jackson-virtual-platform:${id.version}")
}
}
}
}通过使用belongsTo不带进一步参数的关键字(platform is virtual),我们声明所有模块都属于同一个虚拟平台,该平台受到引擎的特殊对待。不会从存储库中检索虚拟平台。在这种情况下,标识符com.fasterxml.jackson:jackson-virtual-platform是您作为构建作者自己定义的。然后,Gradle 通过收集belongsTo指向同一虚拟平台的所有语句来即时创建平台的“内容” 。
dependencies {
components.all<JacksonAlignmentRule>()
}dependencies {
components.all(JacksonAlignmentRule)
}使用该规则,上例中的所有版本都将与2.9.5.在这种情况下,也jackson-annotation:2.9.5将被采用,因为这就是我们定义本地虚拟平台的方式。
对于发布平台和虚拟平台,Gradle 允许您通过指定对平台的强制依赖来覆盖平台本身的版本选择:
dependencies {
// Forcefully downgrade the virtual Jackson platform to 2.8.9
implementation(enforcedPlatform("com.fasterxml.jackson:jackson-virtual-platform:2.8.9"))
}dependencies {
// Forcefully downgrade the virtual Jackson platform to 2.8.9
implementation enforcedPlatform('com.fasterxml.jackson:jackson-virtual-platform:2.8.9')
}处理互斥的依赖关系
组件能力介绍
通常,依赖关系图会意外地包含同一 API 的多个实现。这在日志记录框架中尤其常见,其中有多个绑定可用,并且当另一个传递依赖项选择另一个绑定时,一个库会选择一个绑定。由于这些实现位于不同的 GAV 坐标,因此构建工具通常无法发现这些库之间存在冲突。为了解决这个问题,Gradle 提供了能力的概念。
在单个依赖图中找到两个提供相同功能的组件是非法的。直观上,这意味着如果 Gradle 发现两个在类路径上提供相同内容的组件,它将失败并显示错误,指示哪些模块存在冲突。在我们的示例中,这意味着日志记录框架的不同绑定提供相同的功能。
能力坐标
能力由三元组定义。(group, module, version)每个组件定义了与其 GAV 坐标(组、工件、版本)相对应的隐式功能。例如,该模块具有包含 group 、 name和 version 的org.apache.commons:commons-lang3:3.8隐式功能。重要的是要认识到功能是有版本的。org.apache.commonscommons-lang33.8
声明组件功能
默认情况下,如果依赖图中的两个组件提供相同的功能,Gradle 将失败。由于大多数模块目前在没有 Gradle 模块元数据的情况下发布,因此 Gradle 并不总是自动发现功能。然而,使用规则来声明组件功能以便在构建期间而不是运行时尽快发现冲突是很有趣的。
一个典型的例子是每当一个组件在新版本中重新定位到不同的坐标时。例如,ASM 库在asm:asmversion 之前的坐标为3.3.1,然后更改为org.ow2.asm:asmsince 4.0。在类路径上同时存在 ASM <= 3.3.1 和 4.0+ 是非法的,因为它们提供相同的功能,只是组件已重新定位。因为每个组件都有一个与其 GAV 坐标相对应的隐式功能,所以我们可以通过一条声明该asm:asm模块提供该功能的规则来“修复”此问题org.ow2.asm:asm:
class AsmCapability : ComponentMetadataRule {
override
fun execute(context: ComponentMetadataContext) = context.details.run {
if (id.group == "asm" && id.name == "asm") {
allVariants {
withCapabilities {
// Declare that ASM provides the org.ow2.asm:asm capability, but with an older version
addCapability("org.ow2.asm", "asm", id.version)
}
}
}
}
}@CompileStatic
class AsmCapability implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
context.details.with {
if (id.group == "asm" && id.name == "asm") {
allVariants {
it.withCapabilities {
// Declare that ASM provides the org.ow2.asm:asm capability, but with an older version
it.addCapability("org.ow2.asm", "asm", id.version)
}
}
}
}
}
}现在,只要在同一个依赖图中找到两个组件,构建就会失败。
|
笔记
|
在这个阶段,Gradle 只会让更多的构建失败。它不会自动为您解决问题,但可以帮助您意识到自己有问题。建议在插件中编写此类规则,然后将其应用于您的构建。然后,如果可能的话,用户必须表达他们的偏好,或者修复类路径上存在不兼容内容的问题,如下一节所述。 |
在候选人之间进行选择
在某些时候,依赖关系图将包括不兼容的模块或互斥的模块。例如,您可能有不同的记录器实现,并且需要选择一种绑定。 功能有助于意识到您存在冲突,但 Gradle 还提供了工具来表达如何解决冲突。
在不同能力候选人之间进行选择
在上面的重定位示例中,Gradle 能够告诉您,类路径上有同一 API 的两个版本:一个“旧”模块和一个“重定位”模块。现在我们可以通过自动选择具有最高能力版本的组件来解决冲突:
configurations.all {
resolutionStrategy.capabilitiesResolution.withCapability("org.ow2.asm:asm") {
selectHighestVersion()
}
}configurations.all {
resolutionStrategy.capabilitiesResolution.withCapability('org.ow2.asm:asm') {
selectHighestVersion()
}
}然而,通过选择最高功能版本冲突解决方案来修复并不总是合适的。例如,对于日志框架,无论我们使用什么版本的日志框架,我们都应该始终选择 Slf4j。
在这种情况下,我们可以通过明确选择 slf4j 作为获胜者来修复它:
configurations.all {
resolutionStrategy.capabilitiesResolution.withCapability("log4j:log4j") {
val toBeSelected = candidates.firstOrNull { it.id.let { id -> id is ModuleComponentIdentifier && id.module == "log4j-over-slf4j" } }
if (toBeSelected != null) {
select(toBeSelected)
}
because("use slf4j in place of log4j")
}
}configurations.all {
resolutionStrategy.capabilitiesResolution.withCapability("log4j:log4j") {
def toBeSelected = candidates.find { it.id instanceof ModuleComponentIdentifier && it.id.module == 'log4j-over-slf4j' }
if (toBeSelected != null) {
select(toBeSelected)
}
because 'use slf4j in place of log4j'
}
}请注意,如果您在类路径上有多个Slf4j 绑定,这种方法也很有效:绑定基本上是不同的记录器实现,您只需要一个。然而,所选择的实现可能取决于正在解析的配置。例如,对于测试来说,slf4j-simple可能就足够了,但对于生产来说,slf4-over-log4j可能更好。
只能做出有利于图中找到的模块的解决方案。
该方法仅接受在当前select候选中找到的模块。如果您要选择的模块不是冲突的一部分,您可以放弃执行选择,实际上并不能解决此冲突。图表中可能存在相同功能的另一个冲突,并且将包含您要选择的模块。
如果没有针对给定功能的所有冲突给出解决方案,则构建将失败,因为选择用于解决方案的模块根本不是图表的一部分。
另外select(null)还会导致错误,因此应该避免。
有关更多信息,请查看功能解析 API。
使用组件元数据规则修复元数据
从存储库中提取的每个模块都有与其关联的元数据,例如其组、名称、版本以及它提供的不同变体及其工件和依赖项。有时,此元数据不完整或不正确。为了在构建脚本中操作此类不完整的元数据,Gradle 提供了一个 API 来编写组件元数据规则。这些规则在模块的元数据下载之后、用于依赖关系解析之前生效。
编写组件元数据规则的基础知识
组件元数据规则应用于构建脚本的依赖项块 ( DependencyHandler ) 的组件 ( ComponentMetadataHandler ) 部分或设置脚本中。规则可以通过两种不同的方式定义:
-
当它们应用于组件部分时直接作为操作
虽然将内联规则定义为操作可以方便实验,但通常建议将规则定义为单独的类。可以对编写为独立类的规则进行注释,以@CacheableRule缓存其应用程序的结果,这样就不需要在每次解决依赖关系时重新执行它们。
@CacheableRule
abstract class TargetJvmVersionRule @Inject constructor(val jvmVersion: Int) : ComponentMetadataRule {
@get:Inject abstract val objects: ObjectFactory
override fun execute(context: ComponentMetadataContext) {
context.details.withVariant("compile") {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, jvmVersion)
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage.JAVA_API))
}
}
}
}
dependencies {
components {
withModule<TargetJvmVersionRule>("commons-io:commons-io") {
params(7)
}
withModule<TargetJvmVersionRule>("commons-collections:commons-collections") {
params(8)
}
}
implementation("commons-io:commons-io:2.6")
implementation("commons-collections:commons-collections:3.2.2")
}@CacheableRule
abstract class TargetJvmVersionRule implements ComponentMetadataRule {
final Integer jvmVersion
@Inject TargetJvmVersionRule(Integer jvmVersion) {
this.jvmVersion = jvmVersion
}
@Inject abstract ObjectFactory getObjects()
void execute(ComponentMetadataContext context) {
context.details.withVariant("compile") {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, jvmVersion)
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, Usage.JAVA_API))
}
}
}
}
dependencies {
components {
withModule("commons-io:commons-io", TargetJvmVersionRule) {
params(7)
}
withModule("commons-collections:commons-collections", TargetJvmVersionRule) {
params(8)
}
}
implementation("commons-io:commons-io:2.6")
implementation("commons-collections:commons-collections:3.2.2")
}从上面的示例中可以看出,组件元数据规则是通过实现ComponentMetadataRule来定义的,该规则具有接收ComponentMetadataContextexecute实例作为参数的单个方法。在此示例中,还通过ActionConfiguration进一步配置规则。这是通过在您的实现中使用构造函数来接受已配置的参数和需要注入的服务来支持的。ComponentMetadataRule
Gradle 强制隔离ComponentMetadataRule.这意味着所有参数必须是Serializable或者已知的可以隔离的 Gradle 类型。
此外,Gradle 服务可以注入到您的ComponentMetadataRule.因此,一旦有了构造函数,就必须用 进行注释@javax.inject.Inject。通常需要的服务是ObjectFactory ,用于创建强类型值对象的实例,例如用于设置Attribute 的值。RepositoryResourceAccessor是一项有助于高级使用自定义元数据的组件元数据规则的服务。
组件元数据规则可以应用于所有模块——all(rule)或者应用于选定的模块withModule(groupAndName, rule)。通常,规则是专门为了丰富某个特定模块的元数据而编写的,因此withModule应该首选 API。
在中心位置声明规则
|
笔记
|
在设置中声明组件元数据规则是一项正在孵化的功能 |
可以在文件中settings.gradle(.kts)为整个构建声明规则,而不是单独为每个子项目声明规则。设置中声明的规则是应用于每个项目的常规规则:如果项目未声明任何规则,则将使用设置脚本中的规则。
dependencyResolutionManagement {
components {
withModule<GuavaRule>("com.google.guava:guava")
}
}dependencyResolutionManagement {
components {
withModule("com.google.guava:guava", GuavaRule)
}
}默认情况下,项目中声明的规则将覆盖设置中声明的任何内容。可以更改此默认值,例如始终首选设置规则:
dependencyResolutionManagement {
rulesMode = RulesMode.PREFER_SETTINGS
}dependencyResolutionManagement {
rulesMode = RulesMode.PREFER_SETTINGS
}如果调用此方法并且项目或插件声明了规则,则会发出警告。您可以使用以下替代方案来使其失败:
dependencyResolutionManagement {
rulesMode = RulesMode.FAIL_ON_PROJECT_RULES
}dependencyResolutionManagement {
rulesMode = RulesMode.FAIL_ON_PROJECT_RULES
}默认行为相当于调用此方法:
dependencyResolutionManagement {
rulesMode = RulesMode.PREFER_PROJECT
}dependencyResolutionManagement {
rulesMode = RulesMode.PREFER_PROJECT
}元数据的哪些部分可以修改?
组件元数据规则 API 面向Gradle 模块元数据和构建脚本中的依赖项API 支持的功能。在构建脚本中编写规则与定义依赖项和工件之间的主要区别在于,组件元数据规则遵循 Gradle 模块元数据的结构,直接对变体进行操作。相反,在构建脚本中,您经常会同时影响多个变体的形状(例如,将api依赖项添加到Java 库的api和运行时变体中,由jar任务生成的工件也添加到这两个变体中) 。
可以通过以下方法对变体进行修改:
-
allVariants:修改组件的所有变体 -
withVariant(name):修改由名称标识的单个变体 -
addVariant(name)或:从头开始或通过复制现有变体(基础)的详细信息addVariant(name, base)向组件添加新变体
每个变体的以下细节可以调整:
整个组件还有一些属性可以更改:
-
组件级属性,目前唯一有意义的属性
org.gradle.status -
在版本选择期间影响属性解释的状态方案
org.gradle.status -
通过虚拟平台进行版本对齐的belongsTo属性
根据模块元数据的格式,它会以不同的方式映射到元数据的以变体为中心的表示形式:
-
如果模块具有 Gradle 模块元数据,则规则操作的数据结构与您在模块
.module文件中找到的数据结构非常相似。 -
如果模块仅使用
.pom元数据发布,则会派生出许多固定变体,如POM 文件到变体的映射部分中所述。 -
如果模块仅通过文件发布
ivy.xml,则可以访问文件中定义的Ivy 配置而不是变体。它们的依赖关系、依赖关系约束和文件都可以修改。此外,如果需要,该addVariant(name, baseVariantOrConfiguration) { }API 还可用于从Ivy 配置派生变体(例如,可以使用此定义Java 库插件的编译和运行时变体)。
何时使用组件元数据规则?
一般来说,如果您考虑使用组件元数据规则来调整某个模块的元数据,您应该首先检查该模块是否是使用 Gradle 模块元数据(.module文件)或仅传统元数据(.pom或ivy.xml)发布的。
如果模块是使用 Gradle 模块元数据发布的,则元数据可能是完整的,尽管仍然可能存在明显错误的情况。对于这些模块,如果您已明确识别元数据本身存在问题,则应仅使用组件元数据规则。如果您对依赖项解析结果有问题,您应该首先检查是否可以通过声明丰富版本的依赖项约束来解决该问题。特别是,如果您正在开发要发布的库,您应该记住,与组件元数据规则相反,依赖性约束是作为您自己的库的元数据的一部分发布的。因此,通过依赖关系约束,您可以自动与消费者共享依赖关系解决问题的解决方案,而组件元数据规则仅应用于您自己的构建。
如果模块是使用传统元数据(.pom或ivy.xml仅没有.module文件)发布的,则元数据很可能不完整,因为这些格式不支持变体或依赖性约束等功能。尽管如此,从概念上讲,此类模块可以包含不同的变体,或者可能具有它们刚刚省略的依赖关系约束(或错误地定义为依赖关系)。在接下来的部分中,我们将探讨一些具有此类不完整元数据的现有 oss 模块以及添加缺失元数据信息的规则。
根据经验,您应该考虑您正在编写的规则是否也可以在构建的上下文之外工作。也就是说,如果应用于使用其影响的模块的任何其他构建,该规则是否仍然会产生正确且有用的结果?
修复错误的依赖细节
让我们以Maven Central上的 Jaxen XPath Engine 发布为例。 1.1.3版本的pom在编译范围内声明了许多编译实际上不需要的依赖项。这些已在 1.1.4 pom 中删除。假设由于某种原因我们需要使用 1.1.3,我们可以使用以下规则修复元数据:
@CacheableRule
abstract class JaxenDependenciesRule: ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
context.details.allVariants {
withDependencies {
removeAll { it.group in listOf("dom4j", "jdom", "xerces", "maven-plugins", "xml-apis", "xom") }
}
}
}
}@CacheableRule
abstract class JaxenDependenciesRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
context.details.allVariants {
withDependencies {
removeAll { it.group in ["dom4j", "jdom", "xerces", "maven-plugins", "xml-apis", "xom"] }
}
}
}
}在该withDependencies块中,您可以访问完整的依赖项列表,并可以使用 Java 集合接口上可用的所有方法来检查和修改该列表。此外,还有add(notation, configureAction)一些方法接受类似于在构建脚本中声明依赖项的常用符号。可以在块中以相同的方式检查和修改依赖约束withDependencyConstraints。
如果我们仔细查看 Jaxen 1.1.4 pom,我们会发现dom4j、jdom和xerces依赖项仍然存在,但标记为可选。 Gradle 或 Maven 不会自动处理 poms 中的可选依赖项。原因是它们表明 Jaxen 库提供了一些可选功能变体,这些变体需要一个或多个这些依赖项,但缺少这些功能是什么以及哪个依赖项属于哪个功能的信息。此类信息不能在 pom 文件中表示,而是通过变量和功能在 Gradle 模块元数据中表示。因此,我们也可以在规则中添加这些信息。
@CacheableRule
abstract class JaxenCapabilitiesRule: ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
context.details.addVariant("runtime-dom4j", "runtime") {
withCapabilities {
removeCapability("jaxen", "jaxen")
addCapability("jaxen", "jaxen-dom4j", context.details.id.version)
}
withDependencies {
add("dom4j:dom4j:1.6.1")
}
}
}
}@CacheableRule
abstract class JaxenCapabilitiesRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
context.details.addVariant("runtime-dom4j", "runtime") {
withCapabilities {
removeCapability("jaxen", "jaxen")
addCapability("jaxen", "jaxen-dom4j", context.details.id.version)
}
withDependencies {
add("dom4j:dom4j:1.6.1")
}
}
}
}在这里,我们首先使用该addVariant(name, baseVariant)方法创建一个附加变体,通过定义新功能jaxen-dom4j来表示 Jaxen 的可选 dom4j 集成功能,将其识别为功能变体。这与在构建脚本中定义可选功能变体类似。然后,我们使用添加依赖项的方法之一来定义此可选功能需要哪些依赖项。add
在构建脚本中,我们可以添加对可选功能的依赖项,Gradle 将使用丰富的元数据来发现正确的传递依赖项。
dependencies {
components {
withModule<JaxenDependenciesRule>("jaxen:jaxen")
withModule<JaxenCapabilitiesRule>("jaxen:jaxen")
}
implementation("jaxen:jaxen:1.1.3")
runtimeOnly("jaxen:jaxen:1.1.3") {
capabilities { requireCapability("jaxen:jaxen-dom4j") }
}
}dependencies {
components {
withModule("jaxen:jaxen", JaxenDependenciesRule)
withModule("jaxen:jaxen", JaxenCapabilitiesRule)
}
implementation("jaxen:jaxen:1.1.3")
runtimeOnly("jaxen:jaxen:1.1.3") {
capabilities { requireCapability("jaxen:jaxen-dom4j") }
}
}使变体明确发布为分类罐子
虽然在前面的示例中,所有变体、“主要变体”和可选功能都打包在一个 jar 文件中,但通常将某些变体发布为单独的文件。特别是,当变体是互斥的时——即它们不是特征变体,而是提供替代选择的不同变体。所有基于 pom 的库都已经拥有的一个例子是运行时和编译变体,其中 Gradle 只能根据手头的任务选择一个。 Java 生态系统中经常发现的另一种替代方案是针对不同 Java 版本的 jar。
作为示例,我们看一下Mavencentral上发布的异步编程库 Quasar 0.7.9 版本。如果我们检查目录列表,我们会发现quasar-core-0.7.9-jdk8.jar除了quasar-core-0.7.9.jar.使用分类器(此处为jdk8 )发布其他 jar是 Maven 存储库中的常见做法。虽然 Maven 和 Gradle 都允许您通过分类器引用此类 jar,但元数据中根本没有提及它们。因此,没有任何信息表明这些 jar 存在,也不知道这些 jar 代表的变体之间是否存在任何其他差异(例如不同的依赖关系)。
在 Gradle 模块元数据中,会出现此变体信息,对于已经发布的 Quasar 库,我们可以使用以下规则添加它:
@CacheableRule
abstract class QuasarRule: ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
listOf("compile", "runtime").forEach { base ->
context.details.addVariant("jdk8${base.capitalize()}", base) {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 8)
}
withFiles {
removeAllFiles()
addFile("${context.details.id.name}-${context.details.id.version}-jdk8.jar")
}
}
context.details.withVariant(base) {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 7)
}
}
}
}
}@CacheableRule
abstract class QuasarRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
["compile", "runtime"].each { base ->
context.details.addVariant("jdk8${base.capitalize()}", base) {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 8)
}
withFiles {
removeAllFiles()
addFile("${context.details.id.name}-${context.details.id.version}-jdk8.jar")
}
}
context.details.withVariant(base) {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 7)
}
}
}
}
}在这种情况下,很明显分类器代表目标 Java 版本,这是一个已知的 Java 生态系统属性。因为我们还需要Java 8 的编译和运行时,所以我们创建了两个新变体,但使用现有的编译和运行时变体作为基础。这样,所有其他 Java 生态系统属性都已正确设置,并且所有依赖项都已保留。然后我们将两个变体设置TARGET_JVM_VERSION_ATTRIBUTE为8,从新变体中删除任何现有文件removeAllFiles(),并添加 jdk8 jar 文件addFile()。这removeAllFiles()是必需的,因为对主 jar 的引用quasar-core-0.7.5.jar是从相应的基本变体复制的。
我们还通过它们针对 Java 7 的信息丰富了现有的编译和运行时attribute(TARGET_JVM_VERSION_ATTRIBUTE, 7)变体 — .
现在,我们可以为构建脚本中编译类路径的所有依赖项请求 Java 8 版本,Gradle 会自动为每个库选择最合适的变体。对于 Quasar,这现在将是公开quasar-core-0.7.9-jdk8.jar.
configurations["compileClasspath"].attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 8)
}
dependencies {
components {
withModule<QuasarRule>("co.paralleluniverse:quasar-core")
}
implementation("co.paralleluniverse:quasar-core:0.7.9")
}configurations.compileClasspath.attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 8)
}
dependencies {
components {
withModule("co.paralleluniverse:quasar-core", QuasarRule)
}
implementation("co.paralleluniverse:quasar-core:0.7.9")
}使版本中编码的变体显式化
为同一库发布多个替代方案的另一个解决方案是使用版本控制模式,如流行的 Guava 库所做的那样。在这里,通过将分类器而不是 jar 工件附加到版本,每个新版本都会发布两次。以 Guava 28 为例,我们可以在Mavencentral上找到28.0-jre (Java 8) 和28.0-android (Java 6) 版本。仅使用 pom 元数据时使用此模式的优点是两种变体都可以通过版本发现。缺点是没有信息说明不同版本后缀的语义含义。因此,在发生冲突的情况下,Gradle 在比较版本字符串时只会选择最高版本。
将其转换为适当的变体有点棘手,因为 Gradle 首先选择模块的版本,然后选择最合适的变体。因此,不直接支持将变体编码为版本的概念。但是,由于这两个变体总是一起发布,我们可以假设这些文件物理上位于同一存储库中。由于它们是按照 Maven 存储库约定发布的,因此如果我们知道模块名称和版本,我们就知道每个文件的位置。我们可以写出以下规则:
@CacheableRule
abstract class GuavaRule: ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
val variantVersion = context.details.id.version
val version = variantVersion.substring(0, variantVersion.indexOf("-"))
listOf("compile", "runtime").forEach { base ->
mapOf(6 to "android", 8 to "jre").forEach { (targetJvmVersion, jarName) ->
context.details.addVariant("jdk$targetJvmVersion${base.capitalize()}", base) {
attributes {
attributes.attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, targetJvmVersion)
}
withFiles {
removeAllFiles()
addFile("guava-$version-$jarName.jar", "../$version-$jarName/guava-$version-$jarName.jar")
}
}
}
}
}
}@CacheableRule
abstract class GuavaRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
def variantVersion = context.details.id.version
def version = variantVersion.substring(0, variantVersion.indexOf("-"))
["compile", "runtime"].each { base ->
[6: "android", 8: "jre"].each { targetJvmVersion, jarName ->
context.details.addVariant("jdk$targetJvmVersion${base.capitalize()}", base) {
attributes {
attributes.attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, targetJvmVersion)
}
withFiles {
removeAllFiles()
addFile("guava-$version-${jarName}.jar", "../$version-$jarName/guava-$version-${jarName}.jar")
}
}
}
}
}
}与前面的示例类似,我们为两个 Java 版本添加运行时和编译变体。然而,在该withFiles块中,我们现在还指定了相应 jar 文件的相对路径,这使得 Gradle 可以找到该文件,无论它选择的是-jre还是-android版本。该路径始终相对于pom选择模块版本的元数据(在本例中)文件的位置。因此,根据此规则,两个 Guava 28“版本”都带有jdk6和jdk8变体。因此,Gradle 解析为哪一个并不重要。该变体以及正确的 jar 文件是根据请求的TARGET_JVM_VERSION_ATTRIBUTE值确定的。
configurations["compileClasspath"].attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 6)
}
dependencies {
components {
withModule<GuavaRule>("com.google.guava:guava")
}
// '23.3-android' and '23.3-jre' are now the same as both offer both variants
implementation("com.google.guava:guava:23.3+")
}configurations.compileClasspath.attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 6)
}
dependencies {
components {
withModule("com.google.guava:guava", GuavaRule)
}
// '23.3-android' and '23.3-jre' are now the same as both offer both variants
implementation("com.google.guava:guava:23.3+")
}添加原生 jar 的变体
带有分类器的 jar 还用于将存在多个替代方案的库部分(例如本机代码)与主要工件分开。例如,这是由轻量级 Java 游戏库 (LWGJ) 完成的,该库将多个特定于平台的 jar 发布到Maven 中心,除了主 jar 之外,在运行时始终需要其中一个。不可能在 pom 元数据中传达此信息,因为不存在通过元数据关联多个工件的概念。在 Gradle 模块元数据中,每个变体可以有任意多个文件,我们可以通过编写以下规则来利用它:
@CacheableRule
abstract class LwjglRule: ComponentMetadataRule {
data class NativeVariant(val os: String, val arch: String, val classifier: String)
private val nativeVariants = listOf(
NativeVariant(OperatingSystemFamily.LINUX, "arm32", "natives-linux-arm32"),
NativeVariant(OperatingSystemFamily.LINUX, "arm64", "natives-linux-arm64"),
NativeVariant(OperatingSystemFamily.WINDOWS, "x86", "natives-windows-x86"),
NativeVariant(OperatingSystemFamily.WINDOWS, "x86-64", "natives-windows"),
NativeVariant(OperatingSystemFamily.MACOS, "x86-64", "natives-macos")
)
@get:Inject abstract val objects: ObjectFactory
override fun execute(context: ComponentMetadataContext) {
context.details.withVariant("runtime") {
attributes {
attributes.attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named("none"))
attributes.attribute(MachineArchitecture.ARCHITECTURE_ATTRIBUTE, objects.named("none"))
}
}
nativeVariants.forEach { variantDefinition ->
context.details.addVariant("${variantDefinition.classifier}-runtime", "runtime") {
attributes {
attributes.attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named(variantDefinition.os))
attributes.attribute(MachineArchitecture.ARCHITECTURE_ATTRIBUTE, objects.named(variantDefinition.arch))
}
withFiles {
addFile("${context.details.id.name}-${context.details.id.version}-${variantDefinition.classifier}.jar")
}
}
}
}
}@CacheableRule
abstract class LwjglRule implements ComponentMetadataRule { //val os: String, val arch: String, val classifier: String)
private def nativeVariants = [
[os: OperatingSystemFamily.LINUX, arch: "arm32", classifier: "natives-linux-arm32"],
[os: OperatingSystemFamily.LINUX, arch: "arm64", classifier: "natives-linux-arm64"],
[os: OperatingSystemFamily.WINDOWS, arch: "x86", classifier: "natives-windows-x86"],
[os: OperatingSystemFamily.WINDOWS, arch: "x86-64", classifier: "natives-windows"],
[os: OperatingSystemFamily.MACOS, arch: "x86-64", classifier: "natives-macos"]
]
@Inject abstract ObjectFactory getObjects()
void execute(ComponentMetadataContext context) {
context.details.withVariant("runtime") {
attributes {
attributes.attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named(OperatingSystemFamily, "none"))
attributes.attribute(MachineArchitecture.ARCHITECTURE_ATTRIBUTE, objects.named(MachineArchitecture, "none"))
}
}
nativeVariants.each { variantDefinition ->
context.details.addVariant("${variantDefinition.classifier}-runtime", "runtime") {
attributes {
attributes.attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named(OperatingSystemFamily, variantDefinition.os))
attributes.attribute(MachineArchitecture.ARCHITECTURE_ATTRIBUTE, objects.named(MachineArchitecture, variantDefinition.arch))
}
withFiles {
addFile("${context.details.id.name}-${context.details.id.version}-${variantDefinition.classifier}.jar")
}
}
}
}
}该规则与上面的 Quasar 库示例非常相似。只是这一次我们添加了五个不同的运行时变体,并且不需要对编译变体进行任何更改。运行时变体均基于现有运行时变体,我们不会更改任何现有信息。所有 Java 生态系统属性、依赖项和主 jar 文件仍然是每个运行时变体的一部分。我们只设置附加属性OPERATING_SYSTEM_ATTRIBUTE和 ,ARCHITECTURE_ATTRIBUTE它们被定义为 Gradle原生支持的一部分。我们添加相应的本机 jar 文件,以便每个运行时变体现在都带有两个文件:主 jar 和本机 jar。
在构建脚本中,我们现在可以请求特定的变体,如果需要更多信息来做出决定,Gradle 将失败并出现选择错误。
configurations["runtimeClasspath"].attributes {
attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named("windows"))
}
dependencies {
components {
withModule<LwjglRule>("org.lwjgl:lwjgl")
}
implementation("org.lwjgl:lwjgl:3.2.3")
}configurations["runtimeClasspath"].attributes {
attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named(OperatingSystemFamily, "windows"))
}
dependencies {
components {
withModule("org.lwjgl:lwjgl", LwjglRule)
}
implementation("org.lwjgl:lwjgl:3.2.3")
}> Could not resolve all files for configuration ':runtimeClasspath'.
> Could not resolve org.lwjgl:lwjgl:3.2.3.
Required by:
project :
> Cannot choose between the following variants of org.lwjgl:lwjgl:3.2.3:
- natives-windows-runtime
- natives-windows-x86-runtime
通过功能提供不同风格的库
由于很难将可选功能变体建模为具有 pom 元数据的单独 jar,因此库有时会使用不同的功能集组合不同的 jar。也就是说,您不必从不同的功能变体中组合您的库风格,而是选择预先组合的变体之一(在一个罐子中提供所有内容)。一个这样的库是著名的依赖注入框架 Guice,发布在Maven 中心,它提供了一个完整的风格(主 jar)和一个没有面向方面编程支持的简化变体(guice-4.2.2-no_aop.jar)。 pom 元数据中没有提到带有分类器的第二个变体。使用以下规则,我们基于该文件创建编译和运行时变体,并使其可以通过名为 的功能进行选择com.google.inject:guice-no_aop。
@CacheableRule
abstract class GuiceRule: ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
listOf("compile", "runtime").forEach { base ->
context.details.addVariant("noAop${base.capitalize()}", base) {
withCapabilities {
addCapability("com.google.inject", "guice-no_aop", context.details.id.version)
}
withFiles {
removeAllFiles()
addFile("guice-${context.details.id.version}-no_aop.jar")
}
withDependencies {
removeAll { it.group == "aopalliance" }
}
}
}
}
}@CacheableRule
abstract class GuiceRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
["compile", "runtime"].each { base ->
context.details.addVariant("noAop${base.capitalize()}", base) {
withCapabilities {
addCapability("com.google.inject", "guice-no_aop", context.details.id.version)
}
withFiles {
removeAllFiles()
addFile("guice-${context.details.id.version}-no_aop.jar")
}
withDependencies {
removeAll { it.group == "aopalliance" }
}
}
}
}
}新变体还删除了对标准化 aop 接口库的依赖aopalliance:aopalliance,因为这些变体显然不需要这一点。同样,这是无法用 pom 元数据表达的信息。我们现在可以选择一个guice-no_aop变体,并将获得正确的 jar 文件和正确的依赖项。
dependencies {
components {
withModule<GuiceRule>("com.google.inject:guice")
}
implementation("com.google.inject:guice:4.2.2") {
capabilities { requireCapability("com.google.inject:guice-no_aop") }
}
}dependencies {
components {
withModule("com.google.inject:guice", GuiceRule)
}
implementation("com.google.inject:guice:4.2.2") {
capabilities { requireCapability("com.google.inject:guice-no_aop") }
}
}添加缺失的功能来检测冲突
功能的另一种用法是表示两个不同的模块(例如log4j和log4j-over-slf4j)提供同一事物的替代实现。通过声明两者提供相同的功能,Gradle 在依赖关系图中仅接受其中之一。该示例以及如何使用组件元数据规则来处理该示例在特征建模部分中进行了详细描述。
使 Ivy 模块具有变体感知能力
具有 Ivy 元数据的模块默认没有变体。但是,Ivy 配置可以映射到变体,因为它addVariant(name, baseVariantOrConfiguration)接受作为基础发布的任何 Ivy 配置。例如,这可用于定义运行时和编译变体。可以在此处找到相应规则的示例。也可以使用 API 修改 Ivy 配置的 Ivy 详细信息(例如依赖项和文件)withVariant(configurationName)。但是,修改 Ivy 配置上的属性或功能没有任何效果。
对于 Ivy 特定的用例,组件元数据规则 API 还提供对仅在 Ivy 元数据中找到的其他详细信息的访问。这些可以通过IvyModuleDescriptor接口获得,并且可以使用getDescriptor(IvyModuleDescriptor)ComponentMetadataContext进行访问。
@CacheableRule
abstract class IvyComponentRule : ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
val descriptor = context.getDescriptor(IvyModuleDescriptor::class)
if (descriptor != null && descriptor.branch == "testing") {
context.details.status = "rc"
}
}
}@CacheableRule
abstract class IvyComponentRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
def descriptor = context.getDescriptor(IvyModuleDescriptor)
if (descriptor != null && descriptor.branch == "testing") {
context.details.status = "rc"
}
}
}使用 Maven 元数据进行过滤
对于 Maven 特定用例,组件元数据规则 API 还提供对仅在 POM 元数据中找到的其他详细信息的访问。这些可以通过PomModuleDescriptor接口获得,并且可以使用getDescriptor(PomModuleDescriptor)ComponentMetadataContext进行访问。
@CacheableRule
abstract class MavenComponentRule : ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
val descriptor = context.getDescriptor(PomModuleDescriptor::class)
if (descriptor != null && descriptor.packaging == "war") {
// ...
}
}
}@CacheableRule
abstract class MavenComponentRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
def descriptor = context.getDescriptor(PomModuleDescriptor)
if (descriptor != null && descriptor.packaging == "war") {
// ...
}
}
}修改组件级别的元数据以进行对齐
虽然上面的所有示例都对组件的变体进行了修改,但还可以对组件本身的元数据进行一组有限的修改。该信息可以影响依赖项解析期间模块的版本选择过程,该过程在选择组件的一个或多个变体之前执行。
该组件上可用的第一个 API 是belongsTo()创建虚拟平台,用于在没有 Gradle 模块元数据的情况下对齐多个模块的版本。有关对齐未随 Gradle 发布的模块版本的部分对此进行了详细解释。
修改组件级别的元数据以根据状态选择版本
Gradle 和 Gradle 模块元数据还允许在整个组件而不是单个变体上设置属性。这些属性中的每一个都带有特殊的语义,因为它们影响在变体选择之前完成的版本选择。虽然变体选择可以处理任何自定义属性,但版本选择仅考虑实现特定语义的属性。目前,这里唯一有意义的属性是org.gradle.status。因此,建议仅在组件级别修改此属性(如果有)。setStatus(value)为此可以使用专用 API 。withAllVariants { attributes {} }应该使用修改组件所有变体的另一个属性。
当解析最新版本选择器时,会考虑模块的状态。具体来说,将解析为具有状态或更成熟状态latest.someStatus的最高模块版本。someStatus例如,latest.integration将选择最高的模块版本,无论其状态如何(因为integration是最不成熟的状态,如下所述),而latest.release将选择状态为的最高模块版本release。
通过API 更改模块的状态方案可以影响状态的解释setStatusScheme(valueList)。这个概念模拟了模块随着时间的推移通过不同的出版物过渡的不同成熟度级别。默认状态方案(从最不成熟状态到最成熟状态排序)为integration, milestone, release。必须将该org.gradle.status属性设置为组件状态方案中的值之一。因此,每个组件始终具有根据元数据确定的状态,如下所示:
-
org.gradle.statusGradle 模块元数据:为组件上的属性发布的值 -
ivy元数据:
status在ivy.xml中定义,integration如果缺失则默认为 -
Pom 元数据:
integration适用于具有 SNAPSHOT 版本的模块,release适用于所有其他模块
以下示例演示了latest基于在适用于所有模块的组件元数据规则中声明的自定义状态方案的选择器:
@CacheableRule
abstract class CustomStatusRule : ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
context.details.statusScheme = listOf("nightly", "milestone", "rc", "release")
if (context.details.status == "integration") {
context.details.status = "nightly"
}
}
}
dependencies {
components {
all<CustomStatusRule>()
}
implementation("org.apache.commons:commons-lang3:latest.rc")
}@CacheableRule
abstract class CustomStatusRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
context.details.statusScheme = ["nightly", "milestone", "rc", "release"]
if (context.details.status == "integration") {
context.details.status = "nightly"
}
}
}
dependencies {
components {
all(CustomStatusRule)
}
implementation("org.apache.commons:commons-lang3:latest.rc")
}与默认方案相比,该规则插入了新的状态rc并替换integration为nightly。具有状态的现有模块integration被映射到nightly.
直接自定义依赖项的解析
本节介绍 Gradle 提供的直接影响依赖解析引擎行为的机制。与本章中介绍的其他概念(例如依赖关系约束或组件元数据规则)相比,这些概念都是解析的输入,以下机制允许您编写直接注入解析引擎的规则。因此,它们可以被视为强力解决方案,可能隐藏未来的问题(例如,如果添加新的依赖项)。因此,一般建议是仅在其他方法不够时才使用以下机制。如果您正在编写库,您应该始终更喜欢依赖关系约束,因为它们是为您的消费者发布的。
使用依赖关系解析规则
为每个已解析的依赖项执行依赖项解析规则,并提供强大的 API,用于在解析该依赖项之前操作所请求的依赖项。该功能当前提供了更改所请求依赖项的组、名称和/或版本的能力,允许在解析期间用完全不同的模块替换依赖项。
依赖关系解析规则提供了一种非常强大的方法来控制依赖关系解析过程,并且可用于实现依赖关系管理中的各种高级模式。下面概述了其中一些模式。有关更多信息和代码示例,请参阅API 文档中的ResolutionStrategy类。
实施自定义版本控制方案
在某些企业环境中,可以在 Gradle 构建中声明的模块版本列表是在外部维护和审核的。依赖关系解析规则提供了此模式的简洁实现:
-
在构建脚本中,开发人员声明与模块组和名称的依赖关系,但使用占位符版本,例如:
default。 -
该
default版本通过依赖关系解析规则解析为特定版本,该规则在已批准模块的公司目录中查找该版本。
该规则实现可以巧妙地封装在企业插件中,并在组织内的所有构建之间共享。
configurations.all {
resolutionStrategy.eachDependency {
if (requested.version == "default") {
val version = findDefaultVersionInCatalog(requested.group, requested.name)
useVersion(version.version)
because(version.because)
}
}
}
data class DefaultVersion(val version: String, val because: String)
fun findDefaultVersionInCatalog(group: String, name: String): DefaultVersion {
//some custom logic that resolves the default version into a specific version
return DefaultVersion(version = "1.0", because = "tested by QA")
}configurations.all {
resolutionStrategy.eachDependency { DependencyResolveDetails details ->
if (details.requested.version == 'default') {
def version = findDefaultVersionInCatalog(details.requested.group, details.requested.name)
details.useVersion version.version
details.because version.because
}
}
}
def findDefaultVersionInCatalog(String group, String name) {
//some custom logic that resolves the default version into a specific version
[version: "1.0", because: 'tested by QA']
}通过替换拒绝特定版本
依赖项解析规则提供了一种拒绝依赖项的特定版本并提供替换版本的机制。如果某个依赖项版本已损坏且不应使用,其中依赖项解析规则导致该版本被已知的良好版本替换,则这可能很有用。损坏模块的一个示例是声明对在任何公共存储库中都找不到的库的依赖关系的模块,但是还有许多其他原因导致不需要特定的模块版本并且首选不同的版本。
在下面的示例中,假设该版本1.2.1包含重要修复,并且应始终优先于1.2.提供的规则将强制执行此操作:任何时候1.2遇到版本时,它将被替换为1.2.1.请注意,这与上述强制版本不同,因为该模块的任何其他版本都不会受到影响。这意味着1.3如果该版本也被传递地拉取,“最新”冲突解决策略仍会选择该版本。
configurations.all {
resolutionStrategy.eachDependency {
if (requested.group == "org.software" && requested.name == "some-library" && requested.version == "1.2") {
useVersion("1.2.1")
because("fixes critical bug in 1.2")
}
}
}configurations.all {
resolutionStrategy.eachDependency { DependencyResolveDetails details ->
if (details.requested.group == 'org.software' && details.requested.name == 'some-library' && details.requested.version == '1.2') {
details.useVersion '1.2.1'
details.because 'fixes critical bug in 1.2'
}
}
}|
笔记
|
与使用丰富版本约束的拒绝指令有一个区别:如果在图中找到被拒绝的版本,丰富版本将导致构建失败,或者在使用动态依赖项时选择非拒绝版本。在这里,我们操纵请求的版本,以便在发现被拒绝的版本时选择不同的版本。换句话说,这是拒绝版本的解决方案,而丰富的版本约束允许声明意图(您不应该使用此版本)。 |
使用模块替换规则
最好用功能冲突来表达模块冲突。但是,如果没有声明此类规则,或者您正在使用不支持功能的 Gradle 版本,Gradle 会提供工具来解决这些问题。
模块替换规则允许构建声明旧库已被新库替换。新库替换旧库的一个很好的例子是google-collections->guava迁移。创建 google-collections 的团队决定将模块名称从 更改com.google.collections:google-collections为com.google.guava:guava.这是行业中的合法场景:团队需要能够更改他们维护的产品的名称,包括模块坐标。模块坐标的重命名会影响冲突解决。
为了解释对冲突解决的影响,让我们考虑google-collections->guava场景。可能会发生两个库被拉入同一个依赖关系图的情况。例如,我们的项目依赖于,但我们的guava一些依赖项引入了.这可能会导致运行时错误,例如在测试或应用程序执行期间。 Gradle 不会自动解决->冲突,因为它不被视为版本冲突。这是因为两个库的模块坐标完全不同,并且当和坐标相同时激活冲突解决,但依赖关系图中有不同的版本(有关更多信息,请参阅冲突解决部分)。解决这个问题的传统方法是:google-collectionsgoogle-collectionsguavagroupmodule
-
声明排除规则以避免拉入
google-collections图表。这可能是最流行的方法。 -
避免引入遗留库的依赖关系。
-
如果新版本不再提取旧库,请升级依赖项版本。
-
降级到
google-collections.不推荐,只是为了完整性而提及。
传统方法有效,但不够通用。例如,一个组织想要解决所有项目中的google-collections->冲突解决问题。guava可以声明某个模块已被其他模块替换。这使得组织能够将有关模块替换的信息包含在企业插件套件中,并为企业中所有 Gradle 支持的项目全面解决问题。
dependencies {
modules {
module("com.google.collections:google-collections") {
replacedBy("com.google.guava:guava", "google-collections is now part of Guava")
}
}
}dependencies {
modules {
module("com.google.collections:google-collections") {
replacedBy("com.google.guava:guava", "google-collections is now part of Guava")
}
}
}当我们声明google-collections被 替换时会发生什么guava? Gradle 可以使用此信息来解决冲突。 Gradle 会考虑每个版本guava比任何版本更新/更好的google-collections.此外,Gradle 将确保类路径/已解析文件列表中仅存在 guava jar。请注意,如果仅google-collections出现在依赖关系图中(例如 no guava),Gradle 不会急切地将其替换为guava。模块替换是 Gradle 用于解决冲突的信息。如果不存在冲突(例如,仅google-collections或仅guava在图中),则不使用替换信息。
目前无法声明给定模块被一组模块替换。但是,可以声明多个模块被单个模块替换。
使用依赖替换规则
依赖项替换规则的工作方式与依赖项解析规则类似。事实上,依赖关系解析规则的许多功能都可以通过依赖关系替换规则来实现。它们允许用指定的替换透明地替换项目和模块依赖项。与依赖项解析规则不同,依赖项替换规则允许项目和模块依赖项可以互换替换。
向配置添加依赖项替换规则会更改解析该配置的时间。 配置不是在第一次使用时解析,而是在构建任务图时解析。如果在任务执行期间进一步修改配置,或者配置依赖于在另一个任务执行期间发布的模块,这可能会产生意外的后果。
解释:
-
A
Configuration可以声明为任何任务的输入,并且该配置在解析时可以包含项目依赖项。 -
如果项目依赖项是任务的输入(通过配置),则必须将构建项目工件的任务添加到任务依赖项中。
-
为了确定作为任务输入的项目依赖项,Gradle 需要解析输入
Configuration。 -
由于一旦任务执行开始,Gradle 任务图就固定了,因此 Gradle 需要在执行任何任务之前执行此解析。
在没有依赖项替换规则的情况下,Gradle 知道外部模块依赖项永远不会传递引用项目依赖项。这样可以通过简单的图形遍历轻松确定配置的完整项目依赖关系集。有了这个功能,Gradle 就不能再做出这种假设,并且必须执行完整解析才能确定项目依赖项。
用项目依赖项替换外部模块依赖项
依赖项替换的一种用例是使用本地开发的模块版本来代替从外部存储库下载的版本。这对于测试依赖项的本地修补版本可能很有用。
声明要替换的模块时可以指定或不指定版本。
configurations.all {
resolutionStrategy.dependencySubstitution {
substitute(module("org.utils:api"))
.using(project(":api")).because("we work with the unreleased development version")
substitute(module("org.utils:util:2.5")).using(project(":util"))
}
}configurations.all {
resolutionStrategy.dependencySubstitution {
substitute module("org.utils:api") using project(":api") because "we work with the unreleased development version"
substitute module("org.utils:util:2.5") using project(":util")
}
}请注意,被替换的项目必须包含在多项目构建中(通过settings.gradle)。依赖项替换规则负责用项目依赖项替换模块依赖项并连接任何任务依赖项,但不会在构建中隐式包含项目。
用模块替换来替换项目依赖项
使用替换规则的另一种方法是用多项目构建中的模块替换项目依赖项。通过允许从存储库下载而不是构建项目依赖项的子集,这对于加速大型多项目构建的开发非常有用。
要用作替换的模块必须使用指定的版本进行声明。
configurations.all {
resolutionStrategy.dependencySubstitution {
substitute(project(":api"))
.using(module("org.utils:api:1.3")).because("we use a stable version of org.utils:api")
}
}configurations.all {
resolutionStrategy.dependencySubstitution {
substitute project(":api") using module("org.utils:api:1.3") because "we use a stable version of org.utils:api"
}
}当项目依赖项替换为模块依赖项时,该项目仍包含在整个多项目构建中。但是,为了解析依赖项,将不会执行构建替换依赖项的任务Configuration。
有条件地替换依赖项
依赖替换的一个常见用例是允许在多项目构建中更灵活地组装子项目。这对于开发外部依赖项的本地修补版本或在大型多项目构建中构建模块子集非常有用。
以下示例使用依赖项替换规则将任何模块依赖项替换为 group org.example,但前提是可以找到与依赖项名称匹配的本地项目。
configurations.all {
resolutionStrategy.dependencySubstitution.all {
requested.let {
if (it is ModuleComponentSelector && it.group == "org.example") {
val targetProject = findProject(":${it.module}")
if (targetProject != null) {
useTarget(targetProject)
}
}
}
}
}configurations.all {
resolutionStrategy.dependencySubstitution.all { DependencySubstitution dependency ->
if (dependency.requested instanceof ModuleComponentSelector && dependency.requested.group == "org.example") {
def targetProject = findProject(":${dependency.requested.module}")
if (targetProject != null) {
dependency.useTarget targetProject
}
}
}
}请注意,被替换的项目必须包含在多项目构建中(通过settings.gradle)。依赖项替换规则负责用项目依赖项替换模块依赖项,但不会在构建中隐式包含项目。
用另一个变体替换依赖项
Gradle 的依赖项管理引擎具有变体感知能力,这意味着对于单个组件,引擎可以选择不同的工件和传递依赖项。
选择什么是由消费者配置的属性和生产者端找到的变体的属性决定的。但是,某些特定的依赖项可能会覆盖配置本身的属性。使用Java 平台插件时通常会出现这种情况:该插件构建一种特殊类型的组件,称为“平台”,可以通过将组件类别属性设置为 来解决platform,这与针对库的典型依赖项相反。
因此,您可能会遇到想要用常规依赖项替换平台依赖项的情况,或者反之亦然。
用属性替换依赖项
假设您想要用常规依赖项替换平台依赖项。这意味着您正在使用的库声明如下:
dependencies {
// This is a platform dependency but you want the library
implementation(platform("com.google.guava:guava:28.2-jre"))
}dependencies {
// This is a platform dependency but you want the library
implementation platform('com.google.guava:guava:28.2-jre')
}该关键字实际上是具有attribute 的依赖关系platform的简写符号。如果我们想用常规依赖项替换此依赖项,那么我们需要精确选择具有该属性的依赖项。platform
这可以通过使用替换规则来完成:
configurations.all {
resolutionStrategy.dependencySubstitution {
substitute(platform(module("com.google.guava:guava:28.2-jre")))
.using(module("com.google.guava:guava:28.2-jre"))
}
}configurations.all {
resolutionStrategy.dependencySubstitution {
substitute(platform(module('com.google.guava:guava:28.2-jre'))).
using module('com.google.guava:guava:28.2-jre')
}
}没有关键字的相同规则platform会尝试用常规依赖项替换常规依赖项,这不是您想要的,因此了解替换规则适用于依赖项规范非常重要:它将请求的依赖项 ( substitute XXX) 与替代项 ( using YYY)。
您可以在请求的依赖项或替代项上拥有属性,并且替代项不限于platform:您实际上可以使用表示法指定整个依赖项属性集variant。以下规则与上述规则严格等效:
configurations.all {
resolutionStrategy.dependencySubstitution {
substitute(variant(module("com.google.guava:guava:28.2-jre")) {
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.REGULAR_PLATFORM))
}
}).using(module("com.google.guava:guava:28.2-jre"))
}
}configurations.all {
resolutionStrategy.dependencySubstitution {
substitute variant(module('com.google.guava:guava:28.2-jre')) {
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.REGULAR_PLATFORM))
}
} using module('com.google.guava:guava:28.2-jre')
}
}请参阅Substitution DSL API 文档,获取变体替换 API 的完整参考。
|
警告
|
在复合构建中,不应用必须精确匹配请求的依赖属性的规则:使用复合时,Gradle 将自动匹配请求的属性。换句话说,如果您包含另一个构建,那么您将用包含的构建中的等效变体替换被替换模块的 所有变体。 |
用具有功能的依赖项替换依赖项
与属性替换类似,Gradle 允许您将具有或不具有功能的依赖项替换为另一个具有或不具有功能的依赖项。
例如,假设您需要用其测试装置替换常规依赖项。您可以通过使用以下依赖项替换规则来实现此目的:
configurations.testCompileClasspath {
resolutionStrategy.dependencySubstitution {
substitute(module("com.acme:lib:1.0")).using(variant(module("com.acme:lib:1.0")) {
capabilities {
requireCapability("com.acme:lib-test-fixtures")
}
})
}
}configurations.testCompileClasspath {
resolutionStrategy.dependencySubstitution {
substitute(module('com.acme:lib:1.0'))
.using variant(module('com.acme:lib:1.0')) {
capabilities {
requireCapability('com.acme:lib-test-fixtures')
}
}
}
}在所请求的依赖项的替换规则中声明的功能构成依赖项匹配规范的一部分,因此不需要该功能的依赖项将不会被匹配。
请参阅Substitution DSL API 文档,获取变体替换 API 的完整参考。
用分类器或工件替换依赖项
虽然外部模块通常通过其组/工件/版本坐标来寻址,但此类模块通常会与您可能想要用来代替主工件的其他工件一起发布。这通常是分类工件的情况,但您可能还需要选择具有不同文件类型或扩展名的工件。 Gradle 不鼓励在依赖项中使用分类器,并且更喜欢将此类工件建模为模块的附加变体。使用变体而不是分类工件有很多优点,包括但不仅限于这些工件的一组不同的依赖关系。
但是,为了帮助桥接这两个模型,Gradle 提供了更改或删除替换规则中的分类器的方法。
dependencies {
implementation("com.google.guava:guava:28.2-jre")
implementation("co.paralleluniverse:quasar-core:0.8.0")
implementation(project(":lib"))
}dependencies {
implementation 'com.google.guava:guava:28.2-jre'
implementation 'co.paralleluniverse:quasar-core:0.8.0'
implementation project(':lib')
}在上面的示例中,第一级依赖quasar使我们认为 Gradle 会解析,quasar-core-0.8.0.jar但事实并非如此:构建将失败并显示以下消息:
Execution failed for task ':resolve'.
> Could not resolve all files for configuration ':runtimeClasspath'.
> Could not find quasar-core-0.8.0-jdk8.jar (co.paralleluniverse:quasar-core:0.8.0).
Searched in the following locations:
https://repo1.maven.org/maven2/co/paralleluniverse/quasar-core/0.8.0/quasar-core-0.8.0-jdk8.jar这是因为存在对另一个项目 的依赖,lib该项目本身又依赖于 的不同版本quasar-core:
dependencies {
implementation("co.paralleluniverse:quasar-core:0.7.10:jdk8")
}dependencies {
implementation "co.paralleluniverse:quasar-core:0.7.10:jdk8"
}发生的情况是 Gradle 将在quasar-core0.8.0 和quasar-core0.7.10 之间执行冲突解决。因为0.8.0更高,所以我们选择这个版本,但是其中的依赖lib有一个分类器,jdk8而这个分类器在0.8.0版本中不再存在。
要解决此问题,您可以要求 Gradle在没有分类器的情况下解决这两个依赖项:
configurations.all {
resolutionStrategy.dependencySubstitution {
substitute(module("co.paralleluniverse:quasar-core"))
.using(module("co.paralleluniverse:quasar-core:0.8.0"))
.withoutClassifier()
}
}configurations.all {
resolutionStrategy.dependencySubstitution {
substitute module('co.paralleluniverse:quasar-core') using module('co.paralleluniverse:quasar-core:0.8.0') withoutClassifier()
}
}该规则有效地quasar-core用不带分类器的依赖项替换了对图中找到的任何依赖项。
或者,可以选择具有特定分类器的依赖项,或者对于更特定的用例,用非常特定的工件(类型、扩展和分类器)替代。
更多信息请参考以下API文档:
禁用传递解析
默认情况下,Gradle 会解析依赖项元数据指定的所有传递依赖项。有时,这种行为可能并不理想,例如,如果元数据不正确或定义了大的传递依赖关系图。您可以通过将ModuleDependency.setTransitive(boolean)设置为 来告诉 Gradle 禁用依赖项的传递依赖项管理false。因此,只有主要工件将被解析为声明的依赖项。
dependencies {
implementation("com.google.guava:guava:23.0") {
isTransitive = false
}
}dependencies {
implementation('com.google.guava:guava:23.0') {
transitive = false
}
}|
笔记
|
禁用传递依赖项解析可能需要您在构建脚本中声明必要的运行时依赖项,否则这些依赖项将被自动解析。不这样做可能会导致运行时类路径问题。 |
项目可以决定完全禁用传递依赖解析。您要么不想依赖发布到所使用的存储库的元数据,要么希望完全控制图表中的依赖关系。有关更多信息,请参阅Configuration.setTransitive(boolean)。
configurations.all {
isTransitive = false
}
dependencies {
implementation("com.google.guava:guava:23.0")
}configurations.all {
transitive = false
}
dependencies {
implementation 'com.google.guava:guava:23.0'
}在解决之前更改配置依赖项
有时,插件可能希望在解析配置之前修改配置的依赖关系。该withDependencies方法允许以编程方式添加、删除或修改依赖项。
configurations {
create("implementation") {
withDependencies {
val dep = this.find { it.name == "to-modify" } as ExternalModuleDependency
dep.version {
strictly("1.2")
}
}
}
}configurations {
implementation {
withDependencies { DependencySet dependencies ->
ExternalModuleDependency dep = dependencies.find { it.name == 'to-modify' } as ExternalModuleDependency
dep.version {
strictly "1.2"
}
}
}
}设置默认配置依赖项
如果没有为配置显式设置依赖项,则可以使用要使用的默认依赖项来配置配置。此功能的主要用例是开发使用用户可能覆盖的版本化工具的插件。通过指定默认依赖项,仅当用户未指定要使用的特定版本时,插件才能使用该工具的默认版本。
configurations {
create("pluginTool") {
defaultDependencies {
add(project.dependencies.create("org.gradle:my-util:1.0"))
}
}
}configurations {
pluginTool {
defaultDependencies { dependencies ->
dependencies.add(project.dependencies.create("org.gradle:my-util:1.0"))
}
}
}从配置中完全排除依赖项
与排除依赖项声明中的依赖项类似,您可以使用Configuration.exclude(java.util.Map)完全排除特定配置的传递依赖项。这将自动排除配置上声明的所有依赖项的传递依赖项。
configurations {
"implementation" {
exclude(group = "commons-collections", module = "commons-collections")
}
}
dependencies {
implementation("commons-beanutils:commons-beanutils:1.9.4")
implementation("com.opencsv:opencsv:4.6")
}configurations {
implementation {
exclude group: 'commons-collections', module: 'commons-collections'
}
}
dependencies {
implementation 'commons-beanutils:commons-beanutils:1.9.4'
implementation 'com.opencsv:opencsv:4.6'
}将依赖项与存储库相匹配
Gradle 公开一个 API 来声明存储库可能包含或不包含的内容。此功能提供了对哪个存储库服务哪些工件的细粒度控制,这可以是控制依赖项来源的一种方法。
请参阅存储库内容过滤部分以了解有关此功能的更多信息。
启用ivy动态解析模式
Gradle 的 Ivy 存储库实现支持相当于 Ivy 的动态解析模式。通常,Gradle 将为文件rev中包含的每个依赖项定义使用该属性ivy.xml。在动态解析模式下,Gradle 将优先选择该revConstraint属性而rev不是给定依赖项定义的属性。如果该revConstraint属性不存在,rev则使用该属性。
要启用动态解析模式,您需要在存储库定义上设置适当的选项。下面显示了几个示例。请注意,动态解析模式仅适用于 Gradle 的 Ivy 存储库。它不适用于 Maven 存储库或自定义 IvyDependencyResolver实现。
// Can enable dynamic resolve mode when you define the repository
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
resolve.isDynamicMode = true
}
}
// Can use a rule instead to enable (or disable) dynamic resolve mode for all repositories
repositories.withType<IvyArtifactRepository> {
resolve.isDynamicMode = true
}// Can enable dynamic resolve mode when you define the repository
repositories {
ivy {
url "http://repo.mycompany.com/repo"
resolve.dynamicMode = true
}
}
// Can use a rule instead to enable (or disable) dynamic resolve mode for all repositories
repositories.withType(IvyArtifactRepository) {
resolve.dynamicMode = true
}防止意外的依赖升级
在某些情况下,您可能希望完全控制依赖关系图。特别是,您可能需要确保:
-
构建脚本中声明的版本实际上对应于正在解析的版本
-
或者确保依赖性解析随着时间的推移是可重现的
Gradle 提供了通过配置解析策略来执行此操作的方法。
版本冲突失败
每当 Gradle 在依赖关系图中的两个不同版本中找到相同的模块时,就会出现版本冲突。默认情况下,Gradle 执行乐观升级,这意味着如果在图中找到版本1.1和,我们将解析为最高版本。但是,由于传递依赖,很容易忽略某些依赖项的升级。在上面的示例中,如果构建脚本中使用了一个版本并且传递了一个版本,那么您可以在不实际注意到的情况下使用。1.31.31.11.31.3
为了确保您了解此类升级,Gradle 提供了一种可以在配置的解决策略中激活的模式。想象一下以下依赖关系声明:
dependencies {
implementation("org.apache.commons:commons-lang3:3.0")
// the following dependency brings lang3 3.8.1 transitively
implementation("com.opencsv:opencsv:4.6")
}dependencies {
implementation 'org.apache.commons:commons-lang3:3.0'
// the following dependency brings lang3 3.8.1 transitively
implementation 'com.opencsv:opencsv:4.6'
}然后默认情况下 Gradle 会升级,但构建commons-lang3可能会失败:
configurations.all {
resolutionStrategy {
failOnVersionConflict()
}
}configurations.all {
resolutionStrategy {
failOnVersionConflict()
}
}确保分辨率可重现
在某些情况下,依赖关系解析可能会随着时间的推移而不稳定。也就是说,如果您在日期 D 构建,则在日期 D+x 构建可能会给出不同的解析结果。
在以下情况下可以这样做:
-
使用动态依赖版本(版本范围、、、
latest.release...1.+) -
或使用更改版本(快照、内容更改的固定版本……)
处理动态版本的推荐方法是使用依赖锁定。但是,可以完全阻止使用动态版本,这是一种替代策略:
configurations.all {
resolutionStrategy {
failOnDynamicVersions()
}
}configurations.all {
resolutionStrategy {
failOnDynamicVersions()
}
}同样,可以通过激活此标志来防止使用更改版本:
configurations.all {
resolutionStrategy {
failOnChangingVersions()
}
}configurations.all {
resolutionStrategy {
failOnChangingVersions()
}
}在发布时更改版本失败是一个很好的做法。
最终,可以使用单个调用将动态版本失败和版本更改结合起来:
configurations.all {
resolutionStrategy {
failOnNonReproducibleResolution()
}
}configurations.all {
resolutionStrategy {
failOnNonReproducibleResolution()
}
}获得一致的依赖解析结果
|
笔记
|
依赖解析一致性是一个正在孵化的功能 |
一个常见的误解是应用程序只有一个依赖图。事实上,Gradle 在构建过程中会解析许多不同的依赖关系图,即使在单个项目中也是如此。例如,编译时使用的依赖关系图与运行时使用的依赖关系图不同。一般来说,运行时的依赖关系图是编译依赖关系的超集(该规则也有例外,例如,某些依赖关系在运行时二进制文件中重新打包的情况)。
Gradle 独立解析这些依赖图。这意味着,例如在 Java 生态系统中,“编译类路径”的解析不会影响“运行时类路径”的解析。同样,测试依赖项最终可能会影响生产依赖项的版本,从而在执行测试时导致一些令人惊讶的结果。
通过启用依赖性解析一致性可以减轻这些令人惊讶的行为。
启用项目本地依赖解析一致性
例如,假设您的 Java 库依赖于以下库:
dependencies {
implementation("org.codehaus.groovy:groovy:3.0.1")
runtimeOnly("io.vertx:vertx-lang-groovy:3.9.4")
}dependencies {
implementation 'org.codehaus.groovy:groovy:3.0.1'
runtimeOnly 'io.vertx:vertx-lang-groovy:3.9.4'
}然后解析compileClasspath配置会将groovy库解析为预期的版本3.0.1。但是,解析runtimeClasspath配置将返回groovy 3.0.2.
原因是 的传递依赖vertx(即依赖runtimeOnly)带来了更高版本的groovy.一般来说,这不是问题,但这也意味着您将在运行时使用的 Groovy 库的版本将与您用于编译的版本不同。
为了避免这种情况,Gradle提供了一个API来解释配置应该一致地解析。
声明配置之间的分辨率一致性
在上面的示例中,我们可以通过声明“运行时类路径”应与“编译类路径”一致来声明我们希望在运行时获得与编译时相同版本的公共依赖项:
configurations {
runtimeClasspath.get().shouldResolveConsistentlyWith(compileClasspath.get())
}configurations {
runtimeClasspath.shouldResolveConsistentlyWith(compileClasspath)
}因此, 和 都runtimeClasspath将compileClasspath解析 Groovy 3.0.1。
这种关系是有向的,这意味着如果runtimeClasspath必须解析配置,Gradle 将首先解析compileClasspath,然后将解析结果作为严格约束“注入”到 中runtimeClasspath。
如果由于某种原因,两个图的版本无法“对齐”,则解决方案将因号召性用语而失败。
在 Java 生态系统中声明一致的解决方案
runtimeClasspath上面的例子compileClasspath在 Java 生态系统中很常见。然而,仅声明这两种配置之间的一致性通常是不够的。例如,您很可能希望测试运行时类路径与运行时类路径一致
。
为了使这更容易,Gradle 提供了一种使用扩展为 Java 生态系统配置一致分辨率的方法java:
java {
consistentResolution {
useCompileClasspathVersions()
}
}java {
consistentResolution {
useCompileClasspathVersions()
}
}请参阅Java 插件扩展文档以获取更多配置选项。
生成和使用库的变体
声明库的功能
能力作为第一层概念
组件提供了许多功能,这些功能通常与用于提供这些功能的软件架构正交。例如,库可能在单个工件中包含多个功能。然而,这样的库将在单个 GAV(组、工件和版本)坐标上发布。这意味着,在单个坐标处,组件的不同“特征”可能共存。
使用 Gradle,显式声明组件提供的功能变得很有趣。为此,Gradle 提供了能力的概念。
功能通常是通过组合不同的功能来构建的。
在理想的情况下,组件不应声明对显式 GAV 的依赖关系,而应以功能的形式表达其需求:
-
“给我一个提供日志记录的组件”
-
“给我一个脚本引擎”
-
“给我一个支持 Groovy 的脚本引擎”
通过对功能进行建模,依赖关系管理引擎可以变得更加智能,并在依赖关系图中出现不兼容的功能时告诉您,或者在图中的不同模块提供相同功能时要求您进行选择。
声明外部模块的功能
值得注意的是,Gradle 支持为您构建的组件声明功能,也支持为外部组件声明功能(如果它们没有声明)。
例如,如果您的构建文件包含以下依赖项:
dependencies {
// This dependency will bring log4:log4j transitively
implementation("org.apache.zookeeper:zookeeper:3.4.9")
// We use log4j over slf4j
implementation("org.slf4j:log4j-over-slf4j:1.7.10")
}dependencies {
// This dependency will bring log4:log4j transitively
implementation 'org.apache.zookeeper:zookeeper:3.4.9'
// We use log4j over slf4j
implementation 'org.slf4j:log4j-over-slf4j:1.7.10'
}事实上,很难弄清楚您最终会在类路径上有两个日志框架。其实,zookeeper就会带进来log4j,我们要用的地方就是哪里log4j-over-slf4j。我们可以通过添加一条规则来预先检测冲突,该规则将声明两个日志框架提供相同的功能:
dependencies {
// Activate the "LoggingCapability" rule
components.all(LoggingCapability::class.java)
}
class LoggingCapability : ComponentMetadataRule {
val loggingModules = setOf("log4j", "log4j-over-slf4j")
override
fun execute(context: ComponentMetadataContext) = context.details.run {
if (loggingModules.contains(id.name)) {
allVariants {
withCapabilities {
// Declare that both log4j and log4j-over-slf4j provide the same capability
addCapability("log4j", "log4j", id.version)
}
}
}
}
}dependencies {
// Activate the "LoggingCapability" rule
components.all(LoggingCapability)
}
@CompileStatic
class LoggingCapability implements ComponentMetadataRule {
final static Set<String> LOGGING_MODULES = ["log4j", "log4j-over-slf4j"] as Set<String>
void execute(ComponentMetadataContext context) {
context.details.with {
if (LOGGING_MODULES.contains(id.name)) {
allVariants {
it.withCapabilities {
// Declare that both log4j and log4j-over-slf4j provide the same capability
it.addCapability("log4j", "log4j", id.version)
}
}
}
}
}
}通过添加此规则,我们将确保 Gradle能够检测到冲突并正确失败:
> Could not resolve all files for configuration ':compileClasspath'.
> Could not resolve org.slf4j:log4j-over-slf4j:1.7.10.
Required by:
project :
> Module 'org.slf4j:log4j-over-slf4j' has been rejected:
Cannot select module with conflict on capability 'log4j:log4j:1.7.10' also provided by [log4j:log4j:1.2.16(compile)]
> Could not resolve log4j:log4j:1.2.16.
Required by:
project : > org.apache.zookeeper:zookeeper:3.4.9
> Module 'log4j:log4j' has been rejected:
Cannot select module with conflict on capability 'log4j:log4j:1.2.16' also provided by [org.slf4j:log4j-over-slf4j:1.7.10(compile)]
请参阅文档的功能部分以了解如何解决功能冲突。
声明本地组件的附加功能
所有组件都具有与组件相同的 GAV 坐标相对应的隐式功能。然而,也可以为组件声明附加的显式功能。当在不同 GAV 坐标发布的库是同一 API 的替代实现时,这很方便:
configurations {
apiElements {
outgoing {
capability("com.acme:my-library:1.0")
capability("com.other:module:1.1")
}
}
runtimeElements {
outgoing {
capability("com.acme:my-library:1.0")
capability("com.other:module:1.1")
}
}
}configurations {
apiElements {
outgoing {
capability("com.acme:my-library:1.0")
capability("com.other:module:1.1")
}
}
runtimeElements {
outgoing {
capability("com.acme:my-library:1.0")
capability("com.other:module:1.1")
}
}
}功能必须附加到传出配置,这是组件的消耗性配置。
此示例显示我们声明了两个功能:
-
com.acme:my-library:1.0,对应于库的隐式能力 -
com.other:module:1.1,对应于该库的另一个功能
值得注意的是,我们需要做 1. 因为一旦开始声明显式功能,那么所有功能都需要声明,包括隐式功能。
第二功能可以特定于该库,或者它可以对应于外部组件提供的功能。在这种情况下,如果com.other:module出现在同一个依赖图中,构建将失败,消费者将必须选择要使用的模块。
功能发布到 Gradle 模块元数据。然而,它们在 POM 或 Ivy 元数据文件中没有等效项。因此,当发布此类组件时,Gradle 会警告您此功能仅适用于 Gradle 使用者:
Maven publication 'maven' contains dependencies that cannot be represented in a published pom file. - Declares capability com.acme:my-library:1.0 - Declares capability com.other:module:1.1
建模库功能
Gradle 支持功能的概念:通常情况下,单个库可以分为多个相关但不同的库,其中每个功能都可以与主库一起使用。
功能允许组件公开多个相关库,每个库都可以声明自己的依赖项。这些库作为变体公开,类似于主库公开其 API 和运行时变体的方式。
这允许多种不同的场景(列表并不详尽):
-
Maven 可选依赖项的(更好)替代品
-
构建一个主库,支持运行时功能的不同互斥实现;用户必须为每个此类功能选择一个且仅一个实现
-
主库的构建支持可选的运行时功能,每个功能都需要一组不同的依赖项
-
主库附带测试装置等补充功能
-
主库附带一个主要工件,启用附加功能需要额外的工件
通过功能选择功能
声明对组件的依赖关系通常是通过提供一组坐标(组、工件、版本也称为 GAV 坐标)来完成的。这使得引擎能够确定我们正在寻找的组件,但是这样的组件可能会提供不同的变体。通常根据用途选择变体。例如,我们可能会选择不同的变体来针对组件进行编译(在这种情况下我们需要组件的 API)或在执行代码时(在这种情况下我们需要组件的运行时)。组件的所有变体都提供了许多功能,这些功能都使用 GAV 坐标进行类似的表示。
能力由 GAV 坐标表示,但您必须将其视为功能描述:
-
“我提供 SLF4J 绑定”
-
“我为 MySQL 提供运行时支持”
-
“我提供 Groovy 运行时”
一般来说,有两个组件在图中提供相同的东西是一个问题(它们是冲突的)。
这是一个重要的概念,因为:
-
默认情况下,变体提供与其组件的 GAV 坐标相对应的功能
-
依赖图中没有两个变体可以提供相同的功能
-
可以选择单个组件的多个变体,只要它们提供不同的功能
典型的组件仅提供具有默认功能的变体。例如,Java 库公开了两个提供相同功能的变体(API 和运行时) 。因此,在依赖关系图中同时包含单个组件的API和运行时是错误的。
但是,假设您需要组件的运行时和测试装置运行时。然后,只要库的运行时和测试装置运行时变体声明不同的功能,就允许这样做。
如果我们这样做,消费者就必须声明两个依赖项:
-
其一是“主要”功能,即图书馆
-
关于“测试夹具”功能的一项,要求其能力
|
笔记
|
虽然解析引擎支持独立于生态系统的多变体组件,但目前只能使用 Java 插件使用 这些功能。 |
注册功能
可以通过应用java-library插件来声明功能。以下代码说明了如何声明名为 的功能mongodbSupport:
sourceSets {
create("mongodbSupport") {
java {
srcDir("src/mongodb/java")
}
}
}
java {
registerFeature("mongodbSupport") {
usingSourceSet(sourceSets["mongodbSupport"])
}
}sourceSets {
mongodbSupport {
java {
srcDir 'src/mongodb/java'
}
}
}
java {
registerFeature('mongodbSupport') {
usingSourceSet(sourceSets.mongodbSupport)
}
}Gradle 会自动为您设置许多内容,其方式与Java 库插件设置配置的方式非常相似。
依赖范围配置的创建方式与主要功能相同:
-
配置
mongodbSupportApi,用于声明此功能的API 依赖项 -
配置
mongodbSupportImplementation,用于声明此功能的实现依赖项 -
配置
mongodbSupportRuntimeOnly,用于声明此功能的仅运行时依赖项 -
配置
mongodbSupportCompileOnly,用于声明此功能的仅编译依赖项 -
配置
mongodbSupportCompileOnlyApi,用于声明此功能的仅编译 API 依赖项
此外,消耗品配置的创建方式与主要功能相同:
-
配置
mongodbSupportApiElements,供消费者用来获取该功能的工件和 API 依赖项 -
配置
mongodbSupportRuntimeElements,消费者使用它来获取该功能的工件和运行时依赖项
功能应该有一个同名的源集。 Gradle 将创建一个Jar任务来捆绑从功能源集构建的类,使用与功能的短横线命名相对应的分类器。
|
警告
|
注册功能时 请勿使用主源集。此行为将在 Gradle 的未来版本中弃用。 |
大多数用户只需要关心依赖范围配置,来声明该功能的具体依赖:
dependencies {
"mongodbSupportImplementation"("org.mongodb:mongodb-driver-sync:3.9.1")
}dependencies {
mongodbSupportImplementation 'org.mongodb:mongodb-driver-sync:3.9.1'
}按照约定,Gradle 将功能名称映射到一个功能,该功能的组和版本分别与主组件的组和版本相同,但其名称是主组件名称后跟 ,后跟-短横线命名的功能名称。
例如,如果组件的组是org.gradle.demo,其名称是provider,其版本是1.0,并且该功能的名称是mongodbSupport,则该功能的变体将具有该org.gradle.demo:provider-mongodb-support:1.0功能。
如果您自己选择功能名称或向变体添加更多功能,建议遵循相同的约定。
发布功能
根据元数据文件格式,发布功能可能会有损失:
-
使用Gradle 模块元数据,所有内容都会发布,消费者将充分受益于功能
-
使用 POM 元数据 (Maven),将功能发布为可选依赖项,并使用不同的分类器发布功能工件
-
使用ivy元数据,功能作为额外配置发布,这些配置不会通过
default配置进行扩展
maven-publish仅使用和插件支持发布功能ivy-publish。 Java 库插件将负责为您注册其他变体,因此不需要其他配置,只需常规发布:
plugins {
`java-library`
`maven-publish`
}
// ...
publishing {
publications {
create("myLibrary", MavenPublication::class.java) {
from(components["java"])
}
}
}plugins {
id 'java-library'
id 'maven-publish'
}
// ...
publishing {
publications {
myLibrary(MavenPublication) {
from components.java
}
}
}添加 javadoc 和源 JAR
与主要的 Javadoc 和源 JAR类似,您可以配置添加的功能,以便它为 Javadoc 和源生成 JAR。
java {
registerFeature("mongodbSupport") {
usingSourceSet(sourceSets["mongodbSupport"])
withJavadocJar()
withSourcesJar()
}
}java {
registerFeature('mongodbSupport') {
usingSourceSet(sourceSets.mongodbSupport)
withJavadocJar()
withSourcesJar()
}
}对功能的依赖
如前所述,功能在发布时可能会有所损失。因此,消费者只能在以下情况下依赖某个功能:
-
具有项目依赖性(在多项目构建中)
-
Gradle 模块元数据可用,即发布者必须已发布它
-
在 Ivy 世界中,通过声明对与功能匹配的配置的依赖
消费者可以通过声明所需的功能来指定它需要生产者的特定功能。例如,如果生产者声明“MySQL 支持”功能,如下所示:
group = "org.gradle.demo"
sourceSets {
create("mysqlSupport") {
java {
srcDir("src/mysql/java")
}
}
}
java {
registerFeature("mysqlSupport") {
usingSourceSet(sourceSets["mysqlSupport"])
}
}
dependencies {
"mysqlSupportImplementation"("mysql:mysql-connector-java:8.0.14")
}group = 'org.gradle.demo'
sourceSets {
mysqlSupport {
java {
srcDir 'src/mysql/java'
}
}
}
java {
registerFeature('mysqlSupport') {
usingSourceSet(sourceSets.mysqlSupport)
}
}
dependencies {
mysqlSupportImplementation 'mysql:mysql-connector-java:8.0.14'
}然后,消费者可以通过执行以下操作来声明对 MySQL 支持功能的依赖:
dependencies {
// This project requires the main producer component
implementation(project(":producer"))
// But we also want to use its MySQL support
runtimeOnly(project(":producer")) {
capabilities {
requireCapability("org.gradle.demo:producer-mysql-support")
}
}
}dependencies {
// This project requires the main producer component
implementation(project(":producer"))
// But we also want to use its MySQL support
runtimeOnly(project(":producer")) {
capabilities {
requireCapability("org.gradle.demo:producer-mysql-support")
}
}
}这将自动带来mysql-connector-java对运行时类路径的依赖。如果存在多个依赖项,则所有依赖项都会被引入,这意味着可以使用一项功能将对某一功能做出贡献的依赖项分组在一起。
同样,如果使用Gradle Module Metadata发布了具有功能的外部库,则可以依赖该库提供的功能:
dependencies {
// This project requires the main producer component
implementation("org.gradle.demo:producer:1.0")
// But we also want to use its MongoDB support
runtimeOnly("org.gradle.demo:producer:1.0") {
capabilities {
requireCapability("org.gradle.demo:producer-mongodb-support")
}
}
}dependencies {
// This project requires the main producer component
implementation('org.gradle.demo:producer:1.0')
// But we also want to use its MongoDB support
runtimeOnly('org.gradle.demo:producer:1.0') {
capabilities {
requireCapability("org.gradle.demo:producer-mongodb-support")
}
}
}处理互斥变体
使用功能作为处理功能的方式的主要优点是您可以精确地处理变体的兼容性。规则很简单:
依赖图中没有两个变体可以提供相同的功能
我们可以利用这一点来确保每当用户错误配置依赖项时 Gradle 都会失败。考虑这样一种情况,您的库支持 MySQL、Postgres 和 MongoDB,但只允许同时选择其中之一。我们可以通过确保每个特征也提供相同的功能来模拟这种限制,从而使这些特征不可能在同一个图中一起使用。
java {
registerFeature("mysqlSupport") {
usingSourceSet(sourceSets["mysqlSupport"])
capability("org.gradle.demo", "producer-db-support", "1.0")
capability("org.gradle.demo", "producer-mysql-support", "1.0")
}
registerFeature("postgresSupport") {
usingSourceSet(sourceSets["postgresSupport"])
capability("org.gradle.demo", "producer-db-support", "1.0")
capability("org.gradle.demo", "producer-postgres-support", "1.0")
}
registerFeature("mongoSupport") {
usingSourceSet(sourceSets["mongoSupport"])
capability("org.gradle.demo", "producer-db-support", "1.0")
capability("org.gradle.demo", "producer-mongo-support", "1.0")
}
}
dependencies {
"mysqlSupportImplementation"("mysql:mysql-connector-java:8.0.14")
"postgresSupportImplementation"("org.postgresql:postgresql:42.2.5")
"mongoSupportImplementation"("org.mongodb:mongodb-driver-sync:3.9.1")
}java {
registerFeature('mysqlSupport') {
usingSourceSet(sourceSets.mysqlSupport)
capability('org.gradle.demo', 'producer-db-support', '1.0')
capability('org.gradle.demo', 'producer-mysql-support', '1.0')
}
registerFeature('postgresSupport') {
usingSourceSet(sourceSets.postgresSupport)
capability('org.gradle.demo', 'producer-db-support', '1.0')
capability('org.gradle.demo', 'producer-postgres-support', '1.0')
}
registerFeature('mongoSupport') {
usingSourceSet(sourceSets.mongoSupport)
capability('org.gradle.demo', 'producer-db-support', '1.0')
capability('org.gradle.demo', 'producer-mongo-support', '1.0')
}
}
dependencies {
mysqlSupportImplementation 'mysql:mysql-connector-java:8.0.14'
postgresSupportImplementation 'org.postgresql:postgresql:42.2.5'
mongoSupportImplementation 'org.mongodb:mongodb-driver-sync:3.9.1'
}在这里,生产者声明了 3 个功能,每个功能对应一个数据库运行时支持:
-
mysql-support提供db-support和mysql-support功能 -
postgres-support提供db-support和postgres-support功能 -
mongo-support提供db-support和mongo-support功能
然后,如果消费者尝试同时获取postgres-support和mysql-support功能(这也可以传递):
dependencies {
// This project requires the main producer component
implementation(project(":producer"))
// Let's try to ask for both MySQL and Postgres support
runtimeOnly(project(":producer")) {
capabilities {
requireCapability("org.gradle.demo:producer-mysql-support")
}
}
runtimeOnly(project(":producer")) {
capabilities {
requireCapability("org.gradle.demo:producer-postgres-support")
}
}
}dependencies {
implementation(project(":producer"))
// Let's try to ask for both MySQL and Postgres support
runtimeOnly(project(":producer")) {
capabilities {
requireCapability("org.gradle.demo:producer-mysql-support")
}
}
runtimeOnly(project(":producer")) {
capabilities {
requireCapability("org.gradle.demo:producer-postgres-support")
}
}
}依赖关系解析将失败并出现以下错误:
Cannot choose between org.gradle.demo:producer:1.0 variant mysqlSupportRuntimeElements and org.gradle.demo:producer:1.0 variant postgresSupportRuntimeElements because they provide the same capability: org.gradle.demo:producer-db-support:1.0
了解变体选择
在其他依赖项管理引擎(如 Apache Maven™)中,依赖项和工件绑定到在特定 GAV(组工件版本)坐标处发布的组件。无论该组件使用哪个工件,该组件的依赖项集始终相同。
如果组件确实有多个工件,则每个工件都由一个繁琐的分类器来识别。没有与分类器相关的通用语义,这使得很难保证全局一致的依赖图。这意味着没有什么可以阻止单个组件(例如,分类器)的多个工件jdk7出现jdk8在类路径中并导致难以诊断的问题。
Maven 组件模型

Gradle 组件模型

Gradle 的依赖管理引擎是变体感知的。
除了组件之外,Gradle 还有组件变体的概念。变体对应于组件的不同使用方式,例如 Java 编译或本机链接或文档。工件附加到一个变体,每个变体可以有一组不同的依赖项。
当有多个变体时,Gradle 如何知道选择哪种变体?变体通过使用属性进行匹配,属性为变体提供语义并帮助引擎产生一致的解析结果。
Gradle 区分两种组件:
-
从源构建的本地组件(如项目)
-
外部组件,发布到存储库
对于本地组件,变体被映射到消耗品配置。对于外部组件,变体由已发布的 Gradle 模块元数据定义或源自 Ivy/Maven 元数据。
由于历史原因,变体和配置有时在文档、DSL 或 API 中可以互换使用。
所有组件都提供变体,并且这些变体可由消耗品配置支持。并非所有配置都是变体,因为它们可用于声明或解决依赖关系。
变体属性
属性是类型安全的键值对,由消费者(对于可解析配置)和生产者(对于每个变体)定义。
消费者可以定义任意数量的属性。每个属性都有助于缩小可选择的可能变体范围。属性值不需要完全匹配。
该变体还可以定义任意数量的属性。属性应描述变体的用途。例如,Gradle 使用名为 的属性org.gradle.usage来描述使用者如何使用组件(用于编译、运行时执行等)。变体具有的属性多于消费者选择它所需的属性的情况并不罕见。
变体属性匹配
变体名称主要用于调试目的和错误消息。该名称不参与变体匹配——只有它的属性参与。
组件可以定义的变体数量没有限制。通常,一个组件至少有一个实现变体,但它也可以公开测试装置、文档或源代码。组件还可以为相同用途的不同消费者公开不同的变体。例如,在编译时,Linux、Windows 和 macOS 的组件可能具有不同的标头。
Gradle通过将消费者请求的属性与生产者定义的属性进行匹配来执行变体感知选择。选择算法将在另一节中详细介绍。
|
笔记
|
此规则有两个例外,可以绕过变体感知解决方案:
|
一个简单的例子
让我们考虑一个消费者尝试使用库进行编译的示例。
首先,消费者需要解释它将如何使用依赖解析的结果。这是通过在消费者的可解析配置上设置属性来完成的。
消费者想要解析匹配的变体:org.gradle.usage=java-api
其次,生产者需要公开组件的不同变体。
生产者组件公开了 2 个变体:
-
它的 API(名为
apiElements)带有属性org.gradle.usage=java-api -
它的运行时(名为
runtimeElements)带有属性org.gradle.usage=java-runtime
最后,Gradle 通过查看变体属性来选择适当的变体:
-
消费者想要一个具有属性的变体
org.gradle.usage=java-api -
生产者有一个匹配的变体 (
apiElements) -
生产者有一个不匹配的变体 (
runtimeElements)
apiElementsGradle向消费者提供变体的工件和依赖项。
一个更复杂的例子
在现实世界中,消费者和生产者具有不止一种属性。
Gradle 中的 Java 库项目将涉及几个不同的属性:
-
org.gradle.usage描述了如何使用该变体 -
org.gradle.dependency.bundling描述变体如何处理依赖关系(shadow jar、fat jar 和常规 jar) -
org.gradle.libraryelements,描述变体的包装(类或 jar) -
org.gradle.jvm.version描述此变体目标的最小 Java 版本 -
org.gradle.jvm.environment描述了该变体目标的 JVM 类型
让我们考虑一个示例,其中使用者希望使用 Java 8 上的库运行测试,而生产者支持两个不同的 Java 版本(Java 8 和 Java 11)。
首先,消费者需要解释其需要哪个版本的 Java。
消费者想要解决一个变体:
-
可以在运行时使用(有
org.gradle.usage=java-runtime) -
至少可以在Java 8上运行(
org.gradle.jvm.version=8)
其次,生产者需要公开组件的不同变体。
就像这个简单的例子一样,有一个 API(编译)和运行时变体。这些组件的 Java 8 和 Java 11 版本均存在。
-
它针对 Java 8 消费者(名为
apiJava8Elements)的 API 具有属性org.gradle.usage=java-api和org.gradle.jvm.version=8 -
Java 8 消费者(名为
runtime8Elements)的运行时具有属性org.gradle.usage=java-runtime和org.gradle.jvm.version=8 -
其针对 Java 11 消费者(名为
apiJava11Elements)的 API 具有属性org.gradle.usage=java-api和org.gradle.jvm.version=11 -
Java 11 消费者(名为
runtime11Elements)的运行时具有属性org.gradle.usage=java-runtime和org.gradle.jvm.version=11
最后,Gradle 通过查看所有属性来选择最佳匹配变体:
-
消费者想要一个具有兼容属性的变
org.gradle.usage=java-runtime体org.gradle.jvm.version=8 -
变体
runtime8Elements并runtime11Elements具有 `org.gradle.usage=java-runtime -
变体
apiJava8Elements并且apiJava11Elements不兼容 -
该变体
runtime8Elements是兼容的,因为它可以在 Java 8 上运行 -
该变体
runtime11Elements不兼容,因为它无法在 Java 8 上运行
runtime8ElementsGradle向消费者提供变体的工件和依赖项。
如果消费者设置org.gradle.jvm.version为7怎么办?
依赖项解析将失败,并显示一条错误消息,说明没有合适的变体。 Gradle 认识到消费者需要 Java 7 兼容库,而生产者可用的最低Java 版本是 8。
如果消费者提出请求org.gradle.jvm.version=15,Gradle 就会知道 Java 8 或 Java 11 变体都可以工作。 Gradle 选择最高兼容的 Java 版本(11)。
变体选择错误
当选择最兼容的组件变体时,解析可能会失败:
-
当生产者的多个变体与消费者属性匹配时(歧义错误)
-
当生产者没有任何变体与消费者属性匹配时(不兼容错误)
处理歧义错误
不明确的变体选择如下所示:
> Could not resolve all files for configuration ':compileClasspath'.
> Could not resolve project :lib.
Required by:
project :ui
> Cannot choose between the following variants of project :lib:
- feature1ApiElements
- feature2ApiElements
All of them match the consumer attributes:
- Variant 'feature1ApiElements' capability org.test:test-capability:1.0:
- Unmatched attribute:
- Found org.gradle.category 'library' but wasn't required.
- Compatible attributes:
- Provides org.gradle.dependency.bundling 'external'
- Provides org.gradle.jvm.version '11'
- Required org.gradle.libraryelements 'classes' and found value 'jar'.
- Provides org.gradle.usage 'java-api'
- Variant 'feature2ApiElements' capability org.test:test-capability:1.0:
- Unmatched attribute:
- Found org.gradle.category 'library' but wasn't required.
- Compatible attributes:
- Provides org.gradle.dependency.bundling 'external'
- Provides org.gradle.jvm.version '11'
- Required org.gradle.libraryelements 'classes' and found value 'jar'.
- Provides org.gradle.usage 'java-api'
所有兼容的候选变体都会显示其属性。
-
首先呈现不匹配的属性,因为它们可能是选择正确变体时缺失的部分。
-
其次是兼容的属性,因为它们表明消费者想要什么以及这些变体如何满足该请求。
-
不会有任何不兼容的属性,因为变体不会被视为候选。
在上面的示例中,修复不在于属性匹配,而在于功能匹配,这显示在变体名称旁边。由于这两个变体有效地提供了相同的属性和功能,因此无法消除它们的歧义。因此在这种情况下,修复很可能在生产者端提供不同的功能(project :lib)并在消费者端表达功能选择(project :ui)。
处理没有匹配变体的错误
没有匹配变体错误如下所示:
> No variants of project :lib match the consumer attributes:
- Configuration ':lib:compile':
- Incompatible attribute:
- Required artifactType 'dll' and found incompatible value 'jar'.
- Other compatible attribute:
- Provides usage 'api'
- Configuration ':lib:compile' variant debug:
- Incompatible attribute:
- Required artifactType 'dll' and found incompatible value 'jar'.
- Other compatible attributes:
- Found buildType 'debug' but wasn't required.
- Provides usage 'api'
- Configuration ':lib:compile' variant release:
- Incompatible attribute:
- Required artifactType 'dll' and found incompatible value 'jar'.
- Other compatible attributes:
- Found buildType 'release' but wasn't required.
- Provides usage 'api'
或类似:
> No variants of project : match the consumer attributes:
- Configuration ':myElements' declares attribute 'color' with value 'blue':
- Incompatible because this component declares attribute 'artifactType' with value 'jar' and the consumer needed attribute 'artifactType' with value 'dll'
- Configuration ':myElements' variant secondary declares attribute 'color' with value 'blue':
- Incompatible because this component declares attribute 'artifactType' with value 'jar' and the consumer needed attribute 'artifactType' with value 'dll'
取决于变体选择算法中发生错误的阶段。
所有潜在兼容的候选变体都与其属性一起显示。
-
首先呈现不兼容的属性,因为它们通常是理解为什么无法选择变体的关键。
-
其次呈现其他属性,这包括请求的和兼容的属性以及消费者未请求的所有额外生产者属性。
与模糊变体错误类似,目标是了解应选择哪个变体。在某些情况下,生产者可能没有任何兼容的变体(例如,尝试使用为 Java 11 构建的库在 Java 8 上运行)。
处理不兼容的变体错误
不兼容的变体错误类似于以下示例,其中消费者想要选择带有 的变体color=green,但唯一可用的变体具有color=blue:
> Could not resolve all task dependencies for configuration ':resolveMe'.
> Could not resolve project :.
Required by:
project :
> Configuration 'mismatch' in project : does not match the consumer attributes
Configuration 'mismatch':
- Incompatible because this component declares attribute 'color' with value 'blue' and the consumer needed attribute 'color' with value 'green'
当 Gradle 无法选择依赖项的单个变体时,就会发生这种情况,因为显式请求的属性值与依赖项的任何变体上的该属性值不匹配(且不兼容)。
当 Gradle成功选择同一组件的多个变体,但所选变体彼此不兼容时,会发生此故障的子类型。
如下所示,消费者想要选择组件的两种不同变体,每种变体提供不同的功能,这是可以接受的。不幸的是,一种变体有color=blue,另一种有color=green:
> Could not resolve all task dependencies for configuration ':resolveMe'.
> Could not resolve project :.
Required by:
project :
> Multiple incompatible variants of org.example:nyvu:1.0 were selected:
- Variant org.example:nyvu:1.0 variant blueElementsCapability1 has attributes {color=blue}
- Variant org.example:nyvu:1.0 variant greenElementsCapability2 has attributes {color=green}
> Could not resolve project :.
Required by:
project :
> Multiple incompatible variants of org.example:pi2e5:1.0 were selected:
- Variant org.example:pi2e5:1.0 variant blueElementsCapability1 has attributes {color=blue}
- Variant org.example:pi2e5:1.0 variant greenElementsCapability2 has attributes {color=green}
处理不明确的转换错误
ArtifactTransforms 可用于将工件从一种类型转换为另一种类型,从而更改其属性。变体选择可以使用作为工件变换的结果可用的属性作为候选变体。
如果一个项目注册了多个工件转换,需要使用一个工件转换来为消费者的请求生成一个匹配的变体,并且多个工件转换都可以用于完成此操作,那么 Gradle 将失败,并出现如下不明确的转换错误:
> Could not resolve all task dependencies for configuration ':resolveMe'.
> Found multiple transforms that can produce a variant of project : with requested attributes:
- color 'red'
- shape 'round'
Found the following transforms:
- From 'configuration ':roundBlueLiquidElements'':
- With source attributes:
- color 'blue'
- shape 'round'
- state 'liquid'
- Candidate transform(s):
- Transform 'BrokenTransform' producing attributes:
- color 'red'
- shape 'round'
- state 'gas'
- Transform 'BrokenTransform' producing attributes:
- color 'red'
- shape 'round'
- state 'solid'
可视化变体信息
传出变体报告
报告任务outgoingVariants显示可供项目使用者选择的变体列表。它显示每个变体的功能、属性和工件。
dependencyInsight 此任务与报告任务类似。
默认情况下,outgoingVariants打印有关所有变体的信息。它提供可选参数--variant <variantName>来选择要显示的单个变体。它还接受该--all标志以包含有关旧版和已弃用配置的信息,或--no-all排除此信息。
outgoingVariants以下是新生成的项目上的任务输出java-library:
> Task :outgoingVariants
--------------------------------------------------
Variant apiElements
--------------------------------------------------
API elements for the 'main' feature.
Capabilities
- new-java-library:lib:unspecified (default capability)
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = jar
- org.gradle.usage = java-api
Artifacts
- build/libs/lib.jar (artifactType = jar)
Secondary Variants (*)
--------------------------------------------------
Secondary Variant classes
--------------------------------------------------
Description = Directories containing compiled class files for main.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = classes
- org.gradle.usage = java-api
Artifacts
- build/classes/java/main (artifactType = java-classes-directory)
--------------------------------------------------
Variant mainSourceElements (i)
--------------------------------------------------
Description = List of source directories contained in the Main SourceSet.
Capabilities
- new-java-library:lib:unspecified (default capability)
Attributes
- org.gradle.category = verification
- org.gradle.dependency.bundling = external
- org.gradle.verificationtype = main-sources
Artifacts
- src/main/java (artifactType = directory)
- src/main/resources (artifactType = directory)
--------------------------------------------------
Variant runtimeElements
--------------------------------------------------
Runtime elements for the 'main' feature.
Capabilities
- new-java-library:lib:unspecified (default capability)
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = jar
- org.gradle.usage = java-runtime
Artifacts
- build/libs/lib.jar (artifactType = jar)
Secondary Variants (*)
--------------------------------------------------
Secondary Variant classes
--------------------------------------------------
Description = Directories containing compiled class files for main.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = classes
- org.gradle.usage = java-runtime
Artifacts
- build/classes/java/main (artifactType = java-classes-directory)
--------------------------------------------------
Secondary Variant resources
--------------------------------------------------
Description = Directories containing the project's assembled resource files for use at runtime.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = resources
- org.gradle.usage = java-runtime
Artifacts
- build/resources/main (artifactType = java-resources-directory)
--------------------------------------------------
Variant testResultsElementsForTest (i)
--------------------------------------------------
Description = Directory containing binary results of running tests for the test Test Suite's test target.
Capabilities
- new-java-library:lib:unspecified (default capability)
Attributes
- org.gradle.category = verification
- org.gradle.testsuite.name = test
- org.gradle.testsuite.target.name = test
- org.gradle.testsuite.type = unit-test
- org.gradle.verificationtype = test-results
Artifacts
- build/test-results/test/binary (artifactType = directory)
(i) Configuration uses incubating attributes such as Category.VERIFICATION.
(*) Secondary variants are variants created via the Configuration#getOutgoing(): ConfigurationPublications API which also participate in selection, in addition to the configuration itself.
从中您可以看到 java 库公开的两个主要变体,apiElements以及runtimeElements.请注意,主要区别在于org.gradle.usage属性,即值java-api和java-runtime。正如他们所指出的,这就是消费者的编译类路径上需要的内容与运行时类路径上需要的内容之间的区别所在。
它还显示了次要变体,这些变体是 Gradle 项目独有的且未发布。例如,第二个变体classes允许Gradle 在针对项目apiElements进行编译时跳过 JAR 创建。java-library
可解析的配置报告
Gradle 还提供了一个名为 的免费报告任务,resolvableConfigurations该任务显示项目的可解析配置,这些配置可以添加依赖项并进行解析。该报告将列出它们的属性以及它们扩展的任何配置。它还将列出解析过程中将受兼容性规则或消歧规则影响的任何属性的摘要。
默认情况下,resolvableConfigurations打印有关所有纯可解析配置的信息。这些配置被标记为可解析但未标记为可消耗。尽管一些可解析的配置也被标记为可消耗的,但这些是遗留配置,不应在构建脚本中添加依赖项。此报告提供可选参数--configuration <configurationName>来选择要显示的单个配置。它还接受该--all标志以包含有关旧版和已弃用配置的信息,或--no-all排除此信息。最后,它接受--recursive标志以在扩展配置部分中列出那些间接扩展而不是直接扩展的配置。或者,--no-recursive可用于排除此信息。
resolvableConfigurations以下是新生成的项目上的任务输出java-library:
> Task :resolvableConfigurations
--------------------------------------------------
Configuration annotationProcessor
--------------------------------------------------
Description = Annotation processors and their dependencies for source set 'main'.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.environment = standard-jvm
- org.gradle.libraryelements = jar
- org.gradle.usage = java-runtime
--------------------------------------------------
Configuration compileClasspath
--------------------------------------------------
Description = Compile classpath for source set 'main'.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.environment = standard-jvm
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = classes
- org.gradle.usage = java-api
Extended Configurations
- compileOnly
- implementation
--------------------------------------------------
Configuration runtimeClasspath
--------------------------------------------------
Description = Runtime classpath of source set 'main'.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.environment = standard-jvm
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = jar
- org.gradle.usage = java-runtime
Extended Configurations
- implementation
- runtimeOnly
--------------------------------------------------
Configuration testAnnotationProcessor
--------------------------------------------------
Description = Annotation processors and their dependencies for source set 'test'.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.environment = standard-jvm
- org.gradle.libraryelements = jar
- org.gradle.usage = java-runtime
--------------------------------------------------
Configuration testCompileClasspath
--------------------------------------------------
Description = Compile classpath for source set 'test'.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.environment = standard-jvm
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = classes
- org.gradle.usage = java-api
Extended Configurations
- testCompileOnly
- testImplementation
--------------------------------------------------
Configuration testRuntimeClasspath
--------------------------------------------------
Description = Runtime classpath of source set 'test'.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.environment = standard-jvm
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = jar
- org.gradle.usage = java-runtime
Extended Configurations
- testImplementation
- testRuntimeOnly
--------------------------------------------------
Compatibility Rules
--------------------------------------------------
Description = The following Attributes have compatibility rules defined.
- org.gradle.dependency.bundling
- org.gradle.jvm.environment
- org.gradle.jvm.version
- org.gradle.libraryelements
- org.gradle.plugin.api-version
- org.gradle.usage
--------------------------------------------------
Disambiguation Rules
--------------------------------------------------
Description = The following Attributes have disambiguation rules defined.
- org.gradle.category
- org.gradle.dependency.bundling
- org.gradle.jvm.environment
- org.gradle.jvm.version
- org.gradle.libraryelements
- org.gradle.plugin.api-version
- org.gradle.usage
从中可以看到用于解决依赖关系的两个主要配置 和compileClasspath,runtimeClasspath以及它们对应的测试配置。
从 Maven/Ivy 到 Gradle 变体的映射
Maven 和 Ivy 都没有变体的概念,只有 Gradle 模块元数据原生支持变体。 Gradle 仍然可以通过使用不同的变体派生策略与 Maven 和 Ivy 配合使用。
Gradle 模块元数据是在 Maven、Ivy 和其他类型的存储库上发布的模块的元数据格式。它类似于pom.xml或ivy.xml元数据文件,但此格式包含有关变体的详细信息。
有关更多信息,请参阅Gradle 模块元数据规范。
Maven POM 元数据到变体的映射
在 Maven 存储库上发布的模块会自动转换为变体感知模块。
Gradle 无法知道发布了哪种组件:
-
代表 Gradle 平台的 BOM
-
用作超级 POM 的 BOM
-
既是平台又是库的POM
Gradle 中 Java 项目使用的默认策略是派生 8 种不同的变体:
-
两个“库”变体(属性
org.gradle.category=library) -
代表组件源 jar 的“源”变体
-
表示组件的 javadoc jar 的“javadoc”变体
-
从该
<dependencyManagement>块派生的四个“平台”变体(属性org.gradle.category=platform):-
该变体将依赖关系管理依赖关系
platform-compile映射为依赖关系约束。<scope>compile</scope> -
该
platform-runtime变体将<scope>compile</scope>和<scope>runtime</scope>依赖管理依赖关系映射为依赖约束。 -
类似于
enforced-platform-compile但platform-compile所有约束都是强制的 -
类似于
enforced-platform-runtime但platform-runtime所有约束都是强制的
-
您可以通过查看手册的导入 BOM部分来了解有关平台和强制平台变体的使用的更多信息。默认情况下,每当您声明对 Maven 模块的依赖项时,Gradle 都会查找library变体。然而,使用platformorenforcedPlatform关键字,Gradle 现在正在寻找“平台”变体之一,它允许您从 POM 文件导入约束,而不是依赖项。
Ivy 文件到变体的映射
Gradle 没有为 Ivy 文件实现内置的派生策略。 Ivy 是一种灵活的格式,允许您发布任意文件并且可以进行大量自定义。
如果您想为 Ivy 的编译和运行时变体实现派生策略,您可以使用组件元数据规则来实现。组件元数据规则 API 允许您访问 Ivy 配置并基于它们创建变体。如果您知道您正在使用的所有 Ivy 模块都已使用 Gradle 发布,而无需进一步自定义文件ivy.xml,则可以将以下规则添加到您的构建中:
abstract class IvyVariantDerivationRule @Inject internal constructor(objectFactory: ObjectFactory) : ComponentMetadataRule {
private val jarLibraryElements: LibraryElements
private val libraryCategory: Category
private val javaRuntimeUsage: Usage
private val javaApiUsage: Usage
init {
jarLibraryElements = objectFactory.named(LibraryElements.JAR)
libraryCategory = objectFactory.named(Category.LIBRARY)
javaRuntimeUsage = objectFactory.named(Usage.JAVA_RUNTIME)
javaApiUsage = objectFactory.named(Usage.JAVA_API)
}
override fun execute(context: ComponentMetadataContext) {
// This filters out any non Ivy module
if(context.getDescriptor(IvyModuleDescriptor::class) == null) {
return
}
context.details.addVariant("runtimeElements", "default") {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, jarLibraryElements)
attribute(Category.CATEGORY_ATTRIBUTE, libraryCategory)
attribute(Usage.USAGE_ATTRIBUTE, javaRuntimeUsage)
}
}
context.details.addVariant("apiElements", "compile") {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, jarLibraryElements)
attribute(Category.CATEGORY_ATTRIBUTE, libraryCategory)
attribute(Usage.USAGE_ATTRIBUTE, javaApiUsage)
}
}
}
}
dependencies {
components { all<IvyVariantDerivationRule>() }
}abstract class IvyVariantDerivationRule implements ComponentMetadataRule {
final LibraryElements jarLibraryElements
final Category libraryCategory
final Usage javaRuntimeUsage
final Usage javaApiUsage
@Inject
IvyVariantDerivationRule(ObjectFactory objectFactory) {
jarLibraryElements = objectFactory.named(LibraryElements, LibraryElements.JAR)
libraryCategory = objectFactory.named(Category, Category.LIBRARY)
javaRuntimeUsage = objectFactory.named(Usage, Usage.JAVA_RUNTIME)
javaApiUsage = objectFactory.named(Usage, Usage.JAVA_API)
}
void execute(ComponentMetadataContext context) {
// This filters out any non Ivy module
if(context.getDescriptor(IvyModuleDescriptor) == null) {
return
}
context.details.addVariant("runtimeElements", "default") {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, jarLibraryElements)
attribute(Category.CATEGORY_ATTRIBUTE, libraryCategory)
attribute(Usage.USAGE_ATTRIBUTE, javaRuntimeUsage)
}
}
context.details.addVariant("apiElements", "compile") {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, jarLibraryElements)
attribute(Category.CATEGORY_ATTRIBUTE, libraryCategory)
attribute(Usage.USAGE_ATTRIBUTE, javaApiUsage)
}
}
}
}
dependencies {
components { all(IvyVariantDerivationRule) }
}该规则apiElements根据配置创建一个变体,并根据每个 ivy 模块的配置创建compile一个变体。对于每个变体,它设置相应的Java生态系统属性。变体的依赖关系和工件取自底层配置。如果并非所有消耗的 Ivy 模块都遵循此模式,则可以调整该规则或仅将其应用于选定的一组模块。runtimeElementsdefault
对于所有没有变体的 Ivy 模块,Gradle 有一个后备选择方法。 Gradle不执行变体感知解析,而是选择default配置或显式命名的配置。
使用变体属性
如变体感知匹配部分所述,属性为变体提供语义,并由 Gradle 的依赖管理引擎用来选择最佳匹配变体。
作为 Gradle 的用户,属性通常隐藏为实现细节。但了解Gradle 及其核心插件定义的标准属性可能会很有用。
作为插件作者,这些属性及其定义方式可以作为在生态系统插件中构建您自己的属性集的基础。
Gradle定义的标准属性
Gradle 定义了 Gradle 核心插件使用的标准属性列表。
独立于生态系统的标准属性
| 属性名称 | 描述 | 价值观 | 兼容性和消歧规则 |
|---|---|---|---|
表示变体的主要目的 |
|
遵循生态系统语义(例如 |
|
表示该软件组件的类别 |
|
遵循生态系统语义(例如, |
|
|
|
遵循生态系统语义(例如,在 JVM 世界中, |
|
|
|
无默认,无兼容性 |
|
指示如何访问变体的依赖项。 |
|
遵循生态系统语义(例如,在 JVM 世界中, |
|
指示产生此输出的验证任务类型。 |
|
无默认,无兼容性 |
|
警告
|
当 这些变体仅包含运行验证任务的结果,例如测试结果或代码覆盖率报告。它们不可发布,如果添加到已发布的组件中,将会产生错误。 |
| 属性名称 | 描述 | 价值观 | 兼容性和消歧规则 |
|---|---|---|---|
|
组件级属性,派生的 |
基于状态方案,默认方案基于源存储库。 |
基于所使用的方案 |
JVM 生态系统特定属性
除了上面定义的生态系统独立属性之外,JVM 生态系统还添加了以下属性:
| 属性名称 | 描述 | 价值观 | 兼容性和消歧规则 |
|---|---|---|---|
指示JVM版本兼容性。 |
整数使用 Java 1.4 及之前的版本 |
默认为 Gradle 使用的 JVM 版本,较低版本与较高版本兼容,优先选择最高兼容版本。 |
|
指示变体针对特定 JVM 环境进行了优化。 |
共同值为 |
如果有多个可用,该属性用于优先选择一种变体而不是另一种变体,但通常所有值都是兼容的。默认为 |
|
指示生成此输出的TestSuite的名称。 |
值是套件的名称。 |
无默认,无兼容性 |
|
指示生成此输出的TestSuiteTarget的名称。 |
值是目标的名称。 |
无默认,无兼容性 |
|
指示测试套件的类型(单元测试、集成测试、性能测试等) |
|
无默认,无兼容性 |
JVM 生态系统还包含许多针对不同属性的兼容性和消歧规则。愿意了解更多的读者可以看一下 的代码org.gradle.api.internal.artifacts.JavaEcosystemSupport。
本地生态系统特定属性
除了上面定义的生态系统独立属性之外,原生生态系统还添加了以下属性:
| 属性名称 | 描述 | 价值观 | 兼容性和消歧规则 |
|---|---|---|---|
指示二进制文件是否是使用调试符号构建的 |
布尔值 |
不适用 |
|
指示二进制文件是否是使用优化标志构建的 |
布尔值 |
不适用 |
|
指示二进制文件的目标架构 |
|
没有任何 |
|
指示二进制文件的目标操作系统 |
|
没有任何 |
Gradle 插件生态系统特定属性
对于 Gradle 插件开发,从 Gradle 7.0 开始支持以下属性。 Gradle 插件变体可以通过此属性指定与 Gradle API 版本的兼容性。
| 属性名称 | 描述 | 价值观 | 兼容性和消歧规则 |
|---|---|---|---|
指示 Gradle API 版本兼容性。 |
有效的 Gradle 版本字符串。 |
默认为当前运行的 Gradle,较低的与较高的兼容,首选最高的兼容。 |
在构建脚本或插件中创建属性
属性是键入的。可以通过以下方法创建属性Attribute<T>.of:
// An attribute of type `String`
val myAttribute = Attribute.of("my.attribute.name", String::class.java)
// An attribute of type `Usage`
val myUsage = Attribute.of("my.usage.attribute", Usage::class.java)// An attribute of type `String`
def myAttribute = Attribute.of("my.attribute.name", String)
// An attribute of type `Usage`
def myUsage = Attribute.of("my.usage.attribute", Usage)属性类型支持大多数Java原始类;例如String和Integer;或者任何延伸的东西org.gradle.api.Named。属性必须在处理程序上找到的属性模式dependencies中声明:
dependencies.attributesSchema {
// registers this attribute to the attributes schema
attribute(myAttribute)
attribute(myUsage)
}dependencies.attributesSchema {
// registers this attribute to the attributes schema
attribute(myAttribute)
attribute(myUsage)
}然后可以配置配置来设置属性值:
configurations {
create("myConfiguration") {
attributes {
attribute(myAttribute, "my-value")
}
}
}configurations {
myConfiguration {
attributes {
attribute(myAttribute, 'my-value')
}
}
}对于扩展类型的属性Named,属性的值必须通过对象工厂创建:
configurations {
"myConfiguration" {
attributes {
attribute(myUsage, project.objects.named(Usage::class.java, "my-value"))
}
}
}configurations {
myConfiguration {
attributes {
attribute(myUsage, project.objects.named(Usage, 'my-value'))
}
}
}属性匹配
属性兼容性规则
属性让引擎选择兼容的变体。在某些情况下,生产者可能没有完全满足消费者的要求,但有可以使用的变体。
例如,如果消费者请求库的 API,而生产者没有完全匹配的变体,则运行时变体可以被认为是兼容的。这是发布到外部存储库的典型库。在这种情况下,我们知道即使我们没有完全匹配(API),我们仍然可以针对运行时变体进行编译(它包含的内容比我们需要编译的内容更多,但仍然可以使用)。
Gradle 提供了可以为每个属性定义的属性兼容性规则。兼容性规则的作用是根据消费者的要求解释哪些属性值是兼容的。
属性消歧规则
由于属性的多个值可以兼容,Gradle 需要在所有兼容候选者中选择“最佳”候选者。这称为“消歧”。
这是通过实施属性消歧规则来完成的。
属性消歧规则必须通过属性匹配策略进行注册,您可以从属性模式中获取该策略,该模式是DependencyHandler的成员。
变体属性匹配算法
当组件有许多不同的变体和许多不同的属性时,寻找最佳变体可能会变得很复杂。 Gradle 的依赖解析引擎在找到最佳结果(或失败)时执行以下算法:
-
将每个候选的属性值与消费者请求的属性值进行比较。如果候选者的值与消费者的值完全匹配、通过属性的兼容性规则或未提供,则该候选者被认为是兼容的。
-
如果只有一名候选人被认为兼容,则该候选人获胜。
-
如果多个候选者兼容,但其中一个候选者与其他候选者匹配所有相同的属性,Gradle 将选择该候选者。这是“最长”匹配的候选者。
-
如果多个候选者兼容并且与相同数量的属性兼容,Gradle 需要消除候选者的歧义。
-
对于每个请求的属性,如果候选属性没有与消歧规则匹配的值,则将其从考虑中排除。
-
如果该属性具有已知的优先级,Gradle 将在剩下一个候选属性时立即停止。
-
如果属性没有已知的优先级,Gradle 必须考虑所有属性。
-
-
如果仍然有几个候选者,Gradle 将开始考虑“额外”属性来消除多个候选者之间的歧义。额外属性是消费者未请求但至少存在于一个候选者上的属性。这些额外属性按优先顺序考虑。
-
如果该属性具有已知的优先级,Gradle 将在剩下一个候选属性时立即停止。
-
在考虑了所有具有优先级的额外属性之后,如果剩余的候选属性与所有无序消歧规则兼容,则可以选择它们。
-
-
如果仍然有几个候选属性,Gradle 将再次考虑额外的属性。如果候选者具有最少的额外属性,则可以选择该候选者。
如果在任何步骤中没有候选者保持兼容,则解决方案失败。此外,Gradle 会输出步骤 1 中所有兼容候选者的列表,以帮助调试变体匹配失败。
插件和生态系统可以通过实现兼容性规则、消歧规则以及告诉 Gradle 属性的优先级来影响选择算法。具有较高优先级的属性用于按顺序消除兼容匹配。
例如,在Java生态系统中,org.gradle.usage属性的优先级高于org.gradle.libraryelements.这意味着,如果org.gradle.usage和的两个候选值都具有兼容的值org.gradle.libraryelements,Gradle 将选择通过 的消歧规则的候选者org.gradle.usage。
在项目之间共享输出
在多项目构建中,一种常见的模式是一个项目消耗另一个项目的工件。一般来说,Java生态中最简单的消费形式就是,当A依赖时B,则A依赖jar项目产生的B。如本章前面所述,这是A根据 的变体 B进行建模的,其中变体是根据 的需要选择的A。为了编译,我们需要变体B提供的API 依赖项apiElements。对于运行时,我们需要变体B提供的运行时依赖项runtimeElements。
但是,如果您需要与主要工件不同的工件怎么办?例如,Gradle 提供了对依赖于另一个项目的测试装置的内置支持,但有时您需要依赖的工件根本没有作为变体公开。
为了在项目之间安全地共享并允许最大性能(并行性),此类工件必须通过传出配置公开。
声明跨项目依赖关系的常见反模式是:
dependencies {
// this is unsafe!
implementation project(":other").tasks.someOtherJar
}这种发布模型是不安全的,可能会导致不可重复且难以并行化的构建。本节介绍如何通过使用变体定义项目之间的“交换”来正确创建跨项目边界。
有两个互补的选项可以在项目之间共享工件。仅当您需要共享的是不依赖于消费者的简单工件时,简化版本才适用。简单的解决方案还仅限于此工件未发布到存储库的情况。这也意味着消费者不会发布对此工件的依赖项。如果消费者在不同的上下文(例如,不同的目标平台)中解析不同的工件或需要发布,则需要使用高级版本。
在项目之间简单地共享工件
首先,生产者需要声明将向消费者公开的配置。正如配置章节中所解释的,这对应于消耗性配置。
让我们想象一下,消费者需要来自生产者的检测类,但这个工件不是主要的。生产者可以通过创建一个将“携带”此工件的配置来公开其检测的类:
val instrumentedJars by configurations.creating {
isCanBeConsumed = true
isCanBeResolved = false
// If you want this configuration to share the same dependencies, otherwise omit this line
extendsFrom(configurations["implementation"], configurations["runtimeOnly"])
}configurations {
instrumentedJars {
canBeConsumed = true
canBeResolved = false
// If you want this configuration to share the same dependencies, otherwise omit this line
extendsFrom implementation, runtimeOnly
}
}这种配置是消耗品,这意味着它是针对消费者的“交换”。我们现在将向此配置添加工件,消费者在使用它时将获得这些工件:
artifacts {
add("instrumentedJars", instrumentedJar)
}artifacts {
instrumentedJars(instrumentedJar)
}这里我们附加的“工件”是一个实际生成 Jar 的任务。这样做,Gradle 可以自动跟踪该任务的依赖关系并根据需要构建它们。这是可能的,因为Jar任务延长了AbstractArchiveTask。如果不是这种情况,您将需要显式声明工件是如何生成的。
artifacts {
add("instrumentedJars", someTask.outputFile) {
builtBy(someTask)
}
}artifacts {
instrumentedJars(someTask.outputFile) {
builtBy(someTask)
}
}现在消费者需要依赖此配置才能获得正确的工件:
dependencies {
instrumentedClasspath(project(mapOf(
"path" to ":producer",
"configuration" to "instrumentedJars")))
}dependencies {
instrumentedClasspath(project(path: ":producer", configuration: 'instrumentedJars'))
}|
警告
|
不建议 声明对显式目标配置的依赖。如果您计划发布具有此依赖性的组件,这可能会导致元数据损坏。如果您需要在远程存储库上发布组件,请按照变体感知交叉发布文档的说明进行操作。 |
在本例中,我们将依赖项添加到InstrumentedClasspath配置中,该配置是消费者特定的配置。在 Gradle 术语中,这称为可解析配置,其定义如下:
val instrumentedClasspath by configurations.creating {
isCanBeConsumed = false
}configurations {
instrumentedClasspath {
canBeConsumed = false
}
}项目之间工件的变体感知共享
在简单共享解决方案中,我们在生产者端定义了一个配置,用作生产者和消费者之间的工件交换。然而,消费者必须明确地告诉它依赖于哪个配置,这是我们在变量感知解析中要避免的事情。事实上,我们还解释了消费者可以使用属性来表达需求,并且生产者也应该使用属性提供适当的输出变体。这允许更智能的选择,因为使用单个依赖项声明,无需任何显式目标配置,消费者可以解决不同的问题。典型的例子是,使用单个依赖声明project(":myLib"),我们可以根据架构选择arm64或i386版本。myLib
为此,我们将为消费者和生产者添加属性。
重要的是要理解,一旦配置具有属性,它们就会参与变体感知解析,这意味着只要使用任何类似的符号,它们都是候选者。project(":myLib")也就是说,生产者上设置的属性必须与同一项目上生产的其他变体一致。特别是,它们不得给现有选择带来歧义。
实际上,这意味着您创建的配置上使用的属性集可能依赖于正在使用的生态系统(Java、C++,...),因为这些生态系统的相关插件通常使用不同的属性。
让我们增强之前的示例,该示例恰好是一个 Java 库项目。 Java 库向其使用者公开了几个变体,apiElements并且runtimeElements.现在,我们添加第三个,instrumentedJars.
因此,我们需要了解新变体的用途,以便为其设置正确的属性。让我们看看在runtimeElements生产者的配置中找到的属性:
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = jar
- org.gradle.usage = java-runtime
它告诉我们 Java 库插件生成具有 5 个属性的变体:
-
org.gradle.category告诉我们这个变体代表一个库 -
org.gradle.dependency.bundling告诉我们这个变体的依赖项是作为 jar 找到的(例如,它们没有重新打包在 jar 内) -
org.gradle.jvm.version告诉我们该库支持的最低 Java 版本是 Java 11 -
org.gradle.libraryelements告诉我们这个变体包含在 jar 中找到的所有元素(类和资源) -
org.gradle.usage表示此变体是 Java 运行时,因此适用于 Java 编译器,但也适用于运行时
因此,如果我们希望在执行测试时使用我们的检测类来代替此变体,我们需要将类似的属性附加到我们的变体中。事实上,我们关心的属性是org.gradle.libraryelements解释变量包含的内容,所以我们可以这样设置变量:
val instrumentedJars by configurations.creating {
isCanBeConsumed = true
isCanBeResolved = false
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.LIBRARY))
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage.JAVA_RUNTIME))
attribute(Bundling.BUNDLING_ATTRIBUTE, objects.named(Bundling.EXTERNAL))
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, JavaVersion.current().majorVersion.toInt())
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named("instrumented-jar"))
}
}configurations {
instrumentedJars {
canBeConsumed = true
canBeResolved = false
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.LIBRARY))
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, Usage.JAVA_RUNTIME))
attribute(Bundling.BUNDLING_ATTRIBUTE, objects.named(Bundling, Bundling.EXTERNAL))
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, JavaVersion.current().majorVersion.toInteger())
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named(LibraryElements, 'instrumented-jar'))
}
}
}|
笔记
|
选择正确的属性来设置是这个过程中最困难的事情,因为它们携带了变体的语义。因此,在添加新属性之前,您应该始终问自己是否没有一个属性携带您需要的语义。如果没有,那么您可以添加一个新属性。添加新属性时,您还必须小心,因为它可能会在选择过程中产生歧义。通常添加属性意味着将其添加到所有现有变体中。 |
我们在这里所做的是添加了一个新的变体,它可以在运行时使用,但包含检测类而不是普通类。然而,现在这意味着对于运行时,消费者必须在两种变体之间进行选择:
-
runtimeElementsjava-library,插件提供的常规变体 -
instrumentedJars,我们创建的变体
特别是,假设我们希望测试运行时类路径上的检测类。现在,我们可以在消费者上将我们的依赖项声明为常规项目依赖项:
dependencies {
testImplementation("junit:junit:4.13")
testImplementation(project(":producer"))
}dependencies {
testImplementation 'junit:junit:4.13'
testImplementation project(':producer')
}如果我们停在这里,Gradle 仍然会选择该runtimeElements变体来代替我们的instrumentedJars变体。这是因为testRuntimeClasspath配置要求配置哪个libraryelements属性jar,而我们的新instrumented-jars值不兼容。
因此,我们需要更改请求的属性,以便我们现在查找已检测的 jar:
configurations {
testRuntimeClasspath {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named(LibraryElements::class.java, "instrumented-jar"))
}
}
}configurations {
testRuntimeClasspath {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named(LibraryElements, 'instrumented-jar'))
}
}
}我们可以查看消费者端的另一份报告,以准确查看将请求每个依赖项的哪些属性:
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = instrumented-jar
- org.gradle.usage = java-runtime
该resolvableConfigurations报告是报告的补充outgoingVariants。通过分别在关系的消费者端和生产者端运行这两个报告,您可以准确地看到依赖项解析期间匹配涉及哪些属性,并在解析配置时更好地预测结果。
现在,我们说每当我们要解析测试运行时类路径时,我们正在寻找的是检测类。但有一个问题:在我们的依赖项列表中,我们有 JUnit,显然它没有被检测。因此,如果我们停在这里,Gradle 将失败,并解释说 JUnit 没有提供检测类的变体。这是因为我们没有解释如果没有可用的检测版本,则可以使用常规 jar。为此,我们需要编写兼容性规则:
abstract class InstrumentedJarsRule: AttributeCompatibilityRule<LibraryElements> {
override fun execute(details: CompatibilityCheckDetails<LibraryElements>) = details.run {
if (consumerValue?.name == "instrumented-jar" && producerValue?.name == "jar") {
compatible()
}
}
}abstract class InstrumentedJarsRule implements AttributeCompatibilityRule<LibraryElements> {
@Override
void execute(CompatibilityCheckDetails<LibraryElements> details) {
if (details.consumerValue.name == 'instrumented-jar' && details.producerValue.name == 'jar') {
details.compatible()
}
}
}我们需要在属性模式上声明:
dependencies {
attributesSchema {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE) {
compatibilityRules.add(InstrumentedJarsRule::class.java)
}
}
}dependencies {
attributesSchema {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE) {
compatibilityRules.add(InstrumentedJarsRule)
}
}
}就是这样!现在我们有:
-
添加了一个提供仪器化罐子的变体
-
解释说这个变体是运行时的替代品
-
解释说消费者仅在测试运行时需要此变体
因此,Gradle 提供了一种强大的机制来根据偏好和兼容性选择正确的变体。更多详细信息可以在文档的变体感知插件部分找到。
|
警告
|
通过像我们所做的那样向现有属性添加值,或者通过定义新属性,我们正在扩展模型。这意味着所有消费者都必须了解这个扩展模型。 对于本地消费者来说,这通常不是问题,因为所有项目都理解并共享相同的模式,但是如果您必须将这个新变体发布到外部存储库,则意味着外部消费者必须将相同的规则添加到他们的构建中他们通过。对于生态系统插件(例如:Kotlin 插件)来说,这通常不是问题,在任何情况下,如果不应用插件,消费都是不可能的,但如果您添加自定义值或属性,则会出现问题。 因此,如果自定义变体仅供内部使用,请避免发布它们。 |
针对不同平台
库针对不同平台是很常见的。在Java生态系统中,我们经常看到同一个库的不同工件,通过不同的分类器来区分。一个典型的例子是Guava,它的发布方式是这样的:
-
guava-jre适用于 JDK 8 及以上版本 -
guava-android对于 JDK 7
这种方法的问题在于没有与分类器关联的语义。特别是依赖解析引擎无法根据消费者的需求自动确定使用哪个版本。例如,最好表达你对 Guava 有依赖,并让引擎根据兼容的内容jre进行选择。android
Gradle 为此提供了一个改进的模型,它没有分类器的弱点:属性。
特别是,在 Java 生态系统中,Gradle 提供了一个内置属性,库作者可以使用该属性来表达与 Java 生态系统的兼容性:org.gradle.jvm.version.该属性表示使用者为了正常工作而必须拥有的最小版本。
当您应用java或java-library插件时,Gradle 会自动将此属性关联到传出变体。这意味着使用 Gradle 发布的所有库都会自动告知它们使用哪个目标平台。
虽然此属性是自动设置的,但默认情况下 Gradle不会让您为不同的 JVM 构建项目。如果您需要这样做,那么您将需要按照变体感知匹配的说明创建其他变体。
|
笔记
|
Gradle 的未来版本将提供针对不同 Java 平台自动构建的方法。 |
改变分辨率上的依赖工件
正如不同种类的配置中所描述的,相同的依赖关系可能有不同的变体。例如,外部 Maven 依赖项具有在针对依赖项进行编译时应使用的变体 ( java-api),以及用于运行使用依赖项的应用程序的变体 ( java-runtime)。项目依赖项有更多变体,例如用于编译的项目类可以作为类目录 ( org.gradle.usage=java-api, org.gradle.libraryelements=classes) 或 JAR ( org.gradle.usage=java-api, org.gradle.libraryelements=jar) 提供。
依赖项的变体可能在其传递依赖项或工件本身方面有所不同。例如, Maven 依赖项的java-api和java-runtime变体仅在传递依赖项上有所不同,并且都使用相同的工件 - JAR 文件。对于项目依赖项,java-api,classes和java-api,jars变体具有相同的传递依赖项和不同的工件 - 分别是类目录和 JAR 文件。
Gradle 通过其属性集唯一地标识依赖项的变体。java-api依赖项的变体是由值为 的属性标识的变org.gradle.usage体java-api。
当 Gradle 解析配置时,解析的配置上的属性决定了请求的属性。对于配置中的所有依赖项,在解析配置时会选择具有所请求属性的变体。例如,当配置请求org.gradle.usage=java-api, org.gradle.libraryelements=classes项目依赖项时,则选择类目录作为工件。
当依赖项不具有具有所请求属性的变体时,解析配置将失败。有时,可以将依赖项的工件转换为请求的变体,而不更改传递依赖项。例如,解压缩 JAR 会将java-api,jars变体的工件转换为java-api,classes变体。这种变换称为Artifact Transform。 Gradle 允许注册工件转换,当依赖项没有请求的变体时,Gradle 将尝试查找工件转换链来创建变体。
工件变换选择和执行
如上所述,当 Gradle 解析配置并且配置中的依赖项不具有具有所请求属性的变体时,Gradle 会尝试找到工件转换链来创建变体。寻找匹配的工件变换链的过程称为工件变换选择。每个注册的转换都会从一组属性转换为一组属性。例如,unzip 转换可以从 转换org.gradle.usage=java-api, org.gradle.libraryelements=jars为org.gradle.usage=java-api, org.gradle.libraryelements=classes。
为了找到一条链,Gradle 从请求的属性开始,然后将修改某些请求的属性的所有转换视为通向那里的可能路径。向后看,Gradle 尝试使用转换来获取某些现有变体的路径。
例如,考虑minified具有两个值的属性:true和false。 minified 属性表示删除了不必要的类文件的依赖项的变体。注册了一个工件转换,可以minified从转换false为true。当minified=true请求依赖项,并且只有带 的变体时minified=false,Gradle 选择注册的 minify 转换。缩小转换能够将依赖项 的工件转换minified=false为 的工件minified=true。
在所有找到的变换链中,Gradle 尝试选择最好的一个:
-
如果只有一个变换链,则选择它。
-
如果有两个变换链,并且其中一个是另一个的后缀,则选择它。
-
如果存在最短变换链,则选择它。
-
在所有其他情况下,选择都会失败并报告错误。
|
重要的
|
当已经存在与请求的属性匹配的依赖项变体时,Gradle 不会尝试选择工件转换。 |
|
笔记
|
该 |
选择所需的工件转换后,Gradle 会解析链中初始转换所需的依赖项变体。一旦 Gradle 通过下载外部依赖项或执行生成工件的任务完成解析变体的工件,Gradle 就会开始使用选定的工件转换链来转换变体的工件。 Gradle 在可能的情况下并行执行转换链。
选择上面的 minify 示例,考虑具有两个依赖项的配置:外部guava依赖项和项目的项目依赖项producer。配置具有属性org.gradle.usage=java-runtime,org.gradle.libraryelements=jar,minified=true。外部guava依赖有两种变体:
-
org.gradle.usage=java-runtime,org.gradle.libraryelements=jar,minified=false和 -
org.gradle.usage=java-api,org.gradle.libraryelements=jar,minified=false。
使用 minify 转换,Gradle 可以将org.gradle.usage=java-runtime,org.gradle.libraryelements=jar,minified=false的变体转换guava为org.gradle.usage=java-runtime,org.gradle.libraryelements=jar,minified=true,这是所请求的属性。项目依赖也有变体:
-
org.gradle.usage=java-runtime,org.gradle.libraryelements=jar,minified=false, -
org.gradle.usage=java-runtime,org.gradle.libraryelements=classes,minified=false, -
org.gradle.usage=java-api,org.gradle.libraryelements=jar,minified=false, -
org.gradle.usage=java-api,org.gradle.libraryelements=classes,minified=false -
还有一些。
同样,使用 minify 转换,Gradle 可以将org.gradle.usage=java-runtime,org.gradle.libraryelements=jar,minified=false项目的变体转换producer为org.gradle.usage=java-runtime,org.gradle.libraryelements=jar,minified=true,这是所请求的属性。
解决配置后,Gradle 需要下载guavaJAR 并将其缩小。 Gradle 还需要执行producer:jar任务来生成项目的 JAR 工件,然后对其进行缩小。下载和压缩guava.jar与producer:jar任务的执行和生成的 JAR 的压缩并行进行。
以下是如何设置该minified属性以使上述功能起作用。您需要在架构中注册新属性,将其添加到所有 JAR 工件并在所有可解析配置上请求它。
val artifactType = Attribute.of("artifactType", String::class.java)
val minified = Attribute.of("minified", Boolean::class.javaObjectType)
dependencies {
attributesSchema {
attribute(minified) // (1)
}
artifactTypes.getByName("jar") {
attributes.attribute(minified, false) // (2)
}
}
configurations.all {
afterEvaluate {
if (isCanBeResolved) {
attributes.attribute(minified, true) // (3)
}
}
}
dependencies {
registerTransform(Minify::class) {
from.attribute(minified, false).attribute(artifactType, "jar")
to.attribute(minified, true).attribute(artifactType, "jar")
}
}
dependencies { // (4)
implementation("com.google.guava:guava:27.1-jre")
implementation(project(":producer"))
}
tasks.register<Copy>("resolveRuntimeClasspath") { // (5)
from(configurations.runtimeClasspath)
into(layout.buildDirectory.dir("runtimeClasspath"))
}def artifactType = Attribute.of('artifactType', String)
def minified = Attribute.of('minified', Boolean)
dependencies {
attributesSchema {
attribute(minified) // (1)
}
artifactTypes.getByName("jar") {
attributes.attribute(minified, false) // (2)
}
}
configurations.all {
afterEvaluate {
if (canBeResolved) {
attributes.attribute(minified, true) // (3)
}
}
}
dependencies {
registerTransform(Minify) {
from.attribute(minified, false).attribute(artifactType, "jar")
to.attribute(minified, true).attribute(artifactType, "jar")
}
}
dependencies { // (4)
implementation('com.google.guava:guava:27.1-jre')
implementation(project(':producer'))
}
tasks.register("resolveRuntimeClasspath", Copy) {// (5)
from(configurations.runtimeClasspath)
into(layout.buildDirectory.dir("runtimeClasspath"))
}-
将属性添加到架构中
-
所有 JAR 文件均未缩小
-
请求
minified=true所有可解析的配置 -
添加将要转换的依赖项
-
添加需要转换工件的任务
您现在可以看到当我们运行resolveRuntimeClasspath解析runtimeClasspath配置的任务时会发生什么。观察 Gradle 在任务开始之前转换项目依赖关系resolveRuntimeClasspath。 Gradle 在执行任务时会转换二进制依赖项resolveRuntimeClasspath。
> gradle resolveRuntimeClasspath > Task :producer:compileJava > Task :producer:processResources NO-SOURCE > Task :producer:classes > Task :producer:jar > Transform producer.jar (project :producer) with Minify Nothing to minify - using producer.jar unchanged > Task :resolveRuntimeClasspath Minifying guava-27.1-jre.jar Nothing to minify - using listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar unchanged Nothing to minify - using jsr305-3.0.2.jar unchanged Nothing to minify - using checker-qual-2.5.2.jar unchanged Nothing to minify - using error_prone_annotations-2.2.0.jar unchanged Nothing to minify - using j2objc-annotations-1.1.jar unchanged Nothing to minify - using animal-sniffer-annotations-1.17.jar unchanged Nothing to minify - using failureaccess-1.0.1.jar unchanged BUILD SUCCESSFUL in 0s 3 actionable tasks: 3 executed
实施工件转换
与任务类型类似,工件转换由操作和一些参数组成。与自定义任务类型的主要区别在于操作和参数是作为两个单独的类实现的。
工件转换操作的实现是一个实现TransformAction 的类。您需要transform()在操作上实现该方法,该方法将输入工件转换为零个、一个或多个输出工件。大多数工件转换都是一对一的,因此转换方法会将输入工件转换为恰好一个输出工件。
工件转换操作的实现需要通过调用 TransformOutputs.dir()或TransformOutputs.file()来注册每个输出工件。
您只能为dir或file方法提供两种类型的路径:
-
输入工件或输入工件中的绝对路径(对于输入目录)。
-
相对路径。
Gradle 使用绝对路径作为输出工件的位置。例如,如果输入工件是分解的 WAR,则转换操作可以调用目录TransformOutputs.file()中的所有 jar 文件WEB-INF/lib。转换的输出将是 Web 应用程序的库 JAR。
对于相对路径,dir()orfile()方法将工作空间返回给转换操作。转换操作的实现需要在提供的工作空间的位置创建转换后的工件。
输出工件按照注册顺序替换转换后的变体中的输入工件。例如,如果配置由工件lib1.jar、lib2.jar、组成lib3.jar,并且转换操作<artifact-name>-min.jar为输入工件注册了缩小的输出工件,则转换后的配置由工件lib1-min.jar、lib2-min.jar和组成lib3-min.jar。
下面是一个转换的实现Unzip,它通过解压缩 JAR 文件将其转换为类目录。该Unzip转换不需要任何参数。请注意实现如何使用@InputArtifact注入工件来转换为操作。它通过使用请求解压类的目录TransformOutputs.dir(),然后将 JAR 文件解压到该目录中。
abstract class Unzip : TransformAction<TransformParameters.None> { // (1)
@get:InputArtifact // (2)
abstract val inputArtifact: Provider<FileSystemLocation>
override
fun transform(outputs: TransformOutputs) {
val input = inputArtifact.get().asFile
val unzipDir = outputs.dir(input.name) // (3)
unzipTo(input, unzipDir) // (4)
}
private fun unzipTo(zipFile: File, unzipDir: File) {
// implementation...
}
}abstract class Unzip implements TransformAction<TransformParameters.None> { // (1)
@InputArtifact // (2)
abstract Provider<FileSystemLocation> getInputArtifact()
@Override
void transform(TransformOutputs outputs) {
def input = inputArtifact.get().asFile
def unzipDir = outputs.dir(input.name) // (3)
unzipTo(input, unzipDir) // (4)
}
private static void unzipTo(File zipFile, File unzipDir) {
// implementation...
}
}-
TransformParameters.None如果转换不使用参数则使用 -
注入输入工件
-
请求解压文件的输出位置
-
进行实际的转换工作
工件转换可能需要参数,例如String确定某些过滤器或用于支持输入工件的转换的某些文件集合。为了将这些参数传递给转换操作,您需要使用所需参数定义一个新类型。该类型需要实现标记接口TransformParameters。参数必须使用托管属性表示,并且参数类型必须是托管类型。您可以使用接口或抽象类来声明 getter,Gradle 将生成实现。所有 getter 都需要有适当的输入注释,请参阅增量构建注释表。
您可以在开发自定义 Gradle 类型中找到有关实现工件转换参数的更多信息。
下面是一个转换的实现Minify,它通过仅保留某些类来使 JAR 更小。转换Minify需要将类保留为参数。观察方法TransformAction.getParameters()中如何获取参数transform()。该方法的实现transform()通过使用请求缩小的 JAR 的位置TransformOutputs.file(),然后在该位置创建缩小的 JAR。
abstract class Minify : TransformAction<Minify.Parameters> { // (1)
interface Parameters : TransformParameters { // (2)
@get:Input
var keepClassesByArtifact: Map<String, Set<String>>
}
@get:PathSensitive(PathSensitivity.NAME_ONLY)
@get:InputArtifact
abstract val inputArtifact: Provider<FileSystemLocation>
override
fun transform(outputs: TransformOutputs) {
val fileName = inputArtifact.get().asFile.name
for (entry in parameters.keepClassesByArtifact) { // (3)
if (fileName.startsWith(entry.key)) {
val nameWithoutExtension = fileName.substring(0, fileName.length - 4)
minify(inputArtifact.get().asFile, entry.value, outputs.file("${nameWithoutExtension}-min.jar"))
return
}
}
println("Nothing to minify - using ${fileName} unchanged")
outputs.file(inputArtifact) // (4)
}
private fun minify(artifact: File, keepClasses: Set<String>, jarFile: File) {
println("Minifying ${artifact.name}")
// Implementation ...
}
}abstract class Minify implements TransformAction<Parameters> { // (1)
interface Parameters extends TransformParameters { // (2)
@Input
Map<String, Set<String>> getKeepClassesByArtifact()
void setKeepClassesByArtifact(Map<String, Set<String>> keepClasses)
}
@PathSensitive(PathSensitivity.NAME_ONLY)
@InputArtifact
abstract Provider<FileSystemLocation> getInputArtifact()
@Override
void transform(TransformOutputs outputs) {
def fileName = inputArtifact.get().asFile.name
for (entry in parameters.keepClassesByArtifact) { // (3)
if (fileName.startsWith(entry.key)) {
def nameWithoutExtension = fileName.substring(0, fileName.length() - 4)
minify(inputArtifact.get().asFile, entry.value, outputs.file("${nameWithoutExtension}-min.jar"))
return
}
}
println "Nothing to minify - using ${fileName} unchanged"
outputs.file(inputArtifact) // (4)
}
private void minify(File artifact, Set<String> keepClasses, File jarFile) {
println "Minifying ${artifact.name}"
// Implementation ...
}
}-
声明参数类型
-
变换参数的接口
-
使用参数
-
当不需要缩小时,使用未更改的输入工件
请记住,输入工件是一个依赖项,它可能有自己的依赖项。如果您的工件转换需要访问这些传递依赖项,它可以声明一个返回 a 的抽象 getter并使用@InputArtifactDependencyFileCollection对其进行注释。当您的转换运行时,Gradle 将通过实现 getter将传递依赖项注入到该属性中。请注意,在转换中使用输入工件依赖项会对性能产生影响,仅在真正需要时才注入它们。FileCollection
此外,工件转换可以利用构建缓存来输出。要为工件转换启用构建缓存,请在操作类上添加注释。对于可缓存的转换,您必须使用规范化注释(例如@PathSensitive)注释其@InputArtifact属性以及任何标有@InputArtifactDependency的属性。@CacheableTransform
以下示例显示了更复杂的转换。它将 JAR 的某些选定类移动到不同的包,重写移动类的字节码以及使用移动类的所有类(类重定位)。为了确定要重定位的类,它会查看输入工件的包以及输入工件的依赖项。它也不会重新定位外部类路径中 JAR 文件中包含的包。
@CacheableTransform // (1)
abstract class ClassRelocator : TransformAction<ClassRelocator.Parameters> {
interface Parameters : TransformParameters { // (2)
@get:CompileClasspath // (3)
val externalClasspath: ConfigurableFileCollection
@get:Input
val excludedPackage: Property<String>
}
@get:Classpath // (4)
@get:InputArtifact
abstract val primaryInput: Provider<FileSystemLocation>
@get:CompileClasspath
@get:InputArtifactDependencies // (5)
abstract val dependencies: FileCollection
override
fun transform(outputs: TransformOutputs) {
val primaryInputFile = primaryInput.get().asFile
if (parameters.externalClasspath.contains(primaryInputFile)) { // (6)
outputs.file(primaryInput)
} else {
val baseName = primaryInputFile.name.substring(0, primaryInputFile.name.length - 4)
relocateJar(outputs.file("$baseName-relocated.jar"))
}
}
private fun relocateJar(output: File) {
// implementation...
val relocatedPackages = (dependencies.flatMap { it.readPackages() } + primaryInput.get().asFile.readPackages()).toSet()
val nonRelocatedPackages = parameters.externalClasspath.flatMap { it.readPackages() }
val relocations = (relocatedPackages - nonRelocatedPackages).map { packageName ->
val toPackage = "relocated.$packageName"
println("$packageName -> $toPackage")
Relocation(packageName, toPackage)
}
JarRelocator(primaryInput.get().asFile, output, relocations).run()
}
}@CacheableTransform // (1)
abstract class ClassRelocator implements TransformAction<Parameters> {
interface Parameters extends TransformParameters { // (2)
@CompileClasspath // (3)
ConfigurableFileCollection getExternalClasspath()
@Input
Property<String> getExcludedPackage()
}
@Classpath // (4)
@InputArtifact
abstract Provider<FileSystemLocation> getPrimaryInput()
@CompileClasspath
@InputArtifactDependencies // (5)
abstract FileCollection getDependencies()
@Override
void transform(TransformOutputs outputs) {
def primaryInputFile = primaryInput.get().asFile
if (parameters.externalClasspath.contains(primaryInput)) { // (6)
outputs.file(primaryInput)
} else {
def baseName = primaryInputFile.name.substring(0, primaryInputFile.name.length - 4)
relocateJar(outputs.file("$baseName-relocated.jar"))
}
}
private relocateJar(File output) {
// implementation...
def relocatedPackages = (dependencies.collectMany { readPackages(it) } + readPackages(primaryInput.get().asFile)) as Set
def nonRelocatedPackages = parameters.externalClasspath.collectMany { readPackages(it) }
def relocations = (relocatedPackages - nonRelocatedPackages).collect { packageName ->
def toPackage = "relocated.$packageName"
println("$packageName -> $toPackage")
new Relocation(packageName, toPackage)
}
new JarRelocator(primaryInput.get().asFile, output, relocations).run()
}
}-
声明转换可缓存
-
变换参数的接口
-
声明每个参数的输入类型
-
声明输入工件的标准化
-
注入输入工件依赖项
-
使用参数
注册工件转换
您需要注册工件转换操作,并在必要时提供参数,以便在解析依赖项时可以选择它们。
为了注册工件转换,您必须在块内使用registerTransform()dependencies {}。
使用时有几点需要注意registerTransform():
-
from和属性to是必需的。 -
转换操作本身可以有配置选项。您可以使用
parameters {}块来配置它们。 -
您必须在具有要解析的配置的项目上注册转换。
-
您可以向该方法提供任何实现TransformAction 的
registerTransform()类型。
例如,假设您想要解压一些依赖项并将解压后的目录和文件放在类路径上。您可以通过注册类型为 的工件转换操作来实现此目的Unzip,如下所示:
val artifactType = Attribute.of("artifactType", String::class.java)
dependencies {
registerTransform(Unzip::class) {
from.attribute(artifactType, "jar")
to.attribute(artifactType, "java-classes-directory")
}
}def artifactType = Attribute.of('artifactType', String)
dependencies {
registerTransform(Unzip) {
from.attribute(artifactType, 'jar')
to.attribute(artifactType, 'java-classes-directory')
}
}另一个例子是,您希望通过仅保留classJAR 中的一些文件来缩小 JAR 大小。请注意使用该parameters {}块来提供要保留在转换的缩小 JAR 中的类Minify。
val artifactType = Attribute.of("artifactType", String::class.java)
val minified = Attribute.of("minified", Boolean::class.javaObjectType)
val keepPatterns = mapOf(
"guava" to setOf(
"com.google.common.base.Optional",
"com.google.common.base.AbstractIterator"
)
)
dependencies {
registerTransform(Minify::class) {
from.attribute(minified, false).attribute(artifactType, "jar")
to.attribute(minified, true).attribute(artifactType, "jar")
parameters {
keepClassesByArtifact = keepPatterns
}
}
}def artifactType = Attribute.of('artifactType', String)
def minified = Attribute.of('minified', Boolean)
def keepPatterns = [
"guava": [
"com.google.common.base.Optional",
"com.google.common.base.AbstractIterator"
] as Set
]
dependencies {
registerTransform(Minify) {
from.attribute(minified, false).attribute(artifactType, "jar")
to.attribute(minified, true).attribute(artifactType, "jar")
parameters {
keepClassesByArtifact = keepPatterns
}
}
}实施增量工件转换
与增量任务类似,工件转换可以通过仅处理上次执行中更改的文件来避免工作。这是通过使用InputChanges接口来完成的。对于工件转换,只有输入工件是增量输入,因此转换只能查询其中的更改。为了在转换操作中使用InputChanges,请将其注入到操作中。有关如何使用InputChanges 的更多信息,请参阅增量任务的相应文档。
下面是一个增量转换的示例,用于计算 Java 源文件中的代码行数:
abstract class CountLoc : TransformAction<TransformParameters.None> {
@get:Inject // (1)
abstract val inputChanges: InputChanges
@get:PathSensitive(PathSensitivity.RELATIVE)
@get:InputArtifact
abstract val input: Provider<FileSystemLocation>
override
fun transform(outputs: TransformOutputs) {
val outputDir = outputs.dir("${input.get().asFile.name}.loc")
println("Running transform on ${input.get().asFile.name}, incremental: ${inputChanges.isIncremental}")
inputChanges.getFileChanges(input).forEach { change -> // (2)
val changedFile = change.file
if (change.fileType != FileType.FILE) {
return@forEach
}
val outputLocation = outputDir.resolve("${change.normalizedPath}.loc")
when (change.changeType) {
ChangeType.ADDED, ChangeType.MODIFIED -> {
println("Processing file ${changedFile.name}")
outputLocation.parentFile.mkdirs()
outputLocation.writeText(changedFile.readLines().size.toString())
}
ChangeType.REMOVED -> {
println("Removing leftover output file ${outputLocation.name}")
outputLocation.delete()
}
}
}
}
}abstract class CountLoc implements TransformAction<TransformParameters.None> {
@Inject // (1)
abstract InputChanges getInputChanges()
@PathSensitive(PathSensitivity.RELATIVE)
@InputArtifact
abstract Provider<FileSystemLocation> getInput()
@Override
void transform(TransformOutputs outputs) {
def outputDir = outputs.dir("${input.get().asFile.name}.loc")
println("Running transform on ${input.get().asFile.name}, incremental: ${inputChanges.incremental}")
inputChanges.getFileChanges(input).forEach { change -> // (2)
def changedFile = change.file
if (change.fileType != FileType.FILE) {
return
}
def outputLocation = new File(outputDir, "${change.normalizedPath}.loc")
switch (change.changeType) {
case ADDED:
case MODIFIED:
println("Processing file ${changedFile.name}")
outputLocation.parentFile.mkdirs()
outputLocation.text = changedFile.readLines().size()
case REMOVED:
println("Removing leftover output file ${outputLocation.name}")
outputLocation.delete()
}
}
}
}-
注入
InputChanges -
查询输入工件的更改
出版图书馆
将项目发布为模块
绝大多数软件项目构建的东西旨在以某种方式被使用。它可以是其他软件项目使用的库,也可以是最终用户的应用程序。 发布是将正在构建的东西提供给消费者的过程。
在 Gradle 中,该过程如下所示:
其中每个步骤都取决于您要将工件发布到的存储库的类型。最常见的两种类型是 Maven 兼容和 Ivy 兼容存储库,简称 Maven 和 Ivy 存储库。
从 Gradle 6.0 开始,Gradle 模块元数据将始终与 Ivy XML 或 Maven POM 元数据文件一起发布。
Gradle 通过以Maven Publish Plugin和Ivy Publish Plugin的形式提供一些预打包的基础设施,使发布到这些类型的存储库变得容易。这些插件允许您配置要发布的内容并以最少的努力执行发布。

让我们更详细地看看这些步骤:
- 发布什么
-
Gradle 需要知道要发布哪些文件和信息,以便消费者可以使用您的项目。这通常是工件和元数据的组合,Gradle 称之为发布。出版物所包含的具体内容取决于其发布到的存储库的类型。
例如,发往 Maven 存储库的出版物包括:
-
一个或多个工件——通常由项目构建,
-
Gradle 模块元数据文件将描述已发布组件的变体,
-
Maven POM 文件将识别主要工件及其依赖项。主要工件通常是项目的生产 JAR,次要工件可能由“-sources”和“-javadoc”JAR 组成。
此外,Gradle 将发布上述所有内容的校验和,以及配置后的签名。从 Gradle 6.0 开始,这包括校验
SHA256和。SHA512 -
- 发布地点
-
Gradle 需要知道在哪里发布工件,以便消费者可以获取它们。这是通过存储库完成的,存储库存储并提供各种工件。 Gradle 还需要与存储库交互,这就是为什么您必须提供存储库的类型及其位置。
- 如何发布
-
Gradle 自动为发布和存储库的所有可能组合生成发布任务,允许您将任何工件发布到任何存储库。如果您要发布到 Maven 存储库,则任务的类型为PublishToMavenRepository,而对于 Ivy 存储库,任务的类型为PublishToIvyRepository。
下面通过一个实际例子来演示整个发布过程。
设置基本发布
无论您的项目类型如何,发布的第一步都是应用适当的发布插件。正如简介中提到的,Gradle 通过以下插件支持 Maven 和 Ivy 存储库:
它们提供了配置相应存储库类型的发布所需的特定发布和存储库类。由于 Maven 存储库是最常用的存储库,因此它们将成为本示例以及本章中其他示例的基础。别担心,我们将解释如何调整 Ivy 存储库的单个样本。
假设我们正在处理一个简单的 Java 库项目,因此仅应用以下插件:
plugins {
`java-library`
`maven-publish`
}plugins {
id 'java-library'
id 'maven-publish'
}应用适当的插件后,您可以配置出版物和存储库。对于此示例,我们希望将项目的生产 JAR 文件(任务生成的文件jar)发布到自定义 Maven 存储库。我们使用以下块来实现这一点,该块由PublishingExtensionpublishing {}支持:
group = "org.example"
version = "1.0"
publishing {
publications {
create<MavenPublication>("myLibrary") {
from(components["java"])
}
}
repositories {
maven {
name = "myRepo"
url = uri(layout.buildDirectory.dir("repo"))
}
}
}group = 'org.example'
version = '1.0'
publishing {
publications {
myLibrary(MavenPublication) {
from components.java
}
}
repositories {
maven {
name = 'myRepo'
url = layout.buildDirectory.dir("repo")
}
}
}这定义了一个名为“myLibrary”的发布,可以通过其类型MavenPublication发布到 Maven 存储库。该出版物仅包含生产 JAR 工件及其元数据,它们组合起来由项目的java 组件表示。
|
笔记
|
组件是定义出版物的标准方式。它们由插件提供,通常是不同语言或平台的插件。例如,Java Plugin 定义components.java SoftwareComponent,而 War Plugin 定义components.web.
|
该示例还定义了一个名为“myRepo”的基于文件的 Maven 存储库。这种基于文件的存储库对于示例来说很方便,但实际构建通常使用基于 HTTPS 的存储库服务器,例如 Maven Central 或内部公司服务器。
|
笔记
|
您可以定义一个且仅一个没有名称的存储库。这将转换为 Maven 存储库的隐式名称“Maven”和 Ivy 存储库的隐式名称“Ivy”。所有其他存储库定义必须给出明确的名称。 |
与项目的group和相结合version,发布和存储库定义提供了 Gradle 发布项目的生产 JAR 所需的一切。然后 Gradle 将创建一个专用publishMyLibraryPublicationToMyRepoRepository任务来完成此任务。它的名称是基于模板的。有关此任务的性质以及您可能可以使用的任何其他任务的更多详细信息,请参阅相应的发布插件的文档。publishPubNamePublicationToRepoNameRepository
您可以直接执行各个发布任务,也可以执行publish,这将运行所有可用的发布任务。在此示例中,publish将仅运行publishMyLibraryPublicationToMavenRepository.
|
笔记
|
到 Ivy 存储库的基本发布非常相似:您只需使用 Ivy 发布插件,替换 这两种类型的存储库之间存在差异,特别是在每种存储库支持的额外元数据方面 - 例如,Maven 存储库需要 POM 文件,而 Ivy 存储库有自己的元数据格式 - 因此,请参阅插件章节以获取有关如何配置这两种存储库的全面信息适用于您正在使用的任何存储库类型的出版物和存储库。 |
这就是基本用例的全部内容。但是,许多项目需要对发布的内容进行更多控制,因此我们将在以下部分中介绍几种常见场景。
抑制验证错误
Gradle 对生成的模块元数据执行验证。在某些情况下,验证可能会失败,这表明您很可能有一个错误需要修复,但您可能故意做了一些事情。如果是这种情况,Gradle 将指示您可以在任务上禁用的验证错误的名称GenerateModuleMetadata:
tasks.withType<GenerateModuleMetadata> {
// The value 'enforced-platform' is provided in the validation
// error message you got
suppressedValidationErrors.add("enforced-platform")
}tasks.withType(GenerateModuleMetadata).configureEach {
// The value 'enforced-platform' is provided in the validation
// error message you got
suppressedValidationErrors.add('enforced-platform')
}了解 Gradle 模块元数据
Gradle 模块元数据是一种用于序列化 Gradle 组件模型的格式。它类似于Apache Maven™ 的 POM 文件或Apache Ivy™ ivy.xml文件。元数据文件的目标是向消费者提供存储库上发布内容的合理模型。
Gradle 模块元数据是一种独特的格式,旨在通过使其具有多平台和变体感知能力来改进依赖关系解析。
特别是,Gradle 模块元数据支持:
Gradle 模块元数据的发布将为您的消费者提供更好的依赖管理:
-
通过检测不兼容的模块及早发现问题
-
一致选择特定于平台的依赖项
-
本机依赖版本对齐
-
自动获取库特定功能的依赖项
使用Maven Publish 插件或Ivy Publish 插件时,Gradle 模块元数据会自动发布。
Gradle 模块元数据的规范可以在这里找到。
与其他格式的映射
Gradle 模块元数据自动发布在 Maven 或 Ivy 存储库上。但是,它不会替换pom.xml或ivy.xml文件:它与这些文件一起发布。这样做是为了最大限度地提高与第三方构建工具的兼容性。
Gradle 尽力将 Gradle 特定的概念映射到 Maven 或 Ivy。当构建文件使用只能在 Gradle 模块元数据中表示的功能时,Gradle 将在发布时向您发出警告。下表总结了一些 Gradle 特定功能如何映射到 Maven 和 Ivy:
| 摇篮 | 梅文 | 常春藤 | 描述 |
|---|---|---|---|
|
未发表 |
Gradle 依赖约束是可传递的,而 Maven 的依赖管理块则不是 |
|
发布所需版本 |
发布了需要的版本 |
||
未发表 |
未发表 |
组件功能是 Gradle 独有的 |
|
上传变体工件,将依赖项发布为可选依赖项 |
变体工件已上传,依赖项未发布 |
功能变体是可选依赖项的良好替代品 |
|
工件已上传,依赖项是映射所描述的依赖项 |
工件已上传,依赖项被忽略 |
无论如何,自定义组件类型可能无法从 Maven 或 Ivy 中使用。它们通常存在于自定义生态系统的背景下。 |
禁用元数据兼容性发布警告
如果您想抑制警告,可以使用以下 API 来实现:
-
对于Maven,请参阅MavenPublication
suppress*中的方法 -
对于Ivy,请参阅IvyPublication
suppress*中的方法
publications {
register<MavenPublication>("maven") {
from(components["java"])
suppressPomMetadataWarningsFor("runtimeElements")
}
}publications {
maven(MavenPublication) {
from components.java
suppressPomMetadataWarningsFor('runtimeElements')
}
}与其他构建工具的交互
由于 Gradle 模块元数据并未广泛传播,并且它旨在最大限度地提高与其他工具的兼容性,因此 Gradle 做了几件事:
-
Gradle 模块元数据与给定存储库(Maven 或 Ivy)的正常描述符一起系统地发布
-
pom.xml或文件ivy.xml将包含一个标记注释,告诉 Gradle 该模块存在 Gradle 模块元数据
标记的目标不是让其他工具解析模块元数据:它仅适用于 Gradle 用户。它向 Gradle 解释说存在更好的模块元数据文件,并且应该使用它。这并不意味着 Maven 或 Ivy 的消耗也会被破坏,只是它在降级模式下工作。
|
笔记
|
这必须被视为一种性能优化:Gradle 将首先查看最重要的文件,而不是必须执行 2 个网络请求,一个获取 Gradle 模块元数据,然后一个获取 POM/Ivy 文件,以防丢失。可能存在,那么如果该模块实际上是使用 Gradle 模块元数据发布的,则仅执行第二个请求。 |
如果您知道您依赖的模块始终使用 Gradle 模块元数据发布,则可以通过配置存储库的元数据源来优化网络调用:
repositories {
maven {
setUrl("http://repo.mycompany.com/repo")
metadataSources {
gradleMetadata()
}
}
}repositories {
maven {
url "http://repo.mycompany.com/repo"
metadataSources {
gradleMetadata()
}
}
}Gradle 模块元数据验证
Gradle 模块元数据在发布之前经过验证。
执行以下规则:
-
变体名称必须是唯一的,
-
每个变体必须至少有一个属性,
-
两个变体不可能具有完全相同的属性和功能,
-
如果存在依赖关系,则所有变体中至少有一个必须携带版本信息。
这些规则确保了生成的元数据的质量,并有助于确认消费不会出现问题。
Gradle 模块元数据再现性
UP-TO-DATE由于其实现方式,生成模块元数据文件的任务目前从未被 Gradle 标记。但是,如果构建输入和构建脚本均未更改,则任务结果实际上是最新的:它始终生成相同的输出。
如果用户希望module每次构建调用都有一个唯一的文件,则可以将生成的元数据中的标识符链接到创建它的构建。用户可以选择在其以下位置启用此唯一标识符publication:
publishing {
publications {
create<MavenPublication>("myLibrary") {
from(components["java"])
withBuildIdentifier()
}
}
}publishing {
publications {
myLibrary(MavenPublication) {
from components.java
withBuildIdentifier()
}
}
}通过上述更改,生成的 Gradle 模块元数据文件将始终不同,迫使下游任务认为它已过时。
禁用 Gradle 模块元数据发布
在某些情况下,您可能希望禁用 Gradle 模块元数据的发布:
-
您上传到的存储库拒绝元数据文件(未知格式)
-
您正在使用 Maven 或 Ivy 特定概念,这些概念未正确映射到 Gradle 模块元数据
在这种情况下,只需禁用生成元数据文件的任务即可禁用 Gradle 模块元数据的发布:
tasks.withType<GenerateModuleMetadata> {
enabled = false
}tasks.withType(GenerateModuleMetadata) {
enabled = false
}签名工件
签名插件可用于对构成发布的所有工件和元数据文件进行签名,包括 Maven POM 文件和 Ivy 模块描述符。为了使用它:
-
应用签名插件
-
配置签名者凭据- 点击链接查看如何操作
-
指定您想要签署的出版物
以下是配置插件以签署mavenJava发布的示例:
signing {
sign(publishing.publications["mavenJava"])
}signing {
sign publishing.publications.mavenJava
}这将为Sign您指定的每个发布创建一个任务,并将所有任务都依赖于它。因此,发布任何出版物都会自动创建并发布其工件和元数据的签名,正如您从以下输出中看到的:publishPubNamePublicationToRepoNameRepository
示例:签署并发布项目
gradle publish> gradle publish > Task :compileJava > Task :processResources > Task :classes > Task :jar > Task :javadoc > Task :javadocJar > Task :sourcesJar > Task :generateMetadataFileForMavenJavaPublication > Task :generatePomFileForMavenJavaPublication > Task :signMavenJavaPublication > Task :publishMavenJavaPublicationToMavenRepository > Task :publish BUILD SUCCESSFUL in 0s 10 actionable tasks: 10 executed
定制发布
修改现有组件并添加变体以进行发布
Gradle 的发布模型基于组件的概念,组件由插件定义。例如,Java Library 插件定义了一个java对应于库的组件,但是 Java Platform 插件定义了另一种组件,名为javaPlatform,它实际上是一种不同类型的软件组件(平台)。
有时我们想要添加更多变体或修改现有组件的现有变体。例如,如果您为不同的平台添加了 Java 库的变体,您可能只想在java组件本身上声明此附加变体。一般来说,声明附加变体通常是发布附加工件的最佳解决方案。
为了执行此类添加或修改,该AdhocComponentWithVariants接口声明了两个被调用的方法addVariantsFromConfiguration,并且withVariantsFromConfiguration它们接受两个参数:
-
用作变体源的传出配置
-
自定义操作,允许您过滤要发布的变体
要利用这些方法,您必须确保SoftwareComponent您使用的 本身就是一个AdhocComponentWithVariants,对于由 Java 插件(Java、Java 库、Java 平台)创建的组件来说就是这种情况。添加变体非常简单:
val javaComponent = components.findByName("java") as AdhocComponentWithVariants
javaComponent.addVariantsFromConfiguration(outgoing) {
// dependencies for this variant are considered runtime dependencies
mapToMavenScope("runtime")
// and also optional dependencies, because we don't want them to leak
mapToOptional()
}AdhocComponentWithVariants javaComponent = (AdhocComponentWithVariants) project.components.findByName("java")
javaComponent.addVariantsFromConfiguration(outgoing) {
// dependencies for this variant are considered runtime dependencies
it.mapToMavenScope("runtime")
// and also optional dependencies, because we don't want them to leak
it.mapToOptional()
}在其他情况下,您可能想要修改已由某个 Java 插件添加的变体。例如,如果您激活 Javadoc 和源代码的发布,它们将成为该java组件的其他变体。如果您只想发布其中之一,例如只发布Javadoc而不发布源代码,则可以将sources变体修改为不发布:
java {
withJavadocJar()
withSourcesJar()
}
val javaComponent = components["java"] as AdhocComponentWithVariants
javaComponent.withVariantsFromConfiguration(configurations["sourcesElements"]) {
skip()
}
publishing {
publications {
create<MavenPublication>("mavenJava") {
from(components["java"])
}
}
}java {
withJavadocJar()
withSourcesJar()
}
components.java.withVariantsFromConfiguration(configurations.sourcesElements) {
skip()
}
publishing {
publications {
mavenJava(MavenPublication) {
from components.java
}
}
}创建和发布自定义组件
在前面的示例中,我们演示了如何扩展或修改现有组件,例如 Java 插件提供的组件。但是 Gradle 还允许您构建自定义组件(不是 Java 库,不是 Java 平台,也不是 Gradle 原生支持的东西)。
要创建自定义组件,您首先需要创建一个空的临时组件。目前,这只能通过插件实现,因为您需要获取 SoftwareComponentFactory 的句柄:
class InstrumentedJarsPlugin @Inject constructor(
private val softwareComponentFactory: SoftwareComponentFactory) : Plugin<Project> {private final SoftwareComponentFactory softwareComponentFactory
@Inject
InstrumentedJarsPlugin(SoftwareComponentFactory softwareComponentFactory) {
this.softwareComponentFactory = softwareComponentFactory
}声明自定义组件发布的内容仍然是通过AdhocComponentWithVariants API 完成的。对于自定义组件,第一步是按照本章中的说明创建自定义传出变体。在此阶段,您应该拥有的是可在跨项目依赖项中使用的变体,但我们现在将其发布到外部存储库。
// create an adhoc component
val adhocComponent = softwareComponentFactory.adhoc("myAdhocComponent")
// add it to the list of components that this project declares
components.add(adhocComponent)
// and register a variant for publication
adhocComponent.addVariantsFromConfiguration(outgoing) {
mapToMavenScope("runtime")
}// create an adhoc component
def adhocComponent = softwareComponentFactory.adhoc("myAdhocComponent")
// add it to the list of components that this project declares
project.components.add(adhocComponent)
// and register a variant for publication
adhocComponent.addVariantsFromConfiguration(outgoing) {
it.mapToMavenScope("runtime")
}首先,我们使用工厂创建一个新的临时组件。然后我们通过该方法添加一个变体,这在上一节addVariantsFromConfiguration中有更详细的描述。
在简单的情况下,a 和变体之间存在一对一的映射Configuration,在这种情况下,您可以发布从单个版本发出的所有变体,Configuration因为它们实际上是相同的东西。但是,在某些情况下,a与其他配置发布Configuration相关联,我们也将其称为次要变体。此类配置在跨项目发布用例中有意义,但在外部发布时则不然。例如,在项目之间共享文件目录,但无法直接在 Maven 存储库上发布目录(只能打包诸如 jar 或 zip 之类的东西)时,就会出现这种情况。有关如何跳过特定变体发布的详细信息,请参阅ConfigurationVariantDetails类。如果已经调用了配置,则可以使用 执行对结果变体的进一步修改。addVariantsFromConfigurationwithVariantsFromConfiguration
当发布这样的临时组件时:
-
Gradle 模块元数据将准确代表已发布的变体。特别是,所有传出变体都将继承已发布配置的依赖项、工件和属性。
-
将生成 Maven 和 Ivy 元数据文件,但您需要声明如何通过ConfigurationVariantDetails类将依赖项映射到 Maven 范围。
实际上,这意味着以这种方式创建的组件可以被 Gradle 使用,就像它们是“本地组件”一样。
将自定义工件添加到出版物中
您应该拥抱 Gradle 的变体感知模型,而不是考虑工件。预计单个模块可能需要多个工件。然而,这很少就此停止,如果附加工件代表可选功能,它们也可能具有不同的依赖关系等等。
Gradle 通过Gradle Module Metadata支持发布其他变体,使依赖解析引擎了解这些工件。请参阅文档的变体感知共享部分,了解如何声明此类变体并查看如何发布自定义组件。
如果您将额外的工件直接附加到出版物中,它们将“断章取义”地发布。这意味着,它们根本不在元数据中引用,只能通过依赖项上的分类器直接寻址。与 Gradle 模块元数据相比,Maven pom 元数据不会包含有关其他工件的信息,无论它们是通过变体还是直接添加,因为变体无法以 pom 格式表示。
如果您确定元数据(例如 Gradle 或 POM 元数据)与您的用例无关,以下部分将介绍如何直接发布工件。例如,如果您的项目不需要被其他项目使用,并且发布结果所需的唯一内容就是工件本身。
一般来说,有两种选择:
要创建基于工件的发布,请首先定义自定义工件并将其附加到您选择的Gradle配置。以下示例定义了由rpm任务(未显示)生成的 RPM 工件,并将该工件附加到conf配置:
configurations {
create("conf")
}
val rpmFile = layout.buildDirectory.file("rpms/my-package.rpm")
val rpmArtifact = artifacts.add("conf", rpmFile.get().asFile) {
type = "rpm"
builtBy("rpm")
}configurations {
conf
}
def rpmFile = layout.buildDirectory.file('rpms/my-package.rpm')
def rpmArtifact = artifacts.add('conf', rpmFile.get().asFile) {
type 'rpm'
builtBy 'rpm'
}该artifacts.add()方法(来自ArtifactHandler )返回PublishArtifact类型的工件对象,然后可将其用于定义发布,如以下示例所示:
publishing {
publications {
create<MavenPublication>("maven") {
artifact(rpmArtifact)
}
}
}publishing {
publications {
maven(MavenPublication) {
artifact rpmArtifact
}
}
}-
该
artifact()方法接受发布工件作为参数(如rpmArtifact示例中所示)以及Project.file(java.lang.Object)接受的任何类型的参数,例如File实例、字符串文件路径或存档任务。 -
发布插件支持不同的工件配置属性,因此请务必检查插件文档以获取更多详细信息。Maven Publish Plugin和Ivy Publish Plugin均支持
classifier和属性。extension -
自定义工件需要在出版物中有所不同,通常通过
classifier和的独特组合extension。请参阅您正在使用的插件的文档以了解确切的要求。 -
如果您
artifact()与归档任务一起使用,Gradle 会自动使用该任务中的classifier和extension属性填充工件的元数据。
现在您可以发布 RPM。
如果您确实想向基于组件的出版物添加工件,则可以组合和符号,而不是调整组件本身。from components.someComponentartifact someArtifact
将出版物限制到特定存储库
当您定义了多个发布或存储库时,您通常希望控制哪些发布发布到哪些存储库。例如,考虑以下示例,它定义了两个出版物(一个仅包含二进制文件,另一个包含二进制文件和相关源)以及两个存储库(一个供内部使用,一个供外部使用者使用):
publishing {
publications {
create<MavenPublication>("binary") {
from(components["java"])
}
create<MavenPublication>("binaryAndSources") {
from(components["java"])
artifact(tasks["sourcesJar"])
}
}
repositories {
// change URLs to point to your repos, e.g. http://my.org/repo
maven {
name = "external"
url = uri(layout.buildDirectory.dir("repos/external"))
}
maven {
name = "internal"
url = uri(layout.buildDirectory.dir("repos/internal"))
}
}
}publishing {
publications {
binary(MavenPublication) {
from components.java
}
binaryAndSources(MavenPublication) {
from components.java
artifact sourcesJar
}
}
repositories {
// change URLs to point to your repos, e.g. http://my.org/repo
maven {
name = 'external'
url = layout.buildDirectory.dir('repos/external')
}
maven {
name = 'internal'
url = layout.buildDirectory.dir('repos/internal')
}
}
}发布插件将创建任务,允许您将任一出版物发布到任一存储库。他们还将这些任务附加到publish聚合任务中。但是,假设您希望将仅二进制发布限制为外部存储库,将带有源的二进制发布限制为内部存储库。为此,您需要将发布设为有条件的。
Gradle 允许您通过Task.onlyIf(String, org.gradle.api.specs.Spec)方法根据条件跳过任何您想要的任务。下面的示例演示了如何实现我们刚才提到的约束:
tasks.withType<PublishToMavenRepository>().configureEach {
val predicate = provider {
(repository == publishing.repositories["external"] &&
publication == publishing.publications["binary"]) ||
(repository == publishing.repositories["internal"] &&
publication == publishing.publications["binaryAndSources"])
}
onlyIf("publishing binary to the external repository, or binary and sources to the internal one") {
predicate.get()
}
}
tasks.withType<PublishToMavenLocal>().configureEach {
val predicate = provider {
publication == publishing.publications["binaryAndSources"]
}
onlyIf("publishing binary and sources") {
predicate.get()
}
}tasks.withType(PublishToMavenRepository) {
def predicate = provider {
(repository == publishing.repositories.external &&
publication == publishing.publications.binary) ||
(repository == publishing.repositories.internal &&
publication == publishing.publications.binaryAndSources)
}
onlyIf("publishing binary to the external repository, or binary and sources to the internal one") {
predicate.get()
}
}
tasks.withType(PublishToMavenLocal) {
def predicate = provider {
publication == publishing.publications.binaryAndSources
}
onlyIf("publishing binary and sources") {
predicate.get()
}
}gradle publish> gradle publish > Task :compileJava > Task :processResources > Task :classes > Task :jar > Task :generateMetadataFileForBinaryAndSourcesPublication > Task :generatePomFileForBinaryAndSourcesPublication > Task :sourcesJar > Task :publishBinaryAndSourcesPublicationToExternalRepository SKIPPED > Task :publishBinaryAndSourcesPublicationToInternalRepository > Task :generateMetadataFileForBinaryPublication > Task :generatePomFileForBinaryPublication > Task :publishBinaryPublicationToExternalRepository > Task :publishBinaryPublicationToInternalRepository SKIPPED > Task :publish BUILD SUCCESSFUL in 0s 10 actionable tasks: 10 executed
您可能还想定义自己的聚合任务来帮助您的工作流程。例如,假设您有多个应发布到外部存储库的出版物。一次性发布所有内容而不发布内部内容可能非常有用。
以下示例演示了如何通过定义聚合任务来实现此目的 - publishToExternalRepository该任务取决于所有相关的发布任务:
tasks.register("publishToExternalRepository") {
group = "publishing"
description = "Publishes all Maven publications to the external Maven repository."
dependsOn(tasks.withType<PublishToMavenRepository>().matching {
it.repository == publishing.repositories["external"]
})
}tasks.register('publishToExternalRepository') {
group = 'publishing'
description = 'Publishes all Maven publications to the external Maven repository.'
dependsOn tasks.withType(PublishToMavenRepository).matching {
it.repository == publishing.repositories.external
}
}此特定示例通过将TaskCollection.withType(java.lang.Class)与PublishToMavenRepository任务类型结合使用,自动处理相关发布任务的引入或删除。如果您要发布到 Ivy 兼容的存储库,您可以对PublishToIvyRepository执行相同的操作。
配置发布任务
发布插件在评估项目后创建其非聚合任务,这意味着您无法直接从构建脚本引用它们。如果您想配置任何这些任务,您应该使用延迟任务配置。这可以通过项目的tasks集合以多种方式完成。
例如,假设您想要更改任务写入 POM 文件的位置。您可以使用TaskCollection.withType(java.lang.Class)方法来执行此操作,如以下示例所示:generatePomFileForPubNamePublication
tasks.withType<GenerateMavenPom>().configureEach {
val matcher = Regex("""generatePomFileFor(\w+)Publication""").matchEntire(name)
val publicationName = matcher?.let { it.groupValues[1] }
destination = layout.buildDirectory.file("poms/${publicationName}-pom.xml").get().asFile
}tasks.withType(GenerateMavenPom).all {
def matcher = name =~ /generatePomFileFor(\w+)Publication/
def publicationName = matcher[0][1]
destination = layout.buildDirectory.file("poms/${publicationName}-pom.xml").get().asFile
}上面的示例使用正则表达式从任务名称中提取发布的名称。这样可以避免可能生成的所有 POM 文件的文件路径之间发生冲突。如果您只有一份出版物,那么您不必担心此类冲突,因为只有一个 POM 文件。
Maven 发布插件
Maven 发布插件提供了将构建工件发布到Apache Maven存储库的功能。发布到 Maven 存储库的模块可以由 Maven、Gradle(请参阅声明依赖项)和其他理解 Maven 存储库格式的工具使用。您可以在发布概述中了解发布的基础知识。
用法
要使用 Maven 发布插件,请在构建脚本中包含以下内容:
plugins {
`maven-publish`
}plugins {
id 'maven-publish'
}Maven 发布插件在名为PublishingExtensionpublishing类型的项目上使用扩展。此扩展提供了命名出版物的容器和命名存储库的容器。 Maven 发布插件可与MavenPublication发布和MavenArtifactRepository存储库配合使用。
任务
generatePomFileForPubNamePublication—生成MavenPom-
为名为PubName 的发布创建一个 POM 文件,填充已知的元数据,例如项目名称、项目版本和依赖项。 POM 文件的默认位置是build/publications/$pubName/pom-default.xml。
publishPubNamePublicationToRepoNameRepository— PublishToMavenRepository-
将PubName发布发布到名为RepoName 的存储库。如果您的存储库定义没有显式名称,则 RepoName将为“Maven”。
publishPubNamePublicationToMavenLocal— PublishToMavenLocal-
将PubName发布连同发布的 POM 文件和其他元数据复制到本地 Maven 缓存(通常为<当前用户的主目录>/.m2/repository )。
publish-
取决于:所有任务
publishPubNamePublicationToRepoNameRepository将所有定义的发布发布到所有定义的存储库的聚合任务。它不包括将发布复制到本地 Maven 缓存。
publishToMavenLocal-
取决于:所有任务
publishPubNamePublicationToMavenLocal将所有定义的发布复制到本地 Maven 缓存,包括其元数据(POM 文件等)。
刊物
该插件提供MavenPublication类型的发布。要了解如何定义和使用发布,请参阅基本发布部分。
您可以在 Maven 发布中配置四项主要内容:
-
一个组件——通过MavenPublication.from(org.gradle.api.component.SoftwareComponent)。
-
自定义工件- 通过MavenPublication.artifact(java.lang.Object)方法。有关自定义 Maven 工件的可用配置选项,请参阅MavenArtifact 。
-
标准元数据,如
artifactId、groupId和version。 -
POM 文件的其他内容 — 通过MavenPublication.pom(org.gradle.api.Action)。
您可以在完整的发布示例中看到所有这些操作。 API 文档MavenPublication有额外的代码示例。
生成的 POM 中的标识值
生成的 POM 文件的属性将包含从以下项目属性派生的标识值:
-
groupId-项目.getGroup() -
artifactId-项目.getName() -
version-项目.getVersion()
覆盖默认标识值很简单:只需在配置MavenPublicationgroupId时指定,artifactId或属性即可。version
publishing {
publications {
create<MavenPublication>("maven") {
groupId = "org.gradle.sample"
artifactId = "library"
version = "1.1"
from(components["java"])
}
}
}publishing {
publications {
maven(MavenPublication) {
groupId = 'org.gradle.sample'
artifactId = 'library'
version = '1.1'
from components.java
}
}
}|
提示
|
某些存储库将无法处理所有支持的字符。例如,:在发布到 Windows 上文件系统支持的存储库时,该字符不能用作标识符。
|
Maven 将groupId和限制artifactId为有限的字符集 ( [A-Za-z0-9_\\-.]+),而 Gradle 强制执行此限制。对于version(以及工件extension和classifier属性),Gradle 将处理任何有效的 Unicode 字符。
唯一明确禁止的 Unicode 值是\,/和任何 ISO 控制字符。提供的值在发布之初就经过验证。
自定义生成的 POM
生成的POM文件可以在发布前进行定制。例如,将库发布到 Maven Central 时,您需要设置某些元数据。 Maven Publish Plugin 为此提供了 DSL。请参阅DSL 参考中的MavenPom ,获取可用属性和方法的完整文档。以下示例展示了如何使用最常见的示例:
publishing {
publications {
create<MavenPublication>("mavenJava") {
pom {
name = "My Library"
description = "A concise description of my library"
url = "http://www.example.com/library"
properties = mapOf(
"myProp" to "value",
"prop.with.dots" to "anotherValue"
)
licenses {
license {
name = "The Apache License, Version 2.0"
url = "http://www.apache.org/licenses/LICENSE-2.0.txt"
}
}
developers {
developer {
id = "johnd"
name = "John Doe"
email = "john.doe@example.com"
}
}
scm {
connection = "scm:git:git://example.com/my-library.git"
developerConnection = "scm:git:ssh://example.com/my-library.git"
url = "http://example.com/my-library/"
}
}
}
}
}publishing {
publications {
mavenJava(MavenPublication) {
pom {
name = 'My Library'
description = 'A concise description of my library'
url = 'http://www.example.com/library'
properties = [
myProp: "value",
"prop.with.dots": "anotherValue"
]
licenses {
license {
name = 'The Apache License, Version 2.0'
url = 'http://www.apache.org/licenses/LICENSE-2.0.txt'
}
}
developers {
developer {
id = 'johnd'
name = 'John Doe'
email = 'john.doe@example.com'
}
}
scm {
connection = 'scm:git:git://example.com/my-library.git'
developerConnection = 'scm:git:ssh://example.com/my-library.git'
url = 'http://example.com/my-library/'
}
}
}
}
}自定义依赖版本
支持两种发布依赖关系的策略:
- 声明的版本(默认)
-
此策略发布由构建脚本作者使用块中的依赖项声明定义的版本
dependencies。发布时不会考虑任何其他类型的处理,例如通过更改已解析版本的规则。 - 已解决的版本
-
该策略可能通过应用解决规则和自动冲突解决来发布在构建期间解决的版本。这样做的优点是发布的版本与测试发布的工件的版本相对应。
已解决版本的示例用例:
-
项目使用动态版本作为依赖项,但更喜欢向其使用者公开给定版本的已解析版本。
-
结合依赖锁定,您希望发布锁定的版本。
-
一个项目利用了 Gradle 的丰富版本约束,它对 Maven 进行了有损转换。它不依赖转换,而是发布已解析的版本。
这是通过使用versionMappingDSL 方法来完成的,该方法允许配置VersionMappingStrategy:
publishing {
publications {
create<MavenPublication>("mavenJava") {
versionMapping {
usage("java-api") {
fromResolutionOf("runtimeClasspath")
}
usage("java-runtime") {
fromResolutionResult()
}
}
}
}
}publishing {
publications {
mavenJava(MavenPublication) {
versionMapping {
usage('java-api') {
fromResolutionOf('runtimeClasspath')
}
usage('java-runtime') {
fromResolutionResult()
}
}
}
}
}runtimeClasspath在上面的示例中,Gradle 将使用在 中声明的依赖项上解析的版本api,这些版本映射到compileMaven 的范围。 Gradle 还将使用runtimeClasspath在 中声明的依赖项上解析的版本implementation,这些版本映射到runtimeMaven 的范围。
fromResolutionResult()指示 Gradle 应该使用变体的默认类路径,并且runtimeClasspath是java-runtime.
存储库
该插件提供MavenArtifactRepository类型的存储库。要了解如何定义和使用存储库进行发布,请参阅基本发布部分。
这是定义发布存储库的简单示例:
publishing {
repositories {
maven {
// change to point to your repo, e.g. http://my.org/repo
url = uri(layout.buildDirectory.dir("repo"))
}
}
}publishing {
repositories {
maven {
// change to point to your repo, e.g. http://my.org/repo
url = layout.buildDirectory.dir('repo')
}
}
}您需要配置的两个主要内容是存储库的:
-
网址(必填)
-
姓名(可选)
您可以定义多个存储库,只要它们在构建脚本中具有唯一的名称即可。您还可以声明一个(且仅有一个)没有名称的存储库。该存储库将采用隐式名称“Maven”。
您还可以配置连接到存储库所需的任何身份验证详细信息。有关更多详细信息,请参阅MavenArtifactRepository 。
快照和发布存储库
将快照和版本发布到不同的 Maven 存储库是一种常见的做法。实现此目的的一个简单方法是根据项目版本配置存储库 URL。以下示例对以“SNAPSHOT”结尾的版本使用一个 URL,对其余版本使用不同的 URL:
publishing {
repositories {
maven {
val releasesRepoUrl = layout.buildDirectory.dir("repos/releases")
val snapshotsRepoUrl = layout.buildDirectory.dir("repos/snapshots")
url = uri(if (version.toString().endsWith("SNAPSHOT")) snapshotsRepoUrl else releasesRepoUrl)
}
}
}publishing {
repositories {
maven {
def releasesRepoUrl = layout.buildDirectory.dir('repos/releases')
def snapshotsRepoUrl = layout.buildDirectory.dir('repos/snapshots')
url = version.endsWith('SNAPSHOT') ? snapshotsRepoUrl : releasesRepoUrl
}
}
}同样,您可以使用项目或系统属性来决定要发布到哪个存储库。如果release设置了项目属性,例如当用户运行时gradle -Prelease publish,以下示例将使用发布存储库:
publishing {
repositories {
maven {
val releasesRepoUrl = layout.buildDirectory.dir("repos/releases")
val snapshotsRepoUrl = layout.buildDirectory.dir("repos/snapshots")
url = uri(if (project.hasProperty("release")) releasesRepoUrl else snapshotsRepoUrl)
}
}
}publishing {
repositories {
maven {
def releasesRepoUrl = layout.buildDirectory.dir('repos/releases')
def snapshotsRepoUrl = layout.buildDirectory.dir('repos/snapshots')
url = project.hasProperty('release') ? releasesRepoUrl : snapshotsRepoUrl
}
}
}发布到 Maven 本地
为了与本地 Maven 安装集成,有时将模块及其 POM 文件和其他元数据发布到 Maven 本地存储库(通常位于<当前用户的主目录>/.m2/repository )中很有用。用 Maven 的话说,这称为“安装”模块。
Maven Publish Plugin 通过为容器中的每个MavenPublication自动创建PublishToMavenLocal任务,使这一切变得容易。任务名称遵循 的模式。这些任务中的每一个都连接到聚合任务中。您不需要在您的部分中。publishing.publicationspublishPubNamePublicationToMavenLocalpublishToMavenLocalmavenLocal()publishing.repositories
发布Maven搬迁信息
当项目更改其发布的工件的groupId或artifactId(坐标)时,让用户知道在哪里可以找到新工件非常重要。 Maven 可以通过重定位功能来帮助解决这个问题。其工作方式是,项目在旧坐标下发布一个仅包含最小重定位 POM的附加工件;该 POM 文件指定了新工件的位置。然后,Maven 存储库浏览器和构建工具可以通知用户工件的坐标已更改。
为此,项目添加了一个额外的MavenPublication指定MavenPomRelocation:
publishing {
publications {
// ... artifact publications
// Specify relocation POM
create<MavenPublication>("relocation") {
pom {
// Old artifact coordinates
groupId = "com.example"
artifactId = "lib"
version = "2.0.0"
distributionManagement {
relocation {
// New artifact coordinates
groupId = "com.new-example"
artifactId = "lib"
version = "2.0.0"
message = "groupId has been changed"
}
}
}
}
}
}publishing {
publications {
// ... artifact publications
// Specify relocation POM
relocation(MavenPublication) {
pom {
// Old artifact coordinates
groupId = "com.example"
artifactId = "lib"
version = "2.0.0"
distributionManagement {
relocation {
// New artifact coordinates
groupId = "com.new-example"
artifactId = "lib"
version = "2.0.0"
message = "groupId has been changed"
}
}
}
}
}
}仅需要在 下指定发生变化的属性relocation,即artifactId和/或groupId。所有其他属性都是可选的。
|
提示
|
当新工件具有不同版本时,指定 自定义 |
应该为旧工件的下一个版本创建重定位 POM。例如,当 的工件坐标com.example:lib:1.0.0发生更改并且具有新坐标的工件继续版本编号并发布为 时com.new-example:lib:2.0.0,则重定位 POM 应指定重定位从com.example:lib:2.0.0到com.new-example:lib:2.0.0。
重定位 POM 只需发布一次,发布后应再次删除其构建文件配置。
请注意,重定位 POM 并不适合所有情况;当一个工件被分割成两个或多个单独的工件时,重定位 POM 可能没有帮助。
追溯发布搬迁信息
过go工件坐标发生变化且当时未发布任何重定位信息时,可以追溯发布重定位信息。
与上述相同的建议也适用。为了方便用户迁移,请务必注意version重定位 POM 中指定的内容。重定位 POM 应允许用户一步移动到新工件,然后允许他们在单独的步骤中更新到最新版本。例如,当 的坐标com.new-example:lib:5.0.0在 2.0.0 版本中发生更改时,理想情况下应发布重定位 POM,以将旧坐标com.example:lib:2.0.0重定位到com.new-example:lib:2.0.0。然后,用户可以从版本 2.0.0 切换com.example:lib到com.new-example版本 2.0.0,然后单独更新到版本 5.0.0,逐步处理重大更改(如果有)。
搬迁信息追溯发布时,无需等待项目下次定期发布,可同时发布。如上所述,一旦发布了重定位 POM,就应该再次从构建文件中删除重定位信息。
避免重复的依赖关系
当仅工件的坐标发生变化,但工件内的类的包名称保持不变时,可能会发生依赖性冲突。项目可能(传递地)依赖于旧工件,但同时也依赖于新工件,新工件都包含相同的类,可能具有不兼容的更改。
为了检测此类冲突的重复依赖项,可以将功能作为Gradle 模块元数据的一部分发布。有关使用Java 库项目的示例,请参阅声明本地组件的附加功能。
进行试运行
要在将重定位信息发布到远程存储库之前验证其是否按预期工作,可以先将其发布到本地 Maven 存储库。然后可以创建一个本地测试 Gradle 或 Maven 项目,其中包含重定位工件作为依赖项。
完整示例
以下示例演示如何签署和发布 Java 库,包括源代码、Javadoc 和自定义 POM:
plugins {
`java-library`
`maven-publish`
signing
}
group = "com.example"
version = "1.0"
java {
withJavadocJar()
withSourcesJar()
}
publishing {
publications {
create<MavenPublication>("mavenJava") {
artifactId = "my-library"
from(components["java"])
versionMapping {
usage("java-api") {
fromResolutionOf("runtimeClasspath")
}
usage("java-runtime") {
fromResolutionResult()
}
}
pom {
name = "My Library"
description = "A concise description of my library"
url = "http://www.example.com/library"
properties = mapOf(
"myProp" to "value",
"prop.with.dots" to "anotherValue"
)
licenses {
license {
name = "The Apache License, Version 2.0"
url = "http://www.apache.org/licenses/LICENSE-2.0.txt"
}
}
developers {
developer {
id = "johnd"
name = "John Doe"
email = "john.doe@example.com"
}
}
scm {
connection = "scm:git:git://example.com/my-library.git"
developerConnection = "scm:git:ssh://example.com/my-library.git"
url = "http://example.com/my-library/"
}
}
}
}
repositories {
maven {
// change URLs to point to your repos, e.g. http://my.org/repo
val releasesRepoUrl = uri(layout.buildDirectory.dir("repos/releases"))
val snapshotsRepoUrl = uri(layout.buildDirectory.dir("repos/snapshots"))
url = if (version.toString().endsWith("SNAPSHOT")) snapshotsRepoUrl else releasesRepoUrl
}
}
}
signing {
sign(publishing.publications["mavenJava"])
}
tasks.javadoc {
if (JavaVersion.current().isJava9Compatible) {
(options as StandardJavadocDocletOptions).addBooleanOption("html5", true)
}
}plugins {
id 'java-library'
id 'maven-publish'
id 'signing'
}
group = 'com.example'
version = '1.0'
java {
withJavadocJar()
withSourcesJar()
}
publishing {
publications {
mavenJava(MavenPublication) {
artifactId = 'my-library'
from components.java
versionMapping {
usage('java-api') {
fromResolutionOf('runtimeClasspath')
}
usage('java-runtime') {
fromResolutionResult()
}
}
pom {
name = 'My Library'
description = 'A concise description of my library'
url = 'http://www.example.com/library'
properties = [
myProp: "value",
"prop.with.dots": "anotherValue"
]
licenses {
license {
name = 'The Apache License, Version 2.0'
url = 'http://www.apache.org/licenses/LICENSE-2.0.txt'
}
}
developers {
developer {
id = 'johnd'
name = 'John Doe'
email = 'john.doe@example.com'
}
}
scm {
connection = 'scm:git:git://example.com/my-library.git'
developerConnection = 'scm:git:ssh://example.com/my-library.git'
url = 'http://example.com/my-library/'
}
}
}
}
repositories {
maven {
// change URLs to point to your repos, e.g. http://my.org/repo
def releasesRepoUrl = layout.buildDirectory.dir('repos/releases')
def snapshotsRepoUrl = layout.buildDirectory.dir('repos/snapshots')
url = version.endsWith('SNAPSHOT') ? snapshotsRepoUrl : releasesRepoUrl
}
}
}
signing {
sign publishing.publications.mavenJava
}
javadoc {
if(JavaVersion.current().isJava9Compatible()) {
options.addBooleanOption('html5', true)
}
}结果将发布以下工件:
-
POM:
my-library-1.0.pom -
Java 组件的主要 JAR 工件:
my-library-1.0.jar -
已显式配置的源 JAR 工件:
my-library-1.0-sources.jar -
已显式配置的 Javadoc JAR 工件:
my-library-1.0-javadoc.jar
签名插件用于为每个工件生成签名文件。此外,将为所有工件和签名文件生成校验和文件。
|
提示
|
publishToMavenLocal` 不会在$USER_HOME/.m2/repository.如果您想验证校验和文件是否已正确创建,或将其用于以后发布,请考虑使用 URL 配置自定义 Maven 存储库file://并将其用作发布目标。
|
删除延迟配置行为
在 Gradle 5.0 之前,该publishing {}块(默认情况下)被隐式处理,就好像其中的所有逻辑都是在项目评估后执行的。这种行为引起了相当大的混乱,并在 Gradle 4.8 中被弃用,因为它是唯一具有这种行为的块。
您的发布块或插件中可能有一些依赖于延迟配置行为的逻辑。例如,以下逻辑假设设置 artifactId 时将评估子项目:
subprojects {
publishing {
publications {
create<MavenPublication>("mavenJava") {
from(components["java"])
artifactId = tasks.jar.get().archiveBaseName.get()
}
}
}
}subprojects {
publishing {
publications {
mavenJava(MavenPublication) {
from components.java
artifactId = jar.archiveBaseName
}
}
}
}这种逻辑现在必须包装在一个afterEvaluate {}块中。
subprojects {
publishing {
publications {
create<MavenPublication>("mavenJava") {
from(components["java"])
afterEvaluate {
artifactId = tasks.jar.get().archiveBaseName.get()
}
}
}
}
}subprojects {
publishing {
publications {
mavenJava(MavenPublication) {
from components.java
afterEvaluate {
artifactId = jar.archiveBaseName
}
}
}
}
}Ivy 发布插件
Ivy 发布插件提供了以Apache Ivy格式发布构建工件的能力,通常发布到存储库以供其他构建或项目使用。发布的是由构建创建的一个或多个工件,以及描述工件和工件的依赖项(如果有)的Ivy模块描述符(通常)。ivy.xml
已发布的 Ivy 模块可由 Gradle(请参阅声明依赖项)和其他理解 Ivy 格式的工具使用。您可以在发布概述中了解发布的基础知识。
用法
要使用 Ivy 发布插件,请在构建脚本中包含以下内容:
plugins {
`ivy-publish`
}plugins {
id 'ivy-publish'
}Ivy 发布插件在名为PublishingExtensionpublishing类型的项目上使用扩展。此扩展提供了命名出版物的容器和命名存储库的容器。 Ivy 发布插件可与IvyPublication出版物和IvyArtifactRepository存储库配合使用。
任务
generateDescriptorFileForPubNamePublication—生成IvyDescriptor-
为名为PubName 的发布创建 Ivy 描述符文件,填充已知元数据,例如项目名称、项目版本和依赖项。描述符文件的默认位置是build/publications/$pubName/ivy.xml。
publishPubNamePublicationToRepoNameRepository— PublishToIvyRepository-
将PubName发布发布到名为RepoName 的存储库。如果您的存储库定义没有显式名称,则RepoName将为“Ivy”。
publish-
取决于:所有任务
publishPubNamePublicationToRepoNameRepository将所有定义的发布发布到所有定义的存储库的聚合任务。
刊物
该插件提供IvyPublication类型的出版物。要了解如何定义和使用发布,请参阅基本发布部分。
您可以在 Ivy 出版物中配置四个主要内容:
-
一个组件——通过IvyPublication.from(org.gradle.api.component.SoftwareComponent)。
-
自定义工件- 通过IvyPublication.artifact(java.lang.Object)方法。有关自定义 Ivy 工件的可用配置选项,请参阅IvyArtifact 。
-
标准元数据,如
module、organisation和revision。 -
模块描述符的其他内容 - 通过IvyPublication.descriptor(org.gradle.api.Action)。
您可以在完整的发布示例中看到所有这些操作。 API 文档IvyPublication有额外的代码示例。
已发布项目的标识值
生成的ivy模块描述符文件包含<info>标识模块的元素。默认标识值源自以下内容:
-
organisation-项目.getGroup() -
module-项目.getName() -
revision-项目.getVersion() -
status-项目.getStatus() -
branch- (没有设置)
覆盖默认标识值很简单:只需在配置IvyPublicationorganisation时指定,module或属性。并且可以通过属性进行设置- 请参阅IvyModuleDescriptorSpec。revisionstatusbranchdescriptor
该descriptor属性还可用于添加其他自定义元素作为<info>元素的子元素,如下所示:
publishing {
publications {
create<IvyPublication>("ivy") {
organisation = "org.gradle.sample"
module = "project1-sample"
revision = "1.1"
descriptor.status = "milestone"
descriptor.branch = "testing"
descriptor.extraInfo("http://my.namespace", "myElement", "Some value")
from(components["java"])
}
}
}publishing {
publications {
ivy(IvyPublication) {
organisation = 'org.gradle.sample'
module = 'project1-sample'
revision = '1.1'
descriptor.status = 'milestone'
descriptor.branch = 'testing'
descriptor.extraInfo 'http://my.namespace', 'myElement', 'Some value'
from components.java
}
}
}|
提示
|
某些存储库无法处理所有支持的字符。例如,:在发布到 Windows 上文件系统支持的存储库时,该字符不能用作标识符。
|
Gradle 将处理organisation、module和revision(以及工件的name、extension和classifier)的任何有效 Unicode 字符。唯一明确禁止的值是\,/和任何 ISO 控制字符。所提供的值在发布过程中会尽早得到验证。
自定义生成的模块描述符
有时,从项目信息生成的模块描述符文件在发布之前需要进行调整。 Ivy Publish Plugin 为此提供了 DSL。请参阅DSL 参考中的IvyModuleDescriptorSpec以获取可用属性和方法的完整文档。
以下示例展示了如何使用 DSL 最常见的方面:
publications {
create<IvyPublication>("ivyCustom") {
descriptor {
license {
name = "The Apache License, Version 2.0"
url = "http://www.apache.org/licenses/LICENSE-2.0.txt"
}
author {
name = "Jane Doe"
url = "http://example.com/users/jane"
}
description {
text = "A concise description of my library"
homepage = "http://www.example.com/library"
}
}
versionMapping {
usage("java-api") {
fromResolutionOf("runtimeClasspath")
}
usage("java-runtime") {
fromResolutionResult()
}
}
}
}publications {
ivyCustom(IvyPublication) {
descriptor {
license {
name = 'The Apache License, Version 2.0'
url = 'http://www.apache.org/licenses/LICENSE-2.0.txt'
}
author {
name = 'Jane Doe'
url = 'http://example.com/users/jane'
}
description {
text = 'A concise description of my library'
homepage = 'http://www.example.com/library'
}
}
versionMapping {
usage('java-api') {
fromResolutionOf('runtimeClasspath')
}
usage('java-runtime') {
fromResolutionResult()
}
}
}
}在此示例中,我们只是将“描述”元素添加到生成的 Ivy 依赖项描述符中,但此挂钩允许您修改生成的描述符的任何方面。例如,您可以将依赖项的版本范围替换为用于生成构建的实际版本。
您还可以通过IvyModuleDescriptorSpec.withXml(org.gradle.api.Action)将任意 XML 添加到描述符文件,但不能使用它来修改模块标识符的任何部分(组织、模块、修订)。
|
警告
|
有可能修改描述符使其不再是有效的 Ivy 模块描述符,因此使用此功能时必须小心。 |
自定义依赖版本
支持两种发布依赖关系的策略:
- 声明的版本(默认)
-
此策略发布由构建脚本作者使用块中的依赖项声明定义的版本
dependencies。发布时不会考虑任何其他类型的处理,例如通过更改已解析版本的规则。 - 已解决的版本
-
该策略可能通过应用解决规则和自动冲突解决来发布在构建期间解决的版本。这样做的优点是发布的版本与测试发布的工件的版本相对应。
已解决版本的示例用例:
-
项目使用动态版本作为依赖项,但更喜欢向其使用者公开给定版本的已解析版本。
-
结合依赖锁定,您希望发布锁定的版本。
-
一个项目利用了 Gradle 的丰富版本约束,它对 Ivy 进行了有损转换。它不依赖转换,而是发布已解析的版本。
这是通过使用versionMappingDSL 方法来完成的,该方法允许配置VersionMappingStrategy:
publications {
create<IvyPublication>("ivyCustom") {
versionMapping {
usage("java-api") {
fromResolutionOf("runtimeClasspath")
}
usage("java-runtime") {
fromResolutionResult()
}
}
}
}publications {
ivyCustom(IvyPublication) {
versionMapping {
usage('java-api') {
fromResolutionOf('runtimeClasspath')
}
usage('java-runtime') {
fromResolutionResult()
}
}
}
}runtimeClasspath在上面的示例中,Gradle 将使用在 中声明的依赖项上解析的版本api,这些版本映射到compileIvy 的配置。 Gradle 还将使用runtimeClasspath在 中声明的依赖项上解析的版本implementation,这些版本映射到runtimeIvy 的配置。
fromResolutionResult()指示 Gradle 应该使用变体的默认类路径,并且runtimeClasspath是java-runtime.
存储库
该插件提供IvyArtifactRepository类型的存储库。要了解如何定义和使用存储库进行发布,请参阅基本发布部分。
这是定义发布存储库的简单示例:
publishing {
repositories {
ivy {
// change to point to your repo, e.g. http://my.org/repo
url = uri(layout.buildDirectory.dir("repo"))
}
}
}publishing {
repositories {
ivy {
// change to point to your repo, e.g. http://my.org/repo
url = layout.buildDirectory.dir("repo")
}
}
}您需要配置的两个主要内容是存储库的:
-
网址(必填)
-
姓名(可选)
您可以定义多个存储库,只要它们在构建脚本中具有唯一的名称即可。您还可以声明一个(且仅有一个)没有名称的存储库。该存储库将采用隐式名称“Ivy”。
您还可以配置连接到存储库所需的任何身份验证详细信息。有关更多详细信息,请参阅IvyArtifactRepository 。
完整示例
以下示例演示了使用多项目构建进行发布。每个项目都会发布一个 Java 组件,该组件配置为构建和发布 Javadoc 和源代码工件。描述符文件经过定制以包含每个项目的项目描述。
rootProject.name = "ivy-publish-java"
include("project1", "project2")plugins {
`kotlin-dsl`
}
repositories {
gradlePluginPortal()
}plugins {
id("java-library")
id("ivy-publish")
}
version = "1.0"
group = "org.gradle.sample"
repositories {
mavenCentral()
}
java {
withJavadocJar()
withSourcesJar()
}
publishing {
repositories {
ivy {
// change to point to your repo, e.g. http://my.org/repo
url = uri("${rootProject.buildDir}/repo")
}
}
publications {
create<IvyPublication>("ivy") {
from(components["java"])
descriptor.description {
text = providers.provider({ description })
}
}
}
}plugins {
id("myproject.publishing-conventions")
}
description = "The first project"
dependencies {
implementation("junit:junit:4.13")
implementation(project(":project2"))
}plugins {
id("myproject.publishing-conventions")
}
description = "The second project"
dependencies {
implementation("commons-collections:commons-collections:3.2.2")
}rootProject.name = 'ivy-publish-java'
include 'project1', 'project2'plugins {
id 'groovy-gradle-plugin'
}plugins {
id 'java-library'
id 'ivy-publish'
}
version = '1.0'
group = 'org.gradle.sample'
repositories {
mavenCentral()
}
java {
withJavadocJar()
withSourcesJar()
}
publishing {
repositories {
ivy {
// change to point to your repo, e.g. http://my.org/repo
url = "${rootProject.buildDir}/repo"
}
}
publications {
ivy(IvyPublication) {
from components.java
descriptor.description {
text = providers.provider({ description })
}
}
}
}plugins {
id 'myproject.publishing-conventions'
}
description = 'The first project'
dependencies {
implementation 'junit:junit:4.13'
implementation project(':project2')
}plugins {
id 'myproject.publishing-conventions'
}
description = 'The second project'
dependencies {
implementation 'commons-collections:commons-collections:3.2.2'
}结果是每个项目都会发布以下工件:
-
Gradle 模块元数据文件:
project1-1.0.module. -
Ivy 模块元数据文件:
ivy-1.0.xml. -
Java 组件的主要 JAR 工件:
project1-1.0.jar. -
Java 组件的 Javadoc 和源 JAR 工件(因为我们配置了
withJavadocJar()和withSourcesJar()):project1-1.0-javadoc.jar,project1-1.0-source.jar。
优化构建性能
提高 Gradle 构建的性能
构建性能对于生产力至关重要。完成构建所需的时间越长,它们就越有可能扰乱您的开发流程。构建每天运行多次,因此即使很小的等待时间也会增加。持续集成 (CI) 构建也是如此:花费的时间越少,您对新问题的反应就越快,并且可以更频繁地进行试验。
所有这些意味着值得投入一些时间和精力来使您的构建尽可能快。本节提供了几种加快构建速度的方法。此外,您还将找到有关导致构建性能下降的原因以及如何避免这种情况的详细信息。
|
提示
|
想要更快的 Gradle 构建吗?在此注册我们的构建缓存培训课程,了解 Develocity 如何将构建速度提高高达 90%。 |
检查你的构建
在进行任何更改之前,请使用构建扫描或配置文件报告检查您的构建。正确的构建检查可以帮助您了解:
-
构建您的项目需要多长时间
-
你的构建的哪些部分很慢
检查提供了一个比较点,可以更好地了解本页建议的更改的影响。
为了最好地利用此页面:
-
检查你的构建。
-
做出改变。
-
再次检查您的构建。
如果更改缩短了构建时间,请将其永久化。如果您没有看到改进,请删除更改并尝试其他更改。
更新版本
摇篮
Gradle 团队不断提高 Gradle 构建的性能。如果您使用旧版本的 Gradle,您就会错过这项工作的好处。跟上 Gradle 版本升级的风险很低,因为 Gradle 团队确保 Gradle 次要版本之间的向后兼容性。保持最新状态还可以更轻松地过渡到下一个主要版本,因为您会提前收到弃用警告。
Java
Gradle 在 Java 虚拟机 (JVM) 上运行。 Java 性能的改进通常有利于 Gradle。为了获得最佳 Gradle 性能,请使用最新版本的 Java。
插件
插件作者不断提高插件的性能。如果您使用旧版本的插件,您就会错过该工作的好处。 Android、Java 和 Kotlin 插件尤其可以显着影响构建性能。更新到这些插件的最新版本以提高性能。
启用并行执行
大多数项目都包含多个子项目。通常,其中一些子项目是相互独立的;也就是说,它们不共享状态。但默认情况下,Gradle 一次仅运行一项任务。要并行执行属于不同子项目的任务,请使用以下parallel标志:
$ gradle <task> --parallel
要默认并行执行项目任务,请将以下设置添加到gradle.properties项目根目录或 Gradle 主目录中的文件中:
org.gradle.parallel=true并行构建可以显着缩短构建时间;多少取决于您的项目结构以及子项目之间有多少依赖关系。执行时间由单个子项目主导的构建根本不会受益太多。具有大量子项目间依赖关系的项目也不会。但大多数多子项目构建都会缩短构建时间。
通过构建扫描可视化并行性
构建扫描为您提供任务执行的可视化时间表。在以下示例构建中,您可以在构建的开始和结束时看到长时间运行的任务:

调整构建配置以尽早并行运行两个慢速任务,将总体构建时间从 8 秒减少到 5 秒:

重新启用 Gradle 守护进程
Gradle 守护进程通过以下方式减少构建时间:
-
跨构建缓存项目信息
-
在后台运行,因此每个 Gradle 构建都不必等待 JVM 启动
-
受益于 JVM 中的持续运行时优化
-
在运行构建之前观察文件系统以准确计算需要重建的内容
Gradle 默认启用守护进程,但某些构建会覆盖此首选项。如果您的构建禁用了守护进程,您可以看到启用守护进程后性能显着提高。
您可以在构建时使用以下daemon标志启用守护进程:
$ gradle <task> --daemon
要在较旧的 Gradle 版本中默认启用守护程序,请将以下设置添加到
gradle.properties项目根目录或 Gradle 主目录中的文件中:
org.gradle.daemon=true在开发人员机器上,您应该会看到显着的性能改进。在 CI 机器上,长寿命代理受益于守护进程。但寿命短的机器并没有多大好处。在 Gradle 3.0 及更高版本中,守护进程会在内存压力时自动关闭,因此启用守护进程始终是安全的。
启用配置缓存
|
重要的
|
此功能有以下限制:
|
您可以通过启用配置缓存来缓存配置阶段的结果。当构建配置输入在构建之间保持相同时,配置缓存允许 Gradle 完全跳过配置阶段。
构建配置输入包括:
-
初始化脚本
-
设置脚本
-
构建脚本
-
配置阶段使用的系统属性
-
配置阶段使用的 Gradle 属性
-
配置阶段使用的环境变量
-
使用价值提供者(例如提供商)访问的配置文件
-
buildSrc输入,包括构建配置输入和源文件
默认情况下,Gradle 不使用配置缓存。要在构建时启用配置缓存,请使用以下configuration-cache标志:
$ gradle <task> --configuration-cache
要默认启用配置缓存,请将以下设置添加到gradle.properties项目根目录或 Gradle 主目录中的文件中:
org.gradle.configuration-cache=true有关配置缓存的更多信息,请查看 配置缓存文档。
为自定义任务启用增量构建
增量构建是一种 Gradle 优化,它会跳过之前使用相同输入执行的运行任务。如果任务的输入和输出自上次执行以来没有更改,Gradle 会跳过该任务。
Gradle 提供的大多数内置任务都支持增量构建。要使自定义任务与增量构建兼容,请指定输入和输出:
tasks.register("processTemplatesAdHoc") {
inputs.property("engine", TemplateEngineType.FREEMARKER)
inputs.files(fileTree("src/templates"))
.withPropertyName("sourceFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.property("templateData.name", "docs")
inputs.property("templateData.variables", mapOf("year" to "2013"))
outputs.dir(layout.buildDirectory.dir("genOutput2"))
.withPropertyName("outputDir")
doLast {
// Process the templates here
}
}tasks.register('processTemplatesAdHoc') {
inputs.property('engine', TemplateEngineType.FREEMARKER)
inputs.files(fileTree('src/templates'))
.withPropertyName('sourceFiles')
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.property('templateData.name', 'docs')
inputs.property('templateData.variables', [year: '2013'])
outputs.dir(layout.buildDirectory.dir('genOutput2'))
.withPropertyName('outputDir')
doLast {
// Process the templates here
}
}有关增量构建的更多信息,请查看 增量构建文档。
通过构建扫描时间线可视化增量构建
查看构建扫描时间线视图,以确定可以从增量构建中受益的任务。这还可以帮助您理解为什么当您希望 Gradle 跳过任务时任务会执行。

正如您在上面的构建扫描中看到的,该任务不是最新的,因为其输入之一(“时间戳”)发生了更改,迫使任务重新运行。
按持续时间对任务进行排序,以查找项目中最慢的任务。
启用构建缓存
构建缓存是一种 Gradle 优化,用于存储特定输入的任务输出。当您稍后使用相同的输入运行相同的任务时,Gradle 会从构建缓存中检索输出,而不是再次运行该任务。默认情况下,Gradle 不使用构建缓存。要在构建时启用构建缓存,请使用以下build-cache标志:
$ gradle <task> --build-cache
要默认启用构建缓存,请将以下设置添加到gradle.properties项目根目录或 Gradle 主目录中的文件中:
org.gradle.caching=true您可以使用本地构建缓存来加速单台计算机上的重复构建。您还可以使用共享构建缓存来加速跨多台计算机的重复构建。发展提供了一种。共享构建缓存可以减少 CI 和开发人员构建的构建时间。
有关构建缓存的更多信息,请查看 构建缓存文档。
通过构建扫描可视化构建缓存
构建扫描可以帮助您调查构建缓存的有效性。在性能屏幕中,“构建缓存”选项卡显示有关以下内容的统计信息:
-
有多少任务与缓存交互
-
使用了哪个缓存
-
这些缓存条目的传输和打包/解包速率

“任务执行”选项卡显示有关任务可缓存性的详细信息。单击某个类别可查看突出显示该类别任务的时间线屏幕。


在时间线屏幕上按任务持续时间排序,以突出显示具有巨大节省时间潜力的任务。上面的构建扫描显示了可以改进:task1并:task3使其可缓存,并显示了 Gradle 不缓存它们的原因。
为特定开发人员工作流程创建构建
最快的任务是不执行的任务。如果您能找到跳过不需要运行的任务的方法,那么您最终将获得更快的整体构建速度。
如果您的构建包含多个子项目,请创建任务来独立构建这些子项目。这有助于您充分利用缓存,因为对一个子项目的更改不会强制重建不相关的子项目。这有助于减少处理不相关子项目的团队的构建时间:前端开发人员无需在每次更改前端时都构建后端子项目。即使文档与代码位于同一项目中,文档编写者也不需要构建前端或后端代码。
相反,创建符合开发人员需求的任务。您仍然拥有整个项目的单个任务图。每组用户建议对任务图进行限制视图:将该视图转换为排除不必要任务的 Gradle 工作流程。
Gradle 提供了几个功能来创建这些工作流程:
-
将任务分配给适当的组
-
创建聚合任务:没有任何操作、仅依赖于其他任务的任务,例如
assemble -
通过和其他方式推迟配置
gradle.taskGraph.whenReady(),因此您可以仅在必要时执行验证
增加堆大小
默认情况下,Gradle 为您的构建保留 512MB 的堆空间。这对于大多数项目来说已经足够了。但是,一些非常大的构建可能需要更多内存来保存 Gradle 的模型和缓存。如果您遇到这种情况,您可以指定更大的内存要求。在gradle.properties项目根目录或 Gradle 主目录的文件中指定以下属性:
org.gradle.jvmargs=-Xmx2048M要了解更多信息,请查看JVM 内存配置文档。
优化配置
如构建生命周期章节中所述,Gradle 构建经历 3 个阶段:初始化、配置和执行。无论运行什么任务,配置代码始终都会执行。因此,在配置期间执行的任何昂贵的工作都会减慢每次调用的速度。即使是简单的命令,如gradle help和gradle tasks。
接下来的几小节介绍了可以减少配置阶段所花费时间的技术。
|
笔记
|
您还可以启用配置缓存以减少缓慢配置阶段的影响。但即使使用缓存的机器仍然偶尔会执行您的配置阶段。因此,您应该使用这些技术尽可能快地完成配置阶段。 |
避免昂贵或阻塞的工作
您应该避免在配置阶段进行耗时的工作。但有时它可能会潜入您的构建中不明显的地方。如果该代码位于构建文件中,那么当您在配置期间加密数据或调用远程服务时,通常很清楚。但这样的逻辑更常见于插件和偶尔的自定义任务类中。插件apply()方法或任务构造函数中任何昂贵的工作都是危险信号。
仅在需要的地方应用插件
应用于项目的每个插件和脚本都会增加总体配置时间。有些插件比其他插件有更大的影响。这并不意味着您应该避免使用插件,但您应该注意只在需要的地方应用它们。例如,即使不是每个项目都需要插件allprojects {},也可以轻松地将插件应用到所有子项目。subprojects {}
在上面的构建扫描示例中,您可以看到根构建脚本将该script-a.gradle
脚本应用于构建内的 3 个子项目:

该脚本运行需要 1 秒。由于它适用于 3 个子项目,因此该脚本累计延迟了配置阶段 3 秒。在这种情况下,有几种方法可以减少延迟:
-
如果只有一个子项目使用该脚本,您可以从其他子项目中删除该脚本应用程序。这将每次 Gradle 调用中的配置延迟减少了两秒。
-
如果多个子项目(但不是全部)使用该脚本,您可以将脚本和所有周围逻辑重构为位于
buildSrc.仅将自定义插件应用于相关子项目,减少配置延迟并避免代码重复。
静态编译任务和插件
插件和任务作者经常编写 Groovy,因为它具有简洁的语法、JDK 的 API 扩展以及使用闭包的函数方法。但 Groovy 语法伴随着动态解释的成本。因此,Groovy 中的方法调用比 Java 或 Kotlin 中的方法调用花费更多时间并使用更多 CPU。
您可以通过静态 Groovy 编译来降低此成本:@CompileStatic当您不明确需要动态功能时,将注释添加到 Groovy 类中。如果您需要在方法中使用动态 Groovy,请将@CompileDynamic注释添加到该方法。
或者,您可以使用静态编译语言(例如 Java 或 Kotlin)编写插件和任务。
警告: Gradle 的 Groovy DSL 严重依赖 Groovy 的动态功能。要在插件中使用静态编译,请切换到类似 Java 的语法。
以下示例定义了一个不带动态功能的复制文件的任务:
project.tasks.register('copyFiles', Copy) { Task t ->
t.into(project.layout.buildDirectory.dir('output'))
t.from(project.configurations.getByName('compile'))
}此示例使用所有 Gradle“域对象容器”上可用的register()和方法。getByName()域对象容器包括任务、配置、依赖项、扩展等等。某些集合(例如TaskContainer)具有专用类型和额外的方法,例如create,它接受任务类型。
当您使用静态编译时,IDE 可以:
-
快速显示与无法识别的类型、属性和方法相关的错误
-
自动完成方法名称
优化依赖解析
依赖项解析简化了将第三方库和其他依赖项集成到项目中的过程。 Gradle 联系远程服务器来发现和下载依赖项。您可以优化引用依赖项的方式来减少这些远程服务器调用。
避免不必要和未使用的依赖项
管理第三方库及其传递依赖项会显着增加项目维护成本和构建时间。
注意未使用的依赖项:当第三方库停止使用时,不会从依赖项列表中删除。这种情况在重构过程中经常发生。您可以使用Gradle Lint 插件 来识别未使用的依赖项。
如果您只使用第三方库中的少量方法或类,请考虑:
-
在您的项目中自己实现所需的代码
-
如果它是开源的,则从库中复制所需的代码(带有归属!)
优化存储库顺序
当 Gradle 解析依赖项时,它会按声明的顺序搜索每个存储库。为了减少搜索依赖项所花费的时间,请首先声明托管最大数量依赖项的存储库。这最大限度地减少了解决所有依赖关系所需的网络请求数量。
最小化动态和快照版本
动态版本(例如“2.+”)和更改版本(快照)迫使 Gradle 联系远程存储库以查找新版本。默认情况下,Gradle 仅每 24 小时检查一次。但您可以通过以下设置以编程方式更改此设置:
-
cacheDynamicVersionsFor -
cacheChangingModulesFor
如果构建文件或初始化脚本降低了这些值,Gradle 会更频繁地查询存储库。如果您不需要每次构建时都使用依赖项的绝对最新版本,请考虑删除这些设置的自定义值。
通过构建扫描查找动态和变化的版本
您可以通过构建扫描找到具有动态版本的所有依赖项:

您也许可以使用“1.2”和“3.0.3.GA”等允许 Gradle 缓存版本的固定版本。如果您必须使用动态且不断变化的版本,请调整缓存设置以最好地满足您的需求。
在配置过程中避免依赖解析
无论是在 I/O 方面还是在计算方面,依赖性解析都是一个昂贵的过程。 Gradle 通过缓存减少所需的网络流量。但仍然有成本。 Gradle 在每次构建时都会运行配置阶段。如果您在配置阶段触发依赖项解析,则每个构建都会付出该成本。
切换到声明式语法
如果您评估配置文件,您的项目将在配置期间支付依赖项解析的成本。通常,任务会评估这些文件,因为在您准备好在任务操作中使用这些文件之前,您不需要这些文件。想象一下您正在进行一些调试并想要显示构成配置的文件。要实现这一点,您可以注入一条 print 语句:
tasks.register<Copy>("copyFiles") {
println(">> Compilation deps: ${configurations.compileClasspath.get().files.map { it.name }}")
into(layout.buildDirectory.dir("output"))
from(configurations.compileClasspath)
}tasks.register('copyFiles', Copy) {
println ">> Compilation deps: ${configurations.compileClasspath.files.name}"
into(layout.buildDirectory.dir('output'))
from(configurations.compileClasspath)
}该files属性强制 Gradle 解决依赖关系。在此示例中,这发生在配置阶段。由于配置阶段在每个构建上运行,因此所有构建现在都会付出依赖性解析的性能成本。您可以通过以下doFirst()操作来避免此成本:
tasks.register<Copy>("copyFiles") {
into(layout.buildDirectory.dir("output"))
// Store the configuration into a variable because referencing the project from the task action
// is not compatible with the configuration cache.
val compileClasspath: FileCollection = configurations.compileClasspath.get()
from(compileClasspath)
doFirst {
println(">> Compilation deps: ${compileClasspath.files.map { it.name }}")
}
}tasks.register('copyFiles', Copy) {
into(layout.buildDirectory.dir('output'))
// Store the configuration into a variable because referencing the project from the task action
// is not compatible with the configuration cache.
FileCollection compileClasspath = configurations.compileClasspath
from(compileClasspath)
doFirst {
println ">> Compilation deps: ${compileClasspath.files.name}"
}
}请注意,该from()声明不会解析依赖项,因为您使用依赖项配置本身作为参数,而不是文件。任务Copy在任务执行期间自行解析配置。
通过构建扫描可视化依赖关系解析
构建扫描的性能页面上的“依赖项解析”选项卡显示配置和执行阶段的依赖项解析时间:

构建扫描提供了另一种识别此问题的方法。您的构建应该在“项目配置”期间花费 0 秒来解决依赖关系。此示例显示构建在生命周期中过早地解决了依赖关系。您还可以在“性能”页面上找到“设置和建议”选项卡。这显示了在配置阶段解决的依赖关系。
删除或改进自定义依赖解析逻辑
Gradle 允许用户以最适合他们的方式对依赖解析进行建模。简单的自定义(例如强制依赖项的特定版本或将一种依赖项替换为另一种依赖项)不会对依赖项解析时间产生太大影响。更复杂的自定义(例如下载和解析 POM 的自定义逻辑)可能会显着减慢依赖关系解析速度。
使用构建扫描或配置文件报告来检查自定义依赖项解析逻辑是否不会对依赖项解析时间产生不利影响。这可能是您自己编写的自定义逻辑,也可能是插件的一部分。
删除缓慢或意外的依赖项下载
缓慢的依赖项下载可能会影响您的整体构建性能。有多种原因可能会导致这种情况,包括互联网连接速度慢或存储库服务器过载。在构建扫描的“性能”页面上,您将找到“网络活动”选项卡。此选项卡列出的信息包括:
-
下载依赖项所花费的时间
-
依赖下载的传输速率
-
按下载时间排序的下载列表
在以下示例中,两次缓慢的依赖项下载分别花费了 20 秒和 40 秒,并降低了构建的整体性能:

检查下载列表是否有意外的依赖项下载。例如,您可能会看到由使用动态版本的依赖项引起的下载。
通过切换到不同的存储库或依赖项来消除这些缓慢或意外的下载。
优化 Java 项目
以下部分仅适用于使用java插件或其他 JVM 语言的项目。
优化测试
项目经常花费大量的构建时间进行测试。这些可以是单元测试和集成测试的混合。集成测试通常需要更长的时间。构建扫描可以帮助您识别最慢的测试。然后您可以专注于加快这些测试的速度。

上面的构建扫描显示了运行测试的所有项目的交互式测试报告。
Gradle 有多种方法来加速测试:
-
并行执行测试
-
将测试分叉到多个进程中
-
禁用报告
让我们依次看看其中的每一个。
并行执行测试
Gradle 可以并行运行多个测试用例。要启用此功能,请覆盖maxParallelForks相关任务上的值Test。为了获得最佳性能,请使用小于或等于可用 CPU 核心数量的数字:
tasks.withType<Test>().configureEach {
maxParallelForks = (Runtime.getRuntime().availableProcessors() / 2).coerceAtLeast(1)
}tasks.withType(Test).configureEach {
maxParallelForks = Runtime.runtime.availableProcessors().intdiv(2) ?: 1
}并行测试必须是独立的。他们不应共享文件或数据库等资源。如果您的测试确实共享资源,它们可能会以随机且不可预测的方式相互干扰。
将测试分叉到多个进程中
默认情况下,Gradle 在单个分叉虚拟机中运行所有测试。如果有很多测试,或者某些测试消耗大量内存,则您的测试可能需要比您预期的运行时间更长的时间。您可以增加堆大小,但垃圾收集可能会减慢您的测试速度。
或者,您可以在使用以下设置运行一定数量的测试后分叉一个新的测试虚拟机forkEvery:
tasks.withType<Test>().configureEach {
forkEvery = 100
}tasks.withType(Test).configureEach {
forkEvery = 100
}|
警告
|
分叉虚拟机是一项昂贵的操作。此处设置太小的值会减慢测试速度。 |
禁用报告
无论您是否想查看测试报告,Gradle 都会自动创建它们。该报告的生成会减慢整体构建速度。如果出现以下情况,您可能不需要报告:
-
你只关心测试是否成功(而不是为什么)
-
您使用构建扫描,它提供比本地报告更多的信息
要禁用测试报告,请在任务中设置reports.html.required和:reports.junitXml.requiredfalseTest
tasks.withType<Test>().configureEach {
reports.html.required = false
reports.junitXml.required = false
}tasks.withType(Test).configureEach {
reports.html.required = false
reports.junitXml.required = false
}您可能希望有条件地启用报告,这样您就不必编辑构建文件来查看它们。要启用基于项目属性的报告,请在禁用报告之前检查属性是否存在:
tasks.withType<Test>().configureEach {
if (!project.hasProperty("createReports")) {
reports.html.required = false
reports.junitXml.required = false
}
}tasks.withType(Test).configureEach {
if (!project.hasProperty("createReports")) {
reports.html.required = false
reports.junitXml.required = false
}
}然后,在命令行上传递该属性-PcreateReports以生成报告。
$ gradle <task> -PcreateReports
gradle.properties或者在项目根目录或 Gradle 主目录中的文件中配置属性:
createReports=true优化编译器
Java 编译器速度很快。但是,如果您要编译数百个 Java 类,那么即使很短的编译时间也会增加。 Gradle 为 Java 编译提供了多种优化:
-
将编译器作为单独的进程运行
-
将仅限内部的依赖关系切换为实现可见性
将编译器作为单独的进程运行
JavaCompile您可以将编译器作为单独的进程运行,并为任何任务使用以下配置:
<task>.options.isFork = true<task>.options.fork = true要将配置应用到所有Java编译任务,您可以在configureEachjava编译任务中:
tasks.withType<JavaCompile>().configureEach {
options.isFork = true
}tasks.withType(JavaCompile).configureEach {
options.fork = true
}Gradle 在构建期间重用此过程,因此分叉开销很小。通过将内存密集型编译分叉到一个单独的进程中,我们可以最大限度地减少主 Gradle 进程中的垃圾收集。更少的垃圾收集意味着 Gradle 的基础设施可以运行得更快,特别是当您还使用并行构建时。
分叉编译很少影响小项目的性能。但是,如果单个任务将一千多个源文件一起编译,则应该考虑它。
将仅限内部的依赖关系切换为实现可见性
|
笔记
|
只有库可以定义api依赖关系。使用该
java-library插件定义库中的 API 依赖项。使用该插件的项目java无法声明api依赖项。
|
在 Gradle 3.4 之前,项目使用compile配置声明依赖项。这将所有这些依赖关系暴露给下游项目。在 Gradle 3.4 及更高版本中,您可以将面向下游的api依赖项与仅限内部的implementation详细信息分开。实现依赖项不会泄漏到下游项目的编译类路径中。当实现细节发生变化时,Gradle 仅重新编译api依赖项。
dependencies {
api(project("my-utils"))
implementation("com.google.guava:guava:21.0")
}dependencies {
api project('my-utils')
implementation 'com.google.guava:guava:21.0'
}这可以显着减少由大型多项目构建中的单个更改引起的重新编译的“连锁反应”。
提高旧版 Gradle 版本的性能
有些项目无法轻松升级到当前的 Gradle 版本。虽然您应该尽可能将 Gradle 升级到最新版本,但我们认识到这对于某些特定情况并不总是可行。在这些特定情况下,请查看这些建议来优化旧版本的 Gradle。
启用守护进程
Gradle 3.0及以上版本默认启用Daemon。如果您使用的是旧版本,您应该更新到最新版本的 Gradle。如果您无法更新 Gradle 版本,您可以手动启用 Daemon。
使用增量编译
Gradle 可以分析依赖关系到单个类级别,以便仅重新编译受更改影响的类。 Gradle 4.10及以上版本默认启用增量编译。要在较旧的 Gradle 版本中默认启用增量编译,请将以下设置添加到您的
build.gradle文件中:
tasks.withType<JavaCompile>().configureEach {
options.isIncremental = true
}tasks.withType(JavaCompile).configureEach {
options.incremental = true
}优化Android项目
此页面上的所有内容都适用于 Android 构建,因为 Android 构建使用 Gradle。然而,Android 引入了独特的优化机会。有关更多信息,请查看 Android 团队绩效指南。您还可以观看 Google IO 2017 的附带演讲。
Gradle 守护进程
守护进程是作为后台进程运行而不是在交互式用户的直接控制下运行的计算机程序。
Gradle 在 Java 虚拟机 (JVM) 上运行,并使用多个支持库,初始化时间很长。初创公司可能会很慢。 Gradle守护进程解决了这个问题。
Gradle 守护进程是一个长期存在的后台进程,可以减少运行构建所需的时间。
Gradle 守护进程通过以下方式减少构建时间:
-
跨构建缓存项目信息
-
在后台运行,因此每个 Gradle 构建都不必等待 JVM 启动
-
受益于 JVM 中的持续运行时优化
-
在运行构建之前观察文件系统以准确计算需要重建的内容
了解守护进程
Gradle JVM 客户端发送 Daemon 构建信息,例如命令行参数、项目目录和环境变量,以便它可以运行构建。 Wrapper负责解决依赖关系、执行构建脚本、创建和运行任务;完成后,它会将输出发送给客户端。客户端和守护进程之间的通信通过本地套接字连接进行。
守护进程使用 JVM 的默认最小堆大小。
如果请求的构建环境未指定最大堆大小,则守护程序最多使用 512MB 堆。 512MB 对于大多数构建来说已经足够了。具有数百个子项目、配置和源代码的较大构建可能会受益于较大的堆大小。
检查守护进程状态
要获取正在运行的守护进程及其状态的列表,请使用以下--status命令:
$ gradle --status
PID STATUS INFO 28486 IDLE 7.5 34247 BUSY 7.5
目前,给定的 Gradle 版本只能连接到相同版本的 Daemon。这意味着状态输出仅显示生成的守护进程运行与当前项目相同版本的 Gradle。
查找守护进程
如果您已经安装了 Java 开发工具包 (JDK),则可以使用以下命令查看实时守护进程jps。
$ jps
33920 Jps 27171 GradleDaemon 22792
Live Daemons 出现在名称下方GradleDaemon。由于此命令使用 JDK,因此您可以查看运行任何版本的 Gradle 的守护进程。
启用守护进程
从 Gradle 3.0 开始,Gradle 默认启用 Daemon。如果您的项目不使用守护进程,则可以--daemon在运行构建时使用以下标志为单个构建启用它:
$ gradle <task> --daemon
此标志会覆盖在项目或用户gradle.properties文件中禁用守护程序的任何设置。
要在较旧的 Gradle 版本中默认启用守护程序,请将以下设置添加到gradle.properties项目根目录或 Gradle 用户主页中的文件中(GRADLE_USER_HOME:
org.gradle.daemon=true禁用守护进程
您可以通过多种方式禁用守护进程,但有一些重要的注意事项:
- 一次性守护进程
-
如果客户端进程的 JVM 参数与构建所需的不匹配,则会创建一次性守护进程(一次性 JVM)。这意味着构建需要守护进程,因此它被创建、使用,然后在构建结束时停止。
- 无守护进程
-
如果
JAVA_OPTS和GRADLE_OPTS匹配org.gradle.jvmargs,则根本不会使用守护程序,因为构建发生在客户端 JVM 中。
禁用构建
要禁用单个构建的守护进程,请--no-daemon在运行构建时传递该标志:
$ gradle <task> --no-daemon
此标志会覆盖在项目中启用守护程序的任何设置(包括gradle.properties文件)。
为项目禁用
要为项目的所有构建禁用守护程序,请添加org.gradle.daemon=false到gradle.properties项目根目录中的文件。
为用户禁用
在 Windows 上,此命令会禁用当前用户的守护进程:
(if not exist "%USERPROFILE%/.gradle" mkdir "%USERPROFILE%/.gradle") && (echo. >> "%USERPROFILE%/.gradle/gradle.properties" && echo org.gradle.daemon=false >> "%USERPROFILE%/.gradle/gradle.properties")在类 UNIX 操作系统上,以下 Bash shell 命令会禁用当前用户的守护进程:
mkdir -p ~/.gradle && echo "org.gradle.daemon=false" >> ~/.gradle/gradle.properties全局禁用
有两种建议的方法可以在环境中全局禁用守护程序:
-
添加
org.gradle.daemon=false到/gradle.properties` 文件$GRADLE_USER_HOME -
将标志添加
-Dorg.gradle.daemon=false到GRADLE_OPTS环境变量中
如果您想完全禁用守护进程而不是简单地调用一次性守护进程,请不要忘记确保您的 JVM 参数和GRADLE_OPTS/匹配。JAVA_OPTS
停止守护进程
在故障排除或调试故障时停止守护程序会很有帮助。
如果出现以下任一情况,守护进程将自动停止:
-
可用系统内存不足
-
守护进程已空闲 3 小时
要停止运行守护进程,请使用以下命令:
$ gradle --stop
这将终止使用用于执行命令的同一版本的 Gradle 启动的所有守护进程进程。
您还可以使用操作系统手动终止守护程序。要查找所有守护进程的 PID(无论 Gradle 版本如何),请参阅查找守护进程。
工具和 IDE
IDE 和其他与 Gradle 集成的工具使用的Gradle Tooling API始终使用Gradle Daemon 来执行构建。如果您从 IDE 中执行 Gradle 构建,则您已经使用了 Gradle Daemon。无需为您的环境启用它。
持续集成
我们建议对开发人员计算机和持续集成 (CI) 服务器使用守护程序。
兼容性
如果不存在空闲或兼容的守护进程,Gradle 会启动一个新的守护进程。
以下值决定兼容性:
-
请求的构建环境,包括以下内容:
-
Java版本
-
JVM 属性
-
JVM 属性
-
-
摇篮版本
兼容性基于这些值的精确匹配。例如:
-
如果守护程序可用于 Java 8 运行时,但请求的构建环境调用 Java 10,则该守护程序不兼容。
-
如果守护进程可运行 Gradle 7.0,但当前构建使用 Gradle 7.4,则该守护进程不兼容。
Java 运行时的某些属性是不可变的:一旦 JVM 启动,它们就无法更改。以下 JVM 系统属性是不可变的:
-
file.encoding -
user.language -
user.country -
user.variant -
java.io.tmpdir -
javax.net.ssl.keyStore -
javax.net.ssl.keyStorePassword -
javax.net.ssl.keyStoreType -
javax.net.ssl.trustStore -
javax.net.ssl.trustStorePassword -
javax.net.ssl.trustStoreType -
com.sun.management.jmxremote
以下由启动参数控制的 JVM 属性也是不可变的:
-
最大堆大小(
-XmxJVM 参数) -
最小堆大小(
-XmsJVM 参数) -
启动类路径(
-Xbootclasspath参数) -
“断言”状态(
-ea参数)
如果任何这些特性和属性的请求构建环境要求与守护程序的 JVM 要求不同,则守护程序不兼容。
|
笔记
|
有关构建环境的更多信息,请参阅构建环境文档。 |
性能影响
当您重复构建同一项目时,守护进程可以将构建时间缩短 15-75%。
|
提示
|
要了解守护进程对您的构建的影响,您可以使用 来分析您的构建--profile。
|
在构建之间,守护进程空闲地等待下一个构建。因此,您的机器只会在多次构建时将 Gradle 加载到内存中一次,而不是每次构建一次。这是一项重大的性能优化。
运行时代码优化
JVM 通过运行时代码优化获得了显着的性能:在代码运行时应用优化。
OpenJDK 的 Hotspot 等 JVM 实现会在执行过程中逐步优化代码。因此,纯粹由于此优化过程,后续构建可以更快。
使用守护进程,项目的第 1次和第 10次构建之间的感知构建时间可能会大幅缩短。
性能监控
Gradle 主动监视堆使用情况以检测守护进程中的内存泄漏。
当内存泄漏耗尽可用堆空间时,守护进程:
-
完成当前正在运行的构建。
-
在运行下一个构建之前重新启动。
Gradle 默认启用此监控。
要禁用此监视,请将org.gradle.daemon.performance.enable-monitoringDaemon 选项设置为false。
您可以使用以下命令在命令行上执行此操作:
$ gradle <task> -Dorg.gradle.daemon.performance.enable-monitoring=false
gradle.properties或者您可以在项目根目录或 GRADLE_USER_HOME(Gradle 用户主页)的文件中配置该属性:
org.gradle.daemon.performance.enable-monitoring=false文件系统监视
Gradle 维护一个虚拟文件系统 (VFS) 来计算在项目的重复构建中需要重建的内容。通过监视文件系统,Gradle 在构建之间保持 VFS 最新。
使能够
自 Gradle 7 起,Gradle 默认为受支持的操作系统启用文件系统监视。
使用“--watch-fs”标志运行构建,以强制文件系统监视构建。
要强制文件系统监视所有构建(除非使用 禁用--no-watch-fs),请将以下值添加到gradle.properties:
org.gradle.vfs.watch=true支持的操作系统
Gradle 使用本机操作系统功能来监视文件系统。 Gradle 支持以下操作系统上的文件系统监视:
-
Windows 10 版本 1709 及更高版本
-
Linux,在以下发行版上进行了测试:
-
Ubuntu 16.04 或更高版本
-
CentOS Stream 8 或更高版本
-
红帽企业 Linux (RHEL) 8 或更高版本
-
Amazon Linux 2 或更高版本
-
-
Intel 和 ARM 架构上的 macOS 10.14 (Mojave) 或更高版本
支持的文件系统
文件系统监视支持以下文件系统类型:
-
APFS
-
BTFS
-
外部3
-
外部4
-
XFS
-
高频FS+
-
NTFS
Gradle 还支持 VirtualBox 的共享文件夹。
不支持 Samba 和 NFS 等网络文件系统。
文件系统监视与符号链接不兼容。如果您的项目文件包含符号链接,则符号链接文件不会从文件系统监视优化中受益。
不支持的文件系统
默认启用时,文件系统监视在遇到不受支持的文件系统上的内容时会采取保守的行为。如果您从网络驱动器挂载项目目录或子目录,则可能会发生这种情况。默认情况下启用时,Gradle 不会在构建之间保留有关不支持的文件系统的信息。如果您显式启用文件系统监视,Gradle 会在构建之间保留有关不支持的文件系统的信息。
记录
要在构建开始和结束时查看有关虚拟文件系统 (VFS) 更改的信息,请启用详细 VFS 日志记录。
org.gradle.vfs.verbose将Daemon 选项设置为true启用详细日志记录。
您可以使用以下命令在命令行上执行此操作:
$ gradle <task> -Dorg.gradle.vfs.verbose=true
gradle.properties或者在项目根目录或 Gradle 用户主页的文件中配置属性:
org.gradle.vfs.verbose=true这会在构建开始和结束时产生以下输出:
$ gradle assemble --watch-fs -Dorg.gradle.vfs.verbose=true
Received 3 file system events since last build while watching 1 locations Virtual file system retained information about 2 files, 2 directories and 0 missing files since last build > Task :compileJava NO-SOURCE > Task :processResources NO-SOURCE > Task :classes UP-TO-DATE > Task :jar UP-TO-DATE > Task :assemble UP-TO-DATE BUILD SUCCESSFUL in 58ms 1 actionable task: 1 up-to-date Received 5 file system events during the current build while watching 1 locations Virtual file system retains information about 3 files, 2 directories and 2 missing files until next build
在 Windows 和 macOS 上,Gradle 可能会报告自上次构建以来收到的更改,即使您没有更改任何内容。这些是有关 Gradle 缓存更改的无害通知,可以安全地忽略。
故障排除
- Gradle 未检测到某些更改
-
请在 Gradle 社区 Slack 上告诉我们。 如果构建正确声明其输入和输出,则不应发生这种情况。因此,这要么是我们必须修复的错误,要么是您的构建缺少某些输入或输出的声明。
- 由于状态丢失,VFS 状态下降
-
Dropped VFS state due to lost state您是否收到在构建期间 读取的消息?请在 Gradle 社区 Slack 上告诉我们。 这意味着您的构建无法从文件系统监视中受益,原因如下:-
守护进程收到未知的文件系统事件
-
发生了太多的变化,并且观察 API 无法处理它
-
- macOS 上打开的文件过多
-
如果您
java.io.IOException: Too many open files在 macOS 上收到错误消息,请提高打开的文件限制。请参阅这篇文章了解更多详细信息。
调整 Linux 上的 inotify 限制
Linux 上的文件系统监视使用inotify。根据构建的大小,可能需要增加 inotify 限制。如果您使用的是 IDE,那么您过go可能已经不得不增加限制。
文件系统监视对每个监视目录使用一个 inotify 监视。您可以通过运行以下命令查看每个用户 inotify 监视的当前限制:
cat /proc/sys/fs/inotify/max_user_watches要将限制增加到例如 512K 手表,请运行以下命令:
echo fs.inotify.max_user_watches=524288 | sudo tee -a /etc/sysctl.confsudo sysctl -p --system每个使用的 inotify watch 最多占用 1KB 内存。假设 inotify 使用所有 512K 监视,那么文件系统监视可能会使用最多 500MB。在内存受限的环境中,您可能需要禁用文件系统监视。
增量构建
任何构建工具的一个重要部分是能够避免执行已经完成的工作。考虑一下编译过程。一旦编译了源文件,就不需要重新编译它们,除非发生了影响输出的更改,例如源文件的修改或输出文件的删除。编译可能会花费大量时间,因此在不需要时跳过该步骤可以节省大量时间。
Gradle 通过称为增量构建的功能开箱即用地支持这种行为。您几乎肯定已经看到了它的实际应用。当您运行任务并且该任务UP-TO-DATE在控制台输出中标记为 时,这意味着增量构建正在工作。
增量构建如何工作?如何确保您的任务支持增量运行?让我们来看看。
任务输入和输出
在最常见的情况下,任务接受一些输入并生成一些输出。我们可以将Java编译的过程视为一个任务的例子。 Java 源文件充当任务的输入,而生成的类文件(即编译结果)是任务的输出。

输入的一个重要特征是它会影响一个或多个输出,如上图所示。根据源文件的内容和要运行代码的 Java 运行时的最低版本,生成不同的字节码。这使他们成为任务输入。但是编译是否具有 500MB 还是 600MB 的最大可用内存(由属性决定memoryMaximumSize)对生成的字节码没有影响。在 Gradle 术语中,memoryMaximumSize只是一个内部任务属性。
作为增量构建的一部分,Gradle 测试自上次构建以来是否有任何任务输入或输出发生更改。如果没有,Gradle 可以认为该任务是最新的,因此跳过执行其操作。另请注意,除非任务至少有一个任务输出,否则增量构建将无法工作,尽管任务通常也至少有一个输入。
这对于构建作者来说意味着很简单:您需要告诉 Gradle 哪些任务属性是输入,哪些是输出。如果任务属性影响输出,请务必将其注册为输入,否则任务将被视为最新,但实际上并非如此。相反,如果属性不影响输出,则不要将属性注册为输入,否则任务可能会在不需要时执行。另请注意非确定性任务,这些任务可能会为完全相同的输入生成不同的输出:这些任务不应配置为增量构建,因为最新检查将不起作用。
现在让我们看看如何将任务属性注册为输入和输出。
通过注释声明输入和输出
如果您将自定义任务作为类实现,则只需两个步骤即可使其与增量构建一起使用:
-
为每个任务输入和输出创建类型化属性(通过 getter 方法)
-
为每个属性添加适当的注释
|
笔记
|
注释必须放置在 getter 或 Groovy 属性上。放置在 setter 上或放置在没有相应带注释 getter 的 Java 字段上的注释将被忽略。 |
Gradle 支持四种主要类别的输入和输出:
-
简单的值
像字符串和数字之类的东西。更一般地,简单值可以具有任何实现
Serializable. -
文件系统类型
它们包括
RegularFile、Directory标准File类,还包括 Gradle 的FileCollection类型的派生类以及可以传递给Project.file(java.lang.Object)方法(对于单个文件/目录属性)或Project.files( java.lang.Object...)方法。 -
依赖解析结果
这包括工件元数据的ResolvedArtifactResult类型和依赖关系图的ResolvedComponentResult类型。请注意,它们仅支持包装在
Provider. -
嵌套值
自定义类型不符合其他两个类别,但具有自己的输入或输出属性。实际上,任务输入或输出嵌套在这些自定义类型内。
举个例子,假设您有一个处理不同类型模板的任务,例如 FreeMarker、Velocity、Moustache 等。它采用模板源文件并将它们与一些模型数据组合以生成模板文件的填充版本。
该任务将具有三个输入和一个输出:
-
模板源文件
-
型号数据
-
模板引擎
-
输出文件写入的位置
当您编写自定义任务类时,可以轻松地通过注释将属性注册为输入或输出。为了进行演示,这里是一个骨架任务实现,其中包含一些合适的输入和输出及其注释:
package org.example;
import java.util.HashMap;
import org.gradle.api.DefaultTask;
import org.gradle.api.file.ConfigurableFileCollection;
import org.gradle.api.file.DirectoryProperty;
import org.gradle.api.file.FileSystemOperations;
import org.gradle.api.provider.Property;
import org.gradle.api.tasks.*;
import javax.inject.Inject;
public abstract class ProcessTemplates extends DefaultTask {
@Input
public abstract Property<TemplateEngineType> getTemplateEngine();
@InputFiles
public abstract ConfigurableFileCollection getSourceFiles();
@Nested
public abstract TemplateData getTemplateData();
@OutputDirectory
public abstract DirectoryProperty getOutputDir();
@Inject
public abstract FileSystemOperations getFs();
@TaskAction
public void processTemplates() {
// ...
}
}package org.example;
import org.gradle.api.provider.MapProperty;
import org.gradle.api.provider.Property;
import org.gradle.api.tasks.Input;
public abstract class TemplateData {
@Input
public abstract Property<String> getName();
@Input
public abstract MapProperty<String, String> getVariables();
}gradle processTemplates> gradle processTemplates > Task :processTemplates BUILD SUCCESSFUL in 0s 3 actionable tasks: 3 up-to-date
gradle processTemplates (run again)> gradle processTemplates > Task :processTemplates UP-TO-DATE BUILD SUCCESSFUL in 0s 3 actionable tasks: 3 up-to-date
此示例中有很多内容要讨论,因此让我们依次讨论每个输入和输出属性:
-
templateEngine表示在处理源模板时要使用哪个引擎,例如 FreeMarker、Velocity 等。您可以将其实现为字符串,但在本例中,我们选择了自定义枚举,因为它提供了更多的类型信息和安全性。由于枚举是
Serializable自动实现的,因此我们可以将其视为一个简单的值并使用注释@Input,就像我们使用String属性一样。 -
sourceFiles任务将处理的源模板。单个文件和文件集合需要它们自己的特殊注释。在本例中,我们正在处理输入文件的集合,因此我们使用注释
@InputFiles。稍后您将在表格中看到更多面向文件的注释。 -
templateData对于此示例,我们使用自定义类来表示模型数据。但是,它没有实现
Serializable,所以我们不能使用@Input注释。这不是问题,因为其中的属性TemplateData(字符串和具有可序列化类型参数的哈希映射)是可序列化的,并且可以用@Input.我们使用@NestedontemplateData让 Gradle 知道这是一个具有嵌套输入属性的值。 -
outputDir生成的文件所在的目录。与输入文件一样,输出文件和目录也有多个注释。代表单个目录的属性需要
@OutputDirectory.您很快就会了解其他人。
这些带注释的属性意味着,如果自上次 Gradle 执行任务以来源文件、模板引擎、模型数据或生成的文件都没有发生更改,Gradle 将跳过该任务。这通常会节省大量时间。您可以稍后了解 Gradle 如何检测更改。
这个示例特别有趣,因为它适用于源文件集合。如果仅更改一个源文件会发生什么情况?该任务是再次处理所有源文件还是仅处理修改后的文件?这取决于任务的执行情况。如果是后者,那么任务本身就是增量的,但这与我们在这里讨论的功能不同。 Gradle 确实通过其增量任务输入功能帮助任务实施者完成此任务。
现在您已经在实践中看到了一些输入和输出注释,让我们看一下您可以使用的所有注释以及何时应该使用它们。下表列出了可用的注释以及每个注释可以使用的相应属性类型。
| 注解 | 预期财产类型 | 描述 |
|---|---|---|
任何 |
简单的输入值或依赖解析结果 |
|
|
单个输入文件(不是目录) |
|
|
单个输入目录(不是文件) |
|
|
输入文件和目录的可迭代 |
|
|
表示 Java 类路径的输入文件和目录的可迭代。这允许任务忽略对属性的不相关更改,例如相同文件的不同名称。它与注释属性类似 注意:该 |
|
|
表示 Java 编译类路径的输入文件和目录的可迭代。这允许任务忽略不影响类路径中类的 API 的不相关更改。另请参阅使用类路径注释。 以下类型的类路径更改将被忽略:
注意- 该 |
|
|
单个输出文件(不是目录) |
|
|
单个输出目录(不是文件) |
|
|
输出文件的可迭代或映射。使用文件树会关闭任务的缓存。 |
|
|
输出目录的可迭代。使用文件树会关闭任务的缓存。 |
|
|
指定此任务删除的一个或多个文件。请注意,任务可以定义输入/输出或可破坏项,但不能同时定义两者。 |
|
|
指定代表任务本地状态的一个或多个文件。从缓存加载任务时,这些文件将被删除。 |
|
任何自定义类型 |
一种自定义类型,可能无法实现 |
|
任何类型 |
指示该属性既不是输入也不是输出。它只是以某种方式影响任务的控制台输出,例如增加或减少任务的详细程度。 |
|
任何类型 |
指示该属性在内部使用,但既不是输入也不是输出。 |
|
任何类型 |
指示该属性已被另一个属性替换,并且作为输入或输出应被忽略。 |
|
|
暗示 |
|
|
|
|
任何类型 |
||
|
||
|
|
|
|
|
|
笔记
|
与上面类似, |
注解继承自所有父类型,包括实现的接口。属性类型注释会覆盖父类型中声明的任何其他属性类型注释。这样,@InputFile属性就可以变成@InputDirectory子任务类型中的属性。
类型中声明的属性上的注释会覆盖超类和任何已实现的接口中声明的类似注释。超类注释优先于已实现接口中声明的注释。
表中的控制台和内部注释是特殊情况,因为它们不声明任务输入或任务输出。那么为什么要使用它们呢?这样您就可以利用Java Gradle Plugin Development 插件来帮助您开发和发布自己的插件。该插件检查自定义任务类的任何属性是否缺少增量构建注释。这可以防止您在开发过程中忘记添加适当的注释。
使用依赖性解析结果
依赖关系解析结果可以通过两种方式用作任务输入。首先,使用ResolvedComponentResult使用已解析元数据的图表。其次,使用ResolvedArtifactResult消耗已解析工件的平面集。
可以从 a 的传入解析结果中延迟获取解析图Configuration并将其连接到@Input属性:
link:https://docs.gradle.org/8.7/samples/writing-tasks/tasks-with-dependency-resolution-result-inputs/common/dependency-reports/src/main/java/com/example/GraphResolvedComponents.java[role=include]link:https://docs.gradle.org/8.7/samples/writing-tasks/tasks-with-dependency-resolution-result-inputs/common/dependency-reports/src/main/java/com/example/DependencyReportsPlugin.java[role=include]已解析的工件集可以从 的传入工件中延迟获取Configuration。鉴于ResolvedArtifactResult类型包含元数据和文件信息,实例仅在连接到属性之前需要转换为元数据@Input:
link:https://docs.gradle.org/8.7/samples/writing-tasks/tasks-with-dependency-resolution-result-inputs/common/dependency-reports/src/main/java/com/example/ListResolvedArtifacts.java[role=include]link:https://docs.gradle.org/8.7/samples/writing-tasks/tasks-with-dependency-resolution-result-inputs/common/dependency-reports/src/main/java/com/example/DependencyReportsPlugin.java[role=include]图形和平面结果都可以与解析的文件信息组合和增强。这一切都在具有依赖性解析结果输入的任务示例中进行了演示。
使用类路径注释
此外@InputFiles,对于 JVM 相关任务,Gradle 理解类路径输入的概念。当 Gradle 寻找更改时,运行时和编译类路径的处理方式有所不同。
与用 注释的输入属性相反,对于类路径属性,文件集合中条目的顺序很重要。另一方面,类路径本身上的目录和 jar 文件的名称和路径将被忽略。时间戳以及类路径上的 jar 文件内的类文件和资源的顺序也会被忽略,因此使用不同的文件日期重新创建 jar 文件不会使任务过时。@InputFiles
用 注释的输入属性被视为 Java 编译类路径。除了前面提到的一般类路径规则之外,编译类路径会忽略除类文件之外的所有内容的更改。 Gradle 使用Java 避免编译中描述的相同类分析来进一步过滤不影响类 ABI 的更改。这意味着仅涉及类实现的更改不会使任务过时。@CompileClasspath
嵌套输入
在分析声明的输入和输出子属性的任务属性时,Gradle 使用实际值的类型。因此,它可以发现运行时子类型声明的所有子属性。@Nested
添加到可迭代对象时,每个元素都被视为单独的嵌套输入。可迭代中的每个嵌套输入都分配有一个名称,默认情况下是美元符号后跟可迭代中的索引,例如。如果可迭代的元素实现了,则该名称将用作属性名称。如果不是所有元素都实现,则可迭代中元素的排序对于可靠的最新检查和缓存至关重要。不允许多个元素具有相同的名称。@Nested$2NamedNamed
添加到映射时,将为每个值添加一个嵌套输入,使用键作为名称。@Nested
嵌套输入的类型和类路径也会被跟踪。这确保了对嵌套输入的实现的更改会导致构建过时。通过这种方式,还可以添加用户提供的代码作为输入,例如通过用 注释属性。请注意,应通过操作上带注释的属性或通过在任务中手动注册它们来跟踪此类操作的任何输入。@Action@Nested
这使我们能够对 JaCoCo Java 代理进行建模,从而声明必要的 JVM 参数并向 Gradle 提供输入和输出:
class JacocoAgent implements CommandLineArgumentProvider {
private final JacocoTaskExtension jacoco;
public JacocoAgent(JacocoTaskExtension jacoco) {
this.jacoco = jacoco;
}
@Nested
@Optional
public JacocoTaskExtension getJacoco() {
return jacoco.isEnabled() ? jacoco : null;
}
@Override
public Iterable<String> asArguments() {
return jacoco.isEnabled() ? ImmutableList.of(jacoco.getAsJvmArg()) : Collections.<String>emptyList();
}
}
test.getJvmArgumentProviders().add(new JacocoAgent(extension));为此,JacocoTaskExtension需要有正确的输入和输出注释。
该方法适用于测试 JVM 参数,因为Test.getJvmArgumentProviders()是Iterable用.@Nested
还有其他任务类型可以使用此类嵌套输入:
-
JavaExec.getArgumentProviders() - 模型,例如自定义工具
-
JavaExec.getJvmArgumentProviders() - 用于 Jacoco Java 代理
-
CompileOptions.getCompilerArgumentProviders() - 模型,例如注释处理器
-
Exec.getArgumentProviders() - 模型,例如自定义工具
-
JavaCompile.getOptions().getForkOptions().getJvmArgumentProviders() - 模型 Java 编译器守护进程命令行参数
-
GroovyCompile.getGroovyOptions().getForkOptions().getJvmArgumentProviders() - 模型 Groovy 编译器守护进程命令行参数
-
ScalaCompile.getScalaOptions().getForkOptions().getJvmArgumentProviders() - 模型 Scala 编译器守护进程命令行参数
同样,这种建模也可用于自定义任务。
运行时验证
执行构建 Gradle 时会检查是否使用正确的注释声明了任务类型。它尝试识别问题,例如在不兼容的类型或 setter 等上使用注释。任何未使用输入/输出注释注释的 getter 也会被标记。然后,这些问题会使构建失败,或者在执行任务时变成弃用警告。
具有验证警告的任务将在不进行任何优化的情况下执行。具体来说,它们永远不可能:
在执行无效任务之前,文件系统状态(虚拟文件系统)的内存表示也会失效。
通过运行时 API 声明输入和输出
自定义任务类是将您自己的构建逻辑带入增量构建领域的简单方法,但您并不总是有这种选择。这就是为什么 Gradle 还提供了一个可用于任何任务的替代 API,我们接下来会介绍它。
当您无权访问自定义任务类的源代码时,就无法添加我们在上一节中介绍的任何注释。幸运的是,Gradle 为类似的场景提供了运行时 API。它还可以用于临时任务,正如您接下来将看到的。
声明临时任务的输入和输出
这个运行时 API 是通过几个适当命名的属性提供的,这些属性在每个 Gradle 任务上都可用:
这些对象具有允许您指定构成任务输入和输出的文件、目录和值的方法。事实上,运行时 API 几乎与注释具有同等的功能。
它缺乏等价物
让我们看一下之前的模板处理示例,看看它作为使用运行时 API 的临时任务会是什么样子:
tasks.register("processTemplatesAdHoc") {
inputs.property("engine", TemplateEngineType.FREEMARKER)
inputs.files(fileTree("src/templates"))
.withPropertyName("sourceFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.property("templateData.name", "docs")
inputs.property("templateData.variables", mapOf("year" to "2013"))
outputs.dir(layout.buildDirectory.dir("genOutput2"))
.withPropertyName("outputDir")
doLast {
// Process the templates here
}
}tasks.register('processTemplatesAdHoc') {
inputs.property('engine', TemplateEngineType.FREEMARKER)
inputs.files(fileTree('src/templates'))
.withPropertyName('sourceFiles')
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.property('templateData.name', 'docs')
inputs.property('templateData.variables', [year: '2013'])
outputs.dir(layout.buildDirectory.dir('genOutput2'))
.withPropertyName('outputDir')
doLast {
// Process the templates here
}
}gradle processTemplatesAdHoc> gradle processTemplatesAdHoc > Task :processTemplatesAdHoc BUILD SUCCESSFUL in 0s 3 actionable tasks: 3 executed
和以前一样,有很多话要说。首先,您确实应该为此编写一个自定义任务类,因为它是一个具有多个配置选项的重要实现。在这种情况下,没有任务属性来存储根源文件夹、输出目录的位置或任何其他设置。这是故意强调这样一个事实:运行时 API 不要求任务具有任何状态。在增量构建方面,上述临时任务的行为与自定义任务类相同。
inputs所有的输入和输出定义都是通过和上的方法完成的outputs,例如property()、files()、 和dir()。 Gradle 对参数值执行最新检查,以确定任务是否需要再次运行。每个方法对应于增量构建注释之一,例如inputs.property()映射到@Input和outputs.dir()映射到@OutputDirectory.
可以通过 指定任务删除的文件destroyables.register()。
tasks.register("removeTempDir") {
val tmpDir = layout.projectDirectory.dir("tmpDir")
destroyables.register(tmpDir)
doLast {
tmpDir.asFile.deleteRecursively()
}
}tasks.register('removeTempDir') {
def tempDir = layout.projectDirectory.dir('tmpDir')
destroyables.register(tempDir)
doLast {
tempDir.asFile.deleteDir()
}
}运行时 API 和注释之间的一个显着区别是缺乏直接对应于@Nested.这就是为什么该示例property()对模板数据使用两个声明,每个TemplateData属性一个声明。在使用带有嵌套值的运行时 API 时,您应该使用相同的技术。任何给定的任务都可以声明可销毁对象或输入/输出,但不能同时声明两者。
细粒度配置
运行时 API 方法仅允许您在自身中声明输入和输出。然而,面向文件的构建器返回一个类型为TaskInputFilePropertyBuilder的构建器,它允许您提供有关这些输入和输出的附加信息。
您可以在其 API 文档中了解构建器提供的所有选项,但我们将在此处向您展示一个简单的示例,让您了解可以做什么。
processTemplates假设如果没有源文件,我们不想运行该任务,无论它是否是干净的构建。毕竟,如果没有源文件,任务就无事可做。构建器允许我们像这样配置:
tasks.register("processTemplatesAdHocSkipWhenEmpty") {
// ...
inputs.files(fileTree("src/templates") {
include("**/*.fm")
})
.skipWhenEmpty()
.withPropertyName("sourceFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
.ignoreEmptyDirectories()
// ...
}tasks.register('processTemplatesAdHocSkipWhenEmpty') {
// ...
inputs.files(fileTree('src/templates') {
include '**/*.fm'
})
.skipWhenEmpty()
.withPropertyName('sourceFiles')
.withPathSensitivity(PathSensitivity.RELATIVE)
.ignoreEmptyDirectories()
// ...
}gradle clean processTemplatesAdHocSkipWhenEmpty> gradle clean processTemplatesAdHocSkipWhenEmpty > Task :processTemplatesAdHocSkipWhenEmpty NO-SOURCE BUILD SUCCESSFUL in 0s 3 actionable tasks: 2 executed, 1 up-to-date
该TaskInputs.files()方法返回一个具有skipWhenEmpty()方法的构建器。调用此方法相当于用 注释该属性@SkipWhenEmpty。
现在您已经了解了注释和运行时 API,您可能想知道应该使用哪个 API。我们的建议是尽可能使用注释,有时值得创建一个自定义任务类,以便您可以使用它们。运行时 API 更多地适用于无法使用注释的情况。
声明自定义任务类型的输入和输出
另一种类型的示例涉及为自定义任务类的实例注册附加输入和输出。例如,假设ProcessTemplates任务也需要读取src/headers/headers.txt(例如,因为它是从源之一包含的)。您希望 Gradle 了解此输入文件,以便每当此文件的内容发生更改时它都可以重新执行任务。使用运行时 API,您可以做到这一点:
tasks.register<ProcessTemplates>("processTemplatesWithExtraInputs") {
// ...
inputs.file("src/headers/headers.txt")
.withPropertyName("headers")
.withPathSensitivity(PathSensitivity.NONE)
}tasks.register('processTemplatesWithExtraInputs', ProcessTemplates) {
// ...
inputs.file('src/headers/headers.txt')
.withPropertyName('headers')
.withPathSensitivity(PathSensitivity.NONE)
}像这样使用运行时 API 有点像使用doLast()和doFirst()为任务附加额外的操作,只不过在这种情况下我们附加有关输入和输出的信息。
|
警告
|
如果任务类型已经在使用增量构建注释,则使用相同的属性名称注册输入或输出将导致错误。 |
声明任务输入和输出的好处
一旦您声明了任务的正式输入和输出,Gradle 就可以推断有关这些属性的信息。例如,如果一个任务的输入设置为另一个任务的输出,则意味着第一个任务依赖于第二个任务,对吧? Gradle 知道这一点并且可以据此采取行动。
接下来我们将了解此功能以及来自 Gradle 的一些其他功能,了解有关输入和输出的信息。
推断任务依赖关系
考虑一个打包任务输出的归档任务processTemplates。构建作者会发现存档任务显然需要processTemplates首先运行,因此可能会添加显式的dependsOn.但是,如果您像这样定义存档任务:
tasks.register<Zip>("packageFiles") {
from(processTemplates.map { it.outputDir })
}tasks.register('packageFiles', Zip) {
from processTemplates.map { it.outputDir }
}gradle clean packageFiles> gradle clean packageFiles > Task :processTemplates > Task :packageFiles BUILD SUCCESSFUL in 0s 5 actionable tasks: 4 executed, 1 up-to-date
Gradle 会自动packageFiles依赖processTemplates.它可以执行此操作,因为它知道 packageFiles 的输入之一需要 processTemplates 任务的输出。我们称之为推断任务依赖性。
上面的例子也可以写成
tasks.register<Zip>("packageFiles2") {
from(processTemplates)
}tasks.register('packageFiles2', Zip) {
from processTemplates
}gradle clean packageFiles2> gradle clean packageFiles2 > Task :processTemplates > Task :packageFiles2 BUILD SUCCESSFUL in 0s 5 actionable tasks: 4 executed, 1 up-to-date
这是因为该from()方法可以接受任务对象作为参数。在幕后,from()使用该project.files()方法来包装参数,从而将任务的正式输出公开为文件集合。也就是说,这是一个特例!
输入和输出验证
增量构建注释为 Gradle 提供了足够的信息,以便对带注释的属性执行一些基本验证。特别是,它在任务执行之前对每个属性执行以下操作:
-
@InputFile- 验证属性是否具有值以及路径是否对应于存在的文件(而不是目录)。 -
@InputDirectory- 与 相同@InputFile,但路径必须对应于目录。 -
@OutputDirectory- 验证路径是否与文件不匹配,如果目录尚不存在,则创建该目录。
如果一个任务在某个位置生成输出,而另一个任务通过将该位置引用为输入来使用该位置,则 Gradle 会检查使用者任务是否依赖于生产者任务。当生产者和消费者任务同时执行时,构建无法避免捕获不正确的状态。
此类验证提高了构建的稳健性,使您能够快速识别与输入和输出相关的问题。
您有时会想要禁用某些验证,特别是当输入文件可能实际上不存在时。这就是 Gradle 提供@Optional注释的原因:您使用它来告诉 Gradle 特定输入是可选的,因此如果相应的文件或目录不存在,构建不应失败。
持续构建
定义任务输入和输出的另一个好处是持续构建。由于 Gradle 知道任务依赖哪些文件,因此如果任务的任何输入发生变化,它可以自动再次运行任务。通过在运行 Gradle 时激活持续构建(通过--continuous或-t选项),您将使 Gradle 进入一种状态,在这种状态下,它会不断检查更改并在遇到此类更改时执行请求的任务。
您可以在持续构建中找到有关此功能的更多信息。
任务并行性
定义任务输入和输出的最后一个好处是,Gradle 可以使用此信息来决定在使用“--parallel”选项时如何运行任务。例如,Gradle 在选择下一个要运行的任务时将检查任务的输出,并避免并发执行写入同一输出目录的任务。类似地,Gradle 将使用有关任务销毁哪些文件的信息(例如由Destroys注释指定),并避免运行删除一组文件的任务,而另一个任务正在运行消耗或创建这些相同的文件(反之亦然)。它还可以确定创建一组文件的任务已经运行,而使用这些文件的任务尚未运行,并且将避免运行在其间删除这些文件的任务。通过以这种方式提供任务输入和输出信息,Gradle 可以推断任务之间的创建/消耗/销毁关系,并可以确保任务执行不会违反这些关系。
它是如何工作的?
在第一次执行任务之前,Gradle 会获取输入的指纹。该指纹包含输入文件的路径以及每个文件内容的哈希值。然后 Gradle 执行该任务。如果任务成功完成,Gradle 会获取输出的指纹。该指纹包含输出文件集以及每个文件内容的哈希值。 Gradle 会在下次执行任务时保留这两个指纹。
此后每次执行任务之前,Gradle 都会获取输入和输出的新指纹。如果新指纹与之前的指纹相同,Gradle 会假定输出是最新的并跳过该任务。如果它们不相同,Gradle 就会执行任务。 Gradle 会在下次执行任务时保留这两个指纹。
如果文件的统计信息(即lastModified和size)没有更改,Gradle 将重用上次运行的文件指纹。这意味着当文件的统计信息未更改时,Gradle 不会检测到更改。
Gradle 还将任务的代码视为任务输入的一部分。当任务、其操作或其依赖项在执行之间发生变化时,Gradle 会认为该任务已过时。
Gradle 知道文件属性(例如保存 Java 类路径的属性)是否对顺序敏感。当比较此类属性的指纹时,即使文件顺序发生变化也会导致任务过时。
请注意,如果任务指定了输出目录,则自上次执行以来添加到该目录的任何文件都将被忽略,并且不会导致任务过期。这样,不相关的任务就可以共享输出目录,而不会互相干扰。如果由于某种原因这不是您想要的行为,请考虑使用TaskOutputs.upToDateWhen(groovy.lang.Closure)
另请注意,更改不可用文件的可用性(例如,将损坏的符号链接的目标修改为有效文件,或反之亦然)将通过最新检查进行检测和处理。
为了跟踪任务、任务操作和嵌套输入的实现,Gradle 使用类名和包含实现的类路径的标识符。在某些情况下,Gradle 无法精确跟踪实施情况:
- 未知的类加载器
-
当 Gradle 尚未创建加载实现的类加载器时,无法确定类路径。
- Java lambda
-
Java lambda 类是在运行时使用不确定的类名创建的。因此,类名并不标识 lambda 的实现,并且在不同的 Gradle 运行之间会发生变化。
当无法精确跟踪任务、任务操作或嵌套输入的实现时,Gradle 会禁用该任务的任何缓存。这意味着该任务永远不会是最新的或从构建缓存加载。
先进技术
到目前为止,您在本节中看到的所有内容都将涵盖您将遇到的大多数用例,但有一些场景需要特殊处理。接下来我们将介绍其中的一些以及适当的解决方案。
添加您自己的缓存输入/输出方法
你有没有想过任务from()的方法是如何Copy运作的?它没有注释@InputFiles,但传递给它的任何文件都被视为任务的正式输入。发生了什么?
实现非常简单,您可以对自己的任务使用相同的技术来改进他们的 API。编写您的方法,以便它们将文件直接添加到适当的带注释的属性中。作为示例,以下是如何向我们之前介绍的sources()自定义类添加方法:ProcessTemplates
tasks.register<ProcessTemplates>("processTemplates") {
templateEngine = TemplateEngineType.FREEMARKER
templateData.name = "test"
templateData.variables = mapOf("year" to "2012")
outputDir = layout.buildDirectory.dir("genOutput")
sources(fileTree("src/templates"))
}tasks.register('processTemplates', ProcessTemplates) {
templateEngine = TemplateEngineType.FREEMARKER
templateData.name = 'test'
templateData.variables = [year: '2012']
outputDir = file(layout.buildDirectory.dir('genOutput'))
sources fileTree('src/templates')
}public abstract class ProcessTemplates extends DefaultTask {
// ...
@SkipWhenEmpty
@InputFiles
@PathSensitive(PathSensitivity.NONE)
public abstract ConfigurableFileCollection getSourceFiles();
public void sources(FileCollection sourceFiles) {
getSourceFiles().from(sourceFiles);
}
// ...
}gradle processTemplates> gradle processTemplates > Task :processTemplates BUILD SUCCESSFUL in 0s 3 actionable tasks: 3 executed
换句话说,只要您在配置阶段将值和文件添加到正式任务输入和输出中,无论您在构建中的何处添加它们,它们都会被视为此类。
如果我们也想支持任务作为参数并将其输出视为输入,我们可以TaskProvider直接使用,如下所示:
val copyTemplates by tasks.registering(Copy::class) {
into(file(layout.buildDirectory.dir("tmp")))
from("src/templates")
}
tasks.register<ProcessTemplates>("processTemplates2") {
// ...
sources(copyTemplates)
}def copyTemplates = tasks.register('copyTemplates', Copy) {
into file(layout.buildDirectory.dir('tmp'))
from 'src/templates'
}
tasks.register('processTemplates2', ProcessTemplates) {
// ...
sources copyTemplates
} // ...
public void sources(TaskProvider<?> inputTask) {
getSourceFiles().from(inputTask);
}
// ...gradle processTemplates2> gradle processTemplates2 > Task :copyTemplates > Task :processTemplates2 BUILD SUCCESSFUL in 0s 4 actionable tasks: 4 executed
此技术可以使您的自定义任务更易于使用,并生成更清晰的构建文件。作为一个额外的好处,我们的使用TaskProvider意味着我们的自定义方法可以设置推断的任务依赖性。
最后要注意的一点是:如果您正在开发一个将源文件集合作为输入的任务(如本例所示),请考虑使用内置SourceTask。这将使您不必实施我们投入的一些管道ProcessTemplates。
将 an 链接@OutputDirectory到 an@InputFiles
当您想要将一个任务的输出链接到另一任务的输入时,类型通常匹配,并且简单的属性分配将提供该链接。例如,File可以将输出属性分配给File输入。
@OutputDirectory不幸的是,当您希望一个任务(类型为)中的文件File成为另一个任务@InputFiles属性(类型为FileCollection)的源时,这种方法就会失效。由于两者的类型不同,因此属性分配不起作用。
举个例子,假设您想要使用 Java 编译任务的输出(通过属性destinationDir)作为自定义任务的输入,该任务对一组包含 Java 字节码的文件进行检测。这个自定义任务(我们称之为Instrument)有一个classFiles用 注释的属性@InputFiles。您最初可能会尝试像这样配置任务:
plugins {
id("java-library")
}
tasks.register<Instrument>("badInstrumentClasses") {
classFiles.from(fileTree(tasks.compileJava.flatMap { it.destinationDirectory }))
destinationDir = layout.buildDirectory.dir("instrumented")
}plugins {
id 'java-library'
}
tasks.register('badInstrumentClasses', Instrument) {
classFiles.from fileTree(tasks.named('compileJava').flatMap { it.destinationDirectory }) {}
destinationDir = file(layout.buildDirectory.dir('instrumented'))
}gradle clean badInstrumentClasses> gradle clean badInstrumentClasses > Task :clean UP-TO-DATE > Task :badInstrumentClasses NO-SOURCE BUILD SUCCESSFUL in 0s 3 actionable tasks: 2 executed, 1 up-to-date
这段代码没有什么明显的错误,但是从控制台输出可以看到缺少编译任务。在这种情况下,您需要在instrumentClasses和compileJavavia之间添加显式任务依赖关系dependsOn。使用fileTree()意味着 Gradle 本身无法推断任务依赖关系。
一种解决方案是使用该TaskOutputs.files属性,如以下示例所示:
tasks.register<Instrument>("instrumentClasses") {
classFiles.from(tasks.compileJava.map { it.outputs.files })
destinationDir = layout.buildDirectory.dir("instrumented")
}tasks.register('instrumentClasses', Instrument) {
classFiles.from tasks.named('compileJava').map { it.outputs.files }
destinationDir = file(layout.buildDirectory.dir('instrumented'))
}gradle clean instrumentClasses> gradle clean instrumentClasses > Task :clean UP-TO-DATE > Task :compileJava > Task :instrumentClasses BUILD SUCCESSFUL in 0s 5 actionable tasks: 4 executed, 1 up-to-date
或者,您可以使用以下之一来让 Gradle 本身访问适当的属性project.files():project.layout.files()project.objects.fileCollection()project.fileTree()
tasks.register<Instrument>("instrumentClasses2") {
classFiles.from(layout.files(tasks.compileJava))
destinationDir = layout.buildDirectory.dir("instrumented")
}tasks.register('instrumentClasses2', Instrument) {
classFiles.from layout.files(tasks.named('compileJava'))
destinationDir = file(layout.buildDirectory.dir('instrumented'))
}gradle clean instrumentClasses2> gradle clean instrumentClasses2 > Task :clean UP-TO-DATE > Task :compileJava > Task :instrumentClasses2 BUILD SUCCESSFUL in 0s 5 actionable tasks: 4 executed, 1 up-to-date
请记住files(),layout.files()和objects.fileCollection()可以将任务作为参数,而fileTree()不能。
这种方法的缺点是,instrumentClasses在这种情况下,源任务的所有文件输出都会成为目标的输入文件。只要源任务只有一个基于文件的输出(如JavaCompile任务),就可以了。但是,如果您只需链接多个输出属性中的一个,那么您需要使用以下builtBy方法显式告诉 Gradle 哪个任务生成输入文件:
tasks.register<Instrument>("instrumentClassesBuiltBy") {
classFiles.from(fileTree(tasks.compileJava.flatMap { it.destinationDirectory }) {
builtBy(tasks.compileJava)
})
destinationDir = layout.buildDirectory.dir("instrumented")
}tasks.register('instrumentClassesBuiltBy', Instrument) {
classFiles.from fileTree(tasks.named('compileJava').flatMap { it.destinationDirectory }) {
builtBy tasks.named('compileJava')
}
destinationDir = file(layout.buildDirectory.dir('instrumented'))
}gradle clean instrumentClassesBuiltBy> gradle clean instrumentClassesBuiltBy > Task :clean UP-TO-DATE > Task :compileJava > Task :instrumentClassesBuiltBy BUILD SUCCESSFUL in 0s 5 actionable tasks: 4 executed, 1 up-to-date
您当然可以通过添加显式任务依赖项dependsOn,但上述方法提供了更多语义含义,解释了为什么compileJava必须预先运行。
禁用最新检查
Gradle 自动处理输出文件和目录的最新检查,但如果任务输出完全是其他内容怎么办?也许是对 Web 服务或数据库表的更新。或者有时您有一个应该始终运行的任务。
这就是doNotTrackState()on 方法的Task用武之地。人们可以使用它来完全禁用任务的最新检查,如下所示:
tasks.register<Instrument>("alwaysInstrumentClasses") {
classFiles.from(layout.files(tasks.compileJava))
destinationDir = layout.buildDirectory.dir("instrumented")
doNotTrackState("Instrumentation needs to re-run every time")
}tasks.register('alwaysInstrumentClasses', Instrument) {
classFiles.from layout.files(tasks.named('compileJava'))
destinationDir = file(layout.buildDirectory.dir('instrumented'))
doNotTrackState("Instrumentation needs to re-run every time")
}gradle clean alwaysInstrumentClasses> gradle clean alwaysInstrumentClasses > Task :compileJava > Task :alwaysInstrumentClasses BUILD SUCCESSFUL in 0s 4 actionable tasks: 1 executed, 3 up-to-date
gradle alwaysInstrumentClasses> gradle alwaysInstrumentClasses > Task :compileJava UP-TO-DATE > Task :alwaysInstrumentClasses BUILD SUCCESSFUL in 0s 4 actionable tasks: 1 executed, 3 up-to-date
如果您编写自己的始终应运行的任务,那么您还可以在任务类上使用注释,而不是调用.@UntrackedTaskTask.doNotTrackState()
集成一个外部工具,该工具可以进行自己的最新检查
有时您想要集成 Git 或 Npm 等外部工具,它们都会进行自己的最新检查。在这种情况下,Gradle 也进行最新检查就没有多大意义。您可以通过使用包装该工具的任务上的注释来禁用 Gradle 的最新检查。或者,您可以使用运行时 API 方法。@UntrackedTaskTask.doNotTrackState()
例如,假设您想要实现克隆 Git 存储库的任务。
@UntrackedTask(because = "Git tracks the state") // (1)
public abstract class GitClone extends DefaultTask {
@Input
public abstract Property<String> getRemoteUri();
@Input
public abstract Property<String> getCommitId();
@OutputDirectory
public abstract DirectoryProperty getDestinationDir();
@TaskAction
public void gitClone() throws IOException {
File destinationDir = getDestinationDir().get().getAsFile().getAbsoluteFile(); // (2)
String remoteUri = getRemoteUri().get();
// Fetch origin or clone and checkout
// ...
}
}tasks.register<GitClone>("cloneGradleProfiler") {
destinationDir = layout.buildDirectory.dir("gradle-profiler") // <3
remoteUri = "https://github.com/gradle/gradle-profiler.git"
commitId = "d6c18a21ca6c45fd8a9db321de4478948bdf801b"
}tasks.register("cloneGradleProfiler", GitClone) {
destinationDir = layout.buildDirectory.dir("gradle-profiler") // (3)
remoteUri = "https://github.com/gradle/gradle-profiler.git"
commitId = "d6c18a21ca6c45fd8a9db321de4478948bdf801b"
}-
将任务声明为未跟踪。
-
使用输出目录运行外部工具。
-
添加任务并在构建中配置输出目录。
配置输入标准化
为了进行最新检查和构建缓存,Gradle 需要确定两个任务输入属性是否具有相同的值。为此,Gradle 首先对两个输入进行标准化,然后比较结果。例如,对于编译类路径,Gradle 从类路径上的类中提取 ABI 签名,然后比较上次 Gradle 运行和当前 Gradle 运行之间的签名,如Java 编译避免中所述。
规范化适用于类路径上的所有 zip 文件(例如 jar、wars、aars、apk 等)。这允许 Gradle 识别两个 zip 文件何时功能相同,即使 zip 文件本身可能由于元数据(例如时间戳或文件顺序)而略有不同。规范化不仅适用于直接位于类路径上的 zip 文件,还适用于嵌套在目录内或类路径上其他 zip 文件内的 zip 文件。
可以自定义 Gradle 的内置策略来实现运行时类路径规范化。所有带注释的输入都被视为运行时类路径。@Classpath
假设您想要build-info.properties向所有生成的 jar 文件添加一个文件,其中包含有关构建的信息,例如构建开始时的时间戳或用于标识发布工件的 CI 作业的某个 ID。该文件仅用于审核目的,对运行测试的结果没有影响。尽管如此,该文件是任务的运行时类路径的一部分test,并且在每次构建调用时都会发生变化。因此,它test永远不会是最新的或从构建缓存中提取。为了再次从增量构建中受益,您可以使用Project.normalization(org.gradle.api.Action)(在使用项目中)告诉 Gradle 在项目级别忽略运行时类路径上的此文件:
normalization {
runtimeClasspath {
ignore("build-info.properties")
}
}normalization {
runtimeClasspath {
ignore 'build-info.properties'
}
}如果将这样的文件添加到 jar 文件中是您为构建中的所有项目所做的事情,并且您希望为所有使用者过滤此文件,那么您应该考虑在约定插件中配置此类规范化以在子项目之间共享它。
此配置的效果是,build-info.properties对于最新检查和构建缓存键计算,将忽略对 的更改。请注意,这不会改变test任务的运行时行为 - 即任何测试仍然能够加载build-info.properties,并且运行时类路径仍然与以前相同。
属性文件规范化
默认情况下,属性文件(即以扩展名结尾的文件.properties)将被标准化,以忽略注释、空格和属性顺序的差异。 Gradle 通过加载属性文件并在最新检查或构建缓存键计算期间仅考虑各个属性来实现此目的。
但有时某些属性会影响运行时,而其他属性则不会。如果属性的更改不会对运行时类路径产生影响,则可能需要将其从最新检查和构建缓存键计算中排除。但是,排除整个文件也会排除对运行时有影响的属性。在这种情况下,可以有选择地从运行时类路径上的任何或所有属性文件中排除属性。
可以使用RuntimeClasspathNormalization中描述的模式将忽略属性的规则应用于特定的文件集。如果文件与规则匹配,但无法作为属性文件加载(例如,因为格式不正确或使用非标准编码),则它将被合并到最新或构建缓存键中像普通文件一样计算。换句话说,如果文件无法作为属性文件加载,则对空格、属性顺序或注释的任何更改都可能导致任务过时或导致缓存未命中。
normalization {
runtimeClasspath {
properties("**/build-info.properties") {
ignoreProperty("timestamp")
}
}
}normalization {
runtimeClasspath {
properties('**/build-info.properties') {
ignoreProperty 'timestamp'
}
}
}normalization {
runtimeClasspath {
properties {
ignoreProperty("timestamp")
}
}
}normalization {
runtimeClasspath {
properties {
ignoreProperty 'timestamp'
}
}
}JavaMETA-INF规范化
对于 jar 存档目录中的文件,META-INF由于其运行时影响,并不总是可以完全忽略文件。
其中的清单文件META-INF被标准化以忽略注释、空格和顺序差异。清单属性名称的比较不区分大小写和顺序。清单属性文件根据Properties File Normalization进行规范化。
META-INF manifest attributesnormalization {
runtimeClasspath {
metaInf {
ignoreAttribute("Implementation-Version")
}
}
}normalization {
runtimeClasspath {
metaInf {
ignoreAttribute("Implementation-Version")
}
}
}META-INF property keysnormalization {
runtimeClasspath {
metaInf {
ignoreProperty("app.version")
}
}
}normalization {
runtimeClasspath {
metaInf {
ignoreProperty("app.version")
}
}
}META-INF/MANIFEST.MFnormalization {
runtimeClasspath {
metaInf {
ignoreManifest()
}
}
}normalization {
runtimeClasspath {
metaInf {
ignoreManifest()
}
}
}META-INFnormalization {
runtimeClasspath {
metaInf {
ignoreCompletely()
}
}
}normalization {
runtimeClasspath {
metaInf {
ignoreCompletely()
}
}
}提供自定义的最新逻辑
Gradle 自动处理输出文件和目录的最新检查,但如果任务输出完全是其他内容怎么办?也许是对 Web 服务或数据库表的更新。在这种情况下,Gradle 无法知道如何检查任务是否是最新的。
这就是upToDateWhen()on 方法的TaskOutputs用武之地。它采用一个谓词函数,用于确定任务是否是最新的。例如,您可以从数据库中读取数据库架构的版本号。或者,您可以检查数据库表中的特定记录是否存在或已更改。
请注意,最新的检查应该可以节省您的时间。不要添加花费与任务的标准执行相同或更多时间的检查。事实上,如果任务最终频繁运行,因为它很少是最新的,那么根本不值得进行最新检查,如禁用最新检查中所述。请记住,如果任务位于执行任务图中,您的检查将始终运行。
upToDateWhen()一个常见的错误是使用Task.onlyIf().如果您想根据与任务输入和输出无关的某些条件跳过任务,那么您应该使用onlyIf()。例如,如果您想在设置或未设置特定属性时跳过任务。
过时的任务输出
当 Gradle 版本更改时,Gradle 会检测到需要删除使用旧版本 Gradle 运行的任务的输出,以确保最新版本的任务从已知的干净状态启动。
|
笔记
|
仅针对源集的输出(Java/Groovy/Scala 编译)实现了过时输出目录的自动清理。 |
配置缓存
介绍
配置缓存是一项通过缓存配置阶段的结果并在后续构建中重用它来显着提高构建性能的功能。使用配置缓存,当没有任何影响构建配置(例如构建脚本)发生更改时,Gradle 可以完全跳过配置阶段。 Gradle 还将性能改进应用于任务执行。
配置缓存在概念上类似于构建缓存,但缓存不同的信息。构建缓存负责缓存构建的输出和中间文件,例如任务输出或工件转换输出。配置缓存负责缓存特定任务集的构建配置。换句话说,配置缓存保存配置阶段的输出,构建缓存保存执行阶段的输出。
|
重要的
|
目前默认情况下未启用此功能。此功能有以下限制:
|
它是如何工作的?
当启用配置缓存并且您为特定任务集运行 Gradle 时,例如通过运行gradlew check,Gradle 会检查配置缓存条目是否可用于请求的任务集。如果可用,Gradle 使用此条目而不是运行配置阶段。缓存条目包含有关要运行的任务集的信息,以及它们的配置和依赖性信息。
第一次运行一组特定的任务时,配置缓存中不会有这些任务的条目,因此 Gradle 将正常运行配置阶段:
-
运行初始化脚本。
-
运行构建的设置脚本,应用任何请求的设置插件。
-
配置并构建
buildSrc项目(如果存在)。 -
运行构建的构建脚本,应用任何请求的项目插件。
-
计算所请求任务的任务图,运行任何延迟的配置操作。
在配置阶段之后,Gradle 将任务图的快照写入新的配置缓存条目,以供以后的 Gradle 调用。然后,Gradle 从配置缓存中加载任务图,以便它可以对任务进行优化,然后正常运行执行阶段。首次运行一组特定任务时仍会花费配置时间。但是,您应该立即看到构建性能的提高,因为任务将并行运行。
当您随后使用同一组任务运行 Gradle 时(例如gradlew check再次运行),Gradle 将直接从配置缓存加载任务及其配置,并完全跳过配置阶段。在使用配置缓存条目之前,Gradle 会检查该条目的“构建配置输入”(例如构建脚本)是否已更改。如果构建配置输入已更改,Gradle 将不会使用该条目,并将如上所述再次运行配置阶段,保存结果以供以后重用。
构建配置输入包括:
-
初始化脚本
-
设置脚本
-
构建脚本
-
配置阶段使用的系统属性
-
配置阶段使用的 Gradle 属性
-
配置阶段使用的环境变量
-
使用价值提供者(例如提供商)访问的配置文件
-
buildSrc插件包含构建输入,包括构建配置输入和源文件。
Gradle 使用自己优化的序列化机制和格式来存储配置缓存条目。它自动序列化任意对象图的状态。如果您的任务保存对具有简单状态或受支持类型的对象的引用,则您无需执行任何操作来支持序列化。
作为后备方案并为迁移现有任务提供一些帮助,支持Java 序列化的一些语义。但不建议依赖它,主要是出于性能原因。
性能改进
除了跳过配置阶段之外,配置缓存还提供了一些额外的性能改进:
-
默认情况下,所有任务并行运行,但受依赖性约束。
-
依赖解析被缓存。
-
写入任务图后,配置状态和依赖解析状态将从堆中丢弃。这减少了给定任务集所需的峰值堆使用量。

使用配置缓存
建议从最简单的任务调用开始。启用配置缓存运行help是一个很好的第一步:
❯ gradle --configuration-cache help Calculating task graph as no cached configuration is available for tasks: help ... BUILD SUCCESSFUL in 4s 1 actionable task: 1 executed Configuration cache entry stored.
第一次运行它时,将执行配置阶段,计算任务图。
然后,再次运行相同的命令。这会重用缓存的配置:
❯ gradle --configuration-cache help Reusing configuration cache. ... BUILD SUCCESSFUL in 500ms 1 actionable task: 1 executed Configuration cache entry reused.
如果您的构建成功,那么恭喜您,您现在可以尝试更有用的任务。您应该瞄准您的开发循环。一个很好的例子是在进行增量更改后运行测试。
如果在缓存或重用配置时发现任何问题,则会生成 HTML 报告来帮助您诊断和修复问题。该报告还显示检测到的构建配置输入,例如系统属性、环境变量和在配置阶段读取的值提供者。有关详细信息,请参阅下面的故障排除部分。
继续阅读以了解如何调整配置缓存、在出现问题时手动使状态无效以及使用 IDE 中的配置缓存。
启用配置缓存
默认情况下,Gradle 不使用配置缓存。要在构建时启用缓存,请使用以下configuration-cache标志:
❯ gradle --configuration-cache
gradle.properties您还可以使用以下属性在文件中持久启用缓存org.gradle.configuration-cache:
org.gradle.configuration-cache=true如果在文件中启用gradle.properties,您可以覆盖该设置并在构建时使用以下标志禁用缓存no-configuration-cache:
❯ gradle --no-configuration-cache
忽视问题
默认情况下,如果遇到任何配置缓存问题,Gradle 将使构建失败。当逐渐改进插件或构建逻辑以支持配置缓存时,暂时将问题转变为警告可能会很有用,但不能保证构建能够正常工作。
这可以从命令行完成:
❯ gradle --configuration-cache-problems=warn
或在gradle.properties文件中:
org.gradle.configuration-cache.problems=warn允许最大数量的问题
当配置缓存问题变成警告时,如果512默认情况下发现问题,Gradle 将使构建失败。
这可以通过在命令行上指定允许的最大问题数来调整:
❯ gradle -Dorg.gradle.configuration-cache.max-problems=5
或在gradle.properties文件中:
org.gradle.configuration-cache.max-problems=5稳定的配置缓存
为了稳定配置缓存,当我们认为功能标志对于早期采用者来说太具有破坏性时,我们在功能标志后面实施了一些严格的要求。
您可以按如下方式启用该功能标志:
enableFeaturePreview("STABLE_CONFIGURATION_CACHE")enableFeaturePreview "STABLE_CONFIGURATION_CACHE"功能STABLE_CONFIGURATION_CACHE标志可以实现以下功能:
- 未声明的共享构建服务使用
-
启用后,使用共享构建服务而不通过该方法声明要求的任务
Task.usesService将发出弃用警告。
此外,当未启用配置缓存但存在功能标志时,还会启用以下配置缓存要求的弃用:
建议尽快启用它,以便为我们删除该标志并将链接的功能设为默认功能做好准备。
IDE支持
如果您从文件中启用并配置配置缓存gradle.properties,那么当您的 IDE 委托给 Gradle 时,配置缓存将被启用。没有什么可做的了。
gradle.properties通常会签入源代码管理。如果您不想为整个团队启用配置缓存,但您也可以仅从 IDE 启用配置缓存,如下所述。
请注意,从 IDE 同步构建不会从配置缓存中受益,只有运行任务才能受益。
基于 IntelliJ 的 IDE
在 IntelliJ IDEA 或 Android Studio 中,这可以通过两种方式完成:全局或每次运行配置。
要在整个构建中启用它,请转到Run > Edit configurations…。这将打开 IntelliJ IDEA 或 Android Studio 对话框来配置运行/调试配置。选择Templates > Gradle必要的系统属性并将其添加到该VM options字段。
例如,要启用配置缓存,将问题转化为警告,请添加以下内容:
-Dorg.gradle.configuration-cache=true -Dorg.gradle.configuration-cache.problems=warn
您还可以选择仅针对给定的运行配置启用它。在这种情况下,请保持Templates > Gradle配置不变,并根据需要编辑每个运行配置。
结合这两种方法,您可以全局启用并禁用某些运行配置,或者相反。
|
提示
|
您可以使用gradle-idea-ext-plugin从构建中配置 IntelliJ 运行配置。这是仅为 IDE 启用配置缓存的好方法。 |
Eclipse IDE
在 Eclipse IDE 中,您可以通过 Buildship 以两种方式启用和配置配置缓存:全局配置或每次运行配置。
要全局启用它,请转至Preferences > Gradle。您可以将上述属性用作系统属性。例如,要启用配置缓存,将问题转化为警告,请添加以下 JVM 参数:
-
-Dorg.gradle.configuration-cache=true -
-Dorg.gradle.configuration-cache.problems=warn
要为给定的运行配置启用它,请转至Run configurations…,找到您要更改的配置,转至Project Settings,勾选Override project settings复选框并添加与JVM argument.
结合这两种方法,您可以全局启用并禁用某些运行配置,或者相反。
支持的插件
配置缓存是全新的,并为插件实现引入了新的要求。因此,核心 Gradle 插件和社区插件都需要调整。本节提供有关核心 Gradle 插件和社区插件当前支持的信息。
核心 Gradle 插件
并非所有核心 Gradle 插件都支持配置缓存。
JVM 语言和框架 |
母语 |
包装和分销 |
|---|---|---|
代码分析 |
IDE项目文件生成 |
公用事业 |
| ✓ |
支持的插件 |
| ⚠ |
部分支持的插件 |
| ✖ |
不支持的插件 |
社区插件
请参阅问题gradle/gradle#13490了解社区插件的状态。
故障排除
以下各节将介绍一些有关处理配置缓存问题的一般准则。这适用于您的构建逻辑和 Gradle 插件。
如果无法序列化运行任务所需的状态,则会生成检测到的问题的 HTML 报告。 Gradle 失败输出包括指向报告的可单击链接。该报告很有用,可以让您深入研究问题,了解问题的原因。
让我们看一个简单的示例构建脚本,其中包含几个问题:
tasks.register("someTask") {
val destination = System.getProperty("someDestination") // (1)
inputs.dir("source")
outputs.dir(destination)
doLast {
project.copy { // (2)
from("source")
into(destination)
}
}
}tasks.register('someTask') {
def destination = System.getProperty('someDestination') // (1)
inputs.dir('source')
outputs.dir(destination)
doLast {
project.copy { // (2)
from 'source'
into destination
}
}
}运行该任务失败并在控制台中打印以下内容:
❯ gradle --configuration-cache someTask -DsomeDestination=dest ... * What went wrong: Configuration cache problems found in this build. 1 problem was found storing the configuration cache. - Build file 'build.gradle': line 6: invocation of 'Task.project' at execution time is unsupported. See http://gradle.github.net.cn/0.0.0/userguide/configuration_cache.html#config_cache:requirements:use_project_during_execution See the complete report at file:///home/user/gradle/samples/build/reports/configuration-cache/<hash>/configuration-cache-report.html > Invocation of 'Task.project' by task ':someTask' at execution time is unsupported. * Try: > Run with --stacktrace option to get the stack trace. > Run with --info or --debug option to get more log output. > Run with --scan to get full insights. > Get more help at https://help.gradle.org. BUILD FAILED in 0s 1 actionable task: 1 executed Configuration cache entry discarded with 1 problem.
由于发现构建失败的问题,配置缓存条目被丢弃。
详细信息可以在链接的 HTML 报告中找到:

该报告将这组问题显示两次。首先按问题消息分组,然后按任务分组。前者可以让您快速查看您的构建所面临的问题类别。后者可以让您快速查看哪些任务有问题。在这两种情况下,您都可以展开树以发现罪魁祸首在对象图中的位置。
该报告还包括检测到的构建配置输入的列表,例如在配置阶段读取的环境变量、系统属性和值提供者:

|
提示
|
当更改构建或插件来解决问题时,您应该考虑使用 TestKit 测试构建逻辑。 |
在此阶段,您可以决定将问题转化为警告并继续探索构建对配置缓存的反应,或者修复手头的问题。
让我们忽略报告的问题,并再次运行相同的构建两次,看看重用缓存的有问题的配置时会发生什么:
❯ gradle --configuration-cache --configuration-cache-problems=warn someTask -DsomeDestination=dest Calculating task graph as no cached configuration is available for tasks: someTask > Task :someTask 1 problem was found storing the configuration cache. - Build file 'build.gradle': line 6: invocation of 'Task.project' at execution time is unsupported. See http://gradle.github.net.cn/0.0.0/userguide/configuration_cache.html#config_cache:requirements:use_project_during_execution See the complete report at file:///home/user/gradle/samples/build/reports/configuration-cache/<hash>/configuration-cache-report.html BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed Configuration cache entry stored with 1 problem. ❯ gradle --configuration-cache --configuration-cache-problems=warn someTask -DsomeDestination=dest Reusing configuration cache. > Task :someTask 1 problem was found reusing the configuration cache. - Build file 'build.gradle': line 6: invocation of 'Task.project' at execution time is unsupported. See http://gradle.github.net.cn/0.0.0/userguide/configuration_cache.html#config_cache:requirements:use_project_during_execution See the complete report at file:///home/user/gradle/samples/build/reports/configuration-cache/<hash>/configuration-cache-report.html BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed Configuration cache entry reused with 1 problem.
这两个构建成功报告了观察到的问题,存储然后重用配置缓存。
借助控制台问题摘要和 HTML 报告中的链接,我们可以解决问题。这是构建脚本的固定版本:
abstract class MyCopyTask : DefaultTask() { // (1)
@get:InputDirectory abstract val source: DirectoryProperty // (2)
@get:OutputDirectory abstract val destination: DirectoryProperty // (2)
@get:Inject abstract val fs: FileSystemOperations // (3)
@TaskAction
fun action() {
fs.copy { // (3)
from(source)
into(destination)
}
}
}
tasks.register<MyCopyTask>("someTask") {
val projectDir = layout.projectDirectory
source = projectDir.dir("source")
destination = projectDir.dir(System.getProperty("someDestination"))
}abstract class MyCopyTask extends DefaultTask { // (1)
@InputDirectory abstract DirectoryProperty getSource() // (2)
@OutputDirectory abstract DirectoryProperty getDestination() // (2)
@Inject abstract FileSystemOperations getFs() // (3)
@TaskAction
void action() {
fs.copy { // (3)
from source
into destination
}
}
}
tasks.register('someTask', MyCopyTask) {
def projectDir = layout.projectDirectory
source = projectDir.dir('source')
destination = projectDir.dir(System.getProperty('someDestination'))
}-
我们将临时任务转变为适当的任务类,
-
带有输入和输出声明,
-
并注入该
FileSystemOperations服务,这是project.copy {}.
现在运行该任务两次会成功,不会报告任何问题,并在第二次运行时重用配置缓存:
❯ gradle --configuration-cache someTask -DsomeDestination=dest Calculating task graph as no cached configuration is available for tasks: someTask > Task :someTask BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed Configuration cache entry stored. ❯ gradle --configuration-cache someTask -DsomeDestination=dest Reusing configuration cache. > Task :someTask BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed Configuration cache entry reused.
但是,如果我们更改系统属性的值怎么办?
❯ gradle --configuration-cache someTask -DsomeDestination=another Calculating task graph as configuration cache cannot be reused because system property 'someDestination' has changed. > Task :someTask BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed Configuration cache entry stored.
之前的配置缓存条目无法重用,必须重新计算并存储任务图。这是因为我们在配置时读取系统属性,因此当该属性的值发生变化时,需要 Gradle 再次运行配置阶段。解决这个问题就像获取系统属性的提供者并将其连接到任务输入一样简单,而无需在配置时读取它。
tasks.register<MyCopyTask>("someTask") {
val projectDir = layout.projectDirectory
source = projectDir.dir("source")
destination = projectDir.dir(providers.systemProperty("someDestination")) // (1)
}tasks.register('someTask', MyCopyTask) {
def projectDir = layout.projectDirectory
source = projectDir.dir('source')
destination = projectDir.dir(providers.systemProperty('someDestination')) // (1)
}-
我们直接连接系统属性提供程序,而无需在配置时读取它。
通过这个简单的更改,我们可以运行任务任意多次,更改系统属性值,并重用配置缓存:
❯ gradle --configuration-cache someTask -DsomeDestination=dest Calculating task graph as no cached configuration is available for tasks: someTask > Task :someTask BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed Configuration cache entry stored. ❯ gradle --configuration-cache someTask -DsomeDestination=another Reusing configuration cache. > Task :someTask BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed Configuration cache entry reused.
现在我们已经通过这个简单的任务解决了问题。
继续阅读以了解如何为您的构建或插件采用配置缓存。
声明与配置缓存不兼容的任务
可以通过Task.notCompatibleWithConfigurationCache()方法声明特定任务与配置缓存不兼容。
在标记为不兼容的任务中发现的配置缓存问题将不再导致构建失败。
而且,当计划运行不兼容的任务时,Gradle 会在构建结束时丢弃配置状态。您可以使用它来帮助迁移,方法是暂时选择某些难以更改以使用配置缓存的任务。
检查方法文档以获取更多详细信息。
领养步骤
一个重要的先决条件是使 Gradle 和插件版本保持最新。以下探讨了成功采用的建议步骤。它适用于构建和插件。在执行这些步骤时,请记住 HTML 报告和下面的要求章节中说明的解决方案。
- 从...开始
:help -
始终从尝试构建或插件最简单的任务开始
:help。这将练习构建或插件的最小配置阶段。 - 逐步瞄准有用的任务
-
不要
build立即运行。您还可以使用--dry-run它首先发现更多配置时间问题。在进行构建时,逐步瞄准您的开发反馈循环。例如,对源代码进行一些更改后运行测试。
在开发插件时,逐步瞄准贡献或配置的任务。
- 将问题转化为警告进行探索
-
不要在第一次构建失败时停止并将问题转化为警告来发现构建和插件的行为方式。如果构建失败,请使用 HTML 报告来推断所报告的与失败相关的问题。继续运行更多有用的任务。
这将使您对构建和插件所面临的问题的性质有一个很好的概述。请记住,将问题转变为警告时,您可能需要手动使缓存失效,以防出现问题。
- 退一步并迭代解决问题
-
当您觉得自己足够了解需要解决的问题时,请退一步并开始迭代地解决最重要的问题。使用 HTML 报告和本文档可以帮助您完成此旅程。
从存储配置缓存时报告的问题开始。修复后,您可以依赖有效的缓存配置阶段,并继续修复加载配置缓存时报告的问题(如果有)。
- 报告遇到的问题
-
如果您遇到本文档未涵盖的Gradle 功能或Gradle 核心插件问题,请在 上报告问题
gradle/gradle。如果您遇到社区 Gradle 插件的问题,请查看它是否已在gradle/gradle#13490中列出,并考虑向插件的问题跟踪器报告该问题。
报告此类问题的一个好方法是提供以下信息:
-
到这个文档的链接,
-
您尝试过的插件版本,
-
插件的自定义配置(如果有),或者理想情况下是重现器构建,
-
对失败原因的描述,例如给定任务的问题
-
构建失败的副本,
-
独立的
configuration-cache-report.html文件。
-
- 测试,测试,测试
-
考虑为您的构建逻辑添加测试。请参阅以下有关测试配置缓存的构建逻辑的部分。这将帮助您迭代所需的更改并防止未来的回归。
- 将其推广给您的团队
-
一旦您的开发人员工作流程正常运行(例如从 IDE 运行测试),您就可以考虑为您的团队启用它。更改代码和运行测试时更快的周转可能是值得的。您可能希望首先选择加入。
如果需要,将问题转化为警告,并在构建文件中设置允许的最大问题数
gradle.properties。默认情况下保持禁用配置缓存。让您的团队知道他们可以选择加入,例如,在支持的工作流程的 IDE 运行配置上启用配置缓存。稍后,当更多工作流程运行时,您可以翻转这一点。默认情况下启用配置缓存,配置 CI 以禁用它,并根据需要传达需要禁用配置缓存的不受支持的工作流。
对构建中的配置缓存做出反应
构建逻辑或插件实现可以检测是否为给定构建启用了配置缓存,并做出相应的反应。配置缓存的活动状态在相应的构建功能中提供。您可以通过将服务注入BuildFeatures到代码中来访问它。
您可以使用此信息以不同方式配置插件的功能或禁用尚不兼容的可选功能。另一个示例涉及为您的用户提供额外的指导,以防他们需要调整其设置或被告知临时限制。
采用配置缓存行为的更改
Gradle 版本增强了配置缓存,使其能够检测更多与环境交互的配置逻辑情况。这些更改通过消除潜在的错误缓存命中来提高缓存的正确性。另一方面,他们施加了更严格的规则,插件和构建逻辑需要遵循才能尽可能频繁地缓存。
如果其中一些配置输入的结果不影响配置的任务,则它们可能被视为“良性”。对于构建用户来说,因此出现新的配置缺失可能是不受欢迎的,建议的消除它们的策略是:
-
借助配置缓存报告识别导致配置缓存无效的配置输入。
-
修复项目构建逻辑访问的未声明的配置输入。
-
向插件维护人员报告第三方插件引起的问题,并在修复后更新插件。
-
-
对于某些类型的配置输入,可以使用选择退出选项,使 Gradle 回退到早期行为,从而忽略检测中的输入。此临时解决方法旨在缓解过时插件带来的性能问题。
在以下情况下可以暂时选择退出配置输入检测:
-
从 Gradle 8.1 开始,使用许多与文件系统相关的 API 都会被正确跟踪为配置输入,包括文件系统检查,例如
File.exists()或File.isFile()。为了让输入跟踪忽略对特定路径的这些文件系统检查,可以使用Gradle 属性
org.gradle.configuration-cache.inputs.unsafe.ignore.file-system-checks以及相对于项目根目录并用 分隔的路径列表。;要忽略多个路径,请使用*匹配一个段内或**跨段的任意字符串。以 开头的路径~/基于用户主目录。例如:gradle.propertiesorg.gradle.configuration-cache.inputs.unsafe.ignore.file-system-checks=\ ~/.third-party-plugin/*.lock;\ ../../externalOutputDirectory/**;\ build/analytics.json -
在 Gradle 8.4 之前,当配置缓存序列化任务图时,仍然可以读取一些从未在配置逻辑中使用的未声明的配置输入。但是,他们的更改不会使配置缓存随后失效。从 Gradle 8.4 开始,可以正确跟踪此类未声明的配置输入。
要暂时恢复到之前的行为,请将 Gradle 属性设置
org.gradle.configuration-cache.inputs.unsafe.ignore.in-serialization为true。
谨慎地忽略配置输入,并且仅当它们不影响配置逻辑生成的任务时才忽略。未来版本中将删除对这些选项的支持。
测试您的构建逻辑
Gradle TestKit(又名 TestKit)是一个帮助测试 Gradle 插件和构建逻辑的库。有关如何使用 TestKit 的一般指南,请参阅专门章节。
要在测试中启用配置缓存,您可以将参数传递--configuration-cache给GradleRunner或使用启用配置缓存中描述的其他方法之一。
您需要运行任务两次。一次填充配置缓存。一次重用配置缓存。
@Test
fun `my task can be loaded from the configuration cache`() {
buildFile.writeText("""
plugins {
id 'org.example.my-plugin'
}
""")
runner()
.withArguments("--configuration-cache", "myTask") // (1)
.build()
val result = runner()
.withArguments("--configuration-cache", "myTask") // (2)
.build()
require(result.output.contains("Reusing configuration cache.")) // (3)
// ... more assertions on your task behavior
}def "my task can be loaded from the configuration cache"() {
given:
buildFile << """
plugins {
id 'org.example.my-plugin'
}
"""
when:
runner()
.withArguments('--configuration-cache', 'myTask') // (1)
.build()
and:
def result = runner()
.withArguments('--configuration-cache', 'myTask') // (2)
.build()
then:
result.output.contains('Reusing configuration cache.') // (3)
// ... more assertions on your task behavior
}-
第一次运行会填充配置缓存。
-
第二次运行重用配置缓存。
-
断言配置缓存被重用。
如果发现配置缓存存在问题,那么 Gradle 将会导致构建失败并报告问题,并且测试也会失败。
|
提示
|
Gradle 插件的一个好的测试策略是在启用配置缓存的情况下运行整个测试套件。这需要使用受支持的 Gradle 版本测试插件。 如果插件已经支持一系列 Gradle 版本,它可能已经有多个 Gradle 版本的测试。在这种情况下,我们建议从支持它的 Gradle 版本开始启用配置缓存。 如果这不能立即完成,那么使用多次运行插件提供的所有任务的测试(例如断言 |
要求
为了将任务图的状态捕获到配置缓存并在以后的构建中重新加载它,Gradle 对任务和其他构建逻辑应用了某些要求。这些要求中的每一个都被视为配置缓存“问题”,如果存在违规,则构建失败。
在大多数情况下,这些要求实际上是一些未声明的输入。换句话说,使用配置缓存是对所有构建更加严格、正确和可靠的选择。
以下部分描述了每个要求以及如何更改构建以解决问题。
某些类型不得被任务引用
任务实例不得从其字段引用许多类型。这同样适用于任务操作作为闭包,例如doFirst {}或doLast {}。
这些类型分为以下几类:
-
实时 JVM 状态类型
-
Gradle 模型类型
-
依赖管理类型
在所有情况下,不允许使用这些类型的原因是配置缓存无法轻松存储或重新创建它们的状态。
根本不允许使用实时 JVM 状态类型(例如ClassLoader、Thread、OutputStream等...)。Socket这些类型几乎从不代表任务输入或输出。唯一的例外是标准流:System.in、System.out和System.err。例如,这些流可以用作任务的Exec参数JavaExec。
Gradle 模型类型(例如Gradle、Settings、Project、SourceSet等Configuration...)通常用于携带一些应显式且精确声明的任务输入。
例如,如果您引用 aProject来获取project.version执行时的 ,您应该使用 a 直接将项目版本声明为任务的输入Property<String>。另一个例子是引用 aSourceSet以便稍后获取源文件、编译类路径或源集的输出。相反,您应该将它们声明为FileCollection输入并引用它。
同样的要求也适用于依赖管理类型,但有一些细微差别。
某些类型(例如Configuration或SourceDirectorySet)不能构成良好的任务输入参数,因为它们包含许多不相关的状态,最好将这些输入建模为更精确的东西。我们根本不打算使这些类型可序列化。例如,如果您引用 aConfiguration以便稍后获取已解析的文件,则您应该将 a 声明FileCollection为任务的输入。同样,如果您引用 a,SourceDirectorySet则应该将 a 声明FileTree为任务的输入。
也不允许引用依赖关系解析结果(例如ArtifactResolutionQuery,ResolvedArtifact等等ArtifactResult......)。例如,如果您引用某些ResolvedComponentResult实例,则应该将 a 声明Provider<ResolvedComponentResult>为任务的输入。这样的提供者可以通过调用来获得ResolutionResult.getRootComponent()。同样,如果您引用某些ResolvedArtifactResult实例,则应该使用ArtifactCollection.getResolvedArtifacts()它返回Provider<Set<ResolvedArtifactResult>>可以映射为任务的输入的值。经验法则是任务不得引用已解析的结果,而是引用惰性规范,以便在执行时进行依赖项解析。
某些类型(例如Publication或 )Dependency不可序列化,但可以。如有必要,我们可以允许它们直接用作任务输入。
以下是引用 a 的有问题的任务类型的示例SourceSet:
abstract class SomeTask : DefaultTask() {
@get:Input lateinit var sourceSet: SourceSet // (1)
@TaskAction
fun action() {
val classpathFiles = sourceSet.compileClasspath.files
// ...
}
}abstract class SomeTask extends DefaultTask {
@Input SourceSet sourceSet // (1)
@TaskAction
void action() {
def classpathFiles = sourceSet.compileClasspath.files
// ...
}
}-
这将被报告为一个问题,因为
SourceSet不允许引用
下面是应该如何做:
abstract class SomeTask : DefaultTask() {
@get:InputFiles @get:Classpath
abstract val classpath: ConfigurableFileCollection // (1)
@TaskAction
fun action() {
val classpathFiles = classpath.files
// ...
}
}abstract class SomeTask extends DefaultTask {
@InputFiles @Classpath
abstract ConfigurableFileCollection getClasspath() // (1)
@TaskAction
void action() {
def classpathFiles = classpath.files
// ...
}
}-
没有更多问题报告,我们现在引用支持的类型
FileCollection
同样,如果您在脚本中声明的临时任务遇到相同的问题,如下所示:
tasks.register("someTask") {
doLast {
val classpathFiles = sourceSets.main.get().compileClasspath.files // (1)
}
}tasks.register('someTask') {
doLast {
def classpathFiles = sourceSets.main.compileClasspath.files // (1)
}
}-
这将被报告为一个问题,因为
doLast {}闭包正在捕获对SourceSet
您仍然需要满足相同的要求,即不引用不允许的类型。以下是修复上述任务声明的方法:
tasks.register("someTask") {
val classpath = sourceSets.main.get().compileClasspath // (1)
doLast {
val classpathFiles = classpath.files
}
}tasks.register('someTask') {
def classpath = sourceSets.main.compileClasspath // (1)
doLast {
def classpathFiles = classpath.files
}
}-
没有更多问题报告,
doLast {}闭包现在仅捕获classpath受支持的FileCollection类型
请注意,有时会间接引用不允许的类型。例如,您可以让任务引用允许的插件中的某种类型。该类型可以引用另一个允许的类型,而该类型又引用不允许的类型。 HTML 问题报告中提供的对象图的分层视图应该可以帮助您查明违规者。
使用Project对象
Project任务在执行时不得使用任何对象。这包括Task.getProject()在任务运行时调用。
某些情况可以采用与不允许的类型相同的方式进行修复。
Project通常,类似的东西在和上都可用Task。例如,如果Logger您的任务操作中需要 a ,则应使用 ,Task.logger而不是Project.logger。
否则,您可以使用注入的服务而不是Project.
Project以下是在执行时使用该对象的有问题的任务类型的示例:
abstract class SomeTask : DefaultTask() {
@TaskAction
fun action() {
project.copy { // (1)
from("source")
into("destination")
}
}
}abstract class SomeTask extends DefaultTask {
@TaskAction
void action() {
project.copy { // (1)
from 'source'
into 'destination'
}
}
}-
Project这将被报告为问题,因为任务操作在执行时使用该对象
下面是应该如何做:
abstract class SomeTask : DefaultTask() {
@get:Inject abstract val fs: FileSystemOperations // (1)
@TaskAction
fun action() {
fs.copy {
from("source")
into("destination")
}
}
}abstract class SomeTask extends DefaultTask {
@Inject abstract FileSystemOperations getFs() // (1)
@TaskAction
void action() {
fs.copy {
from 'source'
into 'destination'
}
}
}-
不再报告问题,
FileSystemOperations支持注入的服务作为替代project.copy {}
同样,如果您在脚本中声明的临时任务遇到相同的问题,如下所示:
tasks.register("someTask") {
doLast {
project.copy { // (1)
from("source")
into("destination")
}
}
}tasks.register('someTask') {
doLast {
project.copy { // (1)
from 'source'
into 'destination'
}
}
}-
Project这将被报告为问题,因为任务操作在执行时使用该对象
以下是修复上述任务声明的方法:
interface Injected {
@get:Inject val fs: FileSystemOperations // (1)
}
tasks.register("someTask") {
val injected = project.objects.newInstance<Injected>() // (2)
doLast {
injected.fs.copy { // (3)
from("source")
into("destination")
}
}
}interface Injected {
@Inject FileSystemOperations getFs() // (1)
}
tasks.register('someTask') {
def injected = project.objects.newInstance(Injected) // (2)
doLast {
injected.fs.copy { // (3)
from 'source'
into 'destination'
}
}
}-
服务不能直接在脚本中注入,我们需要一个额外的类型来传达注入点
-
project.object使用任务操作外部创建额外类型的实例 -
不再报告问题,
injected提供FileSystemOperations服务的任务操作引用,支持作为替代project.copy {}
正如您在上面所看到的,修复脚本中声明的临时任务需要相当多的仪式。现在是考虑将任务声明提取为正确的任务类(如前所示)的好时机。
下表显示了应使用哪些 API 或注入的服务来替代每种Project方法。
| 代替: | 使用: |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
可用于您的构建逻辑的 Kotlin、Groovy 或 Java API。 |
|
|
|
|
|
|
|
共享可变对象
将任务存储到配置缓存时,将序列化通过任务字段直接或间接引用的所有对象。在大多数情况下,反序列化保留引用相等性:如果两个字段在配置时引用同一个实例,那么在反序列化时它们将再次引用同一个实例,因此a(或在 Groovy 和 Kotlin 语法中)仍然成立。然而,出于性能原因,某些类(特别是、和接口的许多实现)在不保留引用相等性的情况下进行序列化。反序列化时,引用此类对象的字段可以引用不同但相同的对象。ba == ba === bjava.lang.Stringjava.io.Filejava.util.Collection
让我们看一下存储用户定义对象和ArrayList任务字段的任务。
class StateObject {
// ...
}
abstract class StatefulTask : DefaultTask() {
@get:Internal
var stateObject: StateObject? = null
@get:Internal
var strings: List<String>? = null
}
tasks.register<StatefulTask>("checkEquality") {
val objectValue = StateObject()
val stringsValue = arrayListOf("a", "b")
stateObject = objectValue
strings = stringsValue
doLast { // (1)
println("POJO reference equality: ${stateObject === objectValue}") // (2)
println("Collection reference equality: ${strings === stringsValue}") // (3)
println("Collection equality: ${strings == stringsValue}") // (4)
}
}class StateObject {
// ...
}
abstract class StatefulTask extends DefaultTask {
@Internal
StateObject stateObject
@Internal
List<String> strings
}
tasks.register("checkEquality", StatefulTask) {
def objectValue = new StateObject()
def stringsValue = ["a", "b"] as ArrayList<String>
stateObject = objectValue
strings = stringsValue
doLast { // (1)
println("POJO reference equality: ${stateObject === objectValue}") // (2)
println("Collection reference equality: ${strings === stringsValue}") // (3)
println("Collection equality: ${strings == stringsValue}") // (4)
}
}-
doLast操作捕获来自封闭范围的引用。这些捕获的引用也会序列化到配置缓存中。 -
将任务字段中存储的用户定义类的对象的引用与操作中捕获的引用进行比较
doLast。 -
比较任务字段中存储的实例引用
ArrayList和操作中捕获的引用doLast。 -
检查存储和捕获列表的相等性。
在没有配置缓存的情况下运行构建表明,在两种情况下都保留了引用相等性。
❯ gradle --no-configuration-cache checkEquality > Task :checkEquality POJO reference equality: true Collection reference equality: true Collection equality: true
但是,启用配置缓存后,只有用户定义的对象引用是相同的。尽管引用的列表相同,但列表引用不同。
❯ gradle --configuration-cache checkEquality > Task :checkEquality POJO reference equality: true Collection reference equality: false Collection equality: true
一般来说,不建议在配置和执行阶段之间共享可变对象。如果您需要这样做,您应该始终将状态包装在您定义的类中。无法保证标准 Java、Groovy 和 Kotlin 类型或 Gradle 定义的类型保留引用相等性。
请注意,任务之间不保留引用相等性:每个任务都是其自己的“领域”,因此不可能在任务之间共享对象。相反,您可以使用构建服务来包装共享状态。
访问任务扩展或约定
任务不应在执行时访问约定和扩展,包括额外的属性。相反,与任务执行相关的任何值都应建模为任务属性。
使用构建监听器
插件和构建脚本不得注册任何构建侦听器。即在配置时注册的侦听器在执行时收到通知。例如 aBuildListener或 a TaskExecutionListener。
运行外部进程
插件和构建脚本应避免在配置时运行外部进程。一般来说,最好在具有正确声明的输入和输出的任务中运行外部进程,以避免任务是最新的时不必要的工作。如有必要,应仅使用与配置缓存兼容的 API,而不是使用 Java 和 Groovy 标准 API 或设置和初始化脚本中现有的ExecOperations、
Project.exec、Project.javaexec等。对于更简单的情况,当抓取进程的输出就足够时,
可以使用providers.exec()和
providers.javaexec() :
val gitVersion = providers.exec {
commandLine("git", "--version")
}.standardOutput.asText.get()def gitVersion = providers.exec {
commandLine("git", "--version")
}.standardOutput.asText.get()对于更复杂的情况,可以使用注入的自定义ValueSourceExecOperations实现。该ExecOperations实例可以在配置时使用,没有任何限制。
abstract class GitVersionValueSource : ValueSource<String, ValueSourceParameters.None> {
@get:Inject
abstract val execOperations: ExecOperations
override fun obtain(): String {
val output = ByteArrayOutputStream()
execOperations.exec {
commandLine("git", "--version")
standardOutput = output
}
return String(output.toByteArray(), Charset.defaultCharset())
}
}abstract class GitVersionValueSource implements ValueSource<String, ValueSourceParameters.None> {
@Inject
abstract ExecOperations getExecOperations()
String obtain() {
ByteArrayOutputStream output = new ByteArrayOutputStream()
execOperations.exec {
it.commandLine "git", "--version"
it.standardOutput = output
}
return new String(output.toByteArray(), Charset.defaultCharset())
}
}然后,该ValueSource实现可用于通过providers.of创建提供程序:
val gitVersionProvider = providers.of(GitVersionValueSource::class) {}
val gitVersion = gitVersionProvider.get()def gitVersionProvider = providers.of(GitVersionValueSource.class) {}
def gitVersion = gitVersionProvider.get()在这两种方法中,如果在配置时使用提供程序的值,那么它将成为构建配置输入。每次构建都会执行外部进程来确定配置缓存是否是最新的,因此建议仅在配置时调用快速运行的进程。如果该值发生更改,则缓存将失效,并且该进程将在此构建期间作为配置阶段的一部分再次运行。
读取系统属性和环境变量
插件和构建脚本可以在配置时使用标准 Java、Groovy 或 Kotlin API 或使用值提供者 API 直接读取系统属性和环境变量。这样做会使此类变量或属性成为构建配置输入,因此更改该值会使配置缓存失效。配置缓存报告包含这些构建配置输入的列表,以帮助跟踪它们。
一般来说,您应该避免在配置时读取系统属性和环境变量的值,以避免值更改时缓存未命中。相反,您可以将providers.systemProperty()或
providers.environmentVariable()Provider返回的值连接到任务属性。
不鼓励某些可能枚举所有环境变量或系统属性的访问模式(例如,调用System.getenv().forEach()或使用 it 的迭代器)。keySet()在这种情况下,Gradle 无法找出哪些属性是实际的构建配置输入,因此每个可用属性都成为一个。如果使用此模式,即使添加新属性也会使缓存失效。
使用自定义谓词来过滤环境变量是这种不鼓励的模式的一个示例:
val jdkLocations = System.getenv().filterKeys {
it.startsWith("JDK_")
}def jdkLocations = System.getenv().findAll {
key, _ -> key.startsWith("JDK_")
}谓词中的逻辑对于配置缓存是不透明的,因此所有环境变量都被视为输入。减少输入数量的一种方法是始终使用查询具体变量名称的方法,例如getenv(String)、 或getenv().get():
val jdkVariables = listOf("JDK_8", "JDK_11", "JDK_17")
val jdkLocations = jdkVariables.filter { v ->
System.getenv(v) != null
}.associate { v ->
v to System.getenv(v)
}def jdkVariables = ["JDK_8", "JDK_11", "JDK_17"]
def jdkLocations = jdkVariables.findAll { v ->
System.getenv(v) != null
}.collectEntries { v ->
[v, System.getenv(v)]
}val jdkLocationsProvider = providers.environmentVariablesPrefixedBy("JDK_")def jdkLocationsProvider = providers.environmentVariablesPrefixedBy("JDK_")请注意,不仅当变量的值发生更改或变量被删除时,而且当另一个具有匹配前缀的变量添加到环境中时,配置缓存也会失效。
对于更复杂的用例,可以使用自定义ValueSource实现。代码中引用的系统属性和环境变量ValueSource不会成为构建配置输入,因此可以应用任何处理。相反,ValueSource每次构建运行时都会重新计算的值,并且仅当该值更改时配置缓存才会失效。例如, aValueSource可用于获取名称包含子字符串 的所有环境变量JDK:
abstract class EnvVarsWithSubstringValueSource : ValueSource<Map<String, String>, EnvVarsWithSubstringValueSource.Parameters> {
interface Parameters : ValueSourceParameters {
val substring: Property<String>
}
override fun obtain(): Map<String, String> {
return System.getenv().filterKeys { key ->
key.contains(parameters.substring.get())
}
}
}
val jdkLocationsProvider = providers.of(EnvVarsWithSubstringValueSource::class) {
parameters {
substring = "JDK"
}
}abstract class EnvVarsWithSubstringValueSource implements ValueSource<Map<String, String>, Parameters> {
interface Parameters extends ValueSourceParameters {
Property<String> getSubstring()
}
Map<String, String> obtain() {
return System.getenv().findAll { key, _ ->
key.contains(parameters.substring.get())
}
}
}
def jdkLocationsProvider = providers.of(EnvVarsWithSubstringValueSource.class) {
parameters {
substring = "JDK"
}
}未声明的文件读取
插件和构建脚本不应在配置时使用 Java、Groovy 或 Kotlin API 直接读取文件。相反,使用值提供者 API 将文件声明为潜在的构建配置输入。
该问题是由类似于以下的构建逻辑引起的:
val config = file("some.conf").readText()def config = file('some.conf').text要解决此问题,请改为使用providers.fileContents()读取文件:
val config = providers.fileContents(layout.projectDirectory.file("some.conf"))
.asTextdef config = providers.fileContents(layout.projectDirectory.file('some.conf'))
.asText一般来说,您应该避免在配置时读取文件,以避免在文件内容更改时使配置缓存条目失效。相反,您可以将providers.fileContents()Provider返回的内容连接到任务属性。
字节码修改和Java代理
为了检测配置输入,Gradle 修改构建脚本类路径上的类的字节码,例如插件及其依赖项。 Gradle 使用 Java 代理来修改字节码。由于字节码更改或代理的存在,某些库的完整性自检可能会失败。
要解决此问题,您可以使用带有类加载器或进程隔离的Worker API来封装库代码。工作线程类路径的字节码未修改,因此自检应该通过。使用进程隔离时,工作操作将在未安装 Gradle Java 代理的单独工作进程中执行。
在简单的情况下,当库还提供命令行入口点(public static void main()方法)时,您还可以使用JavaExec任务来隔离库。
凭证和秘密的处理
配置缓存当前没有选项来阻止存储用作输入的机密,因此它们最终可能会出现在序列化的配置缓存条目中,默认情况下,该条目存储.gradle/configuration-cache在项目目录中。
为了降低意外暴露的风险,Gradle 对配置缓存进行了加密。 Gradle 根据需要透明地生成机器特定的密钥,将其缓存在目录下
GRADLE_USER_HOME,并使用它来加密项目特定缓存中的数据。
为了进一步增强安全性,请确保:
-
对配置缓存条目的安全访问;
-
GRADLE_USER_HOME/gradle.properties存储秘密的杠杆。该文件的内容不是配置缓存的一部分,只是其指纹的一部分。如果您在该文件中存储机密,则必须小心保护对文件内容的访问。
GRADLE_ENCRYPTION_KEY通过环境变量提供加密密钥
默认情况下,Gradle 自动生成并管理加密密钥,作为存储在该GRADLE_USER_HOME目录下的 Java 密钥库。
对于不希望出现这种情况的环境(例如,当GRADLE_USER_HOME目录在计算机之间共享时),您可以向 Gradle 提供确切的加密密钥,以便在通过GRADLE_ENCRYPTION_KEY环境变量读取或写入缓存的配置数据时使用。
|
重要的
|
您必须确保在多次 Gradle 运行中一致提供相同的加密密钥,否则 Gradle 将无法重用现有的缓存配置。 |
生成与 GRADLE_ENCRYPTION_KEY 兼容的加密密钥
为了让 Gradle 使用用户指定的加密密钥加密配置缓存,您必须运行 Gradle,同时使用有效的 AES 密钥(编码为 Base64 字符串)设置 GRADLE_ENCRYPTION_KEY 环境变量。
生成 Base64 编码的 AES 兼容密钥的一种方法是使用如下命令:
❯ openssl rand -base64 16如果使用 Cygwin 等工具,此命令应该适用于 Linux、Mac OS 或 Windows。
然后,您可以使用该命令生成的 Base64 编码密钥并将其设置为环境变量的值
GRADLE_ENCRYPTION_KEY。
尚未实现
尚未实现对某些 Gradle 功能使用配置缓存的支持。对这些功能的支持将在以后的 Gradle 版本中添加。
使用 Java 代理和使用 TestKit 运行的构建
使用TestKit运行构建时,配置缓存可能会干扰应用于这些构建的 Java 代理,例如 Jacoco 代理。
作为构建配置输入的 Gradle 属性的细粒度跟踪
目前,Gradle 属性的所有外部源(gradle.properties在项目目录中以及设置属性的环境变量和系统属性中GRADLE_USER_HOME,以及使用命令行标志指定的属性)都被视为构建配置输入,无论配置时实际使用哪些属性。但是,这些源不包含在配置缓存报告中。
Java对象序列化
Gradle 允许将支持Java 对象序列化协议的对象存储在配置缓存中。
目前,该实现仅限于实现该java.io.Serializable接口并定义以下方法组合之一的可序列化类:
-
一种
writeObject与方法相结合的方法readObject来精确控制要存储哪些信息; -
writeObject没有对应的方法readObject;writeObject最终必须调用ObjectOutputStream.defaultWriteObject; -
readObject没有对应的方法writeObject;readObject最终必须调用ObjectInputStream.defaultReadObject; -
writeReplace允许类指定要编写的替换的方法; -
readResolve允许类指定刚刚读取的对象的替换的方法;
不支持以下Java 对象序列化功能:
-
实现
java.io.Externalizable接口的可序列化类;此类的对象在序列化期间被配置缓存丢弃并报告为问题; -
serialPersistentFields显式声明哪些字段可序列化的成员;该成员(如果存在)将被忽略;配置缓存认为除transient字段之外的所有字段都是可序列化的; -
ObjectOutputStream不支持以下方法并会抛出异常UnsupportedOperationException:-
reset(),writeFields(),putFields(),writeChars(String),writeBytes(String)和writeUnshared(Any?)。
-
-
ObjectInputStream不支持以下方法并会抛出异常UnsupportedOperationException:-
readLine(),readFully(ByteArray),readFully(ByteArray, Int, Int),readUnshared(),readFields(),transferTo(OutputStream)和readAllBytes()。
-
-
通过注册的验证
ObjectInputStream.registerValidation将被简单地忽略; -
该
readObjectNoData方法(如果存在)永远不会被调用;
在执行时访问构建脚本的顶级方法和变量
在构建脚本中重用逻辑和数据的常见方法是将重复位提取到顶级方法和变量中。但是,如果启用了配置缓存,当前不支持在执行时调用此类方法。
对于用 Groovy 编写的构建脚本,任务会失败,因为找不到方法。以下代码片段在任务中使用顶级方法listFiles:
def dir = file('data')
def listFiles(File dir) {
dir.listFiles({ file -> file.isFile() } as FileFilter).name.sort()
}
tasks.register('listFiles') {
doLast {
println listFiles(dir)
}
}在启用配置缓存的情况下运行任务会产生以下错误:
Execution failed for task ':listFiles'. > Could not find method listFiles() for arguments [/home/user/gradle/samples/data] on task ':listFiles' of type org.gradle.api.DefaultTask.
为了防止任务失败,请将引用的顶级方法转换为类中的静态方法:
def dir = file('data')
class Files {
static def listFiles(File dir) {
dir.listFiles({ file -> file.isFile() } as FileFilter).name.sort()
}
}
tasks.register('listFilesFixed') {
doLast {
println Files.listFiles(dir)
}
}用 Kotlin 编写的构建脚本根本无法将执行时引用顶级方法或变量的任务存储在配置缓存中。存在此限制是因为捕获的脚本对象引用无法序列化。 Kotlin 版本的任务首次运行listFiles因配置缓存问题而失败。
val dir = file("data")
fun listFiles(dir: File): List<String> =
dir.listFiles { file: File -> file.isFile }.map { it.name }.sorted()
tasks.register("listFiles") {
doLast {
println(listFiles(dir))
}
}要使该任务的 Kotlin 版本与配置缓存兼容,请进行以下更改:
object Files { // (1)
fun listFiles(dir: File): List<String> =
dir.listFiles { file: File -> file.isFile }.map { it.name }.sorted()
}
tasks.register("listFilesFixed") {
val dir = file("data") // (2)
doLast {
println(Files.listFiles(dir))
}
}-
定义对象内部的方法。
-
将变量定义在较小的范围内。
使用构建服务使配置缓存失效
目前,如果在配置时访问的值,则不可能将BuildServiceProvider派生自它的 或 提供程序与map或flatMap作为 的参数一起使用。当在作为配置阶段的一部分执行的任务中获得这样的 a 时,例如构建或包含的构建贡献插件的任务,同样适用。请注意,使用或存储在任务的带注释的属性中是安全的。一般来说,这个限制使得无法使用a来使配置缓存失效。ValueSourceValueSourceValueSourcebuildSrc@ServiceReferenceBuildServiceProvider@InternalBuildService
检查 Gradle 构建
Gradle 提供了多种方法来检查您的构建:
-
带有构建扫描的配置文件
-
本地概况报告
-
低级分析
什么是构建扫描?
构建扫描是运行构建时发生的情况的持久、可共享的记录。构建扫描可以深入了解您的构建,您可以使用它来识别和修复性能瓶颈。
在 Gradle 4.3 及更高版本中,您可以使用命令行选项创建构建扫描--scan:
$ gradle build --scan
对于较旧的 Gradle 版本, 构建扫描插件用户手册 解释了如何启用构建扫描。
在构建结束时,Gradle 会显示一个 URL,您可以在其中找到构建扫描:
BUILD SUCCESSFUL in 2s 4 actionable tasks: 4 executed Publishing build scan... https://gradle.com/s/e6ircx2wjbf7e
本节介绍如何使用构建扫描来分析您的构建。
带有构建扫描的配置文件
性能页面可以帮助使用构建扫描来分析构建。要到达那里,请单击左侧导航菜单中的“性能”或点击构建扫描主页上的“探索性能”链接:

性能页面显示完成构建的不同阶段所花费的时间。此页面显示了以下内容花费的时间:
-
启动
-
配置构建的项目
-
解决依赖关系
-
执行任务
您还可以获得有关环境属性的详细信息,例如是否使用了守护程序。

在上面的构建扫描中,配置需要超过 13 秒。单击“配置”选项卡可将此阶段分解为多个组成部分,从而揭示缓慢的原因。

在这里,您可以按照应用时间的降序查看应用于项目的脚本和插件。最慢的插件和脚本应用程序是优化的良好候选者。例如,该脚本script-b.gradle应用了一次,但花费了 3 秒。展开该行以查看构建应用此脚本的位置。

您可以看到该子项目:app1从该子项目的文件内部应用了一次脚本build.gradle。
概况报告
如果您不想使用构建扫描,您可以在
build/reports/profile根项目的目录中生成 HTML 报告。要生成此报告,请使用--profile命令行选项:
$ gradle --profile <tasks>
每个配置文件报告的名称中都有一个时间戳,以避免覆盖现有的报告。
该报告显示运行构建所需时间的详细信息。然而,这种细分并不像构建扫描那么详细。以下配置文件报告显示了可用的不同类别:

低级分析
有时,即使您的构建脚本一切正常,您的构建也可能很慢。这通常归结为插件和自定义任务效率低下或资源有限。使用Gradle Profiler来查找此类瓶颈。使用 Gradle Profiler,您可以定义“在进行 ABI 破坏性更改后运行‘assemble’”等场景,并多次运行构建来收集分析数据。使用 Profiler 生成构建扫描。或者将其与 JProfiler 和 YourKit 等方法分析器结合使用。这些分析器可以帮助您找到自定义插件中低效的算法。如果您发现 Gradle 本身的某些内容会减慢您的构建速度,请随时将分析器快照发送至Performance@gradle.com。
性能类别
构建扫描和本地配置文件报告都将构建执行分解为相同的类别。以下部分解释了这些类别。
启动
这反映了 Gradle 的初始化时间,主要包括:
-
JVM初始化和类加载
-
如果您使用包装器,请下载 Gradle 发行版
-
如果合适的守护进程尚未运行,则启动该守护进程
-
执行 Gradle 初始化脚本
即使构建执行的启动时间很长,后续运行的启动时间通常也会急剧下降。构建启动时间持续缓慢通常是由于初始化脚本中的问题造成的。仔细检查您正在做的工作是否必要且有效。
设置和buildSrc
启动后,Gradle 会初始化您的项目。通常,Gradle 只处理您的设置文件。如果目录中有自定义构建逻辑buildSrc,Gradle 也会处理该逻辑。构建buildSrc一次后,Gradle 认为它是最新的。最新检查所花费的时间比逻辑处理要少得多。如果您的buildSrc阶段花费太多时间,请考虑将其分解为一个单独的项目。然后,您可以将该项目的 JAR 工件添加为依赖项。
设置文件很少包含具有大量 I/O 或计算的代码。如果您发现 Gradle 需要很长时间来处理它,请使用更传统的分析方法(例如Gradle Profiler)来确定原因。
加载项目
加载项目通常不会花费大量时间,您也无法控制它。这里花费的时间基本上是您构建中的项目数量的函数。
配置JVM内存
Gradle属性org.gradle.jvmargs控制运行构建的 VM。它默认为-Xmx512m "-XX:MaxMetaspaceSize=384m"
您可以通过以下方式调整 Gradle 的 JVM 选项。
选项 1:更改构建 VM 的 JVM 设置:
org.gradle.jvmargs=-Xmx2g -XX:MaxMetaspaceSize=512m -XX:+HeapDumpOnOutOfMemoryError -Dfile.encoding=UTF-8
环境JAVA_OPTS变量控制命令行客户端,仅用于显示控制台输出。它默认为-Xmx64m
选项 2:更改客户端 VM 的 JVM 设置:
JAVA_OPTS="-Xmx64m -XX:+HeapDumpOnOutOfMemoryError -Dfile.encoding=UTF-8"
|
笔记
|
在一种情况下,客户端 VM 也可以充当构建 VM: 如果您停用Gradle Daemon,并且客户端 VM 具有与构建 VM 所需的相同设置,则客户端 VM 将直接运行构建。 否则,客户端 VM 将分叉一个新 VM 来运行实际构建,以遵循不同的设置。 |
某些任务(例如test任务)也会派生额外的 JVM 进程。您可以通过任务本身来配置这些。他们-Xmx512m默认使用。
示例 1:为 Java 编译任务设置编译选项:
plugins {
java
}
tasks.withType<JavaCompile>().configureEach {
options.compilerArgs = listOf("-Xdoclint:none", "-Xlint:none", "-nowarn")
}plugins {
id 'java'
}
tasks.withType(JavaCompile).configureEach {
options.compilerArgs += ['-Xdoclint:none', '-Xlint:none', '-nowarn']
}请参阅测试API 文档中的其他示例以及Java 插件参考中的测试执行。
当您使用以下选项时,构建扫描将告诉您有关执行构建的 JVM 的信息--scan:

使用项目属性配置任务
可以根据调用时指定的项目属性来更改任务的行为。
假设您希望确保发布版本仅由 CI 触发。执行此操作的一个简单方法是使用isCI项目属性。
示例 1:防止在 CI 外部发布:
tasks.register("performRelease") {
val isCI = providers.gradleProperty("isCI")
doLast {
if (isCI.isPresent) {
println("Performing release actions")
} else {
throw InvalidUserDataException("Cannot perform release outside of CI")
}
}
}tasks.register('performRelease') {
def isCI = providers.gradleProperty("isCI")
doLast {
if (isCI.present) {
println("Performing release actions")
} else {
throw new InvalidUserDataException("Cannot perform release outside of CI")
}
}
}$ gradle performRelease -PisCI=true --quiet Performing release actions
项目属性
项目属性在项目对象上可用。可以使用-P/ --project-prop environment 选项从命令行设置它们。
以下示例演示如何以不同方式设置项目属性。
示例 1:通过命令行设置项目属性:
$ gradle -PgradlePropertiesProp=commandLineValue
当 Gradle 看到专门命名的系统属性或环境变量时,它还可以设置项目属性。如果环境变量名称看起来像,那么 Gradle 将在您的项目对象上设置一个属性,其值为。 Gradle 也支持系统属性,但具有不同的命名模式,看起来像.以下两项都将设置.ORG_GRADLE_PROJECT_prop=somevaluepropsomevalueorg.gradle.project.propfoo' property on your Project object to `"bar"
示例 2:通过系统属性设置项目属性:
org.gradle.project.foo=bar
示例 3:通过环境变量设置项目属性:
ORG_GRADLE_PROJECT_foo=bar
当您没有持续集成服务器的管理员权限并且需要设置不易可见的属性值时,此功能非常有用。由于您无法-P在该场景中使用该选项,也无法更改系统级配置文件,因此正确的策略是更改持续集成构建作业的配置,添加与预期模式匹配的环境变量设置。这对于系统上的普通用户来说是不可见的。
以下示例演示了如何使用项目属性。
Example 1: Reading project properties at configuration time:
// Querying the presence of a project property
if (hasProperty("myProjectProp")) {
// Accessing the value, throws if not present
println(property("myProjectProp"))
}
// Accessing the value of a project property, null if absent
println(findProperty("myProjectProp"))
// Accessing the Map<String, Any?> of project properties
println(properties["myProjectProp"])
// Using Kotlin delegated properties on `project`
val myProjectProp: String by project
println(myProjectProp)// Querying the presence of a project property
if (hasProperty('myProjectProp')) {
// Accessing the value, throws if not present
println property('myProjectProp')
}
// Accessing the value of a project property, null if absent
println findProperty('myProjectProp')
// Accessing the Map<String, ?> of project properties
println properties['myProjectProp']
// Using Groovy dynamic names, throws if not present
println myProjectPropThe Kotlin delegated properties are part of the Gradle Kotlin DSL.
You need to explicitly specify the type as String.
If you need to branch depending on the presence of the property, you can also use String? and check for null.
Note that if a Project property has a dot in its name, using the dynamic Groovy names is not possible. You have to use the API or the dynamic array notation instead.
Example 2: Reading project properties for consumption at execution time:
tasks.register<PrintValue>("printValue") {
// Eagerly accessing the value of a project property, set as a task input
inputValue = project.property("myProjectProp").toString()
}tasks.register('printValue', PrintValue) {
// Eagerly accessing the value of a project property, set as a task input
inputValue = project.property('myProjectProp')
}|
Note
|
If a project property is referenced but does not exist, an exception will be thrown, and the build will fail. You should check for the existence of optional project properties before you access them using the Project.hasProperty(java.lang.String) method. |
Accessing the web through a proxy
Configuring a proxy (for downloading dependencies, for example) is done via standard JVM system properties.
These properties can be set directly in the build script.
For example, setting the HTTP proxy host would be done with System.setProperty('http.proxyHost', 'www.somehost.org').
Alternatively, the properties can be specified in gradle.properties.
Example 1: Configuring an HTTP proxy using gradle.properties:
systemProp.http.proxyHost=www.somehost.org systemProp.http.proxyPort=8080 systemProp.http.proxyUser=userid systemProp.http.proxyPassword=password systemProp.http.nonProxyHosts=*.nonproxyrepos.com|localhost
There are separate settings for HTTPS.
Example 2: Configuring an HTTPS proxy using gradle.properties:
systemProp.https.proxyHost=www.somehost.org systemProp.https.proxyPort=8080 systemProp.https.proxyUser=userid systemProp.https.proxyPassword=password # NOTE: this is not a typo. systemProp.http.nonProxyHosts=*.nonproxyrepos.com|localhost
There are separate settings for SOCKS.
Example 3: Configuring a SOCKS proxy using gradle.properties:
systemProp.socksProxyHost=www.somehost.org systemProp.socksProxyPort=1080 systemProp.java.net.socks.username=userid systemProp.java.net.socks.password=password
You may need to set other properties to access other networks.
Helpful references:
NTLM Authentication
If your proxy requires NTLM authentication, you may need to provide the authentication domain as well as the username and password.
There are 2 ways that you can provide the domain for authenticating to a NTLM proxy:
-
Set the
http.proxyUsersystem property to a value likedomain/username. -
Provide the authentication domain via the
http.auth.ntlm.domainsystem property.
USING THE BUILD CACHE
Build Cache
|
Tip
|
Want to learn the tips and tricks top engineering teams use to keep builds fast and performant? Register here for our Build Cache Training. |
Overview
The Gradle build cache is a cache mechanism that aims to save time by reusing outputs produced by other builds. The build cache works by storing (locally or remotely) build outputs and allowing builds to fetch these outputs from the cache when it is determined that inputs have not changed, avoiding the expensive work of regenerating them.
A first feature using the build cache is task output caching. Essentially, task output caching leverages the same intelligence as up-to-date checks that Gradle uses to avoid work when a previous local build has already produced a set of task outputs. But instead of being limited to the previous build in the same workspace, task output caching allows Gradle to reuse task outputs from any earlier build in any location on the local machine. When using a shared build cache for task output caching this even works across developer machines and build agents.
Apart from tasks, artifact transforms can also leverage the build cache and re-use their outputs similarly to task output caching.
|
Tip
|
For a hands-on approach to learning how to use the build cache, start with reading through the use cases for the build cache and the follow up sections. It covers the different scenarios that caching can improve and has detailed discussions of the different caveats you need to be aware of when enabling caching for a build. |
Enable the Build Cache
By default, the build cache is not enabled. You can enable the build cache in a couple of ways:
- Run with
--build-cacheon the command-line -
Gradle will use the build cache for this build only.
- Put
org.gradle.caching=truein yourgradle.properties -
Gradle will try to reuse outputs from previous builds for all builds, unless explicitly disabled with
--no-build-cache.
When the build cache is enabled, it will store build outputs in the Gradle User Home. For configuring this directory or different kinds of build caches see Configure the Build Cache.
Task Output Caching
Beyond incremental builds described in up-to-date checks, Gradle can save time by reusing outputs from previous executions of a task by matching inputs to the task. Task outputs can be reused between builds on one computer or even between builds running on different computers via a build cache.
We have focused on the use case where users have an organization-wide remote build cache that is populated regularly by continuous integration builds.
Developers and other continuous integration agents should load cache entries from the remote build cache.
We expect that developers will not be allowed to populate the remote build cache, and all continuous integration builds populate the build cache after running the clean task.
For your build to play well with task output caching it must work well with the incremental build feature.
For example, when running your build twice in a row all tasks with outputs should be UP-TO-DATE.
You cannot expect faster builds or correct builds when enabling task output caching when this prerequisite is not met.
Task output caching is automatically enabled when you enable the build cache, see Enable the Build Cache.
What does it look like
Let us start with a project using the Java plugin which has a few Java source files. We run the build the first time.
> gradle --build-cache compileJava :compileJava :processResources :classes :jar :assemble BUILD SUCCESSFUL
We see the directory used by the local build cache in the output. Apart from that the build was the same as without the build cache. Let’s clean and run the build again.
> gradle clean :clean BUILD SUCCESSFUL
> gradle --build-cache assemble :compileJava FROM-CACHE :processResources :classes :jar :assemble BUILD SUCCESSFUL
Now we see that, instead of executing the :compileJava task, the outputs of the task have been loaded from the build cache.
The other tasks have not been loaded from the build cache since they are not cacheable. This is due to
:classes and :assemble being lifecycle tasks and :processResources
and :jar being Copy-like tasks which are not cacheable since it is generally faster to execute them.
Cacheable tasks
Since a task describes all of its inputs and outputs, Gradle can compute a build cache key that uniquely defines the task’s outputs based on its inputs. That build cache key is used to request previous outputs from a build cache or store new outputs in the build cache. If the previous build outputs have been already stored in the cache by someone else, e.g. your continuous integration server or other developers, you can avoid executing most tasks locally.
The following inputs contribute to the build cache key for a task in the same way that they do for up-to-date checks:
-
The task type and its classpath
-
The names of the output properties
-
The names and values of properties annotated as described in the section called "Custom task types"
-
The names and values of properties added by the DSL via TaskInputs
-
The classpath of the Gradle distribution, buildSrc and plugins
-
The content of the build script when it affects execution of the task
Task types need to opt-in to task output caching using the @CacheableTask annotation. Note that @CacheableTask is not inherited by subclasses. Custom task types are not cacheable by default.
Built-in cacheable tasks
Currently, the following built-in Gradle tasks are cacheable:
-
Java toolchain: JavaCompile, Javadoc
-
Groovy toolchain: GroovyCompile, Groovydoc
-
Scala toolchain: ScalaCompile,
org.gradle.language.scala.tasks.PlatformScalaCompile(removed), ScalaDoc -
Native toolchain: CppCompile, CCompile, SwiftCompile
-
Testing: Test
-
Code quality tasks: Checkstyle, CodeNarc, Pmd
-
JaCoCo: JacocoReport
-
Other tasks: AntlrTask, ValidatePlugins, WriteProperties
All other built-in tasks are currently not cacheable.
Third party plugins
There are third party plugins that work well with the build cache. The most prominent examples are the Android plugin 3.1+ and the Kotlin plugin 1.2.21+. For other third party plugins, check their documentation to find out whether they support the build cache.
Declaring task inputs and outputs
It is very important that a cacheable task has a complete picture of its inputs and outputs, so that the results from one build can be safely re-used somewhere else.
Missing task inputs can cause incorrect cache hits, where different results are treated as identical because the same cache key is used by both executions. Missing task outputs can cause build failures if Gradle does not completely capture all outputs for a given task. Wrongly declared task inputs can lead to cache misses especially when containing volatile data or absolute paths. (See the section called "Task inputs and outputs" on what should be declared as inputs and outputs.)
|
Note
|
The task path is not an input to the build cache key. This means that tasks with different task paths can re-use each other’s outputs as long as Gradle determines that executing them yields the same result. |
In order to ensure that the inputs and outputs are properly declared use integration tests (for example using TestKit) to check that a task produces the same outputs for identical inputs and captures all output files for the task. We suggest adding tests to ensure that the task inputs are relocatable, i.e. that the task can be loaded from the cache into a different build directory (see @PathSensitive).
In order to handle volatile inputs for your tasks consider configuring input normalization.
Marking tasks as non-cacheable by default
There are certain tasks that don’t benefit from using the build cache.
One example is a task that only moves data around the file system, like a Copy task.
You can signify that a task is not to be cached by adding the @DisableCachingByDefault annotation to it.
You can also give a human-readable reason for not caching the task by default.
The annotation can be used on its own, or together with @CacheableTask.
|
Note
|
This annotation is only for documenting the reason behind not caching the task by default. Build logic can override this decision via the runtime API (see below). |
Enable caching of non-cacheable tasks
As we have seen, built-in tasks, or tasks provided by plugins, are cacheable if their class is annotated with the Cacheable annotation.
But what if you want to make cacheable a task whose class is not cacheable?
Let’s take a concrete example: your build script uses a generic NpmTask task to create a JavaScript bundle by delegating to NPM (and running npm run bundle).
This process is similar to a complex compilation task, but NpmTask is too generic to be cacheable by default: it just takes arguments and runs npm with those arguments.
The inputs and outputs of this task are simple to figure out. The inputs are the directory containing the JavaScript files, and the NPM configuration files. The output is the bundle file generated by this task.
Using annotations
We create a subclass of the NpmTask and use annotations to declare the inputs and outputs.
When possible, it is better to use delegation instead of creating a subclass.
That is the case for the built in JavaExec, Exec, Copy and Sync tasks, which have a method on Project to do the actual work.
If you’re a modern JavaScript developer, you know that bundling can be quite long, and is worth caching. To achieve that, we need to tell Gradle that it’s allowed to cache the output of that task, using the @CacheableTask annotation.
This is sufficient to make the task cacheable on your own machine. However, input files are identified by default by their absolute path. So if the cache needs to be shared between several developers or machines using different paths, that won’t work as expected. So we also need to set the path sensitivity. In this case, the relative path of the input files can be used to identify them.
Note that it is possible to override property annotations from the base class by overriding the getter of the base class and annotating that method.
@CacheableTask // (1)
abstract class BundleTask : NpmTask() {
@get:Internal // (2)
override val args
get() = super.args
@get:InputDirectory
@get:SkipWhenEmpty
@get:PathSensitive(PathSensitivity.RELATIVE) // (3)
abstract val scripts: DirectoryProperty
@get:InputFiles
@get:PathSensitive(PathSensitivity.RELATIVE) // (4)
abstract val configFiles: ConfigurableFileCollection
@get:OutputFile
abstract val bundle: RegularFileProperty
init {
args.addAll("run", "bundle")
bundle = projectLayout.buildDirectory.file("bundle.js")
scripts = projectLayout.projectDirectory.dir("scripts")
configFiles.from(projectLayout.projectDirectory.file("package.json"))
configFiles.from(projectLayout.projectDirectory.file("package-lock.json"))
}
}
tasks.register<BundleTask>("bundle")@CacheableTask // (1)
abstract class BundleTask extends NpmTask {
@Override @Internal // (2)
ListProperty<String> getArgs() {
super.getArgs()
}
@InputDirectory
@SkipWhenEmpty
@PathSensitive(PathSensitivity.RELATIVE) // (3)
abstract DirectoryProperty getScripts()
@InputFiles
@PathSensitive(PathSensitivity.RELATIVE) // (4)
abstract ConfigurableFileCollection getConfigFiles()
@OutputFile
abstract RegularFileProperty getBundle()
BundleTask() {
args.addAll("run", "bundle")
bundle = projectLayout.buildDirectory.file("bundle.js")
scripts = projectLayout.projectDirectory.dir("scripts")
configFiles.from(projectLayout.projectDirectory.file("package.json"))
configFiles.from(projectLayout.projectDirectory.file("package-lock.json"))
}
}
tasks.register('bundle', BundleTask)-
(1) Add
@CacheableTaskto enable caching for the task. -
(2) Override the getter of a property of the base class to change the input annotation to
@Internal. -
(3) (4) Declare the path sensitivity.
Using the runtime API
If for some reason you cannot create a new custom task class, it is also possible to make a task cacheable using the runtime API to declare the inputs and outputs.
For enabling caching for the task you need to use the TaskOutputs.cacheIf() method.
The declarations via the runtime API have the same effect as the annotations described above. Note that you cannot override file inputs and outputs via the runtime API. Input properties can be overridden by specifying the same property name.
tasks.register<NpmTask>("bundle") {
args = listOf("run", "bundle")
outputs.cacheIf { true }
inputs.dir(file("scripts"))
.withPropertyName("scripts")
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.files("package.json", "package-lock.json")
.withPropertyName("configFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
outputs.file(layout.buildDirectory.file("bundle.js"))
.withPropertyName("bundle")
}tasks.register('bundle', NpmTask) {
args = ['run', 'bundle']
outputs.cacheIf { true }
inputs.dir(file("scripts"))
.withPropertyName("scripts")
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.files("package.json", "package-lock.json")
.withPropertyName("configFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
outputs.file(layout.buildDirectory.file("bundle.js"))
.withPropertyName("bundle")
}Configure the Build Cache
You can configure the build cache by using the Settings.buildCache(org.gradle.api.Action) block in settings.gradle.
Gradle supports a local and a remote build cache that can be configured separately.
When both build caches are enabled, Gradle tries to load build outputs from the local build cache first, and then tries the remote build cache if no build outputs are found.
If outputs are found in the remote cache, they are also stored in the local cache, so next time they will be found locally.
Gradle stores ("pushes") build outputs in any build cache that is enabled and has BuildCache.isPush() set to true.
By default, the local build cache has push enabled, and the remote build cache has push disabled.
The local build cache is pre-configured to be a DirectoryBuildCache and enabled by default. The remote build cache can be configured by specifying the type of build cache to connect to (BuildCacheConfiguration.remote(java.lang.Class)).
Built-in local build cache
The built-in local build cache, DirectoryBuildCache, uses a directory to store build cache artifacts. By default, this directory resides in the Gradle User Home, but its location is configurable.
Gradle will periodically clean-up the local cache directory by removing entries that have not been used recently to conserve disk space. How often Gradle will perform this clean-up is configurable as shown in the example below. Note that cache entries are cleaned-up regardless of the project they were produced by. If different projects configure this clean-up to run at different periods, the shortest period will clean-up cache entries for all projects. Therefore it is recommended to configure this setting globally in the init script. The Configuration use-cases section has an example of putting cache configuration in the init script.
For more details on the configuration options refer to the DSL documentation of DirectoryBuildCache. Here is an example of the configuration.
buildCache {
local {
directory = File(rootDir, "build-cache")
removeUnusedEntriesAfterDays = 30
}
}buildCache {
local {
directory = new File(rootDir, 'build-cache')
removeUnusedEntriesAfterDays = 30
}
}Remote HTTP build cache
HttpBuildCache provides the ability read to and write from a remote cache via HTTP.
With the following configuration, the local build cache will be used for storing build outputs while the local and the remote build cache will be used for retrieving build outputs.
buildCache {
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
}
}buildCache {
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
}
}When attempting to load an entry, a GET request is made to https://example.com:8123/cache/«cache-key».
The response must have a 2xx status and the cache entry as the body, or a 404 Not Found status if the entry does not exist.
When attempting to store an entry, a PUT request is made to https://example.com:8123/cache/«cache-key».
Any 2xx response status is interpreted as success.
A 413 Payload Too Large response may be returned to indicate that the payload is larger than the server will accept, which will not be treated as an error.
Specifying access credentials
HTTP Basic Authentication is supported, with credentials being sent preemptively.
buildCache {
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
credentials {
username = "build-cache-user"
password = "some-complicated-password"
}
}
}buildCache {
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
credentials {
username = 'build-cache-user'
password = 'some-complicated-password'
}
}
}Redirects
3xx redirecting responses will be followed automatically.
Servers must take care when redirecting PUT requests as only 307 and 308 redirect responses will be followed with a PUT request.
All other redirect responses will be followed with a GET request, as per RFC 7231,
without the entry payload as the body.
Network error handling
Requests that fail during request transmission, after having established a TCP connection, will be retried automatically.
This prevents temporary problems, such as connection drops, read or write timeouts, and low level network failures such as a connection resets, causing cache operations to fail and disabling the remote cache for the remainder of the build.
Requests will be retried up to 3 times. If the problem persists, the cache operation will fail and the remote cache will be disabled for the remainder of the build.
Using SSL
By default, use of HTTPS requires the server to present a certificate that is trusted by the build’s Java runtime. If your server’s certificate is not trusted, you can:
-
Update the trust store of your Java runtime to allow it to be trusted
-
Change the build environment to use an alternative trust store for the build runtime
-
Disable the requirement for a trusted certificate
The trust requirement can be disabled by setting HttpBuildCache.isAllowUntrustedServer() to true.
Enabling this option is a security risk, as it allows any cache server to impersonate the intended server.
It should only be used as a temporary measure or in very tightly controlled network environments.
buildCache {
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
isAllowUntrustedServer = true
}
}buildCache {
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
allowUntrustedServer = true
}
}HTTP expect-continue
Use of HTTP Expect-Continue can be enabled. This causes upload requests to happen in two parts: first a check whether a body would be accepted, then transmission of the body if the server indicates it will accept it.
This is useful when uploading to cache servers that routinely redirect or reject upload requests, as it avoids uploading the cache entry just to have it rejected (e.g. the cache entry is larger than the cache will allow) or redirected. This additional check incurs extra latency when the server accepts the request, but reduces latency when the request is rejected or redirected.
Not all HTTP servers and proxies reliably implement Expect-Continue. Be sure to check that your cache server does support it before enabling.
To enable, set HttpBuildCache.isUseExpectContinue() to true.
buildCache {
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
isUseExpectContinue = true
}
}buildCache {
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
useExpectContinue = true
}
}Configuration use cases
The recommended use case for the remote build cache is that your continuous integration server populates it from clean builds while developers only load from it. The configuration would then look as follows.
val isCiServer = System.getenv().containsKey("CI")
buildCache {
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
isPush = isCiServer
}
}boolean isCiServer = System.getenv().containsKey("CI")
buildCache {
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
push = isCiServer
}
}It is also possible to configure the build cache from an init script, which can be used from the command line, added to your Gradle User Home or be a part of your custom Gradle distribution.
gradle.settingsEvaluated {
buildCache {
// vvv Your custom configuration goes here
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
}
// ^^^ Your custom configuration goes here
}
}gradle.settingsEvaluated { settings ->
settings.buildCache {
// vvv Your custom configuration goes here
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
}
// ^^^ Your custom configuration goes here
}
}Build cache, composite builds and buildSrc
Gradle’s composite build feature allows including other complete Gradle builds into another. Such included builds will inherit the build cache configuration from the top level build, regardless of whether the included builds define build cache configuration themselves or not.
The build cache configuration present for any included build is effectively ignored, in favour of the top level build’s configuration.
This also applies to any buildSrc projects of any included builds.
The buildSrc directory is treated as an included build, and as such it inherits the build cache configuration from the top-level build.
|
Note
|
This configuration precedence does not apply to plugin builds included through pluginManagement as these are loaded before the cache configuration itself.
|
How to set up an HTTP build cache backend
Gradle provides a Docker image for a build cache node, which can connect with Develocity for centralized management. The cache node can also be used without a Develocity installation with restricted functionality.
Implement your own Build Cache
Using a different build cache backend to store build outputs (which is not covered by the built-in support for connecting to an HTTP backend) requires implementing your own logic for connecting to your custom build cache backend. To this end, custom build cache types can be registered via BuildCacheConfiguration.registerBuildCacheService(java.lang.Class, java.lang.Class).
Develocity includes a high-performance, easy to install and operate, shared build cache backend.
Use cases for the build cache
This section covers the different use cases for Gradle’s build cache, from local-only development to caching task outputs across large teams.
Speed up developer builds with the local cache
Even when used by a single developer only, the build cache can be very useful.
Gradle’s incremental build feature helps to avoid work that is already done, but once you re-execute a task, any previous results are forgotten.
When you are switching branches back and forth, the local results get rebuilt over and over again, even if you are building something that has already been built before.
The build cache remembers the earlier build results, and greatly reduces the need to rebuild things when they have already been built locally.
This can also extend to rebuilding different commits, like when running git bisect.
The local cache can also be useful when working with a project that has multiple variants, as in the case of Android projects. Each variant has a number of tasks associated with it, and some of those task variant dimensions, despite having different names, can end up producing the same output. With the local cache enabled, reuse between task variants will happen automatically when applicable.
Share results between CI builds
The build cache can do more than go back-and-forth in time: it can also bridge physical distance between computers, allowing results generated on one machine to be re-used by another. A typical first step when introducing the build cache within a team is to enable it for builds running as part of continuous integration only. Using a shared HTTP build cache backend (such as the one provided by Develocity) can significantly reduce the work CI agents need to do. This translates into faster feedback for developers, and less money spent on the CI resources. Faster builds also mean fewer commits being part of each build, which makes debugging issues more efficient.
Beginning with the build cache on CI is a good first step as the environment on CI agents is usually more stable and predictable than developer machines. This helps to identify any possible issues with the build that may affect cacheability.
If you are subject to audit requirements regarding the artifacts you ship to your customers you may need to disable the build cache for certain builds. Develocity may help you with fulfilling these requirements while still using the build cache for all your builds. It allows you to easily find out which build produced an artifact coming from the build cache via build scans.

Accelerate developer builds by reusing CI results
When multiple developers work on the same project, they don’t just need to build their own changes: whenever they pull from version control, they end up having to build each other’s changes as well. Whenever a developer is working on something independent of the pulled changes, they can safely reuse outputs already generated on CI. Say, you’re working on module "A", and you pull in some changes to module "B" (which does not depend on your module). If those changes were already built in CI, you can download the task outputs for module "B" from the cache instead of generating them locally. A typical use case for this is when developers start their day, pull all changes from version control and then run their first build.
The changes don’t need to be completely independent, either; we’ll take a look at the strategies to reuse results when dependencies are involved in the section about the different forms of normalization.
Combine remote results with local caching
You can utilize both a local and a remote cache for a compound effect.
While loading results from a CI-filled remote cache helps to avoid work needed because of changes by other developers, the local cache can speed up switching branches and doing git bisect.
On CI machines the local cache can act as a mirror of the remote cache, significantly reducing network usage.
Share results between developers
Allowing developers to upload their results to a shared cache is possible, but not recommended. Developers can make changes to task inputs or outputs while the task is executing. They can do this unintentionally and without noticing, for example by making changes in their IDEs while a build is running. Currently, Gradle has no good way to defend against these changes, and will simply cache whatever is in the output directory once the task is finished. This again can lead to corrupted results being uploaded to the shared cache. This recommendation might change when Gradle has added the necessary safeguards against unintentional modification of task inputs and outputs.
|
Warning
|
If you want to share task output from incremental builds, i.e. non-clean builds, you have to make sure that all cacheable tasks are properly configured and implemented to deal with stale output. There are for example annotation processors that do not clean up stale files in the corresponding classes/resources directories. The cache is a great forcing function to fix these problems, which will also make your incremental builds much more reliable. At the same time, until you have confidence that the incremental build behavior is flawless, only use clean builds to upload content to the cache. |
Build cache performance
The sole reason to use any build cache is to make builds faster. But how much faster can you go when using the cache? Measuring the impact is both important and complicated, as cache performance is determined by many factors. Performing measurements of the cache’s impact can validate the extra effort (work, infrastructure) that is required to start using the cache. These measurements can later serve as baselines for future improvements, and to watch for signs of regressions.
|
Note
|
Proper configuration and maintenance of a build can improve caching performance in a big way. |
Fully cached builds
The most straightforward way to get a feel for what the cache can do for you is to measure the difference between a non-cached build and a fully cached build. This will give you the theoretical limit of how fast builds with the cache can get, if everything you’re trying to build has already been built. The easiest way to measure this is using the local cache:
-
Clean the cache directory to avoid any hits from previous builds (
rm -rf $GRADLE_USER_HOME/caches/build-cache-*) -
Run the build (e.g.
./gradlew --build-cache clean assemble), so that all the results from cacheable tasks get stored in the cache. -
Run the build again (e.g.
./gradlew --build-cache clean assemble); depending on your build, you should see many of the tasks being retrieved from the cache. -
Compare the execution time for the two builds
|
Note
|
You may encounter a few cached tasks even in the first of the two builds, where no previously cached results should be available. This can happen if you have tasks in your build that are configured to produce the same results from the same inputs; in such a case once one of these tasks has finished, Gradle will simply reuse its output for the rest of the tasks. |
Normally, your fully cached build should be significantly faster than the clean build: this is the theoretical limit of how much time using the build cache can save on your particular build.
You usually don’t get the achievable performance gains on the first try, see finding problems with task output caching.
As your build logic is evolving and changing it is also important to make sure that the cache effectiveness is not regressing.
Build scans provide a detailed performance breakdown which show you how effectively your build is using the build cache:

Fully cached builds occur in situations when developers check out the latest from version control and then build, for example to generate the latest sources they need in their IDE. The purpose of running most builds though is to process some new changes. The structure of the software being built (how many modules are there, how independent are its parts etc.), and the nature of the changes themselves ("big refactor in the core of the system" vs. "small change to a unit test" etc.) strongly influence the performance gains delivered by the build cache. As developers tend to submit different kinds of changes over time, caching performance is expected to vary with each change. As with any cache, the impact should therefore be measured over time.
In a setup where a team uses a shared cache backend, there are two locations worth measuring cache impact at: on CI and on developer machines.
Cache impact on CI builds
The best way to learn about the impact of caching on CI is to set up the same builds with the cache enabled and disabled, and compare the results over time. If you have a single Gradle build step that you want to enable caching for, it’s easy to compare the results using your CI system’s built-in statistical tools.
Measuring complex pipelines may require more work or external tools to collect and process measurements. It’s important to distinguish those parts of the pipeline that caching has no effect on, for example, the time builds spend waiting in the CI system’s queue, or time taken by checking out source code from version control.
When using Develocity, you can use the Export API to access the necessary data and run your analytics. Develocity provides much richer data compared to what can be obtained from CI servers. For example, you can get insights into the execution of single tasks, how many tasks were retrieved from the cache, how long it took to download from the cache, the properties that were used to calculate the cache key and more. When using your CI servers built in functions, you can use statistic charts if you use Teamcity for your CI builds. Most of time you will end up extracting data from your CI server via the corresponding REST API (see Jenkins remote access API and Teamcity REST API).
Typically, CI builds above a certain size include parallel sections to utilize multiple agents. With parallel pipelines you can measure the wall-clock time it takes for a set of changes to go from having been pushed to version control to being built, verified and deployed. The build cache’s effect in this case can be measured in the reduction of the time developers have to wait for feedback from CI.
You can also measure the cumulative time your build agents spent building a changeset, which will give you a sense of the amount of work the CI infrastructure has to exert. The cache’s effect here is less money spent on CI resources, as you don’t need as many CI agents to maintain the same number of changes built.
If you want to look at the measurement for the Gradle build itself you can have a look at the blog post "Introducing the build cache".
Measuring developer builds
Gradle’s build cache can be very useful in reducing CI infrastructure cost and feedback time, but it usually has the biggest impact when developers can reuse cached results in their local builds. This is also the hardest to quantify for a number of reasons:
-
developers run different builds
-
developers can have different hardware, or have different settings
-
developers run all kinds of other things on their machines that can slow them down
When using Develocity you can use the Export API to extract data about developer builds, too. You can then create statistics on how many tasks were cached per developer or build. You can even compare the times it took to execute the task vs loading it from the cache and then estimate the time saved per developer.
When using the Develocity build cache backend you should pay close attention to the hit rate in the admin UI. A rise in the hit rate there probably indicates better usage by developers:

Analyzing performance in build scans
Build scans provide a summary of all cache operations for a build via the "Build cache" section of the "Performance" page.

This page details which tasks were able to be avoided by cache hits, and which missed. It also indicates the hits and misses for the local and remote caches individually. For remote cache operations, the time taken to transfer artifacts to and from the cache is given, along with the transfer rate. This is particularly important for assessing the impact of network link quality on performance, as transfer times contribute to build time.
Remote cache performance
Improving the network link between the build and the remote cache can significantly improve build cache performance. How to do this depends on the remote cache in use and your network environment.
The multi-node remote build cache provided by Develocity is a fast and efficient, purpose built, remote build cache. In particular, if your development team is geographically distributed, its replication features can significantly improve performance by allowing developers to use a cache that they have a good network link to. See the “Build Cache Replication” section of the Develocity Admin Manual for more information.
Important concepts
How much of your build gets loaded from the cache depends on many factors. In this section you will see some of the tools that are essential for well-cached builds. Build scans are part of that toolchain and will be used throughout this guide.
Build cache key
Artifacts in the build cache are uniquely identified by a build cache key. A build cache key is assigned to each cacheable task when running with the build cache enabled and is used for both loading and storing task outputs to the build cache. The following inputs contribute to the build cache key for a task:
-
The task implementation
-
The task action implementations
-
The names of the output properties
-
The names and values of task inputs
Two tasks can reuse their outputs by using the build cache if their associated build cache keys are the same.
Repeatable task outputs
Assume that you have a code generator task as part of your build. When you have a fully up to date build and you clean and re-run the code generator task on the same code base it should generate exactly the same output, so anything that depends on that output will stay up-to-date.
It might also be that your code generator adds some extra information to its output that doesn’t depend on its declared inputs, like a timestamp. In such a case re-executing the task will result in different code being generated (because the timestamp will be updated). Tasks that depend on the code generator’s output will need to be re-executed.
When a task is cacheable, then the very nature of task output caching makes sure that the task will have the same outputs for a given set of inputs. Therefore, cacheable tasks should have repeatable task outputs. If they don’t, then the result of executing the task and loading the task from the cache may be different, which can lead to hard-to-diagnose cache misses.
In some cases even well-trusted tools can produce non-repeatable outputs, and lead to cascading effects.
One example is Oracle’s Java compiler, which, due to a bug, was producing different bytecode depending on the order source files to be compiled were presented to it.
If you were using Oracle JDK 8u31 or earlier to compile code in the buildSrc subproject, this could lead to all of your custom tasks producing occasional cache misses, because of the difference in their classpaths (which include buildSrc).
The key here is that cacheable tasks should not use non-repeatable task outputs as an input.
Stable task inputs
Having a task repeatably produce the same output is not enough if its inputs keep changing all the time. Such unstable inputs can be supplied directly to the task. Consider a version number that includes a timestamp being added to the jar file’s manifest:
version = "3.2-${System.currentTimeMillis()}"
tasks.jar {
manifest {
attributes(mapOf("Implementation-Version" to project.version))
}
}version = "3.2-${System.currentTimeMillis()}"
tasks.named('jar') {
manifest {
attributes('Implementation-Version': project.version)
}
}In the above example the inputs for the jar task will be different for each build execution since this timestamp will continually change.
Another example for unstable inputs is the commit ID from version control.
Maybe your version number is generated via git describe (and you include it in the jar manifest as shown above).
Or maybe you include the commit hash directly in version.properties or a jar manifest attribute.
Either way, the outputs produced by any tasks depending on such data will only be re-usable by builds running against the exact same commit.
Another common, but less obvious source of unstable inputs is when a task consumes the output of another task which produces non-repeatable results, such as the example before of a code generator that embeds timestamps in its output.
A task can only be loaded from the cache if it has stable task inputs. Unstable task inputs result in the task having a unique set of inputs for every build, which will always result in a cache miss.
Better reuse via input normalization
Having stable inputs is crucial for cacheable tasks. However, achieving byte for byte identical inputs for each task can be challenging. In some cases sanitizing the output of a task to remove unnecessary information can be a good approach, but this also means that a task’s output can only be normalized for a single purpose.
This is where input normalization comes into play. Input normalization is used by Gradle to determine if two task inputs are essentially the same. Gradle uses normalized inputs when doing up-to-date checks and when determining if a cached result can be re-used instead of executing the task. As input normalization is declared by the task consuming the data as input, different tasks can define different ways to normalize the same data.
When it comes to file inputs, Gradle can normalize the path of the files as well as their contents.
Path sensitivity and relocatability
When sharing cached results between computers, it’s rare that everyone runs the build from the exact same location on their computers. To allow cached results to be shared even when builds are executed from different root directories, Gradle needs to understand which inputs can be relocated and which cannot.
Tasks having files as inputs can declare the parts of a file’s path what are essential to them: this is called the path sensitivity of the input.
Task properties declared with ABSOLUTE path sensitivity are considered non-relocatable.
This is the default for properties not declaring path sensitivity, too.
For example, the class files produced by the Java compiler are dependent on the file names of the Java source files: renaming the source files with public classes in them would fail the build.
Though moving the files around wouldn’t have an effect on the result of the compilation, for incremental compilation the JavaCompile task relies on the relative path to find other classes in the same package.
Therefore, the path sensitivity for the sources of the JavaCompile task is RELATIVE.
Because of this only the normalized (relative) paths of the Java source files are considered as inputs to the JavaCompile task.
|
Note
|
The Java compiler only respects the package declaration in the Java source files, not the relative path of the sources.
As a consequence, path sensitivity for Java sources is NAME_ONLY and not RELATIVE.
|
Content normalization
Compile avoidance for Java
When it comes to the dependencies of a JavaCompile task (i.e. its compile classpath), only changes to the Application Binary Interface (ABI) of these dependencies require compilation to be executed.
Gradle has a deep understanding of what a compile classpath is and uses a sophisticated normalization strategy for it.
Task outputs can be re-used as long as the ABI of the classes on the compile classpath stays the same.
This enables Gradle to avoid Java compilation by using incremental builds, or load results from the cache that were produced by different (but ABI-compatible) versions of dependencies.
For more information on compile avoidance see the corresponding section.
Runtime classpath normalization
Similar to compile avoidance, Gradle also understands the concept of a runtime classpath, and uses tailored input normalization to avoid running e.g. tests. For runtime classpaths Gradle inspects the contents of jar files and ignores the timestamps and order of the entries in the jar file. This means that a rebuilt jar file would be considered the same runtime classpath input. For details on what level of understanding Gradle has for detecting changes to classpaths and what is considered as a classpath see this section.
For a runtime classpath it is possible to provide better insights to Gradle which files are essential to the input by configuring input normalization.
Given that you want to add a file build-info.properties to all your produced jar files which contains volatile information about the build, e.g. the timestamp when the build started or some ID to identify the CI job that published the artifact.
This file is only used for auditing purposes, and has no effect on the outcome of running tests.
Nonetheless, this file is part of the runtime classpath for the test task. Since the file changes on every build invocation, tests cannot be cached effectively.
To fix this you can ignore build-info.properties on any runtime classpath by adding the following configuration to the build script in the consuming project:
normalization {
runtimeClasspath {
ignore("build-info.properties")
}
}normalization {
runtimeClasspath {
ignore 'build-info.properties'
}
}If adding such a file to your jar files is something you do for all of the projects in your build, and you want to filter this file for all consumers, you may wrap the configurations described above in an allprojects {} or subprojects {} block in the root build script.
The effect of this configuration would be that changes to build-info.properties would be ignored for both up-to-date checks and task output caching.
All runtime classpath inputs for all tasks in the project where this configuration has been made will be affected.
This will not change the runtime behavior of the test task — i.e. any test is still able to load build-info.properties, and the runtime classpath stays the same as before.
The case against overlapping outputs
When two tasks write to the same output directory or output file, it is difficult for Gradle to determine which output belongs to which task. There are many edge cases, and executing the tasks in parallel cannot be done safely. For the same reason, Gradle cannot remove stale output files for these tasks. Tasks that have discrete, non-overlapping outputs can always be handled in a safe fashion by Gradle. For the aforementioned reasons, task output caching is automatically disabled for tasks whose output directories overlap with another task.
Build scans show tasks where caching was disabled due to overlapping outputs in the timeline:

Reuse of outputs between different tasks
Some builds exhibit a surprising characteristic: even when executed against an empty cache, they produce tasks loaded from cache. How is this possible? Rest assured that this is completely normal.
When considering task outputs, Gradle only cares about the inputs to the task: the task type itself, input files and parameters etc., but it doesn’t care about the task’s name or which project it can be found in.
Running javac will produce the same output regardless of the name of the JavaCompile task that invoked it.
If your build includes two tasks that share every input, the one executing later will be able to reuse the output produced by the first.
Having two tasks in the same build that do the same might sound like a problem to fix, but it is not necessarily something bad. For example, the Android plugin creates several tasks for each variant of the project; some of those tasks will potentially do the same thing. These tasks can safely reuse each other’s outputs.
As discussed previously, you can use Develocity to diagnose the source build of these unexpected cache-hits.
Non-cacheable tasks
You’ve seen quite a bit about cacheable tasks, which implies there are non-cacheable ones, too. If caching task outputs is as awesome as it sounds, why not cache every task?
There are tasks that are definitely worth caching: tasks that do complex, repeatable processing and produce moderate amounts of output. Compilation tasks are usually ideal candidates for caching.
At the other end of the spectrum lie I/O-heavy tasks, like Copy and Sync. Moving files around locally typically cannot be sped up by copying them from a cache.
Caching those tasks would even waste good resources by storing all those redundant results in the cache.
Most tasks are either obviously worth caching, or obviously not. For those in-between a good rule of thumb is to see if downloading results would be significantly faster than producing them locally.
Caching Java projects
As of Gradle 4.0, the build tool fully supports caching plain Java projects. Built-in tasks for compiling, testing, documenting and checking the quality of Java code support the build cache out of the box.
Java compilation
Caching Java compilation makes use of Gradle’s deep understanding of compile classpaths. The mechanism avoids recompilation when dependencies change in a way that doesn’t affect their application binary interfaces (ABI). Since the cache key is only influenced by the ABI of dependencies (and not by their implementation details like private types and method bodies), task output caching can also reuse compiled classes if they were produced by the same sources and ABI-equivalent dependencies.
For example, take a project with two modules: an application depending on a library. Suppose the latest version is already built by CI and uploaded to the shared cache. If a developer now modifies a method’s body in the library, the library will need to be rebuilt on their computer. But they will be able to load the compiled classes for the application from the shared cache. Gradle can do this because the library used to compile the application on CI, and the modified library available locally share the same ABI.
Annotation processors
Compile avoidance works out of the box. There is one caveat though: when using annotation processors, Gradle uses the annotation processor classpath as an input. Unlike most compile dependencies, in which only the ABI influences compilation, the implementation of annotation processors must be considered as an input to the compiler. For this reason Gradle will treat annotation processors as a runtime classpath, meaning less input normalization is taking place there. If Gradle detects an annotation processor on the compile classpath, the annotation processor classpath defaults to the compile classpath when not explicitly set, which in turn means the entire compile classpath is treated as a runtime classpath input.
For the example above this would mean the ABI extracted from the compile classpath would be unchanged, but the annotation processor classpath (because it’s not treated with compile avoidance) would be different. Ultimately, the developer would end up having to recompile the application.
The easiest way to avoid this performance penalty is to not use annotation processors. However, if you need to use them, make sure you set the annotation processor classpath explicitly to include only the libraries needed for annotation processing. The section on Java compile avoidance describes how to do this.
|
Note
|
Some common Java dependencies (such as Log4j 2.x) come bundled with annotation processors. If you use these dependencies, but do not leverage the features of the bundled annotation processors, it’s best to disable annotation processing entirely. This can be done by setting the annotation processor classpath to an empty set. |
Unit test execution
The Test task used for test execution for JVM languages employs runtime classpath normalization for its classpath.
This means that changes to order and timestamps in jars on the test classpath will not cause the task to be out-of-date or change the build cache key.
For achieving stable task inputs you can also wield the power of filtering the runtime classpath.
Integration test execution
Unit tests are easy to cache as they normally have no external dependencies. For integration tests the situation can be quite different, as they can depend on a variety of inputs outside of the test and production code. These external factors can be for example:
-
operating system type and version,
-
external tools being installed for the tests,
-
environment variables and Java system properties,
-
other services being up and running,
-
a distribution of the software under test.
You need to be careful to declare these additional inputs for your integration test in order to avoid incorrect cache hits.
For example, declaring the operating system in use by Gradle as an input to a Test task called integTest would work as follows:
tasks.integTest {
inputs.property("operatingSystem") {
System.getProperty("os.name")
}
}tasks.named('integTest') {
inputs.property("operatingSystem") {
System.getProperty("os.name")
}
}Archives as inputs
It is common for the integration tests to depend on your packaged application. If this happens to be a zip or tar archive, then adding it as an input to the integration test task may lead to cache misses. This is because, as described in repeatable task outputs, rebuilding an archive often changes the metadata in the archive. You can depend on the exploded contents of the archive instead. See also the section on dealing with non-repeatable outputs.
Dealing with file paths
You will probably pass some information from the build environment to your integration test tasks by using system properties. Passing absolute paths will break relocatability of the integration test task.
// Don't do this! Breaks relocatability!
tasks.integTest {
systemProperty("distribution.location", layout.buildDirectory.dir("dist").get().asFile.absolutePath)
}// Don't do this! Breaks relocatability!
tasks.named('integTest') {
systemProperty "distribution.location", layout.buildDirectory.dir('dist').get().asFile.absolutePath
}Instead of adding the absolute path directly as a system property, it is possible to add an
annotated CommandLineArgumentProvider to the integTest task:
abstract class DistributionLocationProvider : CommandLineArgumentProvider { // (1)
@get:InputDirectory
@get:PathSensitive(PathSensitivity.RELATIVE) // (2)
abstract val distribution: DirectoryProperty
override fun asArguments(): Iterable<String> =
listOf("-Ddistribution.location=${distribution.get().asFile.absolutePath}") // (3)
}
tasks.integTest {
jvmArgumentProviders.add(
objects.newInstance<DistributionLocationProvider>().apply { // (4)
distribution = layout.buildDirectory.dir("dist")
}
)
}abstract class DistributionLocationProvider implements CommandLineArgumentProvider { // (1)
@InputDirectory
@PathSensitive(PathSensitivity.RELATIVE) // (2)
abstract DirectoryProperty getDistribution()
@Override
Iterable<String> asArguments() {
["-Ddistribution.location=${distribution.get().asFile.absolutePath}"] // (3)
}
}
tasks.named('integTest') {
jvmArgumentProviders.add(
objects.newInstance(DistributionLocationProvider).tap { // (4)
distribution = layout.buildDirectory.dir('dist')
}
)
}-
Create a class implementing
CommandLineArgumentProvider. -
Declare the inputs and outputs with the corresponding path sensitivity.
-
asArgumentsneeds to return the JVM arguments passing the desired system properties to the test JVM. -
Add an instance of the newly created class as JVM argument provider to the integration test task.[11]
Ignoring system properties
It may be necessary to ignore some system properties as inputs as they do not influence the outcome of the integration tests.
In order to do so, add a CommandLineArgumentProvider to the integTest task:
abstract class CiEnvironmentProvider : CommandLineArgumentProvider {
@get:Internal // (1)
abstract val agentNumber: Property<String>
override fun asArguments(): Iterable<String> =
listOf("-DagentNumber=${agentNumber.get()}") // (2)
}
tasks.integTest {
jvmArgumentProviders.add(
objects.newInstance<CiEnvironmentProvider>().apply { // (3)
agentNumber = providers.environmentVariable("AGENT_NUMBER").orElse("1")
}
)
}abstract class CiEnvironmentProvider implements CommandLineArgumentProvider {
@Internal // (1)
abstract Property<String> getAgentNumber()
@Override
Iterable<String> asArguments() {
["-DagentNumber=${agentNumber.get()}"] // (2)
}
}
tasks.named('integTest') {
jvmArgumentProviders.add(
objects.newInstance(CiEnvironmentProvider).tap { // (3)
agentNumber = providers.environmentVariable("AGENT_NUMBER").orElse("1")
}
)
}-
@Internalmeans that this property does not influence the output of the integration tests. -
The system properties for the actual test execution.
-
Add an instance of the newly created class as JVM argument provider to the integration test task.[11]
Caching Android projects
While it is true that Android uses the Java toolchain as its foundation, there are nevertheless some significant differences from pure Java projects; these differences impact task cacheability.
This is even more true for Android projects that include Kotlin source code (and therefore use the kotlin-android plugin).
Disambiguation
This guide is about Gradle’s build cache, but you may have also heard about the Android build cache. These are different things. The Android cache is internal to certain tasks in the Android plugin, and will eventually be removed in favor of native Gradle support.
Why use the build cache?
The build cache can significantly improve build performance for Android projects, in many cases by 30-40%. Many of the compilation and assembly tasks provided by the Android Gradle Plugin are cacheable, and more are made so with each new iteration.
Faster CI builds
CI builds benefit particularly from the build cache.
A typical CI build starts with a clean, which means that pre-existing build outputs are deleted and none of the tasks that make up the build will be UP-TO-DATE.
However, it is likely that many of those tasks will have been run with exactly the same inputs in a prior CI build, populating the build cache; the outputs from those prior runs can safely be reused, resulting in dramatic build performance improvements.
Reusing CI builds for local development
When you sign into work at the start of your day, it’s not unusual for your first task to be pulling the main branch and then running a build (Android Studio will probably do the latter, whether you ask it to or not). Assuming all merges to main are built on CI (a best practice!), you can expect this first local build of the day to enjoy a larger-than-typical benefit with Gradle’s remote cache. CI already built this commit — why should you re-do that work?
Switching branches
During local development, it is not uncommon to switch branches several times per day.
This defeats incremental build (i.e., UP-TO-DATE checks), but this issue is mitigated via use of the local build cache.
You might run a build on Branch A, which will populate the local cache.
You then switch to Branch B to conduct a code review, help a colleague, or address feedback on an open PR.
You then switch back to Branch A to continue your original work.
When you next build, all of the outputs previously built while working on Branch A can be reused from the cache, saving potentially a lot of time.
The Android Gradle Plugin and the Gradle Build Tool
The first thing you should always do when working to optimize your build is ensure you’re on the latest stable, supported versions of the Android Gradle Plugin and the Gradle Build Tool. At the time of writing, they are 3.3.0 and 5.0, respectively. Each new version of these tools includes many performance improvements, not least of which is to the build cache.
Java and Kotlin compilation
The discussion above in “Caching Java projects” is equally relevant here, with the caveat that, for projects that include Kotlin source code, the Kotlin compiler does not currently support compile avoidance in the way that the Java compiler does.
Annotation processors and Kotlin
The advice above for pure Java projects also applies to Android projects. However, if you are using annotation processors (such as Dagger2 or Butterknife) in conjunction with Kotlin and the kotlin-kapt plugin, you should know that before Kotlin 1.3.30 kapt was not cached by default.
You can opt into it (which is recommended) by adding the following to build scripts:
pluginManager.withPlugin("kotlin-kapt") {
configure<KaptExtension> { useBuildCache = true }
}plugins.withId("kotlin-kapt") {
kapt.useBuildCache = true
}Unit test execution
Unlike with unit tests in a pure Java project, the equivalent test task in an Android project (AndroidUnitTest) is not cacheable.
The Google Team is working to make these tests cacheable.
Please see this issue.
Instrumented test execution (i.e., Espresso tests)
Android instrumented tests (DeviceProviderInstrumentTestTask), often referred to as “Espresso” tests, are also not cacheable.
The Google Android team is also working to make such tests cacheable.
Please see this issue.
Lint
Users of Android’s Lint task are well aware of the heavy performance penalty they pay for using it, but also know that it is indispensable for finding common issues in Android projects.
Currently, this task is not cacheable.
This task is planned to be cacheable with the release of Android Gradle Plugin 3.5.
This is another reason to always use the latest version of the Android plugin!
The Fabric Plugin and Crashlytics
The Fabric plugin, which is used to integrate the Crashlytics crash-reporting tool (among others), is very popular, yet imposes some hefty performance penalties during the build process. This is due to the need for each version of your app to have a unique identifier so that it can be identified in the Crashlytics dashboard. In practice, the default behavior of Crashlytics is to treat “each version” as synonymous with “each build”. This defeats incremental build, because each build will be unique. It also breaks the cacheability of certain tasks in the build, and for the same reason. This can be fixed by simply disabling Crashlytics in “debug” builds. You may find instructions for that in the Crashlytics documentation.
|
Note
|
The fix described in the referenced documentation does not work directly if you are using the Kotlin DSL; see below for the workaround. |
Kotlin DSL
The fix described in the referenced documentation does not work directly if you are using the Kotlin DSL; this is due to incompatibilities between that Kotlin DSL and the Fabric plugin. There is a simple workaround for this, based on this advice from the Kotlin DSL primer.
Create a file, fabric.gradle, in the module where you apply the io.fabric plugin. This file (known as a script plugin), should have the following contents:
plugins.withId("com.android.application") { // or "com.android.library"
android.buildTypes.debug.ext.enableCrashlytics = false
}
And then, in the module’s build.gradle.kts file, apply this script plugin:
apply(from = "fabric.gradle")
Debugging and diagnosing cache misses
To make the most of task output caching, it is important that any necessary inputs to your tasks are specified correctly, while at the same time avoiding unneeded inputs. Failing to specify an input that affects the task’s outputs can result in incorrect builds, while needlessly specifying inputs that do not affect the task’s output can cause cache misses.
This chapter is about finding out why a cache miss happened. If you have a cache hit which you didn’t expect we suggest to declare whatever change you expected to trigger the cache miss as an input to the task.
Finding problems with task output caching
Below we describe a step-by-step process that should help shake out any problems with caching in your build.
Ensure incremental build works
First, make sure your build does the right thing without the cache. Run a build twice without enabling the Gradle build cache. The expected outcome is that all actionable tasks that produce file outputs are up-to-date. You should see something like this on the command-line:
$ ./gradlew clean --quiet (1) $ ./gradlew assemble (2) BUILD SUCCESSFUL 4 actionable tasks: 4 executed $ ./gradlew assemble (3) BUILD SUCCESSFUL 4 actionable tasks: 4 up-to-date
-
Make sure we start without any leftover results by running
cleanfirst. -
We are assuming your build is represented by running the
assembletask in these examples, but you can substitute whatever tasks make sense for your build. -
Run the build again without running
clean.
|
Note
|
Tasks that have no outputs or no inputs will always be executed, but that shouldn’t be a problem. |
Use the methods as described below to diagnose and fix tasks that should be up-to-date but aren’t. If you find a task which is out of date, but no cacheable tasks depends on its outcome, then you don’t have to do anything about it. The goal is to achieve stable task inputs for cacheable tasks.
In-place caching with the local cache
When you are happy with the up-to-date performance then you can repeat the experiment above, but this time with a clean build, and the build cache turned on. The goal with clean builds and the build cache turned on is to retrieve all cacheable tasks from the cache.
|
Warning
|
When running this test make sure that you have no remote cache configured, and storing in the local cache is enabled.
These are the default settings.
|
This would look something like this on the command-line:
$ rm -rf ~/.gradle/caches/build-cache-1 (1) $ ./gradlew clean --quiet (2) $ ./gradlew assemble --build-cache (3) BUILD SUCCESSFUL 4 actionable tasks: 4 executed $ ./gradlew clean --quiet (4) $ ./gradlew assemble --build-cache (5) BUILD SUCCESSFUL 4 actionable tasks: 1 executed, 3 from cache
-
We want to start with an empty local cache.
-
Clean the project to remove any unwanted leftovers from previous builds.
-
Build it once to let it populate the cache.
-
Clean the project again.
-
Build it again: this time everything cacheable should load from the just populated cache.
You should see all cacheable tasks loaded from cache, while non-cacheable tasks should be executed.

Testing cache relocatability
Once everything loads properly while building the same checkout with the local cache enabled, it’s time to see if there are any relocation problems. A task is considered relocatable if its output can be reused when the task is executed in a different location. (More on this in path sensitivity and relocatability.)
|
Note
|
Tasks that should be relocatable but aren’t are usually a result of absolute paths being present among the task’s inputs. |
To discover these problems, first check out the same commit of your project in two different directories on your machine.
For the following example let’s assume we have a checkout in \~/checkout-1 and \~/checkout-2.
|
Warning
|
Like with the previous test, you should have no remote cache configured, and storing in the local cache should be enabled.
|
$ rm -rf ~/.gradle/caches/build-cache-1 (1) $ cd ~/checkout-1 (2) $ ./gradlew clean --quiet (3) $ ./gradlew assemble --build-cache (4) BUILD SUCCESSFUL 4 actionable tasks: 4 executed $ cd ~/checkout-2 (5) $ ./gradlew clean --quiet (6) $ ./gradlew clean assemble --build-cache (7) BUILD SUCCESSFUL 4 actionable tasks: 1 executed, 3 from cache
-
Remove all entries in the local cache first.
-
Go to the first checkout directory.
-
Clean the project to remove any unwanted leftovers from previous builds.
-
Run a build to populate the cache.
-
Go to the other checkout directory.
-
Clean the project again.
-
Run a build again.
You should see the exact same results as you saw with the previous in place caching test step.
Cross-platform tests
If your build passes the relocation test, it is in good shape already. If your build requires support for multiple platforms, it is best to see if the required tasks get reused between platforms, too. A typical example of cross-platform builds is when CI runs on Linux VMs, while developers use macOS or Windows, or a different variety or version of Linux.
To test cross-platform cache reuse, set up a remote cache (see share results between CI builds) and populate it from one platform and consume it from the other.
Incremental cache usage
After these experiments with fully cached builds, you can go on and try to make typical changes to your project and see if enough tasks are still cached. If the results are not satisfactory, you can think about restructuring your project to reduce dependencies between different tasks.
Evaluating cache performance over time
Consider recording execution times of your builds, generating graphs, and analyzing the results. Keep an eye out for certain patterns, like a build recompiling everything even though you expected compilation to be cached.
You can also make changes to your code base manually or automatically and check that the expected set of tasks is cached.
If you have tasks that are re-executing instead of loading their outputs from the cache, then it may point to a problem in your build. Techniques for debugging a cache miss are explained in the following section.
Helpful data for diagnosing a cache miss
A cache miss happens when Gradle calculates a build cache key for a task which is different from any existing build cache key in the cache. Only comparing the build cache key on its own does not give much information, so we need to look at some finer grained data to be able to diagnose the cache miss. A list of all inputs to the computed build cache key can be found in the section on cacheable tasks.
From most coarse grained to most fine grained, the items we will use to compare two tasks are:
-
Build cache keys
-
Task and Task action implementations
-
classloader hash
-
class name
-
-
Task output property names
-
Individual task property input hashes
-
Hashes of files which are part of task input properties
If you want information about the build cache key and individual input property hashes, use -Dorg.gradle.caching.debug=true:
$ ./gradlew :compileJava --build-cache -Dorg.gradle.caching.debug=true
.
.
.
Appending implementation to build cache key: org.gradle.api.tasks.compile.JavaCompile_Decorated@470c67ec713775576db4e818e7a4c75d
Appending additional implementation to build cache key: org.gradle.api.tasks.compile.JavaCompile_Decorated@470c67ec713775576db4e818e7a4c75d
Appending input value fingerprint for 'options' to build cache key: e4eaee32137a6a587e57eea660d7f85d
Appending input value fingerprint for 'options.compilerArgs' to build cache key: 8222d82255460164427051d7537fa305
Appending input value fingerprint for 'options.debug' to build cache key: f6d7ed39fe24031e22d54f3fe65b901c
Appending input value fingerprint for 'options.debugOptions' to build cache key: a91a8430ae47b11a17f6318b53f5ce9c
Appending input value fingerprint for 'options.debugOptions.debugLevel' to build cache key: f6bd6b3389b872033d462029172c8612
Appending input value fingerprint for 'options.encoding' to build cache key: f6bd6b3389b872033d462029172c8612
.
.
.
Appending input file fingerprints for 'options.sourcepath' to build cache key: 5fd1e7396e8de4cb5c23dc6aadd7787a - RELATIVE_PATH{EMPTY}
Appending input file fingerprints for 'stableSources' to build cache key: f305ada95aeae858c233f46fc1ec4d01 - RELATIVE_PATH{.../src/main/java=IGNORED / DIR, .../src/main/java/Hello.java='Hello.java' / 9c306ba203d618dfbe1be83354ec211d}
Appending output property name to build cache key: destinationDir
Appending output property name to build cache key: options.annotationProcessorGeneratedSourcesDirectory
Build cache key for task ':compileJava' is 8ebf682168823f662b9be34d27afdf77
The log shows e.g. which source files constitute the stableSources for the compileJava task.
To find the actual differences between two builds you need to resort to matching up and comparing those hashes yourself.
|
Tip
|
Develocity already takes care of this for you; it lets you quickly diagnose a cache miss with the Build Scan™ Comparison tool. |
Diagnosing the reasons for a cache miss
Having the data from the last section at hand, you should be able to diagnose why the outputs of a certain task were not found in the build cache. Since you were expecting more tasks to be cached, you should be able to pinpoint a build which would have produced the artifact under question.
Before diving into how to find out why one task has not been loaded from the cache we should first look into which task caused the cache misses. There is a cascade effect which causes dependent tasks to be executed if one of the tasks earlier in the build is not loaded from the cache and has different outputs. Therefore, you should locate the first cacheable task which was executed and continue investigating from there. This can be done from the timeline view in a Build Scan™:

At first, you should check if the implementation of the task changed. This would mean checking the class names and classloader hashes
for the task class itself and for each of its actions. If there is a change, this means that the build script, buildSrc or the Gradle version has changed.
|
Note
|
A change in the output of |
If the implementation is the same, then you need to start comparing inputs between the two builds. There should be at least one different input hash. If it is a simple value property, then the configuration of the task changed. This can happen for example by
-
changing the build script,
-
conditionally configuring the task differently for CI or the developer builds,
-
depending on a system property or an environment variable for the task configuration,
-
or having an absolute path which is part of the input.
If the changed property is a file property, then the reasons can be the same as for the change of a value property. Most probably though a file on the filesystem changed in a way that Gradle detects a difference for this input. The most common case will be that the source code was changed by a check in. It is also possible that a file generated by a task changed, e.g. since it includes a timestamp. As described in Java version tracking, the Java version can also influence the output of the Java compiler. If you did not expect the file to be an input to the task, then it is possible that you should alter the configuration of the task to not include it. For example, having your integration test configuration including all the unit test classes as a dependency has the effect that all integration tests are re-executed when a unit test changes. Another option is that the task tracks absolute paths instead of relative paths and the location of the project directory changed on disk.
Example
We will walk you through the process of diagnosing a cache miss.
Let’s say we have build A and build B and we expected all the test tasks for a sub-project sub1 to be cached in build B since only a unit test for another sub-project sub2 changed.
Instead, all the tests for the sub-project have been executed.
Since we have the cascading effect when we have cache misses, we need to find the task which caused the caching chain to fail.
This can easily be done by filtering for all cacheable tasks which have been executed and then select the first one.
In our case, it turns out that the tests for the sub-project internal-testing were executed even though there was no code change to this project.
This means that the property classpath changed and some file on the runtime classpath actually did change.
Looking deeper into this, we actually see that the inputs for the task processResources changed in that project, too.
Finally, we find this in our build file:
val currentVersionInfo = tasks.register<CurrentVersionInfo>("currentVersionInfo") {
version = project.version as String
versionInfoFile = layout.buildDirectory.file("generated-resources/currentVersion.properties")
}
sourceSets.main.get().output.dir(currentVersionInfo.map { it.versionInfoFile.get().asFile.parentFile })
abstract class CurrentVersionInfo : DefaultTask() {
@get:Input
abstract val version: Property<String>
@get:OutputFile
abstract val versionInfoFile: RegularFileProperty
@TaskAction
fun writeVersionInfo() {
val properties = Properties()
properties.setProperty("latestMilestone", version.get())
versionInfoFile.get().asFile.outputStream().use { out ->
properties.store(out, null)
}
}
}def currentVersionInfo = tasks.register('currentVersionInfo', CurrentVersionInfo) {
version = project.version
versionInfoFile = layout.buildDirectory.file('generated-resources/currentVersion.properties')
}
sourceSets.main.output.dir(currentVersionInfo.map { it.versionInfoFile.get().asFile.parentFile })
abstract class CurrentVersionInfo extends DefaultTask {
@Input
abstract Property<String> getVersion()
@OutputFile
abstract RegularFileProperty getVersionInfoFile()
@TaskAction
void writeVersionInfo() {
def properties = new Properties()
properties.setProperty('latestMilestone', version.get())
versionInfoFile.get().asFile.withOutputStream { out ->
properties.store(out, null)
}
}
}Since properties files stored by Java’s Properties.store method contain a timestamp, this will cause a change to the runtime classpath every time the build runs.
In order to solve this problem see non-repeatable task outputs or use input normalization.
|
Note
|
The compile classpath is not affected since compile avoidance ignores non-class files on the classpath. |
Solving common problems
Small problems in a build, like forgetting to declare a configuration file as an input to your task, can be easily overlooked.
The configuration file might change infrequently, or only change when some other (correctly tracked) input changes as well.
The worst that could happen is that your task doesn’t execute when it should.
Developers can always re-run the build with clean, and "fix" their builds for the price of a slow rebuild.
In the end nobody gets blocked in their work, and the incident is chalked up to "Gradle acting up again."
With cacheable tasks incorrect results are stored permanently, and can come back to haunt you later; re-running with clean won’t help in this situation either. When using a shared cache, these problems even cross machine boundaries. In the example above, Gradle might end up loading a result for your task that was produced with a different configuration. Resolving these problems with the build therefore becomes even more important when task output caching is enabled.
Other issues with the build won’t cause it to produce incorrect results, but will lead to unnecessary cache misses.
In this chapter you will learn about some typical problems and ways to avoid them.
Fixing these issues will have the added benefit that your build will stop "acting up," and developers can forget about running builds with clean altogether.
System file encoding
Most Java tools use the system file encoding when no specific encoding is specified. This means that running the same build on machines with different file encoding can yield different outputs. Currently Gradle only tracks on a per-task basis that no file encoding has been specified, but it does not track the system encoding of the JVM in use. This can cause incorrect builds. You should always set the file system encoding to avoid these kind of problems.
|
Note
|
Build scripts are compiled with the file encoding of the Gradle daemon. By default, the daemon uses the system file encoding, too. |
Setting the file encoding for the Gradle daemon mitigates both above problems by making sure that the encoding is the same across builds.
You can do so in your gradle.properties:
org.gradle.jvmargs=-Dfile.encoding=UTF-8Environment variable tracking
Gradle does not track changes in environment variables for tasks.
For example for Test tasks it is completely possible that the outcome depends on a few environment variables.
To ensure that only the right artifacts are re-used between builds, you need to add environment variables as inputs to tasks depending on them.
Absolute paths are often passed as environment variables, too. You need to pay attention what you add as an input to the task in this case. You would need to ensure that the absolute path is the same between machines. Most times it makes sense to track the file or the contents of the directory the absolute path points to. If the absolute path represents a tool being used it probably makes sense to track the tool version as an input instead.
For example, if you are using tools in your Test task called integTest which depend on the contents of the LANG variable you should do this:
tasks.integTest {
inputs.property("langEnvironment") {
System.getenv("LANG")
}
}tasks.named('integTest') {
inputs.property("langEnvironment") {
System.getenv("LANG")
}
}If you add conditional logic to distinguish CI builds from local development builds, you have to ensure that this does not break the loading of task outputs from CI onto developer machines.
For example, the following setup would break caching of Test tasks, since Gradle always detects the differences in custom task actions.
if ("CI" in System.getenv()) {
tasks.withType<Test>().configureEach {
doFirst {
println("Running test on CI")
}
}
}if (System.getenv().containsKey("CI")) {
tasks.withType(Test).configureEach {
doFirst {
println "Running test on CI"
}
}
}You should always add the action unconditionally:
tasks.withType<Test>().configureEach {
doFirst {
if ("CI" in System.getenv()) {
println("Running test on CI")
}
}
}tasks.withType(Test).configureEach {
doFirst {
if (System.getenv().containsKey("CI")) {
println "Running test on CI"
}
}
}This way, the task has the same custom action on CI and on developer builds and its outputs can be re-used if the remaining inputs are the same.
Line endings
If you are building on different operating systems be aware that some version control systems convert line endings on check-out.
For example, Git on Windows uses autocrlf=true by default which converts all line endings to \r\n.
As a consequence, compilation outputs can’t be re-used on Windows since the input sources are different.
If sharing the build cache across multiple operating systems is important in your environment, then setting autocrlf=false across your build machines is crucial for optimal build cache usage.
Symbolic links
When using symbolic links, Gradle does not store the link in the build cache but the actual file contents of the destination of the link. As a consequence you might have a hard time when trying to reuse outputs which heavily use symbolic links. There currently is no workaround for this behavior.
For operating systems supporting symbolic links, the content of the destination of the symbolic link will be added as an input.
If the operating system does not support symbolic links, the actual symbolic link file is added as an input.
Therefore, tasks which have symbolic links as input files, e.g. Test tasks having symbolic link as part of its runtime classpath, will not be cached between Windows and Linux.
If caching between operating systems is desired, symbolic links should not be checked into version control.
Java version tracking
Gradle tracks only the major version of Java as an input for compilation and test execution. Currently, it does not track the vendor nor the minor version. Still, the vendor and the minor version may influence the bytecode produced by compilation.
|
Note
|
If you’re using Java Toolchains, the Java major version, the vendor (if specified) and implementation (if specified) will be tracked automatically as an input for compilation and test execution. |
If you use different JVM vendors for compiling or running Java we strongly suggest that you add the vendor as an input to the corresponding tasks. This can be achieved by using the runtime API as shown in the following snippet.
tasks.withType<AbstractCompile>().configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}
tasks.withType<Test>().configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}tasks.withType(AbstractCompile).configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}
tasks.withType(Test).configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}With respect to tracking the Java minor version there are different competing aspects: developers having cache hits and "perfect" results on CI. There are basically two situations when you may want to track the minor version of Java: for compilation and for runtime. In the case of compilation, there can sometimes be differences in the produced bytecode for different minor versions. However, the bytecode should still result in the same runtime behavior.
|
Note
|
Java compile avoidance will treat this bytecode the same since it extracts the ABI. |
Treating the minor number as an input can decrease the likelihood of a cache hit for developer builds. Depending on how standard development environments are across your team, it’s common for many different Java minor version to be in use.
Even without tracking the Java minor version you may have cache misses for developers due to some locally compiled class files which constitute an input to test execution. If these outputs made it into the local build cache on this developers machine even a clean will not solve the situation. Therefore, the choice for tracking the Java minor version is between sometimes or never re-using outputs between different Java minor versions for test execution.
|
Note
|
The compiler infrastructure provided by the JVM used to run Gradle is also used by the Groovy compiler. Therefore, you can expect differences in the bytecode of compiled Groovy classes for the same reasons as above and the same suggestions apply. |
Avoid changing inputs external to your build
If your build is dependent on external dependencies like binary artifacts or dynamic data from a web page you need to make sure that these inputs are consistent throughout your infrastructure. Any variations across machines will result in cache misses.
Never re-release a non-changing binary dependency with the same version number but different contents: if this happens with a plugin dependency, you will never be able to explain why you don’t see cache reuse between machines (it’s because they have different versions of that artifact).
Using SNAPSHOTs or other changing dependencies in your build by design violates the stable task inputs principle.
To use the build cache effectively, you should depend on fixed dependencies.
You may want to look into dependency locking or switch to using composite builds instead.
The same is true for depending on volatile external resources, for example a list of released versions. One way of locking the changes would be to check the volatile resource into source control whenever it changes so that the builds only depend on the state in source control and not on the volatile resource itself.
Suggestions for authoring your build
Review usages of doFirst and doLast
Using doFirst and doLast from a build script on a cacheable task ties you to build script changes since the implementation of the closure comes from the build script.
If possible, you should use separate tasks instead.
Modifying input or output properties via the runtime API in doFirst is discouraged since these changes will not be detected for up-to-date checks and the build cache.
Even worse, when the task does not execute, then the configuration of the task is actually different from when it executes.
Instead of using doFirst for modifying the inputs consider using a separate task to configure the task under question - a so called configure task.
E.g., instead of doing
tasks.jar {
val runtimeClasspath: FileCollection = configurations.runtimeClasspath.get()
doFirst {
manifest {
val classPath = runtimeClasspath.map { it.name }.joinToString(" ")
attributes("Class-Path" to classPath)
}
}
}tasks.named('jar') {
FileCollection runtimeClasspath = configurations.runtimeClasspath
doFirst {
manifest {
def classPath = runtimeClasspath.collect { it.name }.join(" ")
attributes('Class-Path': classPath)
}
}
}do
val configureJar = tasks.register("configureJar") {
doLast {
tasks.jar.get().manifest {
val classPath = configurations.runtimeClasspath.get().map { it.name }.joinToString(" ")
attributes("Class-Path" to classPath)
}
}
}
tasks.jar { dependsOn(configureJar) }def configureJar = tasks.register('configureJar') {
doLast {
tasks.jar.manifest {
def classPath = configurations.runtimeClasspath.collect { it.name }.join(" ")
attributes('Class-Path': classPath)
}
}
}
tasks.named('jar') { dependsOn(configureJar) }|
Warning
|
Note that configuring a task from other task is not supported when using the configuration cache. |
Build logic based on the outcome of a task
Do not base build logic on whether a task has been executed.
In particular you should not assume that the output of a task can only change if it actually executed.
Actually, loading the outputs from the build cache would also change them.
Instead of relying on custom logic to deal with changes to input or output files you should leverage Gradle’s built-in support by declaring the correct inputs and outputs for your tasks and leave it to Gradle to decide if the task actions should be executed.
For the very same reason using outputs.upToDateWhen is discouraged and should be replaced by properly declaring the task’s inputs.
Overlapping outputs
You already saw that overlapping outputs are a problem for task output caching.
When you add new tasks to your build or re-configure built-in tasks make sure you do not create overlapping outputs for cacheable tasks.
If you must you can add a Sync task which then would sync the merged outputs into the target directory while the original tasks remain cacheable.
Develocity will show tasks where caching was disabled for overlapping outputs in the timeline and in the task input comparison:

Achieving stable task inputs
It is crucial to have stable task inputs for every cacheable task. In the following section you will learn about different situations which violate stable task inputs and look at possible solutions.
Volatile task inputs
If you use a volatile input like a timestamp as an input property for a task, then there is nothing Gradle can do to make the task cacheable. You should really think hard if the volatile data is really essential to the output or if it is only there for e.g. auditing purposes.
If the volatile input is essential to the output then you can try to make the task using the volatile input cheaper to execute. You can do this by splitting the task into two tasks - the first task doing the expensive work which is cacheable and the second task adding the volatile data to the output. In this way the output stays the same and the build cache can be used to avoid doing the expensive work. For example, for building a jar file the expensive part - Java compilation - is already a different task while the jar task itself, which is not cacheable, is cheap.
If it is not an essential part of the output, then you should not declare it as an input. As long as the volatile input does not influence the output then there is nothing else to do. Most times though, the input will be part of the output.
Non-repeatable task outputs
Having tasks which generate different outputs for the same inputs can pose a challenge for the effective use of task output caching as seen in repeatable task outputs. If the non-repeatable task output is not used by any other task then the effect is very limited. It basically means that loading the task from the cache might produce a different result than executing the same task locally. If the only difference between the outputs is a timestamp, then you can either accept the effect of the build cache or decide that the task is not cacheable after all.
Non-repeatable task outputs lead to non-stable task inputs as soon as another task depends on the non-repeatable output. For example, re-creating a jar file from the files with the same contents but different modification times yields a different jar file. Any other task depending on this jar file as an input file cannot be loaded from the cache when the jar file is rebuilt locally. This can lead to hard-to-diagnose cache misses when the consuming build is not a clean build or when a cacheable task depends on the output of a non-cacheable task. For example, when doing incremental builds it is possible that the artifact on disk which is considered up-to-date and the artifact in the build cache are different even though they are essentially the same. A task depending on this task output would then not be able to load outputs from the build cache since the inputs are not exactly the same.
As described in the stable task inputs section, you can either make the task outputs repeatable or use input normalization. You already learned about the possibilities with configurable input normalization.
Gradle includes some support for creating repeatable output for archive tasks.
For tar and zip files Gradle can be configured to create reproducible archives.
This is done by configuring e.g. the Zip task via the following snippet.
tasks.register<Zip>("createZip") {
isPreserveFileTimestamps = false
isReproducibleFileOrder = true
// ...
}tasks.register('createZip', Zip) {
preserveFileTimestamps = false
reproducibleFileOrder = true
// ...
}Another way to make the outputs repeatable is to activate caching for a task with non-repeatable outputs. If you can make sure that the same build cache is used for all builds then the task will always have the same outputs for the same inputs by design of the build cache. Going down this road can lead to different problems with cache misses for incremental builds as described above. Moreover, race conditions between different builds trying to store the same outputs in the build cache in parallel can lead to hard-to-diagnose cache misses. If possible, you should avoid going down that route.
Limit the effect of volatile data
If none of the described solutions for dealing with volatile data work for you, you should still be able to limit the effect of volatile data on effective use of the build cache.
This can be done by adding the volatile data later to the outputs as described in the volatile task inputs section.
Another option would be to move the volatile data so it affects fewer tasks.
For example moving the dependency from the compile to the runtime configuration may already have quite an impact.
Sometimes it is also possible to build two artifacts, one containing the volatile data and another one containing a constant representation of the volatile data. The non-volatile output would be used e.g. for testing while the volatile one would be published to an external repository. While this conflicts with the Continuous Delivery "build artifacts once" principle it can sometimes be the only option.
Custom and third party tasks
If your build contains custom or third party tasks, you should take special care that these don’t influence the effectiveness of the build cache.
Special care should also be taken for code generation tasks which may not have repeatable task outputs.
This can happen if the code generator includes e.g. a timestamp in the generated files or depends on the order of the input files.
Other pitfalls can be the use of HashMaps or other data structures without order guarantees in the task’s code.
|
Warning
|
Some third party plugins can even influence cacheability of Gradle’s built-in tasks.
This can happen if they add inputs like absolute paths or volatile data to tasks via the runtime API.
In the worst case this can lead to incorrect builds when the plugins try to depend on the outcome of a task and do not take |
GRADLE ON CI
Executing Gradle builds on Jenkins
|
Tip
|
Top engineering teams using Jenkins have been able to reduce CI build time by up to 90% by using the Gradle Build Cache. Register here for our Build Cache training session to learn how your team can achieve similar results. |
Building Gradle projects doesn’t stop with the developer’s machine. Continuous Integration (CI) has been a long-established practice for running a build for every single change committed to version control to tighten the feedback loop.
In this guide, we’ll discuss how to configure Jenkins for a typical Gradle project.
What you’ll need
-
A text editor
-
A command prompt
-
The Java Development Kit (JDK), version 1.7 or higher
-
A Jenkins installation (setup steps explained in this post)
Setup a typical project
As example, this guide is going to focus on a Java-based project. More specifically, a Gradle plugin written in Java and tested with Spek. First, we’ll get the project set up on your local machine before covering the same steps on CI.
Just follow these steps:
Clone the Gradle Site Plugin repository
$ git clone https://github.com/gradle/gradle-site-plugin.git Cloning into 'gradle-site-plugin'... $ cd gradle-site-plugin
Build the project
As a developer of a Java project, you’ll typical want to compile the source code, run the tests and assemble the JAR artifact. That’s no different for Gradle plugins. The following command achieves exactly that:
$ ./gradlew build BUILD SUCCESSFUL 14 actionable tasks: 14 executed
The project provides the Gradle Wrapper as part of the repository. It is a recommended practice for any Gradle project as it enables your project to built on CI without having to install the Gradle runtime.
Build scan integration
The sample project is equipped with support for generating build scans.
Running the build with the command line option --scan renders a link in the console.
$ ./gradlew build --scan Publishing build scan... https://gradle.com/s/7mtynxxmesdio
The following section will describe how to build the project with the help of Jenkins.
Setup Jenkins
Jenkins is one of the most prominent players in the field. In the course of this section, you’ll learn how to set up Jenkins, configure a job to pull the source code from GitHub and run the Gradle build.
Install and start Jenkins
On the Jenkins website you can pick from a variety of distributions. This post uses the runnable WAR file. A simple Java command brings up the Jenkins server.
$ wget https://mirrors.jenkins.io/war-stable/latest/jenkins.war $ java -jar jenkins.war
In the browser, navigate to localhost with port 8080 to render the Jenkins dashboard.
You will be asked to set up an new administration user and which plugins to install.
Installation of plugins
Confirm to install the recommended plugins when starting Jenkins for the first time. Under "Manage Jenkins > Manage Plugins" ensure that you have the following two plugins installed.
Next, we can set up the job for building the project.
Create a Jenkins job
Setting up a new Gradle job can be achieved with just a couple of clicks. From the left navigation bar select "New Item > Freestyle project". Enter a new name for the project. We’ll pick "gradle-site-plugin" for the project.
Select the radio button "Git" in the section "Source Code Management".
Enter the URL of the GitHub repository: https://github.com/gradle/gradle-site-plugin.git.
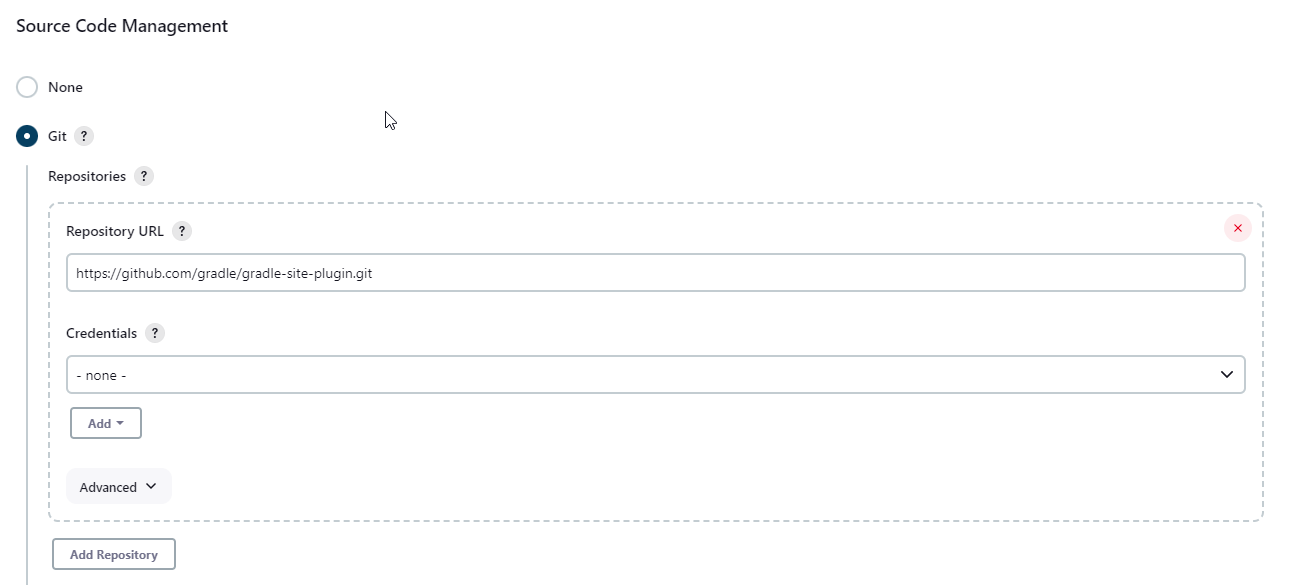
Furthermore, create a "Build step" in the section "Build" by selecting "Invoke Gradle script".
As mentioned before, we’ll want to use the Wrapper to execute the build. In the "Tasks" input box enter the build and use the "Switches" --scan -s to generate a build scan and render a stack trace in case of a build failure.
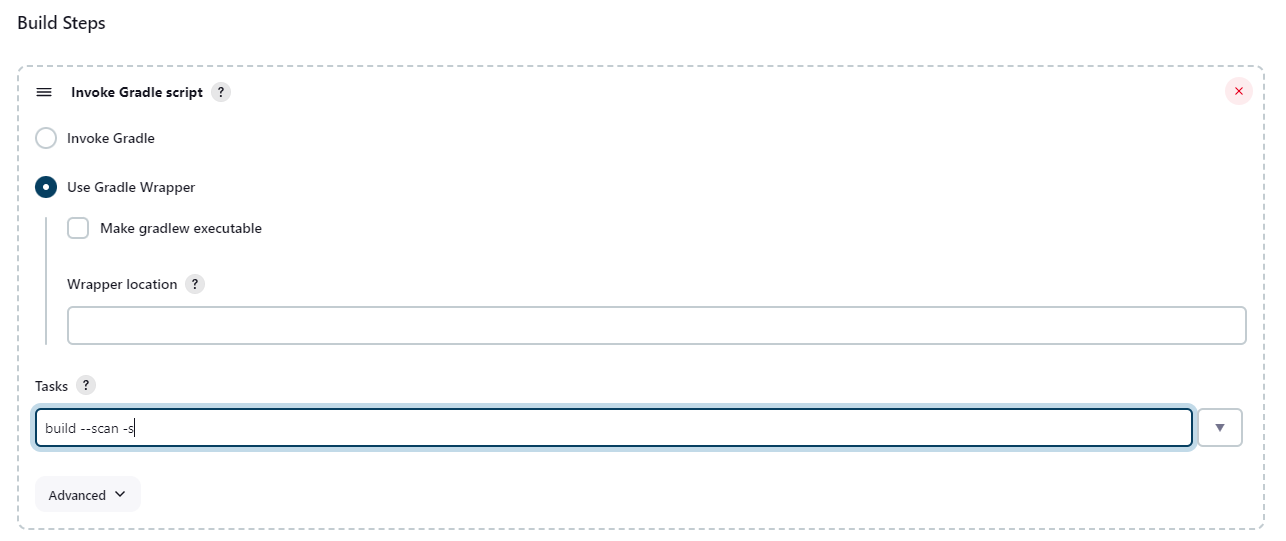
Execute the job
Save the configuration of job and execute an initial build by triggering the "Build Now" button. The build should finish successfully and render a "Gradle Build Scan" icon that brings you directly to the build scan for the given build.
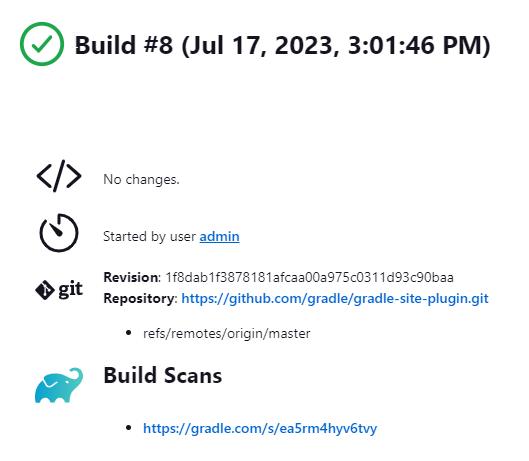
There are various options to trigger Jenkins builds continuously: from polling the repository periodically, to building on a set schedule, or via callback URL.
Further reading
You can learn more about advanced Jenkins usage through these resources:
Summary
Executing Gradle builds on CI can be set up and configured with just a handful of steps. The benefit of receiving fast feedback clearly speaks for itself. If you are not using Jenkins, no problem, many CI products tightly integrate with Gradle as a first-class citizen.
Executing Gradle builds on TeamCity
|
Tip
|
Top engineering teams using TeamCity have been able to reduce CI build time by up to 90% by using the Gradle Build Cache. Register here for our Build Cache training session to learn how your team can achieve similar results. |
Building Gradle projects doesn’t stop with the developer’s machine. Continuous Integration (CI) has been a long-established practice for running a build for every single change committed to version control to tighten the feedback loop.
In this guide, we’ll discuss how to configure TeamCity for a typical Gradle project.
What you’ll need
-
A command prompt
-
The Java Development Kit (JDK), version 1.8 or higher
-
A TeamCity installation (setup steps explained in this guide)
Setup a typical project
For demonstration purposes, this guide is going to focus on building a Java-based project; however, this setup will work with any Gradle-compatible project. More specifically, a Gradle plugin written in Java and tested with Spek. First, we’ll get the project set up on your local machine before covering the same steps on CI.
Just follow these steps:
Clone the Gradle Site Plugin repository
$ git clone https://github.com/gradle/gradle-site-plugin.git Cloning into 'gradle-site-plugin'... $ cd gradle-site-plugin
Build the project
As a developer of a Java project, you’ll typical want to compile the source code, run the tests and assemble the JAR artifact. That’s no different for Gradle plugins. The following command achieves exactly that:
$ ./gradlew build BUILD SUCCESSFUL 14 actionable tasks: 14 executed
The project provides the Gradle Wrapper as part of the repository. It is a recommended practice for any Gradle project as it enables your project to built on CI without having to install the Gradle runtime.
Build scan integration
The sample project is equipped with support for generating build scans.
Running the build with the command line option --scan renders a link in the console.
$ ./gradlew build --scan Publishing build scan... https://gradle.com/s/7mtynxxmesdio
Setup TeamCity
JetBrains TeamCity is a powerful and user-friendly Continuous Integration and Deployment server that works out of the box. JetBrains offers several licensing options that allow you to scale TeamCity to your needs. In this setup, we’ll use TeamCity Professional, a free fully functional edition suitable for average projects. In the course of this section, you’ll learn how to set up TeamCity, create a build configuration to pull the source code from GitHub and run the Gradle build.
Install and start TeamCity
On the TeamCity website you can pick from a variety of distributions. This post uses TeamCity bundled with Tomcat servlet container and covers the evaluation setup of a TeamCity server and a default build agent running on the same machine.
-
Make sure you have JRE or JDK installed and the JAVA_HOME environment variable is pointing to the Java installation directory. Oracle Java 1.8 JDK is required.
-
Download TeamCity .tar.gz distribution. Unpack the
TeamCity<version number>.tar.gzarchive, for example, using the WinZip, WinRar or a similar utility under Windows, or the following command under Linux or macOS:
tar xfz TeamCity<version number>.tar.gz
-
Start the TeamCity server and one default agent at the same time, using the runAll script provided in the <TeamCity home>/bin directory, e.g.
runAll.sh start
-
To access the TeamCity Web UI, navigate to
http://localhost:8111/. Follow the defaults of the TeamCity setup. You will be asked to set up a new administration user.
Next, we can set up the project and run a build in TeamCity.
Create a TeamCity build
Setting up a new Gradle build in TeamCity requires just a few clicks: TeamCity comes bundled with a Gradle plugin, so you do not need to install plugins additionally. However, it is recommended that you install the TeamCity Build Scan plugin.
On the Administration | Projects page click Create project,
use the option From the repository URL and enter the URL of the GitHub repository: https://github.com/gradle/gradle-site-plugin.git.
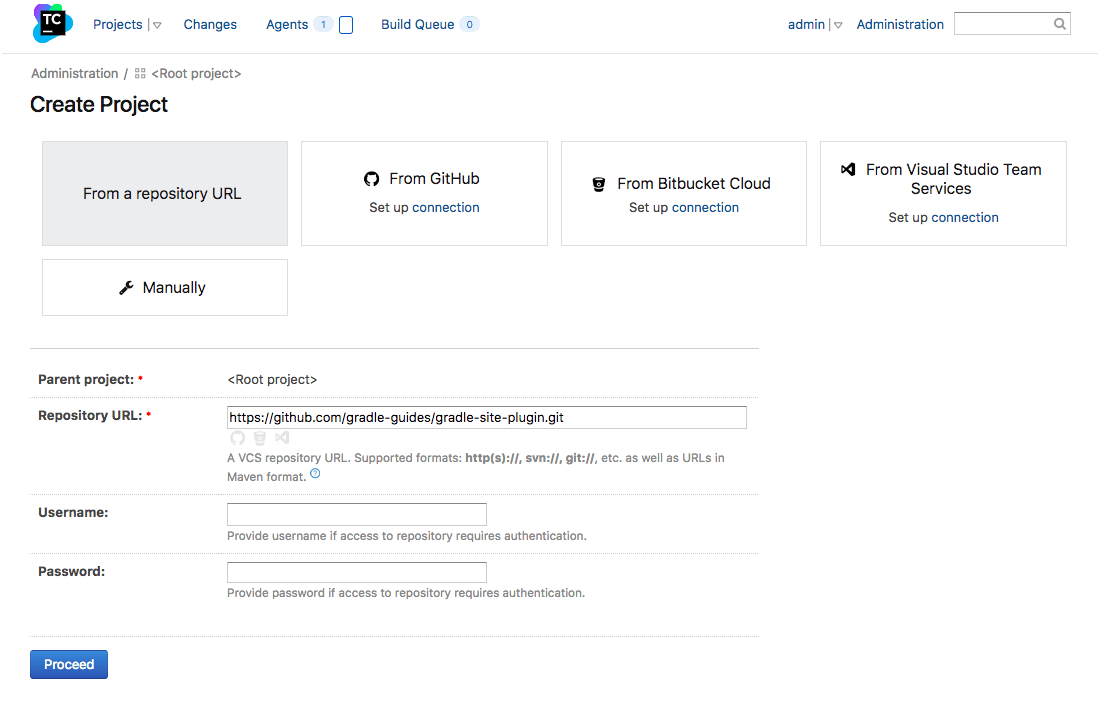
Follow the Create Project wizard, it will prompt for the project and build configuration name and automatically detect build steps. Select the automatically Gradle build step and click Use selected:
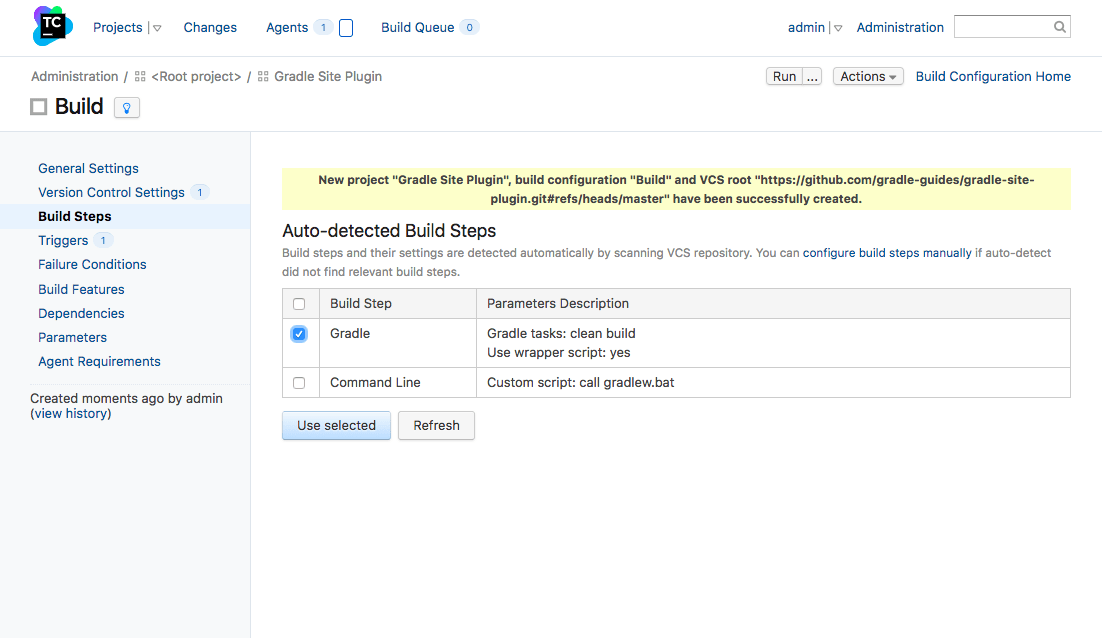
The build step is added to the build configuration:
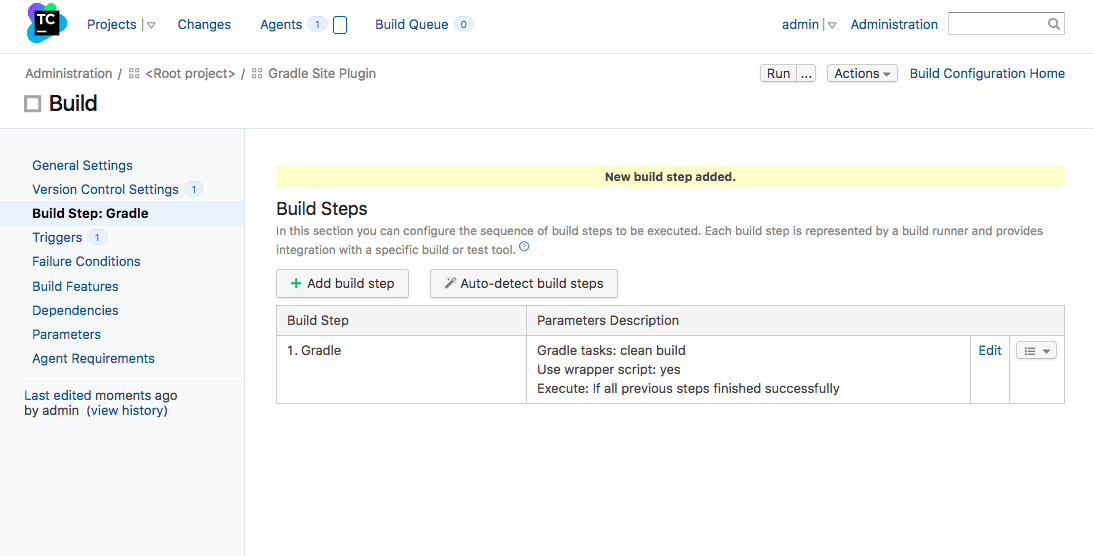
Click Edit, on the page that opens click Advanced options.
Using the Wrapper to execute the build is considered good practice with Gradle,
and on automatic detection this option is selected by default.
We’ll want to generate a build scan,
so we’ll enter the --scan option in Additional Gradle command line parameters field.
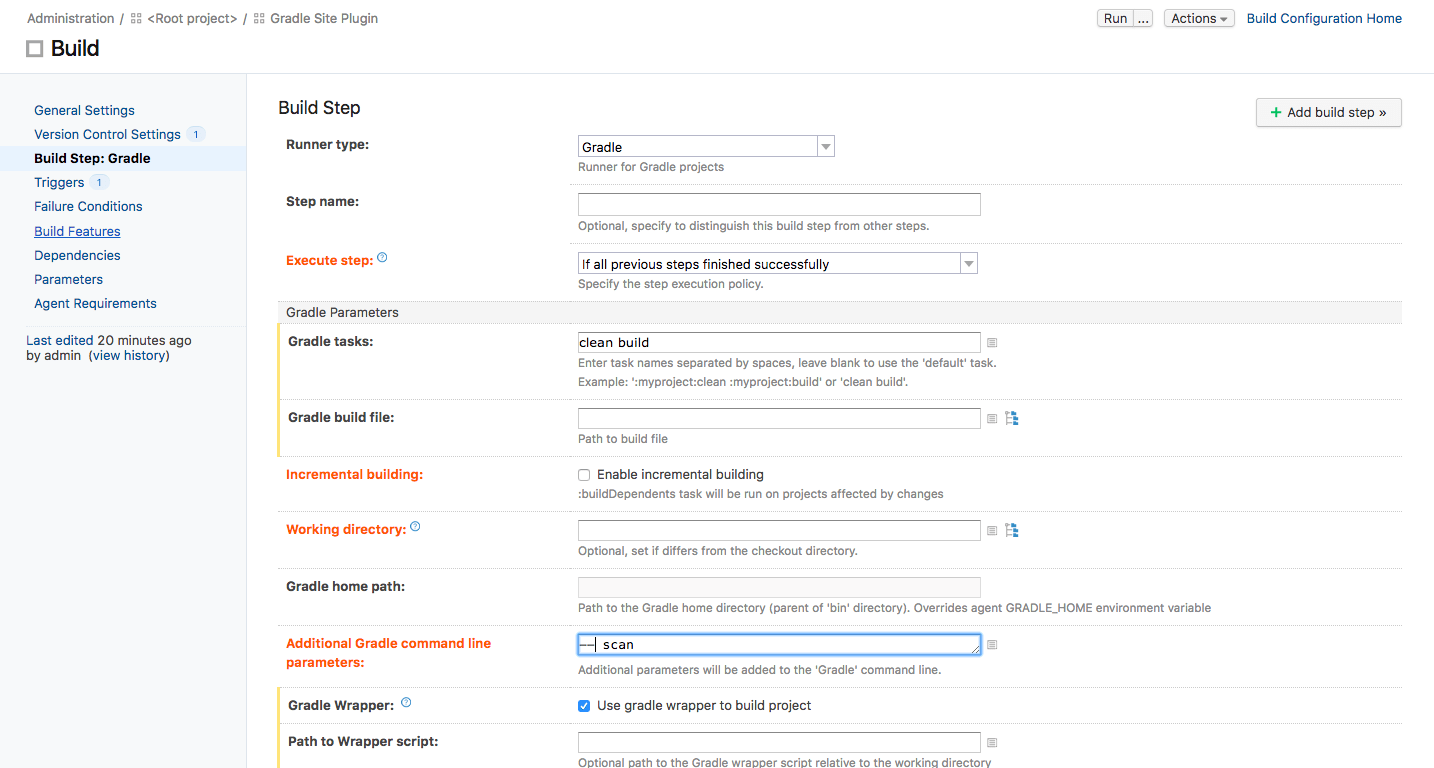
Save the settings and we’re ready to run the build.
Run the build in TeamCity
Click the Run button in the right top corner:
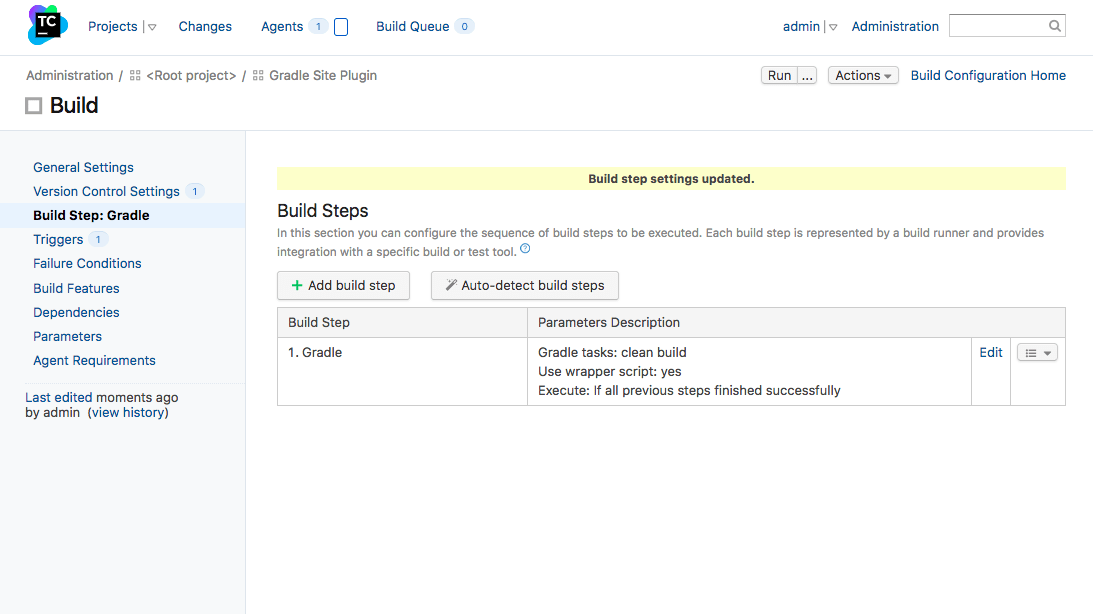
TeamCity will start the build and you’ll be able to view the build progress by clicking Build Configuration Home. When the build is finished, you can review the build results by clicking the build number link:

You can view the tests right here in TeamCity:
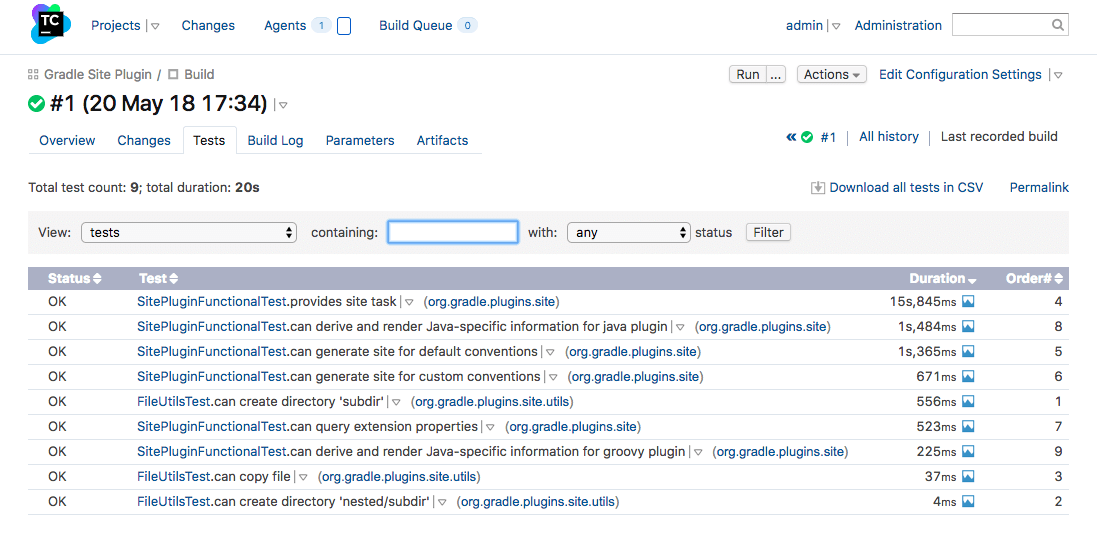
The information on parameters and environment of the build is available on the Parameters tab of the build results.
If you installed the TeamCity Build Scan plugin, you will see a link to the build scan in the Build Results view:
Otherwise, the link to the build scan for the given build is available in the build log:
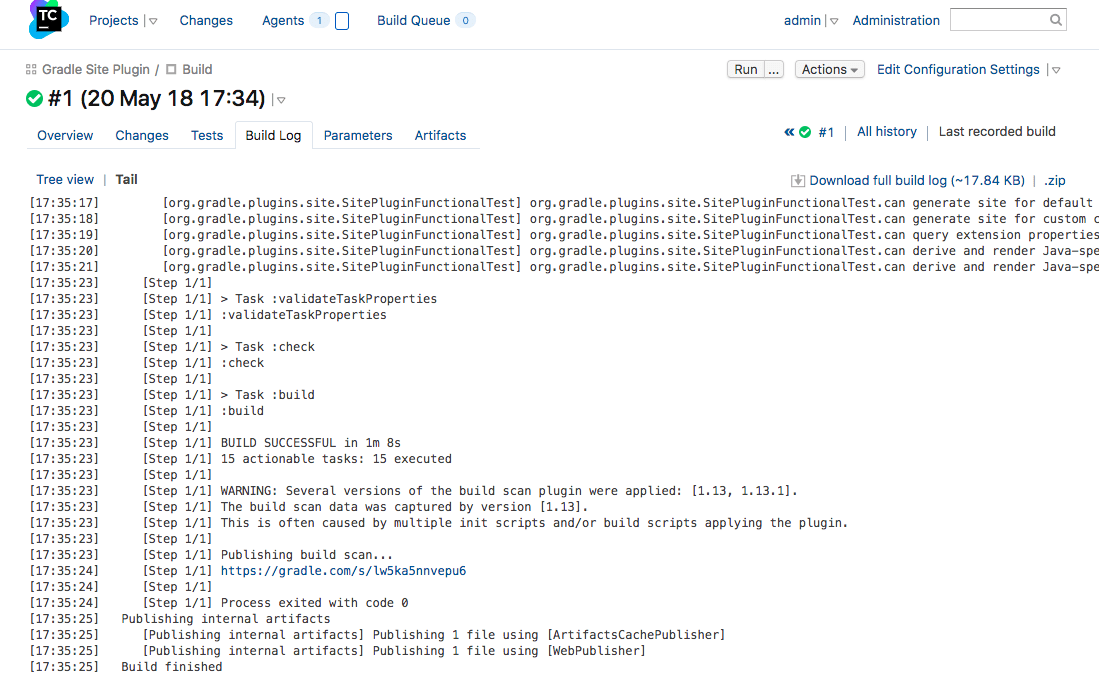
There are various options to trigger TeamCity builds continuously: from polling the repository periodically, to building on a set schedule, or via post-commit hook.
Further reading
You can learn more about advanced TeamCity usage through these resources:
More information is available in TeamCity documentation. Follow the TeamCity blog for the latest news.
Summary
Executing Gradle builds on CI can be set up and configured with just a handful of steps. The benefit of receiving fast feedback clearly speaks for itself. If you are not using TeamCity, no problem, many CI products tightly integrate with Gradle as a first-class citizen.
Executing Gradle builds on GitHub Actions
|
Tip
|
Top engineering teams using GitHub Actions have been able to reduce CI build time by up to 90% by using the Gradle Build Cache. Register here for our Build Cache training session to learn how your team can achieve similar results. |
Building Gradle projects doesn’t stop with the developer’s machine. Continuous Integration (CI) has been a long-established practice for running a build for every single change committed to version control to tighten the feedback loop.
In this guide, we’ll discuss how to configure GitHub Actions for a Gradle project hosted on GitHub.
Introduction
GitHub Actions is a cloud-based CI solution provider built directly into GitHub, making it an excellent choice for projects hosted on GitHub.
Using the Gradle Build Action makes it simple to integrate any Gradle project into a GitHub Actions workflow.
What you’ll need
-
A text editor
-
A command prompt
-
The Java Development Kit (JDK), version 1.8 or higher
-
A local Gradle installation, to initialize a new Gradle project
-
A GitHub account
Setup a Gradle project on GitHub
If you have an existing Gradle project hosted on GitHub, then you can skip this step and move directly to Configure GitHub Actions.
If not, follow these step to initialize a new Gradle project on GitHub.
Create a new GitHub repository for your project
Via the GitHub user interface, create a new repository named github-actions-gradle-sample.
Clone the repository locally
$ git clone git@github.com:<YOUR-GITHUB-USER>/github-actions-gradle-sample.git Cloning into 'github-actions-gradle-sample'... $ cd github-actions-gradle-sample
Initialize the Gradle project and commit to the repository
Use gradle init to create a fresh Gradle project. You can choose any of the available options during init, but we recommend choosing "library" as the project type.
Once the project is generated, commit the changes and push to the repository.
$ gradle init $ git add . $ git commit -m "Initial commit" $ git push
Enable Build Scan™ publishing
Gradle Build Scans are a great way to view your build results, and provide valuable insights into your build. In order to publish Build Scans from GitHub Actions, you’ll need to pre-approve the Terms & Conditions.
To do so, add the following content to the top of your settings.gradle[.kts] file. The "CI" environment variable is set by GitHub Actions:
plugins {
id("com.gradle.enterprise") version("3.16.2")
}
gradleEnterprise {
if (System.getenv("CI") != null) {
buildScan {
publishAlways()
termsOfServiceUrl = "https://gradle.com/terms-of-service"
termsOfServiceAgree = "yes"
}
}
}Test building the project
The project uses the Gradle Wrapper for building the project. It is a recommended practice for any Gradle project as it enables your project to built on CI without having to install the Gradle runtime.
Before asking GitHub Actions to build your project, it’s useful to ensure that it builds locally. Adding the "CI" environment variable will emulate running the build on GitHub Actions.
The following command achieves that:
$ CI=true ./gradlew build BUILD SUCCESSFUL Publishing build scan... https://gradle.com/s/7mtynxxmesdio
If the build works as expected, commit the changes and push to the repository.
$ git commit -a -m "Publish Build Scans from GitHub Actions" $ git push
Configure GitHub Actions
You can create a GitHub Actions workflow by adding a .github/workflows/<workflow-name>.yml file to your repository.
This workflow definition file contains all relevant instructions for building the project on GitHub Actions.
The following workflow file instructs GitHub Actions to build your Gradle project using the Gradle Wrapper, executed by the default Java distribution for GitHub Actions.
Create a new file named .github/workflows/build-gradle-project.yml with the following content, and push it to the GitHub repository.
name: Build Gradle project
on:
push:
jobs:
build-gradle-project:
runs-on: ubuntu-latest
steps:
- name: Checkout project sources
uses: actions/checkout@v4
- name: Setup Gradle
uses: gradle/gradle-build-action@v2
- name: Run build with Gradle Wrapper
run: ./gradlew build
Commit the changes and push to the repository:
$ git add . $ git commit -m "Add GitHub Actions workflow" $ git push
View the GitHub Actions results
Once this workflow file is pushed, you should immediately see the workflow execution in the GitHub Actions page for your repository (eg https://github.com/gradle/gradle/actions). Any subsequent push to the repository will trigger the workflow to run.
List all runs of the GitHub Actions workflow
The main actions page can be filtered to list all runs for a GitHub Actions workflow.
See the results for GitHub Actions workflow run
Clicking on the link for a workflow run will show the details of the workflow run, including a link to the build scan produced for the build.
|
Note
|
Configuring build scans is especially helpful on cloud CI systems like GitHub Actions because it has additional environment and test results information that are difficult to obtain otherwise. |
View the details for Jobs and Steps in the workflow
Finally, you can view the details for the individual workflow Jobs and each Step defined for a Job:
Enable caching of downloaded artifacts
The gradle-build-action used by this workflow will enable saving and restoring of the Gradle User Home directory in the built-in GitHub Actions cache. This will speed up your GitHub Actions build by avoiding the need to re-download Gradle versions and project dependencies, as well as re-using state from the previous workflow execution.
Details about what entries are saved/restored from the cache can be viewed in the Post Setup Gradle step:
Further reading
Learn more about building Gradle projects with GitHub Actions:
Summary
Executing Gradle builds on CI can be set up and configured with just a handful of steps. The benefit of receiving fast feedback clearly speaks for itself. GitHub Actions provides a simple, convenient mechanism to setup CI for any Gradle project hosted on GitHub.
Executing Gradle builds on Travis CI
|
Tip
|
Top engineering teams using Travis CI have been able to reduce CI build time by up to 90% by using the Gradle Build Cache. Register here for our Build Cache training session to learn how your team can achieve similar results. |
Building Gradle projects doesn’t stop with the developer’s machine. Continuous Integration (CI) has been a long-established practice for running a build for every single change committed to version control to tighten the feedback loop.
In this guide, we’ll discuss how to configure Travis CI for a typical Gradle project.
What you’ll need
-
A text editor
-
A command prompt
-
The Java Development Kit (JDK), version 1.8 or higher
Setup a typical project
As example, this guide is going to focus on a Java-based project. More specifically, a Gradle plugin written in Java and tested with Spek. First, we’ll get the project set up on your local machine before covering the same steps on CI.
Just follow these steps:
Clone the Gradle Site Plugin repository
$ git clone https://github.com/gradle/gradle-site-plugin.git Cloning into 'gradle-site-plugin'... $ cd gradle-site-plugin
Build the project
As a developer of a Java project, you’ll typical want to compile the source code, run the tests and assemble the JAR artifact. That’s no different for Gradle plugins. The following command achieves exactly that:
$ ./gradlew build BUILD SUCCESSFUL 14 actionable tasks: 14 executed
The project provides the Gradle Wrapper as part of the repository. It is a recommended practice for any Gradle project as it enables your project to built on CI without having to install the Gradle runtime.
Build scan integration
The sample project is equipped with support for generating build scans.
Running the build with the command line option --scan renders a link in the console.
$ ./gradlew build --scan Publishing build scan... https://gradle.com/s/7mtynxxmesdio
The following section will describe how to build the project with the help of Travis CI.
Configure Travis CI
Travis CI is a free, cloud-based CI solution provider making it an excellent choice for open source projects. You can build any project as long as it is hosted on GitHub as a public repository. Travis CI doesn’t not provide built-in options to post-process produced artifacts of the build e.g. host the JAR file or the HTML test reports. You will have to use external services (like S3) to transfer the files.
Create the configuration file
Travis CI requires you to check in a configuration file with your source code named .travis.yml.
This file contains all relevant instructions for building the project.
The following configuration file tells Travis CI to build a Java project with JDK 8, skip the usual default execution step, and run the Gradle build with the Wrapper.
language: java install: skip os: linux dist: trusty jdk: oraclejdk8 script: - ./gradlew build --scan -s
Select the project from the Travis CI profile. After activating the repository from the dashboard, the project is ready to be built with every single commit.

|
Note
|
Configuring build scans is especially helpful on cloud CI systems like Travis CI because it has additional environment and test results information that are difficult to obtain otherwise. |
Enable caching of downloaded artifacts
Gradle’s dependency management mechanism resolves declared modules and their corresponding artifacts from a binary repository. Once downloaded, the files will be re-used from the cache. You need to tell Travis CI explicitly that you want to store and use the Gradle cache and Wrapper for successive invocations of the build.
before_cache:
- rm -f $HOME/.gradle/caches/modules-2/modules-2.lock
- rm -fr $HOME/.gradle/caches/*/plugin-resolution/
cache:
directories:
- $HOME/.gradle/caches/
- $HOME/.gradle/wrapper/
Further reading
You can learn more about advanced Travis CI usage through these resources:
Summary
Executing Gradle builds on CI can be set up and configured with just a handful of steps. The benefit of receiving fast feedback clearly speaks for itself. If you are not using Travis CI, no problem, many CI products tightly integrate with Gradle as a first-class citizen.
REFERENCE
Command-Line Interface Reference
The command-line interface is the primary method of interacting with Gradle.
The following is a reference for executing and customizing the Gradle command-line. It also serves as a reference when writing scripts or configuring continuous integration.
Use of the Gradle Wrapper is highly encouraged.
Substitute ./gradlew (in macOS / Linux) or gradlew.bat (in Windows) for gradle in the following examples.
Executing Gradle on the command-line conforms to the following structure:
gradle [taskName...] [--option-name...]
Options are allowed before and after task names.
gradle [--option-name...] [taskName...]
If multiple tasks are specified, you should separate them with a space.
gradle [taskName1 taskName2...] [--option-name...]
Options that accept values can be specified with or without = between the option and argument. The use of = is recommended.
gradle [...] --console=plain
Options that enable behavior have long-form options with inverses specified with --no-. The following are opposites.
gradle [...] --build-cache gradle [...] --no-build-cache
Many long-form options have short-option equivalents. The following are equivalent:
gradle --help gradle -h
|
Note
|
Many command-line flags can be specified in gradle.properties to avoid needing to be typed.
See the Configuring build environment guide for details.
|
Command-line usage
The following sections describe the use of the Gradle command-line interface.
Some plugins also add their own command line options.
For example, --tests, which is added by Java test filtering.
For more information on exposing command line options for your own tasks, see Declaring command-line options.
Executing tasks
You can learn about what projects and tasks are available in the project reporting section.
Most builds support a common set of tasks known as lifecycle tasks. These include the build, assemble, and check tasks.
To execute a task called myTask on the root project, type:
$ gradle :myTask
This will run the single myTask and all of its dependencies.
Specify options for tasks
To pass an option to a task, prefix the option name with -- after the task name:
$ gradle exampleTask --exampleOption=exampleValue
Disambiguate task options from built-in options
Gradle does not prevent tasks from registering options that conflict with Gradle’s built-in options, like --profile or --help.
You can fix conflicting task options from Gradle’s built-in options with a -- delimiter before the task name in the command:
$ gradle [--built-in-option-name...] -- [taskName...] [--task-option-name...]
Consider a task named mytask that accepts an option named profile:
-
In
gradle mytask --profile, Gradle accepts--profileas the built-in Gradle option. -
In
gradle -- mytask --profile=value, Gradle passes--profileas a task option.
Executing tasks in multi-project builds
In a multi-project build, subproject tasks can be executed with : separating the subproject name and task name.
The following are equivalent when run from the root project:
$ gradle :subproject:taskName
$ gradle subproject:taskName
You can also run a task for all subprojects using a task selector that consists of only the task name.
The following command runs the test task for all subprojects when invoked from the root project directory:
$ gradle test
|
Note
|
Some tasks selectors, like help or dependencies, will only run the task on the project they are invoked on and not on all the subprojects.
|
When invoking Gradle from within a subproject, the project name should be omitted:
$ cd subproject
$ gradle taskName
|
Tip
|
When executing the Gradle Wrapper from a subproject directory, reference gradlew relatively. For example: ../gradlew taskName.
|
Executing multiple tasks
You can also specify multiple tasks. The tasks' dependencies determine the precise order of execution, and a task having no dependencies may execute earlier than it is listed on the command-line.
For example, the following will execute the test and deploy tasks in the order that they are listed on the command-line and will also execute the dependencies for each task.
$ gradle test deploy
Command line order safety
Although Gradle will always attempt to execute the build quickly, command line ordering safety will also be honored.
For example, the following will
execute clean and build along with their dependencies:
$ gradle clean build
However, the intention implied in the command line order is that clean should run first and then build. It would be incorrect to execute clean after build, even if doing so would cause the build to execute faster since clean would remove what build created.
Conversely, if the command line order was build followed by clean, it would not be correct to execute clean before build. Although Gradle will execute the build as quickly as possible, it will also respect the safety of the order of tasks specified on the command line and ensure that clean runs before build when specified in that order.
Note that command line order safety relies on tasks properly declaring what they create, consume, or remove.
Excluding tasks from execution
You can exclude a task from being executed using the -x or --exclude-task command-line option and providing the name of the task to exclude:
$ gradle dist --exclude-task test
> Task :compile compiling source > Task :dist building the distribution BUILD SUCCESSFUL in 0s 2 actionable tasks: 2 executed

You can see that the test task is not executed, even though the dist task depends on it.
The test task’s dependencies, such as compileTest, are not executed either.
The dependencies of test that other tasks depend on, such as compile, are still executed.
Forcing tasks to execute
You can force Gradle to execute all tasks ignoring up-to-date checks using the --rerun-tasks option:
$ gradle test --rerun-tasks
This will force test and all task dependencies of test to execute. It is similar to running gradle clean test, but without the build’s generated output being deleted.
Alternatively, you can tell Gradle to rerun a specific task using the --rerun built-in task option.
Continue the build after a task failure
By default, Gradle aborts execution and fails the build when any task fails. This allows the build to complete sooner and prevents cascading failures from obfuscating the root cause of an error.
You can use the --continue option to force Gradle to execute every task when a failure occurs:
$ gradle test --continue
When executed with --continue, Gradle executes every task in the build if all the dependencies for that task are completed without failure.
For example, tests do not run if there is a compilation error in the code under test because the test task depends on the compilation task.
Gradle outputs each of the encountered failures at the end of the build.
|
Note
|
If any tests fail, many test suites fail the entire test task.
Code coverage and reporting tools frequently run after the test task, so "fail fast" behavior may halt execution before those tools run.
|
Name abbreviation
When you specify tasks on the command-line, you don’t have to provide the full name of the task.
You can provide enough of the task name to identify the task uniquely.
For example, it is likely gradle che is enough for Gradle to identify the check task.
The same applies to project names. You can execute the check task in the library subproject with the gradle lib:che command.
You can use camel case patterns for more complex abbreviations. These patterns are expanded to match camel case and kebab case names.
For example, the pattern foBa (or fB) matches fooBar and foo-bar.
More concretely, you can run the compileTest task in the my-awesome-library subproject with the command gradle mAL:cT.
$ gradle mAL:cT
> Task :my-awesome-library:compileTest compiling unit tests BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
Abbreviations can also be used with the -x command-line option.
Tracing name expansion
For complex projects, it might be ambiguous if the intended tasks were executed. When using abbreviated names, a single typo can lead to the execution of unexpected tasks.
When INFO, or more verbose logging is enabled, the output will contain extra information about the project and task name expansion.
For example, when executing the mAL:cT command on the previous example, the following log messages will be visible:
No exact project with name ':mAL' has been found. Checking for abbreviated names. Found exactly one project that matches the abbreviated name ':mAL': ':my-awesome-library'. No exact task with name ':cT' has been found. Checking for abbreviated names. Found exactly one task name, that matches the abbreviated name ':cT': ':compileTest'.
Common tasks
The following are task conventions applied by built-in and most major Gradle plugins.
Computing all outputs
It is common in Gradle builds for the build task to designate assembling all outputs and running all checks:
$ gradle build
Running applications
It is common for applications to run with the run task, which assembles the application and executes some script or binary:
$ gradle run
Running all checks
It is common for all verification tasks, including tests and linting, to be executed using the check task:
$ gradle check
Cleaning outputs
You can delete the contents of the build directory using the clean task. Doing so will cause pre-computed outputs to be lost, causing significant additional build time for the subsequent task execution:
$ gradle clean
Project reporting
Gradle provides several built-in tasks which show particular details of your build. This can be useful for understanding your build’s structure and dependencies, as well as debugging problems.
Listing projects
Running the projects task gives you a list of the subprojects of the selected project, displayed in a hierarchy:
$ gradle projects
You also get a project report within Build Scans.
Listing tasks
Running gradle tasks gives you a list of the main tasks of the selected project. This report shows the default tasks for the project, if any, and a description for each task:
$ gradle tasks
By default, this report shows only those tasks assigned to a task group.
Groups (such as verification, publishing, help, build…) are available as the header of each section when listing tasks:
> Task :tasks Build tasks ----------- assemble - Assembles the outputs of this project. Build Setup tasks ----------------- init - Initializes a new Gradle build. Distribution tasks ------------------ assembleDist - Assembles the main distributions Documentation tasks ------------------- javadoc - Generates Javadoc API documentation for the main source code.
You can obtain more information in the task listing using the --all option:
$ gradle tasks --all
The option --no-all can limit the report to tasks assigned to a task group.
If you need to be more precise, you can display only the tasks from a specific group using the --group option:
$ gradle tasks --group="build setup"
Show task usage details
Running gradle help --task someTask gives you detailed information about a specific task:
$ gradle -q help --task libs
Detailed task information for libs
Paths
:api:libs
:webapp:libs
Type
Task (org.gradle.api.Task)
Options
--rerun Causes the task to be re-run even if up-to-date.
Description
Builds the JAR
Group
build
This information includes the full task path, the task type, possible task-specific command line options, and the description of the given task.
You can get detailed information about the task class types using the --types option or using --no-types to hide this information.
Reporting dependencies
Build Scans give a full, visual report of what dependencies exist on which configurations, transitive dependencies, and dependency version selection.
They can be invoked using the --scan options:
$ gradle myTask --scan
This will give you a link to a web-based report, where you can find dependency information like this:
Listing project dependencies
Running the dependencies task gives you a list of the dependencies of the selected project, broken down by configuration. For each configuration, the direct and transitive dependencies of that configuration are shown in a tree.
Below is an example of this report:
$ gradle dependencies
> Task :app:dependencies
------------------------------------------------------------
Project ':app'
------------------------------------------------------------
compileClasspath - Compile classpath for source set 'main'.
+--- project :model
| \--- org.json:json:20220924
+--- com.google.inject:guice:5.1.0
| +--- javax.inject:javax.inject:1
| +--- aopalliance:aopalliance:1.0
| \--- com.google.guava:guava:30.1-jre -> 28.2-jre
| +--- com.google.guava:failureaccess:1.0.1
| +--- com.google.guava:listenablefuture:9999.0-empty-to-avoid-conflict-with-guava
| +--- com.google.code.findbugs:jsr305:3.0.2
| +--- org.checkerframework:checker-qual:2.10.0 -> 3.28.0
| +--- com.google.errorprone:error_prone_annotations:2.3.4
| \--- com.google.j2objc:j2objc-annotations:1.3
+--- com.google.inject:guice:{strictly 5.1.0} -> 5.1.0 (c)
+--- org.json:json:{strictly 20220924} -> 20220924 (c)
+--- javax.inject:javax.inject:{strictly 1} -> 1 (c)
+--- aopalliance:aopalliance:{strictly 1.0} -> 1.0 (c)
+--- com.google.guava:guava:{strictly [28.0-jre, 28.5-jre]} -> 28.2-jre (c)
+--- com.google.guava:guava:{strictly 28.2-jre} -> 28.2-jre (c)
+--- com.google.guava:failureaccess:{strictly 1.0.1} -> 1.0.1 (c)
+--- com.google.guava:listenablefuture:{strictly 9999.0-empty-to-avoid-conflict-with-guava} -> 9999.0-empty-to-avoid-conflict-with-guava (c)
+--- com.google.code.findbugs:jsr305:{strictly 3.0.2} -> 3.0.2 (c)
+--- org.checkerframework:checker-qual:{strictly 3.28.0} -> 3.28.0 (c)
+--- com.google.errorprone:error_prone_annotations:{strictly 2.3.4} -> 2.3.4 (c)
\--- com.google.j2objc:j2objc-annotations:{strictly 1.3} -> 1.3 (c)
Concrete examples of build scripts and output available in Viewing and debugging dependencies.
Running the buildEnvironment task visualises the buildscript dependencies of the selected project, similarly to how gradle dependencies visualizes the dependencies of the software being built:
$ gradle buildEnvironment
Running the dependencyInsight task gives you an insight into a particular dependency (or dependencies) that match specified input:
$ gradle dependencyInsight --dependency [...] --configuration [...]
The --configuration parameter restricts the report to a particular configuration such as compileClasspath.
Listing project properties
Running the properties task gives you a list of the properties of the selected project:
$ gradle -q api:properties
------------------------------------------------------------ Project ':api' - The shared API for the application ------------------------------------------------------------ allprojects: [project ':api'] ant: org.gradle.api.internal.project.DefaultAntBuilder@12345 antBuilderFactory: org.gradle.api.internal.project.DefaultAntBuilderFactory@12345 artifacts: org.gradle.api.internal.artifacts.dsl.DefaultArtifactHandler_Decorated@12345 asDynamicObject: DynamicObject for project ':api' baseClassLoaderScope: org.gradle.api.internal.initialization.DefaultClassLoaderScope@12345
You can also query a single property with the optional --property argument:
$ gradle -q api:properties --property allprojects
------------------------------------------------------------ Project ':api' - The shared API for the application ------------------------------------------------------------ allprojects: [project ':api']
Command-line completion
Gradle provides bash and zsh tab completion support for tasks, options, and Gradle properties through gradle-completion (installed separately):

Debugging options
-?,-h,--help-
Shows a help message with the built-in CLI options. To show project-contextual options, including help on a specific task, see the
helptask. -v,--version-
Prints Gradle, Groovy, Ant, JVM, and operating system version information and exit without executing any tasks.
-V,--show-version-
Prints Gradle, Groovy, Ant, JVM, and operating system version information and continue execution of specified tasks.
-S,--full-stacktrace-
Print out the full (very verbose) stacktrace for any exceptions. See also logging options.
-s,--stacktrace-
Print out the stacktrace also for user exceptions (e.g. compile error). See also logging options.
--scan-
Create a Build Scan with fine-grained information about all aspects of your Gradle build.
-Dorg.gradle.debug=true-
Debug Gradle Daemon process. Gradle will wait for you to attach a debugger at
localhost:5005by default. -Dorg.gradle.debug.host=(host address)-
Specifies the host address to listen on or connect to when debug is enabled. In the server mode on Java 9 and above, passing
*for the host will make the server listen on all network interfaces. By default, no host address is passed to JDWP, so on Java 9 and above, the loopback address is used, while earlier versions listen on all interfaces. -Dorg.gradle.debug.port=(port number)-
Specifies the port number to listen on when debug is enabled. Default is
5005. -Dorg.gradle.debug.server=(true,false)-
If set to
trueand debugging is enabled, Gradle will run the build with the socket-attach mode of the debugger. Otherwise, the socket-listen mode is used. Default istrue. -Dorg.gradle.debug.suspend=(true,false)-
When set to
trueand debugging is enabled, the JVM running Gradle will suspend until a debugger is attached. Default istrue. -Dorg.gradle.daemon.debug=true-
Debug Gradle Daemon process. (duplicate of
-Dorg.gradle.debug)
Performance options
Try these options when optimizing and improving build performance.
Many of these options can be specified in the gradle.properties file, so command-line flags are unnecessary.
--build-cache,--no-build-cache-
Toggles the Gradle Build Cache. Gradle will try to reuse outputs from previous builds. Default is off.
--configuration-cache,--no-configuration-cache-
Toggles the Configuration Cache. Gradle will try to reuse the build configuration from previous builds. Default is off.
--configuration-cache-problems=(fail,warn)-
Configures how the configuration cache handles problems. Default is
fail.Set to
warnto report problems without failing the build.Set to
failto report problems and fail the build if there are any problems. --configure-on-demand,--no-configure-on-demand-
Toggles configure-on-demand. Only relevant projects are configured in this build run. Default is off.
--max-workers-
Sets the maximum number of workers that Gradle may use. Default is number of processors.
--parallel,--no-parallel-
Build projects in parallel. For limitations of this option, see Parallel Project Execution. Default is off.
--priority-
Specifies the scheduling priority for the Gradle daemon and all processes launched by it. Values are
normalorlow. Default is normal. --profile-
Generates a high-level performance report in the
layout.buildDirectory.dir("reports/profile")directory.--scanis preferred. --scan-
Generate a build scan with detailed performance diagnostics.

--watch-fs,--no-watch-fs-
Toggles watching the file system. When enabled, Gradle reuses information it collects about the file system between builds. Enabled by default on operating systems where Gradle supports this feature.
Gradle daemon options
You can manage the Gradle Daemon through the following command line options.
--daemon,--no-daemon-
Use the Gradle Daemon to run the build. Starts the daemon if not running or the existing daemon is busy. Default is on.
--foreground-
Starts the Gradle Daemon in a foreground process.
--status(Standalone command)-
Run
gradle --statusto list running and recently stopped Gradle daemons. It only displays daemons of the same Gradle version. --stop(Standalone command)-
Run
gradle --stopto stop all Gradle Daemons of the same version. -Dorg.gradle.daemon.idletimeout=(number of milliseconds)-
Gradle Daemon will stop itself after this number of milliseconds of idle time. Default is 10800000 (3 hours).
Logging options
Setting log level
You can customize the verbosity of Gradle logging with the following options, ordered from least verbose to most verbose.
-Dorg.gradle.logging.level=(quiet,warn,lifecycle,info,debug)-
Set logging level via Gradle properties.
-q,--quiet-
Log errors only.
-w,--warn-
Set log level to warn.
-i,--info-
Set log level to info.
-d,--debug-
Log in debug mode (includes normal stacktrace).
Lifecycle is the default log level.
Customizing log format
You can control the use of rich output (colors and font variants) by specifying the console mode in the following ways:
-Dorg.gradle.console=(auto,plain,rich,verbose)-
Specify console mode via Gradle properties. Different modes are described immediately below.
--console=(auto,plain,rich,verbose)-
Specifies which type of console output to generate.
Set to
plainto generate plain text only. This option disables all color and other rich output in the console output. This is the default when Gradle is not attached to a terminal.Set to
auto(the default) to enable color and other rich output in the console output when the build process is attached to a console or to generate plain text only when not attached to a console. This is the default when Gradle is attached to a terminal.Set to
richto enable color and other rich output in the console output, regardless of whether the build process is not attached to a console. When not attached to a console, the build output will use ANSI control characters to generate the rich output.Set to
verboseto enable color and other rich output likerichwith output task names and outcomes at the lifecycle log level, (as is done by default in Gradle 3.5 and earlier).
Showing or hiding warnings
By default, Gradle won’t display all warnings (e.g. deprecation warnings). Instead, Gradle will collect them and render a summary at the end of the build like:
Deprecated Gradle features were used in this build, making it incompatible with Gradle 5.0.
You can control the verbosity of warnings on the console with the following options:
-Dorg.gradle.warning.mode=(all,fail,none,summary)-
Specify warning mode via Gradle properties. Different modes are described immediately below.
--warning-mode=(all,fail,none,summary)-
Specifies how to log warnings. Default is
summary.Set to
allto log all warnings.Set to
failto log all warnings and fail the build if there are any warnings.Set to
summaryto suppress all warnings and log a summary at the end of the build.Set to
noneto suppress all warnings, including the summary at the end of the build.
Rich console
Gradle’s rich console displays extra information while builds are running.

Features:
-
Progress bar and timer visually describe the overall status
-
Parallel work-in-progress lines below describe what is happening now
-
Colors and fonts are used to highlight significant output and errors
Execution options
The following options affect how builds are executed by changing what is built or how dependencies are resolved.
--include-build-
Run the build as a composite, including the specified build.
--offline-
Specifies that the build should operate without accessing network resources.
-U,--refresh-dependencies-
Refresh the state of dependencies.
--continue-
Continue task execution after a task failure.
-m,--dry-run-
Run Gradle with all task actions disabled. Use this to show which task would have executed.
-t,--continuous-
Enables continuous build. Gradle does not exit and will re-execute tasks when task file inputs change.
--write-locks-
Indicates that all resolved configurations that are lockable should have their lock state persisted.
--update-locks <group:name>[,<group:name>]*-
Indicates that versions for the specified modules have to be updated in the lock file.
This flag also implies
--write-locks. -a,--no-rebuild-
Do not rebuild project dependencies. Useful for debugging and fine-tuning
buildSrc, but can lead to wrong results. Use with caution!
Dependency verification options
Learn more about this in dependency verification.
-F=(strict,lenient,off),--dependency-verification=(strict,lenient,off)-
Configures the dependency verification mode.
The default mode is
strict. -M,--write-verification-metadata-
Generates checksums for dependencies used in the project (comma-separated list) for dependency verification.
--refresh-keys-
Refresh the public keys used for dependency verification.
--export-keys-
Exports the public keys used for dependency verification.
Environment options
You can customize many aspects about where build scripts, settings, caches, and so on through the options below.
-b,--build-file(deprecated)-
Specifies the build file. For example:
gradle --build-file=foo.gradle. The default isbuild.gradle, thenbuild.gradle.kts. -c,--settings-file(deprecated)-
Specifies the settings file. For example:
gradle --settings-file=somewhere/else/settings.gradle -g,--gradle-user-home-
Specifies the Gradle User Home directory. The default is the
.gradledirectory in the user’s home directory. -p,--project-dir-
Specifies the start directory for Gradle. Defaults to current directory.
--project-cache-dir-
Specifies the project-specific cache directory. Default value is
.gradlein the root project directory. -D,--system-prop-
Sets a system property of the JVM, for example
-Dmyprop=myvalue. -I,--init-script-
Specifies an initialization script.
-P,--project-prop-
Sets a project property of the root project, for example
-Pmyprop=myvalue. -Dorg.gradle.jvmargs-
Set JVM arguments.
-Dorg.gradle.java.home-
Set JDK home dir.
Task options
Tasks may define task-specific options which are different from most of the global options described in the sections above (which are interpreted by Gradle itself, can appear anywhere in the command line, and can be listed using the --help option).
Task options:
-
Are consumed and interpreted by the tasks themselves;
-
Must be specified immediately after the task in the command-line;
-
May be listed using
gradle help --task someTask(see Show task usage details).
To learn how to declare command-line options for your own tasks, see Declaring and Using Command Line Options.
Built-in task options
Built-in task options are options available as task options for all tasks. At this time, the following built-in task options exist:
--rerun-
Causes the task to be rerun even if up-to-date. Similar to
--rerun-tasks, but for a specific task.
Bootstrapping new projects
Creating new Gradle builds
Use the built-in gradle init task to create a new Gradle build, with new or existing projects.
$ gradle init
Most of the time, a project type is specified.
Available types include basic (default), java-library, java-application, and more.
See init plugin documentation for details.
$ gradle init --type java-library
Standardize and provision Gradle
The built-in gradle wrapper task generates a script, gradlew, that invokes a declared version of Gradle, downloading it beforehand if necessary.
$ gradle wrapper --gradle-version=8.1
You can also specify --distribution-type=(bin|all), --gradle-distribution-url, --gradle-distribution-sha256-sum in addition to --gradle-version.
Full details on using these options are documented in the Gradle wrapper section.
Continuous build
Continuous Build allows you to automatically re-execute the requested tasks when file inputs change.
You can execute the build in this mode using the -t or --continuous command-line option.
For example, you can continuously run the test task and all dependent tasks by running:
$ gradle test --continuous
Gradle will behave as if you ran gradle test after a change to sources or tests that contribute to the requested tasks.
This means unrelated changes (such as changes to build scripts) will not trigger a rebuild.
To incorporate build logic changes, the continuous build must be restarted manually.
Continuous build uses file system watching to detect changes to the inputs.
If file system watching does not work on your system, then continuous build won’t work either.
In particular, continuous build does not work when using --no-daemon.
When Gradle detects a change to the inputs, it will not trigger the build immediately.
Instead, it will wait until no additional changes are detected for a certain period of time - the quiet period.
You can configure the quiet period in milliseconds by the Gradle property org.gradle.continuous.quietperiod.
Terminating Continuous Build
If Gradle is attached to an interactive input source, such as a terminal, the continuous build can be exited by pressing CTRL-D (On Microsoft Windows, it is required to also press ENTER or RETURN after CTRL-D).
If Gradle is not attached to an interactive input source (e.g. is running as part of a script), the build process must be terminated (e.g. using the kill command or similar).
If the build is being executed via the Tooling API, the build can be cancelled using the Tooling API’s cancellation mechanism.
Learn more in Continuous Builds Continuous Builds.
Changes to symbolic links
In general, Gradle will not detect changes to symbolic links or to files referenced via symbolic links.
Changes to build logic are not considered
The current implementation does not recalculate the build model on subsequent builds. This means that changes to task configuration, or any other change to the build model, are effectively ignored.
Gradle Wrapper Reference
The recommended way to execute any Gradle build is with the help of the Gradle Wrapper (referred to as "Wrapper").
The Wrapper is a script that invokes a declared version of Gradle, downloading it beforehand if necessary. As a result, developers can get up and running with a Gradle project quickly.
In a nutshell, you gain the following benefits:
-
Standardizes a project on a given Gradle version for more reliable and robust builds.
-
Provisioning the Gradle version for different users is done with a simple Wrapper definition change.
-
Provisioning the Gradle version for different execution environments (e.g., IDEs or Continuous Integration servers) is done with a simple Wrapper definition change.
There are three ways to use the Wrapper:
-
You set up a new Gradle project and add the Wrapper to it.
-
You run a project with the Wrapper that already provides it.
-
You upgrade the Wrapper to a new version of Gradle.
The following sections explain each of these use cases in more detail.
Adding the Gradle Wrapper
Generating the Wrapper files requires an installed version of the Gradle runtime on your machine as described in Installation. Thankfully, generating the initial Wrapper files is a one-time process.
Every vanilla Gradle build comes with a built-in task called wrapper.
The task is listed under the group "Build Setup tasks" when listing the tasks.
Executing the wrapper task generates the necessary Wrapper files in the project directory:
$ gradle wrapper
> Task :wrapper BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
|
Tip
|
To make the Wrapper files available to other developers and execution environments, you need to check them into version control. Wrapper files, including the JAR file, are small. Adding the JAR file to version control is expected. Some organizations do not allow projects to submit binary files to version control, and there is no workaround available. |
The generated Wrapper properties file, gradle/wrapper/gradle-wrapper.properties, stores the information about the Gradle distribution:
-
The server hosting the Gradle distribution.
-
The type of Gradle distribution. By default, the
-bindistribution contains only the runtime but no sample code and documentation. -
The Gradle version used for executing the build. By default, the
wrappertask picks the same Gradle version used to generate the Wrapper files. -
Optionally, a timeout in ms used when downloading the Gradle distribution.
-
Optionally, a boolean to set the validation of the distribution URL.
The following is an example of the generated distribution URL in gradle/wrapper/gradle-wrapper.properties:
distributionUrl=https\://services.gradle.org/distributions/gradle-8.7-bin.zipAll of those aspects are configurable at the time of generating the Wrapper files with the help of the following command line options:
--gradle-version-
The Gradle version used for downloading and executing the Wrapper. The resulting distribution URL is validated before it is written to the properties file.
The following labels are allowed:
--distribution-type-
The Gradle distribution type used for the Wrapper. Available options are
binandall. The default value isbin. --gradle-distribution-url-
The full URL pointing to the Gradle distribution ZIP file. This option makes
--gradle-versionand--distribution-typeobsolete, as the URL already contains this information. This option is valuable if you want to host the Gradle distribution inside your company’s network. The URL is validated before it is written to the properties file. --gradle-distribution-sha256-sum-
The SHA256 hash sum used for verifying the downloaded Gradle distribution.
--network-timeout-
The network timeout to use when downloading the Gradle distribution, in ms. The default value is
10000. --no-validate-url-
Disables the validation of the configured distribution URL.
--validate-url-
Enables the validation of the configured distribution URL. Enabled by default.
If the distribution URL is configured with --gradle-version or --gradle-distribution-url, the URL is validated by sending a HEAD request in the case of the https scheme or by checking the existence of the file in the case of the file scheme.
Let’s assume the following use-case to illustrate the use of the command line options.
You would like to generate the Wrapper with version 8.7 and use the -all distribution to enable your IDE to enable code-completion and being able to navigate to the Gradle source code.
The following command-line execution captures those requirements:
$ gradle wrapper --gradle-version 8.7 --distribution-type all > Task :wrapper BUILD SUCCESSFUL in 0s 1 actionable task: 1 executed
As a result, you can find the desired information (the generated distribution URL) in the Wrapper properties file:
distributionUrl=https\://services.gradle.org/distributions/gradle-8.7-all.zipLet’s have a look at the following project layout to illustrate the expected Wrapper files:
.
├── a-subproject
│ └── build.gradle.kts
├── settings.gradle.kts
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
└── gradlew.bat.
├── a-subproject
│ └── build.gradle
├── settings.gradle
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
└── gradlew.batA Gradle project typically provides a settings.gradle(.kts) file and one build.gradle(.kts) file for each subproject.
The Wrapper files live alongside in the gradle directory and the root directory of the project.
The following list explains their purpose:
gradle-wrapper.jar-
The Wrapper JAR file containing code for downloading the Gradle distribution.
gradle-wrapper.properties-
A properties file responsible for configuring the Wrapper runtime behavior e.g. the Gradle version compatible with this version. Note that more generic settings, like configuring the Wrapper to use a proxy, need to go into a different file.
gradlew,gradlew.bat-
A shell script and a Windows batch script for executing the build with the Wrapper.
You can go ahead and execute the build with the Wrapper without installing the Gradle runtime. If the project you are working on does not contain those Wrapper files, you will need to generate them.
Using the Gradle Wrapper
It is always recommended to execute a build with the Wrapper to ensure a reliable, controlled, and standardized execution of the build.
Using the Wrapper looks like running the build with a Gradle installation.
Depending on the operating system you either run gradlew or gradlew.bat instead of the gradle command.
The following console output demonstrates the use of the Wrapper on a Windows machine for a Java-based project:
$ gradlew.bat build Downloading https://services.gradle.org/distributions/gradle-5.0-all.zip ..................................................................................... Unzipping C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-all\ac27o8rbd0ic8ih41or9l32mv\gradle-5.0-all.zip to C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-al\ac27o8rbd0ic8ih41or9l32mv Set executable permissions for: C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-all\ac27o8rbd0ic8ih41or9l32mv\gradle-5.0\bin\gradle BUILD SUCCESSFUL in 12s 1 actionable task: 1 executed
If the Gradle distribution is unavailable on the machine, the Wrapper will download it and store it in the local file system. Any subsequent build invocation will reuse the existing local distribution as long as the distribution URL in the Gradle properties doesn’t change.
|
Note
|
The Wrapper shell script and batch file reside in the root directory of a single or multi-project Gradle build. You will need to reference the correct path to those files in case you want to execute the build from a subproject directory e.g. ../../gradlew tasks.
|
Upgrading the Gradle Wrapper
Projects typically want to keep up with the times and upgrade their Gradle version to benefit from new features and improvements.
One way to upgrade the Gradle version is by manually changing the distributionUrl property in the Wrapper’s gradle-wrapper.properties file.
The better and recommended option is to run the wrapper task and provide the target Gradle version as described in Adding the Gradle Wrapper.
Using the wrapper task ensures that any optimizations made to the Wrapper shell script or batch file with that specific Gradle version are applied to the project.
As usual, you should commit the changes to the Wrapper files to version control.
Note that running the wrapper task once will update gradle-wrapper.properties only, but leave the wrapper itself in gradle-wrapper.jar untouched.
This is usually fine as new versions of Gradle can be run even with older wrapper files.
|
Note
|
If you want all the wrapper files to be completely up-to-date, you will need to run the wrapper task a second time.
|
The following command upgrades the Wrapper to the latest version:
$ ./gradlew wrapper --gradle-version latest BUILD SUCCESSFUL in 4s 1 actionable task: 1 executed
The following command upgrades the Wrapper to a specific version:
$ ./gradlew wrapper --gradle-version 8.7 BUILD SUCCESSFUL in 4s 1 actionable task: 1 executed
Once you have upgraded the wrapper, you can check that it’s the version you expected by executing ./gradlew --version.
Don’t forget to run the wrapper task again to download the Gradle distribution binaries (if needed) and update the gradlew and gradlew.bat files.
Customizing the Gradle Wrapper
Most users of Gradle are happy with the default runtime behavior of the Wrapper. However, organizational policies, security constraints or personal preferences might require you to dive deeper into customizing the Wrapper.
Thankfully, the built-in wrapper task exposes numerous options to bend the runtime behavior to your needs.
Most configuration options are exposed by the underlying task type Wrapper.
Let’s assume you grew tired of defining the -all distribution type on the command line every time you upgrade the Wrapper.
You can save yourself some keyboard strokes by re-configuring the wrapper task.
tasks.wrapper {
distributionType = Wrapper.DistributionType.ALL
}tasks.named('wrapper') {
distributionType = Wrapper.DistributionType.ALL
}With the configuration in place, running ./gradlew wrapper --gradle-version 8.7 is enough to produce a distributionUrl value in the Wrapper properties file that will request the -all distribution:
distributionUrl=https\://services.gradle.org/distributions/gradle-8.7-all.zip
Check out the API documentation for a more detailed description of the available configuration options. You can also find various samples for configuring the Wrapper in the Gradle distribution.
Authenticated Gradle distribution download
The Gradle Wrapper can download Gradle distributions from servers using HTTP Basic Authentication.
This enables you to host the Gradle distribution on a private protected server.
You can specify a username and password in two different ways depending on your use case: as system properties or directly embedded in the distributionUrl.
Credentials in system properties take precedence over the ones embedded in distributionUrl.
|
Tip
|
HTTP Basic Authentication should only be used with |
System properties can be specified in the .gradle/gradle.properties file in the user’s home directory or by other means.
To specify the HTTP Basic Authentication credentials, add the following lines to the system properties file:
systemProp.gradle.wrapperUser=username
systemProp.gradle.wrapperPassword=passwordEmbedding credentials in the distributionUrl in the gradle/wrapper/gradle-wrapper.properties file also works.
Please note that this file is to be committed into your source control system.
|
Tip
|
Shared credentials embedded in distributionUrl should only be used in a controlled environment.
|
To specify the HTTP Basic Authentication credentials in distributionUrl, add the following line:
distributionUrl=https://username:password@somehost/path/to/gradle-distribution.zip
This can be used in conjunction with a proxy, authenticated or not.
See Accessing the web via a proxy for more information on how to configure the Wrapper to use a proxy.
Verification of downloaded Gradle distributions
The Gradle Wrapper allows for verification of the downloaded Gradle distribution via SHA-256 hash sum comparison. This increases security against targeted attacks by preventing a man-in-the-middle attacker from tampering with the downloaded Gradle distribution.
To enable this feature, download the .sha256 file associated with the Gradle distribution you want to verify.
Downloading the SHA-256 file
You can download the .sha256 file from the stable releases or release candidate and nightly releases.
The format of the file is a single line of text that is the SHA-256 hash of the corresponding zip file.
You can also reference the list of Gradle distribution checksums.
Configuring checksum verification
Add the downloaded (SHA-256 checksum) hash sum to gradle-wrapper.properties using the distributionSha256Sum property or use --gradle-distribution-sha256-sum on the command-line:
distributionSha256Sum=371cb9fbebbe9880d147f59bab36d61eee122854ef8c9ee1ecf12b82368bcf10Gradle will report a build failure if the configured checksum does not match the checksum found on the server hosting the distribution. Checksum verification is only performed if the configured Wrapper distribution hasn’t been downloaded yet.
|
Note
|
The Wrapper task fails if gradle-wrapper.properties contains distributionSha256Sum, but the task configuration does not define a sum.
Executing the Wrapper task preserves the distributionSha256Sum configuration when the Gradle version does not change.
|
Verifying the integrity of the Gradle Wrapper JAR
The Wrapper JAR is a binary file that will be executed on the computers of developers and build servers. As with all such files, you should ensure it’s trustworthy before executing it.
Since the Wrapper JAR is usually checked into a project’s version control system, there is the potential for a malicious actor to replace the original JAR with a modified one by submitting a pull request that only upgrades the Gradle version.
To verify the integrity of the Wrapper JAR, Gradle has created a GitHub Action that automatically checks Wrapper JARs in pull requests against a list of known good checksums.
Gradle also publishes the checksums of all releases (except for version 3.3 to 4.0.2, which did not generate reproducible JARs), so you can manually verify the integrity of the Wrapper JAR.
Automatically verifying the Gradle Wrapper JAR on GitHub
The GitHub Action is released separately from Gradle, so please check its documentation for how to apply it to your project.
Manually verifying the Gradle Wrapper JAR
You can manually verify the checksum of the Wrapper JAR to ensure that it has not been tampered with by running the following commands on one of the major operating systems.
Manually verifying the checksum of the Wrapper JAR on Linux:
$ cd gradle/wrapper$ curl --location --output gradle-wrapper.jar.sha256 \
https://services.gradle.org/distributions/gradle-{gradleVersion}-wrapper.jar.sha256
$ echo " gradle-wrapper.jar" >> gradle-wrapper.jar.sha256
$ sha256sum --check gradle-wrapper.jar.sha256
gradle-wrapper.jar: OK
Manually verifying the checksum of the Wrapper JAR on macOS:
$ cd gradle/wrapper$ curl --location --output gradle-wrapper.jar.sha256 \
https://services.gradle.org/distributions/gradle-{gradleVersion}-wrapper.jar.sha256
$ echo " gradle-wrapper.jar" >> gradle-wrapper.jar.sha256
$ shasum --check gradle-wrapper.jar.sha256
gradle-wrapper.jar: OK
Manually verifying the checksum of the Wrapper JAR on Windows (using PowerShell):
> $expected = Invoke-RestMethod -Uri https://services.gradle.org/distributions/gradle-8.7-wrapper.jar.sha256> $actual = (Get-FileHash gradle\wrapper\gradle-wrapper.jar -Algorithm SHA256).Hash.ToLower()
> @{$true = 'OK: Checksum match'; $false = "ERROR: Checksum mismatch!`nExpected: $expected`nActual: $actual"}[$actual -eq $expected]
OK: Checksum match
Troubleshooting a checksum mismatch
If the checksum does not match the one you expected, chances are the wrapper task wasn’t executed with the upgraded Gradle distribution.
You should first check whether the actual checksum matches a different Gradle version.
Here are the commands you can run on the major operating systems to generate the actual checksum of the Wrapper JAR.
Generating the checksum of the Wrapper JAR on Linux:
$ sha256sum gradle/wrapper/gradle-wrapper.jar
d81e0f23ade952b35e55333dd5f1821585e887c6d24305aeea2fbc8dad564b95 gradle/wrapper/gradle-wrapper.jarGenerating the actual checksum of the Wrapper JAR on macOS:
$ shasum --algorithm=256 gradle/wrapper/gradle-wrapper.jar
d81e0f23ade952b35e55333dd5f1821585e887c6d24305aeea2fbc8dad564b95 gradle/wrapper/gradle-wrapper.jarGenerating the actual checksum of the Wrapper JAR on Windows (using PowerShell):
> (Get-FileHash gradle\wrapper\gradle-wrapper.jar -Algorithm SHA256).Hash.ToLower()
d81e0f23ade952b35e55333dd5f1821585e887c6d24305aeea2fbc8dad564b95Once you know the actual checksum, check whether it’s listed on https://gradle.org/release-checksums/.
If it is listed, you have verified the integrity of the Wrapper JAR.
If the version of Gradle that generated the Wrapper JAR doesn’t match the version in gradle/wrapper/gradle-wrapper.properties, it’s safe to run the wrapper task again to update the Wrapper JAR.
If the checksum is not listed on the page, the Wrapper JAR might be from a milestone, release candidate, or nightly build or may have been generated by Gradle 3.3 to 4.0.2. Try to find out how it was generated but treat it as untrustworthy until proven otherwise. If you think the Wrapper JAR was compromised, please let the Gradle team know by sending an email to security@gradle.com.
Gradle Plugin Reference
This page contains links and short descriptions for all the core plugins provided by Gradle itself.
JVM languages and frameworks
- Java
-
Provides support for building any type of Java project.
- Java Library
-
Provides support for building a Java library.
- Java Platform
-
Provides support for building a Java platform.
- Groovy
-
Provides support for building any type of Groovy project.
- Scala
-
Provides support for building any type of Scala project.
- ANTLR
-
Provides support for generating parsers using ANTLR.
- JVM Test Suite
-
Provides support for modeling and configuring multiple test suite invocations.
- Test Report Aggregation
-
Aggregates the results of multiple Test task invocations (potentially spanning multiple Gradle projects) into a single HTML report.
Native languages
- C++ Application
-
Provides support for building C++ applications on Windows, Linux, and macOS.
- C++ Library
-
Provides support for building C++ libraries on Windows, Linux, and macOS.
- C++ Unit Test
-
Provides support for building and running C++ executable-based tests on Windows, Linux, and macOS.
- Swift Application
-
Provides support for building Swift applications on Linux and macOS.
- Swift Library
-
Provides support for building Swift libraries on Linux and macOS.
- XCTest
-
Provides support for building and running XCTest-based tests on Linux and macOS.
Packaging and distribution
- Application
-
Provides support for building JVM-based, runnable applications.
- WAR
-
Provides support for building and packaging WAR-based Java web applications.
- EAR
-
Provides support for building and packaging Java EE applications.
- Maven Publish
-
Provides support for publishing artifacts to Maven-compatible repositories.
- Ivy Publish
-
Provides support for publishing artifacts to Ivy-compatible repositories.
- Distribution
-
Makes it easy to create ZIP and tarball distributions of your project.
- Java Library Distribution
-
Provides support for creating a ZIP distribution of a Java library project that includes its runtime dependencies.
Code analysis
- Checkstyle
-
Performs quality checks on your project’s Java source files using Checkstyle and generates associated reports.
- PMD
-
Performs quality checks on your project’s Java source files using PMD and generates associated reports.
- JaCoCo
-
Provides code coverage metrics for your Java project using JaCoCo.
- JaCoCo Report Aggregation
-
Aggregates the results of multiple JaCoCo code coverage reports (potentially spanning multiple Gradle projects) into a single HTML report.
- CodeNarc
-
Performs quality checks on your Groovy source files using CodeNarc and generates associated reports.
IDE integration
- Eclipse
-
Generates Eclipse project files for the build that can be opened by the IDE. This set of plugins can also be used to fine tune Buildship’s import process for Gradle builds.
- IntelliJ IDEA
-
Generates IDEA project files for the build that can be opened by the IDE. It can also be used to fine tune IDEA’s import process for Gradle builds.
- Visual Studio
-
Generates Visual Studio solution and project files for build that can be opened by the IDE.
- Xcode
-
Generates Xcode workspace and project files for the build that can be opened by the IDE.
Utility
- Base
-
Provides common lifecycle tasks, such as
clean, and other features common to most builds. - Build Init
-
Generates a new Gradle build of a specified type, such as a Java library. It can also generate a build script from a Maven POM — see Migrating from Maven to Gradle for more details.
- Signing
-
Provides support for digitally signing generated files and artifacts.
- Plugin Development
-
Makes it easier to develop and publish a Gradle plugin.
- Project Report Plugin
-
Helps to generate reports containing useful information about your build.
Gradle & Third-party Tools
Gradle can be integrated with many different third-party tools such as IDEs and continuous integration platforms. Here we look at some of the more common ones as well as how to integrate your own tool with Gradle.
IDEs
- Android Studio
-
As a variant of IntelliJ IDEA, Android Studio has built-in support for importing and building Gradle projects. You can also use the IDEA Plugin for Gradle to fine-tune the import process if that’s necessary.
This IDE also has an extensive user guide to help you get the most out of the IDE and Gradle.
- Eclipse
-
If you want to work on a project within Eclipse that has a Gradle build, you should use the Eclipse Buildship plugin. This will allow you to import and run Gradle builds. If you need to fine tune the import process so that the project loads correctly, you can use the Eclipse Plugins for Gradle. See the associated release announcement for details on what fine tuning you can do.
- IntelliJ IDEA
-
IDEA has built-in support for importing Gradle projects. If you need to fine tune the import process so that the project loads correctly, you can use the IDEA Plugin for Gradle.
- NetBeans
-
Built-in support for Gradle in Apache NetBeans
- Visual Studio
-
For developing C++ projects, Gradle comes with a Visual Studio plugin.
- Xcode
-
For developing C++ projects, Gradle comes with a Xcode plugin.
- CLion
-
JetBrains supports building C++ projects with Gradle.
Continuous integration
We have dedicated guides showing you how to integrate a Gradle project with the following CI platforms:
Even if you don’t use one of the above, you can almost certainly configure your CI platform to use the Gradle Wrapper scripts.
How to integrate with Gradle
There are two main ways to integrate a tool with Gradle:
-
The Gradle build uses the tool
-
The tool executes the Gradle build
The former case is typically implemented as a Gradle plugin. The latter can be accomplished by embedding Gradle through the Tooling API as described below.
Embedding Gradle using the Tooling API
Introduction to the Tooling API
Gradle provides a programmatic API called the Tooling API, which you can use for embedding Gradle into your own software. This API allows you to execute and monitor builds and to query Gradle about the details of a build. The main audience for this API is IDE, CI server, other UI authors; however, the API is open for anyone who needs to embed Gradle in their application.
-
Gradle TestKit uses the Tooling API for functional testing of your Gradle plugins.
-
Eclipse Buildship uses the Tooling API for importing your Gradle project and running tasks.
-
IntelliJ IDEA uses the Tooling API for importing your Gradle project and running tasks.
Tooling API Features
A fundamental characteristic of the Tooling API is that it operates in a version independent way. This means that you can use the same API to work with builds that use different versions of Gradle, including versions that are newer or older than the version of the Tooling API that you are using. The Tooling API is Gradle wrapper aware and, by default, uses the same Gradle version as that used by the wrapper-powered build.
Some features that the Tooling API provides:
-
Query the details of a build, including the project hierarchy and the project dependencies, external dependencies (including source and Javadoc jars), source directories and tasks of each project.
-
Execute a build and listen to stdout and stderr logging and progress messages (e.g. the messages shown in the 'status bar' when you run on the command line).
-
Execute a specific test class or test method.
-
Receive interesting events as a build executes, such as project configuration, task execution or test execution.
-
Cancel a build that is running.
-
Combine multiple separate Gradle builds into a single composite build.
-
The Tooling API can download and install the appropriate Gradle version, similar to the wrapper.
-
The implementation is lightweight, with only a small number of dependencies. It is also a well-behaved library, and makes no assumptions about your classloader structure or logging configuration. This makes the API easy to embed in your application.
Tooling API and the Gradle Build Daemon
The Tooling API always uses the Gradle daemon. This means that subsequent calls to the Tooling API, be it model building requests or task executing requests will be executed in the same long-living process. Gradle Daemon contains more details about the daemon, specifically information on situations when new daemons are forked.
Quickstart
As the Tooling API is an interface for developers, the Javadoc is the main documentation for it.
To use the Tooling API, add the following repository and dependency declarations to your build script:
repositories {
maven { url = uri("https://repo.gradle.org/gradle/libs-releases") }
}
dependencies {
implementation("org.gradle:gradle-tooling-api:$toolingApiVersion")
// The tooling API need an SLF4J implementation available at runtime, replace this with any other implementation
runtimeOnly("org.slf4j:slf4j-simple:1.7.10")
}repositories {
maven { url 'https://repo.gradle.org/gradle/libs-releases' }
}
dependencies {
implementation "org.gradle:gradle-tooling-api:$toolingApiVersion"
// The tooling API need an SLF4J implementation available at runtime, replace this with any other implementation
runtimeOnly 'org.slf4j:slf4j-simple:1.7.10'
}The main entry point to the Tooling API is the GradleConnector.
You can navigate from there to find code samples and explore the available Tooling API models.
You can use GradleConnector.connect() to create a ProjectConnection.
A ProjectConnection connects to a single Gradle project.
Using the connection you can execute tasks, tests and retrieve models relative to this project.
Compatibility of Java and Gradle versions
The following components should be considered when implementing Gradle integration: the Tooling API version, The JVM running the Tooling API client (i.e. the IDE process), the JVM running the Gradle daemon, and the Gradle version.
The Tooling API itself is a Java library published as part of the Gradle release. Each Gradle release has a corresponding Tooling API version with the same version number.
The Tooling API classes are loaded into the client’s JVM, so they should have a matching version. The current version of the Tooling API library is compiled with Java 8 compatibility.
The JVM running the Tooling API client and the one running the daemon can be different. At the same time, classes that are sent to the build via custom build actions need to be targeted to the lowest supported Java version. The JVM versions supported by Gradle is version-specific. The upper bound is defined in the compatibility matrix. The rule for the lower bound is the following:
-
Gradle 3.x and 4.x require a minimum version of Java 7.
-
Gradle 5 and above require a minimum version of Java 8.
The Tooling API version is guaranteed to support running builds with all Gradle versions for the last five major releases. For example, the Tooling API 8.0 release is compatible with Gradle versions >= 3.0. Besides, the Tooling API is guaranteed to be compatible with future Gradle releases for the current and the next major. This means, for example, that the 8.1 version of the Tooling API will be able to run Gradle 9.x builds and might break with Gradle 10.0.
GRADLE DSLs and API
A Groovy Build Script Primer
Ideally, a Groovy build script looks mostly like configuration: setting some properties of the project, configuring dependencies, declaring tasks, and so on. That configuration is based on Groovy language constructs. This primer aims to explain what those constructs are and — most importantly — how they relate to Gradle’s API documentation.
The Project object
As Groovy is an object-oriented language based on Java, its properties and methods apply to objects. In some cases, the object is implicit — particularly at the top level of a build script, i.e. not nested inside a {} block.
Consider this fragment of build script, which contains an unqualified property and block:
version = '1.0.0.GA'
configurations {
...
}Both version and configurations {} are part of org.gradle.api.Project.
This example reflects how every Groovy build script is backed by an implicit instance of Project. If you see an unqualified element and you don’t know where it’s defined, always check the Project API documentation to see if that’s where it’s coming from.
|
Caution
|
Avoid using Groovy MetaClass programming techniques in your build scripts. Gradle provides its own API for adding dynamic runtime properties. Use of Groovy-specific metaprogramming can cause builds to retain large amounts of memory between builds that will eventually cause the Gradle daemon to run out-of-memory. |
Properties
<obj>.<name> // Get a property value
<obj>.<name> = <value> // Set a property to a new value
"$<name>" // Embed a property value in a string
"${<obj>.<name>}" // Same as previous (embedded value)version = '1.0.1'
myCopyTask.description = 'Copies some files'
file("$projectDir/src")
println "Destination: ${myCopyTask.destinationDir}"A property represents some state of an object. The presence of an = sign is a clear indicator that you’re looking at a property. Otherwise, a qualified name — it begins with <obj>. — without any other decoration is also a property.
If the name is unqualified, then it may be one of the following:
-
A task instance with that name.
-
A property on Project.
-
An extra property defined elsewhere in the project.
-
A property of an implicit object within a block.
-
A local variable defined earlier in the build script.
Note that plugins can add their own properties to the Project object. The API documentation lists all the properties added by core plugins. If you’re struggling to find where a property comes from, check the documentation for the plugins that the build uses.
|
Tip
|
When referencing a project property in your build script that is added by a non-core plugin, consider prefixing it with project. — it’s clear then that the property belongs to the project object.
|
Properties in the API documentation
The Groovy DSL reference shows properties as they are used in your build scripts, but the Javadocs only display methods. That’s because properties are implemented as methods behind the scenes:
-
A property can be read if there is a method named
get<PropertyName>with zero arguments that returns the same type as the property. -
A property can be modified if there is a method named
set<PropertyName>with one argument that has the same type as the property and a return type ofvoid.
Note that property names usually start with a lower-case letter, but that letter is upper case in the method names. So the getter method getProjectVersion() corresponds to the property projectVersion. This convention does not apply when the name begins with at least two upper-case letters, in which case there is not change in case. For example, getRAM() corresponds to the property RAM.
project.getVersion()
project.version
project.setVersion('1.0.1')
project.version = '1.0.1'Methods
<obj>.<name>() // Method call with no arguments
<obj>.<name>(<arg>, <arg>) // Method call with multiple arguments
<obj>.<name> <arg>, <arg> // Method call with multiple args (no parentheses)myCopyTask.include '**/*.xml', '**/*.properties'
ext.resourceSpec = copySpec() // `copySpec()` comes from `Project`
file('src/main/java')
println 'Hello, World!'A method represents some behavior of an object, although Gradle often uses methods to configure the state of objects as well. Methods are identifiable by their arguments or empty parentheses. Note that parentheses are sometimes required, such as when a method has zero arguments, so you may find it simplest to always use parentheses.
|
Note
|
Gradle has a convention whereby if a method has the same name as a collection-based property, then the method appends its values to that collection. |
Blocks
Blocks are also methods, just with specific types for the last argument.
<obj>.<name> {
...
}
<obj>.<name>(<arg>, <arg>) {
...
}plugins {
id 'java-library'
}
configurations {
assets
}
sourceSets {
main {
java {
srcDirs = ['src']
}
}
}
dependencies {
implementation project(':util')
}Blocks are a mechanism for configuring multiple aspects of a build element in one go. They also provide a way to nest configuration, leading to a form of structured data.
There are two important aspects of blocks that you should understand:
-
They are implemented as methods with specific signatures.
-
They can change the target ("delegate") of unqualified methods and properties.
Both are based on Groovy language features and we explain them in the following sections.
Block method signatures
You can easily identify a method as the implementation behind a block by its signature, or more specifically, its argument types. If a method corresponds to a block:
-
It must have at least one argument.
-
The last argument must be of type
groovy.lang.Closureor org.gradle.api.Action.
For example, Project.copy(Action) matches these requirements, so you can use the syntax:
copy {
into layout.buildDirectory.dir("tmp")
from 'custom-resources'
}That leads to the question of how into() and from() work. They’re clearly methods, but where would you find them in the API documentation? The answer comes from understanding object delegation.
Delegation
The section on properties lists where unqualified properties might be found. One common place is on the Project object. But there is an alternative source for those unqualified properties and methods inside a block: the block’s delegate object.
To help explain this concept, consider the last example from the previous section:
copy {
into layout.buildDirectory.dir("tmp")
from 'custom-resources'
}All the methods and properties in this example are unqualified. You can easily find copy() and layout in the Project API documentation, but what about into() and from()? These are resolved against the delegate of the copy {} block. What is the type of that delegate? You’ll need to check the API documentation for that.
There are two ways to determine the delegate type, depending on the signature of the block method:
-
For
Actionarguments, look at the type’s parameter.In the example above, the method signature is
copy(Action<? super CopySpec>)and it’s the bit inside the angle brackets that tells you the delegate type — CopySpec in this case. -
For
Closurearguments, the documentation will explicitly say in the description what type is being configured or what type the delegate it (different terminology for the same thing).
Hence you can find both into() and from() on CopySpec. You might even notice that both of those methods have variants that take an Action as their last argument, which means you can use block syntax with them.
All new Gradle APIs declare an Action argument type rather than Closure, which makes it very easy to pick out the delegate type. Even older APIs have an Action variant in addition to the old Closure one.
Local variables
def <name> = <value> // Untyped variable
<type> <name> = <value> // Typed variabledef i = 1
String errorMsg = 'Failed, because reasons'Local variables are a Groovy construct — unlike extra properties — that can be used to share values within a build script.
|
Caution
|
Avoid using local variables in the root of the project, i.e. as pseudo project properties. They cannot be read outside of the build script and Gradle has no knowledge of them. Within a narrower context — such as configuring a task — local variables can occasionally be helpful. |
Gradle Kotlin DSL Primer
Gradle’s Kotlin DSL provides an alternative syntax to the traditional Groovy DSL with an enhanced editing experience in supported IDEs, with superior content assist, refactoring, documentation, and more. This chapter provides details of the main Kotlin DSL constructs and how to use it to interact with the Gradle API.
|
Tip
|
If you are interested in migrating an existing Gradle build to the Kotlin DSL, please also check out the dedicated migration section. |
Prerequisites
-
The embedded Kotlin compiler is known to work on Linux, macOS, Windows, Cygwin, FreeBSD and Solaris on x86-64 architectures.
-
Knowledge of Kotlin syntax and basic language features is very helpful. The Kotlin reference documentation and Kotlin Koans will help you to learn the basics.
-
Use of the plugins {} block to declare Gradle plugins significantly improves the editing experience and is highly recommended.
IDE support
The Kotlin DSL is fully supported by IntelliJ IDEA and Android Studio. Other IDEs do not yet provide helpful tools for editing Kotlin DSL files, but you can still import Kotlin-DSL-based builds and work with them as usual.
| Build import | Syntax highlighting 1 | Semantic editor 2 | |
|---|---|---|---|
IntelliJ IDEA |
✓ |
✓ |
✓ |
Android Studio |
✓ |
✓ |
✓ |
Eclipse IDE |
✓ |
✓ |
✖ |
CLion |
✓ |
✓ |
✖ |
Apache NetBeans |
✓ |
✓ |
✖ |
Visual Studio Code (LSP) |
✓ |
✓ |
✖ |
Visual Studio |
✓ |
✖ |
✖ |
1 Kotlin syntax highlighting in Gradle Kotlin DSL scripts
2 code completion, navigation to sources, documentation, refactorings etc… in Gradle Kotlin DSL scripts
As mentioned in the limitations, you must import your project from the Gradle model to get content-assist and refactoring tools for Kotlin DSL scripts in IntelliJ IDEA.
Builds with slow configuration time might affect the IDE responsiveness, so please check out the performance section to help resolve such issues.
Automatic build import vs. automatic reloading of script dependencies
Both IntelliJ IDEA and Android Studio — which is derived from IntelliJ IDEA — will detect when you make changes to your build logic and offer two suggestions:
-
Import the whole build again
-
Reload script dependencies when editing a build script



We recommend that you disable automatic build import, but enable automatic reloading of script dependencies. That way you get early feedback while editing Gradle scripts and control over when the whole build setup gets synchronized with your IDE.
Troubleshooting
The IDE support is provided by two components:
-
The Kotlin Plugin used by IntelliJ IDEA/Android Studio
-
Gradle
The level of support varies based on the versions of each.
If you run into trouble, the first thing you should try is running ./gradlew tasks from the command line to see whether your issue is limited to the IDE. If you encounter the same problem from the command line, then the issue is with the build rather than the IDE integration.
If you can run the build successfully from the command line but your script editor is complaining, then you should try restarting your IDE and invalidating its caches.
If the above doesn’t work and you suspect an issue with the Kotlin DSL script editor, you can:
-
Run
./gradle tasksto get more details -
Check the logs in one of these locations:
-
$HOME/Library/Logs/gradle-kotlin-dslon Mac OS X -
$HOME/.gradle-kotlin-dsl/logon Linux -
$HOME/AppData/Local/gradle-kotlin-dsl/logon Windows
-
-
Open an issue on the Gradle issue tracker, including as much detail as you can.
From version 5.1 onwards, the log directory is cleaned up automatically. It is checked periodically (at most every 24 hours) and log files are deleted if they haven’t been used for 7 days.
If the above isn’t enough to pinpoint the problem, you can enable the org.gradle.kotlin.dsl.logging.tapi system property in your IDE. This will cause the Gradle Daemon to log extra information in its log file located in $HOME/.gradle/daemon. In IntelliJ IDEA this can be done by opening Help > Edit Custom VM Options… and adding -Dorg.gradle.kotlin.dsl.logging.tapi=true.
For IDE problems outside of the Kotlin DSL script editor, please open issues in the corresponding IDE’s issue tracker:
Lastly, if you face problems with Gradle itself or with the Kotlin DSL, please open issues on the Gradle issue tracker.
Kotlin DSL scripts
Just like the Groovy-based equivalent, the Kotlin DSL is implemented on top of Gradle’s Java API. Everything you can read in a Kotlin DSL script is Kotlin code compiled and executed by Gradle. Many of the objects, functions and properties you use in your build scripts come from the Gradle API and the APIs of the applied plugins.
|
Tip
|
You can use the Kotlin DSL reference search functionality to drill through the available members. |
Script file names
-
Groovy DSL script files use the
.gradlefile name extension. -
Kotlin DSL script files use the
.gradle.ktsfile name extension.
To activate the Kotlin DSL, simply use the .gradle.kts extension for your build scripts in place of .gradle. That also applies to the settings file — for example settings.gradle.kts — and initialization scripts.
Note that you can mix Groovy DSL build scripts with Kotlin DSL ones, i.e. a Kotlin DSL build script can apply a Groovy DSL one and each project in a multi-project build can use either one.
We recommend that you apply the following conventions to get better IDE support:
-
Name settings scripts (or any script that is backed by a Gradle
Settingsobject) according to the pattern*.settings.gradle.kts— this includes script plugins that are applied from settings scripts -
Name initialization scripts according to the pattern
*.init.gradle.ktsor simplyinit.gradle.kts.
Implicit imports
All Kotlin DSL build scripts have implicit imports consisting of:
-
The Kotlin DSL API, which is all types within the following packages:
-
org.gradle.kotlin.dsl -
org.gradle.kotlin.dsl.plugins.dsl -
org.gradle.kotlin.dsl.precompile
-
Use of internal Kotlin DSL APIs in plugins and build scripts has the potential to break builds when either Gradle or plugins change. The Kotlin DSL API extends the Gradle public API with the types listed in the corresponding API docs that are in the packages listed above (but not subpackages of those).
Compilation warnings
Gradle Kotlin DSL scripts are compiled by Gradle during the configuration phase of your build. Deprecation warnings found by the Kotlin compiler are reported on the console when compiling the scripts.
> Configure project :
w: build.gradle.kts:4:5: 'getter for uploadTaskName: String!' is deprecated. Deprecated in JavaIt is possible to configure your build to fail on any warning emitted during script compilation by setting the org.gradle.kotlin.dsl.allWarningsAsErrors Gradle property to true:
# gradle.properties
org.gradle.kotlin.dsl.allWarningsAsErrors=trueType-safe model accessors
The Groovy DSL allows you to reference many elements of the build model by name, even when they are defined at runtime. Think named configurations, named source sets, and so on. For example, you can get hold of the implementation configuration via configurations.implementation.
The Kotlin DSL replaces such dynamic resolution with type-safe model accessors that work with model elements contributed by plugins.
Understanding when type-safe model accessors are available
The Kotlin DSL currently supports type-safe model accessors for any of the following that are contributed by plugins:
-
Dependency and artifact configurations (such as
implementationandruntimeOnlycontributed by the Java Plugin) -
Project extensions and conventions (such as
sourceSets) -
Extensions on the
dependenciesandrepositoriescontainers -
Elements in the
tasksandconfigurationscontainers -
Elements in project-extension containers (for example the source sets contributed by the Java Plugin that are added to the
sourceSetscontainer) -
Extensions on each of the above
|
Important
|
Only the main project build scripts and precompiled project script plugins have type-safe model accessors. Initialization scripts, settings scripts, script plugins do not. These limitations will be removed in a future Gradle release. |
The set of type-safe model accessors available is calculated right before evaluating the script body, immediately after the plugins {} block.
Any model elements contributed after that point do not work with type-safe model accessors.
For example, this includes any configurations you might define in your own build script.
However, this approach does mean that you can use type-safe accessors for any model elements that are contributed by plugins that are applied by parent projects.
The following project build script demonstrates how you can access various configurations, extensions and other elements using type-safe accessors:
plugins {
`java-library`
}
dependencies { // (1)
api("junit:junit:4.13")
implementation("junit:junit:4.13")
testImplementation("junit:junit:4.13")
}
configurations { // (1)
implementation {
resolutionStrategy.failOnVersionConflict()
}
}
sourceSets { // (2)
main { // (3)
java.srcDir("src/core/java")
}
}
java { // (4)
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}
tasks {
test { // (5)
testLogging.showExceptions = true
useJUnit()
}
}-
Uses type-safe accessors for the
api,implementationandtestImplementationdependency configurations contributed by the Java Library Plugin -
Uses an accessor to configure the
sourceSetsproject extension -
Uses an accessor to configure the
mainsource set -
Uses an accessor to configure the
javasource for themainsource set -
Uses an accessor to configure the
testtask
|
Tip
|
Your IDE knows about the type-safe accessors, so it will include them in its suggestions. This will happen both at the top level of your build scripts — most plugin extensions are added to the |
Note that accessors for elements of containers such as configurations, tasks and sourceSets leverage Gradle’s configuration avoidance APIs.
For example, on tasks they are of type TaskProvider<T> and provide a lazy reference and lazy configuration of the underlying task.
Here are some examples that illustrate the situations in which configuration avoidance applies:
tasks.test {
// lazy configuration
}
// Lazy reference
val testProvider: TaskProvider<Test> = tasks.test
testProvider {
// lazy configuration
}
// Eagerly realized Test task, defeat configuration avoidance if done out of a lazy context
val test: Test = tasks.test.get()For all other containers than tasks, accessors for elements are of type NamedDomainObjectProvider<T> and provide the same behavior.
Understanding what to do when type-safe model accessors are not available
Consider the sample build script shown above that demonstrates the use of type-safe accessors.
The following sample is exactly the same except that is uses the apply() method to apply the plugin.
The build script can not use type-safe accessors in this case because the apply() call happens in the body of the build script.
You have to use other techniques instead, as demonstrated here:
apply(plugin = "java-library")
dependencies {
"api"("junit:junit:4.13")
"implementation"("junit:junit:4.13")
"testImplementation"("junit:junit:4.13")
}
configurations {
"implementation" {
resolutionStrategy.failOnVersionConflict()
}
}
configure<SourceSetContainer> {
named("main") {
java.srcDir("src/core/java")
}
}
configure<JavaPluginExtension> {
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}
tasks {
named<Test>("test") {
testLogging.showExceptions = true
}
}Type-safe accessors are unavailable for model elements contributed by the following:
-
Plugins applied via the
apply(plugin = "id")method -
The project build script
-
Script plugins, via
apply(from = "script-plugin.gradle.kts") -
Plugins applied via cross-project configuration
You also can not use type-safe accessors in Binary Gradle plugins implemented in Kotlin.
If you can’t find a type-safe accessor, fall back to using the normal API for the corresponding types. To do that, you need to know the names and/or types of the configured model elements. We’ll now show you how those can be discovered by looking at the above script in detail.
Artifact configurations
The following sample demonstrates how to reference and configure artifact configurations without type accessors:
apply(plugin = "java-library")
dependencies {
"api"("junit:junit:4.13")
"implementation"("junit:junit:4.13")
"testImplementation"("junit:junit:4.13")
}
configurations {
"implementation" {
resolutionStrategy.failOnVersionConflict()
}
}The code looks similar to that for the type-safe accessors, except that the configuration names are string literals in this case.
You can use string literals for configuration names in dependency declarations and within the configurations {} block.
The IDE won’t be able to help you discover the available configurations in this situation, but you can look them up either in the corresponding plugin’s documentation or by running gradle dependencies.
Project extensions and conventions
Project extensions and conventions have both a name and a unique type, but the Kotlin DSL only needs to know the type in order to configure them.
As the following sample shows for the sourceSets {} and java {} blocks from the original example build script, you can use the configure<T>() function with the corresponding type to do that:
apply(plugin = "java-library")
configure<SourceSetContainer> {
named("main") {
java.srcDir("src/core/java")
}
}
configure<JavaPluginExtension> {
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}Note that sourceSets is a Gradle extension on Project of type SourceSetContainer and java is an extension on Project of type JavaPluginExtension.
You can discover what extensions and conventions are available either by looking at the documentation for the applied plugins or by running gradle kotlinDslAccessorsReport, which prints the Kotlin code necessary to access the model elements contributed by all the applied plugins.
The report provides both names and types.
As a last resort, you can also check a plugin’s source code, but that shouldn’t be necessary in the majority of cases.
Note that you can also use the the<T>() function if you only need a reference to the extension or convention without configuring it, or if you want to perform a one-line configuration, like so:
the<SourceSetContainer>()["main"].srcDir("src/core/java")The snippet above also demonstrates one way of configuring the elements of a project extension that is a container.
Elements in project-extension containers
Container-based project extensions, such as SourceSetContainer, also allow you to configure the elements held by them.
In our sample build script, we want to configure a source set named main within the source set container, which we can do by using the named() method in place of an accessor, like so:
apply(plugin = "java-library")
configure<SourceSetContainer> {
named("main") {
java.srcDir("src/core/java")
}
}All elements within a container-based project extension have a name, so you can use this technique in all such cases.
As for project extensions and conventions themselves, you can discover what elements are present in any container by either looking at the documentation of the applied plugins or by running gradle kotlinDslAccessorsReport.
And as a last resort, you may be able to view the plugin’s source code to find out what it does, but that shouldn’t be necessary in the majority of cases.
Tasks
Tasks are not managed through a container-based project extension, but they are part of a container that behaves in a similar way. This means that you can configure tasks in the same way as you do for source sets, as you can see in this example:
apply(plugin = "java-library")
tasks {
named<Test>("test") {
testLogging.showExceptions = true
}
}We are using the Gradle API to refer to the tasks by name and type, rather than using accessors.
Note that it’s necessary to specify the type of the task explicitly, otherwise the script won’t compile because the inferred type will be Task, not Test, and the testLogging property is specific to the Test task type.
You can, however, omit the type if you only need to configure properties or to call methods that are common to all tasks, i.e. they are declared on the Task interface.
One can discover what tasks are available by running gradle tasks. You can then find out the type of a given task by running gradle help --task <taskName>, as demonstrated here:
❯ ./gradlew help --task test
...
Type
Test (org.gradle.api.tasks.testing.Test)Note that the IDE can assist you with the required imports, so you only need the simple names of the types, i.e. without the package name part.
In this case, there’s no need to import the Test task type as it is part of the Gradle API and is therefore imported implicitly.
About conventions
Some of the Gradle core plugins expose configurability with the help of a so-called convention object. These serve a similar purpose to — and have now been superseded by — extensions. Conventions are deprecated. Please avoid using convention objects when writing new plugins.
As seen above, the Kotlin DSL provides accessors only for convention objects on Project.
There are situations that require you to interact with a Gradle plugin that uses convention objects on other types.
The Kotlin DSL provides the withConvention(T::class) {} extension function to do this:
sourceSets {
main {
withConvention(CustomSourceSetConvention::class) {
someOption = "some value"
}
}
}This technique is primarily necessary for source sets added by language plugins that have yet to be migrated to extensions.
Multi-project builds
As with single-project builds, you should try to use the plugins {} block in your multi-project builds so that you can use the type-safe accessors. Another consideration with multi-project builds is that you won’t be able to use type-safe accessors when configuring subprojects within the root build script or with other forms of cross configuration between projects. We discuss both topics in more detail in the following sections.
Applying plugins
You can declare your plugins within the subprojects to which they apply, but we recommend that you also declare them within the root project build script. This makes it easier to keep plugin versions consistent across projects within a build. The approach also improves the performance of the build.
The Using Gradle plugins chapter explains how you can declare plugins in the root project build script with a version and then apply them to the appropriate subprojects' build scripts. What follows is an example of this approach using three subprojects and three plugins. Note how the root build script only declares the community plugins as the Java Library Plugin is tied to the version of Gradle you are using:
rootProject.name = "multi-project-build"
include("domain", "infra", "http")plugins {
id("com.github.johnrengelman.shadow") version "7.1.2" apply false
id("io.ratpack.ratpack-java") version "1.8.2" apply false
}plugins {
`java-library`
}
dependencies {
api("javax.measure:unit-api:1.0")
implementation("tec.units:unit-ri:1.0.3")
}plugins {
`java-library`
id("com.github.johnrengelman.shadow")
}
shadow {
applicationDistribution.from("src/dist")
}
tasks.shadowJar {
minimize()
}plugins {
java
id("io.ratpack.ratpack-java")
}
dependencies {
implementation(project(":domain"))
implementation(project(":infra"))
implementation(ratpack.dependency("dropwizard-metrics"))
}
application {
mainClass = "example.App"
}
ratpack.baseDir = file("src/ratpack/baseDir")If your build requires additional plugin repositories on top of the Gradle Plugin Portal, you should declare them in the pluginManagement {} block in your settings.gradle.kts file, like so:
pluginManagement {
repositories {
mavenCentral()
gradlePluginPortal()
}
}Plugins fetched from a source other than the Gradle Plugin Portal can only be declared via the plugins {} block if they are published with their plugin marker artifacts.
|
Note
|
At the time of writing, all versions of the Android Plugin for Gradle up to 3.2.0 present in the google() repository lack plugin marker artifacts.
|
If those artifacts are missing, then you can’t use the plugins {} block. You must instead fall back to declaring your plugin dependencies using the buildscript {} block in the root project build script. Here’s an example of doing that for the Android Plugin:
include("lib", "app")buildscript {
repositories {
google()
gradlePluginPortal()
}
dependencies {
classpath("com.android.tools.build:gradle:7.3.0")
}
}plugins {
id("com.android.library")
}
android {
// ...
}plugins {
id("com.android.application")
}
android {
// ...
}This technique is not that different from what Android Studio produces when creating a new build.
The main difference is that the subprojects' build scripts in the above sample declare their plugins using the plugins {} block. This means that you can use type-safe accessors for the model elements that they contribute.
Note that you can’t use this technique if you want to apply such a plugin either to the root project build script of a multi-project build (rather than solely to its subprojects) or to a single-project build. You’ll need to use a different approach in those cases that we detail in another section.
Cross-configuring projects
Cross project configuration is a mechanism by which you can configure a project from another project’s build script. A common example is when you configure subprojects in the root project build script.
Taking this approach means that you won’t be able to use type-safe accessors for model elements contributed by the plugins. You will instead have to rely on string literals and the standard Gradle APIs.
As an example, let’s modify the Java/Ratpack sample build to fully configure its subprojects from the root project build script:
rootProject.name = "multi-project-build"
include("domain", "infra", "http")import com.github.jengelman.gradle.plugins.shadow.ShadowExtension
import com.github.jengelman.gradle.plugins.shadow.tasks.ShadowJar
import ratpack.gradle.RatpackExtension
plugins {
id("com.github.johnrengelman.shadow") version "7.1.2" apply false
id("io.ratpack.ratpack-java") version "1.8.2" apply false
}
project(":domain") {
apply(plugin = "java-library")
repositories { mavenCentral() }
dependencies {
"api"("javax.measure:unit-api:1.0")
"implementation"("tec.units:unit-ri:1.0.3")
}
}
project(":infra") {
apply(plugin = "java-library")
apply(plugin = "com.github.johnrengelman.shadow")
configure<ShadowExtension> {
applicationDistribution.from("src/dist")
}
tasks.named<ShadowJar>("shadowJar") {
minimize()
}
}
project(":http") {
apply(plugin = "java")
apply(plugin = "io.ratpack.ratpack-java")
repositories { mavenCentral() }
val ratpack = the<RatpackExtension>()
dependencies {
"implementation"(project(":domain"))
"implementation"(project(":infra"))
"implementation"(ratpack.dependency("dropwizard-metrics"))
"runtimeOnly"("org.slf4j:slf4j-simple:1.7.25")
}
configure<JavaApplication> {
mainClass = "example.App"
}
ratpack.baseDir = file("src/ratpack/baseDir")
}Note how we’re using the apply() method to apply the plugins since the plugins {} block doesn’t work in this context.
We are also using standard APIs instead of type-safe accessors to configure tasks, extensions and conventions — an approach that we discussed in more detail elsewhere.
When you can’t use the plugins {} block
Plugins fetched from a source other than the Gradle Plugin Portal may or may not be usable with the plugins {} block.
It depends on how they have been published and, specifically, whether they have been published with the necessary plugin marker artifacts.
For example, the Android Plugin for Gradle is not published to the Gradle Plugin Portal and — at least up to version 3.2.0 of the plugin — the metadata required to resolve the artifacts for a given plugin identifier is not published to the Google repository.
If your build is a multi-project build and you don’t need to apply such a plugin to your root project, then you can get round this issue using the technique described above. For any other situation, keep reading.
|
Tip
|
When publishing plugins, please use Gradle’s built-in Gradle Plugin Development Plugin. It automates the publication of the metadata necessary to make your plugins usable with the |
We will show you in this section how to apply the Android Plugin to a single-project build or the root project of a multi-project build.
The goal is to instruct your build on how to map the com.android.application plugin identifier to a resolvable artifact.
This is done in two steps:
-
Add a plugin repository to the build’s settings script
-
Map the plugin ID to the corresponding artifact coordinates
You accomplish both steps by configuring a pluginManagement {} block in the build’s settings script.
To demonstrate, the following sample adds the google() repository — where the Android plugin is published — to the repository search list, and uses a resolutionStrategy {} block to map the com.android.application plugin ID to the com.android.tools.build:gradle:<version> artifact available in the google() repository:
pluginManagement {
repositories {
google()
gradlePluginPortal()
}
resolutionStrategy {
eachPlugin {
if(requested.id.namespace == "com.android") {
useModule("com.android.tools.build:gradle:${requested.version}")
}
}
}
}plugins {
id("com.android.application") version "7.3.0"
}
android {
// ...
}In fact, the above sample will work for all com.android.* plugins that are provided by the specified module. That’s because the packaged module contains the details of which plugin ID maps to which plugin implementation class, using the properties-file mechanism described in the Writing Custom Plugins chapter.
See the Plugin Management section of the Gradle user manual for more information on the pluginManagement {} block and what it can be used for.
Working with container objects
The Gradle build model makes heavy use of container objects (or just "containers").
For example, both configurations and tasks are container objects that contain Configuration and Task objects respectively.
Community plugins also contribute containers, like the android.buildTypes container contributed by the Android Plugin.
The Kotlin DSL provides several ways for build authors to interact with containers.
We look at each of those ways next, using the tasks container as an example.
|
Tip
|
Note that you can leverage the type-safe accessors described in another section if you are configuring existing elements on supported containers. That section also describes which containers support type-safe accessors. |
Using the container API
All containers in Gradle implement NamedDomainObjectContainer<DomainObjectType>. Some of them can contain objects of different types and implement PolymorphicDomainObjectContainer<BaseType>. The simplest way to interact with containers is through these interfaces.
The following sample demonstrates how you can use the named() method to configure existing tasks and the register() method to create new ones.
tasks.named("check") // (1)
tasks.register("myTask1") // (2)
tasks.named<JavaCompile>("compileJava") // (3)
tasks.register<Copy>("myCopy1") // (4)
tasks.named("assemble") { // (5)
dependsOn(":myTask1")
}
tasks.register("myTask2") { // (6)
description = "Some meaningful words"
}
tasks.named<Test>("test") { // (7)
testLogging.showStackTraces = true
}
tasks.register<Copy>("myCopy2") { // (8)
from("source")
into("destination")
}-
Gets a reference of type
Taskto the existing task namedcheck -
Registers a new untyped task named
myTask1 -
Gets a reference to the existing task named
compileJavaof typeJavaCompile -
Registers a new task named
myCopy1of typeCopy -
Gets a reference to the existing (untyped) task named
assembleand configures it — you can only configure properties and methods that are available onTaskwith this syntax -
Registers a new untyped task named
myTask2and configures it — you can only configure properties and methods that are available onTaskin this case -
Gets a reference to the existing task named
testof typeTestand configures it — in this case you have access to the properties and methods of the specified type -
Registers a new task named
myCopy2of typeCopyand configures it
|
Note
|
The above sample relies on the configuration avoidance APIs. If you need or want to eagerly configure or register container elements, simply replace named() with getByName() and register() with create().
|
Using Kotlin delegated properties
Another way to interact with containers is via Kotlin delegated properties. These are particularly useful if you need a reference to a container element that you can use elsewhere in the build. In addition, Kotlin delegated properties can easily be renamed via IDE refactoring.
The following sample does the exact same things as the one in the previous section, but it uses delegated properties and reuses those references in place of string-literal task paths:
val check by tasks.existing
val myTask1 by tasks.registering
val compileJava by tasks.existing(JavaCompile::class)
val myCopy1 by tasks.registering(Copy::class)
val assemble by tasks.existing {
dependsOn(myTask1) // (1)
}
val myTask2 by tasks.registering {
description = "Some meaningful words"
}
val test by tasks.existing(Test::class) {
testLogging.showStackTraces = true
}
val myCopy2 by tasks.registering(Copy::class) {
from("source")
into("destination")
}-
Uses the reference to the
myTask1task rather than a task path
|
Note
|
The above rely on configuration avoidance APIs.
If you need to eagerly configure or register container elements simply replace |
Configuring multiple container elements together
When configuring several elements of a container one can group interactions in a block in order to avoid repeating the container’s name on each interaction. The following example uses a combination of type-safe accessors, the container API and Kotlin delegated properties:
tasks {
test {
testLogging.showStackTraces = true
}
val myCheck by registering {
doLast { /* assert on something meaningful */ }
}
check {
dependsOn(myCheck)
}
register("myHelp") {
doLast { /* do something helpful */ }
}
}Working with runtime properties
Gradle has two main sources of properties that are defined at runtime: project properties and extra properties. The Kotlin DSL provides specific syntax for working with these types of properties, which we look at in the following sections.
Project properties
The Kotlin DSL allows you to access project properties by binding them via Kotlin delegated properties. Here’s a sample snippet that demonstrates the technique for a couple of project properties, one of which must be defined:
val myProperty: String by project // (1)
val myNullableProperty: String? by project // (2)-
Makes the
myPropertyproject property available via amyPropertydelegated property — the project property must exist in this case, otherwise the build will fail when the build script attempts to use themyPropertyvalue -
Does the same for the
myNullablePropertyproject property, but the build won’t fail on using themyNullablePropertyvalue as long as you check for null (standard Kotlin rules for null safety apply)
The same approach works in both settings and initialization scripts, except you use by settings and by gradle respectively in place of by project.
Extra properties
Extra properties are available on any object that implements the ExtensionAware interface.
Kotlin DSL allows you to access extra properties and create new ones via delegated properties, using any of the by extra forms demonstrated in the following sample:
val myNewProperty by extra("initial value") // (1)
val myOtherNewProperty by extra { "calculated initial value" } // (2)
val myProperty: String by extra // (3)
val myNullableProperty: String? by extra // (4)-
Creates a new extra property called
myNewPropertyin the current context (the project in this case) and initializes it with the value"initial value", which also determines the property’s type -
Create a new extra property whose initial value is calculated by the provided lambda
-
Binds an existing extra property from the current context (the project in this case) to a
myPropertyreference -
Does the same as the previous line but allows the property to have a null value
This approach works for all Gradle scripts: project build scripts, script plugins, settings scripts and initialization scripts.
You can also access extra properties on a root project from a subproject using the following syntax:
val myNewProperty: String by rootProject.extra // (1)-
Binds the root project’s
myNewPropertyextra property to a reference of the same name
Extra properties aren’t just limited to projects.
For example, Task extends ExtensionAware, so you can attach extra properties to tasks as well.
Here’s an example that defines a new myNewTaskProperty on the test task and then uses that property to initialize another task:
tasks {
test {
val reportType by extra("dev") // (1)
doLast {
// Use 'suffix' for post processing of reports
}
}
register<Zip>("archiveTestReports") {
val reportType: String by test.get().extra // (2)
archiveAppendix = reportType
from(test.get().reports.html.destination)
}
}-
Creates a new
reportTypeextra property on thetesttask -
Makes the
testtask’sreportTypeextra property available to configure thearchiveTestReportstask
If you’re happy to use eager configuration rather than the configuration avoidance APIs, you could use a single, "global" property for the report type, like this:
tasks.test.doLast { ... }
val testReportType by tasks.test.get().extra("dev") // (1)
tasks.create<Zip>("archiveTestReports") {
archiveAppendix = testReportType // (2)
from(test.get().reports.html.destination)
}-
Creates and initializes an extra property on the
testtask, binding it to a "global" property -
Uses the "global" property to initialize the
archiveTestReportstask
There is one last syntax for extra properties that we should cover, one that treats extra as a map.
We recommend against using this in general as you lose the benefits of Kotlin’s type checking and it prevents IDEs from providing as much support as they could.
However, it is more succinct than the delegated properties syntax and can reasonably be used if you only need to set the value of an extra property without referencing it later.
Here’s a simple example demonstrating how to set and read extra properties using the map syntax:
extra["myNewProperty"] = "initial value" // (1)
tasks.create("myTask") {
doLast {
println("Property: ${project.extra["myNewProperty"]}") // (2)
}
}-
Creates a new project extra property called
myNewPropertyand sets its value -
Reads the value from the project extra property we created — note the
project.qualifier onextra[…], otherwise Gradle will assume we want to read an extra property from the task
Kotlin lazy property assignment
Gradle’s Kotlin DSL supports lazy property assignment using the = operator .
Lazy property assignment reduces the verbosity for Kotlin DSL when lazy properties are used.
It works for properties that are publicly seen as final (without a setter) and have type Property or ConfigurableFileCollection.
Since properties have to be final, our general recommendation is not to implement custom setters for properties with lazy types and, if possible, implement such properties via an abstract getter.
Using the = operator is the preferred way to call set() in the Kotlin DSL.
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
abstract class WriteJavaVersionTask : DefaultTask() {
@get:Input
abstract val javaVersion: Property<String>
@get:OutputFile
abstract val output: RegularFileProperty
@TaskAction
fun execute() {
output.get().asFile.writeText("Java version: ${javaVersion.get()}")
}
}
tasks.register<WriteJavaVersionTask>("writeJavaVersion") {
javaVersion.set("17") // (1)
javaVersion = "17" // (2)
javaVersion = java.toolchain.languageVersion.map { it.toString() } // (3)
output = layout.buildDirectory.file("writeJavaVersion/javaVersion.txt")
}-
Set value with the
.set()method -
Set value with lazy property assignment using the
=operator -
The
=operator can be used also for assigning lazy values
IDE support
Lazy property assignment is supported from IntelliJ 2022.3 and from Android Studio Giraffe.
The Kotlin DSL Plugin
The Kotlin DSL Plugin provides a convenient way to develop Kotlin-based projects that contribute build logic. That includes buildSrc projects, included builds and Gradle plugins.
The plugin achieves this by doing the following:
-
Applies the Kotlin Plugin, which adds support for compiling Kotlin source files.
-
Adds the
kotlin-stdlib,kotlin-reflectandgradleKotlinDsl()dependencies to thecompileOnlyandtestImplementationconfigurations, which allows you to make use of those Kotlin libraries and the Gradle API in your Kotlin code. -
Configures the Kotlin compiler with the same settings that are used for Kotlin DSL scripts, ensuring consistency between your build logic and those scripts:
-
registers the SAM-with-receiver Kotlin compiler plugin.
-
Enables support for precompiled script plugins.
kotlin-dsl pluginEach Gradle release is meant to be used with a specific version of the kotlin-dsl plugin and compatibility between arbitrary Gradle releases and kotlin-dsl plugin versions is not guaranteed. Using an unexpected version of the kotlin-dsl plugin in a build will emit a warning and can cause hard to diagnose problems.
This is the basic configuration you need to use the plugin:
buildSrc projectplugins {
`kotlin-dsl`
}
repositories {
// The org.jetbrains.kotlin.jvm plugin requires a repository
// where to download the Kotlin compiler dependencies from.
mavenCentral()
}The Kotlin DSL Plugin leverages Java Toolchains. By default the code will target Java 8. You can change that by defining a Java toolchain to be used by the project:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
}
}The embedded Kotlin
Gradle embeds Kotlin in order to provide support for Kotlin-based scripts.
Kotlin versions
Gradle ships with kotlin-compiler-embeddable plus matching versions of kotlin-stdlib and kotlin-reflect libraries. For details see the Kotlin section of Gradle’s compatibility matrix. The kotlin package from those modules is visible through the Gradle classpath.
The compatibility guarantees provided by Kotlin apply for both backward and forward compatibility.
Backward compatibility
Our approach is to only do backwards-breaking Kotlin upgrades on a major Gradle release. We will always clearly document which Kotlin version we ship and announce upgrade plans before a major release.
Plugin authors who want to stay compatible with older Gradle versions need to limit their API usage to a subset that is compatible with these old versions. It’s not really different from any other new API in Gradle. E.g. if we introduce a new API for dependency resolution and a plugin wants to use that API, then they either need to drop support for older Gradle versions or they need to do some clever organization of their code to only execute the new code path on newer versions.
Forward compatibility
The biggest issue is the compatibility between the external kotlin-gradle-plugin version and the kotlin-stdlib version shipped with Gradle. More generally, between any plugin that transitively depends on kotlin-stdlib and its version shipped with Gradle. As long as the combination is compatible everything should work. This will become less of an issue as the language matures.
Kotlin compiler arguments
These are the Kotlin compiler arguments used for compiling Kotlin DSL scripts and Kotlin sources and scripts in a project that has the kotlin-dsl plugin applied:
-java-parameters-
Generate metadata for Java >= 1.8 reflection on method parameters. See Kotlin/JVM compiler options in the Kotlin documentation for more information.
-Xjvm-default=all-
Makes all non-abstract members of Kotlin interfaces default for the Java classes implementing them. This is to provide a better interoperability with Java and Groovy for plugins written in Kotlin. See Default methods in interfaces in the Kotlin documentation for more information.
-Xsam-conversions=class-
Sets up the implementation strategy for SAM (single abstract method) conversion to always generate anonymous classes, instead of using the
invokedynamicJVM instruction. This is to provide a better support for configuration cache and incremental build. See KT-44912 in the Kotlin issue tracker for more information. -Xjsr305=strict-
Sets up Kotlin’s Java interoperability to strictly follow JSR-305 annotations for increased null safety. See Calling Java code from Kotlin in the Kotlin documentation for more information.
Interoperability
When mixing languages in your build logic, you may have to cross language boundaries. An extreme example would be a build that uses tasks and plugins that are implemented in Java, Groovy and Kotlin, while also using both Kotlin DSL and Groovy DSL build scripts.
Quoting the Kotlin reference documentation:
Kotlin is designed with Java Interoperability in mind. Existing Java code can be called from Kotlin in a natural way, and Kotlin code can be used from Java rather smoothly as well.
Both calling Java from Kotlin and calling Kotlin from Java are very well covered in the Kotlin reference documentation.
The same mostly applies to interoperability with Groovy code. In addition, the Kotlin DSL provides several ways to opt into Groovy semantics, which we look at next.
Static extensions
Both the Groovy and Kotlin languages support extending existing classes via Groovy Extension modules and Kotlin extensions.
To call a Kotlin extension function from Groovy, call it as a static function, passing the receiver as the first parameter:
TheTargetTypeKt.kotlinExtensionFunction(receiver, "parameters", 42, aReference)Kotlin extension functions are package-level functions and you can learn how to locate the name of the type declaring a given Kotlin extension in the Package-Level Functions section of the Kotlin reference documentation.
To call a Groovy extension method from Kotlin, the same approach applies: call it as a static function passing the receiver as the first parameter. Here’s an example:
TheTargetTypeGroovyExtension.groovyExtensionMethod(receiver, "parameters", 42, aReference)Named parameters and default arguments
Both the Groovy and Kotlin languages support named function parameters and default arguments, although they are implemented very differently.
Kotlin has fully-fledged support for both, as described in the Kotlin language reference under named arguments and default arguments.
Groovy implements named arguments in a non-type-safe way based on a Map<String, ?> parameter, which means they cannot be combined with default arguments.
In other words, you can only use one or the other in Groovy for any given method.
Calling Kotlin from Groovy
To call a Kotlin function that has named arguments from Groovy, just use a normal method call with positional parameters. There is no way to provide values by argument name.
To call a Kotlin function that has default arguments from Groovy, always pass values for all the function parameters.
Calling Groovy from Kotlin
To call a Groovy function with named arguments from Kotlin, you need to pass a Map<String, ?>, as shown in this example:
groovyNamedArgumentTakingMethod(mapOf(
"parameterName" to "value",
"other" to 42,
"and" to aReference))To call a Groovy function with default arguments from Kotlin, always pass values for all the parameters.
Groovy closures from Kotlin
You may sometimes have to call Groovy methods that take Closure arguments from Kotlin code. For example, some third-party plugins written in Groovy expect closure arguments.
|
Note
|
Gradle plugins written in any language should prefer the type Action<T> type in place of closures. Groovy closures and Kotlin lambdas are automatically mapped to arguments of that type.
|
In order to provide a way to construct closures while preserving Kotlin’s strong typing, two helper methods exist:
-
closureOf<T> {} -
delegateClosureOf<T> {}
Both methods are useful in different circumstances and depend upon the method you are passing the Closure instance into.
Some plugins expect simple closures, as with the Bintray plugin:
closureOf<T> {}bintray {
pkg(closureOf<PackageConfig> {
// Config for the package here
})
}In other cases, like with the Gretty Plugin when configuring farms, the plugin expects a delegate closure:
delegateClosureOf<T> {}farms {
farm("OldCoreWar", delegateClosureOf<FarmExtension> {
// Config for the war here
})
}There sometimes isn’t a good way to tell, from looking at the source code, which version to use.
Usually, if you get a NullPointerException with closureOf<T> {}, using delegateClosureOf<T> {}
will resolve the problem.
These two utility functions are useful for configuration closures, but some plugins might expect Groovy closures for other purposes.
The KotlinClosure0 to KotlinClosure2 types allows adapting Kotlin functions to Groovy closures with more flexibility.
KotlinClosureX typessomePlugin {
// Adapt parameter-less function
takingParameterLessClosure(KotlinClosure0({
"result"
}))
// Adapt unary function
takingUnaryClosure(KotlinClosure1<String, String>({
"result from single parameter $this"
}))
// Adapt binary function
takingBinaryClosure(KotlinClosure2<String, String, String>({ a, b ->
"result from parameters $a and $b"
}))
}The Kotlin DSL Groovy Builder
If some plugin makes heavy use of Groovy metaprogramming, then using it from Kotlin or Java or any statically-compiled language can be very cumbersome.
The Kotlin DSL provides a withGroovyBuilder {} utility extension that attaches the Groovy metaprogramming semantics to objects of type Any.
The following example demonstrates several features of the method on the object target:
withGroovyBuilder {}target.withGroovyBuilder { // (1)
// GroovyObject methods available // (2)
if (hasProperty("foo")) { /*...*/ }
val foo = getProperty("foo")
setProperty("foo", "bar")
invokeMethod("name", arrayOf("parameters", 42, aReference))
// Kotlin DSL utilities
"name"("parameters", 42, aReference) // (3)
"blockName" { // (4)
// Same Groovy Builder semantics on `blockName`
}
"another"("name" to "example", "url" to "https://example.com/") // (5)
}-
The receiver is a GroovyObject and provides Kotlin helpers
-
The
GroovyObjectAPI is available -
Invoke the
methodNamemethod, passing some parameters -
Configure the
blockNameproperty, maps to aClosuretaking method invocation -
Invoke
anothermethod taking named arguments, maps to a Groovy named argumentsMap<String, ?>taking method invocation
Using a Groovy script
Another option when dealing with problematic plugins that assume a Groovy DSL build script is to configure them in a Groovy DSL build script that is applied from the main Kotlin DSL build script:
native { (1)
dynamic {
groovy as Usual
}
}plugins {
id("dynamic-groovy-plugin") version "1.0" (2)
}
apply(from = "dynamic-groovy-plugin-configuration.gradle") (3)-
The Groovy script uses dynamic Groovy to configure plugin
-
The Kotlin build script requests and applies the plugin
-
The Kotlin build script applies the Groovy script
Limitations
-
The Kotlin DSL is known to be slower than the Groovy DSL on first use, for example with clean checkouts or on ephemeral continuous integration agents. Changing something in the buildSrc directory also has an impact as it invalidates build-script caching. The main reason for this is the slower script compilation for Kotlin DSL.
-
In IntelliJ IDEA, you must import your project from the Gradle model in order to get content assist and refactoring support for your Kotlin DSL build scripts.
-
Kotlin DSL script compilation avoidance has known issues. If you encounter problems, it can be disabled by setting the
org.gradle.kotlin.dsl.scriptCompilationAvoidancesystem property tofalse. -
The Kotlin DSL will not support the
model {}block, which is part of the discontinued Gradle Software Model.
If you run into trouble or discover a suspected bug, please report the issue in the Gradle issue tracker.
LICENSE INFORMATION
License Information
Gradle Documentation
Copyright © 2007-2023 Gradle, Inc.
Gradle build tool source code is open-source and licensed under the Apache License 2.0.
Gradle user manual and DSL reference manual are licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
@groovy.transform.CompileStatic.
testng.xml文件时的测试排序的更多详细信息:http://testng.org/doc/documentation-main.html#testng-xml。